LeetCode热题100——链表
链表
- 相交链表
- 反转链表
- 回文链表
- 环形链表
- 环形链表 II
- 合并两个有序列表
- 两数相加
- 删除链表的倒数第N个节点
- 两两交换链表中的节点
- K 个一组翻转链表
- 随机链表的复制
- 排序列表
- 合并K个升序链表
- LRU缓存
相交链表
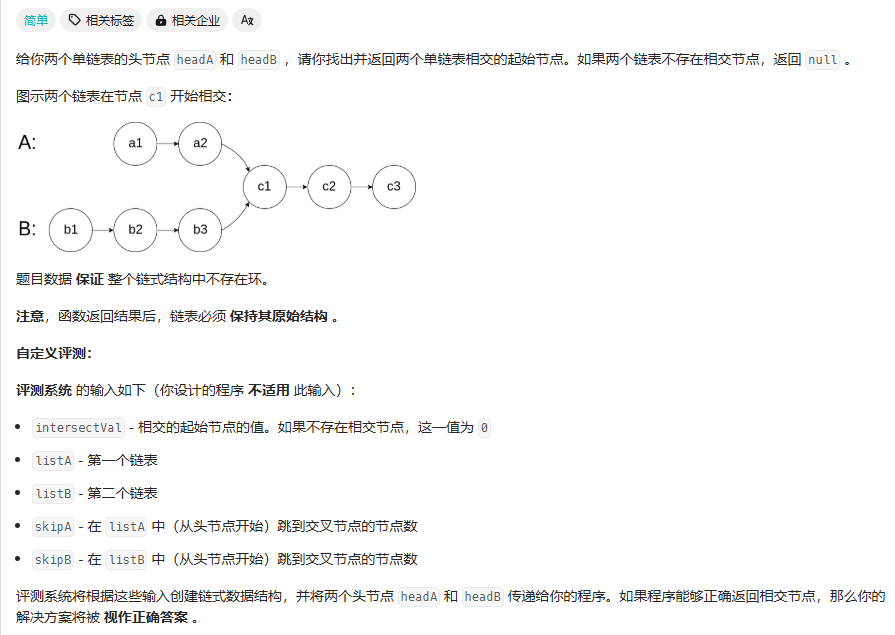


这里担心的问题是从头开始遍历会存在遍历不知道谁走下一步 因为长度不一样,然后又考虑添加一个map存放已经遍历过的数据,然后用find函数复杂度也比较低 ,但是实现还是挺麻烦
这里给出的做法是 :考虑到希望两个链表的遍历能同时到达第一个相同结点,因此设第一个公共结点为node,链表headA的结点数量为a,headB的节点数量为b,两链表的公共尾部的节点数量为c,则:
headA到node前,共有a-c个节点;
headB到node前,共有b-c个节点;
指针A遍历完headA再开始遍历headB,则到node时,共走了a+(b-c)
指针B同上,则共走了b+(a-c)
class Solution{
public:ListNode *getInsertsectionNode(ListNode *headA,ListNode *headB){ListNode *B = headB,*A=headA;while(A!=B){A = A!=nullptr?A->next:headB;B = B!=nullptr?B->next:headA;}return A;}
}
反转链表

笔者自己的做法是先遍历链表使用栈存储链表的值 再创建一个链表保存栈的值 代码如下:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverseList(ListNode* head) {if(head==nullptr) return {};stack<int> st;while(head!=nullptr){st.push(head->val);head = head->next;}ListNode* ans = new ListNode;ListNode* point = ans;if(!st.empty()){ans->val = st.top();st.pop();}while(!st.empty()){ListNode* A = new ListNode;A->next = nullptr;A->val = st.top();st.pop();point->next = A;point = point->next;}return ans;}
};
这里介绍官方的两种方法解答:
**1.迭代:**在遍历链表时,将之前节点的next指针改为指向前一个节点。由于节点没有引用其前一个节点,因此必须实现存储前一个节点。
class Solution{
public:ListNode* reverseList(ListNode* head){ListNode* prev = nullptr;ListNode* curr = head;while(curr){ListNode* next = curr->next;curr->next = prev;prev = curr;curr = next;}return prev;}
}
**2.递归:**递归的关键在于反向工作。需要注意的是n1的下一个节点必须指向空。如果忽略可能会出现环。
class Solution{
public:ListNode* reverseList(ListNode* head){if(!head||!head->next){return head;}ListNode* newHead = reverseList(head->next);head->next->next = head;head->next = nullptr;return newHead;}
}
回文链表

这里介绍两种做法:
1.先将链表的值存入数组中再用双指针法对数组双向遍历进行判断
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public:bool isPalindrome(ListNode* head){vector<int> vals;while(head!=nullptr){vals.emplace_back(head->val);head = head->next;}for(int i=0,j=vals.size()-1;i<j;i++,j--){if(vals[i]!=vals[j]){return false;}}return true;}
}
2.使用迭代的方法,先将一个指针通过迭代的方式移动的最末尾,然后双向进行比较判断
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {ListNode* frontPointer;
public:bool rec(ListNode* currentNode){if(currentNode!=nullptr){if(!rec(currentNode->next)){return false;}if(currentNode->val!=frontPointer->val){return false;}frontPointer = frontPointer->next;}return true;}bool isPalindrome(ListNode* head) {frontPointer = head;return rec(head);}
};
环形链表
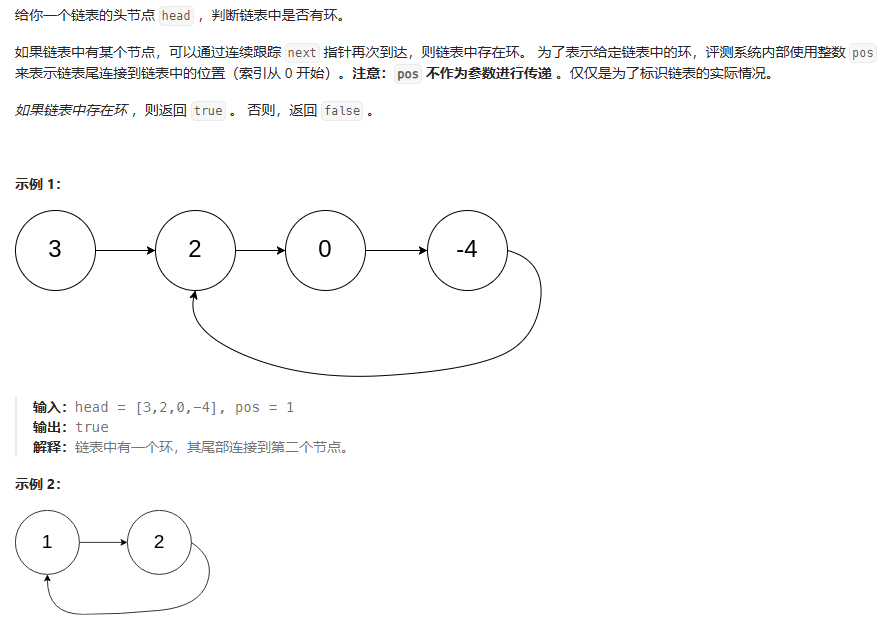

这里给出两种做法:
1.使用哈希表:
