Mask-aware Pixel-Shuffle Down-Sampling (MPD) 下采样
来源
简介:这个代码实现了一个带有掩码感知的像素重排下采样模块,主要用于图像处理任务(如图像修复或分割)。
论文题目:HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attention
期刊:IEEE TRANSACTIONS ON MULTIMEDIA
源码介绍
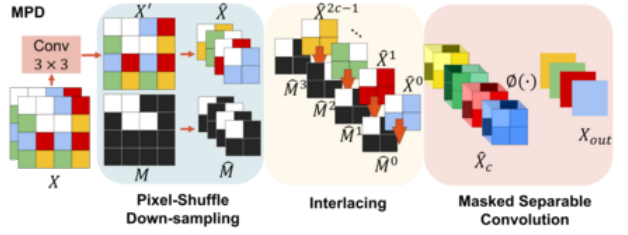
初始化部分
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelUnshuffle(2)
)self.body2 = nn.Sequential(nn.PixelUnshuffle(2)) self.proj = nn.Conv2d(n_feat * 4, n_feat * 2, kernel_size=3, stride=1, padding=1, groups=n_feat * 2, bias=False)-
body:
-
先是一个3x3卷积,将通道数从n_feat减半到n_feat//2
-
然后使用PixelUnshuffle(2)进行空间下采样(将H,W变为H/2,W/2,通道数变为4倍)
-
-
body2:
-
仅包含PixelUnshuffle(2),用于处理掩码(mask)
-
-
proj:
-
分组卷积(group convolution),用于将合并后的特征和掩码信息投影到目标维度
-
输入通道是n_feat4,输出通道是n_feat2
-
使用分组数等于输出通道数,这意味着这是一个深度可分离卷积
-
前向传播
def forward(self, x, mask):out = self.body(x) # 处理输入特征out_mask = self.body2(mask) # 处理掩码b,n,h,w = out.shapet = torch.zeros((b,2*n,h,w)).cuda()# 交错合并特征和掩码for i in range(n):t[:,2*i,:,:] = out[:,i,:,:]for i in range(n):if i <= 3:t[:,2*i+1,:,:] = out_mask[:,i,:,:]else:t[:,2*i+1,:,:] = out_mask[:,(i%4),:,:]return self.proj(t)-
首先分别处理输入特征x和掩码mask:
-
x经过卷积和像素重排
-
mask只经过像素重排
-
-
创建一个零张量t,其通道数是out的两倍
-
将out和out_mask的值交错放入t中:
-
偶数通道(2*i)放out的特征
-
奇数通道(2*i+1)放out_mask的值
-
对于mask通道数不足的情况(i>3),使用循环方式(i%4)填充
-
-
最后通过投影卷积proj得到输出
功能总结
这个模块实现了:
-
空间下采样(通过PixelUnshuffle)
-
通道数调整(通过卷积和投影)
-
将掩码信息与特征图信息交错融合
-
使用深度可分离卷积进行高效的特征变换
这种设计可能用于需要同时处理图像和掩码的任务,如图像修复、分割等,其中掩码信息可以指导特征的下采样过程。
即插即用代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MaskAwareDownsample(nn.Module):"""Mask-aware Pixel-Shuffle Down-Sampling (MPD) Module参数:n_feat (int): 输入特征通道数mask_channels (int): 掩码的通道数(默认为1)use_depthwise (bool): 是否使用深度可分离卷积(默认为True)"""def __init__(self, n_feat, mask_channels=1, use_depthwise=True):super(MaskAwareDownsample, self).__init__()self.n_feat = n_featself.mask_channels = mask_channels# 特征处理路径self.feature_path = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelUnshuffle(2) # (B, C//2, H, W) -> (B, C//2 * 4, H//2, W//2))# 掩码处理路径self.mask_path = nn.Sequential(nn.PixelUnshuffle(2) # (B, mask_channels, H, W) -> (B, mask_channels * 4, H//2, W//2))# 计算合并后的通道数merged_channels = (n_feat // 2) * 4 + mask_channels * 4# 投影层if use_depthwise:# 确保groups能整除输入通道数# 这里我们取groups为输出通道数(n_feat*2)和输入通道数的最大公约数groups = torch.gcd(torch.tensor(merged_channels), torch.tensor(n_feat * 2)).item()self.proj = nn.Conv2d(merged_channels,n_feat * 2,kernel_size=3,stride=1,padding=1,groups=groups,bias=False)else:self.proj = nn.Conv2d(merged_channels,n_feat * 2,kernel_size=3,stride=1,padding=1,bias=False)def forward(self, x, mask):"""前向传播参数:x (Tensor): 输入特征图, shape (B, C, H, W)mask (Tensor): 输入掩码, shape (B, mask_channels, H, W)返回:Tensor: 下采样后的特征图, shape (B, 2*C, H//2, W//2)"""# 处理特征feat = self.feature_path(x) # (B, C//2 * 4, H//2, W//2)# 处理掩码mask_feat = self.mask_path(mask) # (B, mask_channels * 4, H//2, W//2)# 合并特征和掩码out = torch.cat([feat, mask_feat], dim=1) # (B, C//2*4 + mask_channels*4, H//2, W//2)# 投影到目标维度return self.proj(out)if __name__ == "__main__":# 测试代码B, C, H, W = 2, 64, 128, 128mask_channels = 1# 创建模块实例mpd = MaskAwareDownsample(n_feat=C, mask_channels=mask_channels)# 创建测试输入x = torch.randn(B, C, H, W)mask = torch.randn(B, mask_channels, H, W)print(f"输入特征图尺寸: {x.shape}")print(f"输入掩码尺寸: {mask.shape}")# 前向传播out = mpd(x, mask)print(f"输出特征图尺寸: {out.shape}")# 验证尺寸是否正确assert out.shape == (B, 2 * C, H // 2, W // 2), "输出尺寸不正确!"print("测试通过!")输出的结果:
