缓存(5):常见 缓存数据淘汰算法/缓存清空策略
主要的三种缓存数据淘汰算法
FIFO(first in first out):先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used):最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used):最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
其他的一些简单策略比如:
- 根据过期时间判断,清理过期时间最长的元素;
- 根据过期时间判断,清理最近要过期的元素;
- 随机清理;
- 根据关键字(或元素内容)长短清理等。
FIFO
算法:最先进来的数据,被认为在未来被访问的概率也是最低的,因此,当规定空间用尽且需要放入新数据的时候,会优先淘汰最早进来的数据
优点:最简单、最公平的一种数据淘汰算法,逻辑简单清晰,易于实现
缺点:这种算法逻辑设计所实现的缓存的命中率是比较低的,因为没有任何额外逻辑能够尽可能的保证常用数据不被淘汰掉
LRU-时间 (适用局部突发流量场景)
算法:如果一个数据最近很少被访问到,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰最久未被访问的数据
优点:
- LRU 实现简单,在一般情况下能够表现出很好的命中率,是一个“性价比”很高的算法。
- LRU可以
有效的对访问比较频繁的数据进行保护,也就是针对热点数据的命中率提高有明显的效果。 - LRU局部突发流量场景,对
突发性的稀疏流量(sparse bursts)表现很好。
缺点:
- 在存在 周期性的局部热点 数据场景,有大概率可能造成缓存污染。
- 最近访问的数据,并不一定是周期性数据,比如把全量的数据做一次迭代,那么LRU 会产生较大的缓存污染,因为周期性的局部热点数据,可能会被淘汰。
LRU-K
算法:LRU中的K是指数据被访问K次,传统LRU与此对比则可以认为传统LRU是LRU-1
LRU-K有两个队列,新来的元素先进入到历史访问队列中,该队列用于记录元素的访问次数,采用的淘汰策略是LRU或者FIFO,- 当
历史队列中的元素访问次数达到K的时候,才会进入缓存队列
Two Queues
Two Queues与LRU-K相比,他也同样是两个队列,不同之处在于,他的队列一个是缓存队列,一个是FIFO队列,
当新元素进来的时候,首先进入FIFO队列,当该队列中的元素被访问的时候,会进入LRU队列
LFU-频率 (适用局部周期性流量场景)
算法:如果一个数据在一定时间内被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰时间段内访问次数最低的数据
优点:
- LFU
适用于 局部周期性流量场景,在这个场景下,比LRU有更好的缓存命中率。 - 在 局部周期性流量场景下,
LFU是以次数为基准,所以更加准确,自然能有效的保证和提高命中率
缺点:
- 因为LFU
需要记录数据的访问频率,因此需要额外的空间; - 它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;
- 在**
存在 局部突发流量场景下,有大概率可能造成缓存污染, 算法命中率会急剧下降,这也是他最大弊端。** 所以,LFU 对突发性的稀疏流量(sparse bursts)是无效的。
LFU 按照访问次数或者访问频率取胜,这个次数有一个累计的长周期, 导致前期经常访问的数据,访问次数很大,或者说权重很高
新来的缓存数据, 哪怕他是突发热点,但是,新数据的访问次数累计的时间太短老的记录已经占用了缓存,过去的一些大量被访问的记录,在将来不一定会继续是热点数据,但是就一直把“坑”占着了,而那些偶然的突破热点数据,不太可能会被保留下来,而是被淘汰- 所以,
存在突发性的稀疏流量下,LFU中的偶然的、稀疏的突发流量在访问频率上,不占优势,很容易被淘汰,造成缓存污染和未来缓存命中率下降
TinyLFU
概述
TinyLFU 就是其中一个优化算法,专门为了解决 LFU 上的三个问题而被设计出来的。
LFU 上的三个问题如下
- 如何减少访问频率的保存,所带来的空间开销
- 如何减少访问记录的更新,所带来的时间开销
- 如果提升对局部热点数据的 算法命中率
解决第1个问题/第2个问题是采用了 Count–Min Sketch 算法
Count-Min Sketch算法
将一个hash操作,扩增为多个hash,这样原来hash冲突的概率就降低了几个等级,且当多个hash取得数据的时候,取最低值,也就是Count Min的含义所在。
Count–Min Sketch 的原理跟 Bloom Filter 一样,只不过Bloom Filter 只有 0 和 1的值,可以把 Count–Min Sketch 看作是“数值”版的 Bloom Filter。
解决第三个问题是让老的访问记录,尽量降低“新鲜度”
Count–Min Sketch 算法
工作原理
ount-Min Sketch算法简单的工作原理:
- 假设有四个hash函数,每当元素被访问时,将进行次数加1;
- 此时会按照约定好的四个hash函数进行hash计算找到对应的位置,相应的位置进行+1操作;
当获取元素的频率时,同样根据hash计算找到4个索引位置;取得四个位置的频率信息,然后根据Count Min取得最低值作为本次元素的频率值返回,即Min(Count);
空间开销
Count-Min Sketch访问次数的空间开销?
