SQL语句,索引,视图,存储过程以及触发器
一、初识MySQL
1.数据库
按照数据结构来组织、存储和管理数据的仓库;是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合;
2.OLTP与OLAP
🌰 超市场景类比
1. OLTP(联机事务处理)—— 处理 “当下正在发生的事”
场景:收银员扫码卖一瓶水(实时业务操作)
- 做什么:
- 扫码后,系统立刻做 3 件事:
- 从数据库查这瓶水的价格(查);
- 扣减库存(改:库存从 100 变 99);
- 记录这笔交易(增:写入销售记录表)。
- 特点:
- 实时性:必须马上出结果(不能让顾客等半小时);
- 单次操作小:每次只处理一个订单、少量数据;
- 高频次:每天几万次收银,都靠它支撑;
- 保证正确:比如库存扣减和交易记录必须同时成功,否则 “回滚”(比如扫码后系统崩溃,库存不能平白减少)。
一句话总结:OLTP 是 “干实事”,负责日常业务的实时增删改查,确保每笔操作又快又准(比如收银、下单、转账)。
2. OLAP(联机分析处理)—— 分析 “过去发生的所有事”
场景:月底老板想知道 “哪个品牌的水卖得最好?”(历史数据统计分析)
- 做什么:
- 系统从整个月的销售记录表中,按品牌汇总销量:
SELECT 品牌, SUM(销量) FROM 销售记录 GROUP BY 品牌 ORDER BY SUM(销量) DESC;- 可能还会关联库存表、供应商表,计算毛利、周转率等。
- 特点:
- 非实时:不需要立刻出结果(等几分钟甚至几小时都行);
- 处理大量数据:要分析几十万、几百万条记录;
- 只读不写:只查询统计,不修改原始数据(比如不会边分析边改库存);
- 复杂计算:涉及多表关联、聚合函数(SUM/COUNT)、多层分组(比如按 “品牌 + 地区 + 月份” 分析)。
一句话总结:OLAP 是 “看报表”,负责从历史数据中找规律、辅助决策(比如销售统计、用户画像、趋势预测)。
📝 核心区别对比
维度 OLTP(事务处理) OLAP(分析处理) 用途 处理日常业务(比如收银、下单) 分析历史数据(比如统计、报表、预测) 数据操作 增删改查(每天无数次小操作) 只查不改(复杂查询、汇总、关联) 实时性 必须马上出结果(毫秒级) 可以慢慢算(分钟 / 小时级) 数据量 每次处理少量数据(比如一条订单) 处理大量历史数据(比如全量数据汇总) 用户 普通员工(比如收银员、客服) 管理层、分析师(看结果做决策) 类比 前台干活的 “执行者” 后台看数据的 “决策者”
3.SQL
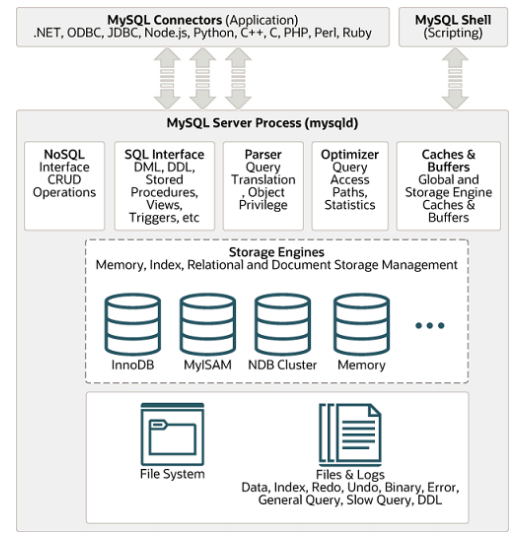
4.MySQL体系结构
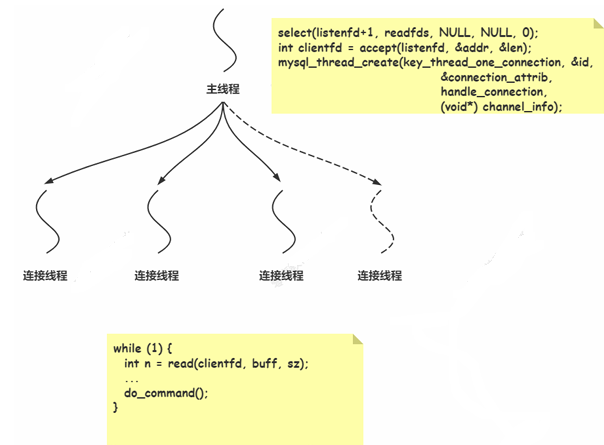
主线程负责接收客户端连接,然后为每个客户端 fd 分配一个连接线程,负责处理该客户端的 sql 命 令处理;
1. 主线程与连接线程的分工
主线程:负责监听端口(如
select()和accept()),接受新连接。每收到一个客户端连接,主线程会创建一个新的独立线程(通过mysql_thread_create)。连接线程:每个新线程负责处理对应客户端的完整生命周期(如读取请求、执行SQL、返回结果)。代码中的
while(1)循环表明线程会持续处理该连接的所有操作,直到连接关闭。2. 连接池的作用
连接池(客户端/中间件):通常由客户端(如Java应用)或中间件(如ProxySQL)维护,用于复用数据库连接。例如,应用启动时预先建立多个连接放入池中,后续请求直接从池中获取连接,避免频繁建立TCP连接和身份验证的开销。
与线程模型的配合:即使客户端使用连接池,MySQL服务端仍会为每个物理连接分配一个独立线程(每连接一线程)。例如,连接池中有10个连接,MySQL服务端会对应10个线程。
MySQL 传统架构采用 “每个连接分配一个线程”(one - thread - per - connection) 的设计,主要基于以下原因:
一、设计简单与历史兼容性
- 逻辑清晰:每个连接独立对应一个线程,无需复杂的线程调度与资源共享管理,减少了同步机制(如锁竞争)的复杂度,便于实现和维护。
- 历史延续:早期 MySQL 设计时,这种模型能直接利用操作系统线程特性,适配当时的硬件与应用场景,后续为保持兼容性和稳定性,未彻底改变基础模型。
二、阻塞 IO 与多线程处理的权衡
- 命令处理并发:虽然每个连接是阻塞 IO,但 MySQL 命令处理本身是多线程并发的。每个线程独立处理一个客户端的请求,避免了单个线程处理多个连接时的复杂状态切换,提升了处理的专注性。
- 编程模型友好:对开发者而言,每个连接对应一个线程的模型更直观,无需处理异步 IO 或事件驱动模型的复杂性。
三、为何不直接使用线程池?
