《Python星球日记》 第67天:Transformer 架构与自注意力机制
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、回顾Transformer架构
- 1. Transformer的起源与意义
- 2. 整体架构概览
- 二、自注意力机制详解
- 1. 自注意力(Self-Attention)的基本原理
- 2. QKV计算过程
- 3. 多头注意力(Multi-Head Attention)机制
- 三、位置编码与前馈网络
- 1. 位置编码的必要性
- 2. 正弦余弦位置编码
- 3. 前馈神经网络的作用
- 四、Transformer 的优势
- 1. 并行化训练与计算效率
- 2. 长距离依赖关系的捕捉
- 3. 与RNN/LSTM的对比
- 五、代码练习:实现一个简单的自注意力机制
- 1. 自注意力类的设计
- 2. 测试与可视化注意力机制
- 六、总结与展望
- 推荐阅读
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第66天:序列建模与语言模型
大家好,欢迎来到Python星球的第67天!🪐
在我们的Python学习之旅中,今天将深入探讨自然语言处理领域最具革命性的架构之一——Transformer。这一架构彻底改变了NLP领域,也为计算机视觉等其他领域带来了创新。让我们一起探索Transformer的奥秘和它的核心——自注意力机制。
一、回顾Transformer架构
1. Transformer的起源与意义
Transformer架构由Google团队在2017年的论文《Attention is All You Need》中首次提出。它解决了传统RNN和LSTM模型的两大痛点:
- 无法并行计算(序列依赖性)
- 长距离依赖问题(信息衰减)
在Transformer出现之前,处理序列数据几乎都依赖于循环神经网络结构,而Transformer证明了:仅仅依靠注意力机制,我们就能构建出更强大的模型。
2. 整体架构概览
Transformer采用了编码器-解码器(Encoder-Decoder)架构,由多个相同层堆叠而成。每一层编码器包含两个主要子层:自注意力层和前馈神经网络,而每个子层都使用了残差连接和层归一化。这种设计使得信息可以更顺畅地在网络中流动,同时保持梯度稳定性。
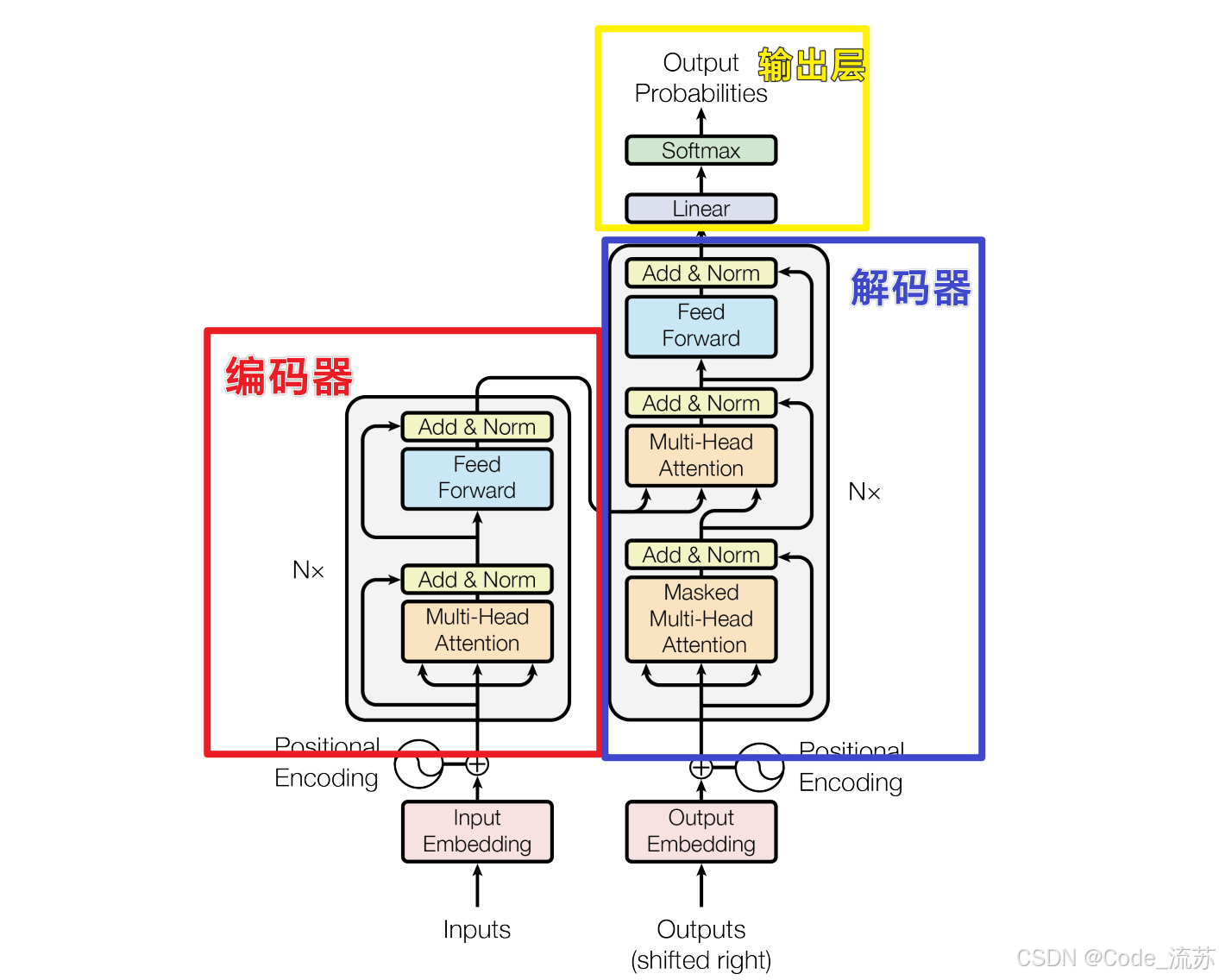
二、自注意力机制详解
1. 自注意力(Self-Attention)的基本原理
自注意力机制是Transformer的核心创新,它允许模型在处理序列中的每个位置时,能够"关注"序列中的所有其他位置,从而捕捉长距离依赖关系。
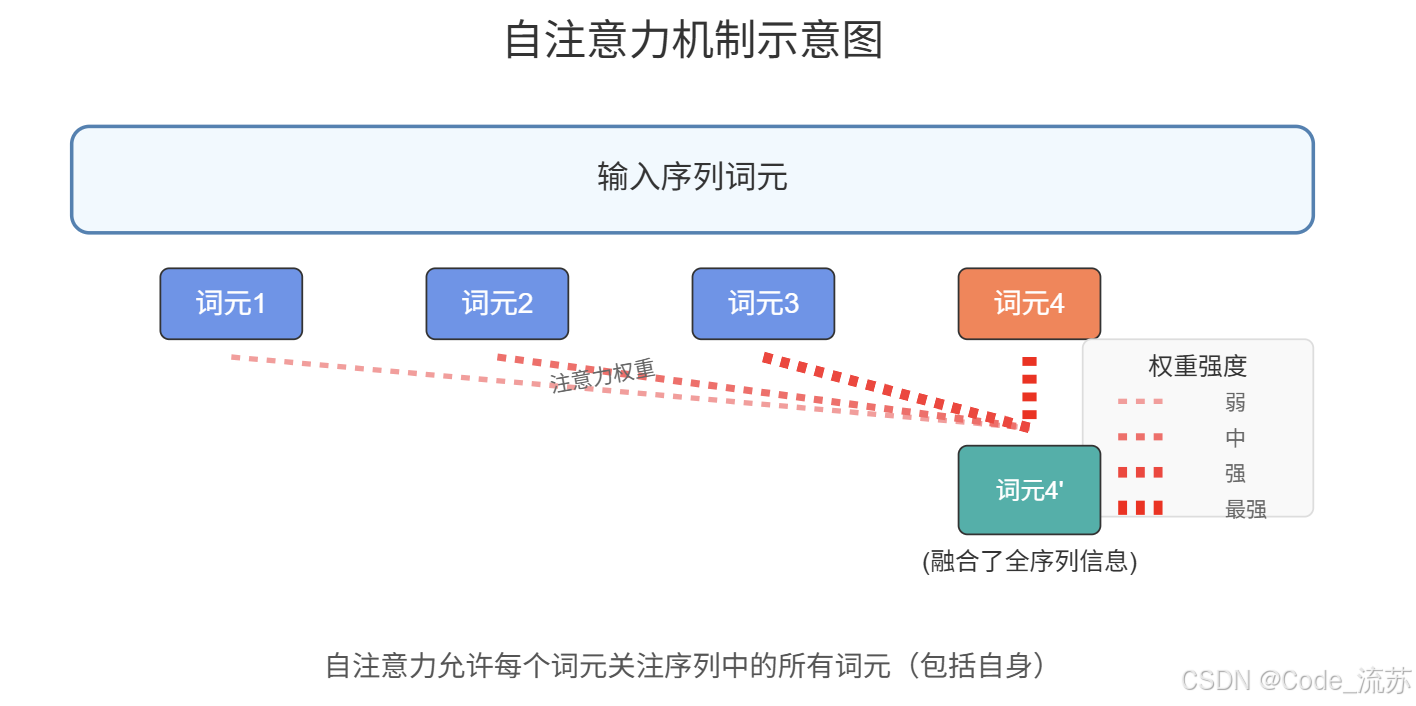
自注意力的基本思想非常直观:对于序列中的每个元素,我们希望知道它与序列中其他所有元素的关联程度,并据此进行信息整合。这种机制使模型能够在不受距离限制的情况下,灵活地从序列的任何部分获取信息。