-
用4个hash函数会存访问次数,那空间就是4倍
-
解决:
- 访问次数超过15次其实是很热的数据了,没必要存太大的数字。所以我们用4位就可以存到15
一个访问次数占4个位,一个long有64位,可以存 16个访问次数,4个访问一次一组的话, 一个long 可以分为4组- 一个 key 对应到 4个hash 值, 也就是 4个 访问次数,一个long 可以分为存储 4个Key的 访问 次数
最终:一个long对应的数组大小其实是容量的4倍(本来一个long是一个key的,但是现在可以存4个key)
降鲜机制
提升对局部热点数据的 算法命中率
让缓存降低“新鲜度”,剔除掉过往频率很高,但之后不经常的缓存
Caffeine 有一个 Freshness Mechanism。
做法:当整体的统计计数(当前所有记录的频率统计之和,这个数值内部维护)达到某一个值时,那么所有记录的频率统计除以 2。
TinyLFU 的算法流程
当缓存空间不够的时候,TinyLFU 找到 要淘汰的元素 (the cache victim),也就是使用频率最小的元素 ,
然后 TinyLFU 决定 将新元素放入缓存,替代 将 要淘汰的元素 (the cache victim)
W-TinyLFU
演进
TinyLFU 在面对突发性的稀疏流量(sparse bursts)时表现很差
新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降
W-TinyLFU是 LFU 的变种,也是TinyLFU的变种
W-TinyLFU是如何演进:W-TinyLFU = LRU + LFU
LRU能很好的 处理 局部突发流量LFU能很好的 处理 局部周期流量
W-TinyLFU(Window Tiny Least Frequently Used)是对TinyLFU的的优化和加强,加入 LRU 以应对局部突发流量, 从而实现缓存命中率的最优。
W-TinyLFU 在空间效率和访问命中率之间达到了显著平衡,成为现代缓存库(如 Caffeine)的核心算法。
数据结构
W-TinyLFU增加了一个 W-LRU窗口队列 的组件
- 当一个数据进来的时候,会进行筛选比较,进入W-LRU窗口队列
- 经过淘汰后进入Count-Min Sketch算法过滤器,
通过访问访问频率判决, 是否进入缓存
作用:如果一个数据最近被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽的时候,会优先淘汰最近访问次数很低的数据
W-LRU窗口队列 用于应 对 局部突发流量TinyLFU 用于 应对 局部周期流量
存储空间结构
W-TinyLFU将缓存存储空间分为两个大的区域:Window Cache和Main Cache
-
Window Cache:是一个标准的LRU Cache -
Main Cache:是一个SLRU(Segmemted LRU)cache,划分为Protected Cache(保护区)和Probation Cache(考察区)两个区域,这两个区域都是基于LRU的Cache。- 精细化淘汰:使用 TinyLFU 算法(基于概率型频率统计)结合 SLRU(Segmented LRU,分段LRU)策略,区分高频和低频条目。
- 长期频率管理:存储经过 Window Cache 筛选的高频访问条目,基于访问频率决定保留优先级。
Protected 是一个受保护的区域,该区域中的缓存项不会被淘汰- 存储长期高频访问的条目(“热数据”)。
- 占比约 80%,使用 LRU 淘汰策略。
- Probation Region(观察区)