- 适用场景限制:线程池在高并发短查询场景下优势明显,但在长查询场景中,线程池线程可能被长期占用,导致后续请求排队,效率反而降低。而传统模型中长查询仅阻塞单个线程,不影响其他连接。
- 版本特性:线程池并非 MySQL 社区版的原生默认配置,而是在 Percona、MariaDB、Oracle MySQL 企业版等特定版本中提供。传统模型需兼顾不同环境的普适性。
- 资源控制:MySQL 可通过
max_connections配置限制最大连接数,避免无限制创建线程导致资源耗尽。同时,连接池(如应用层连接池)可在客户端进一步控制连接数,减轻数据库压力。
管理服务和工具组件:
系统管理和控制工具,例如备份恢复、MySQL 复制、集群等;
SQL接口:
将 SQL 语句解析生成相应对象;DML,DDL,存储过程,视图,触发器等;
查询解析器:
将 SQL 对象交由解析器验证和解析,并生成语法树;
查询优化器:
SQL 语句执行前使用查询优化器进行优化;
缓冲组件:
是一块内存区域,用来弥补磁盘速度较慢对数据库性能的影响;在数据库进行读取页操作,首先将 从磁盘读到的页存放在缓冲池中,下一次再读相同的页时,首先判断该页是否在缓冲池中,若在缓 冲池命中,直接读取;否则读取磁盘中的页,说明该页被 LRU 淘汰了;缓冲池中 LRU 采用最近最 少使用算法来进行管理; 缓冲池缓存的数据类型有:索引页、数据页、以及与存储引擎缓存相关的数据(比如innoDB 引 擎:undo 页、插入缓冲、自适应 hash 索引、innoDB 相关锁信息、数据字典信息等);
以下是当执行一条select语句,mysql内部的执行流程:
1. 连接器阶段
- 作用:负责与客户端建立连接、验证身份及管理连接。
- 示例:当使用 MySQL 客户端输入用户名、密码连接服务器时,连接器会校验信息。若正确,建立连接并分配专用线程处理后续请求;若错误(如密码错误),则返回
Access denied拒绝连接。2. 查询缓存阶段(MySQL 8.0 已删除,因为命中率过低,仅作历史说明)
- 作用:检查 SQL 语句是否已被缓存。若缓存中存在相同语句(精确匹配),直接返回缓存结果,跳过后续步骤。
- 示例:若此前执行过
select * from user where id = 1;且结果被缓存,此时直接返回缓存数据。但在 MySQL 8.0 及后续版本中,此阶段已移除。3. 分析器阶段
- 词法分析:将 SQL 语句拆解为单词(
select、*、from、user、where、id = 1),识别每个词的含义。- 语法分析:检查语句是否符合 SQL 语法规则。例如,若写成
selec * from user where id = 1;(select拼写错误),语法分析会报错You have an error in your SQL syntax。- 生成语法树:对语句结构进行解析,生成对应的语法树,为后续处理提供基础。
SELECT_STATEMENT ├─ SELECT_CLAUSE(SELECT 子句) │ └─ WILDCARD(通配符 *,表示所有列) ├─ FROM_CLAUSE(FROM 子句) │ └─ TABLE_NAME(表名,值为 "user") └─ WHERE_CLAUSE(WHERE 子句,条件过滤) └─ COMPARISON_EXPR(比较表达式) ├─ OPERATOR(运算符,值为 "=") ├─ LEFT_OPERAND(左操作数) │ └─ COLUMN_NAME(列名,值为 "id") └─ RIGHT_OPERAND(右操作数) └─ LITERAL(字面量,值为 "1")4. 优化器阶段
- 作用:制定最优执行计划。例如,判断是否使用索引、表连接顺序(多表查询时)等,选择成本最小的方案。
- 示例:若
user表的id列有索引,优化器需评估:全表扫描成本高还是通过索引查找成本低。若表数据量大,使用索引(index)查找id = 1的行更高效;若表极小,全表扫描(all)可能更快。优化器最终选择最优方式(如索引查找),生成执行计划。5. 执行器阶段
- 作用:根据执行计划,调用存储引擎接口获取数据并返回给客户端。
- 示例:若存储引擎为 InnoDB,执行器调用 InnoDB 接口,传入
id = 1的条件。InnoDB 通过索引找到对应数据行,返回给执行器,执行器再将数据封装后返回给客户端,完成select操作。
5.数据库设计三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这 种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库, 必须满足一定的范式。
范式一:
确保每列保持原子性;数据库表中的所有字段都是不可分解的原子值; 例如:某表中有一个地址字段,如果经常需要访问地址字段中的城市属性,则需要将该字段拆分为 多个字段,省份、城市、详细地址等;
假设我们设计一个简单的 “员工信息表”,初始设计不符合第一范式,修改后符合,通过对比理解第一范式:
❌ 不符合第一范式的设计
员工编号 员工信息(可分解) 001 张三,30, 上海 002 李四,25, 北京 此时,“员工信息” 字段包含了 姓名、年龄、城市 多个信息,是可分解的(用逗号分隔),违反第一范式(每列需保持原子性)。
✅ 符合第一范式的设计
将 “员工信息” 拆分为 “姓名”“年龄”“城市” 三列,每列都是不可再分的原子值:
员工编号 姓名 年龄 城市 001 张三 30 上海 002 李四 25 北京 这样,每个字段(列)都只存储单一属性,满足第一范式要求。例如,要查询员工所在城市时,可直接通过 “城市” 列获取,无需解析复合字段,确保了数据的规范性和操作的便利性。
范式二:
满足范式一的基础上,确保表中的每列都和主键完全依赖,而不能只与主键的某一部分依赖(组合 索引);
❌ 不符合范式二的设计
表名:订单详情表
订单编号 商品编号 订单日期 商品名称 商品数量 OD001 P001 2024-03-15 笔记本电脑 2 OD001 P002 2024-03-15 鼠标 3 OD002 P003 2024-03-16 键盘 5 问题分析
- 主键:组合主键(订单编号,商品编号),表示一条订单中的一个商品。
- 部分依赖:
- “订单日期” 只依赖于 “订单编号”(同一订单的所有商品共享同一个订单日期,与商品编号无关);
- “商品名称” 只依赖于 “商品编号”(同一商品在不同订单中的名称不变,与订单编号无关);
- 只有 “商品数量” 完全依赖组合主键(不同订单中的同一商品可能有不同数量)。
因此,表中存在非主键列(订单日期、商品名称)只依赖主键的一部分,违反范式二。✅ 符合范式二的设计
通过拆分表,让每个非主键列完全依赖于对应的主键:
1. 订单表(主键:订单编号)
订单编号 订单日期 OD001 2024-03-15 OD002 2024-03-16 2. 商品表(主键:商品编号)
商品编号 商品名称 P001 笔记本电脑 P002 鼠标 P003 键盘 3. 订单商品关联表(主键:订单编号,商品编号)
订单编号 商品编号 商品数量 OD001 P001 2 OD001 P002 3 OD002 P003 5 优化后优点
- 消除部分依赖:
- “订单日期” 完全依赖 “订单编号”(在订单表中);
- “商品名称” 完全依赖 “商品编号”(在商品表中);
- “商品数量” 完全依赖组合主键(在关联表中)。
- 减少数据冗余:同一订单的日期只需存储一次(原表中同一订单的不同商品会重复存储日期);同一商品的名称也只需存储一次(原表中同一商品在不同订单中会重复存储名称)。
- 避免更新异常:修改商品名称时,只需在商品表中修改一次(原表中需修改所有包含该商品的订单记录);修改订单日期时,只需在订单表中修改一次(原表中需修改该订单下所有商品的记录)。
范式三:
满足范式二的基础上,确保每列都和主键直接相关,而不是间接相关;减少数据冗余;
❌ 不符合范式三的设计
表名:员工部门综合表
员工编号 员工姓名 部门编号 部门名称 部门所在地 001 张三 D01 销售部 上海 002 李四 D02 技术部 北京
- 主键:员工编号。
- 间接依赖问题:
- “部门名称”“部门所在地” 依赖于 “部门编号”(
