Python_day21
DAY 21 常见的降维算法
知识点回顾:
- LDA线性判别
- PCA主成分分析
- t-sne降维
还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
一、降维的主要应用场景
降维技术(如PCA、t-SNE、SVD等)主要用于解决高维数据带来的挑战,常见应用场景包括:
1. 数据可视化 :将高维数据映射到2D/3D空间,直观观察数据分布(如类别聚类效果)。
2. 减少计算开销 :降低特征维度可显著减少模型训练时间(尤其对高维数据如基因序列、图像像素)。
3. 缓解维度灾难 :高维空间中数据稀疏,基于距离的算法(如KNN)性能下降,降维可改善。
4. 去除冗余特征 :消除噪声或高度相关的特征,提升模型泛化能力。
5. 多模态数据融合 :将不同来源的高维特征(如文本+图像)统一到低维空间。
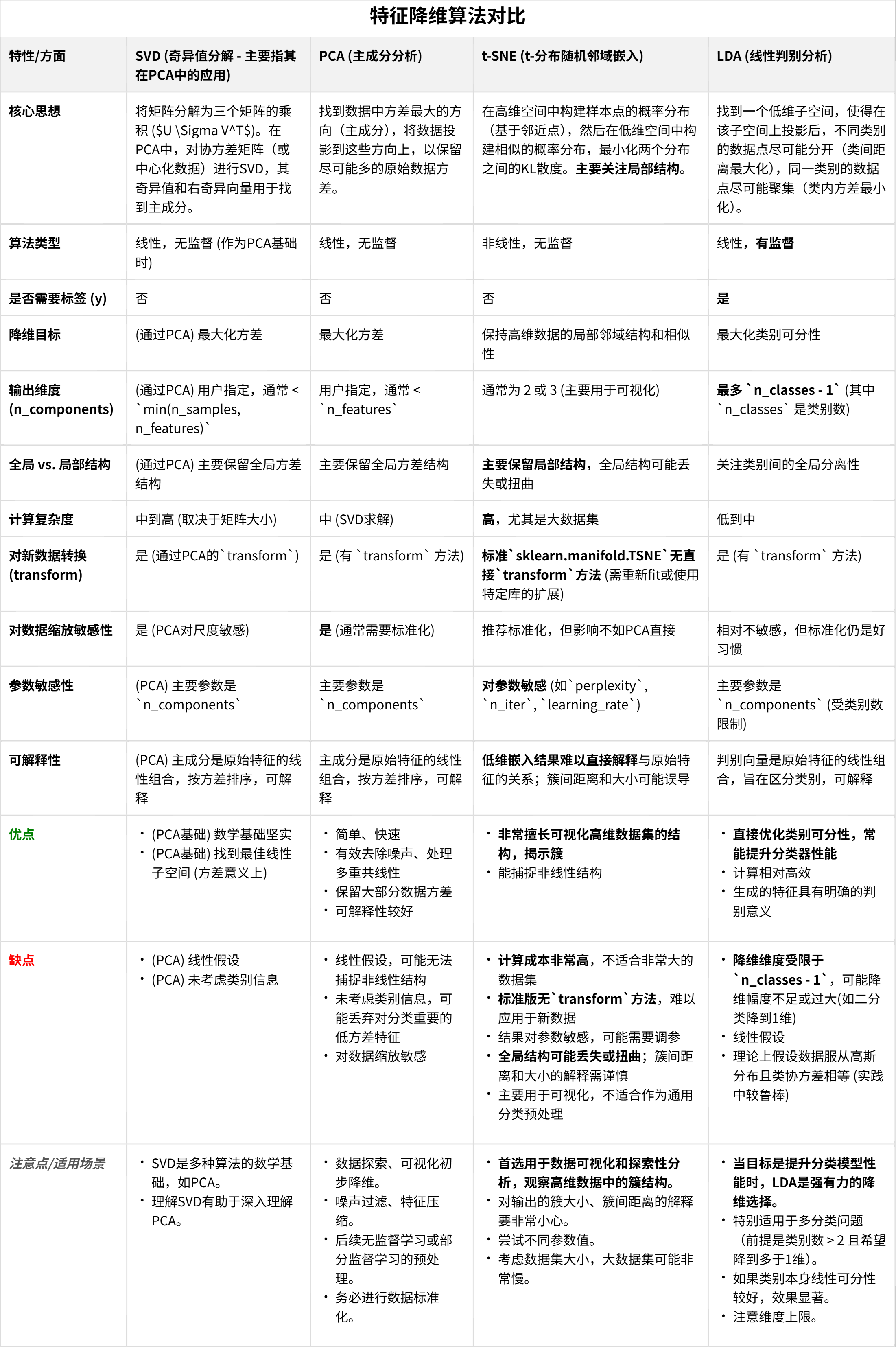
二、基于heart数据集的题目设计
题目 :使用heart心脏病数据集,对比PCA和t-SNE在2D可视化中的表现差异,并分析原因。 (要求:包含数据预处理、两种降维方法的实现、可视化对比图、结果分析)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split# ---------------------- 数据预处理 ----------------------
# 加载心脏病数据集(假设文件路径正确)
data = pd.read_csv('heart.csv')
# 分离特征和标签(target=1表示有心脏病)
X = data.drop('target', axis=1)
y = data['target']
# 标准化特征(PCA和t-SNE对尺度敏感)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# ---------------------- PCA降维 ----------------------
pca = PCA(n_components=2, random_state=42) # 降维到2D
