RAGMCP基本原理说明和相关问题解惑
一、RAG架构原理和局限性
1.1 概念解释
RAG(Retrieval-Augmented Generation):检索增强生成,让大模型接受外部输入后,总结输出
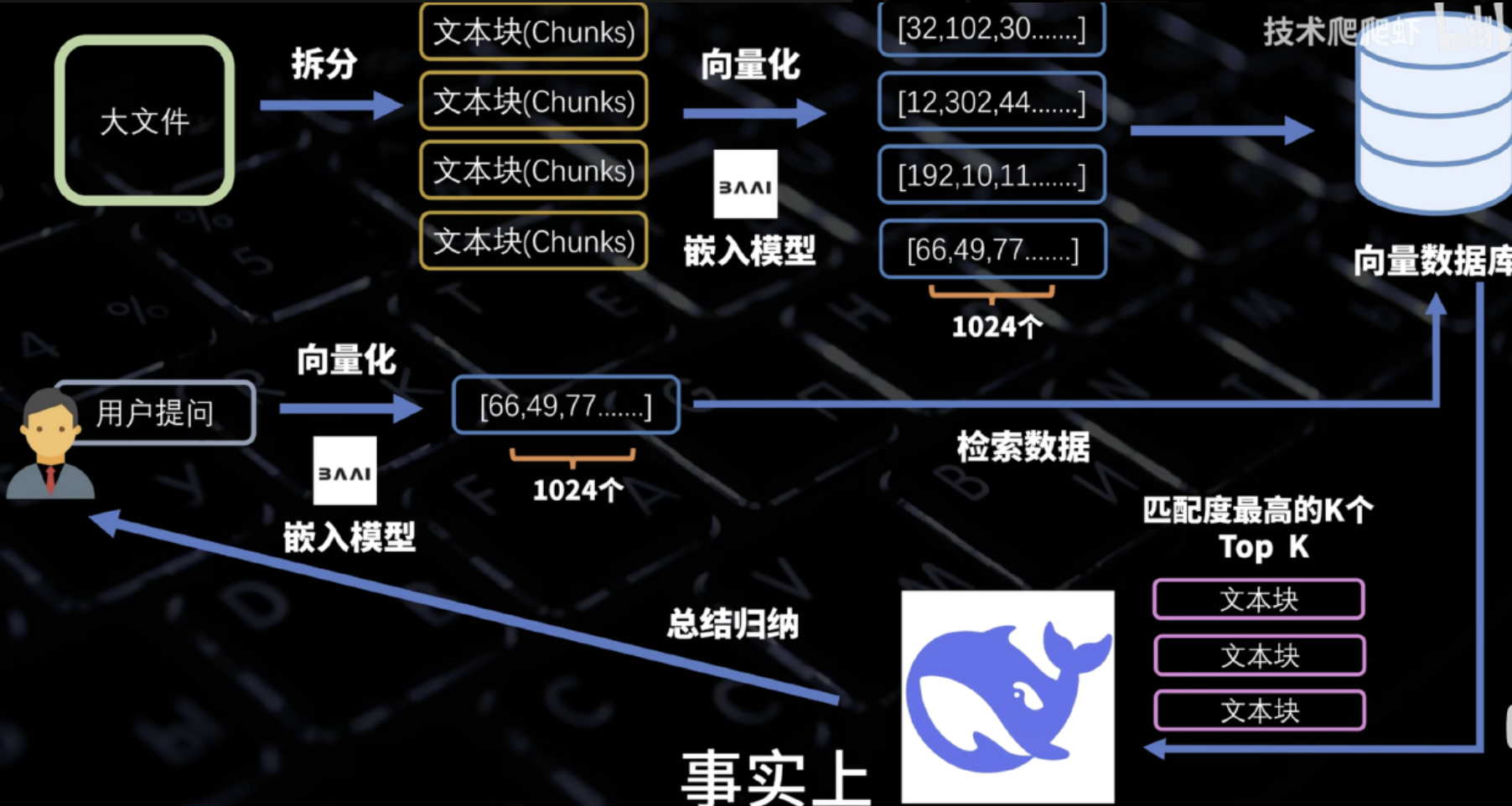
向量数据库:向量数据通常是高维空间中的点,代表复杂的数据结构,如文本、图像、音频等,传统数据库通常基于精确匹配或范围查询,而向量数据库则专注于相似性搜索。
Dify的向量数据库Weaviate:结合了图数据库和向量数据库的功能,支持语义搜索。
嵌入模型:Embedding模型,将文本块向量化嵌入向量数据库。
重排序模型:Rerank模型,重排序模型将根据候选文档列表与用户问题语义匹配度进行重新排序,改变相似的排序Top K
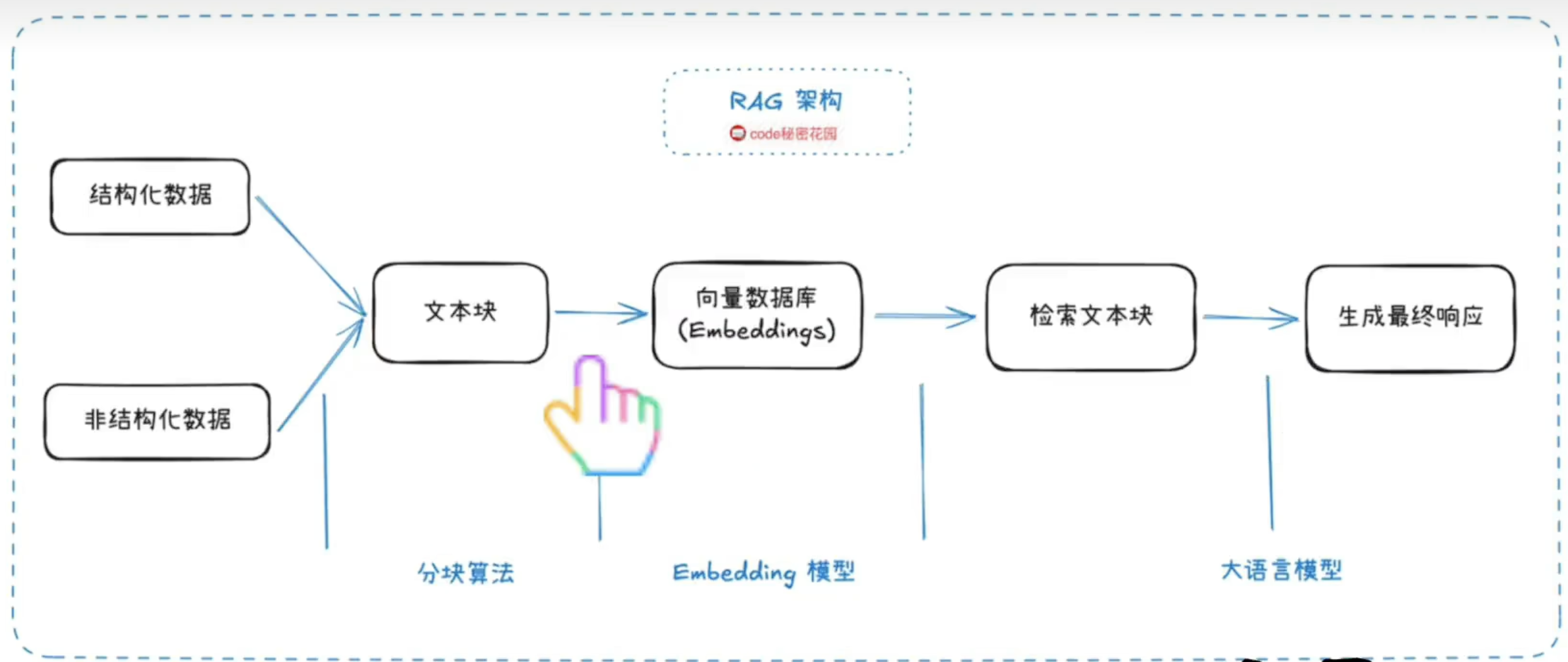
1.2 RAG架构原理
参考: 本地知识库痛点与进阶方案
1.3 RAG局限性
- 检索精度不足:RAG核心流程中,大模型仅仅起到了总结的作用,而检索到信息的精准度大部分取决于向量的相似度匹配,检索结果可能包含无关内容(低精确率)或遗漏关键信息(低召回率)。
- 切片很粗暴:切片的局部性注定了大模型无法看到整篇文档的信息,因此在回答列举XXX,总结XXX的时候回答是不完整的。故此不适合做结构化数据的统计,倒是适合做知识问答QA,智能客服这些。
