定时器设计
定时器设计的必要性
服务器中的定时器设计具有多方面的必要性,主要体现在以下几个关键方面:
- 任务调度与管理
定时任务执行:服务器常常需要执行一些定时性的任务,如定时备份数据、定时清理缓存、定时更新系统日志等。通过定时器可以精确地设置任务的执行时间和周期,确保这些任务按照预定的计划自动执行,无需人工干预,提高服务器的自动化管理水平。
资源合理分配:服务器资源有限,通过定时器可以合理分配资源在不同任务之间的使用时间。例如,在业务低谷期定时启动一些耗时的维护任务,避免在业务高峰期占用过多资源,影响正常业务处理。 - 连接管理与优化
连接超时处理:服务器需要处理大量的客户端连接,对于长时间没有活动的连接,定时器可以设置超时时间,当连接超过规定时间没有数据传输时,自动关闭连接,释放服务器资源,防止大量无效连接占用资源,提高服务器的并发处理能力。
心跳检测:通过定时器定期向客户端发送心跳包,检测客户端的连接状态。如果客户端在一定时间内没有响应心跳包,服务器可以判断客户端可能出现异常,进而采取相应的措施,如关闭连接或进行重连尝试,保证连接的稳定性和可靠性。 - 性能监控与维护
性能指标统计:定时器可以定时触发对服务器性能指标的统计,如 CPU 使用率、内存使用率、网络带宽利用率等。通过定期收集这些数据,管理员可以及时了解服务器的性能状况,发现潜在的性能问题,为性能优化和资源调整提供依据。
故障检测与恢复:定时检查服务器的关键组件和服务状态,当发现某个服务出现故障或异常时,定时器可以触发相应的恢复机制,如自动重启服务、切换到备用服务器等,尽可能减少故障对业务的影响,提高服务器的可用性和稳定性
2 定时器设计的两种模式
对于服务端来说,驱动服务端逻辑的事件主要有两个,⼀个是⽹络事件,另⼀个是时间事件
2.1 网络事件和定时事件在一个线程中处理
协同处理原理
在服务器编程中,基于事件驱动的网络 IO 模型(如 reactor 模型)是常见的处理方式。这里的 IO 处理同步,意味着当进行网络 IO 操作(如读取或写入网络数据)时,线程会等待操作完成,直到数据可读或可写。而事件处理(包括定时任务处理)是异步的,即不需要等待定时任务时间到达才去执行后续操作,程序可以继续处理其他事情,当定时时间到达时,系统会自动触发相应的处理逻辑。
