《Python星球日记》 第55天:迁移学习与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、迁移学习基础
- 1. 什么是迁移学习?
- 2. 迁移学习的优势
- 3. 迁移学习的应用场景
- 二、预训练模型详解
- 1. 预训练模型的基本概念
- 2. 常用的预训练模型
- a) VGG系列
- b) ResNet系列
- c) EfficientNet系列
- 三、冻结层与微调技巧
- 1. 模型迁移的两种主要策略
- 2. 如何实现层冻结
- 3. 微调的最佳实践
- 四、超参数调优方法
- 1. 超参数调优的重要性
- 2. 网格搜索(Grid Search)
- 3. 随机搜索(Random Search)
- 4. 早停法(Early Stopping)
- 五、基于ResNet的图像分类实战
- 1. 项目概述与数据准备
- 2. 构建迁移学习模型
- 3. 分两阶段训练模型
- 4. 评估模型并可视化结果
- 5. 模型部署与应用
- 六、总结与进阶方向
- 1. 知识回顾
- 2. 进阶方向
- 3. 实践建议
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第54天:卷积神经网络进阶
欢迎来到Python星球的第55天!🪐
今天我们将探索深度学习中的一项重要技术——迁移学习,以及如何利用预训练模型来提升我们的模型性能。无论你是想节省训练时间,还是面临数据量不足的挑战,这些技术都将帮助你构建更强大的神经网络。
一、迁移学习基础
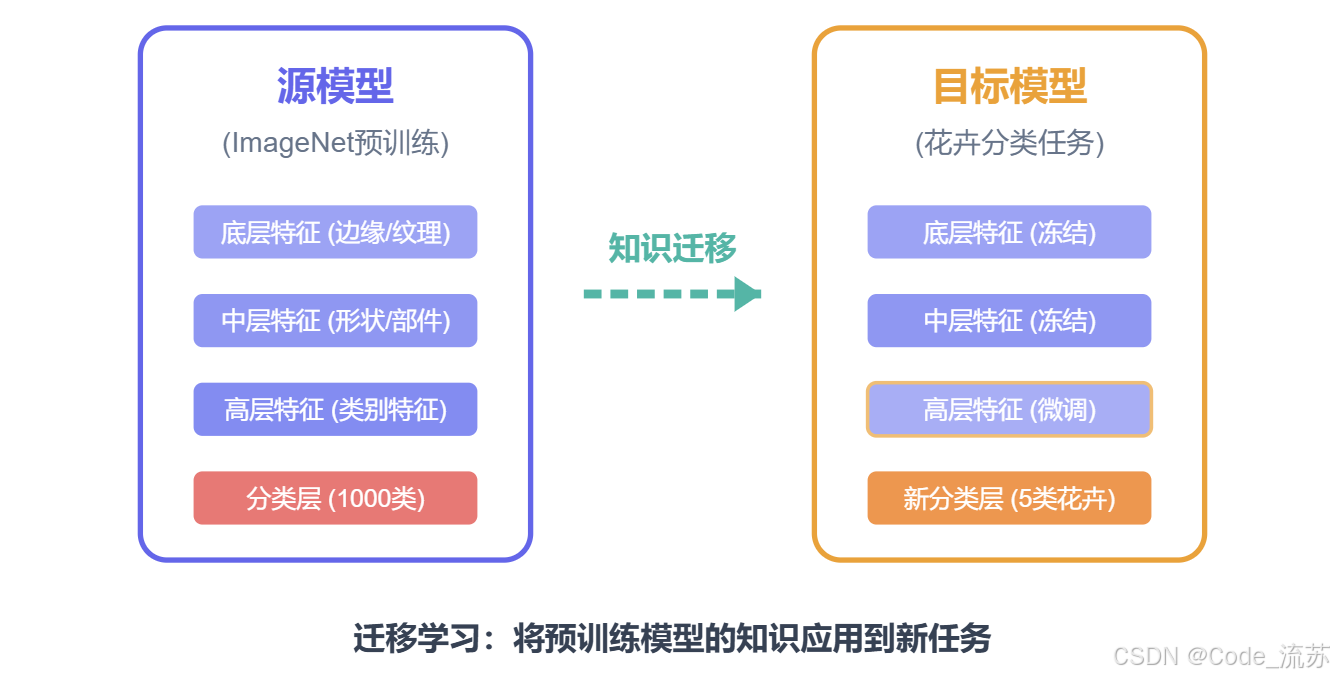
1. 什么是迁移学习?
迁移学习是一种机器学习方法,它允许我们将从一个任务中学到的知识应用到另一个相关任务中。简单来说,就是让模型"借鉴"已有经验来解决新问题,而不是从零开始学习。
想象一下:如果你已经会骑自行车,那么学习骑摩托车就会容易得多,因为你已经掌握了平衡和方向控制的基本技能。迁移学习在深度学习中的原理也是如此!