- 没有大局观:RAG没办法判断要用多少个分块来回答问题,也无法判断文档间的联系。
微调和超大上下文模型?:这个能解决这个问题,相当于所有信息都抛给大模型,但是我每次想知道的新东西就要微调一下?微调成本很高,不然大家每天微调一下就好了,还要什么RAG。超大上下文模型,是能解决一部分问题,但是再大也有个上限,而且一次问答消耗的token数很高,也不现实。
二、MCP 的基础知识
2.1 Function Call
由openAI提出,提供大模型与外界系统交互的能力,主动调用预设的函数去获取外部数据。
但并没有想做成规范,导致各家大模型的Function Call的参数并不相同,使得服务方想提供调用就要给每个模型都做适配,成本很高
tips:所以之前有公司来做这种简化适配的事,比如dify的自定义工具功能,把swagger文档给dify制作成dify的工具,使dify上不同模型可以复用工具,不过问题是这个工具出了dify就没有用了,别家用不了。
模型想支持FunctionCall需要事先进行数据集的训练或微调才能稳定获得这种能力
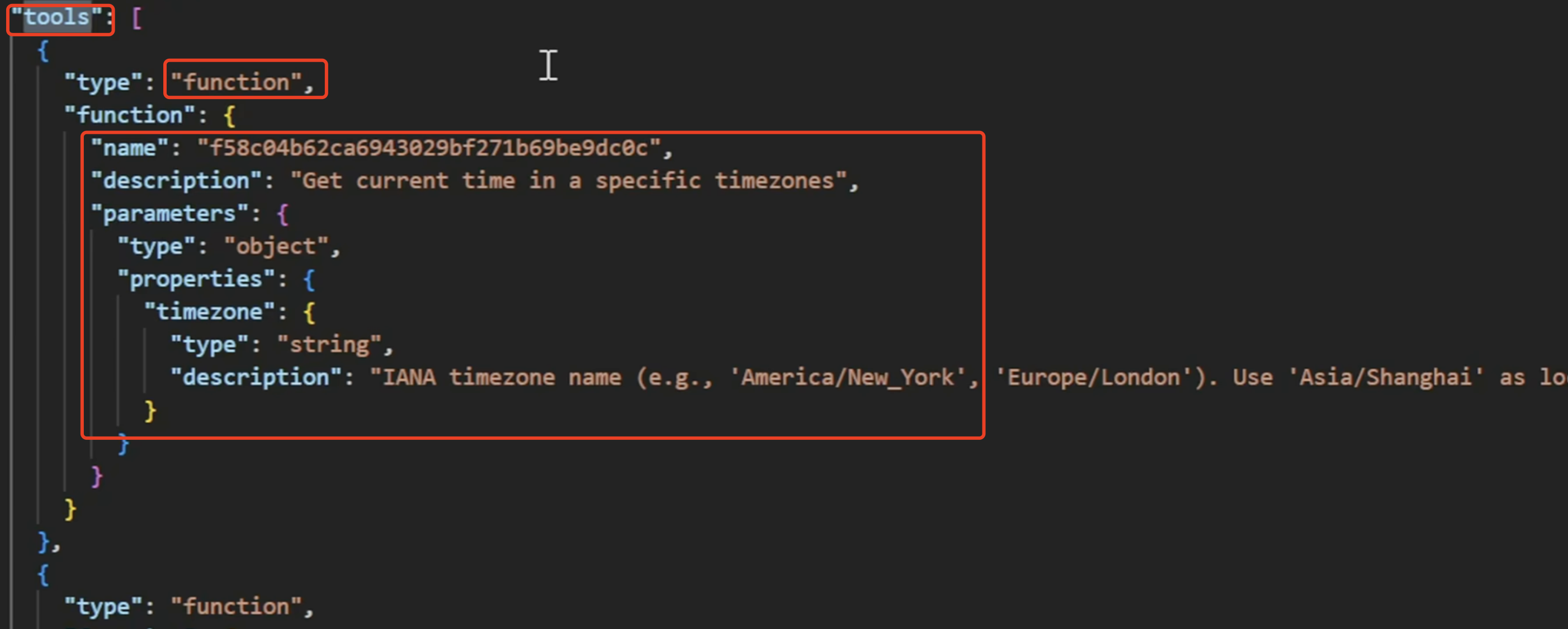
想使用FunctionCall功能需要在与模型对话的消息体中增加一个tools字段,来描述自己的工具,如图:
2.2 Model Context Protocol