使用set存储整个ListNode,并在每次都查找set中是否有相同的节点,如果set.count(xx)>0则return true
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution{
public:bool hasCycle(ListNode *head){set<ListNode*> seen;while(head!=nullptr){if(seen.count(head)) return true;seen.insert(head);head = head->next;}return false;}
}
2.使用快慢指针
使用两个指针,一个slow在head,一个fast在head->next处,fast每次移动两步,slow移动一步,但是需要提前判断head是否有两个以上的元素
如果有环形,则fast会先进入循环中,然后slow再进入 二者会相遇
class Solution{
public:bool hasCycle(ListNode *head){if(head == nullptr || head->next == nullptr){return false;}ListNode* slow = head,*fast = head->next;while(slow!=fast){if(fast==nullptr || fast->next==nullptr){return false;}slow = slow->next;fast = fast->next->next;}return true;}
}
环形链表 II
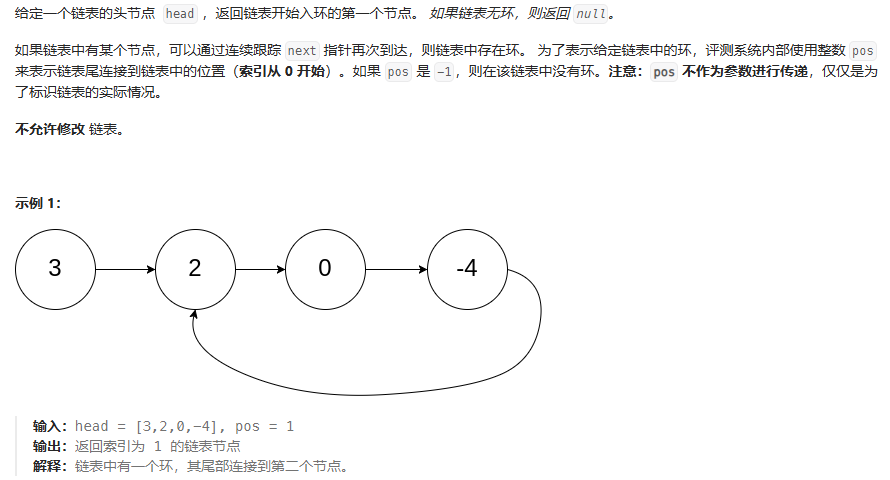

方法1:使用哈希表存储,如果后序遍历到相同的结点直接输出、
class Solution{
public:ListNode *detectCycle(ListNode *head){set<ListNode *> visited;while(head!=nullptr){if(visited.count(head)) return head;visited.insert(head);head = head->next;}return nullptr;}
};
方法2:使用快慢指针
就是快指针与慢指针相遇的地方(紫色)再经过n-1圈加上相遇点到进入环的点等于a的距离,因此从相遇点开始 设置一个指针ptr指向头结点head,然后slow跟ptr相遇的地方就是进入环的第一个结点位置
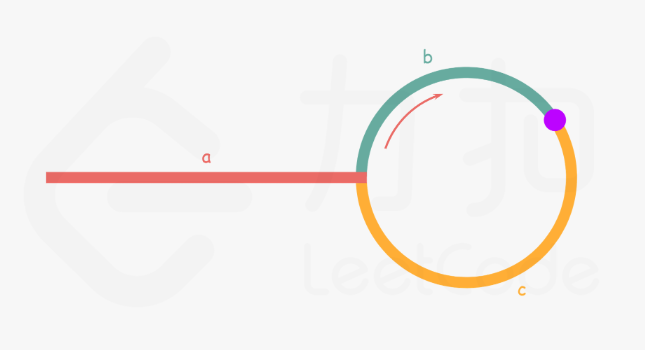
class Solution{
