小土堆pytorch--torchvision中的数据集的使用dataloader的使用
torchvision中的数据集的使用&dataloader的使用
- 一级目录
- 二级目录
- 三级目录
- 1 torchvision 中的数据集的使用
- 1.1 对与CIFAR - 10数据集的介绍
- 1.2 数据集加载代码
- 1.3 使用transform加载代码
- 2 DataLoader的使用
- 2.1 DataLoader的作用
- 1. 数据读取
- 2. 数据预处理
- 3. 批量处理
- 4. 并行加载
- 5. 数据打乱
- 6. 数据持久化(部分场景 )
- 7. 提供迭代器接口
- 2.2 常用参数讲解
- 2.3 代码
一级目录
二级目录
三级目录
1 torchvision 中的数据集的使用
1.1 对与CIFAR - 10数据集的介绍
数据规模:
总样本数:60,000 张彩色图像
训练集:50,000 张(每个类别 5,000 张)
测试集:10,000 张(每个类别 1,000 张)
图像尺寸:32×32 像素,RGB 三通道
类别:共 10 个互斥类别,涵盖常见物体:
0: 飞机 (airplane)
1: 汽车 (automobile)
2: 鸟类 (bird)
3: 猫 (cat)
4: 鹿 (deer)
5: 狗 (dog)
6: 青蛙 (frog)
7: 马 (horse)
8: 船 (ship)
9: 卡车 (truck)
数据特点
小尺寸图像:32×32 的低分辨率使得模型训练相对高效,适合快速验证算法。
多类别分类:10 个类别覆盖不同物体,挑战性适中,适合初学者入门。
平衡性:每个类别样本数量相等,避免类别不平衡问题。
现实场景:图像来自真实世界,但经过裁剪和简化,降低了背景复杂度。
典型应用
图像分类模型评估:如卷积神经网络(CNN)、Transformer 等架构的基础测试。
算法对比:研究人员常用 CIFAR - 10 比较不同模型的性能(如 ResNet、VGG 等)。
教学与实践:高校和在线课程中常用作深度学习入门案例。
模型预训练:部分研究将 CIFAR - 10 作为预训练任务,迁移到更复杂的任务中。
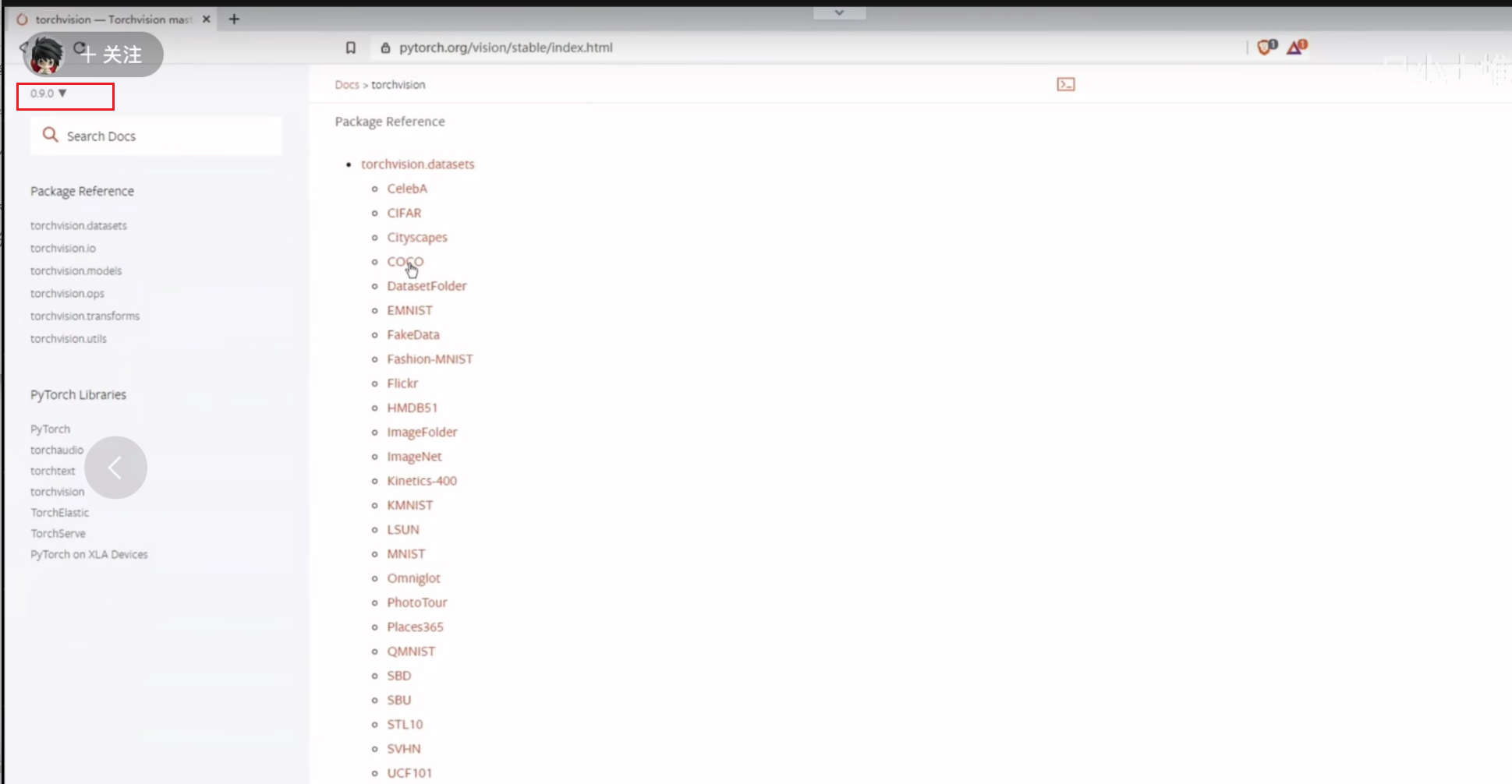
可以从pytorch官网下载所需数据集,注意要保持与图片中的版本相同(在左上角)
1.2 数据集加载代码
import torchvision
from torch.utils.tensorboard import SummaryWriter# dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./das", train = True, download = True)
test_set = torchvision.datasets.CIFAR10(root="./das", train=False, download = True)print(test_set[0])
代码功能讲解
torchvision.datasets.CIFAR10(root="./das", train = True, download = True)

各个参数的作用
在torchvision.datasets.CIFAR10这行代码中各个参数的作用:
root- 作用:指定数据集下载后存储的根目录路径 。代码中
root='./das',表示将CIFAR - 10数据集存储在当前目录下名为das的文件夹中。若该文件夹不存在,会自动创建。 - 示例:若希望存储在
/data/cifar10目录,则可设置root='/data/cifar10'。
