【Mysql基础】二、函数和约束

📚博客主页:代码探秘者-CSDN博客
🌈:最难不过坚持
✨专栏
| 🌈语言篇 | C语言\ C++ | Javase基础 | ||
|---|---|---|---|---|
| 🌈数据结构专栏 | 数据结构 | |||
| 🌈算法专栏 | 必备算法 | |||
| 🌈数据库专栏 | Mysql | Redis | ||
| 🌈必备篇 |

其他更新ing…
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏作者水平有限,欢迎各位大佬指点,相互学习进步!
一、函数
字符串函数
常用函数:
| 函数 | 功能 |
|---|---|
| CONCAT(s1, s2, …, sn) | 字符串拼接,将s1, s2, …, sn拼接成一个字符串 |
| LOWER(str) | 将字符串全部转为小写 |
| UPPER(str) | 将字符串全部转为大写 |
| LPAD(str, n, pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str, n, pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str, start, len) | 返回从字符串str从start位置起的len个长度的字符串 |
-- 拼接 CONCAT(s1, s2, …, sn)
select concat('Hello','MySQL');-- 小写 LOWER(str)
select lower('I AM SPIDERMAN');-- 大写 UPPER(str)
select upper('i am spiderman');-- 左填充 LPAD(str, n, pad)
select lpad('hellomysql',20,0);-- 右填充 RPAD(str, n, pad)
select rpad('hellomysql',20,0);-- 去除空格 TRIM(str)
select trim(' do you wanna build a snowman ');-- 切片(起始索引为1) SUBSTRING(str, start, len)
select substr('howareuiamfinethanku',5,5);-- 根据业务需求,企业员工的工号统一改为5位数,不足五位的前面用0补齐
UPDATE emp SET workno = lpad(workno,5,'0');
数值函数
常见函数:
| 函数 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x, y) | 返回x/y的模 |
| RAND() | 返回0~1内的随机数 |
| ROUND(x, y) | 求参数x的四舍五入值,保留y位小数 |
-- 数值函数-- CEIL(x) answer=2
select ceil(1.8);-- FLOOR(x) answer=1
select floor(1.8);-- MOD(x, y) (取余数)
select mod(4,3);-- RAND()
select rand();-- ROUND(x, y) 求参数x的四舍五入值,保留y位小数 answer=2.90
select round(2.899,2);-- 生成随机6位数
select rpad(round(rand()*1000000,0),6,0);
日期函数
常用函数:
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1, date2) | 返回起始时间date1和结束时间date2之间的天数 |
-- CURDATE()
select curdate();-- CURTIME()
select curtime();-- NOW()
select now();-- YEAR(date)-- MONTH(date)-- DAY(date)
select year(now());
select month(now());
select day(now());-- DATE_ADD(date, INTERVAL expr type)
select date_add(now(),interval 10 day);-- DATEDIFF(date1, date2)---date1-date2
select datediff(now(),'2000-04-01');-- 查询所有员工的入职天数,并根据入职天数倒序排序
select name,datediff(now(),entrydate) from emp order by datediff(now(),entrydate) DESC;
select name,datediff(now(),entrydate) as entrydays from emp order by entrydays DESC;
流程函数
常用函数:
| 函数 | 功能 |
|---|---|
| IF(value, t, f) | 如果value为true,则返回t,否则返回f |