利用 IO 多路复用(如 epoll、kqueue 等)机制,它可以同时监控多个文件描述符(对应网络连接等)的状态变化。在这种机制下,通过设置 epoll_wait () 等函数的 timeout 参数来模拟定时器功能。
具体流程
- 确定等待时间:首先获取最近要触发的定时任务的触发时间与当前时间的差值,将这个差值作为 epoll_wait () 函数的 timeout 参数。例如,如果最近的定时任务还有 5 秒触发,那么 timeout 就设为 5 秒。
- 阻塞等待:调用 epoll_wait () 函数,线程进入阻塞状态。在这期间,如果没有网络事件发生,当等待时间超过设定的 timeout,就会先去处理定时任务。比如,5 秒内没有网络连接的读写事件,那么就执行到期的定时任务。
- 事件处理顺序:若在等待过程中收到网络事件(如客户端发送了新数据,对应的网络连接的文件描述符状态变为可读),则 epoll_wait () 返回,先处理网络事件。处理完网络事件后,再去轮询处理定时事件。比如先读取并处理完客户端发送的数据,再检查并执行到期的定时任务。
应用场景
- 单 reactor 场景(以 redis 为例):Redis 采用单 reactor 模式,在一个线程中处理网络请求和定时任务。它适用于业务逻辑相对简单、对性能要求高且定时任务不是特别多的场景。因为单线程处理避免了线程切换带来的开销,能高效处理大量的短小请求,同时定时任务也能在合适的时机得到处理。
- 多 reactor 场景(以 memcached、nginx 为例):memcached 和 nginx 采用多 reactor 模式,主 reactor 负责监听新连接,将连接分配给子 reactor,子 reactor 在各自线程中处理网络事件和定时任务。这种模式适用于高并发场景,能充分利用多核 CPU 的性能,同时在每个子 reactor 线程内也能较好地协调网络事件和定时任务的处理,不过定时任务不能过于繁重,否则会影响网络事件的及时处理。
在同一个线程中处理网络事件和定时任务时,若定时任务即将执行但此时线程还在处理网络事件,可按以下方式处理:
基于 IO 多路复用的处理策略
一般通过 IO 多路复用机制(如 epoll )来协调。在设置 epoll_wait 的 timeout 参数时,是依据最近要触发的定时任务时间来确定的。当 epoll_wait 返回有网络事件时,线程先处理网络事件。处理网络事件过程中,定时任务时间到达也不会立即中断处理 。等网络事件处理完毕,再去检查并执行到期的定时任务。这是因为在单线程内,为保证数据一致性和避免复杂的中断处理逻辑,优先完整处理完当前网络事件。例如在 Redis 中,即使在处理网络请求时定时任务时间到了,也会等请求处理完再去处理定时任务 。
任务优先级与抢占机制(有限应用)
从理论上,若要提高定时任务的实时性,可引入任务优先级和抢占机制。但在单线程场景下,实现复杂且易引发问题。若定时任务优先级极高,可设计在网络事件处理函数中定期检查定时任务状态(比如每处理完一批网络数据检查一次 ),一旦发现有高优先级定时任务到期,暂停当前网络事件处理(需保存好上下文 ),先去执行定时任务,执行完再恢复网络事件处理。不过这种方式会增加代码复杂度和出错风险,实际应用中较少采用,因为可能破坏单线程内操作的原子性和一致性,引发数据竞争等问题。
2.2 网络事件和定时事件在不同线程中处理
- 创建定时任务检测线程:专门创建一个独立的线程,这个线程的职责就是检测定时任务。它以 sleep (time) 作为定时器驱动,这里的 time 要小于最小时间精度,比如最小时间精度是 100 毫秒,那么 time 可以设为 50 毫秒。
- 循环检测与处理:在这个线程中,不断循环更新定时器的状态。线程处于休眠状态等待定时事件,当设定的时间到达时,通过信号(如 Linux 下的信号机制,向负责业务逻辑的线程发送特定信号)或者将任务插入运行队列(由其他线程从队列中取出任务并执行)的方式,让其他线程去执行业务逻辑。例如,当一个定时任务到期,该线程向业务线程发送信号,业务线程收到信号后执行相应的定时任务操作。
3 基本数据结构简介
3.1按触发时间顺序组织
**红黑树建议了解一下 **
3.1.1 跳表
下图是一个简单的有序单链表,单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。
