Day21打卡—常见降维算法
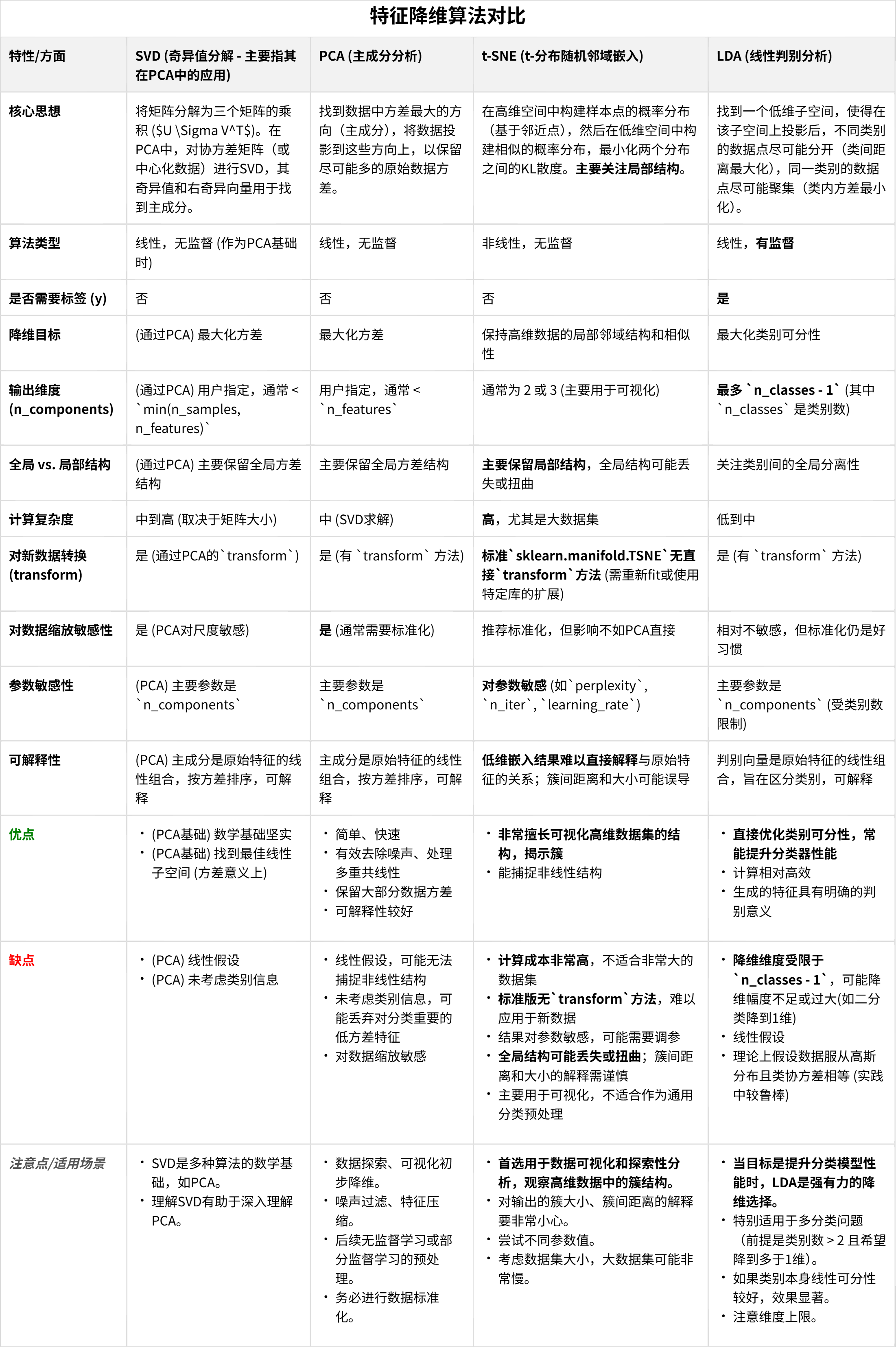
知识点回顾:
- LDA线性判别
- PCA主成分分析
- t-sne降维
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
(一)降维的应用场景和主要用途
何时使用降维?