想象一下,当我们阅读"The animal didn’t cross the street because it was too tired"(那只动物没有过马路,因为它太累了)这个句子时,“it"指代的是什么?作为人类,我们很容易理解"it"指的是"animal”。
而自注意力机制正是让模型学会这种关联能力的方式。
2. QKV计算过程
自注意力机制的核心是通过查询(Query)、**键(Key)和值(Value)**三个向量来计算注意力权重。这些向量通过对输入进行线性变换得到:
# 线性变换产生Q,K,V
Q = X @ W_q # 查询矩阵
K = X @ W_k # 键矩阵
V = X @ W_v # 值矩阵
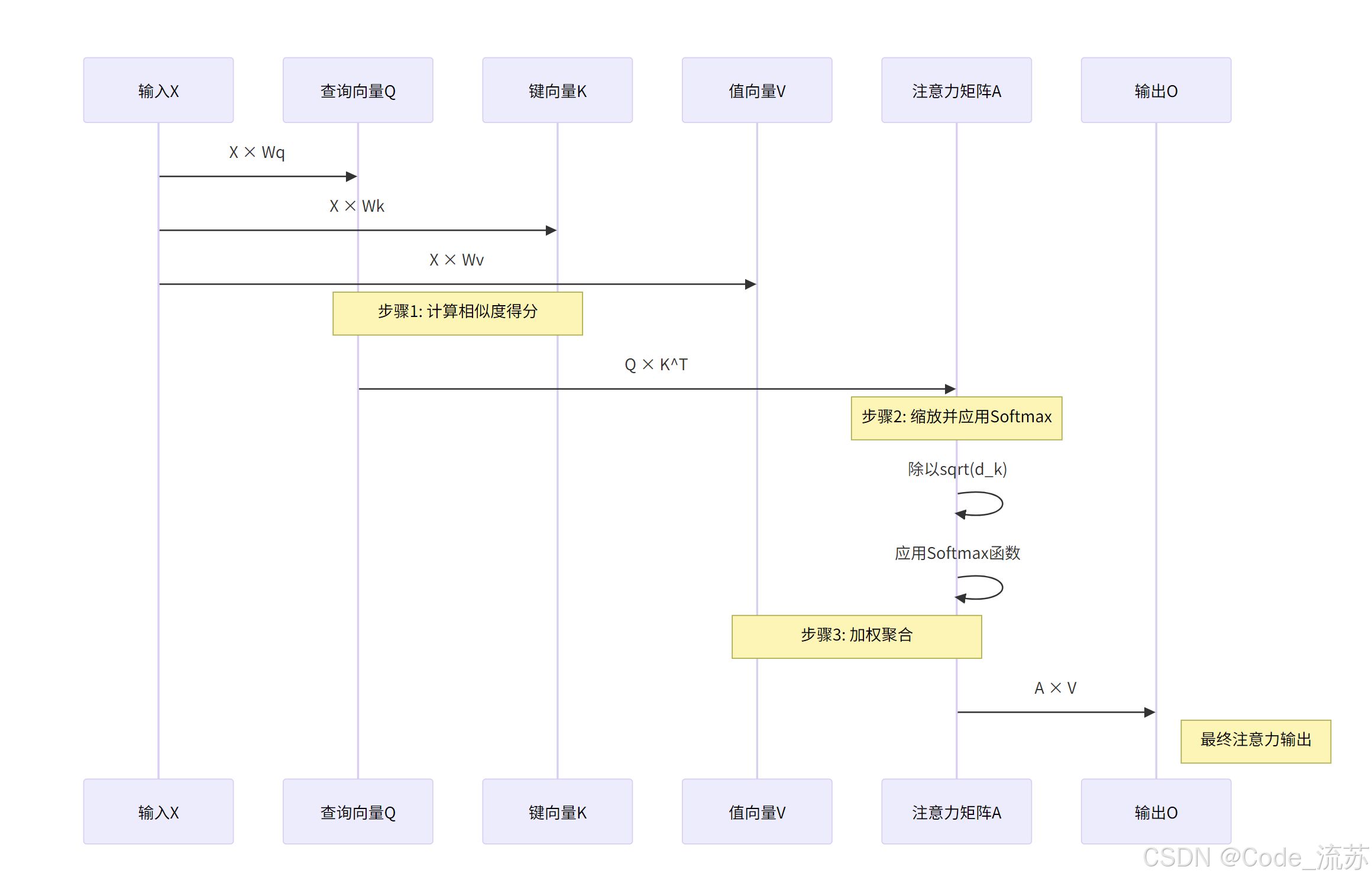
注意力计算的过程可以分为三步:
-
相似度计算:将查询向量与所有键向量进行点积运算,得到一个相似度分数矩阵:
# 计算注意力分数 scores = Q @ K.transpose(-2, -1) # [batch_size, seq_len, seq_len] -
缩放与归一化:为了稳定梯度,将分数除以键向量维度的平方根,然后应用softmax函数将分数转化为概率分布:
# 缩放 d_k = K.size(-1) scores = scores / math.sqrt(d_k)# 应用softmax得到注意力权重 attention_weights = F.softmax(scores, dim=-1) -
加权聚合:使用注意力权重对值向量进行加权求和,得到最终的注意力输出:
# 加权聚合 output = attention_weights @ V # [batch_size, seq_len, d_model]
若要用一张图来表示的话,大致如下:
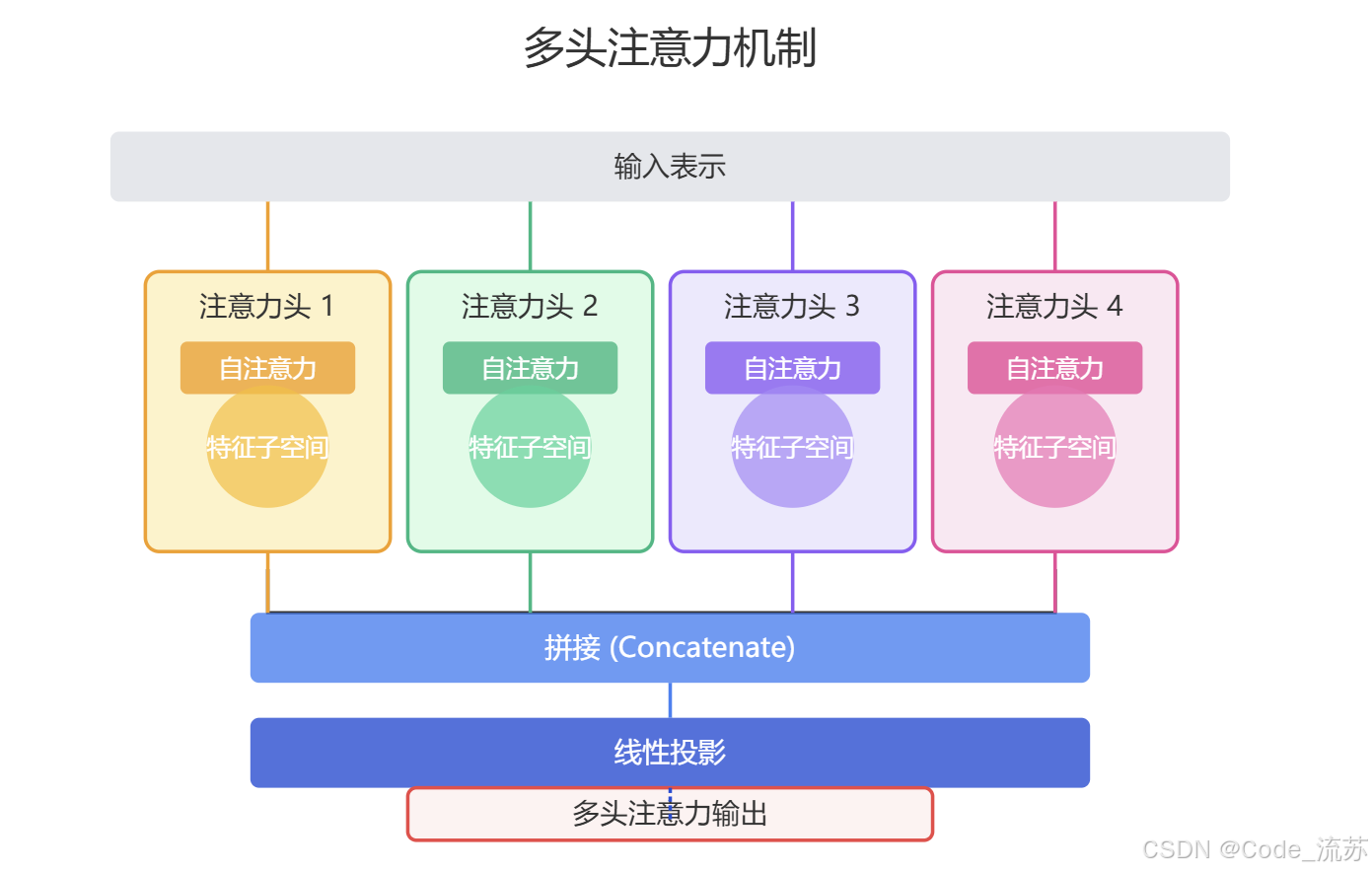
3. 多头注意力(Multi-Head Attention)机制
为了让模型能够关注不同位置的不同表示子空间信息,多头注意力机制被引入Transformer中。它允许模型同时学习多组不同的注意力模式:
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.head_dim = d_model // num_heads# 线性变换层self.q_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.out_linear = nn.Linear(d_model, d_model)def forward(self, q, k, v, mask=None):batch_size = q.size(0)# 线性变换并分割头q = self.q_linear(q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)k = self.k_linear(k).