| IFNULL(value1, value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果val1为true,返回res1,… 否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果expr的值等于val1,返回res1,… 否则返回default默认值 |
-- IF(value, t, f)--如果value为true,则返回t,否则返回f
select if(false,'ok','error');-- IFNULL(value1, value2)--如果value1不为空,返回value1,否则返回value2
select ifnull(null,'error');
select ifnull('ok','error');-- CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END
-- 如果expr的值等于val1,返回res1,… 否则返回default默认值
-- 需求:查询emp表的员工姓名和工作地址(上海/北京--->一线城市,其他--->二线城市)
selectname,(case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end) as '工作城市'
from emp;-- CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END
-- 如果val1为true,返回res1,… 否则返回default默认值
-- 统计班级成绩{ >=85优秀, >=60及格, else不及格 }
create table score(id int comment 'ID',name varchar(20) comment '姓名',math int comment '数学',english int comment '英文',chinese int comment '语文'
) comment '学员成绩表';insert into score(id, name, math, english, chinese)
values (1, 'Tom',67,88,95),(2,'Rose',23,66,90),(3,'Jack',56,98,76);selectid,name,(case when math >=85 then '优秀' when math >=60 then '及格' else '不及格'end) as math,(case when english >=85 then '优秀' when math >=60 then '及格' else '不及格'end) as english,(case when chinese >=85 then '优秀' when math >=60 then '及格' else '不及格'end) as chinese
from score;
条件函数

处理空值 coalesce
COALESCE(value1, value2, ..., valueN)
- 参数:可以是任意数量的表达式,这些表达式可以是列名、常量或子查询结果。
- 返回值:返回参数列表中的第一个非空值。如果所有参数都是 NULL,则返回 NULL。
用途
| emp_id | name | sal | comm |
|---|---|---|---|
| 1 | Alice | 5000 | NULL |
| 2 | Bob | 6000 | 1000 |
| 3 | Carol | NULL | 2000 |
| 4 | Dave | 7000 | NULL |
提供默认值:当某列可能包含 NULL 值时,可以用 COALESCE 提供一个默认值。
SELECT name, COALESCE(sal, 0) AS salary FROM employees;
- 如果 sal 列的值是 NULL,则用 0 作为默认值
| name | salary |
|---|---|
| Alice | 5000 |
| Bob | 6000 |
| Carol | 0 |
| Dave | 7000 |
合并列:从多个列中选择第一个非空值。
SELECT name, COALESCE(sal, comm, 0) AS total_compensation FROM employees;
- 如果 sal 是 NULL,则检查 comm;如果 comm 也是 NULL,则用 0 作为默认值。
| name | total_compensation |
|---|---|
| Alice | 5000 |
| Bob | 6000 |
| Carol | 2000 |
| Dave | 7000 |
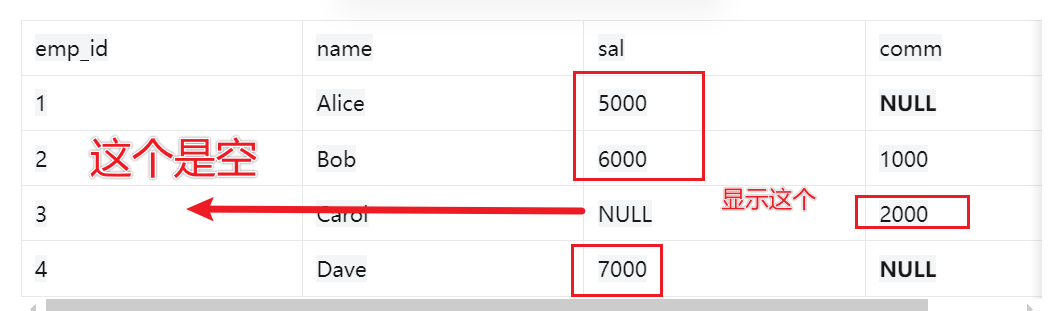
处理空值:在计算或显示结果时避免 NULL 值。
SELECT name, COALESCE(sal, 'N/A') AS salary FROM employees;
- 如果 sal 列的值是 NULL,则用字符串 ‘N/A’ 作为默认值。
| name | salary |
|---|---|
| Alice | 5000 |
| Bob | 6000 |
| Carol | N/A |
| Dave | 7000 |
NULLIF