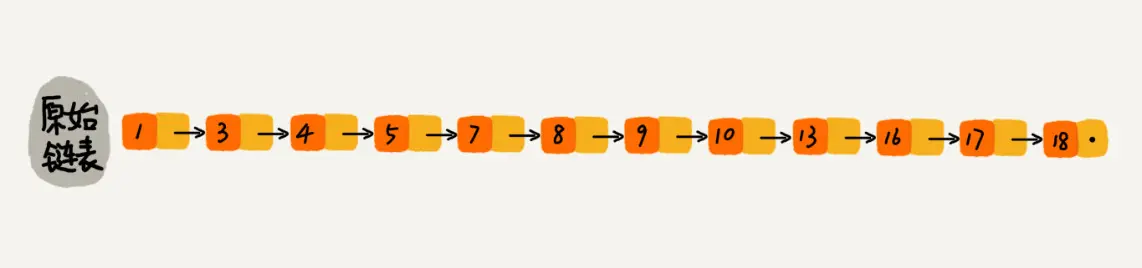
现在我们有个场景,想快速找到上图链表中的 10 这个元素,只能从头开始遍历链表,直到找到我们需要找的元素。查找路径:1、3、4、5、7、8、9、10。这样的查找效率很低,平均时间复杂度很高O(n)。
先在索引找 1、4、7、9,遍历到一级索引的 9 时,发现 9 的后继节点是 13,比 10 大,于是不往后找了,而是通过 9 找到原始链表的 9,然后再往后遍历找到了我们要找的 10,遍历结束。有没有发现,加了一级索引后,查找路径:1、4、7、9、10,查找节点需要遍历的元素相对少了,我们不需要对 10 之前的所有数据都遍历,查找的效率提升了。
那如果加二级索引呢?如下图所示,查找路径:1、7、9、10。是不是找 10 的效率更高了?这就是跳表的思想,用“空间换时间”,通过给链表建立索引,提高了查找的效率。
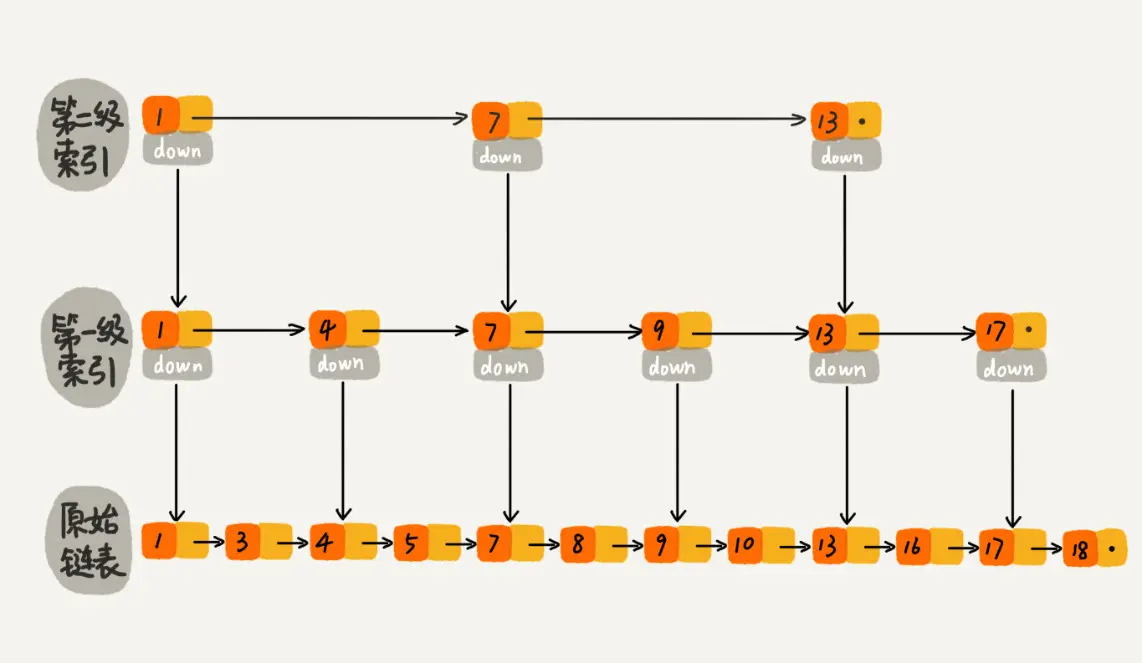
到这里大家应该已经明白了什么是跳表。跳表是可以实现二分查找的有序链表。
相对于黑红树 它的优势就是范围输出
3.1.2 最小堆
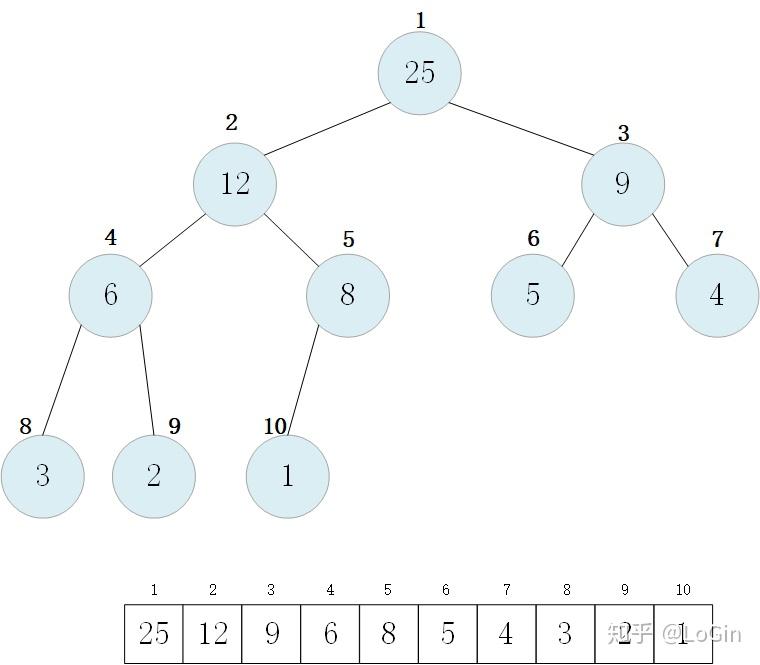
上面这种类型的数据结构我们将它称为二叉堆。二叉堆在逻辑上虽然是完全二叉树,但是它却是以1为起点的一维数组表示的。假设表示二叉堆的数组为A,二叉堆的大小(元素的数量)为H,那么二叉堆的元素就存储在 A[1, … , H] 中,其中根的下标是1.观察可以发现,只要一个结点的下标i确定了,那么它的父节点就是floor(i/2),左子结点下标是2i, 右子结点的下标是2i+1。
二叉堆和完全二叉树的区别之一在于,二叉堆中存储的各结点的键值需要保证堆具有以下性质之一
最大堆性质: 结点的键值都小于等于其父结点的键值。
·最小堆性质: 结点的键值都大于等于其父结点的键值。
取最小值操作高效时间复杂度低:最小堆查询顶节点(即最小值)的时间复杂度为 (O(1)) ,能直接获取最小值 。而红黑树查找最小值需要从根节点开始,沿着左子树不断向下遍历,时间复杂度为 (O(\log N)) (N 为节点数 ) 。在频繁获取最小值的场景,如优先队列、任务调度系统中确定最早执行任务等,最小堆效率明显更高 。