2. 迁移学习的优势
在深度学习世界中,迁移学习具有以下显著优势:
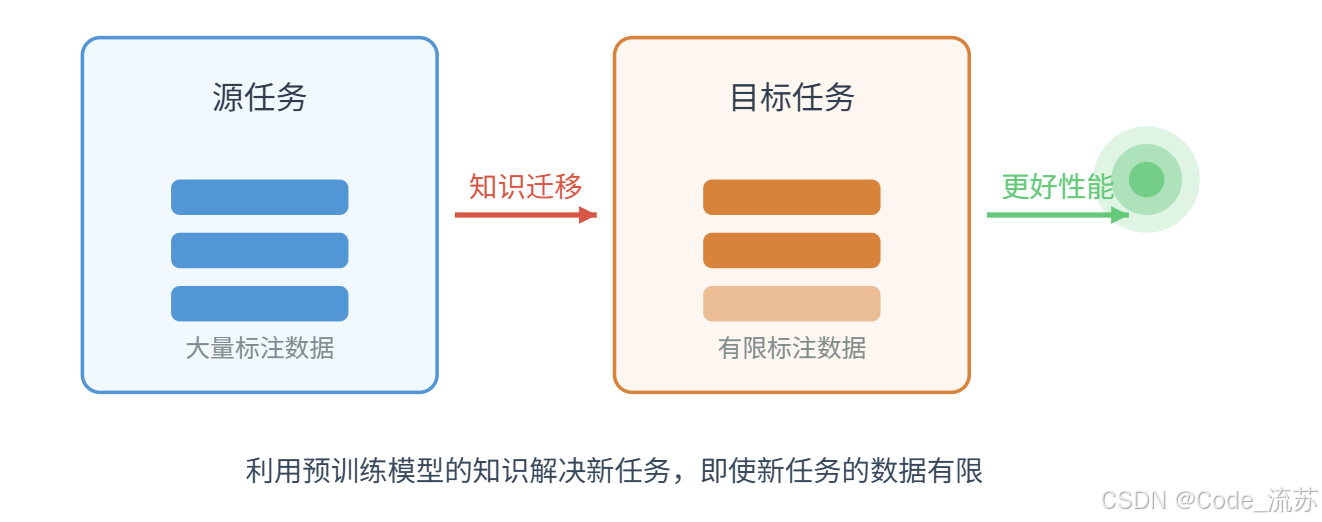
- 减少训练数据需求:当我们的目标任务数据有限时,迁移学习能够大幅降低对大规模标注数据的依赖
- 缩短训练时间:从预训练模型开始,通常能比从随机权重开始训练更快地收敛
- 提高模型性能:尤其在数据有限的情况下,迁移学习通常能获得更好的准确率和泛化能力
- 降低计算资源需求:不需要从头训练大型模型,节省GPU资源和电力消耗
3. 迁移学习的应用场景
迁移学习特别适用于以下场景:
- 目标任务的标注数据量不足
- 源任务和目标任务存在相关性
- 需要快速构建模型原型
- 计算资源有限
二、预训练模型详解
1. 预训练模型的基本概念
预训练模型是指在大规模数据集(如ImageNet,包含上百万张图片)上训练过的神经网络模型。这些模型已经学习了丰富的视觉特征和模式,可以被迁移到其他计算机视觉任务中。
预训练模型的底层卷积层通常捕获通用的特征(如边缘、纹理、简单形状),而高层则捕获更复杂、更特定于任务的特征。这种分层特征提取的能力是迁移学习能够成功的关键原因。
2. 常用的预训练模型
在计算机视觉领域,有几种广泛使用的预训练模型:
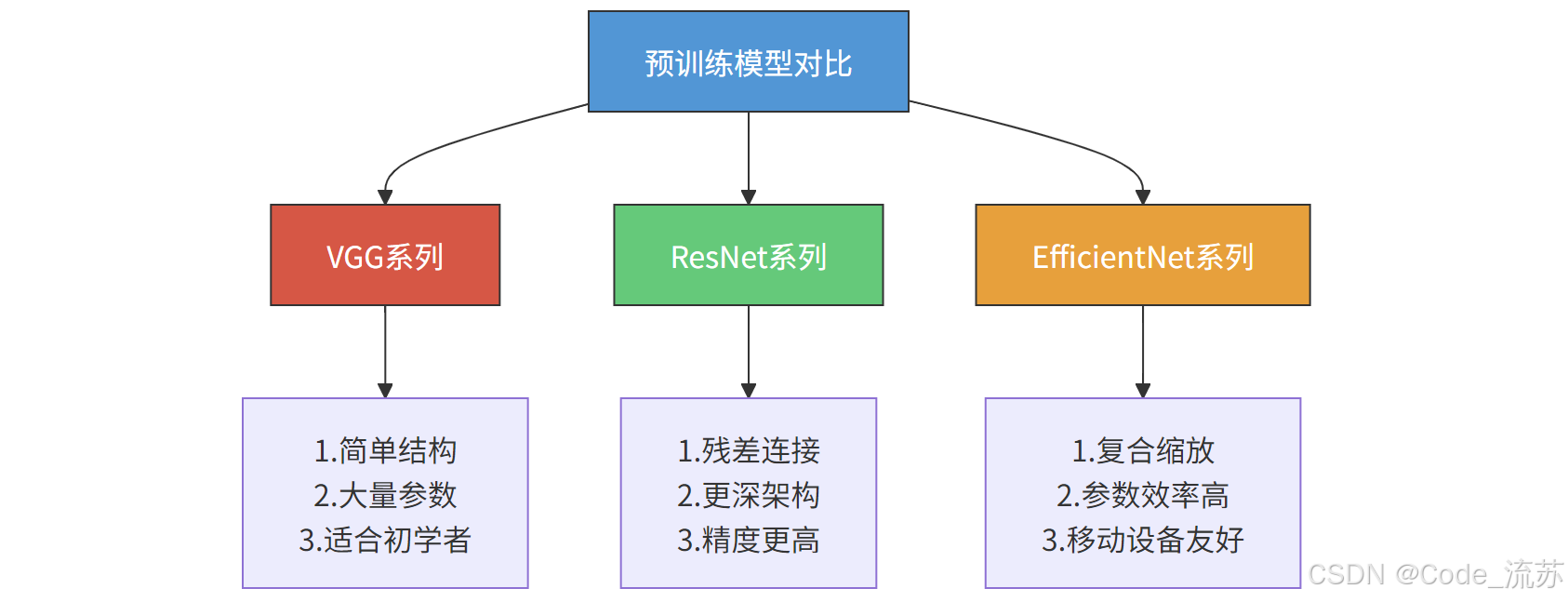
a) VGG系列
VGG16/VGG19是由牛津大学Visual Geometry Group开发的模型。
- 特点:结构简单、易于理解,使用3×3卷积堆叠而成
- 参数量:VGG16约有1.38亿参数,VGG19约有1.44亿参数
- 优缺点:结构规整清晰,但参数量大,推理速度相对较慢
- 适用场景:初学者学习CNN架构,较简单的图像分类任务
# 导入VGG16预训练模型
from tensorflow.keras.applications import VGG16# 加载不含顶层(全连接层)的VGG16模型
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
b) ResNet系列
ResNet(残差网络)由微软研究院提出,通过引入残差连接解决了深层网络训练困难的问题。
- 特点:引入跳跃连接(skip connection),允许信息直接从前层传到后层
- 变体:ResNet18、ResNet50、ResNet101、ResNet152等
- 优势:能够构建更深的网络而不导致梯度消失/爆炸问题
- 使用场景:复杂图像分类、目标检测、图像分割等