D01 → 销售部、上海),而 “部门编号” 又依赖于 “员工编号”,属于间接依赖主键(员工编号),违反范式三。✅ 符合范式三的设计
通过拆分表,消除间接依赖:
1. 员工表(主键:员工编号)
员工编号 员工姓名 部门编号 001 张三 D01 002 李四 D02
- 员工编号直接关联部门编号,无间接依赖。
2. 部门表(主键:部门编号)
部门编号 部门名称 部门所在地 D01 销售部 上海 D02 技术部 北京
- 部门编号直接关联部门名称和所在地,无间接依赖。
优化后优点
- 消除间接依赖:
- 员工表中,“部门编号” 直接依赖 “员工编号”;
- 部门表中,“部门名称”“部门所在地” 直接依赖 “部门编号”。
- 减少数据冗余:原表中每个员工对应一行部门信息(如部门名称、所在地会随员工重复存储),拆分后部门信息仅在部门表存储一次。
- 避免异常:
- 修改异常:修改部门所在地(如销售部迁至广州),原表需修改所有该部门员工的记录,拆分后只需在部门表改一次。
- 插入异常:若新成立部门(无员工时),原表无法插入(缺少员工编号主键),拆分后部门表可直接插入新部门信息。
- 删除异常:若删除某部门所有员工(原表删除员工记录会导致部门信息丢失),拆分后部门表仍保留部门信息,不受影响。
反范式:
范式可以避免数据冗余,减少数据库的空间,减小维护数据完整性的麻烦;但是采用数据库范式化设计,可能导致数据库业务涉及的表变多,并且造成更多的联表查询,将导致整个系统的性能降低因此基于性能考虑,可能需要进行反范式设计;
6. CRUD
执行过程: 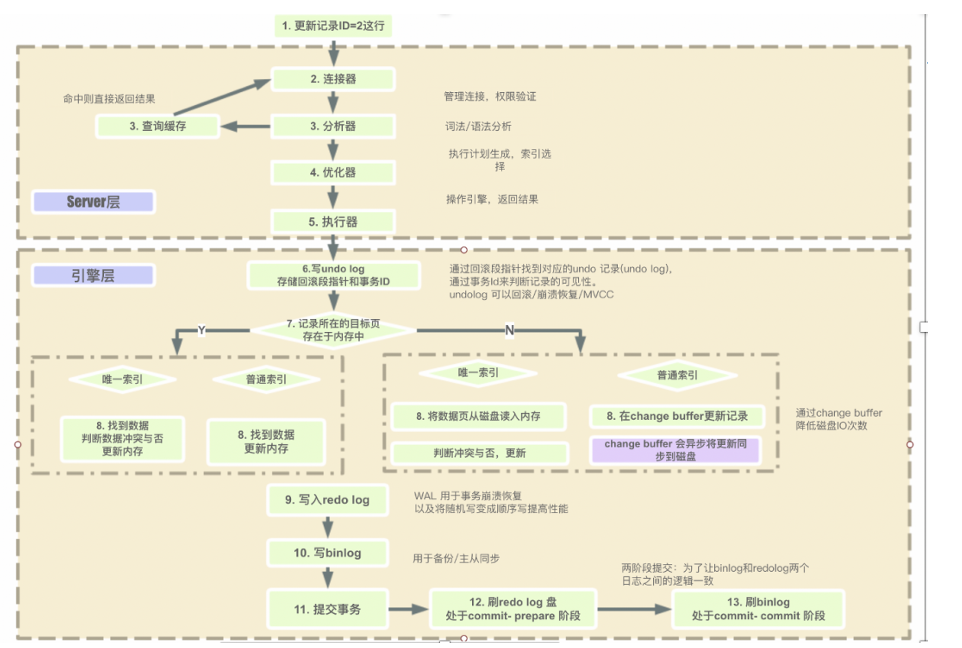
基础操作:
一、数据库操作
1. 创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] `数据库名` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
IF NOT EXISTS:可选参数,若数据库已存在则不重复创建(避免报错)。DEFAULT CHARACTER SET:设置数据库默认字符集(推荐utf8mb4,支持存储 emoji 等复杂字符,原utf8仅支持 3 字节字符)。COLLATE:设置字符集排序规则(可选,默认utf8mb4_general_ci表示不区分大小写)。示例:
CREATE DATABASE IF NOT EXISTS `0voice_db` DEFAULT CHARACTER SET utf8mb4;2. 删除数据库
语法:
DROP DATABASE [IF EXISTS] `数据库名`;
IF EXISTS:可选参数,若数据库不存在则不报错(避免误操作)。示例:
DROP DATABASE IF EXISTS `0voice_db`;3. 选择数据库(切换当前操作库)
语法:
USE `数据库名`;示例:
USE `0voice_db`; -- 后续操作将针对此数据库二、表操作
1. 创建表
语法:
CREATE TABLE [IF NOT EXISTS] `表名` (`字段1` 数据类型 [约束条件] [注释],`字段2` 数据类型 [约束条件] [注释],...主键约束/索引约束 ) ENGINE=存储引擎 DEFAULT CHARSET=字符集 COMMENT='表注释';
- 常用数据类型:
INT UNSIGNED:无符号整数(取值 ≥0)。VARCHAR(长度):可变长度字符串(长度为字符数,如VARCHAR(100)最多存 100 个字符)。DECIMAL(总位数,小数位):精确小数(如DECIMAL(8,2)表示总 8 位,其中 2 位小数,最大 999999.99)。DATETIME:日期时间(格式YYYY-MM-DD HH:MM:SS)。- 常用约束:
NOT NULL:字段必填(不可为空)。AUTO_INCREMENT:自增(仅适用于主键,值自动递增)。PRIMARY KEY:主键(唯一标识一条记录,非空且唯一)。- 存储引擎:常用
InnoDB(支持事务、外键),或MyISAM(性能高但不支持事务)。示例(创建课程表):
CREATE TABLE IF NOT EXISTS `0voice_tbl` (`id` INT UNSIGNED AUTO_INCREMENT COMMENT '课程编号(自增)',`course` VARCHAR(100) NOT NULL COMMENT '课程名称',`teacher` VARCHAR(40) NOT NULL COMMENT '讲师姓名',`price` DECIMAL(8,2) NOT NULL COMMENT '课程价格(元)',`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间(自动填充)',PRIMARY KEY (`id`) -- 主键约束(id 非空且唯一) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='0voice 课程信息表';2. 删除表
语法:
DROP TABLE [IF EXISTS] `表名`;
- 作用:删除表及表中所有数据(无法恢复,谨慎操作!)。
示例:
DROP TABLE IF EXISTS `0voice_tbl`;3. 清空表数据
语法:
-- 方式1:TRUNCATE(快速清空,重置自增列) TRUNCATE TABLE `表名`;-- 方式2:DELETE(逐行删除,保留自增列当前值) DELETE FROM `表名` [WHERE 条件];
- 关键区别:
TRUNCATE:删除表所有数据,自增列(如id)重置为初始值(如从 1 开始);速度快(按页删除)。DELETE:逐行删除数据,自增列保留最后一次插入的值(下次插入继续递增);若不加WHERE则删除全表数据。示例:
TRUNCATE TABLE `0voice_tbl`; -- 清空数据,id 从 1 重新开始 DELETE FROM `0voice_tbl`; -- 清空数据,id 下次插入时继续之前的最大值+1 DELETE FROM `0voice_tbl` WHERE `id` = 3; -- 仅删除 id=3 的记录三、数据操作(增删改查)
1. 插入数据(增)
语法:
INSERT INTO `表名` (`字段1`, `字段2`, ...) VALUES (值1, 值2, ...);
- 字段顺序需与值顺序一一对应;若插入所有字段,可省略字段名(但不推荐,易出错)。
- 字符串值需用单引号
' '包裹(如'Mark'),数字、日期等无需引号。示例:
-- 插入单条记录(指定字段) INSERT INTO `0voice_tbl` (`course`, `teacher`, `price`) VALUES ('C/C++ Linux服务器开发/高级架构师', 'Mark', 7580.00);-- 插入多条记录(MySQL 支持批量插入) INSERT INTO `0voice_tbl` (`course`, `teacher`, `price`) VALUES ('Python全栈开发', 'Alice', 6800.00),('大数据架构师', 'Bob', 8200.00);2. 修改数据(改)
语法:
UPDATE `表名` SET 字段1=新值1, 字段2=新值2 [WHERE 条件];
WHERE子句:可选,若省略则修改全表数据(谨慎!)。- 支持字段值的计算(如累加、拼接)。
示例:
-- 修改 id=2 的记录的讲师为 'Mark' UPDATE `0voice_tbl` SET `teacher` = 'Mark' WHERE `id` = 2;-- 将 id=1 的课程价格增加 100 元(price = 原价格 + 100) UPDATE `0voice_tbl` SET `price` = `price` + 100 WHERE `id` = 1;3. 查询数据(查)
语法:
SELECT 字段1, 字段2,... [AS 别名] FROM `表名` [WHERE 条件] [ORDER BY 排序字段] [LIMIT 数量];
- 常用子句:
WHERE:过滤数据(如WHERE price > 7000)。ORDER BY:排序(如ORDER BY price DESC按价格降序)。LIMIT:限制返回数量(如LIMIT 5仅返回前 5 条)。示例:
-- 查询所有课程的名称和讲师 SELECT `course`, `teacher` FROM `0voice_tbl`;-- 查询价格高于 7000 元的课程,按价格升序排列,取前 2 条 SELECT * FROM `0voice_tbl` WHERE `price` > 7000 ORDER BY `price` ASC LIMIT 2;
高级查询:
一、表结构与关联关系(基础准备)
以下是本次高级查询涉及的 5 张表,表间通过外键建立关联,理解表关系是高级查询的核心:
1. 表结构概览
表名 核心字段 主键 外键关联 classcid(班级 ID)、caption(班级名称)cid无 teachertid(教师 ID)、tname(教师姓名)tid无 coursecid(课程 ID)、cname(课程名称)、teacher_id(教师 ID)cidteacher_id→teacher.tid(课程所属教师)studentsid(学生 ID)、sname(学生姓名)、gender(性别)、class_id(班级 ID)sidclass_id→class.cid(学生所属班级)scoresid(成绩 ID)、student_id(学生 ID)、course_id(课程 ID)、num(分数)sidstudent_id→student.sid(成绩所属学生)
course_id→course.cid(成绩所属课程)二、高级查询分类详解
1. 条件查询(WHERE 子句)
通过
WHERE过滤符合特定条件的记录,支持逻辑运算符(AND/OR)和比较运算符(=,<>,>,<等)。语法:
SELECT 字段列表 FROM 表名 WHERE 条件1 [AND/OR 条件2 ...];示例:
-- 查询性别为男且班级ID为2的学生 SELECT * FROM `student` WHERE `gender` = '男' AND `class_id` = 2;-- 查询分数大于80分或课程ID为3的成绩记录(注意括号优先级) SELECT * FROM `score` WHERE (`num` > 80) OR (`course_id` = 3);关键说明:
- 条件中字符串需用单引号
' '包裹(如'男'),数字直接写(如80)。- 逻辑运算符
AND优先级高于OR,复杂条件建议用括号明确优先级。2. 范围查询(BETWEEN/IN)
查询值在某个区间或集合中的记录。
语法:
示例:
-- 查询班级ID在1到3之间的学生(等价于 class_id >=1 AND class_id <=3) SELECT * FROM `student` WHERE `class_id` BETWEEN 1 AND 3;-- 查询课程ID为1、3、5的成绩记录 SELECT * FROM `score` WHERE `course_id` IN (1, 3, 5);关键说明:
BETWEEN是闭区间(包含边界值),NOT BETWEEN取反。IN可替代多个OR条件(如course_id=1 OR course_id=3),更简洁。3. 判空查询(IS NULL/IS NOT NULL)
判断字段是否为
NULL(未赋值)或空字符串''(显式空值)。语法:
-- 判断字段为NULL SELECT 字段列表 FROM 表名 WHERE 字段 IS NULL;-- 判断字段不为NULL SELECT 字段列表 FROM 表名 WHERE 字段 IS NOT NULL;-- 判断字段为空字符串(需显式比较) SELECT 字段列表 FROM 表名 WHERE 字段 = '';示例:
-- 查询未分配班级的学生(class_id为NULL) SELECT * FROM `student` WHERE `class_id` IS NULL;-- 查询性别不为空字符串的学生(避免无效数据) SELECT * FROM `student` WHERE `gender` <> '';关键说明:
NULL表示 “未知 / 未定义”,与空字符串''不同(''是显式的空值)。- 索引字段用
IS NULL可能导致索引失效(取决于数据库优化器),需谨慎。4. 模糊查询(LIKE 通配符)
通过
LIKE匹配字符串模式,支持%(任意长度字符)和_(单个字符)。语法:
SELECT 字段列表 FROM 表名 WHERE 字段 LIKE '模式';示例:
-- 查询姓名以“谢”开头的教师(如“谢小二”“谢老师”) SELECT * FROM `teacher` WHERE `tname` LIKE '谢%';-- 查询姓名第二个字为“小”的教师(如“王小”“李小”) SELECT * FROM `teacher` WHERE `tname` LIKE '_小%';-- 查询姓名包含“明”的学生(如“小明”“大明”) SELECT * FROM `student` WHERE `sname` LIKE '%明%';关键说明:
%匹配 0 个或多个任意字符(如'谢%'匹配所有以 “谢” 开头的字符串)。_匹配恰好 1 个字符(如'_小%'要求第二个字符是 “小”)。5. 分页查询(LIMIT)
限制返回记录的数量,常用于分页(如网站 “下一页” 功能)。
语法:
SELECT 字段列表 FROM 表名 [WHERE 条件] LIMIT [偏移量,] 数量;示例:
-- 查询前5条学生记录(偏移量0可省略) SELECT * FROM `student` LIMIT 5;-- 查询第2页数据(每页5条,偏移量=(页码-1)*每页数量) -- 第2页:偏移量=(2-1)*5=5,取5条 SELECT * FROM `student` LIMIT 5, 5;关键说明:
- 偏移量从 0 开始计数(第一条记录偏移量为 0)。
- 分页时需配合
ORDER BY排序(否则结果顺序不确定,可能重复)。6. 排序查询(ORDER BY)
按指定字段升序(
ASC)或降序(DESC)排列结果。语法:
示例:
-- 按分数升序排列(分数低→高) SELECT * FROM `score` ORDER BY `num` ASC;-- 先按课程ID降序,再按分数降序(课程ID相同则分数高的在前) SELECT * FROM `score` ORDER BY `course_id` DESC, `num` DESC;关键说明:
- 多字段排序时,优先级从左到右(先按字段 1 排序,字段 1 相同再按字段 2 排序)。
7. 聚合查询(聚合函数)
通过聚合函数统计数据(如总和、平均值、数量等)。
常用聚合函数:
函数 描述 注意事项 SUM(字段)计算某列的总和 忽略 NULL值AVG(字段)计算某列的平均值 忽略 NULL值,结果为浮点型MAX(字段)计算某列的最大值 支持数值、字符串(按字典序) MIN(字段)计算某列的最小值 同上 COUNT(*)统计总记录数(含 NULL)不关心具体字段,统计所有行 COUNT(字段)统计非 NULL的记录数忽略字段为 NULL的行示例:
-- 计算所有学生的分数总和 SELECT SUM(`num`) AS 总分 FROM `score`;-- 计算课程ID为1的平均分(忽略缺考的NULL分数) SELECT AVG(`num`) AS 平均分 FROM `score` WHERE `course_id` = 1;-- 统计学生总数(含未分配班级的学生) SELECT COUNT(*) AS 学生总数 FROM `student`;8. 分组查询(GROUP BY + HAVING)
按字段分组统计,配合聚合函数使用;
HAVING过滤分组结果(区别于WHERE过滤行)。语法:
SELECT 分组字段, 聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 聚合函数条件];示例:
-- 按性别分组,统计每组的学生数量(如男30人,女25人) SELECT `gender`, COUNT(*) AS 人数 FROM `student` GROUP BY `gender`;-- 按课程分组,统计平均分大于80分的课程(HAVING过滤分组) SELECT `course_id`, AVG(`num`) AS 平均分 FROM `score` GROUP BY `course_id` HAVING 平均分 > 80;-- 按班级分组,合并该班级所有学生姓名(GROUP_CONCAT) SELECT `class_id`, GROUP_CONCAT(`sname` SEPARATOR '、') AS 学生名单 FROM `student` GROUP BY `class_id`;关键说明:
GROUP BY后,SELECT中只能包含分组字段或聚合函数(否则报错)。WHERE在分组前过滤行,HAVING在分组后过滤分组(可引用聚合函数)。9. 联表查询(JOIN)
通过
JOIN关联多张表,获取跨表数据(核心是通过外键匹配关联条件)。常用联表类型:
类型 描述 结果特点 INNER JOIN仅保留两表都有匹配的记录 交集 LEFT JOIN保留左表所有记录,右表无匹配时补 NULL左表全部 + 右表匹配 RIGHT JOIN保留右表所有记录,左表无匹配时补 NULL右表全部 + 左表匹配 FULL JOIN保留两表所有记录(MySQL 不支持,用 UNION模拟)左表全部 + 右表全部 语法:
SELECT 表1.字段, 表2.字段 FROM 表1 [INNER/LEFT/RIGHT JOIN 表2 ON 表1.关联字段 = 表2.关联字段] [WHERE 条件];示例:
-- INNER JOIN:查询有教师的课程(课程表与教师表匹配) SELECT `course`.`cname` AS 课程名, `teacher`.`tname` AS 教师名 FROM `course` INNER JOIN `teacher` ON `course`.`teacher_id` = `teacher`.`tid`;-- LEFT JOIN:查询所有课程及其教师(无教师的课程教师名为NULL) SELECT `course`.`cname` AS 课程名, `teacher`.`tname` AS 教师名 FROM `course` LEFT JOIN `teacher` ON `course`.`teacher_id` = `teacher`.`tid`;-- RIGHT JOIN:查询所有教师及其教授的课程(无课程的教师课程名为NULL) SELECT `teacher`.`tname` AS 教师名, `course`.`cname` AS 课程名 FROM `course` RIGHT JOIN `teacher` ON `course`.`teacher_id` = `teacher`.`tid`;关键说明:
- 联表时需明确关联条件(如
course.teacher_id = teacher.tid),避免笛卡尔积(无关联条件时所有行两两组合)。- 字段名冲突时用表别名区分(如
course.cname或c.cname)。10. 子查询(嵌套查询)
在查询内部嵌套另一个查询(子查询),用于复杂条件过滤或数据关联。
常见类型:
类型 描述 示例 单行子查询 子查询返回 1 行 1 列,用 =/>等比较WHERE teacher_id = (SELECT tid FROM teacher WHERE tname='谢小二')多行子查询 子查询返回多行,用 IN/ANY/ALLWHERE class_id IN (SELECT cid FROM class WHERE caption='高三')存在性子查询 检查子查询是否有结果,用 EXISTSWHERE EXISTS (SELECT * FROM score WHERE student_id=student.sid)FROM 子句子查询 子查询作为临时表(派生表) FROM (SELECT * FROM score WHERE num>80) AS high_score示例:
-- 单行子查询:查询“谢小二”教师教授的课程 SELECT * FROM `course` WHERE `teacher_id` = (SELECT `tid` FROM `teacher` WHERE `tname` = '谢小二');-- 多行子查询:查询班级ID在“高三”班级中的学生(IN) SELECT * FROM `student` WHERE `class_id` IN (SELECT `cid` FROM `class` WHERE `caption` LIKE '高三%');-- 存在性子查询:查询至少有1门课分数>90的学生(EXISTS) SELECT * FROM `student` WHERE EXISTS (SELECT * FROM `score` WHERE `student_id` = `student`.`sid` AND `num` > 90);-- FROM子句子查询:查询“数学”课程的高分学生(派生表) SELECT `student`.`sname`, `high_score`.`num` FROM (SELECT * FROM `score` WHERE `course_id` = (SELECT `cid` FROM `course` WHERE `cname`='数学')) AS high_score LEFT JOIN `student` ON `high_score`.`student_id` = `student`.`sid`;
7.正则表达式
| 选项 | 说明 | 示例 | 匹配值示例 |
|---|---|---|---|
| ^ | 文本开始字符 | ^a | 匹配以 a 开头的字符串,如 apple、ant、angry |
| . | 任何单个字符 | c.t | 匹配 c 和 t 之间有一个任意字符的字符串,如 cat(a 为中间字符)、cut(u 为中间字符)、cbt(b 为中间字符) |
| * | 0 个或多个在它前面的字符 | a*n | 匹配 n(a 出现 0 次)、an(a 出现 1 次)、aan(a 出现 2 次)等 |
| + | 前面的字符一次或多次 | b+g | 匹配以 b 开头且后面紧跟至少一个 b 和 g 的字符串,如 bg(一个 b)、bbg(两个 b) |
<字符串> | 包含指定字符串的文本 | ed | 匹配包含 ed 的字符串,如 red、bed、needle |
[字符集合] | 字符集合中的任一个字符 | [pq]ig | 匹配 pig(取 p)或 qig(取 q) |
[^] | 不在括号中的任何字符 | [^abc]ook | 匹配第一个字符不是 a、b、c 的 ook 字符串,如 look(l 不在 abc 中)、mook(m 不在 abc 中) |
字符串{n} | 前面的字符串至少 n 次 | o{2} | 匹配包含至少两个 o 的字符串,如 book(两个 o)、good(两个 o) |
字符串{n,m} | 前面的字符串至少 n 次,至多 m 次 | e{1,3} | 匹配 e 出现 1 到 3 次的字符串,如 he(一个 e)、see(两个 e)、tree(两个 e)、bee(两个 e)、deee(三个 e) |
SELECT * FROM `teacher` WHERE `tname` REGEXP '^谢';二、视图
1.定义
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。其内容由查询定义。 基表:用来创建视图的表叫做基表; 通过视图,可以展现基表的部分数据;视图数据来自定义视图的查询中使用的表,使用视图动态生成;
2.优点
简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影 响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
3.语法
CREATE VIEW <视图名> AS <SELECT语句>
4.案例
-- 创建视图:查询“c++高级”课程比“音视频”课程成绩高的学生学号
CREATE VIEW view_test1 AS
SELECT A.student_id