- 比较两个表达式,如果它们相等,则返回 NULL;如果它们不相等,则返回第一个表达式的值。
NULLIF(expression1, expression2)
- 避免除以零:在计算中,如果分母可能为零,可以使用 NULLIF 来避免错误。
- 处理重复值:在比较两个值时,如果它们相等,可以返回 NULL。
- 数据清洗:在数据清洗过程中,处理某些特定的重复或异常值
SELECT COALESCE(NULLIF(sal, 0), 1) AS adjusted_sal FROM employees;
IFNULL
- 返回其参数列表中的第一个非空值。如果所有参数都是 NULL,则返回 NULL。
IFNULL(expression1, expression2)
SELECT name, IFNULL(sal, 0) AS salary FROM employees;
解释:如果 sal 列的值是 NULL,则用 0 作为默认值。
小总结
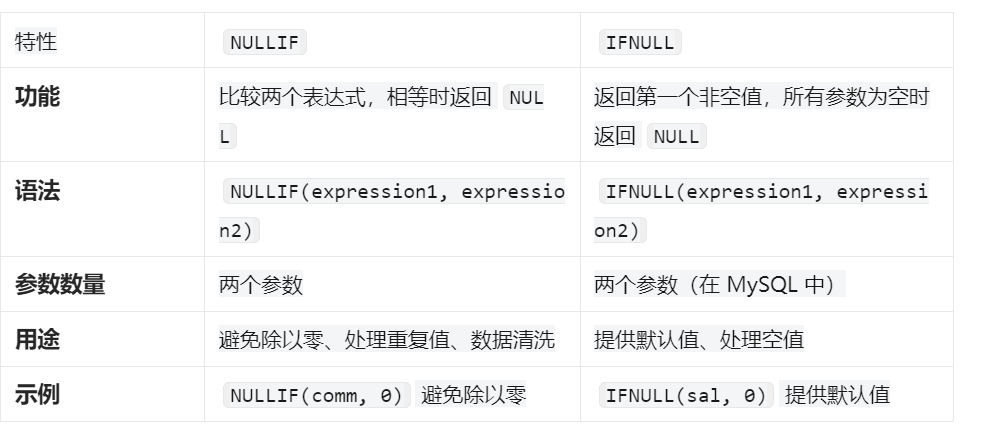
注意:
在某些数据库(如 MySQL)中,
IFNULL和NULL 通常接受两个参数。
在标准 SQL 中,COALESCE 是更通用的函数,可以接受多个参数。
CASE
- 用于根据多个条件返回不同的值。它类似于其他编程语言中的 if-else 语句。
CASEWHEN condition1 THEN result1WHEN condition2 THEN result2...ELSE default_result
END
SELECT name, sal, comm,CASEWHEN sal > 6000 THEN 'High'WHEN sal BETWEEN 5000 AND 6000 THEN 'Medium'ELSE 'Low'END AS salary_level
FROM employees;
| name | sal | comm | salary_level |
|---|---|---|---|
| Alice | 5000 | NULL | Medium |
| Bob | 6000 | 1000 | Medium |
| Carol | NULL | 2000 | Low |
| Dave | 7000 | NULL | High |
IF
- 根据一个条件返回两个值中的一个。
- 类似JAVA和c语言的三目表达式
IF(condition, true_value, false_value)
案例:
SELECT name, sal, IF(sal > 5000, 'High', 'Low') AS salary_level FROM employees;
| name | sal | salary_level |
|---|---|---|
| Alice | 5000 | Low |
| Bob | 6000 | High |
| Carol | NULL | Low |
| Dave | 7000 | High |
二、约束 Constraints
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确、有效性和完整性。
- 分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束(8.0.1版本后) | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张图的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
【注意】
约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
常用约束
- 非空约束:not null
- 唯一约束:unique
- 主键约束:primary key(自增)
- 默认约束:defualt
- 检查约束:check
- 外键约束:foreign key
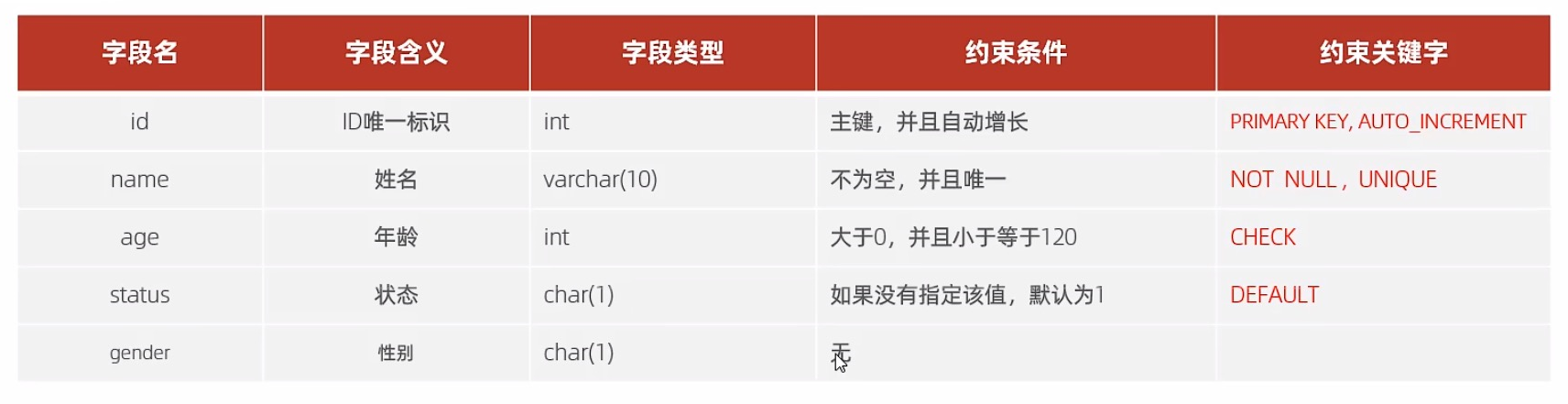
| 约束条件 | 关键字 |
|---|---|
| 主键 | PRIMARY KEY |
| 自动增长 | AUTO_INCREMENT |
| 不为空 | NOT NULL |
| 唯一 | UNIQUE |
| 逻辑条件 | CHECK |
| 默认值 | DEFAULT |
create table user(id int primary key auto_increment comment 'id主键',name varchar(10) not null unique comment '姓名',age int check ( age > 0 and age <= 120 ) comment '年龄',status char(1) default '1' comment '状态',gender char(1) comment '性别'
) comment '用户表';
主键细节
- 1.primary key不能重复而且不能为null。
- 2.一张表最多只能有一个主键,但可以是复合主键
- 3.主键的指定方式有两种
- 直接在字段名后指定:字段名primakry key
- 在表定义最后写primary key(列名);
- 4.使用desc表名,可以看到primary key的情况.