Model Context Protocol(模型上下文协议),就是约好模型怎么传参数,服务怎么返回信息。本来其实也没人重视,但是随之越来越多公司支持它,导致它现在成为了一个业内标准,进而使更多的AI应用程序也支持了它。
概念:
- MCP Hosts:AI应用程序,如Cursor、Cline,其实就是内部支持了MCP Client
- MCP Client:专门调用MCP Server的
- MCP Server:轻量级程序,按协议公开特定功能,形态可以是个cli工具放在客户本地运行,也可以是个云服务远程访问。
大致分三类:
1.文件和数据访问类:让大模型能够操作、访问本地文件或数据库,如File System MCP Server
2.Web自动化类:让大模型能够操作浏览器
3.三方工具集成类:让大模型能够调用三方平台暴露的APl,如高德地图MCP Server,各家产品出的API封装,自己的openAPI可能比较复杂,这里简化,并且可能返回体都不一样,所以在这层去做大一统,预处理等等。
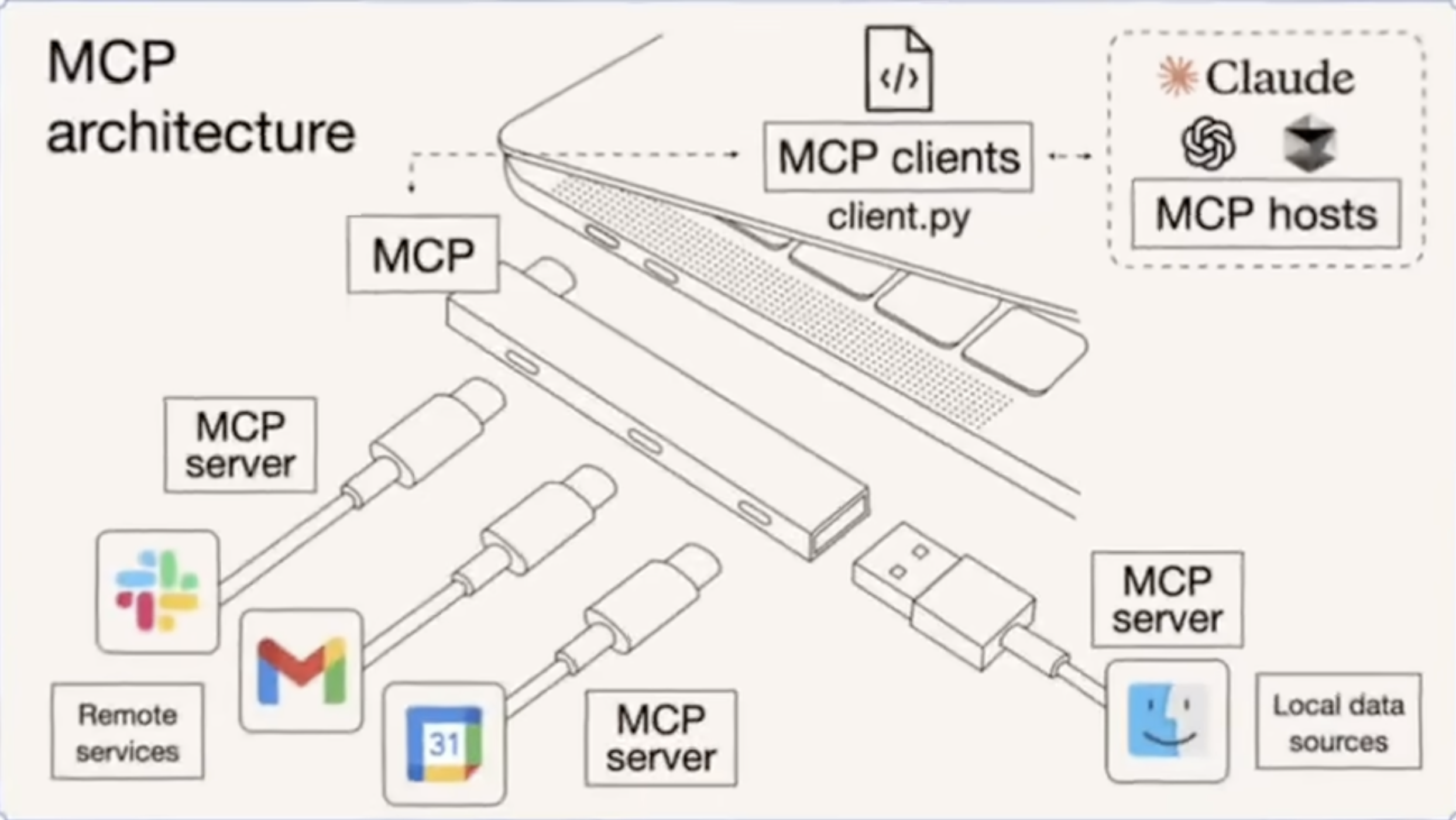
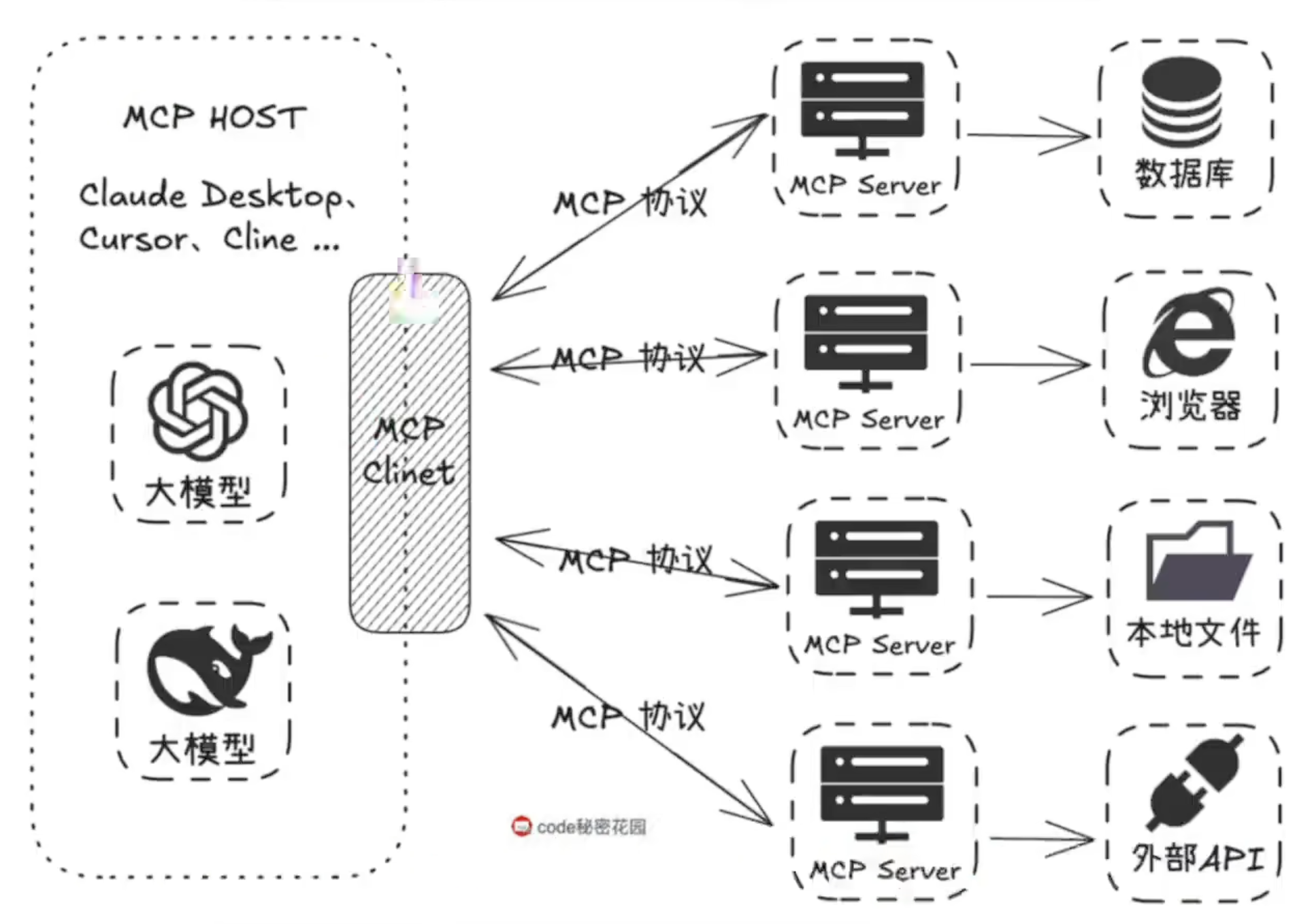
关系流程:
参考:https://zhuanlan.zhihu.com/p/1897306683727910356
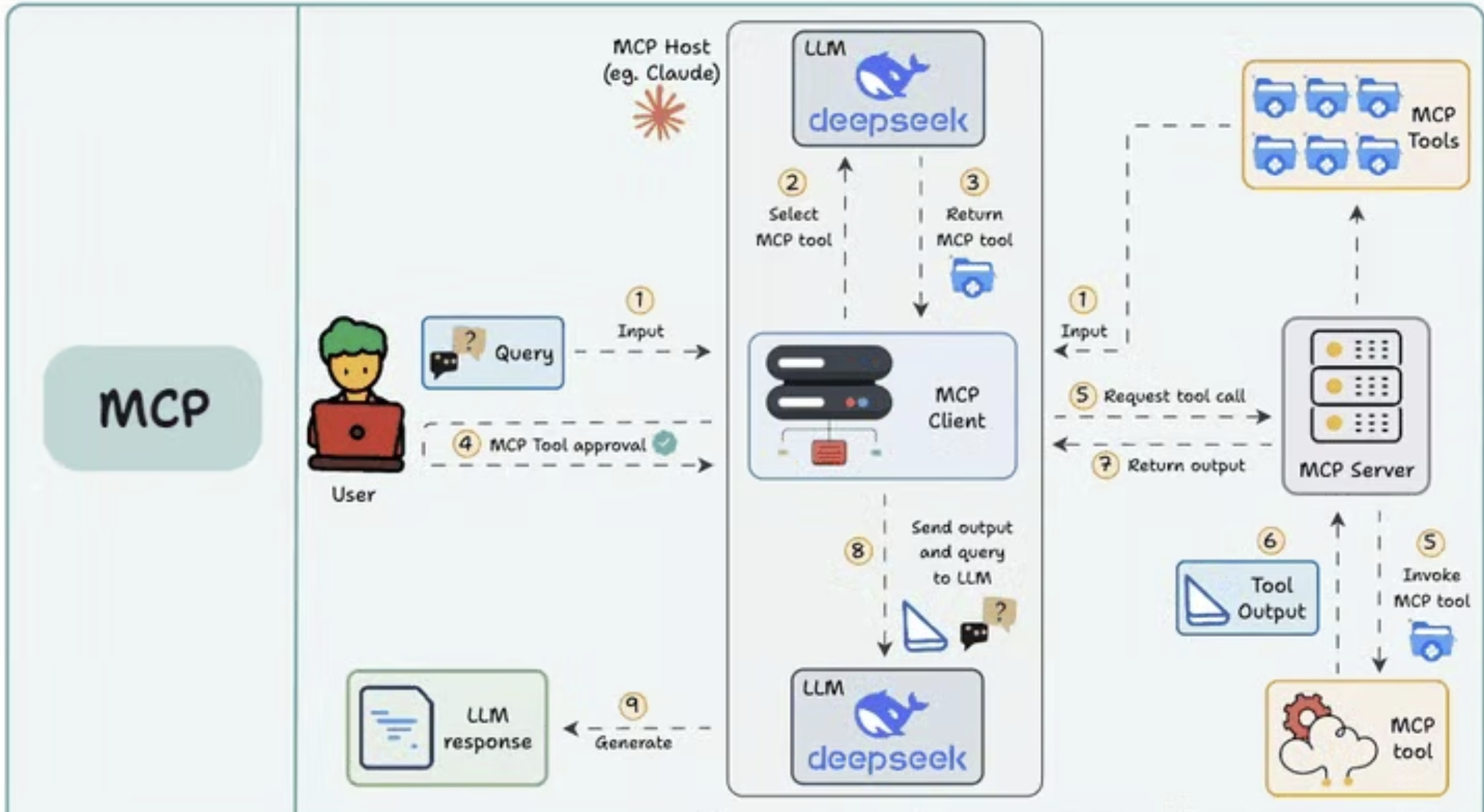