X_pca = pca.fit_transform(X_scaled)# ---------------------- t-SNE降维 ----------------------
tsne = TSNE(n_components=2, perplexity=30, random_state=42) # 常用perplexity=5-50
X_tsne = tsne.fit_transform(X_scaled)# ---------------------- 可视化对比 ----------------------
plt.figure(figsize=(12, 6))# PCA可视化
plt.subplot(1, 2, 1)
plt.scatter(X_pca[y==0, 0], X_pca[y==0, 1], c='blue', label='无心脏病', alpha=0.6)
plt.scatter(X_pca[y==1, 0], X_pca[y==1, 1], c='red', label='有心脏病', alpha=0.6)
plt.title('PCA降维到2D的心脏病数据分布')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.legend()# t-SNE可视化
plt.subplot(1, 2, 2)
plt.scatter(X_tsne[y==0, 0], X_tsne[y==0, 1], c='blue', label='无心脏病', alpha=0.6)
plt.scatter(X_tsne[y==1, 0], X_tsne[y==1, 1], c='red', label='有心脏病', alpha=0.6)
plt.title('t-SNE降维到2D的心脏病数据分布')
plt.xlabel('t-SNE维度1')
plt.ylabel('t-SNE维度2')
plt.legend()plt.tight_layout()
plt.show()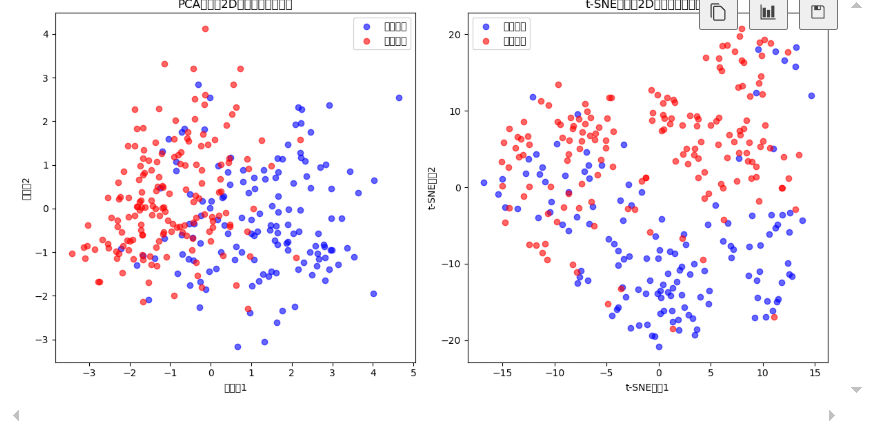
# 5. 特征分布对比直方图
plt.subplot(2, 2, 1)
sns.histplot(data=data, x='age hue='Credit Default', element='step', # 修改列名palette={0:'blue', 1:'red'}, bins=20, kde=True)