- 存储候选条目,与 Window Cache 淘汰的条目竞争。
- 占比约 20%,使用 TinyLFU 比较频率决定去留。
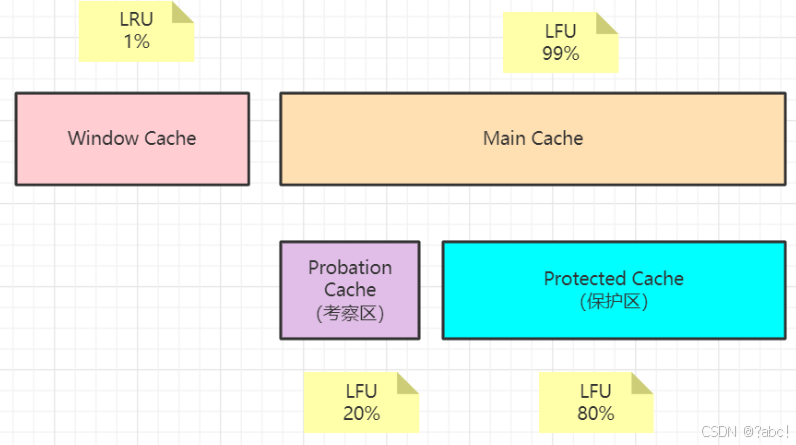
空间最优选:当 window 区配置为总容量的 1%,剩余的 99%当中的 80%分给 protected 区,20%分给 probation 区时,这时整体性能和命中率表现得最好,所以 Caffeine 默认的比例设置就是这个。
- 这个比例 Caffeine 会在运行时根据统计数据(statistics)去动态调整,如果你的
应用程序的缓存随着时间变化比较快的话,或者说具备的突发特点数据多,那么增加 window 区的比例可以提高命中率 - 如果
周期性热地数据多,缓存都是比较固定不变的话,增加 Main Cache 区(protected 区 +probation 区)的比例会有较好的效果。
W-TinyLFU的算法流程
写入机制
第一步:当有新的缓存项写入缓存时,会先写入Window Cache区域,当Window Cache空间满时,最旧的缓存项会被移出Window Cache
第二步:将移出Window Cache的缓存移动到Main Cache
- 如果Probation Cache未满,从Window Cache移出的缓存项会直接写入Probation Cache
- 如果Probation Cache已满,则会根据
TinyLFU算法确定从Window Cache移出的缓存项是丢弃(淘汰)还是写入Probation Cache
第三步:Probation Cache中的缓存项如果访问频率达到一定次数,会提升到Protected Cache
- 如果Protected Cache也满了,最旧的缓存项也会移出Protected Cache,然后
根据TinyLFU算法确定是丢弃(淘汰)还是写入Probation Cache。
淘汰机制为
从Window Cache或Protected Cache移出的缓存项称为Candidate,Probation Cache中最旧的缓存项称为Victim。
如果Candidate缓存项的访问频率大于Victim缓存项的访问频率,则淘汰掉Victim。
如果Candidate小于或等于Victim的频率,
- 那么如果Candidate的频率小于5,则淘汰掉Candidate;
- 否则,则在Candidate和Victim两者之中随机地淘汰一个。
总结
caffeine综合了LFU和LRU的优势,将不同特性的缓存项存入不同的缓存区域,
- 最近刚产生的缓存项进入Window区,不会被淘汰
- 访问频率高的缓存项进入Protected区,也不会淘汰
- 介于这两者之间的缓存项存在Probation区,当缓存空间满了时,Probation区的缓存项会根据访问频率判断是保留还是淘汰;
优点:
- 很好的平衡了访问频率和访问时间新鲜程度两个维度因素,尽量将新鲜的访问频率高的缓存项保留在缓存中
- 同时在维护缓存项访问频率时,引入计数器饱和和衰减机制,即节省了存储资源,也能较好的处理稀疏流量、短时超热点流量等传统LRU和LFU无法很好处理的场景
- 使用Count-Min Sketch算法存储访问频率,极大的节省空间;
- TinyLFU会 定期进行新鲜度 衰减操作,应对访问模式变化;、
- 并且使用W-LRU机制能够尽可能避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据
W-TinyLFU的缺点:目前已知应用于Caffeine Cache组件里,应用不是很多。