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)v = self.v_linear(v).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)# 注意力计算scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)attention_weights = F.softmax(scores, dim=-1)output = torch.matmul(attention_weights, v)# 合并多头结果output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)return self.out_linear(output)
多头注意力就像是多个"专家"同时分析同一个问题,每个专家关注不同的特征,最后将所有专家的意见整合起来。这种机制大大提高了模型的表达能力。
三、位置编码与前馈网络
1. 位置编码的必要性
Transformer中没有循环或卷积结构,这意味着模型对输入序列的位置信息"一无所知"。为解决这个问题,我们需要添加位置编码,将位置信息注入到输入表示中。
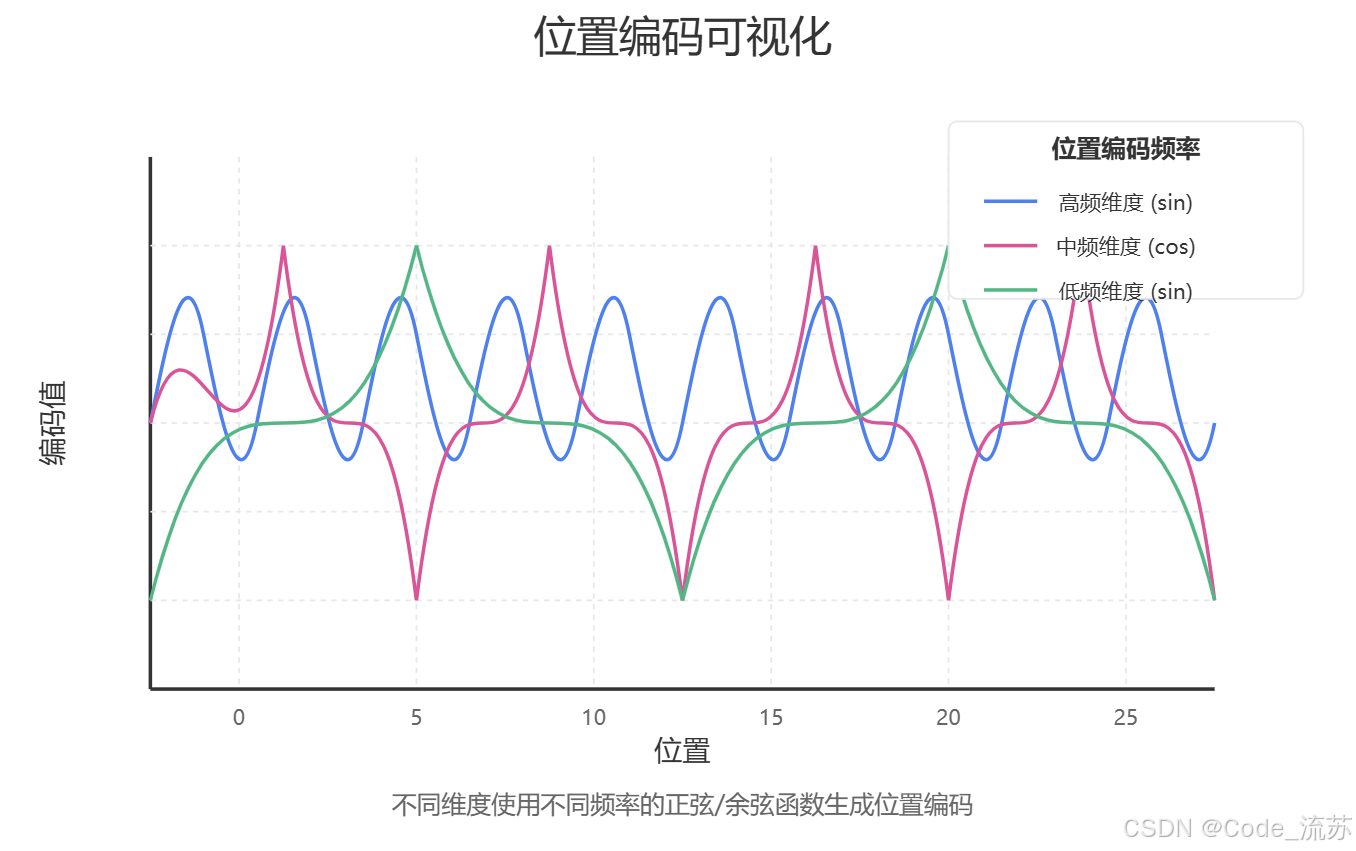