public:ListNode* detectCycle(ListNode *head){ListNode *slow = head,*fast=head;while(head!=nullptr){slow = slow->next;if(fast->next==nullptr) return nullptr;fast = fast ->next->next;if(fast==slow){ListNode* ptr = head;while(slow!=ptr){ptr = ptr->next;slow = slow->next;}return ptr;}}return nullptr;}
};
合并两个有序列表
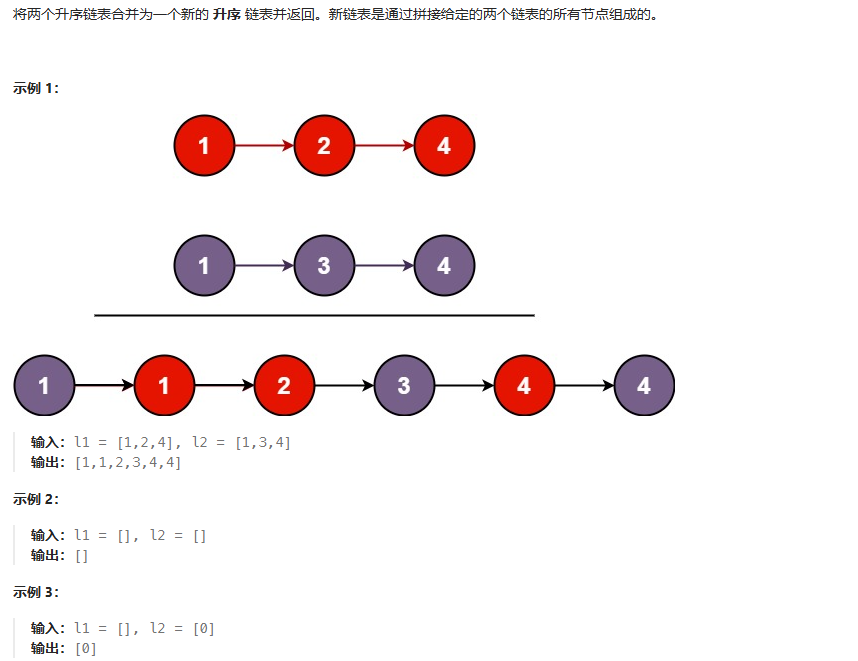
这里要求节点需要是原链表的结点,可以使用递归的方法
当然这里还要判断两个链表是否为空链表,如果一个为空则直接返回另一个链表
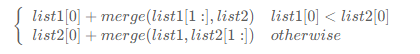
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if(l1==nullptr){return l2;}else if(l2==nullptr){return l1;}else if(l1.val<l2.val){l1->next = mergeTwoLists(l1->next,l2);return l1;}else{l2->next = mergeTwoLists(l1,l2->next);return l2;}}
};
两数相加
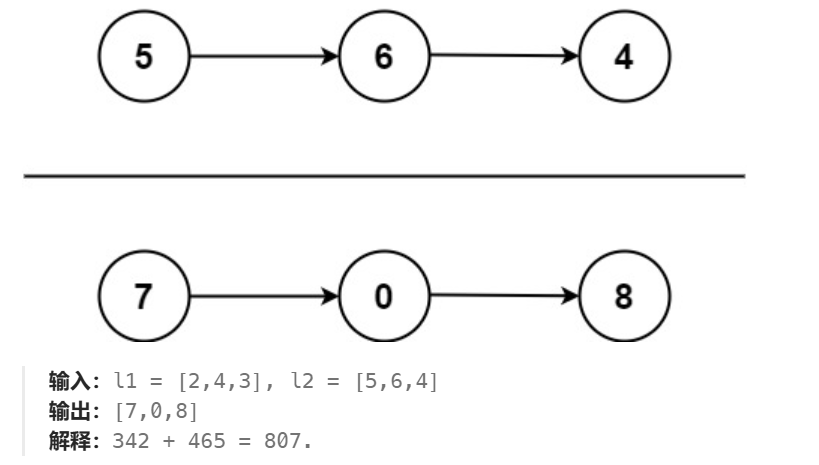

由于是逆序排列,于是可以对应位置的数相加 然后进位数用carry保存;实现的方式为n1+n2+carry
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public:ListNode* addTwoNumbers(ListNode* l1,ListNode* l2){ListNode* head = nullptr, *tail = nullptr;int carry = 0;while(l1 || l2){int n1 = l1?l1->val:0;int n2 = l2?l2->val:0;int sum = n1 +n2+carry;if(!head){head = tail = new ListNode(sum%10);}else{tail->next = new ListNode(sum%10);tail =tail->next;}carry = sum/10;if(l1){l1 = l1->next;}if(l2){l2 = l2->next;}}if(carry>0){tail->next = new ListNode(carry);}return head;}
};
删除链表的倒数第N个节点
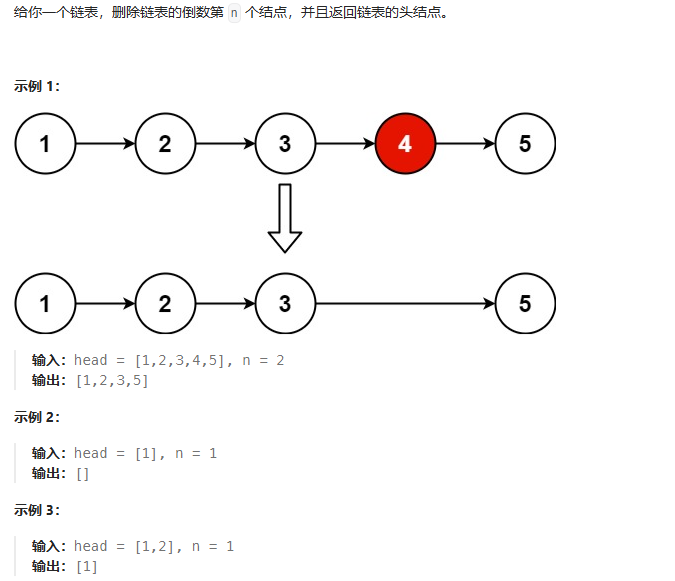

这里给出两种方法:
同时在解决链表问题的时候一般会使用哑结点(dummy node),它的 next 指针指向链表的头节点,这样便可以不需要对头结点进行特殊判断了 。即使链表只有一个元素,删除之后直接返回空指针这个空指针即可
1.计算出链表的长度然后将第(length-n+1)个删除,也就是将前一个指针指向next的next
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public:int getLength(ListNode* head){int length = 0;while(head){length++;head = head->next;}return length;}ListNode* removeNthFromEnd(ListNode* head,int n){ListNode* dummy = new ListNode(0,head); //定义的是一个头结点的前驱结点int length = getLength(head);ListNode* cur = dummy;for(int i=1;i<length-n+1;i++){ //为了跟题目的个数对应 因此从1开始cur = cur->next;}cur->next = cur->next->next;ListNode* ans = dummy->next;delete dummy;return ans;}
}
2.使用栈的新进后出原则 ,将每个ListNode入栈,然后全部入栈后弹出第n个 对第n个的next指向next的next,最后返回头指针
class Solution{
public:ListNode* removeNthFromed(ListNode* head,int n){ListNode* dummy = new ListNode(0,head);stack<ListNode*> stk;ListNode* cur = dummy;while(cur){stk.push(cur);cur=cur->next;}for(int i=0;i<n;i++){stk.pop();}ListNode* prev = stk.top();prev->next = prev->next->next;ListNode* ans = dummy->next;delete dummy;return ans;}
}
两两交换链表中的节点
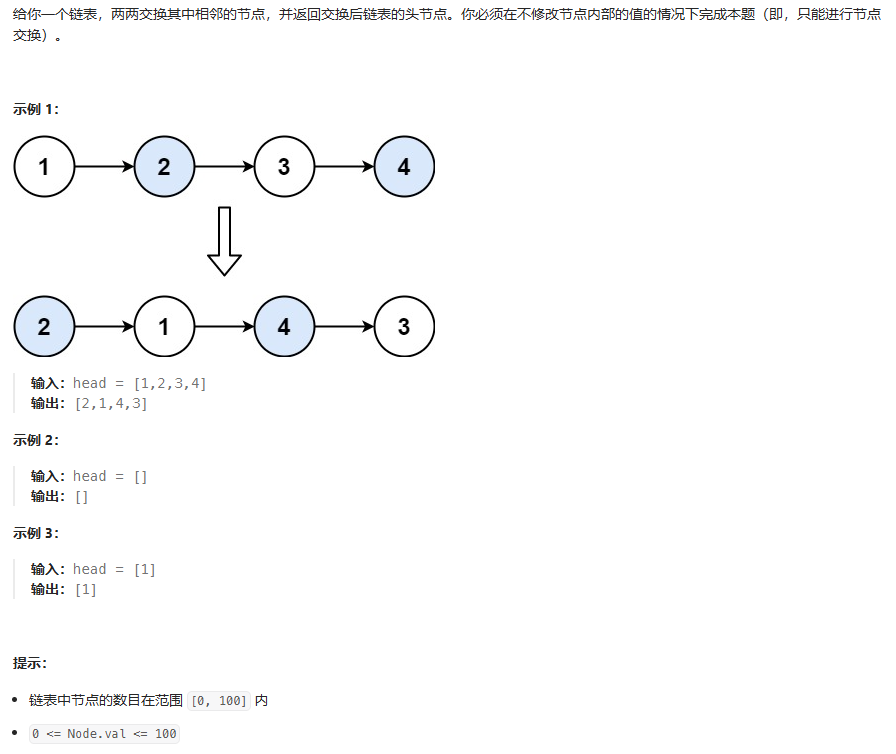
这里可以采用迭代的方法 但针对头结点为空以及只有一个节点的情况则作为递归结束的标志
用head表示原始链表的头结点,新的链表的第二个节点用newHead表示,返回的链表的头结点也是原始链表的第二个节点 。而链表中的其他节点进行两两交换即可
