时间序列基础【学习记录】
文章目录
- 1. 时间序列中的标签
- 2. 时间序列中的窗口分割器
- 2.1.概述
- 2.2.窗口分割器demo
- 3. 时间序列的数据加载器
- 3.1.概述
- 3.2.时间序列的dataset
- 3.3.Tensor类型
- 3.4.测试完整流程demo
1. 时间序列中的标签
在目标检测领域的数据集中的图像会有一个标签**(标记一个物体是猫还是狗或者是其它的物体),而对于时间序列,在预测的时候,实验者都会选择预测未来多少条数据。假设我们16条数据,选择其中的6条数据为窗口大小来预测未来的2条数据,那么我们的标签就是这2条数据(假设我们的特征数1即你是单元预测,那么我们这16条数据会送入到模型内部进行训练,模型会输出2条数据,输出的2条数据会和我们的标签求一个损失用于反向传播)**
在时间序列预测中,单元预测(Unit Prediction)通常指的是对时间序列中某个特定时间点的未来值进行预测。时间序列是一组按时间顺序排列的数据点,单元预测的目标是根据过去的数据点预测未来的单个数据点的值。
2. 时间序列中的窗口分割器
2.1.概述
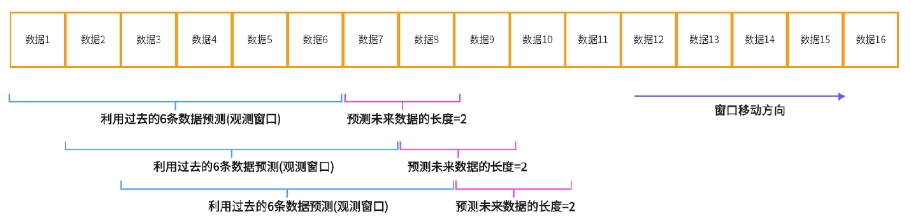
在时间序列中特有的就是窗口分割器,利用一个滑动的窗口(类似于卷积操作)沿着数据的方向进行滑动从而产生用于训练时间序列的数据和标签。如上图所示,我们的蓝色和粉色就是滑动的窗口,一个用于滑动训练数据一个用于滑动标签,最后滑动到数据的结尾。我们可以计算我们能够得到的训练数据的多少,其中数据为16条滑动窗口为6标签为2那么我们最后能够得到的训练加载器中的数据大小就为16 - ( 6 + 2 - 1) = 9,所以最后我们就能得到9个数据。
(样本数 = 数据总数 - (窗口大小 + 预测长度 - 1))
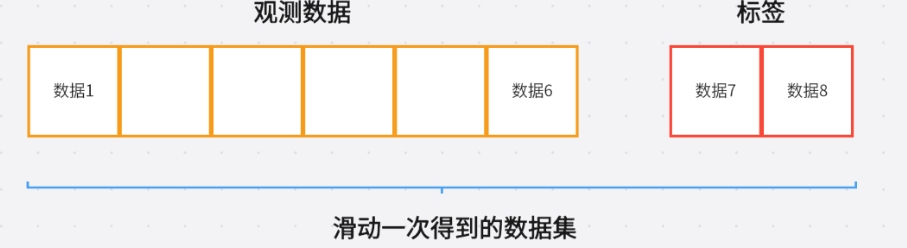
每个数据的内容如下图所示:
2.2.窗口分割器demo
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_10:49
@FileName:1.时间序列中的窗口分割.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np# 分割数据集的函数
def create_data_sequence(input_data, ws, pl):# 存放分割后的数据seq_list = []# 数据集长度L = len(input_data)for i in range(L - ws):train_set = input_data[i:i + ws]if i + ws + pl > L:breaktrain_label = input_data[i + ws:i + ws + pl]seq_list.append((train_set, train_label))return seq_listdef main():# 定义参数total_data_points = 16 # 总数据点数window_size = 6 # 滑动窗口大小predict_length = 2 # 预测长度# 随机生成一个数据集data_set = np.random.rand(total_data_points)print(f"生成的数据集类型是{type(data_set)}, 数据集为{data_set}")# 分割数据集data_set_seq = create_data_sequence(data_set, window_size, predict_length)for i in range(len(data_set_seq)):print(f"分割的第{i}个数据为:{data_set_seq[i]}")if __name__ == '__main__':main()
3. 时间序列的数据加载器
3.1.概述
经过上面的数据分割器处理之后,我们得到了一个样本数为9的数据集,一般用list在外侧内部为tuple元组保存训练数据和标签,这样list就包含九个数据点,每个 数据点内包含一个大的元组,大的元组内包含两个小的元组一个是储存训练集一个储存标签。
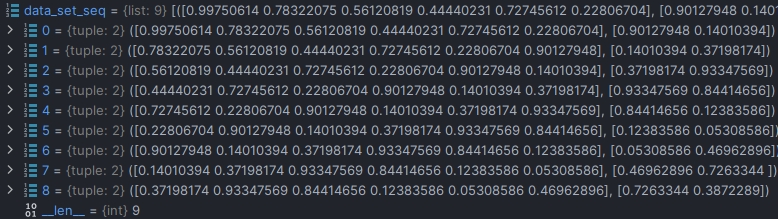
之后我们就要用这个list来生成数据加载器了,我们一般也用下面的加载器进行定义
from torch.utils.data import DataLoader
但是用它进行定义数据加载器之前需要输入的数据格式是dataset的格式,时间序列的dataset和其它领域的不太一样
3.2.时间序列的dataset
一般的数据的dataset需要两个数据的输入但是我们的数据只有一个,所以我们需要自己定义一个定义dataset的类来实现这个功能。
class TimeSeriesDataset(Dataset):def __init__(self, sequence):self.sequence = sequencedef __len__(self):return len(self.sequence)def __getitem__(self, index):sequence, label = self.sequence[index]return torch.Tensor(sequence), torch.Tensor(label)
上面这个就是一个基本的Dataset的定义, 通过这个类的定义我们将数据集输入到这个类里转化为Dataset格式,再将其输入到Dataloader里就形成了一个数据加载器
# 创建数据集train_dataset = TimeSeriesDataset(data_set_seq)# 创建数据加载器DataLoaderbatch_size = 2 # 根据需要调整批量大小# shuffle代表的含义是从我们定义的九条数据里随机的取# drop_last代表丢掉不满足条件的数据train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
**上面的代码就是定义一个数据加载器的方法,**其中我们设置了batch_size=2就是我们的批次大小, shuffle代表的含义是从我们定义的九条数据里随机的取,drop_last代表丢掉不满足条件的数据,类似于我们的数据大部分都是6条但是最后一条数据不足6,此时如果将其输入到模型里就会报错,所以这个参数就是将其丢弃掉。
3.3.Tensor类型
在PyTorch中,Tensor是一种多维数组结构,类似于NumPy的数组(ndarray),但Tensor提供了更强大的功能,特别是在GPU加速计算方面。Tensor是PyTorch中的基本数据结构,用于存储和操作数据。
关键特点:
- 多维数组:
Tensor可以是标量、向量、矩阵或高维数组。例如,0维的Tensor是标量,1维的Tensor是向量,2维的Tensor是矩阵。 - 支持GPU加速:
Tensor可以在GPU上进行计算,利用PyTorch的CUDA支持,大大加速深度学习模型的训练和推理过程。 - 自动微分:
Tensor支持自动微分,这是PyTorch的一个核心功能,使得梯度计算变得非常简单和高效,适用于深度学习中的反向传播算法。
创建Tensor:
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_14:28
@FileName:3.Tensor.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import torch# 创建Tensor# 从列表或数组创建Tensor
x = torch.tensor([1, 2, 3, 4, 5])
print(x)# 创建全零Tensor
zeros = torch.zeros((2, 3))
print(zeros)# 创建全一 Tensor
ones = torch.ones((2, 3))
print(ones)# 创建随机数 Tensor
random_tensor = torch.rand((2, 3))
print(random_tensor)# 创建单位矩阵
eye = torch.eye(3)
print(eye)# 创建指定数据类型的 Tensor
float_tensor = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
int_tensor = torch.tensor([1, 2, 3], dtype=torch.int32)# 检查是否有可用的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 在GPU上创建 Tensor
gpu_tensor = torch.tensor([1, 2, 3], device=device)
print(gpu_tensor) # tensor([1, 2, 3], device='cuda:0'# 或者将现有的 Tensor 移动到 GPU 上
cpu_tensor = torch.tensor([1, 2, 3])
gpu_tensor = cpu_tensor.to(device)
print(gpu_tensor) # tensor([1, 2, 3], device='cuda:0'# 示例
a = torch.tensor([1, 2, 3], dtype=torch.float32)
b = torch.tensor([4, 5, 6], dtype=torch.float32)c = a + b
d = a * bprint("a:", a)
print("b:", b)
print("c(a + b):", c)
print("d(a * b):", d)
3.4.测试完整流程demo
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_14:36
@FileName:4.完整流程demo.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset# 随机数种子
np.random.seed(0)class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return mae"""
数据定义部分
"""
true_data = pd.read_csv(r'E:\07-code\time_series_study\data\test.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列target = 'X' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 40 # 预测未来数据的长度
train_window = 320 # 观测窗口# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + 4) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seq# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)class GRU(nn.Module):def __init__(self, input_dim=1, hidden_dim=32, num_layers=1, output_dim=1, pre_len=4):super(GRU, self).__init__()self.pre_len = pre_lenself.num_layers = num_layersself.hidden_dim = hidden_dim# 替换 LSTM 为 GRUself.gru = nn.GRU(input_dim, hidden_dim, num_layers=num_layers, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.1)def forward(self, x):h0_gru = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)out, _ = self.gru(x, h0_gru)out = self.dropout(out)# 取最后 pre_len 时间步的输出out = out[:, -self.pre_len:, :]out = self.fc(out)out = self.relu(out)return outlstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")else:# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(batch_size):for i in range(pre_len):reals.append(labels[j][i][0].detach().numpy())results.append(pred[j][i][0].detach().numpy())reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]print("模型预测结果:", results)print("预测误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals, label='real', color='blue') # 实际值plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')