最速下降法和梯度下降法的异同
一、概念与原理
| 特性 | 最速下降法 (Steepest Descent) | 梯度下降法 (Gradient Descent) |
|---|---|---|
| 方向定义 | 在给定范数下,沿负梯度方向是“最快减少方向” | 通常默认欧氏范数,也沿负梯度方向 |
| 目标 | 每步都在当前点寻找使目标函数沿负梯度方向的最优步长 | 固定或简单规则选步长,保证总体下降 |
| 本质区别 | 强调“局部一维最优化”——每次都要精确或近似最优的线搜索 | 强调“易实现、低开销”,往往采用固定或预定的学习率 |
-
在二次凸函数上,最速下降法每一步都做一次精确(或足够精确)的 线搜索,确保当前方向上的最优下降;
-
梯度下降法则可视为最速下降法在“步长为常数”或“步长按预设衰减”两种策略下的特例,不一定每步都做线搜索。
二、算法步骤与伪代码
1. 最速下降法(含线搜索)
输入:初始点 x⁰,精度 ε
k ← 0
repeat1. 计算梯度 gᵏ = ∇f(xᵏ)2. 若 ‖gᵏ‖ ≤ ε,则停止,x* = xᵏ3. 选取步长 αᵏ = argmin_{α>0} f(xᵏ − α gᵏ) // 一维线搜索4. 更新 xᵏ⁺¹ = xᵏ − αᵏ gᵏ5. k ← k + 1
until 收敛
-
线搜索可以用精确搜索(解析解,仅对二次函数可行)或常见的 Armijo、Wolfe 条件等 弱线搜索(简化一维最优化)。
2. 梯度下降法(固定步长/衰减步长)
输入:初始点 x⁰,学习率序列 {αᵏ},精度 ε
k ← 0
repeat1. 计算梯度 gᵏ = ∇f(xᵏ)2. 若 ‖gᵏ‖ ≤ ε,则停止,x* = xᵏ3. 选取步长 αᵏ (如常数 α, 或 αᵏ = α₀/(1 + βk))4. 更新 xᵏ⁺¹ = xᵏ − αᵏ gᵏ5. k ← k + 1
until 收敛
-
步长 αᵏ 通常预先设定,不做每步一维最优化。
三、步长选择
| 方法 | 最速下降法 | 梯度下降法 |
|---|---|---|
| 精确线搜索 | 每步解 | 不常用 |
| 弱线搜索 | Armijo / Wolfe 等条件,保证充分下降 | 有时也可用于自适应学习率,但多为简化版本 |
| 固定步长 | 不推荐;可能失去“最速”特性 | 最常用;需满足 0<α<2/L(L是 Lipschitz 常数) |
| 衰减步长 | 可用,但本质已偏离“最速” | 常用,如 |
四、收敛性与复杂度
| 指标 | 最速下降法 | 梯度下降法 |
|---|---|---|
| 收敛速率(二次凸) | 线搜索后,理论上 | 固定步长下, |
| 每步开销 | 需做一维最优化(若解析线搜索则是 O(1),否则 O(n)~O(nlogn)) | 仅梯度计算 O(n) |
| 迭代次数 | 最少(在同样精度下通常比固定步长少) | 更多;尤其当条件数大时,需小步长才稳定 |
| 整体时间 | 迭代少但每步贵;适中问题优 | 迭代多但每步便宜;高维大数据常用 |
-
对于二次凸二次型
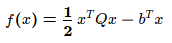 ,最速下降法在每一步都可获得最大可能的下降量;梯度下降法固定步长则无法针对矩阵谱分布做最优调整,收敛受条件数影响更大。
,最速下降法在每一步都可获得最大可能的下降量;梯度下降法固定步长则无法针对矩阵谱分布做最优调整,收敛受条件数影响更大。
五、优缺点比较
| 方面 | 最速下降法 | 梯度下降法 |
|---|---|---|
| 实现难度 | 中等(需要线搜索子模块) | 简单(只需固定或衰减步长) |
| 参数依赖 | 主要依赖线搜索准则 | 严重依赖学习率(不当会震荡或收敛缓慢) |
| 适用场景 | 维度中等、追求快速收敛的光滑优化 | 高维、大规模、在线学习、深度学习 |
| 鲁棒性 | 对目标函数信息更多(线搜索),更稳定 | 对学习率敏感,需要经验或调参 |
| 扩展性 | 可推广到共轭梯度、BFGS 等更高级方法 | 可轻松并行、分布式,也可与动量、自适应结合 |
六、总结
-
最速下降法 是梯度下降的一种“最优方向+最优步长”实现,更接近理想的每步最大下降,但线搜索开销不容忽视;
-
梯度下降法 则牺牲每步最优,换取更简单、更高效的迭代,尤其在大规模或在线场景中更为实用。