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public:ListNode* swapPairs(ListNode* head){if(head==nullptr||head->next==nullptr){return head;}ListNode* newHead = head->next;head->next = swapPairs(newHead->next);newHead->next = head;return newHead;}
}
K 个一组翻转链表
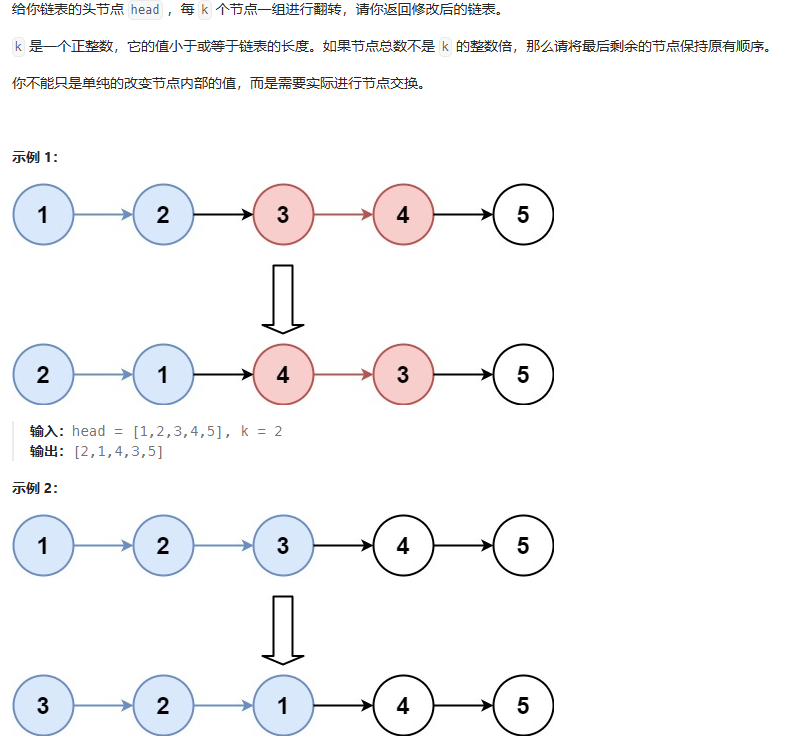

这道题确实有点难度,对K个一组的进行翻转首先还是需要定义一个翻转函数的myReverse。在进行翻转前 要判断后序链表是否够K个数。
同时 我们需要考虑的问题还有
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public://翻转一个子链表,并且返回新的头与尾pair<ListNode*,ListNode*> myReverse(ListNode* head,ListNode* tail){ListNode* prev = tail->next;ListNode* p = head;while(prev!=tail){ListNode* nex = p->next;p->next = prev;prev = p;p = nex;}return {tail,head};}ListNode* reverseKGroup(ListNode* head,int k){ListNode* hair = new ListNode(0);hair->next = head;ListNode* pre = hair;while(head){ListNode* tail = pre;//查看剩余部分长度是否大于等于kfor(int i=0;i<k;i++){tail = tail->next;if(!tail){return hair->next;}}ListNode* nex = tail->next;pair<ListNode*,ListNode*> result = myReverse(head,tail);head = result.first;tail = result.second;//把子链表重新接回原链表pre->next = head;tail->next = nex;head = tail->next;}return hair->next;}
};
随机链表的复制
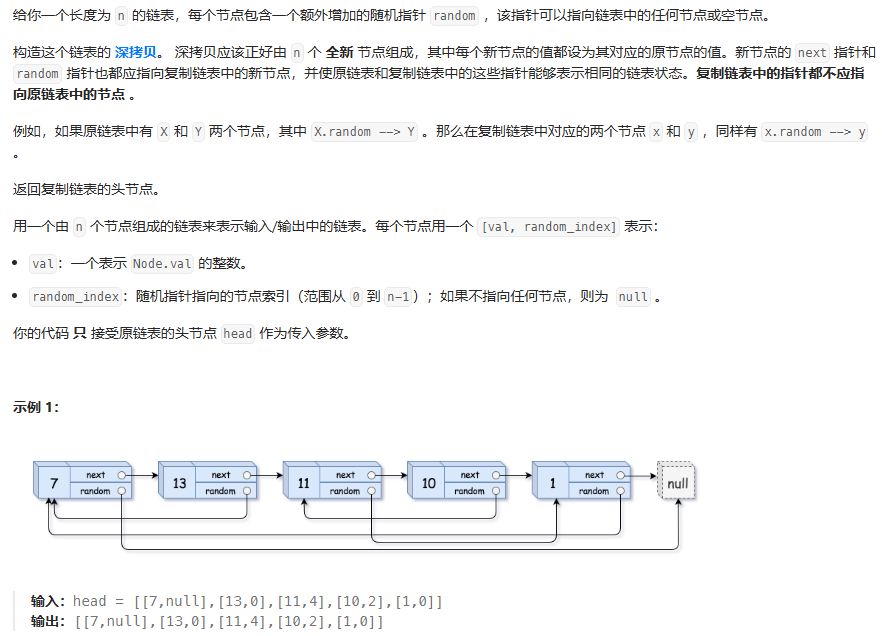
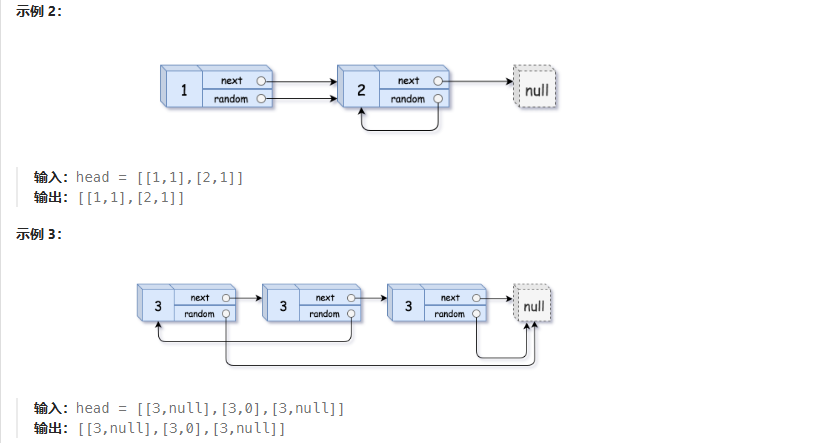
考虑到对原链表的深拷贝存在next和random指针指向的指针没有先创建 直接指向会报错,因此可以使用哈希表查看指向节点是否被创建,并采用迭代的方式对节点进行遍历
/*
// Definition for a Node.