特点:
- 协议标准化:统一工具调用格式
- 生态兼容性:一次开发即可对接所有模型
- 动态扩展:新增工具无需修改模型代码,即插即用
价值/解决的问题:
- 数据孤岛 → 打通本地/云端数据源
- 重复开发 → 开发者只需适配MCP协议
- 生态割裂 → 形成统一工具市场
2.3 MCP 对比 Function Call
核心区别
| 对比维度 | Function Call | MCP |
|---|---|---|
| 标准化程度 | 由厂商自定义(如 OpenAI 的 JSON 格式) | 开放标准(遵循 JSON-RPC 2.0) |
| 交互方式 | 同步调用,直接嵌入模型运行时 | 异步通信,通过协议解耦 |
| 扩展性 | 受限于模型接口,新增功能需适配 | 即插即用,支持多数据源/工具动态接入 |
| 安全性 | 需在客户端处理敏感逻辑(如 API 密钥) | 服务端隔离敏感操作,提升安全性 |
适用场景
• Function Call 更适合:
✅ 简单、低延迟任务(如实时翻译、数学计算)
✅ 封闭生态内的功能扩展(如 OpenAI 生态的专属 API 调用)
• MCP 更适合:
✅ 复杂任务协作(如跨平台数据整合、多步骤流程)
✅ 企业级系统集成(如 CRM、ERP 对接,需统一协议)
✅ 高安全性需求场景(如医疗、金融数据隔离)
三、MCP Server如何开发