结构简单,实现难度低原理与代码实现:最小堆原理直观,只需满足父节点小于子节点,实现代码相对简洁。红黑树要满足多种平衡规则(如节点颜色规则、路径黑色节点数相同等 ) ,插入、删除操作需复杂的旋转和颜色调整来维持平衡,实现难度大,代码出错风险高 。数据局部性好内存访问优势:**最小堆常以数组存储,**在内存中数据连续。CPU 缓存预取机制能利用这种数据局部性,访问相邻元素时可直接从缓存获取,减少内存访问开销。红黑树节点通过指针链接,内存分布分散,缓存命中率低,性能受影响 。
3.2 时间轮
为了不产生过多的定时器,我们只使用一个定时器,将所有的定时任务放到一个队列中,每个定时任务都保存一份自己的定时信息,定时器每隔一个周期轮询一遍队列中的所有任务,如果任务的超时时间已到,则执行该任务,如果超时时间还没到,则将该任务的定时信息减掉一个定时器的时间间隔,等到完全减为0时,该任务就可以被执行了, 这个定时器一直这么执行并轮询下去.假设当前定时任务总数有100个,那定时器每个周期会遍历一个100个元素的队列,听上去还可以,那要有1000个的时候,10000个时候,这定时器就太可怜了,像一头老牛
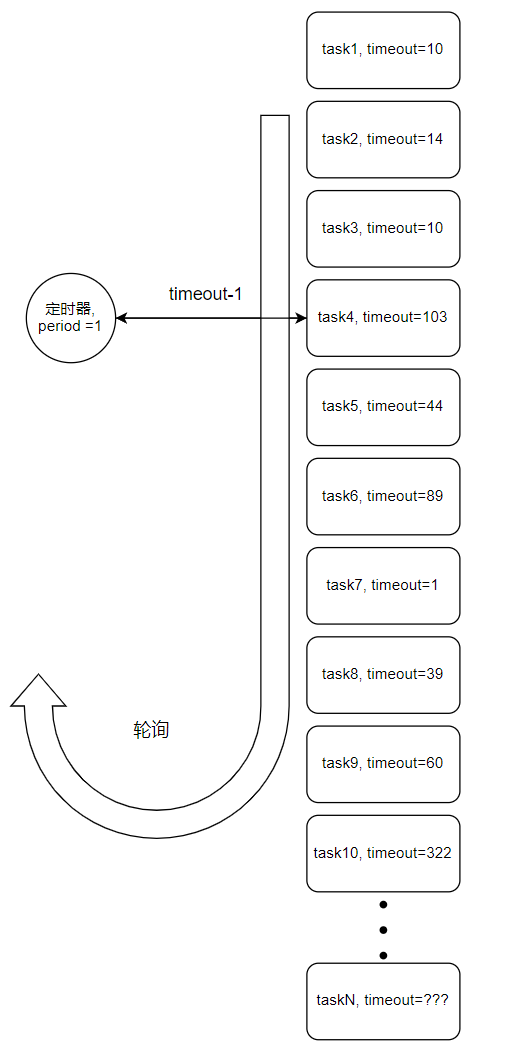
为了解决任务队列中任务太多,一个定时器压力太大的问题,我们继续对其进行优化,既然所有的定时任务都放在一个队列下不太行,那就对定时任务进行分类,将定时周期相同的任务放在同一个定时器下,这样每个定时器的压力就会大大减小,每个定时器只负责自己周期内的任务,不负责其他周期的任务.但是如果每个任务的周期都相同,还是要产生很多定时器,似乎还是无法从根本上解决问题…
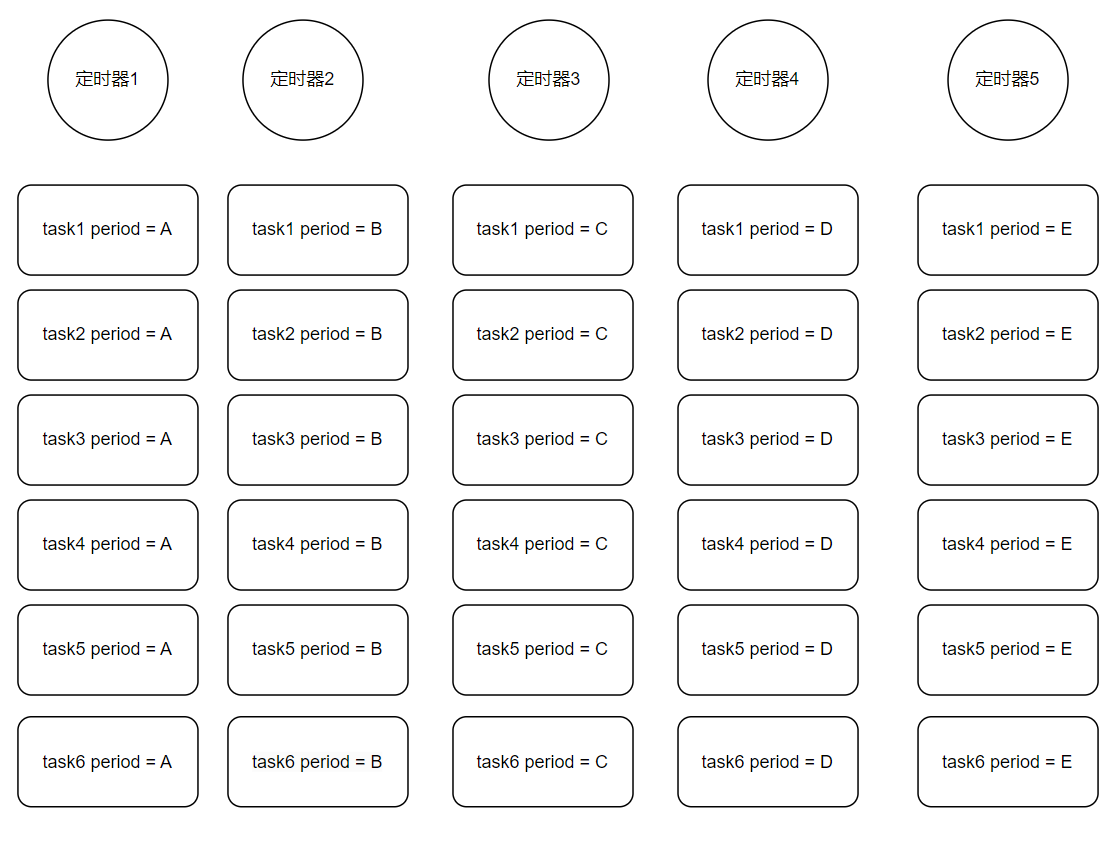
这时候时间轮的优势就体现出来了,我们设置一个环状的时间队列,队列上的每一个元素,我们称为一个槽(slot),这个槽所对应的时间在整个时间轮里是唯一的, 根据前面的分析也能知道,槽里面是放任务的,而且肯定不会放一个任务,而是放一个任务队列.