class Node {
public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};
*/
class Solution{
public:unordered_map<Node*,Node*> cacheNode;Node* copyRandomList(Node* head){if(head==nullptr) return nullptr;if(!cacheNode.count(head)){Node* headNew = new Node(head->val);cacheNode[head] = headNew;headNew->next = copyRandomList(head->next);headNew->random = copyRandomList(head->random);}return cacheNode[head];}
};
排序列表
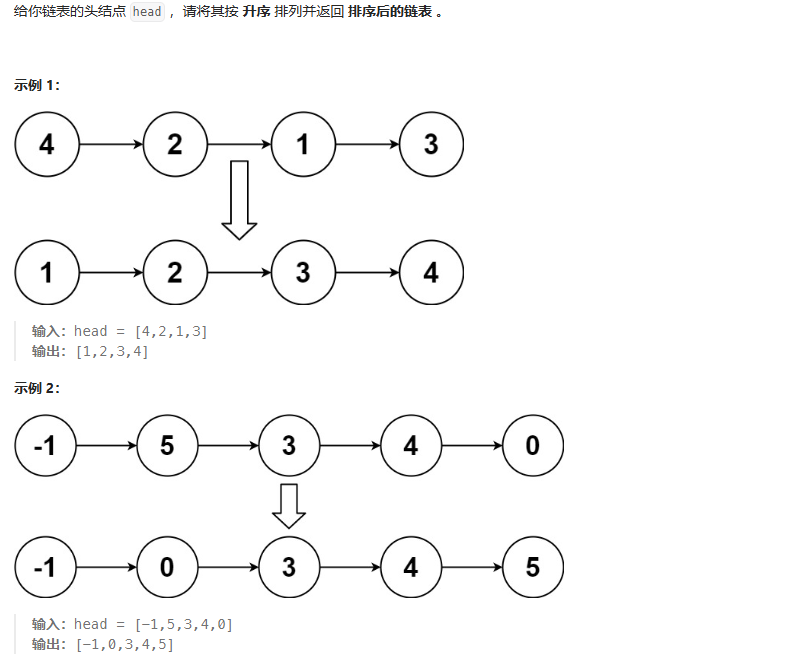

这道题使用的是自顶向下的归并排序,因为进阶要求了时间复杂度是O(nlogn),空间复杂度是O(1)。快速排序最差的时间复杂度是O(n^2)
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是O(logn)。如果要达到O(1)的空间复杂度,则需要使用自底向上的实现方式。
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution{
public:ListNode* sortList(ListNode* head){return sortList(head,nullptr);}ListNode* sortList(ListNode* head,ListNode* tail){if(head==nullptr) return head;if(head->next==tail){head->next = nullptr;return head;}ListNode* slow = head,*fast = head;while(fast!=tail){slow = slow->next;fast = fast->next;if(fast!=tail) fast = fast->next;}ListNode* mid = slow;return merge(sortList(head,mid),sortList(mid,tail));}ListNode* merge(ListNode* head1,ListNode* head2){ListNode* dummyHead = new ListNode(0);ListNode* temp = dummyHead, *temp1 = head1,*temp2 = head2;while(temp1!=nullptr && temp2!=nullptr){if(temp1->val <= temp2->val){temp->next = temp1;temp1 = temp1->next;}else{temp->next = temp2;temp2 = temp2->next;}temp = temp->next;}if(temp1!=nullptr){temp->next = temp1;}else if(temp2!=nullptr){temp->next = temp2;}return dummyHead->next;}
};
合并K个升序链表



对K个升序链表进行合并可以考虑对每两个链表进行合并,先写出两个升序列表的合并,然后一次对两个链表顺序合并 或者 使用分治合并
先给出两个升序链表合并并返回的函数
ListNode* mergeTwoLists(ListNode* a,ListNode* b){if((!a) || (!b)) return a?a:b; //其中一个为空则返回//因为head是定义的一个结构,他是充当的虚拟指针 因此不需要一定得是指针本身 只要他的next可以执行我们结果链表中的head即可ListNode head,*tail = &head,*aPtr = a,* bPtr = b;while(aPtr&&bPtr){if(aPtr->val < bPtr->val){tail->next = aPtr;aPtr = aPtr->next;}else{tail->next = bPtr;bPtr = bPtr->next;}tail = tail->next;}tail->next = (aPtr?aPtr:bPtr);return head.next;//这里head只是一个结构
}
1.使用顺序合并
class Solution{
public:ListNode* mergeKLists(vector<ListNode*>& lists){ListNode* ans = nullptr;//size_t是一种无符号整数类型,在C++中用于表示大小、索引或计数等非负值。//使用size_t来作为循环变量的类型是很自然的选择,//因为它与容器大小类型相匹配,能够避免类型不匹配等潜在问题。for(size_t i=0;i<lists.size();i++){ans = mergeTwoLists(ans,lists[i]);}return ans;}