- 可以使用任意语言编写
- 两种模式:stdio、sse即本地cli命令行工具或提供sse服务
示例:
其实就是写一些方法函数,接受入参处理后返回,代码可以是一个cli工具,也可以监听一个端口
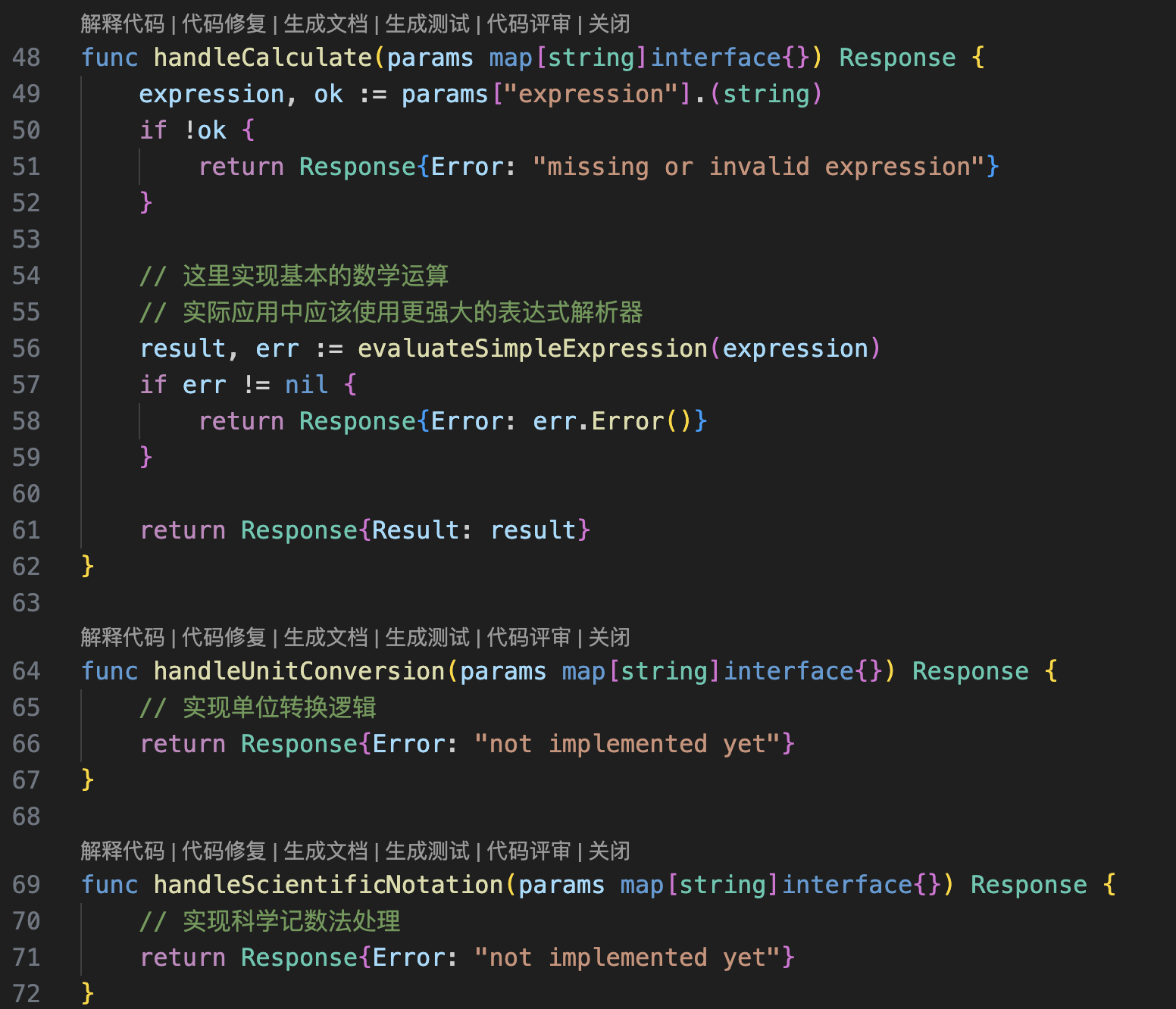
详细的可以看一个天气的MCP-Server是怎么写的:
https://github.com/MrCare/mcp_tool/blob/main/src/weather_server/server.py
四、Q&A
4.1 MCP Client 调用本地/其它工具的方式?
MCP Client 通过获取工具列表和工具描述,由大模型确定使用哪个工具并组合入参。如下:
- 工具列表获取:MCP Client 从本地或远程获取可用的工具列表,每个工具都有详细的描述信息。
- 工具选择:大模型根据任务需求和分析工具描述,选择最合适的工具。
- 参数组合:大模型根据任务需求,组合生成调用工具所需的参数。
4.2 MCP Client 与 Server 的通信方式?
MCP Client 与 Server 的通信主要通过以下两种方式实现:
- 本地 CLI 调用:MCP Client 通过本地命令行接口 (CLI) 直接调用 MCP Server。
- SSE 长连接:MCP Client 与 MCP Server 之间建立 Server-Sent Events (SSE) 长连接,实现实时通信。
4.3 MCP Server 的实现方式?
MCP Server 的实现遵循规范要求,可以使用以下两种方式:
- 标准输入输出 (stdio):MCP Server 通过标准输入输出与外部工具或服务进行交互。
- SSE 工具:MCP Server 支持 SSE 协议,实现与客户端的实时通信。
MCP Server 可以本地cli工具,也可以作为云服务提供接口访问。
4.4 MCP Server 的调用方式?
MCP Server 的调用由 MCP Client 发起
- 请求发送:MCP Client 向 MCP Server 发送请求,请求中包含任务描述和所需工具。
- 任务处理:MCP Server 根据请求内容,调用相应的工具或服务进行处理。
- 结果返回:MCP Server 将处理结果返回给 MCP Client,完成整个调用流程。
4.5 MCP依赖FunctionCall吗?
可依赖可不依赖,两种东西不冲突。
DeepseekR1不支持FunctionCall,但是可以调用MCP,原理是和AI应用程序的实现方式有关,比如cline插件是将MCP的工具信息写到系统提示词中,所以只要模型够聪明就可以调用,而5ire则是将工具信息写到模型交互的tools字段中,也就是依赖了模型的FunctionCall能力
4.5 为什么有FunctionCall了还要MCP?