位置编码需要满足两个条件:
- 每个位置有唯一的编码
- 编码之间的相对关系应该保持一致(如距离相等的位置对应关系应相似)
2. 正弦余弦位置编码
原始Transformer使用的是基于正弦和余弦函数的位置编码:
def get_position_encoding(max_seq_len, d_model):position = torch.arange(0, max_seq_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pos_encoding = torch.zeros(max_seq_len, d_model)pos_encoding[:, 0::2] = torch.sin(position * div_term) # 偶数位置pos_encoding[:, 1::2] = torch.cos(position * div_term) # 奇数位置return pos_encoding
这种编码巧妙地利用了三角函数的特性,使得模型可以轻松学习相对位置关系。它的每一维都对应一个不同频率的正弦波,从而创建了独特的"位置指纹"。
3. 前馈神经网络的作用
自注意力层之后,Transformer使用前馈神经网络(Feed-Forward Network)来处理每个位置的表示。这是一个由两个线性变换组成的简单网络,中间有一个ReLU激活函数:
class FeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):return self.linear2(self.dropout(F.relu(self.linear1(x))))
这个网络对序列中每个位置独立应用,可以看作是对特征进行非线性变换的层,增强模型的表达能力。
四、Transformer 的优势
1. 并行化训练与计算效率
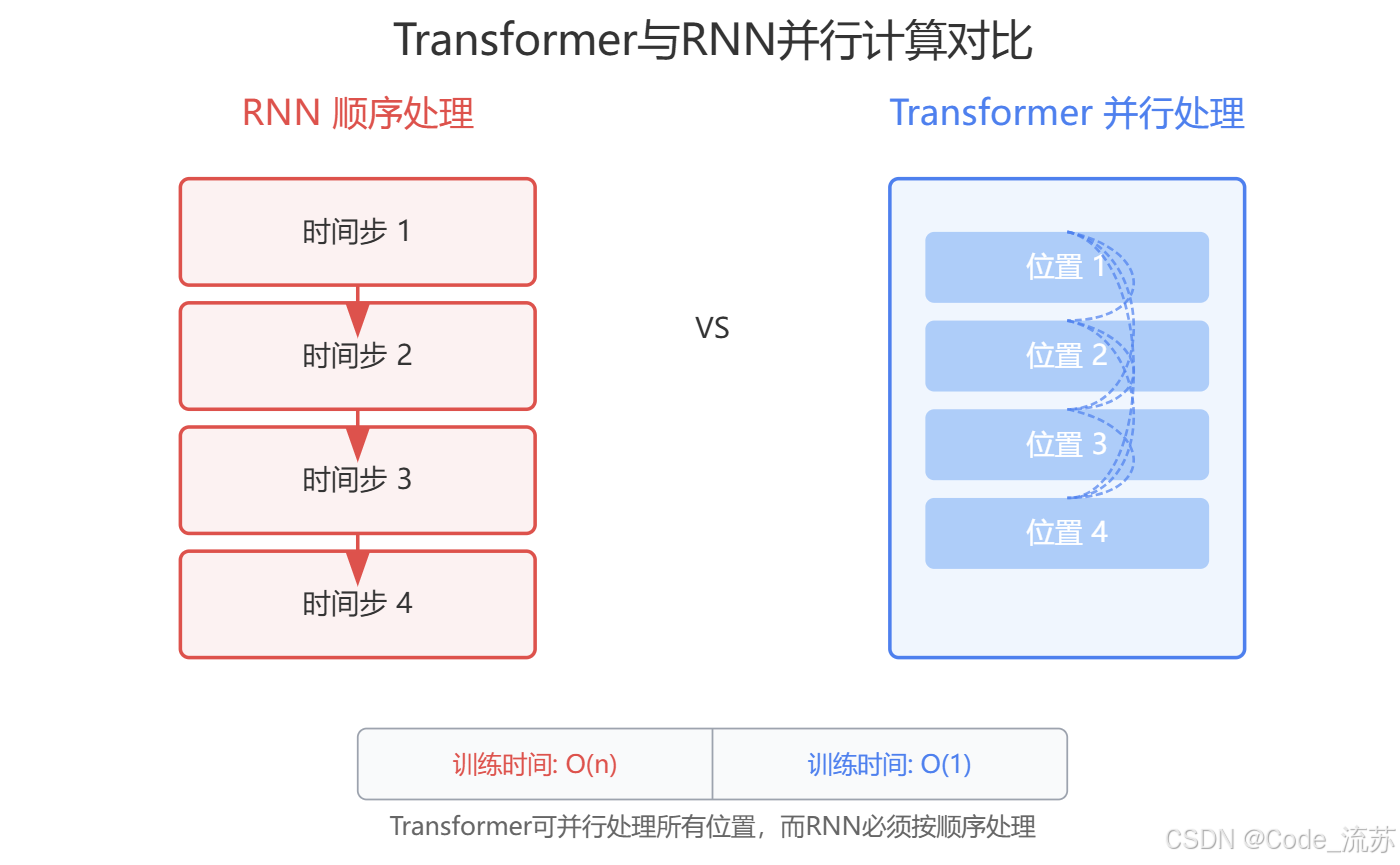
Transformer的一个重大突破是将序列处理从本质上变成了并行计算,这与RNN的顺序处理形成鲜明对比:
# RNN处理(顺序)
hidden = initial_state
for token in sequence:hidden = rnn_cell(token, hidden) # 必须依次计算# Transformer处理(并行)
outputs = self_attention(sequence) # 一次性处理整个序列
这种并行性使Transformer训练速度大大提升,尤其在处理长序列时优势更为明显。
2. 长距离依赖关系的捕捉
在RNN或LSTM中,随着序列长度增加,信息会逐渐衰减。而在Transformer中,由于自注意力机制允许直接连接任意两个位置,信息传递路径长度恒定为常数(O(1))。
例如,在处理这样的句子时:
“I grew up in France… I speak fluent French.”
