MySQL——性能调优
explain有什么用?
explain是查看sql的执行计划,主要用来分析sql语句的执行过程,比如有没有走索引,有没有外部排序,有没有索引覆盖。
使用force index()命令可以强制选择指定索引
EXPLAIN SELECT productName,buyPrice
FROMproducts
FORCE INDEX (idx_buyprice)
WHEREbuyPrice BETWEEN 10 AND 80
ORDER BY buyPrice; 使用主键索引查询单个记录

使用主键索引查询范围记录

未使用索引:
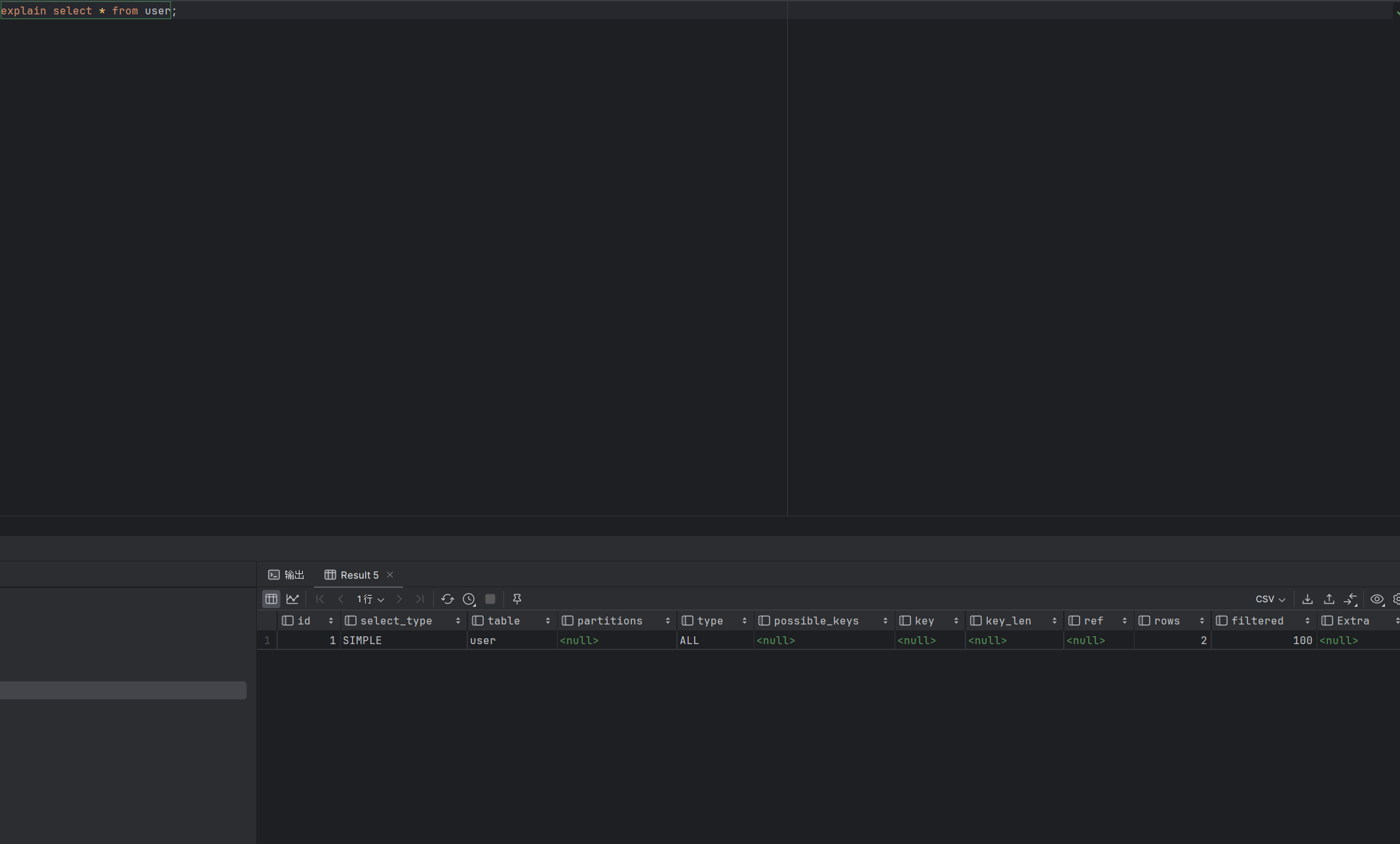
执行计划的参数有:
- possible_keys:表示可能用到的索引。
- key:表示实际用到的索引,若为NULL则说明没有使用索引。
- key_len:表示索引长度。
- rows:表示扫描的数据行数。
- type:表示数据扫描类型。
type字段指定扫描方式,常见扫描方式的执行效率从低到高为:
- All(全表扫描):开销最大,全表扫描。
- index(全索引扫描):与all差不多,对索引表进行全扫描,好处是不用再对数据进行排序,但开销依然很大。
- range(索引范围扫描):一般where子句种存在<、>、in、between等关键词,只检索给定范围的行,属于范围查找。
- ref(非唯一索引扫描):采用了非唯一索引,或者是唯一索引的非唯一行前缀,返回数据可能是多条。使用了索引,但索引列的值并不唯一,有重复。查找到第一条数据后仍然需要小范围查询重复的结果。
- eq_ref(唯一索引扫描):使用主键或唯一索引,通常在多表联查(至少一个关联字段是主键或唯一索引)中使用。
- const(唯一索引扫描):表示使用主键或唯一索引与常量值进行比较。const与eq_ref相似,但const是与常量比较,查询效率会更高。
extra的参考指标:
- Using index:所需数据只需在索引中即可全部获得,不需要回表查询数据,也就是覆盖索引。
- Using temporary:使用了临时表保存中间结果,MySQL在对查询结果排序时使用了临时表,常见于order by和group by。
- Using filesort:查询语句包含gruop by操作,而且无法利用索引完成排序操作,不得不选择相应的排序算法进行排序,甚至可能通过文件排序,效率很低。
如果某张表查询速度很慢,有哪些解决方案?
开启慢查询日志,筛选耗时较长的sql语句
-- 临时开启(重启后失效)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2; -- 设置慢查询阈值(秒)
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';-- 永久生效需修改配置文件(my.cnf或my.ini):
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2- 分析查询语句:使用日志或explain分析sql执行计划,找出慢查询的原因,例如是否使用了全表扫描,是否索引没有被正确使用等情况。
- 创建或优化索引:根据查询条件创建合适的索引,特别是用于where子句的字段、order by排序字段,join连表查询的字段、group by的字段。如果查询涉及的字段较多,考虑建立联合索引,并遵循最左匹配原则。
- 避免索引失效:不要使用左模糊匹配、函数计算、表达式计算等等。
- 查询优化:尽量避免使用select *,只查询需要的列;使用覆盖索引,减少回表查询。联表查询时尽量使用小表驱动大表,且关联字段最好有索引,否则可能全表扫描。或通过冗余字段的设计避免联表查询。
- 优化数据库表:如果单表数据超过了千万级,考虑将大表拆分为多个小表,减少磁盘IO次数。
- 使用缓存:引入缓存层,存储热点数据和频繁查询的结果,但是要考虑缓存一致性的问题,对于写请求应该选择先更新db,再更新缓存的策略。