}
方法2:使用分治合并的方法
该方法用作方法一的优化

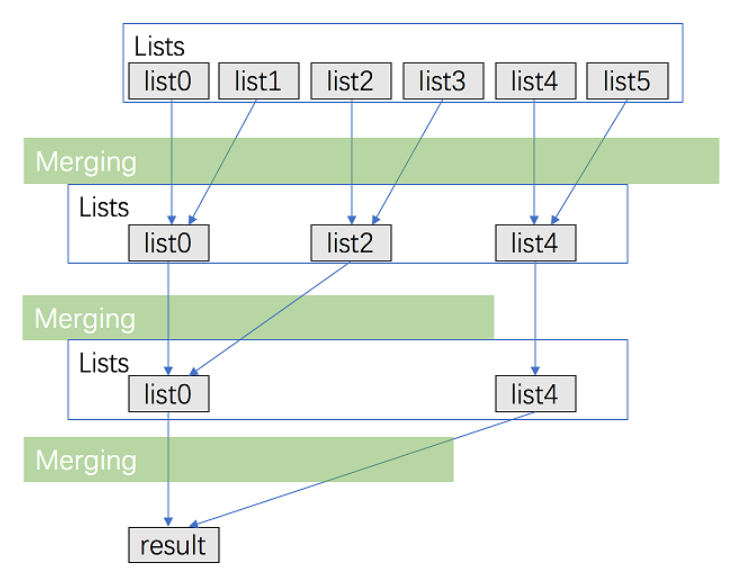
ListNode* merge(vector<ListNode*> &lists,int l,int r){if(l==r) return lists[l];if(l>r) return nullptr;int mid = (l+r)>>1; //就是除以2的意思return mergeTwoLists(merge(lists,l,mid),merge(lists,mid+1,r));
}
ListNode* mergeKLists(vector<ListNode*>& lists){return merge(lists,0,lists.size()-1);
}
LRU缓存


这道题使用哈希表和双向链表来进行实现:
使用哈希表来实现查询容器中是否存在某个值,而使用双向链表实现LRU的数据的添加和删除操作,比如对访问过的数据移至双向链表的头部 put操作也将新节点添加到头部,容量如果超过的话则对尾部元素删除操作
不过首先还是要先实现对双向链表的插入和删除操作,然后再调用进行头部尾部元素的操作,除此之外 双向链表在初始化时可以设置伪头结点和尾节点,方便对数据进行操作。
struct DLinkedNode{int key,value;DLinkedNode* prev;DLinkedNode* next;//定义了一个默认构造函数:将Key和Value初始化为0,将prev和next指针初始化为nullptrDLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr){}//定义了一个带参数的构造函数:// 接受_key和_value作为参数DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr){}};class LRUCache {
private:unordered_map<int,DLinkedNode*> cache;DLinkedNode* head;DLinkedNode* tail;int size;int capacity;public:LRUCache(int _capacity): capacity(_capacity), size(0) {//使用为头部和伪尾部节点head = new DLinkedNode();tail = new DLinkedNode();head->next = tail;tail->prev = head;}int get(int key) {if(!cache.count(key)){return -1;}//如果key存在,先通过哈希表定位,再移到头部DLinkedNode* node = cache[key];moveToHead(node);return node->value;}void put(int key, int value) {if(!cache.count(key)){//如果不存在key,创建一个新节点DLinkedNode* node = new DLinkedNode(key,value);//添加至双向链表的头部cache[key] = node;//添加至双向链表的头部addToHead(node);++size;if(size>capacity){//超出容量,删除双向链表中的尾部即节点DLinkedNode* removed = removeTail();// 删除哈希表中对应的项cache.erase(removed->key);//防止内存泄漏delete removed;--size;}}else{// 如果key存在,先通过哈希表定位再,修改value,并移到头部DLinkedNode* node = cache[key];node->value = value;moveToHead(node);}}void addToHead(DLinkedNode* node){node->prev = head;node->next = head->next;head->next->prev = node;head->next = node;}void removeNode(DLinkedNode* node){node->prev->next = node->next;node->next->prev = node->prev;}void moveToHead(DLinkedNode* node){removeNode(node);addToHead(node);}DLinkedNode* removeTail(){DLinkedNode* node = tail->prev;removeNode(node);return node;}
};/*** Your LRUCache object will be instantiated and called as such:* LRUCache* obj = new LRUCache(capacity);* int param_1 = obj->get(key);* obj->put(key,value);*/