# 导入ResNet50预训练模型
from tensorflow.keras.applications import ResNet50# 加载预训练的ResNet50
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
c) EfficientNet系列
EfficientNet由Google研究团队开发,通过复合缩放方法在准确率和效率之间取得优异平衡。
- 特点:同时缩放网络的宽度、深度和分辨率
- 变体:EfficientNetB0到EfficientNetB7(复杂度递增)
- 优势:参数量少但性能高,FLOPS效率极佳
- 适用场景:资源受限设备、需要高效推理的应用
# 导入EfficientNetB0预训练模型
from tensorflow.keras.applications import EfficientNetB0# 加载预训练的EfficientNetB0
base_model = EfficientNetB0(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
预训练模型对比:
三、冻结层与微调技巧
1. 模型迁移的两种主要策略
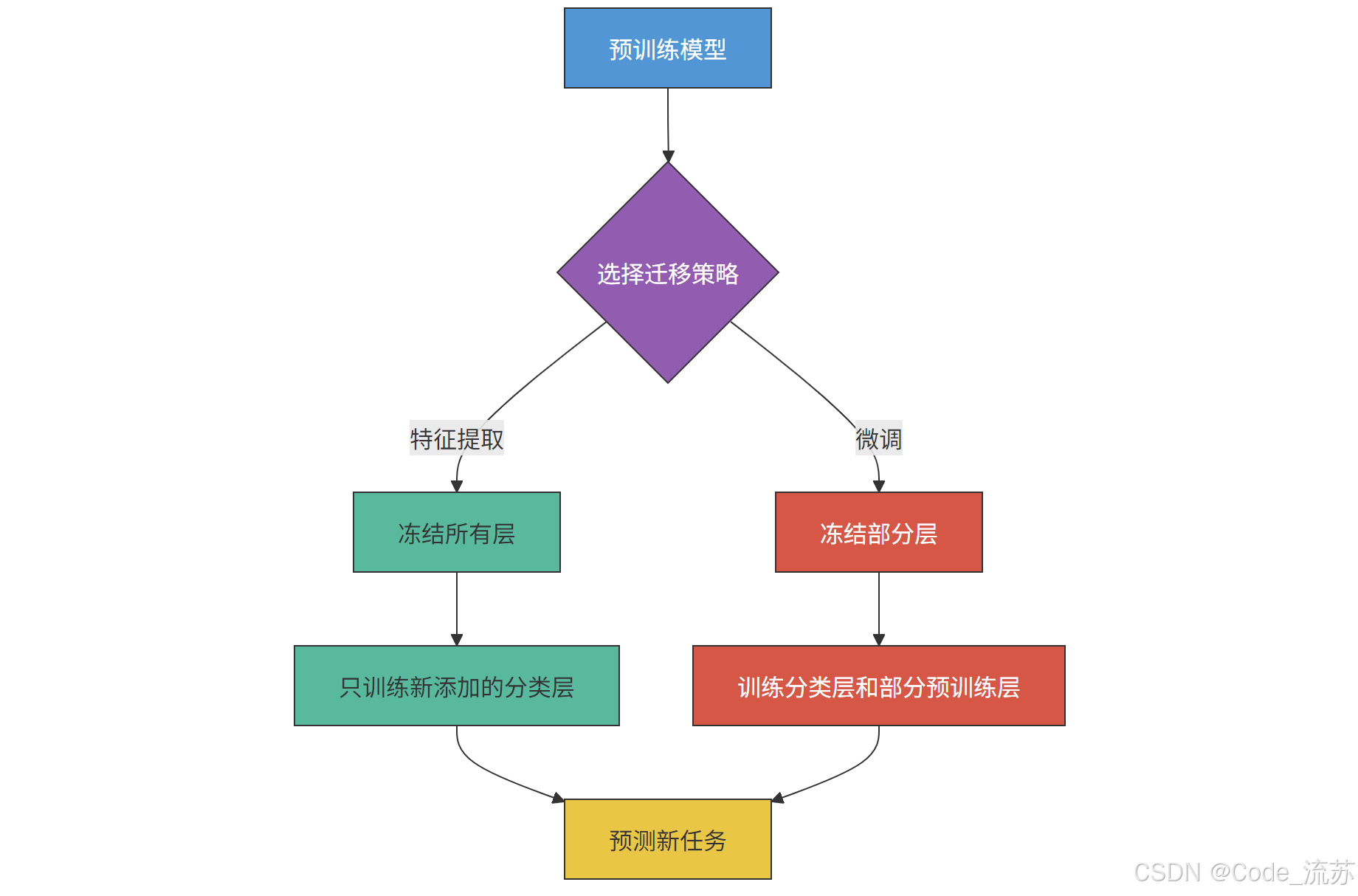
在迁移学习中,我们主要有两种策略来利用预训练模型:特征提取和微调。
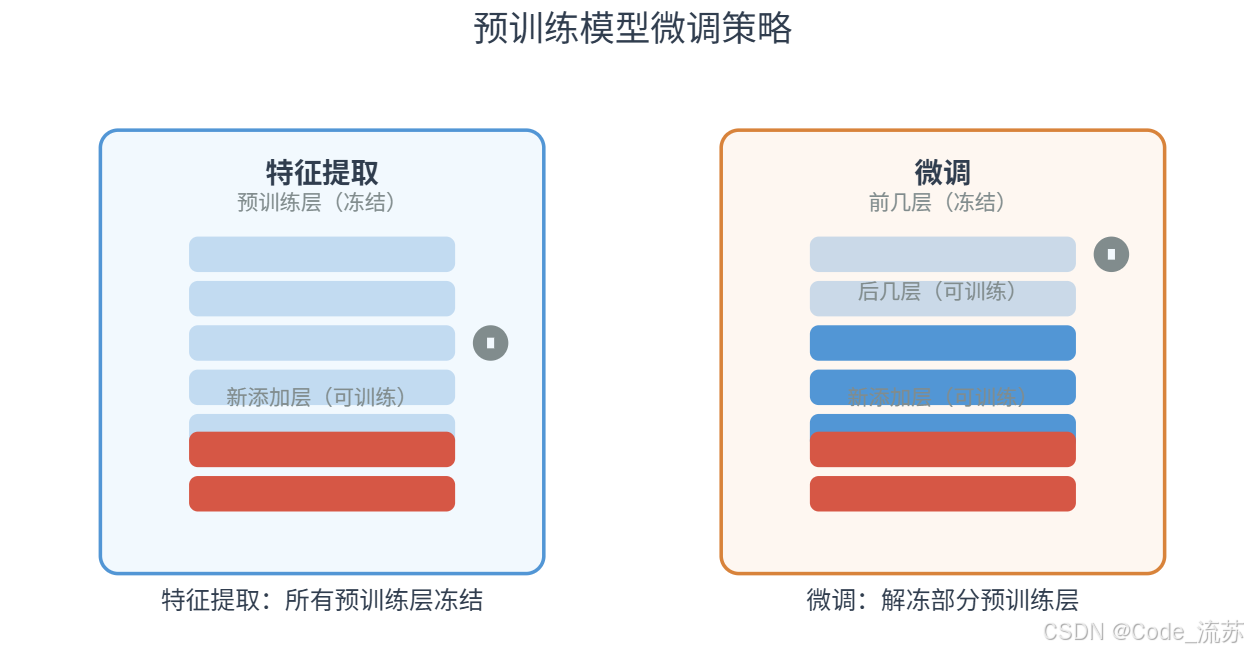
特征提取(Feature Extraction):
在这种策略中,我们将预训练模型视为固定的特征提取器,只训练新添加的层。
- 我们冻结(freeze)预训练模型的所有层,使其权重在训练过程中不更新
- 然后添加自定义的分类层(通常是全连接层),只训练这些新添加的层
- 这种方法适用于新任务与预训练模型的原始任务非常相似的情况,或数据量非常小的情况
微调(Fine-tuning):
在微调策略中,除了训练新添加的层外,我们还会更新预训练模型的部分层。
- 通常冻结预训练模型的前几层(捕获通用特征的层)
- 允许后面的层(捕获更特定任务特征的层)与新添加的分类层一起训练
- 这种方法适用于新任务与原始任务有一定差异,且有足够数据的情况
2. 如何实现层冻结
在TensorFlow/Keras中,冻结层非常简单:
# 冻结预训练模型的所有层
base_model = ResNet50(weights='imagenet', include_top=False)
base_model.trainable = False # 整个模型不可训练# 或者选择性地冻结特定层