-
高维数据可视化:当数据维度超过3维时,难以直接可视化,降维可将其映射到2D/3D。
-
特征冗余或噪声:数据中存在高度相关或冗余特征时,降维可提取关键信息。
-
模型训练加速:降低计算复杂度(如SVM、神经网络在高维数据中计算成本高)。
-
避免维度灾难:特征数接近样本量时,模型容易过拟合,降维可缓解。
主要应用领域
-
图像处理:将像素特征压缩(如人脸识别中的特征提取)。
-
自然语言处理:词向量降维(如Word2Vec的300维降到2D)。
-
生物信息学:基因表达数据分析。
-
推荐系统:用户-物品矩阵的稀疏性处理。
总结:降维方法的选择:
- 需要可视化或保留局部结构 → t-SNE,常被用于探索性数据分析和可视化任务
-
需要快速预处理或保留全局方差 → PCA。
-
有标签数据且需分类优化 → LDA
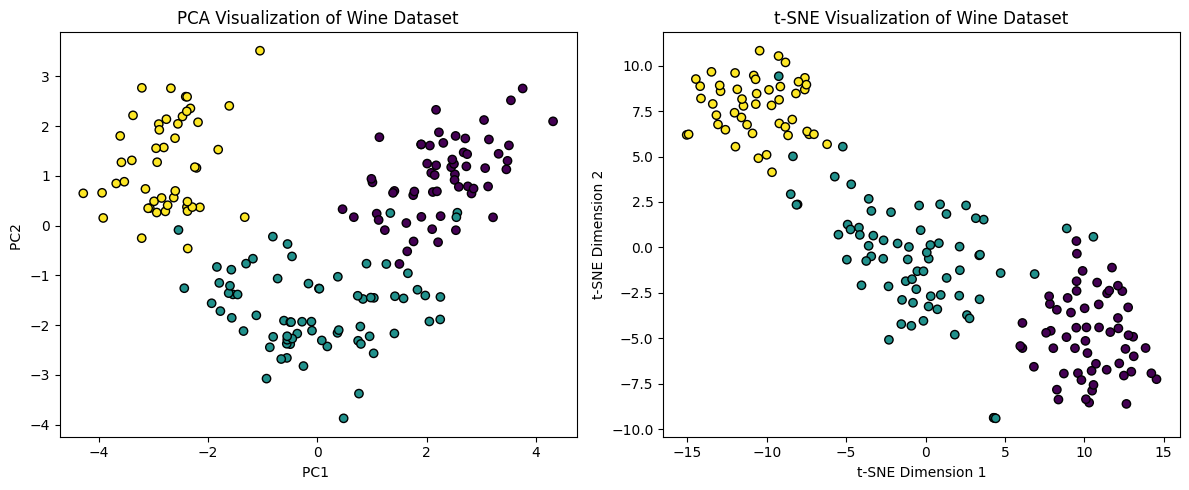
(二)在某些特定数据集上t-sne的可视化和pca可视化的区别
-
MNIST数据集:
-
PCA:全局结构保留,但不同数字可能重叠。
-
t-SNE:局部簇更清晰,不同数字分离明显。
-
-
环形/流形数据:
-
PCA:可能将环形数据压扁成线性分布。
-
t-SNE:能保留环形或非线性结构。
-
(三)应用
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler# 加载葡萄酒数据集(13维特征,3个类别)
data = load_wine()
X = data.data
y = data.target# 数据标准化(t-SNE对尺度敏感)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# PCA降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# t-SNE降维(设置random_state保证结果可复现)
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne = tsne.fit_transform(X_scaled)# 可视化对比
plt.figure(figsize=(12, 5))# PCA可视化
plt.subplot(1, 2, 1)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title('PCA Visualization of Wine Dataset')
plt.xlabel('PC1 ')
plt.ylabel('PC2 ')# t-SNE可视化
plt.subplot(1, 2, 2)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title('t-SNE Visualization of Wine Dataset')
plt.xlabel('t-SNE Dimension 1')
plt.ylabel('t-SNE Dimension 2')plt.tight_layout()
plt.show()结果:
@浙大疏锦行