- 作用:指定数据集下载后存储的根目录路径 。代码中
train- 作用:用于区分加载训练集还是测试集。当
train = True时,加载的是CIFAR - 10数据集中的训练集(包含50000张图像 );当train = False时,加载的是测试集(包含10000张图像 )。 - 示例:若要加载测试集,可写成
test_set = torchvision.datasets.CIFAR10(root='./das', train = False)。
- 作用:用于区分加载训练集还是测试集。当
transform- 作用:对加载的图像进行一系列预处理操作 。可使用
torchvision.transforms中的各种变换函数,如将图像转换为张量(ToTensor)、归一化(Normalize)等。代码中未完整展示该参数的使用,若要对图像进行预处理,可像这样设置:transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),先把图像转成张量,再进行归一化。 - 示例:在实际应用中,常通过该参数对图像进行标准化处理,以提升模型训练效果。
- 作用:对加载的图像进行一系列预处理操作 。可使用
target_transform- 作用:对图像对应的标签(类别)进行转换操作 。例如,可以将标签从数值型转换为独热编码形式等。在一般图像分类任务中,如果不需要对标签做特殊处理,该参数可不设置。
- 示例:若要将标签转换为独热编码,可自定义一个转换函数传入该参数。
download- 作用:是一个布尔值,用于指定是否从网络下载数据集。当
download = True,且指定的root目录下不存在CIFAR - 10数据集时,会自动从网络下载数据集;download = False可以在已经将数据集下载到对应目录时候使用。 - 示例:如果已经提前下载好数据集并放在指定目录,可设置
download = True
也不会报错
- 作用:是一个布尔值,用于指定是否从网络下载数据集。当
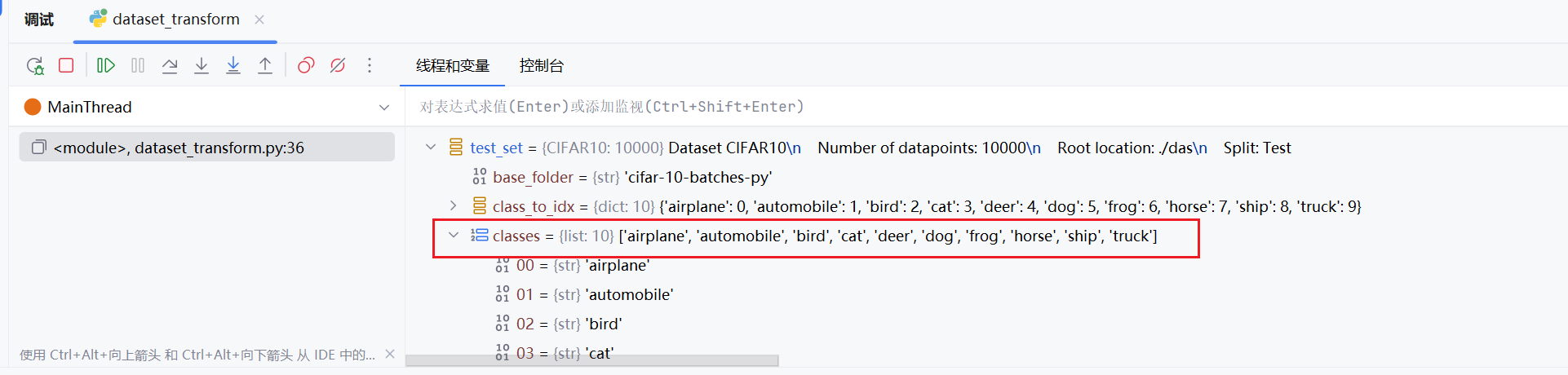
在print(test_set[0])的位置打一个断点,可以看到该数据集确实有这10给类别
print(test_set.classes)
我们也可以通过打印,由此可以看到数据集中的类别

我们打印更多信息来看看
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
print(test_set[0])
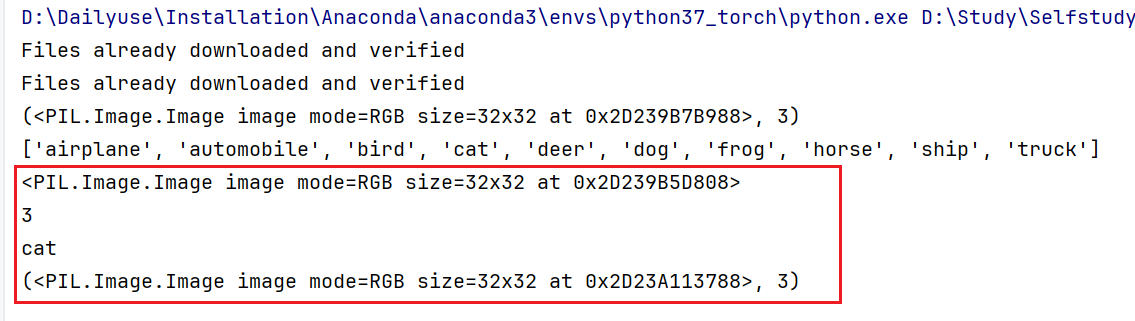
img.show()的作用是展示图片

1.3 使用transform加载代码
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./das", train = True,transform=dataset_transform, download = True)
test_set = torchvision.datasets.CIFAR10(root="./das", train=False,transform=dataset_transform, download = True)# print(test_set[0])
# print(test_set.classes)
#
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set3",img, i)writer.close()
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
这是将PIL的数据类型转换成ToTensor的数据类型