base_model = ResNet50(weights='imagenet', include_top=False)
# 冻结前面的层,只训练后面的层
for layer in base_model.layers[:-10]: # 除了最后10层外都冻结layer.trainable = False
3. 微调的最佳实践
微调是一门既需要理论知识又需要经验的艺术,以下是一些最佳实践:
- 分阶段训练:先冻结预训练模型训练几个epoch,然后解冻部分层进行微调
- 较小的学习率:微调时使用比从头训练小10-100倍的学习率,避免破坏预训练权重
- 逐层解冻:从顶层开始逐渐解冻更多层,而不是一次性解冻所有层
- 数据增强:对训练数据应用增强技术,帮助模型更好泛化
- 早停法:使用早停法防止过拟合
四、超参数调优方法
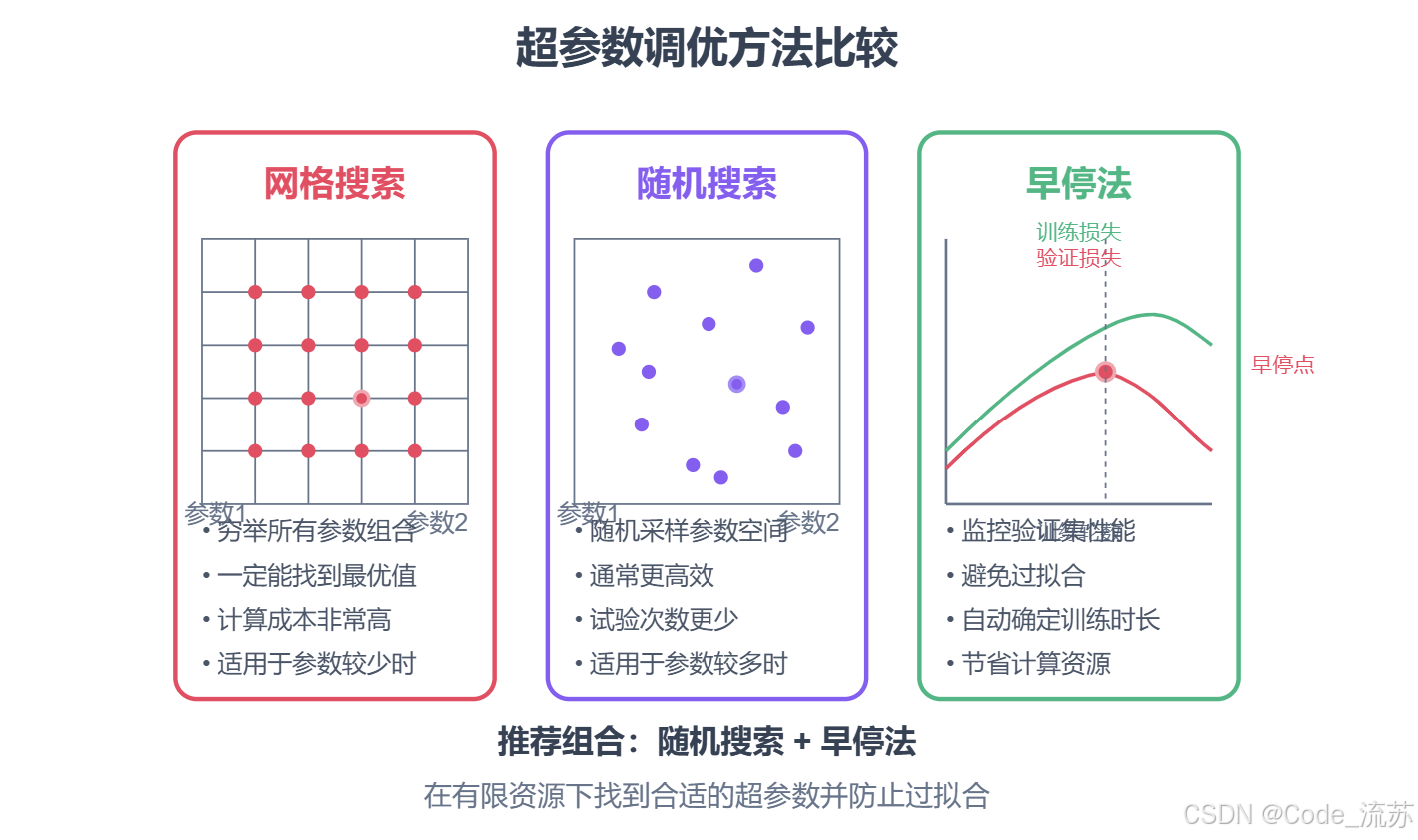
1. 超参数调优的重要性
超参数是在模型训练开始前需要设置的参数,如学习率、批量大小、正则化强度等。在迁移学习中,合适的超参数设置对模型性能至关重要。
与模型权重不同,超参数不能通过梯度下降自动学习,需要我们手动调整或使用自动化方法寻找最佳值。优化超参数可以:
- 提高模型准确率
- 加速训练收敛
- 防止过拟合
- 提升模型泛化能力
2. 网格搜索(Grid Search)
网格搜索是一种穷举搜索方法,它会尝试超参数空间中所有可能的组合。
- 原理:为每个超参数定义一组离散值,然后尝试所有可能的组合
- 优点:简单、易于理解,一定能找到预定义空间中的最佳组合
- 缺点:计算成本高,参数数量增加时组合数量呈指数增长
- 适用场景:超参数较少,计算资源充足
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten# 定义一个创建模型的函数
def create_model(learning_rate=0.001):model = Sequential([base_model,Flatten(),Dense(256, activation='relu'),Dense(num_classes, activation='softmax')])model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),loss='categorical_crossentropy',metrics=['accuracy'])return model# 创建包装的模型
model = KerasClassifier(build_fn=create_model, verbose=0)# 定义超参数网格
