SAM论文学习
SAM是首个面向图像分割的“基础模型”,通过提示工程实现任务泛化,为构建可组合的视觉系统(如结合检测+分割)提供了新范式。SA-1B数据集的开放将推动通用视觉模型的研究。
动机
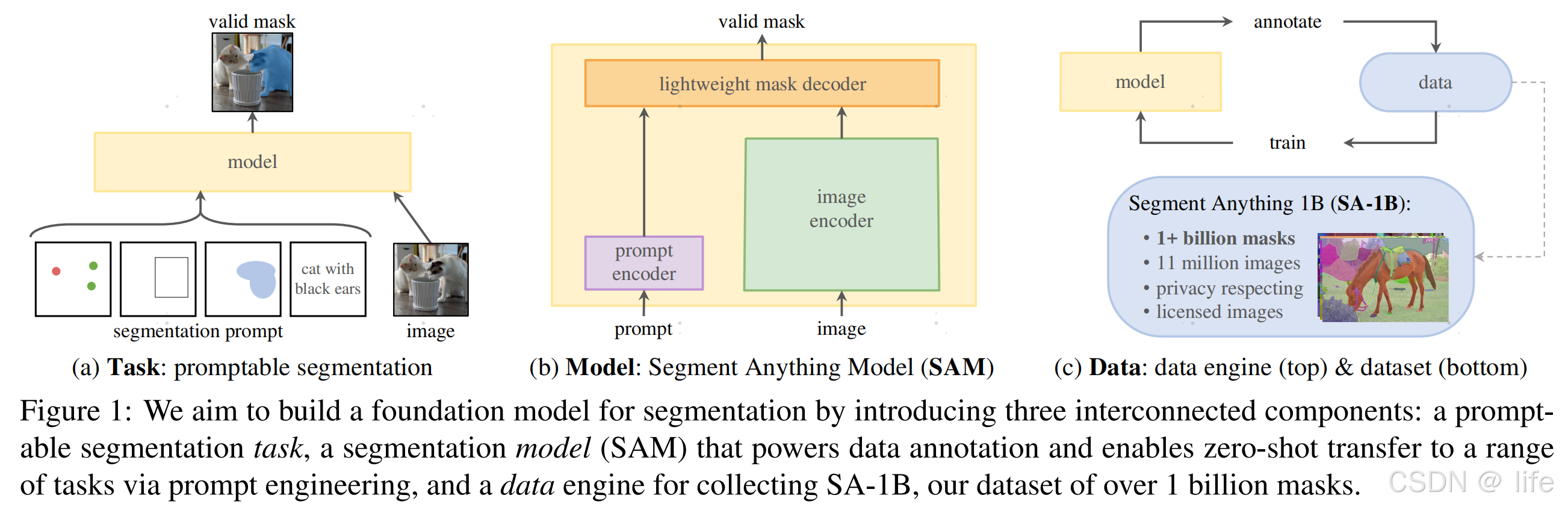
构建一个用于图像分割的基础模型,开发一个可提示的模型,并使用一种能够实现强大泛化能力的任务,在广泛的数据集上对其进行预训练。利用这个模型,旨在通过提示工程,解决一系列新数据分布上的下游分割问题。
针对这个动机,如果是你,会怎么思考这个问题的解决方式?作者问了自己3个问题:
- 什么任务能够实现零样本泛化?——可提示的分割任务,且具备足够的通用性
- 相应的模型架构是什么?——支持灵活提示方式,并且输出分割mask
- 哪些数据可以支撑这项任务和模型?——需要分割任务的大规模数据,但当前还没有(所以作者提出了“数据引擎”Data Engine)
定义
prompt
本文的一大核心是prompt,支持多种prompt作为输入,那么什么是prompt?
A prompt simply specifies what to segment in an image, e.g., a prompt can include spatial or text information identifying an object.
