机器学习 day01
文章目录
- 前言
- 一、机器学习的基本概念
- 二、数据集的加载
- 1.玩具数据集
- 2.联网数据集
- 3.本地数据集
- 三、数据集的划分
- 四、特征提取
- 1.稀疏矩阵与稠密矩阵
- 2.字典列表特征提取
- 3.文本特征提取
前言
目前我开始学习机器学习部分的相关知识,通过今天的学习,我掌握了机器学习的基本概念,数据集的加载,划分以及部分特征提取API的使用
一、机器学习的基本概念
- 机器学习通俗来讲就是通过编程,使计算机像人类一样从已有的数据中学习规律并对新的数据进行预测
- 机器学习算法主要包括以下种类:分类,回归,聚类,神经网络,深度学习等等
- 按照学习模式的不同,可以分为:有监督学习,半监督学习,无监督学习和强化学习(这里的“监督”主要是指数据是否给定标签)
- 强化学习是一种特殊的学习模式,它主要通过让模型不断试错来进行训练
二、数据集的加载
以下的章节均使用scikit-learn库进行讨论
1.玩具数据集
- sklearn库中有一些数据量较小并且已经下载到本地的数据集成为玩具数据集
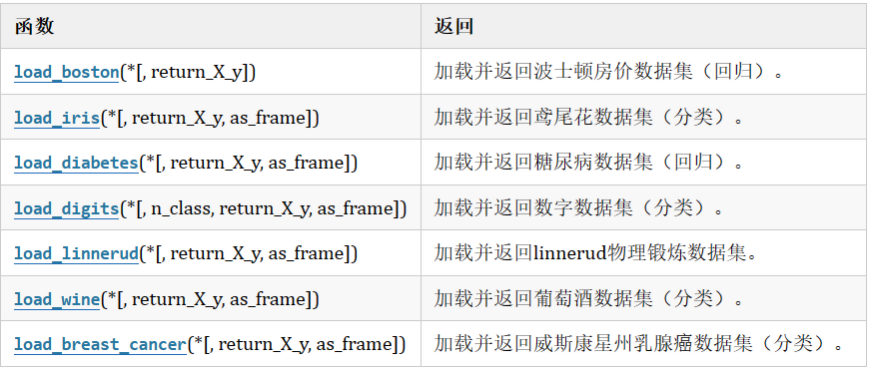
- 加载以上的这些数据集不用进行联网下载,直接导包即可,以下用鸢尾花数据集为例展示:
from sklearn.datasets import load_iris
iris = load_iris()# 特征(x,data)
data = iris.data
print(iris.feature_names) #返回数据集的特征名# 标签(y,target,目标,labels)
target = iris.target
print(iris.target_names) # 返回数据集的标签名
2.联网数据集
- sklearn库中还提供了一些数据量较大的现实数据,需要导包后联网进行下载

- 以下使用sklearn中的新闻数据集为例:
from sklearn.datasets import fetch_20newsgroups
# 加载数据集
news = fetch_20newsgroups(data_home="/.src",subset="train")
# 特征
data = news.data
# 目标
target = news.target
tips:data_home参数指定数据集下载位置,也可以通过datasets.get_data_home()查看默认下载位置;subset指定需要下载数据集的哪个部分
3.本地数据集
- 可以借助Pandas库对本地数据集进行加载
# 加载本地数据集
data = pd.read_csv("./src/ss.csv")
data = data.to_numpy()
print(data)
三、数据集的划分
- 从sklearn.model_selection中导入train_test_split方法,一般按照“8:2”或者“7:3”的比例划分训练集和测试集
from sklearm.model_selection import train_test_split
iris = load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.8,shuffle=True,random_state=42)
- 以上的代码中的shuffle用于指定是否打乱数据集,random_state用于指定随机数种子
tips:需要注意使用划分函数时必须保证输入的x,y能够一一对应;同时需要注意划分前和划分后的数据类型是相同的,即输入的数据如果是列表则输出的划分也是列表
四、特征提取
- 特征提取是从原始数据中提取出对后续分析、建模或任务具有代表性和区分性信息的过程。
1.稀疏矩阵与稠密矩阵
- 稀疏矩阵指的是大部分元素为零,只有少量非零元素组成的矩阵
- 由于稀疏矩阵中存在大量零元素,在存储时可以只存非零元素,可以节省空间并提高效率
- 三元组表 (Coordinate List, COO):一种稀疏矩阵类型数据,存储非零元素的行,列索引和值
- 稠密矩阵与稀疏矩阵恰好相反,其中主要包括的是非零元素,可以最大程度的保留数据的信息
2.字典列表特征提取
- 由于字典中含有非数值的元素,对于后续操作并不方便,故将其信息提取到稀疏矩阵中进行表示
API:sklearn.feature_extraction.DictVectorizer(sparse=True)
- 参数:
sparse=True返回类型为稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
# 创建DictVectorizer类对象
tool = DictVectorizer(sparse=False)
# fit后transform
data = tool.fit_transform(data)
print(data)
print(transfer.get_feature_names_out())
data_new:
[[ 30. 0. 1. 0. 200.]
[ 33. 0. 0. 1. 60.]
[ 42. 1. 0. 0. 80.]]
特征名字:
[‘age’ ‘city=北京’ ‘city=成都’ ‘city=重庆’ ‘temperature’]
- 代码结果如上,结果数组中用0或1代表对应文字特征是否出现
3.文本特征提取
- 同样,文本数据也不便于进行数据处理,因此,可以使用文本特征提取的API进行处理
API:sklearn.feature_extraction.text.CountVectorizer()
- 该函数是一个类,仍然需要进行对象创建
from sklearn.feature_extraction.text import CountVectorizer
# 词频特征提取,中文需要有空格进行分词
data=["stu is well, stu is great", "You like stu"]
# 创建CountVectorizer对象
cv = CountVectorizer()
# 特征转换
data = cv.fit_transform(data)
print(data)
print(data.toarray())
# 查看特征名
print(cv.get_feature_names_out())
- 如果输入的文本是中文,那么需要手动进行分词,也可以使用jieba分词进行处理后再进行特征提取
import jieba
from sklearn.feature_extraction.text import CountVectorizertext = "Python,启动!"
data = jieba.cut(text)
data = list(data)
data = " ".join(data)
text = [data]tool = CountVectorizer()
text = tool.fit_transform(text)
tips:需要注意jieba.cut()方法返回的是一个生成器,我们可以使用list接进行类型转换,使用join进行拼接
THE END