FROM (-- 子查询A:获取“c++高级”课程(course_id=1)的学生ID和成绩SELECT student_id, num FROM score WHERE course_id = 1) AS A LEFT JOIN (-- 子查询B:获取“音视频”课程(course_id=2)的学生ID和成绩SELECT student_id, num FROM score WHERE course_id = 2) AS B ON A.student_id = B.student_id -- 按学生ID关联两科成绩
WHERE -- 判断条件:A课程(c++高级)成绩 > B课程(音视频)成绩(若B无成绩则视为0)A.num > IF(ISNULL(B.num), 0, B.num);1. 假设
score表数据假设
score表记录了学生选修两门课程的成绩(course_id=1为 “c++ 高级”,course_id=2为 “音视频”):
sid student_id course_id num 1 101 1 85 (学生 101 的 c++ 高级成绩) 2 101 2 78 (学生 101 的音视频成绩) 3 102 1 92 (学生 102 的 c++ 高级成绩) 4 102 2 95 (学生 102 的音视频成绩) 5 103 1 88 (学生 103 的 c++ 高级成绩,未选修音视频) 6 104 2 80 (学生 104 的音视频成绩,未选修 c++ 高级) 7 105 1 75 (学生 105 的 c++ 高级成绩) 8 105 2 75 (学生 105 的音视频成绩) 2. 视图
view_test1的执行逻辑视图通过以下步骤筛选符合条件的学生:
子查询 A:提取所有选修 “c++ 高级”(
course_id=1)的学生 ID 和成绩。
结果:A表包含学生 101(85)、102(92)、103(88)、105(75)。子查询 B:提取所有选修 “音视频”(
course_id=2)的学生 ID 和成绩。
结果:B表包含学生 101(78)、102(95)、104(80)、105(75)。LEFT JOIN 关联:将
A表(c++ 高级)与B表(音视频)按学生 ID 左连接。
结果:
A.student_id A.num B.student_id B.num 101 85 101 78 (两科都选修) 102 92 102 95 (两科都选修) 103 88 NULL NULL (仅选修 c++ 高级) 105 75 105 75 (两科都选修) 条件筛选:
A.num > IF(ISNULL(B.num), 0, B.num)
- 学生 101:
85 > 78→ 符合条件。- 学生 102:
92 > 95→ 不符合(92 不大于 95)。- 学生 103:
B.num为NULL,视为 0 →88 > 0→ 符合条件。- 学生 105:
75 > 75→ 不符合(等于,不满足 “大于”)。3. 视图最终输出结果
视图
view_test1会返回以下学生 ID:
student_id 101 (c++ 高级 85 > 音视频 78) 103 (c++ 高级 88 > 音视频 0,因未选修音视频)
5.作用
- 简化操作:把复杂查询 “打包” 成快捷方式,下次直接用,不用重复写长代码;
- 保护隐私:比如只让普通员工看到姓名,看不到工资,像给数据加了层 “滤镜”;
- 灵活适配:底层表格变了(比如新增列),视图能悄悄调整 “显示界面”,不让外面的程序察觉;
- 整合数据:把多张表的信息 “拼” 成一张表,比如同时看到 “产品名” 和 “销量”,不用自己手动连表;
- 按需展示:不同人打开同一个视图,能看到不同的内容(比如给财务看金额,给客服看客户电话),各取所需不混乱。
三、流程控制
1. IF:条件判断
作用:根据条件执行不同分支。
语法:IF 条件1 THEN 操作1; ELSEIF 条件2 THEN 操作2; ELSE 操作3; END IF;示例(判断成绩等级):
-- 创建存储过程:输入分数,输出等级(A/B/C/D) DELIMITER $$ CREATE PROCEDURE GetGrade(IN score INT) BEGIN IF score >= 90 THEN SELECT 'A'; ELSEIF score >= 80 THEN SELECT 'B'; ELSEIF score >= 60 THEN SELECT 'C'; ELSE SELECT 'D'; END IF; END$$ DELIMITER ; -- 调用:输入85分 CALL GetGrade(85); -- 输出 B2. CASE:多条件分支
作用:类似
IF-ELSEIF,但更清晰,支持两种形式(简单 CASE、搜索 CASE)。
语法-- 简单 CASE(等值判断) CASE 表达式 WHEN 值1 THEN 操作1; WHEN 值2 THEN 操作2; ELSE 操作3; END CASE; -- 搜索 CASE(任意条件) CASE WHEN 条件1 THEN 操作1; WHEN 条件2 THEN 操作2; ELSE 操作3; END CASE;示例(根据部门 ID 返回部门名):
-- 创建存储过程:输入部门ID,输出部门名称 DELIMITER $$ CREATE PROCEDURE GetDeptName(IN dept_id INT) BEGIN CASE dept_id WHEN 1 THEN SELECT '技术部'; WHEN 2 THEN SELECT '销售部'; WHEN 3 THEN SELECT '财务部'; ELSE SELECT '未知部门'; END CASE; END$$ DELIMITER ; -- 调用:输入部门ID=2 CALL GetDeptName(2); -- 输出 销售部3. WHILE:条件循环(先判断后执行)
作用:当条件为真时,重复执行循环体(类似
while)。
语法WHILE 条件 DO 循环体; END WHILE;示例(计算 1 到 N 的和):
-- 创建存储过程:输入N,输出1+2+...+N的和 DELIMITER $$ CREATE PROCEDURE SumUpToN(IN N INT, OUT total INT) BEGIN DECLARE i INT DEFAULT 1; -- 初始化计数器 SET total = 0; WHILE i <= N DO SET total = total + i; -- 累加i到总和 SET i = i + 1; -- 计数器+1 END WHILE; END$$ DELIMITER ; -- 调用:计算1到5的和 CALL SumUpToN(5, @sum); SELECT @sum; -- 输出 15(1+2+3+4+5)4. LEAVE:退出循环(类似 break)
作用:在循环中提前终止整个循环。
语法:LEAVE 循环标签;(需配合循环标签使用)示例(累加到 100 时停止)
-- 创建存储过程:累加直到总和≥100 DELIMITER $$ CREATE PROCEDURE StopAt100(OUT total INT) BEGIN DECLARE i INT DEFAULT 1; SET total = 0; my_loop: WHILE TRUE DO -- 标签my_loop SET total = total + i; IF total >= 100 THEN LEAVE my_loop; -- 退出循环 END IF; SET i = i + 1; END WHILE; END$$ DELIMITER ; -- 调用 CALL StopAt100(@total); SELECT @total; -- 输出 105(1+2+...+14=105)5. ITERATE:跳过当前循环(类似 continue)
作用:跳过当前循环体剩余代码,直接进入下一次循环。
语法:ITERATE 循环标签;(需配合循环标签使用)示例(累加奇数)
-- 创建存储过程:累加1到10的奇数和 DELIMITER $$ CREATE PROCEDURE SumOddNumbers(OUT total INT) BEGIN DECLARE i INT DEFAULT 0; SET total = 0; my_loop: WHILE i < 10 DO SET i = i + 1; IF i % 2 = 0 THEN -- 偶数 ITERATE my_loop; -- 跳过当前循环,进入下一次 END IF; SET total = total + i; -- 只累加奇数 END WHILE; END$$ DELIMITER ; -- 调用 CALL SumOddNumbers(@total); SELECT @total; -- 输出 25(1+3+5+7+9)6. LOOP:无限循环(需手动退出)