对这个环状队列,我们维护一个指针,指针指向的槽,就是已经到达超时时间的槽,槽里的任务就要被执行.任务在被插入时间轮的时候,就根据当前时间以及自己的时间周期,确定好了自己会处于时间轮中的哪个槽.等到时间轮指针指到这个槽,任务就被触发.
基本模型组成
- tickMs(基本时间跨度):时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。
- wheelSize(时间单位个数):时间轮的时间格个数是固定的,可用(wheelSize)来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs × wheelSize计算得出。
- currentTime(当前所处时间):时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime 是 tickMs 的整数倍。currentTime 可以将整个时间轮划分为到期部分和未到期部分,currentTime 当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的 TimerTaskList 的所有任务。
单层时间轮
上面图例就是单层时间轮,这个时间轮的所能处理的最大周期是有限的,比如,一个具有10个slot的时间轮,wheel size = 10,每两个槽之间的间隔为1s,这个间隔称为tick,即最小的时间间隔,那么这个时间轮的跨度就是10*1 = 10s,也就是所支持能设置的最大周期为10s,如果一个任务每隔11秒执行一次.
同时,10s这个周期太短了,现在各种系统中不乏周期为成百上千秒的定时任务,且以1s为分割,颗粒太大了,秒级以下的定时任务无法被触发.
如果仅仅是个时间跨度为10s切以秒为tick的时间轮,是基本满足不了大部分场景的,为了满足需求,最简单快速的方法就是加大时间轮跨度来提升周期**,降低tick来提高精度,如果时间跨度提升为60s, tick改成10ms,就需要6000个槽来安插任务,这样就可以设置周期更长的任务,可以根据更精细的时间单位(10ms)来执行定时任务**
需求虽然得到满足,但也引发了一系列问题:
首先,轮询线程的遍历效率显著降低。当timescale数量增加而task数量较少时,例如仅有50个槽位存在task,却需要遍历6000个timescale,这与时间轮算法提升遍历效率的初衷相悖。
其次,存在内存空间浪费的问题。由于时间尺度密集而任务数量稀少,大部分时间尺度占用的内存空间实际上并未发挥应有作用。
更为严重的是,如果将时间轮跨度设置为1小时,整个时间轮将需要36000个单位的时间刻度(60x60x1000/100),这将导致时间轮算法的遍历线程面临更大的运行效率挑战。
由此可见,单层时间轮的性能上限较低,一旦对精度和时间跨度的要求提高,便难以实现预期目标。
多层时间轮
解析
第一层的时间轮 tickMs=1ms, wheelSize=20, interval=20ms。第二层的时间轮的 tickMs 为第一层时间轮的 interval,即为 20ms。每一层时间轮的 wheelSize 是固定的,都是 20,那么第二层的时间轮的总体时间跨度 interval 为 400ms。以此类推,这个 400ms 也是第三层的 tickMs 的大小,第三层的时间轮的总体时间跨度为 8000ms。
流程分析
- 当到达时间格 2 时,如果此时有个定时为 350ms 的任务,显然第一层时间轮不能满足条件,所以就 时间轮升级 到第二层时间轮中,最终被插入到第二层时间轮中时间格 17 所对应的 TimerTaskList 中;
- 如果此时又有一个定时为 450ms 的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入到第三层时间轮中时间格 1 的 TimerTaskList 中;
注意到在到期时间在 [400ms,800ms) 区间的多个任务(比如446ms、455ms以及473ms的定时任务)都会被放入到第三层时间轮的时间格 1 中,时间格 1 对应的TimerTaskList的超时时间为400ms; - 随着时间的流逝,当次 TimerTaskList 到期之时,原本定时为 450ms 的任务还剩下 50ms 的时间,还不能执行这个任务的到期操作。这里就有一个 时间轮降级 的操作,会将这个剩余时间为 50ms 的定时任务重新提交到层级时间轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为 [40ms,60ms) 的时间格中;
- 再经历了 40ms 之后,此时这个任务又被“察觉”到,不过还剩余 10ms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到第一层时间轮到期时间为 [10ms,11ms) 的时间格中,之后再经历 10ms 后,此任务真正到期,最终执行相应的到期操作。