param_grid = {'learning_rate': [0.001, 0.01, 0.1],'batch_size': [32, 64, 128],'epochs': [10, 20]
}# 创建网格搜索
grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3)
grid_result = grid.fit(X_train, y_train)# 打印最佳结果
print(f"最佳准确率: {grid_result.best_score_:.4f}")
print(f"最佳参数: {grid_result.best_params_}")
3. 随机搜索(Random Search)
随机搜索不会尝试所有组合,而是随机采样超参数空间中的点。
- 原理:为每个超参数定义一个分布,然后随机采样
- 优点:比网格搜索更高效,通常能以更少的试验次数找到良好的超参数
- 缺点:不保证找到全局最优解
- 适用场景:超参数较多,计算资源有限
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint# 定义超参数分布
param_dist = {'learning_rate': uniform(0.0001, 0.1), # 均匀分布'batch_size': randint(16, 256), # 随机整数'epochs': randint(5, 30)
}# 创建随机搜索
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist,n_iter=20, # 尝试20次随机组合cv=3
)random_result = random_search.fit(X_train, y_train)print(f"最佳准确率: {random_result.best_score_:.4f}")
print(f"最佳参数: {random_result.best_params_}")
4. 早停法(Early Stopping)
早停法不是寻找最佳超参数的方法,而是一种防止过拟合的技术。它通过监控验证集性能,在性能开始下降时提前结束训练。
- 原理:在每个epoch后评估验证集性能,如果连续多个epoch没有改善,则停止训练
- 优点:自动确定合适的训练轮数,防止过拟合,节省计算资源
- 缺点:需要单独的验证集,可能过早停止导致欠拟合
- 实现方式:在Keras中使用
EarlyStopping回调函数
from tensorflow.keras.callbacks import EarlyStopping# 定义早停回调
