【深度学习|学习笔记】广义线性模型Generalized linear model(GLM)模型详解,附代码。
【深度学习|学习笔记】广义线性模型Generalized linear model(GLM)模型详解,附代码。
【深度学习|学习笔记】广义线性模型Generalized linear model(GLM)模型详解,附代码。
文章目录
- 【深度学习|学习笔记】广义线性模型Generalized linear model(GLM)模型详解,附代码。
- 前言
- 1 起源与发展
- 2 模型原理
- 2.1 三要素框架
- 2.2 参数估计:IRLS 与 Fisher 得分
- 2.3 方差函数与分布族
- 3 应用领域
- 4 Python 实现示例
- 4.1 statsmodels 中的 GLM
- 4.2 scikit-learn 中的 Logistic 回归
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957966
前言
本文先给出对广义线性模型(GLM)关键内容的综合概述,然后分四大部分详细展开:起源与发展、模型原理、应用领域,以及 Python 实现示例。
- 广义线性模型(GLM)由 John Nelder 和 Robert Wedderburn 于 1972 年提出,统一了线性回归、逻辑回归、泊松回归等模型,通过“指数族分布+链接函数+线性预测”框架,实现对各类非正态响应变量的回归分析。
- GLM 的核心算法是迭代重加权最小二乘(IRLS)或等价的Fisher 得分方法,广泛应用于生物统计、经济学、风险管理、生态学等领域。
- Python 中可通过 statsmodels 和 scikit-learn 等库方便地构建和评估 GLM。
1 起源与发展
- 早在 20 世纪 50–60 年代,统计学家已认识到将非正态响应纳入回归分析的必要性;Kolmogorov–Arnold 表示定理表明任意连续函数可分解为单变量函数之和,但其构造难用。
- 1972 年,Nelder 和 Wedderburn 在《Journal of the Royal Statistical Society》上正式提出 GLM 框架,展示了如何用最大似然与 IRLS 方法估计包括线性回归、Logit、Poisson 等在内的一大类回归模型参数,从而实现模型的“统一”。
- 1974 年,Wedderburn 等人进一步在约束条件、准似然(quasi-likelihood)等方面拓展了 GLM 的理论与应用,奠定了后续各种分布族与方差函数的统计推断基础。
- 到 1989 年,McCullagh 与 Nelder 在其经典专著《Generalized Linear Models》中系统化了 GLM 理论、算法与实现细节,使其成为统计学与机器学习课程的标配。
- 90 年代后期至今,各种准则(如 AIC、BIC)、正则化(ridge、lasso)、广义估计方程(GEE)与混合效应扩展(GLMM)相继出现,极大丰富了 GLM 的实践与理论深度。
2 模型原理
2.1 三要素框架
GLM 由三部分组成:
- 随机成分(Random Component):响应变量 Y Y Y 服从指数族分布(如高斯、二项、泊松、Gamma 等)。
- 系统成分(Systematic Component):线性预测子 η = X β η=Xβ η=Xβ,其中 X X X 为设计矩阵, β β β 为待估参数。
- 链接函数(Link Function):将条件期望 μ = E [ Y ∣ X ] μ=E[Y∣X] μ=E[Y∣X] 与线性预测子连接:
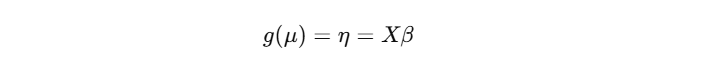
常见链接包括身份(identity)、对数(log)、logit 等。
2.2 参数估计:IRLS 与 Fisher 得分
- 对数似然 ℓ ( β ) ℓ(β) ℓ(β) 关于 β β β 求导得到得分函数 u ( β ) u(β) u(β),用牛顿–拉夫森或 Fisher 得分迭代:
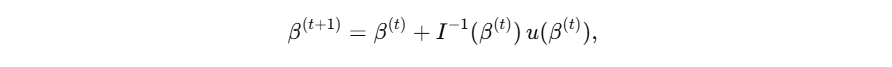
其中 I ( β ) I(β) I(β) 为 Fisher 信息矩阵。 - 等价地,IRLS 将每一步视为对加权最小二乘问题求解,权重由当前 μ μ μ 和方差函数决定,直到收敛。
2.3 方差函数与分布族
指数族分布的一般形式决定了 GLM 中的方差函数 V ( μ ) V(μ) V(μ):
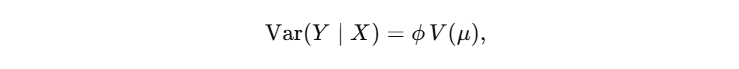
例如:
- 高斯: V ( μ ) = 1 V(μ)=1 V(μ)=1;
- 泊松: V ( μ ) = μ V(μ)=μ V(μ)=μ;
- 二项: V ( μ ) = μ ( 1 − μ ) V(μ)=μ(1−μ) V(μ)=μ(1−μ);
- Gamma: V ( μ ) = μ 2 V(μ)=μ^2 V(μ)=μ2。
3 应用领域
GLM 因其灵活性与可解释性,在各领域广泛应用:
- 生物统计与医学:Logistic 回归分析病例对照研究中风险因素与疾病的关联;Poisson 回归建模不良事件发生率。
- 生态学:用 Poisson/负二项 GLM 研究物种分布与环境因子的非线性关系。
- 金融与风险管理:信用评分模型(logit GLM)、保险索赔频率(Tweedie 分布 GLM)等。
- 社会科学与经济学:评估教育、收入等因素对行为概率的影响;Gamma GLM 用于建模消费支出等正偏分布。
- 工业与制造:故障率分析、寿命数据建模(Weibull/Gamma GLM)。
4 Python 实现示例
下面用 statsmodels 和 scikit-learn 两个库分别演示 GLM 的典型回归。
4.1 statsmodels 中的 GLM
import statsmodels.api as sm
import numpy as np
from sklearn.datasets import load_iris# 用 Iris 数据预测花瓣长度(连续)→ Gaussian GLM
iris = load_iris()
X = sm.add_constant(iris.data[:, :2]) # sepal length & width + intercept
y = iris.data[:, 2] # petal lengthmodel = sm.GLM(y, X, family=sm.families.Gaussian()) # 高斯 GLM(identity link)
result = model.fit() # IRLS 拟合
print(result.summary()) # 输出模型摘要​:contentReference[oaicite:12]{index=12}# 用同数据演示 Poisson 回归(count 模拟)
y_count = np.round(iris.data[:, 2]).astype(int)
pois = sm.GLM(y_count, X, family=sm.families.Poisson()) # 泊松 GLM(log link)
res2 = pois.fit()
print(res2.summary()) # 泊松回归结果​:contentReference[oaicite:13]{index=13}4.2 scikit-learn 中的 Logistic 回归
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split# 二分类示例→Logistic GLM(logit link)
data = load_breast_cancer()
Xtr, Xte, ytr, yte = train_test_split(data.data, data.target, test_size=0.3, random_state=0)clf = LogisticRegression(max_iter=1000).fit(Xtr, ytr)
print("Test accuracy:", clf.score(Xte, yte)) # 准确率​:contentReference[oaicite:14]{index=14}以上内容系统地回顾了 GLM 的起源与发展、理论框架、主要应用,以及 Python 中的两种典型实现,帮助在科研与工程实践中灵活运用广义线性模型。