如果需要确定"French"的上下文,即使相关信息"France"出现在很远的位置,Transformer也能轻松建立这种关联。
3. 与RNN/LSTM的对比
让我们比较Transformer与传统循环网络的关键区别:
| 特性 | RNN/LSTM | Transformer |
|---|---|---|
| 序列处理方式 | 顺序处理 | 并行处理 |
| 长距离依赖 | 随距离呈指数衰减 | 恒定强度 |
| 计算复杂度 | O(n) | O(1)~O(n²) |
| 参数量 | 较少 | 较多 |
| 训练效率 | 较低 | 很高 |
| 推理速度 | 较慢 | 较快 |
这些优势使Transformer成为处理序列数据的首选架构,不仅在NLP领域,如今在计算机视觉、音频处理等多个领域也有广泛应用。
五、代码练习:实现一个简单的自注意力机制
1. 自注意力类的设计
让我们实现一个简单的自注意力机制,并观察它是如何工作的:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
import matplotlib.pyplot as pltclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be divisible by heads"# 定义线性层来创建QKV矩阵self.q = nn.Linear(self.head_dim, self.head_dim, bias=False)self.k = nn.Linear(self.head_dim, self.head_dim, bias=False)self.v = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask=None):# 获取批次大小和序列长度N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 分割输入为多头values = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)# 计算QKVqueries = self.q(queries)keys = self.k(keys)values = self.v(values)# 计算能量(注意力分数)energy = torch.einsum("nqhd,nkhd->nqkh", [queries, keys])# queries shape: (N, query_len, heads, head_dim)# keys shape: (N, key_len, heads, head_dim)# energy shape: (N, query_len, key_len, heads)# 缩放注意力分数energy = energy / math.sqrt(self.head_dim)# 应用掩码(如果有)if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))# 应用Softmax得到注意力权重attention = torch.softmax(energy, dim=2)# 加权聚合值向量out = torch.einsum("nqkh,nvhd->nqhd", [attention, values])# attention shape: (N, query_len, key_len, heads)# values shape: (N, value_len, heads, head_dim)# out shape: (N, query_len, heads, head_dim)# 重塑并通过最终线性层out = out.reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out, attention
2. 测试与可视化注意力机制
让我们创建一个简单的例子,看看自注意力如何在实际中工作:
def visualize_attention():# 创建一个简单的序列seq_len = 4batch_size = 1embed_size = 512heads = 8# 创建随机输入x = torch.randn(batch_size, seq_len, embed_size)# 初始化自注意力模型attention = SelfAttention(embed_size, heads)# 通过模型获取输出和注意力权重output, attention_weights = attention(x, x, x)# 选择第一个头的注意力权重进行可视化att_matrix = attention_weights[0, :, :, 0].detach().numpy()# 可视化注意力矩阵plt.figure(figsize=(8, 6))plt.imshow(att_matrix, cmap='viridis')plt.colorbar()plt.title("Self-Attention Weights")plt.xlabel("Key Position")plt.ylabel("Query Position")plt.xticks(range(seq_len))plt.yticks(range(seq_len))# 添加数值标签for i in range(seq_len):for j in range(seq_len):plt.text(j, i, f'{att_matrix[i, j]:.2f}',ha="center", va="center", color="white" if att_matrix[i, j] > 0.5 else "black")plt.tight_layout()plt.show()# 运行可视化函数
visualize_attention()
通过这个练习,我们可以直观地看到自注意力机制是如何为不同位置分配权重的。注意这只是一个简化版的实现,完整的Transformer架构还包括位置编码、层归一化等组件。
六、总结与展望
今天,我们深入学习了Transformer架构的核心机制——自注意力。我们了解了:
- Transformer如何通过自注意力机制捕捉序列中的长距离依赖关系
- 自注意力计算过程中的QKV原理
- 多头注意力如何增强模型表达能力
- 位置编码如何为模型提供位置信息
- Transformer相比传统RNN/LSTM模型的优势
Transformer的出现彻底改变了NLP领域,并催生了BERT、GPT、DeepSeek、Qwen、llama等强大的预训练模型。如今,Transformer已经扩展到计算机视觉(ViT)、多模态学习等众多领域。
自从2017年诞生以来,Transformer架构已经成为深度学习中最重要的架构之一,也是大语言模型革命的基础。通过今天的学习,你已经掌握了理解现代AI系统的核心原理!
下次我们将继续深入探索应用Transformer的实际案例,敬请期待!
推荐阅读
- 《Attention is All You Need》原论文
- 《The Illustrated Transformer》- Jay Alammar
- 《Transformers from Scratch》- Brandon Rohrer
- PyTorch官方Transformer教程
记得动手实践今天学习的代码,只有亲自运行、修改并观察结果,才能真正理解Transformer的魔力!欢迎在评论区分享你的实践心得!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!