early_stopping = EarlyStopping(monitor='val_loss', # 监控验证集损失patience=5, # 容忍5个epoch没有改善min_delta=0.001, # 最小改善阈值restore_best_weights=True # 恢复最佳权重
)# 在模型训练中使用
history = model.fit(train_generator,validation_data=validation_generator,epochs=100, # 设置较大的epochs,让早停决定何时结束callbacks=[early_stopping]
)
五、基于ResNet的图像分类实战
1. 项目概述与数据准备
现在,让我们将所学的知识应用到实际项目中!我们将使用ResNet50预训练模型来解决一个图像分类任务。在本例中,我们将构建一个能识别5种不同花卉的分类器。
首先,我们需要准备数据和环境:
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint# 设置随机种子,确保结果可复现
tf.random.set_seed(42)# 数据路径
train_dir = 'flowers/train'
valid_dir = 'flowers/validation'
test_dir = 'flowers/test'# 图像尺寸
img_height, img_width = 224, 224 # ResNet50要求的输入尺寸
batch_size = 32# 数据增强与预处理
train_datagen = ImageDataGenerator(rescale=1./255, # 像素值缩放到0-1范围rotation_range=20, # 随机旋转±20度width_shift_range=0.1, # 水平平移±10%height_shift_range=0.1, # 垂直平移±10%shear_range=0.1, # 剪切变换zoom_range=0.1, # 随机缩放±10%horizontal_flip=True, # 随机水平翻转fill_mode='nearest' # 填充模式
)# 验证集只进行缩放,不做增强
valid_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)# 创建数据生成器