复合主键
复合主键(Composite Primary Key)是指由两个或多个字段共同组成的主键,用来唯一标识数据库表中的每一行记录。简单来说,就是用多个列的组合来确保每条记录的唯一性。
为什么要用复合主键?
想象一下,你在管理一个图书馆的书籍。每本书都有一个ISBN号,理论上,ISBN号应该是唯一的。但是,假设有两本不同的书,它们恰好有相同的ISBN号(虽然在现实中这种情况几乎不可能发生,但为了举例,我们暂时这么假设)。在这种情况下,如果你只用ISBN号作为主键,数据库就会遇到问题,因为它不允许有重复的主键值。
为了解决这个问题,你可能会决定同时使用ISBN号和书籍的出版年份来唯一标识每本书。这样,即使两本书的ISBN号相同,它们的出版年份也不同,从而确保了每本书都能被唯一地识别。
举个例子 假设你有一个订单表,记录了客户下单的详细信息。每张订单可能包含多个商品,而且每个商品可能在不同的订单中重复出现。如果你只用商品ID作为主键,就无法区分同一个商品在不同订单中的记录。因此,你可能会选择使用“订单ID”和“商品ID”的组合作为复合主键。
CREATE TABLE OrderDetails (OrderID INT,ProductID INT,Quantity INT,Price DECIMAL(10, 2),PRIMARY KEY (OrderID, ProductID) -- 复合主键
);
在这个例子中: OrderID 和 ProductID 共同组成了复合主键。 这意味着在同一个订单中,每个商品的组合(订单ID和商品ID的组合)必须是唯一的。 这样的设计确保了即使两个订单中都包含了同一个商品,它们也能被区分开来,因为每个订单的订单ID是不同的。
错误示范
CREATE TABLE OrderDetails (-- 不能有两个主键OrderID INT PRIMARY KEY,ProductID INT PRIMARY KEY,Quantity INT,Price DECIMAL(10, 2),
);
自增长细节
- 1.一般来说自增长是和primary key配合使用的
- 2.自增长也可以单独使用[但是需要配合一个unique]
- 3.自增长修饰的字段为整数型的(虽然小数也可以但是非常非常少这样使用)
- 4.自增长默认从1开始,你也可以通过如下命令修改
- alter table 表名 auto_increment =新的开始值;
- 5.如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说,就按照自增长的规则来添加数据.
unique细节
- 如果没有指定not null,则unique字段可以有多个null
- 一张表可以有多个unigque字段
外键约束 foreign key
- 外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。

外键必会细节
● foreign key(外键)—细节说明(创建小表演示)
- 1.外键指向的表的字段,要求是primary key或者是unique
- 2.表的类型是innodb,这样的表才支持外键
- 3.外键字段的类型要和主键字段的类型一致(长度可以不同)
- 4.外键字段的值,必须在主键字段中出现过,或者为null [前提是外键字段允许为null]
- 5.一旦建立主外键的关系,数据不能随意删除了.