我们运行代码之后可以再打开tensorboard就可以看到一下结果

2 DataLoader的使用
2.1 DataLoader的作用
在深度学习框架(如PyTorch )中,DataLoader 是用于数据加载的重要工具,主要有以下作用:
1. 数据读取
负责从存储介质(如硬盘 )中读取原始数据,数据可以是图片、文本、音频等多种格式,这些数据通常存储在文件或数据库中。比如读取CIFAR - 10图像数据集用于图像分类任务。
2. 数据预处理
读取数据后,能对数据进行一系列预处理操作,包括但不限于:
- 归一化:将数据的值映射到特定范围,如把图像像素值归一化到[0, 1]或[-1, 1] ,使模型训练更稳定。
- 标准化:按照均值为0、方差为1的标准对数据进行变换,加快模型收敛速度。
- 数据增强:通过旋转、缩放、裁剪、颜色变换等方式扩充数据样本,增加数据多样性,提升模型泛化能力,在图像领域应用广泛。
- 编码转换:例如将文本数据转换为数值编码,方便模型处理。
3. 批量处理
受内存限制,无法一次性将大规模数据集全部加载到内存中,DataLoader 将数据划分成多个小批次(batch),每个批次包含一定数量的样本,模型每次训练处理一个批次数据,有效利用内存,提高训练效率 。比如设置batch_size=32 ,则每次从数据集中取出32个样本组成一个批次供模型训练。
4. 并行加载
借助多线程或多进程,可并行地从多个文件或数据源中加载数据,充分利用计算机多核资源,大幅提升数据加载速度,尤其在处理大型数据集时优势明显 。通过设置num_workers参数指定加载数据的线程或进程数量。
5. 数据打乱
在每个训练周期(epoch)开始时,可通过设置相关参数(如PyTorch中DataLoader 的shuffle=True )打乱数据顺序,使模型在训练过程中学习到数据的不同模式,避免过拟合 。
6. 数据持久化(部分场景 )
有时为加快后续训练时的数据加载速度,会将预处理后的数据保存到磁盘(如HDF5文件 ),后续训练可直接加载预处理后的数据,无需重复预处理 。
7. 提供迭代器接口
DataLoader 是可迭代对象,提供迭代器接口,在模型训练循环中能通过简单的循环方便地访问每个批次的数据,与模型训练循环紧密集成,保证数据及时、连续地供给模型进行训练 。例如在PyTorch中可通过for batch in dataloader 遍历DataLoader 获取每个批次数据。
2.2 常用参数讲解
以PyTorch中的DataLoader为例,其常用参数如下:
dataset- 类型:
torch.utils.data.Dataset子类实例 - 作用:指定从哪个数据集对象加载数据,是必须传入的参数 。比如使用
torchvision.datasets加载的CIFAR - 10数据集,或是自定义的继承自torch.utils.data.Dataset的数据集类实例 。
- 类型:
batch_size- 类型:
int - 作用:确定每个批次中数据样本的数量 。默认值为1。例如设置
batch_size = 32,模型每次训练就会处理32个样本。一般根据内存大小和数据集规模调整,过小会使CPU、GPU空闲时间增多,过大可能导致内存不足,常见取值为2的幂次方 。
- 类型:
shuffle- 类型:
bool - 作用:决定是否在每个训练周期(epoch)开始时打乱数据集样本顺序 。默认值为
False。设置为True可避免模型学习到数据的固定顺序模式,降低过拟合风险,提升模型泛化能力 。
- 类型:
num_workers- 类型:
int - 作用:指定用于数据加载的子进程数量 。默认值为0,即使用主进程加载数据 。设置为大于0的值,能利用多个子进程并行加载数据,加快数据读取速度,尤其适合大型数据集。但在Windows系统中,多进程机制可能不稳定,常建议设为0来规避问题 。常用取值范围是0 - 8 。
- 类型:
drop_last- 类型:
bool - 作用:当数据集大小不能被
batch_size整除时,控制是否丢弃最后一个不完整的批次 。默认值为False。若设为True,会舍弃最后一个不足batch_size的批次,保证每个批次大小一致,避免训练时因批次大小差异导致的不稳定;设为False则会保留最后不完整批次 。
- 类型:
sampler- 类型:实现了
__iter__()方法的对象,常为torch.utils.data.Sampler子类 - 作用:定义从数据集中抽取样本的策略 。若指定了该参数,
shuffle参数将被忽略 。比如可以使用SubsetRandomSampler实现从数据集中按特定索引子集随机抽样 。
- 类型:实现了
batch_sampler- 类型:类似
sampler,但返回一批次的索引 - 作用:与
sampler功能相似,不过它一次返回一个批次的索引,而非单个样本索引 。不能与batch_size、shuffle和sampler同时使用 。
- 类型:类似
collate_fn- 类型:函数
- 作用:可选参数,用于指定如何将多个数据样本整理成一个批次 。比如处理不同长度的序列数据时,可自定义
collate_fn函数实现特殊的整理逻辑 。
pin_memory- 类型:
bool - 作用:设置是否将数据保存在CUDA支持的固定内存中 。默认值为
False。设为True时,可避免在显存和内存之间重复传输数据,提升数据读取和使用速度,但仅在使用CUDA时生效 。
- 类型:
2.3 代码
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./ds", train = False, transform=torchvision.transforms.ToTensor())
#专门加载测试集
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0,drop_last=False)# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = data# print(imgs.shape)# print(targets)writer.add_images("Epoch: {}".format(epoch), imgs, step)step = step + 1writer.close()
注意:
1.对于dataloader(batch_size=64), 相当于把其中的img0-63 & target0-63 都进行打包作为dataloader中的一个返回
我们来验证一下
img, target = test_data[0]
print(img.shape)
print(target)for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)

可以看到返回的一组(batch_size)中确实是64张图片
再加入tensorboard相关代码,进行展示
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)writer.add_images("Epoch: {}".format(epoch), imgs, step)step = step + 1writer.close()运行结果

2.注意epoch的作用是:外层循环遍历 2 个训练轮次(epoch),这在实际应用中用于训练多轮,并查看结果