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)valid_generator = valid_datagen.flow_from_directory(valid_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)test_generator = test_datagen.flow_from_directory(test_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)# 获取类别数量
num_classes = train_generator.num_classes
print(f"分类任务目标: {num_classes}类花卉")
2. 构建迁移学习模型
接下来,我们创建一个基于ResNet50的迁移学习模型:
# 加载预训练的ResNet50模型,不包括顶层
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(img_height, img_width, 3))# 添加自定义的顶层
x = base_model.output
x = GlobalAveragePooling2D()(x) # 全局平均池化降维
x = Dense(256, activation='relu')(x) # 全连接层
predictions = Dense(num_classes, activation='softmax')(x) # 输出层# 创建最终模型
model = Model(inputs=base_model.input, outputs=predictions)# 冻结ResNet50所有层
for layer in base_model.layers:layer.trainable = False# 打印模型结构
model.summary()
3. 分两阶段训练模型
我们采用两阶段训练策略:先训练新添加的层,然后进行微调。
# 阶段1: 训练新添加的层
model.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy']
)# 设置回调函数
callbacks = [EarlyStopping(monitor='val_accuracy', patience=5, restore_best_weights=True),ModelCheckpoint('best_model_stage1.h5', monitor='val_accuracy',save_best_only=True)
]# 开始训练
print("阶段1: 训练新添加的层...")