作用:创建一个无限循环,需配合
LEAVE退出。
语法[标签:] LOOP 循环体; IF 条件 THEN LEAVE 标签; END IF; -- 必须手动退出 END LOOP;示例(循环 5 次后退出)
-- 创建存储过程:输出1到5 DELIMITER $$ CREATE PROCEDURE Loop5Times() BEGIN DECLARE i INT DEFAULT 1; my_loop: LOOP SELECT i; -- 输出当前i SET i = i + 1; IF i > 5 THEN LEAVE my_loop; END IF; -- 第5次后退出 END LOOP; END$$ DELIMITER ; -- 调用 CALL Loop5Times(); -- 依次输出1,2,3,4,57. REPEAT:条件循环(先执行后判断)
作用:先执行一次循环体,再判断条件是否继续(类似
do...while)。
语法REPEAT 循环体; UNTIL 条件 -- 条件为真时终止循环 END REPEAT;示例(直到总和≥50 时停止):
-- 创建存储过程:累加直到总和≥50 DELIMITER $$ CREATE PROCEDURE RepeatUntil50(OUT total INT) BEGIN DECLARE i INT DEFAULT 1; SET total = 0; REPEAT SET total = total + i; SET i = i + 1; UNTIL total >= 50 -- 总和≥50时终止 END REPEAT; END$$ DELIMITER ; -- 调用 CALL RepeatUntil50(@total); SELECT @total; -- 输出 55(1+2+...+10=55)总结
语句 核心作用 典型场景 IF基础条件判断 成绩等级、状态分类 CASE多条件分支(更清晰) 枚举值映射(如部门 ID 转名称) WHILE先判断条件,再执行循环 已知循环次数或条件 LEAVE提前终止整个循环 满足特定条件时退出(如累加≥100) ITERATE跳过当前循环,继续下一次 过滤不需要的循环迭代(如跳过偶数) LOOP无限循环(需手动退出) 固定次数循环(如输出 1-5) REPEAT先执行循环体,再判断条件 至少执行一次的场景(如累加直到≥50)
四、触发器
一、触发器(Trigger)的核心概念
触发器是 MySQL 中一种自动执行的数据库对象,它绑定在表上,当表发生
INSERT(插入)、UPDATE(更新)或DELETE(删除)操作时,会自动触发预先定义的 SQL 逻辑。关键特点:
- 事件驱动:仅在特定操作(
INSERT/UPDATE/DELETE)发生时触发。- 行级触发:对每一行受影响的数据执行一次触发逻辑(如插入 5 行数据,触发器会执行 5 次)。
- 前后关联:支持
BEFORE(操作前触发)和AFTER(操作后触发)两种时机。二、触发器的类型与语法
触发器的类型由两个维度组合:
- 触发事件:
INSERT(插入)、UPDATE(更新)、DELETE(删除)。- 触发时机:
BEFORE(操作前)、AFTER(操作后)。完整语法:
DELIMITER $$ -- 修改语句结束符(避免分号冲突) CREATE TRIGGER 触发器名称 触发时机 触发事件 ON 表名 FOR EACH ROW -- 行级触发 BEGIN -- 触发逻辑(可包含多条SQL语句) END$$ DELIMITER ; -- 恢复默认结束符关键变量:
OLD:表示触发事件前的旧行数据(仅UPDATE/DELETE可用)。NEW:表示触发事件后的新行数据(仅INSERT/UPDATE可用)。三、实战案例:触发器的典型应用场景
案例 1:数据自动校验(BEFORE INSERT)
需求:插入学生成绩时,确保分数在 0-100 之间,否则自动修正为 0 或 100。
步骤 1:创建成绩表
CREATE TABLE score (id INT PRIMARY KEY AUTO_INCREMENT,student_id INT,course VARCHAR(20),score DECIMAL(5,2) -- 分数(如90.5) );步骤 2:创建触发器(BEFORE INSERT)
DELIMITER $$ CREATE TRIGGER before_score_insert BEFORE INSERT ON score FOR EACH ROW BEGIN -- 如果新分数 >100,修正为100 IF NEW.score > 100 THEN SET NEW.score = 100; -- 如果新分数 <0,修正为0 ELSEIF NEW.score < 0 THEN SET NEW.score = 0; END IF; END$$ DELIMITER ;测试:插入非法分数
-- 插入分数105(触发修正为100) INSERT INTO score (student_id, course, score) VALUES (101, '数学', 105); -- 插入分数-5(触发修正为0) INSERT INTO score (student_id, course, score) VALUES (102, '数学', -5);结果验证:
id student_id course score 1 101 数学 100.00 2 102 数学 0.00 案例 2:自动记录操作日志(AFTER UPDATE)
需求:当修改学生分数时,自动记录旧分数和新分数到日志表,用于审计。
步骤 1:创建日志表
CREATE TABLE score_log (log_id INT PRIMARY KEY AUTO_INCREMENT,student_id INT,course VARCHAR(20),old_score DECIMAL(5,2), -- 旧分数new_score DECIMAL(5,2), -- 新分数update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 修改时间 );步骤 2:创建触发器(AFTER UPDATE)
DELIMITER $$ CREATE TRIGGER after_score_update AFTER UPDATE ON score FOR EACH ROW BEGIN -- 插入日志:记录旧分数(OLD.score)和新分数(NEW.score) INSERT INTO score_log (student_id, course, old_score, new_score) VALUES (OLD.student_id, OLD.course, OLD.score, NEW.score); END$$ DELIMITER ;测试:修改分数
-- 将学生101的数学成绩从100改为95 UPDATE score SET score = 95 WHERE student_id = 101 AND course = '数学';结果验证(日志表):
log_id student_id course old_score new_score update_time 1 101 数学 100.00 95.00 2024-07-20 14:30:00 案例 3:级联删除(AFTER DELETE)
需求:删除学生表中的学生时,自动删除其对应的成绩记录(级联删除)。
步骤 1:创建学生表和成绩表
CREATE TABLE student (id INT PRIMARY KEY,name VARCHAR(20) );CREATE TABLE score (id INT PRIMARY KEY AUTO_INCREMENT,student_id INT,course VARCHAR(20),score DECIMAL(5,2),FOREIGN KEY (student_id) REFERENCES student(id) -- 外键关联 );步骤 2:创建触发器(AFTER DELETE)
DELIMITER $$ CREATE TRIGGER after_student_delete AFTER DELETE ON student FOR EACH ROW BEGIN -- 删除该学生的所有成绩(OLD.id是被删除学生的ID) DELETE FROM score WHERE student_id = OLD.id; END$$ DELIMITER ;测试:删除学生
-- 删除学生ID=101 DELETE FROM student WHERE id = 101;结果验证:
- 学生表中
id=101的记录被删除。- 成绩表中所有
student_id=101的记录也被自动删除(触发器触发)。四、触发器的注意事项与限制
- 性能影响:触发器会在每次操作时自动执行,频繁触发可能影响数据库性能(尤其是批量操作时)。
- 递归触发:触发器内部若对本表进行
INSERT/UPDATE/DELETE,可能导致递归触发(如A触发器触发B触发器,再触发A触发器),需谨慎设计。- 作用域限制:触发器只能绑定到单张表,无法直接跨多张表触发(需通过其他表的触发器间接实现)。
五、存储过程
一、存储过程详解:概念、语法与核心作用
1. 存储过程的定义
** 存储过程(Stored Procedure)** 是数据库中一组 预编译、可重复调用的 SQL 语句集合,它可以包含参数、变量、流程控制(如
IF、WHILE),甚至调用其他存储过程或触发器。本质上是 “数据库中的函数”,用于封装复杂业务逻辑,提升开发效率和数据库性能。2. 存储过程的核心语法
基本结构:
DELIMITER $$ -- 修改语句结束符(避免分号冲突) CREATE PROCEDURE 存储过程名称([参数列表]) BEGIN -- 声明变量(可选) DECLARE 变量名 数据类型 [DEFAULT 默认值]; -- 业务逻辑(SQL语句、流程控制等) ... END$$ DELIMITER ; -- 恢复默认结束符参数类型(3 种):
参数类型 符号 作用 IN输入参数 向存储过程传递值(默认类型,可省略) OUT输出参数 存储过程向调用者返回值 INOUT输入输出参数 既可以传入值,也可以被存储过程修改后返回 3. 存储过程的典型场景
- 封装复杂查询:将多表连接、统计等复杂操作打包,简化调用。
- 批量数据处理:如批量插入测试数据、更新符合条件的记录。
- 业务逻辑集中管理:将核心业务规则(如奖金计算、积分规则)放在数据库中,避免重复开发。
二、存储过程的具体案例
案例 1:计算两个数的和(基础输入输出)
需求:输入两个整数,返回它们的和。
步骤 1:创建存储过程
DELIMITER $$ CREATE PROCEDURE AddTwoNumbers(IN num1 INT, -- 输入参数1IN num2 INT, -- 输入参数2OUT sum INT -- 输出参数(和) ) BEGIN SET sum = num1 + num2; -- 计算和并赋值给输出参数 END$$ DELIMITER ;调用与结果:
CALL AddTwoNumbers(5, 3, @sum); -- 传入5和3,结果存入@sum SELECT @sum; -- 输出8案例 2:根据成绩返回等级(流程控制)
需求:输入学生分数,返回等级(A/B/C/D)。
步骤 1:创建存储过程
DELIMITER $$ CREATE PROCEDURE GetGrade(IN score INT, -- 输入分数OUT grade VARCHAR(1) -- 输出等级 ) BEGIN IF score >= 90 THEN SET grade = 'A'; ELSEIF score >= 80 THEN SET grade = 'B'; ELSEIF score >= 60 THEN SET grade = 'C'; ELSE SET grade = 'D'; END IF; END$$ DELIMITER ;调用与结果:
CALL GetGrade(85, @grade); -- 输入85分 SELECT @grade; -- 输出B案例 3:批量插入测试数据(循环与条件)
需求:向
student表批量插入 10 条测试数据(学号从 1001 到 1010,姓名为 “学生 1” 到 “学生 10”)。步骤 1:创建学生表
CREATE TABLE student (id INT PRIMARY KEY,name VARCHAR(20) );步骤 2:创建存储过程(含循环)
DELIMITER $$ CREATE PROCEDURE InsertTestStudents() BEGIN DECLARE i INT DEFAULT 1001; -- 初始化学号 WHILE i <= 1010 DO INSERT INTO student (id, name) VALUES (i, CONCAT('学生', i-1000)); SET i = i + 1; -- 学号自增 END WHILE; END$$ DELIMITER ;调用与结果:
CALL InsertTestStudents(); -- 执行存储过程 SELECT * FROM student; -- 查看插入的10条数据三、存储过程与触发器的对比
1. 核心差异
特性 存储过程 触发器 触发方式 主动调用(需显式执行 CALL)事件驱动(自动触发,无需调用) 作用 封装业务逻辑,简化复杂操作 自动响应数据变更(如校验、日志) 执行时机 由用户 / 应用程序控制 绑定到 INSERT/UPDATE/DELETE参数 支持 IN/OUT/INOUT参数无参数(通过 OLD/NEW访问数据)灵活性 可包含复杂逻辑(循环、条件判断) 逻辑相对简单(通常关联单表操作) 2. 典型协作场景
存储过程和触发器可配合使用,例如:
- 存储过程负责主动执行批量操作(如修改 100 条成绩);
- 触发器负责自动记录每次修改的日志(如每次成绩修改触发日志插入)。
3. 如何选择?
- 用存储过程:需要显式调用、封装复杂逻辑(如计算奖金、生成报表)。
- 用触发器:需要自动响应数据变更(如数据校验、级联操作、审计日志)。
六、权限管理
1. 创建用户
使用
CREATE USER语句创建用户,语法为:CREATE USER username@host IDENTIFIED BY password;
host:指定用户可登录的主机。本地用户可用localhost,允许从任意远程主机登录则使用通配符%。2. 授权
通过
GRANT语句授予用户权限,语法为:GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
privileges:用户的操作权限,如SELECT(查询)、INSERT(插入)、UPDATE(更新)等,ALL表示所有权限。databasename.tablename:权限作用的数据库和表。*.*表示任意数据库及任意表。WITH GRANT OPTION:允许该用户将已拥有的权限授予他人。若不想赋予此权限,则不添加该选项。3. 对视图授权
针对视图授权的语法:
GRANT select, SHOW VIEW ON `databasename`.`tablename` TO 'username'@'host';用于授予用户对特定视图的查看等权限。
4. 刷新权限
修改权限后需刷新权限,使配置生效,使用命令:
FLUSH PRIVILEGES;5. 远程连接 - 修改配置
- 修改配置文件:编辑
mysqlld.cnf(如vi /etc/mysql/mysql.conf.d/mysqlld.cnf),调整bind - address(默认127.0.0.1表示仅本地访问)。- 修改用户表:
SELECT * FROM mysql.user; -- 查看用户表 UPDATE user SET host = '%' WHERE user = 'root'; -- 将 root 用户的 host 改为 %,允许任意远程连接修改后需重启 MySQL 服务使配置生效。
0voice · GitHub