FunctionCall扩展性不好,没有形成标准,各家都有自己的规范,开发者需要为不同模型适配不同代码,以往智能考dify或扣子这样的应用程序实现一个工具多个模型使用,但是脱离dify就又不能用了。MCP实现大一统,开发者开发一次,模型和AI应用程序也按规范支持,使得大家都能共用
五、MCP 的基本使用
5.1 环境准备
- 如果使用的MCP Server启动命令是npx,证明是js写的MCP Server则需要node环境和npx命令。
- 如果是uv或uvx则证明是python写的,那就需要安装uv。uv是新的python包管理工具,可以理解成pip升级版。
未验证:用golang写完交叉编译后,不需要安装任何环境
5.2 在 Cherry Studio 中使用 MCP
Cherry Studio 是一个支持 MCP 的AI聊天软件,小白友好,因为mcp需要安装一下环境,这个软件可以在界面上操作安装。
但是需要自己有模型的api token
具体操作网上很多,就是下载软件后点点点。
5.3 在VS Code+Cline插件使用MCP
也需要自己有模型的api token,没办法白嫖。
这个是使用教程最多的,因为Cline开源免费。
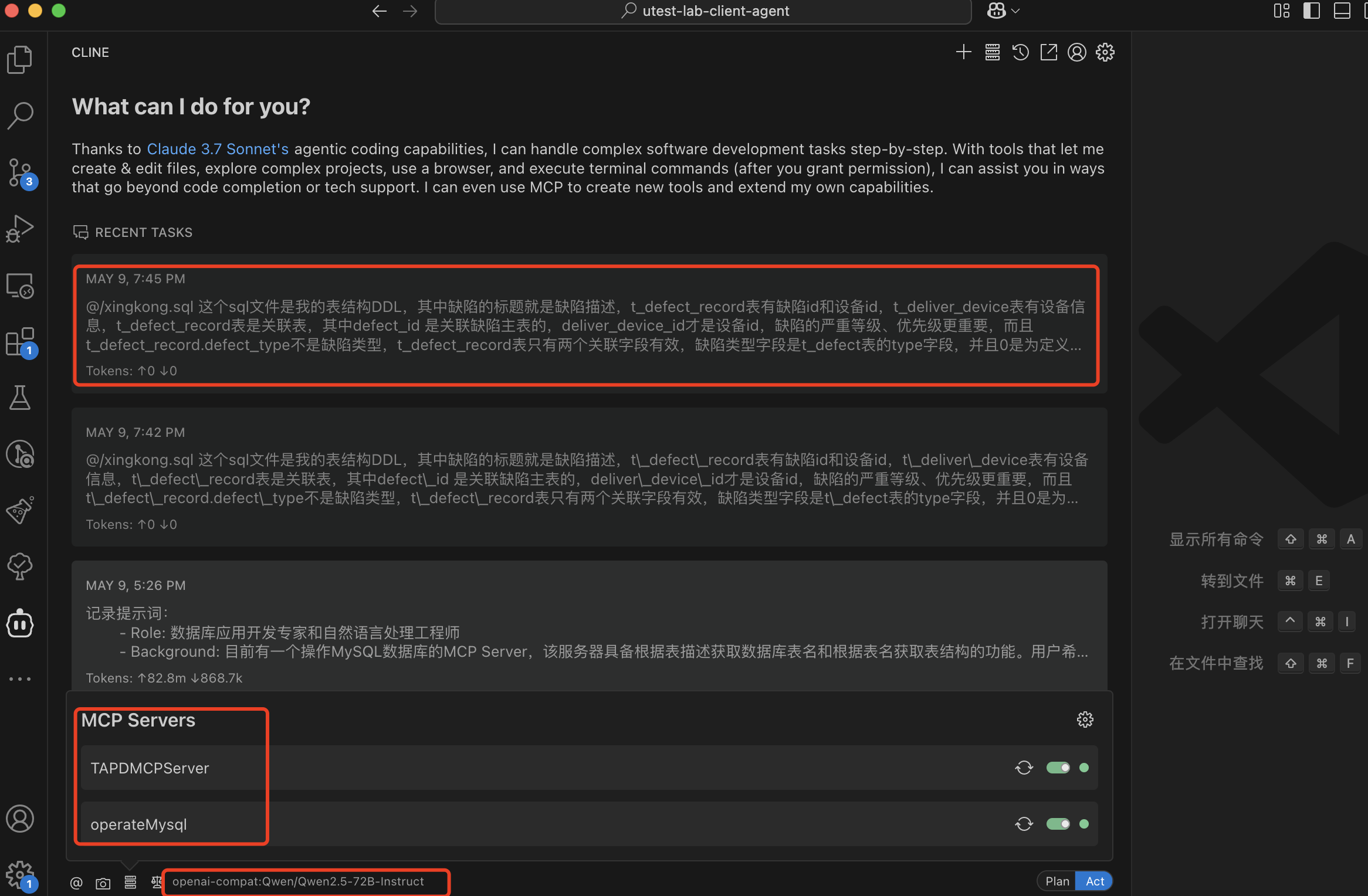
5.4 在VS Code + 腾讯云CodeBuddy使用MCP(推荐,免费)
不需要api token,可以使用免费的hunyuan或者Deepseek,全都免费。
六、实践:使用 MCP 调用MySQL数据库
6.1 VsCode + 腾讯云CodeBuddy
插件中搜索‘腾讯云代码助手’,如果用cline,就搜cline