plt.title('年龄分布对比(违约 vs 正常)') # 更新标题描述
plt.xlabel('年龄')
plt.ylabel('频数')# 6. 多变量关系矩阵图
plt.subplot(2, 2, 2)
sns.pairplot(data=data[['age', 'trestbps', 'chol', 'thalach', 'Credit Default']], # 修改列名hue='Credit Default', palette={0:'blue', 1:'red'}, corner=True)
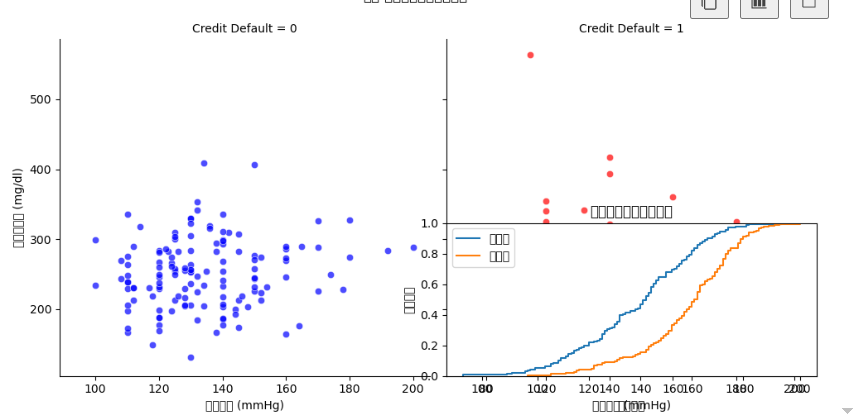
plt.suptitle('关键特征关系矩阵图', y=1.02)# 7. 分面网格-血压与胆固醇关系
g = sns.FacetGrid(data=data, col='Credit Default', hue='Credit Default', # 修改列名palette={0:'blue', 1:'red'}, height=5)
g.map_dataframe(sns.scatterplot, x='trestbps', y='chol', alpha=0.7)
g.set_axis_labels('静息血压 (mmHg)', '血清胆固醇 (mg/dl)')
g.fig.suptitle('血压-胆固醇关系分面可视化', y=1.05)# 8. 累积分布函数图
plt.subplot(2, 2, 4)
for target_value in [0, 1]:subset = data[data['Credit Default'] == target_value] # 修改列名sns.ecdfplot(subset['thalach'], label=f'违约组' if target_value else '正常组') # 更新标签
plt.title('最大心率累积分布对比')
plt.xlabel('最大心率')
plt.ylabel('累积概率')
plt.legend()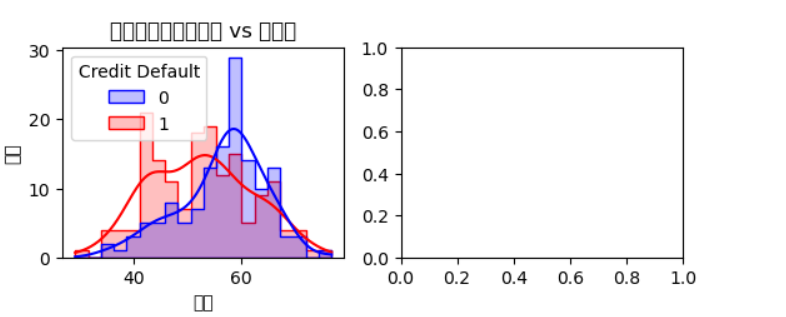
@浙大疏锦行