4 定时器设计
#ifndef _MARK_RBT_
#define _MARK_RBT_#include <stdio.h>
#include <stdint.h> // 整数
#include <unistd.h> // usleep
#include <stdlib.h> // malloc 注意需要强转
#include <stddef.h> //offsetof#if defined(__APPLE__)
#include <AvailabilityMacros.h>
#include <sys/time.h>
#include <mach/task.h>
#include <mach/mach.h>
#else
#include <time.h>
#endif#include "rbtree.h"ngx_rbtree_t timer;
static ngx_rbtree_node_t sentinel;typedef struct timer_entry_s timer_entry_t;
typedef void (*timer_handler_pt)(timer_entry_t *ev);struct timer_entry_s {ngx_rbtree_node_t rbnode;timer_handler_pt handler;
};static uint32_t
current_time() {uint32_t t;
#if !defined(__APPLE__) || defined(AVAILABLE_MAC_OS_X_VERSION_10_12_AND_LATER)struct timespec ti;clock_gettime(CLOCK_MONOTONIC, &ti);t = (uint32_t)ti.tv_sec * 1000;t += ti.tv_nsec / 1000000;
#elsestruct timeval tv;gettimeofday(&tv, NULL);t = (uint32_t)tv.tv_sec * 1000;t += tv.tv_usec / 1000;
#endifreturn t;
}ngx_rbtree_t * init_timer() {ngx_rbtree_init(&timer, &sentinel, ngx_rbtree_insert_timer_value);return &timer;
}void add_timer(uint32_t msec, timer_handler_pt func) {timer_entry_t *te = malloc(sizeof(timer_entry_t));memset(te, 0, sizeof(timer_entry_t));te->handler = func;msec += current_time();printf("add_timer expire at msec = %u\n", msec);te->rbnode.key = msec;ngx_rbtree_insert(&timer, &te->rbnode);
}void del_timer(timer_entry_t *te) {ngx_rbtree_delete(&timer, &te->rbnode);free(te);
}int find_nearest_expire_timer() {ngx_rbtree_node_t *node;if (timer.root == &sentinel) {return -1;}node = ngx_rbtree_min(timer.root, timer.sentinel);int diff = (int)node->key - (int)current_time();return diff > 0 ? diff : 0;
}void expire_timer() {timer_entry_t *te;ngx_rbtree_node_t *sentinel, *root, *node;sentinel = timer.sentinel;uint32_t now = current_time();for (;;) {root = timer.root;if (root == sentinel) break;node = ngx_rbtree_min(root, sentinel);if (node->key > now) break;printf("touch timer expire time=%u, now = %u\n", node->key, now);te = (timer_entry_t *) ((char *) node - offsetof(timer_entry_t, rbnode));te->handler(te);ngx_rbtree_delete(&timer, &te->rbnode);free(te);}
}