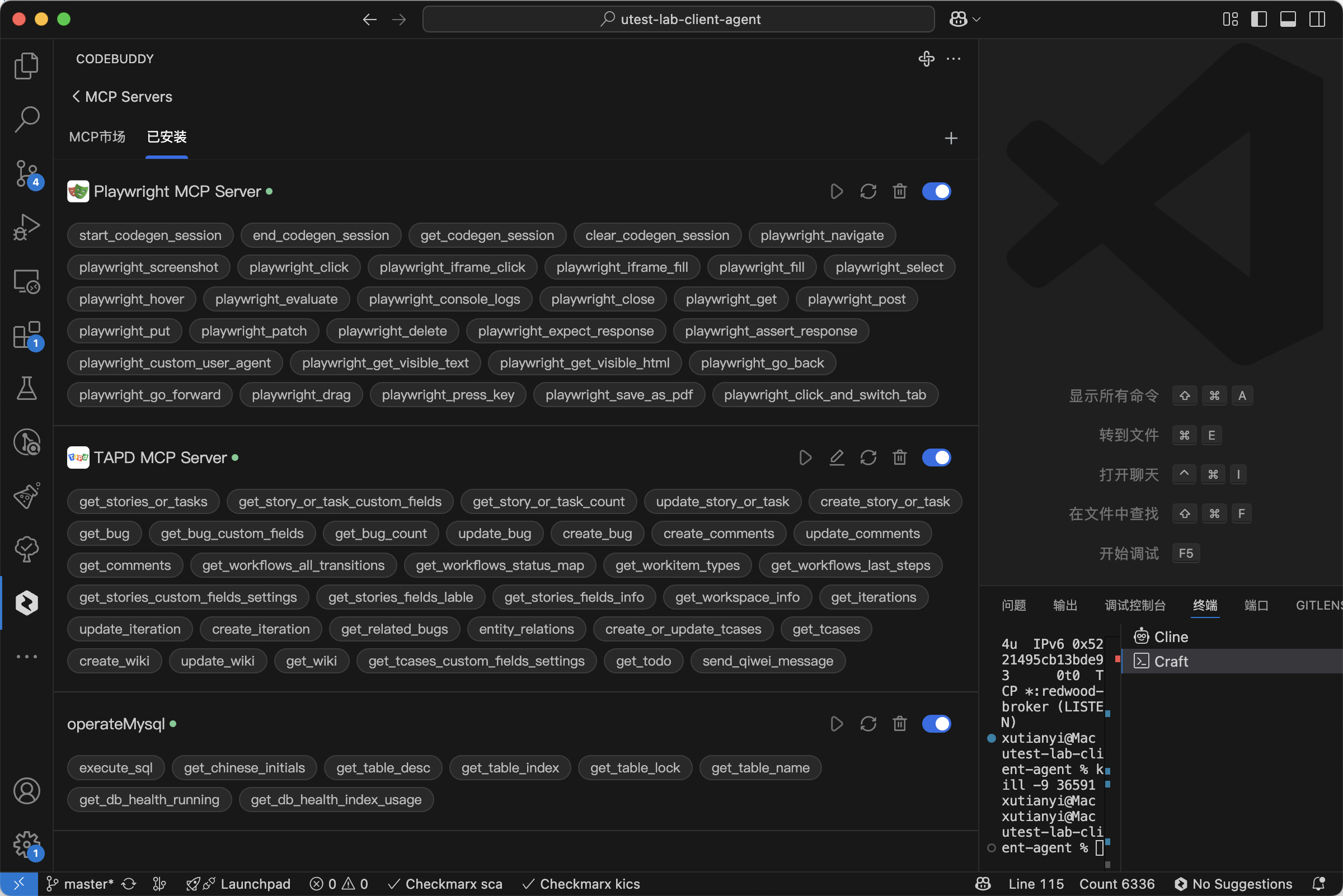
6.2 在 CodeBuddy 中配置 mysql_mcp_server
- 找到MySql的MCP Server
如:mysql_mcp_server_pro
https://github.com/wenb1n-dev/mysql_mcp_server_pro
以下直接参考仓库的readme配置,下面是我的配置方式:
- 安装环境:uv/npx
安装uv:
brew install uv
# OR
curl -LsSf https://astral.sh/uv/install.sh | sh
# OR
打开PowerShell,执行:
irm https://astral.sh/uv/install.ps1 | iex
- 配置Setting
{"mcpServers": {"operateMysql": {"name": "operateMysql","description": "","isActive": true,"url": "http://localhost:9000/sse",}}
}
6.3 基础 Prompt 优化查询效果
在系统提示词中将数据库的表结构加进去,并且告诉大模型他们的关系关联性等等。
6.4 MCP+DB检索效果
实操
6.5 目前的局限性
- 切忌让A!检索过大的数据,因为这种方式不像RAG,每次只检索一小部分需要的内容,它是真正的会执行SQL,你要多少数据,就查多少数据,如果一次查询数据量过大,会消耗大量Token,甚至让MCP客户端卡死
- 很多MCP客户端是依靠大量系统提示词来实现与MCP工具的通信,所以一旦使用MCP,Token的消耗量一定会大幅增长