TGRS | FSVLM: 用于遥感农田分割的视觉语言模型
论文介绍
题目:FSVLM: A Vision-Language Model for Remote Sensing Farmland Segmentation
期刊:IEEE Transactions on Geoscience and Remote Sensing
论文:https://ieeexplore.ieee.org/document/10851315
年份:2025
单位:中南大学

创新点
-
构建 FIT 数据集:首次建立了农田图像-文本对(Farmland Image-Text Pair, FIT)数据集,包括图像的语义描述和分割掩膜,覆盖中国四个省份的多种地貌与气候类型;
-
提出 FSVLM 模型:结合语义分割模型与多模态大语言模型(LLM),采用“embedding-as-mask”策略实现语言引导的图像分割;
-
分析语言描述影响:通过消融实验,发现描述农田属性(如分布、形状等)的文本比描述周边环境的文本对分割精度提升更显著。
【遥感图像分类实战项目】
这才是科研人该学的!基于深度学习的遥感图像分类实战,一口气学完图像处理、特征提取、分类算法、变化检测、图像配准、辐射校正等7大算法!通俗易懂,新手也能学会!![]() https://www.bilibili.com/video/BV1qYvaePEoE/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1qYvaePEoE/?spm_id_from=333.337.search-card.all.click
数据
覆盖区域:
-
中国四个省份的7个城市/地区:
-
湖南:邵阳、衡阳
-
广东:梅州、茂名、湛江
-
安徽:亳州
-
云南:西双版纳
-
-
这些区域地形多样(平原、丘陵、山地、台地),气候类型涵盖亚热带、温带和热带。
-
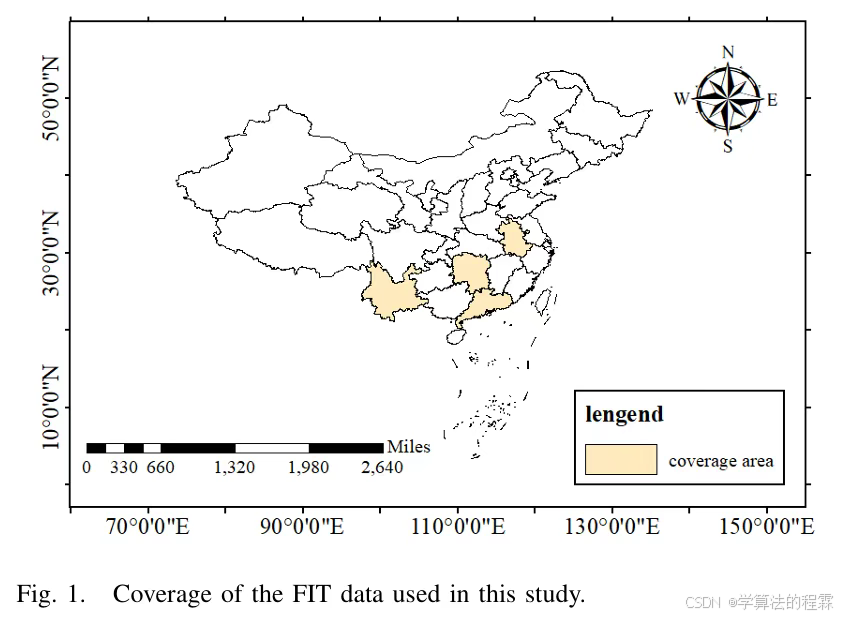
图像数据:
-
来源:Google卫星图像(0.5 米分辨率)
-
时间:涵盖全年不同月份,反映农田物候变化
-
数量:共 7269 张图像,裁剪为 512×512 尺寸
-
预处理:
-
使用 ENVI 进行大气校正和畸变去除
-
使用 Segment Anything Model (SAM) + Labelme 进行半自动标注
-
文本描述:
-
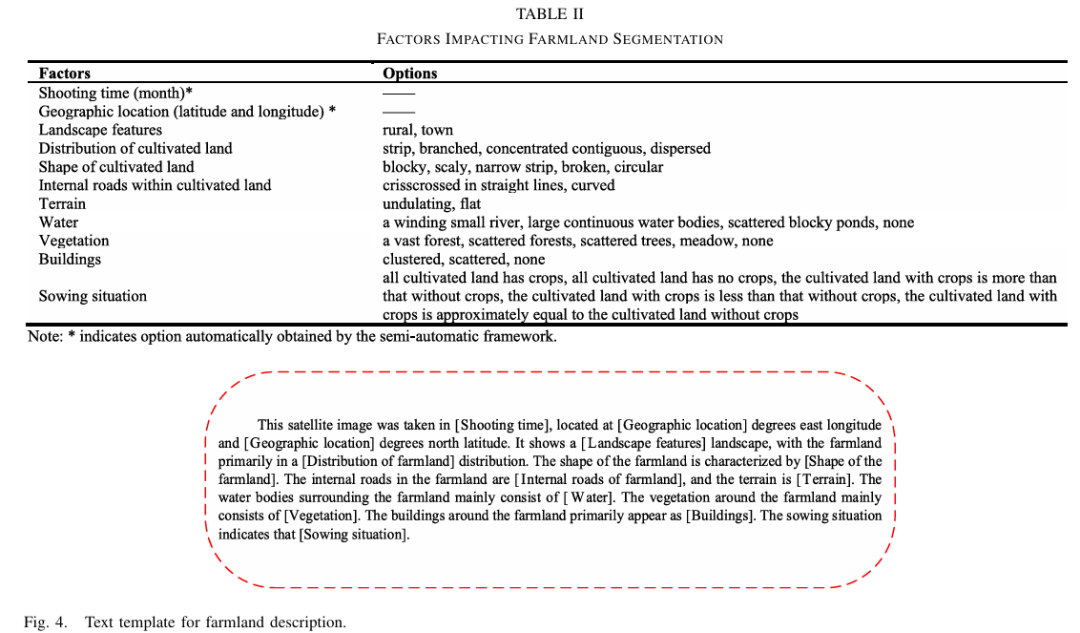
使用 12 个关键因素构建农田描述模板,包括:
-
农田内部:形状、分布、道路、地形等
-
周边环境:水体、建筑、植被分布等
-
时间与地理信息:拍摄时间、地理位置等
-
-
通过模板化选项在 Labelme 中实现半自动化生成,显著降低人工成本。


核心步骤:
-
选取多地区、多气候、多作物的图像,确保数据多样性;