history_stage1 = model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=valid_generator,validation_steps=valid_generator.samples // batch_size,epochs=20,callbacks=callbacks
)# 阶段2: 微调 - 解冻部分ResNet50层
print("阶段2: 微调部分预训练层...")# 解冻ResNet50的最后15层
for layer in model.layers[0].layers[-15:]:layer.trainable = True# 使用更小的学习率重新编译模型
model.compile(optimizer=Adam(learning_rate=0.0001), # 学习率降低10倍loss='categorical_crossentropy',metrics=['accuracy']
)# 更新回调函数
callbacks = [EarlyStopping(monitor='val_accuracy', patience=7, restore_best_weights=True),ModelCheckpoint('best_model_stage2.h5', monitor='val_accuracy',save_best_only=True)
]# 进一步训练
history_stage2 = model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=valid_generator,validation_steps=valid_generator.samples // batch_size,epochs=30,callbacks=callbacks
)
4. 评估模型并可视化结果
最后,我们评估模型性能并可视化训练过程:
# 在测试集上评估模型
test_loss, test_acc = model.evaluate(test_generator)
print(f'测试集准确率: {test_acc:.4f}')# 可视化训练过程
import matplotlib.pyplot as plt# 绘制准确率曲线
plt.figure(figsize=(12, 4))# 阶段1的曲线
plt.subplot(1, 2, 1)
plt.plot(history_stage1.history['accuracy'], label='训练准确率(阶段1)')
plt.plot(history_stage1.history['val_accuracy'], label='验证准确率(阶段1)')
# 阶段2的曲线
epochs_stage1 = len(history_stage1.history['accuracy'])
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['accuracy'])),history_stage2.history['accuracy'],label='训练准确率(阶段2)'
)
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['val_accuracy'])),history_stage2.history['val_accuracy'],label='验证准确率(阶段2)'
)plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history_stage1.history['loss'], label='训练损失(阶段1)')
plt.plot(history_stage1.history['val_loss'], label='验证损失(阶段1)')
# 阶段2的曲线
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['loss'])),history_stage2.history['loss'],label='训练损失(阶段2)'
)
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['val_loss'])),history_stage2.history['val_loss'],label='验证损失(阶段2)'
)plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()plt.tight_layout()
plt.show()# 可视化预测结果
import numpy as np
from tensorflow.keras.preprocessing.image import load_img, img_to_array# 获取类别名称
class_names = list(train_generator.class_indices.keys())# 随机选择测试图像
import os
import randomdef predict_and_visualize(image_path):# 加载并预处理图像img = load_img(image_path, target_size=(img_height, img_width))img_array = img_to_array(img) / 255.0img_array = np.expand_dims(img_array, axis=0)# 预测predictions = model.predict(img_array)predicted_class = np.argmax(predictions[0])confidence = predictions[0][predicted_class]# 显示结果plt.figure(figsize=(6, 6))plt.imshow(img)plt.title(f'预测: {class_names[predicted_class]} ({confidence:.2f})')plt.axis('off')plt.show()# 打印所有类别的置信度for i, class_name in enumerate(class_names):print(f"{class_name}: {predictions[0][i]:.4f}")# 随机选择几张测试图像进行预测
test_images = []
for class_dir in os.listdir(test_dir):class_path = os.path.join(test_dir, class_dir)if os.path.isdir(class_path):images = os.listdir(class_path)if images:random_image = random.choice(images)test_images.append(os.path.join(class_path, random_image))# 展示3张随机图像的预测结果
for img_path in test_images[:3]:predict_and_visualize(img_path)
5. 模型部署与应用
将训练好的模型保存为TensorFlow SavedModel格式,便于部署:
# 保存整个模型
model.save('flower_classifier_resnet50.h5')# 转换为TensorFlow Lite格式(适用于移动设备)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()# 保存TFLite模型
with open('flower_classifier_resnet50.tflite', 'wb') as f:f.write(tflite_model)print("模型已保存为标准格式和TFLite格式,可用于部署!")
恭喜你!你已经成功构建了一个使用迁移学习的图像分类模型。这种技术不仅能在小数据集上获得良好性能,还大大减少了训练时间和计算资源需求。
六、总结与进阶方向
1. 知识回顾
在本文中,我们学习了:
- 迁移学习的基本概念与优势
- 常用预训练模型的特点与适用场景
- 冻结层与微调的策略和最佳实践
- 三种超参数调优方法(网格搜索、随机搜索、早停法)
- 如何使用ResNet50构建实际的图像分类应用
2. 进阶方向
如果你希望进一步探索迁移学习和预训练模型,可以考虑以下方向:
- 更多预训练模型探索:尝试MobileNet(适用于移动设备)、DenseNet(密集连接)等架构
- 领域适应(Domain Adaptation):解决源域和目标域分布不同的问题
- 知识蒸馏(Knowledge Distillation):将大型预训练模型的知识迁移到小型模型
- 跨模态迁移学习:如图像到文本、文本到图像的知识迁移
- 多任务迁移学习:同时学习多个相关任务
3. 实践建议
- 从简单开始:先使用特征提取,再尝试微调
- 数据质量很重要:即使是迁移学习,高质量的数据集仍然是成功的关键
- 充分实验:尝试不同的预训练模型、不同的冻结策略、不同的超参数
- 关注新动态:深度学习领域发展迅速,新的预训练模型和迁移学习技术不断涌现
通过掌握迁移学习和预训练模型,你可以以更少的数据和计算资源构建强大的深度学习应用。这些技术不仅在学术研究中广泛应用,也在工业界产品开发中扮演着重要角色。
📌 今日学习打卡
学习了迁移学习与预训练模型的基本概念
掌握了模型冻结与微调的最佳实践
了解了超参数调优的三种方法
实现了基于ResNet的图像分类案例
明天我们将进入循环神经网络的学习!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!