添加外键关联
创建表时添加
CREATE TABLE 表名(字段名 字段类型,...[CONSTRAINT] [外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名)
);
比如
CREATE TABLE parents (parent_id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL
);CREATE TABLE children (child_id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL,parent_id INT,FOREIGN KEY (parent_id) REFERENCES parents(parent_id)ON DELETE CASCADEON UPDATE CASCADE
);
- 外键约束使用 FOREIGN KEY 关键字定义,并指定了 REFERENCES 子句来引用主键。
- ON DELETE CASCADE 和 ON UPDATE CASCADE 选项表示,当引用的主键被删除或更新时,相应的外键记录也会被级联删除或更新。(看情况也可以不要)
创建表后添加
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表(主表列名);
- 外键在创建后,主表中的关联无法删除,这样保证了一致性和完整性
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
案例
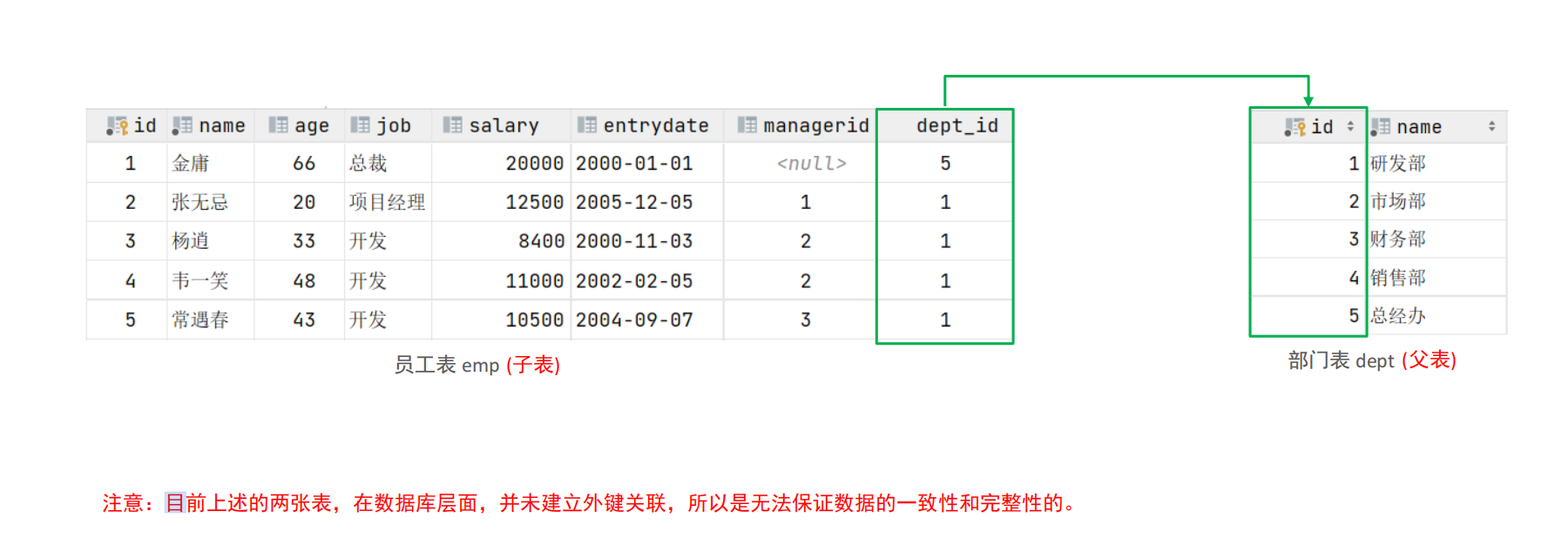
create table dept
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '部门名称'
) comment '部门表';INSERT INTO dept (id, name)
VALUES (1, '研发部'),(2, '市场部'),(3, '财务部'),(4, '销售部'),(5, '总经办');create table emp1
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '姓名',age int comment '年龄',job varchar(20) comment '职位',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment '直属领导ID',dept_id int comment '部门ID'
) comment '员工表';INSERT INTO emp1 (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5),(2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1),(3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1),(4, '韦一笑', 48, '开 发', 11000, '2002-02-05', 2, 1),(5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1),(6, '小昭', 19, '程 序员鼓励师', 6600, '2004-10-12', 2, 1);-- 建立外键关联 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表(主表列名);
alter table emp1 add constraint fk_emp1_dept_id foreign key (dept_id) references dept(id);-- 删除外键 ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
alter table emp1 drop foreign key fk_emp1_dept_id;
删除/更新行为
| 行为 | 说明 |
|---|---|
| NO ACTION | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新(与RESTRICT一致) |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新(与NO ACTION一致) |
| CASCADE | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则也删除/更新外键在子表中的记录 |
| SET NULL | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(要求该外键允许为null) |
| SET DEFAULT | 父表有变更时,子表将外键设为一个默认值(Innodb不支持) |
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名(主表字段名) ON UPDATE 行为 ON DELETE 行为;alter table emp1 add constraint fk_emp1_dept_id foreign key (dept_id) references dept(id) on update CASCADE on delete CASCADE ;#CASCADE 的位置可以是上面四个