prompt指定图像中要分割的内容,可以包含待识别物体的空间或文本信息等。
ambiguity-aware
有时候提示是模糊的或不明确的,例如衬衫上的一个点可能表示衬衫、也可能表示穿着衬衫的人,此时模型也应该有一个合理的输出。
背景
图像分割是计算机视觉的核心任务,但传统方法面临两大挑战:
- 数据稀缺:现有分割数据集(如COCO、ADE20K)规模有限,且手动标注掩码耗时费力。
- 任务局限性:模型多为特定任务设计(如实例分割、边缘检测),缺乏通用性和零样本迁移能力。
受NLP中“基础模型”(如GPT)启发,本文旨在构建图像分割领域的基础模型,通过大规模数据和灵活提示机制实现通用分割能力。
解决的问题
- 大规模数据标注难题:传统方法无法高效生成海量高质量分割掩码。
- 模型通用性不足:现有模型难以通过简单提示适应不同分割任务(如点、框、文本驱动的分割)。
- 模糊性处理:单一提示可能对应多个合理掩码(如衬衫与穿衬衫的人),需模型支持多掩码预测。
创新与贡献
-
提出可提示分割任务:
- 定义通过任意提示(点、框、文本)生成有效掩码的任务,统一预训练目标与下游应用。
- 支持零样本迁移,例如结合目标检测框即可实现实例分割。
-
Segment Anything Model (SAM):
- 架构创新:
- 图像编码器:基于MAE预训练的ViT,提取图像嵌入。
- 提示编码器:支持点、框、文本等多模态提示。
- 轻量级掩码解码器:结合图像和提示嵌入,实时生成掩码(50ms/次)。
- 模糊性处理:预测多个掩码(如整体、部分、子部分),通过置信度排序选择最佳结果。
- 架构创新:
-
Segment Anything Dataset (SA-1B):
- 规模:11M图像、1.1B掩码,比最大现有数据集(Open Images)大400倍。
- 质量:通过三阶段数据引擎(人工辅助→半自动→全自动)确保多样性和精度,验证显示94%的自动掩码与人工修正掩码IoU>90%。
-
数据引擎(Data Engine):
- 人工辅助阶段:SAM辅助标注员快速标注(14秒/掩码,比COCO快6.5倍)。
- 半自动阶段:SAM生成部分掩码,标注员补充剩余对象。
- 全自动阶段:密集网格提示生成掩码,结合稳定性和非极大抑制(NMS)筛选高质量结果。
技术路线总结
- 任务定义:将分割任务转化为“输入提示→输出有效掩码”,兼容多种下游任务。
- 模型设计:
- 图像编码器提取全局特征,提示编码器嵌入点/框/文本,轻量解码器动态生成掩码。
- 通过多掩码预测和最小损失训练解决模糊性问题。
- 数据构建:
- 三阶段数据引擎逐步提升模型能力,最终实现全自动标注。
- 数据覆盖多样化场景,地理分布更均衡(非洲、亚洲等区域代表性提升)。
- 实验验证:
- 零样本性能:在23个数据集上,SAM单点提示的mIoU优于RITM等交互式分割模型。
- 下游任务:在边缘检测(BSDS500)、目标提议(LVIS)、实例分割(COCO)中表现接近或超越专用模型。
- 公平性:SAM在不同人群肤色、年龄、性别上的分割性能一致。
主要贡献详细介绍
task
model
data engine
包含11M图片、1.1Bmask的数据集SA-1B是怎么来的?如上分为三个阶段(1) 模型辅助人工标注阶段,(2) 半自动阶段,结合自动预测掩码和模型辅助标注,(3) 全自动阶段,在此阶段我们的模型无需标注人员输入即可生成掩码。
由于在实际应用中这种构建大规模数据方式有很好的参考意义,所以这里重点介绍一下。
模型辅助人工标注阶段
在这个阶段开始时,SAM 使用常见的公开分割数据集进行训练。经过充分的数据标注后,SAM 仅使用新标注的掩码进行重新训练。随着收集到更多的掩码,图像编码器从 ViT-B 扩展到 ViT-H,其他架构细节也有所演变;我们总共对模型进行了 6 次重新训练。随着模型的改进,每个掩码的平均标注时间从 34 秒减少到 14 秒。我们注意到,14 秒比 COCO 的掩码标注速度快 6.5 倍,仅比使用极值点的边界框标注速度慢 2 倍 。随着 SAM 的改进,每张图像的平均掩码数量从 20 个增加到 44 个。总体而言,我们在这个阶段从 12 万张图像中收集了 430 万个掩码。
半自动阶段
在这个阶段,我们旨在增加掩码的多样性,以提高模型对任意物体的分割能力。为了让标注人员专注于不太显著的物体,我们首先自动检测出置信度较高的掩码。然后,我们向标注人员展示预先填充了这些掩码的图像,并要求他们标注任何其他未标注的物体。为了检测置信度较高的掩码,我们使用通用的 “物体” 类别,在所有第一阶段的掩码上训练了一个边界框检测器 [84]。在这个阶段,我们在 18 万张图像中额外收集了 590 万个掩码(总共达到 1020 万个掩码)。与第一阶段一样,我们定期使用新收集的数据对模型进行重新训练(5 次)。由于这些物体的标注难度更大,每个掩码的平均标注时间回升至 34 秒(不包括自动生成的掩码)。每张图像的平均掩码数量从 44 个增加到 72 个(包括自动生成的掩码)。
全自动阶段
在最后阶段,标注完全是自动进行的。这之所以可行,得益于我们对模型的两项重大改进。首先,在这个阶段开始时,我们已经收集了足够多的掩码来大幅改进模型,其中包括前一阶段的各种不同掩码。其次,到这个阶段时,我们已经开发出了模糊感知模型,这使我们即使在模糊情况下也能预测有效的掩码。具体来说,我们用一个 32×32 的规则点网格来提示模型,并且针对每个点预测一组可能对应有效物体的掩码。借助模糊感知模型,如果一个点位于某个部分或子部分上,我们的模型将返回子部分、部分以及整个物体。
最后,在选择了置信度高且稳定的掩码后,我们应用非极大值抑制(NMS)来过滤重复项。为了进一步提高较小掩码的质量,我们还处理了多个重叠的放大图像裁剪区域。关于此阶段的更多详细信息,请参阅 §B。我们对数据集中的所有 1100 万张图像应用了全自动掩码生成,总共生成了 11 亿个高质量掩码。接下来我们将描述并分析由此产生的数据集 SA - 1B。