-
利用大语言模型能力,设计基于12个关键描述因子的文本模板;
-
结合图像内容,半自动生成语言描述;
-
使用 Segment Anything Model(SAM)辅助生成图像掩膜,提升标注效率;
-
最终构建图像、掩膜、文本三元组的数据集(FIT)。
2. LoveDA 数据集(用于模型泛化测试)
-
来源:由 RSIDEA 团队构建
-
分辨率:0.3 米
-
地点:南京、常州、武汉
-
用于测试区域泛化能力,仅使用其 rural 部分(包含 2358 张图像)
-
训练中未使用 LoveDA,确保其为“完全未知”的测试集
方法
方法包括FIT数据集构建和FSVLM模型,这里主要介绍模型,FIT见上一节。
FSVLM(Farmland Segmentation Vision-Language Model)是本文提出的一种结合遥感图像与语言描述的多模态模型,旨在提升农田分割的准确性和泛化能力。该模型的设计主要包括两个核心部分:多模态语言模块 和 图像分割模块。
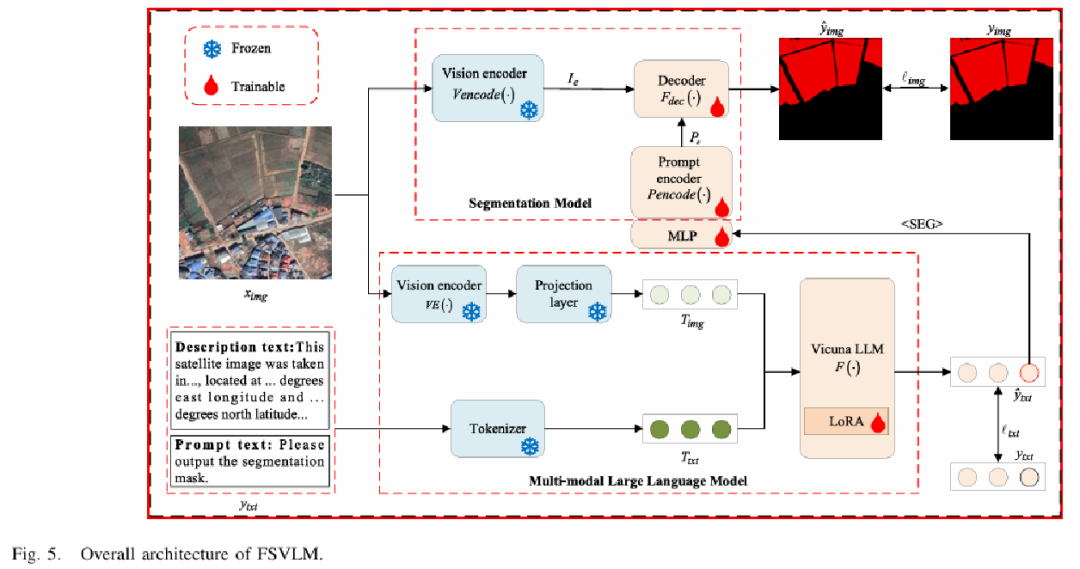
基于深度学习的遥感图像分类实战,一口气学完图像处理、特征提取、分类算法、变化检测 https://www.bilibili.com/video/BV1qYvaePEoE/?spm_id_from=333.337.search-card.all.click&vd_source=75de451a527a341260671f8dfa9534001. 多模态语言模块(基于大语言模型)
https://www.bilibili.com/video/BV1qYvaePEoE/?spm_id_from=333.337.search-card.all.click&vd_source=75de451a527a341260671f8dfa9534001. 多模态语言模块(基于大语言模型)
✅ 主要功能:
-
理解输入的农田描述文本;
-
提取用于引导分割的关键信息;
-
输出可用于图像分割的引导特征。
🧩 结构特点:
-
文本输入:包括提示文本(如“请输出农田分割掩膜”)和图像对应的描述文本(基于12个因子,如形状、水体、地形等);
-
语言模型:使用 LLaVA(一个视觉语言助手)和 Vicuna 作为基础大语言模型;
-
分割标记嵌入:在语言输入中嵌入特殊标记(如
<SEG>),引导模型输出与分割相关的特征; -
特征输出:语言模型输出的嵌入通过多层感知器(MLP)处理,生成语义引导特征,传递给图像模块。
2. 图像分割模块(基于 Segment Anything Model, SAM)
✅ 主要功能:
-
提取图像的空间视觉特征;
-
融合语言引导特征;
-
输出精确的农田掩膜。
🧩 结构特点:
-
视觉编码器:使用预训练的 ViT(Vision Transformer)提取图像的多尺度特征;
-
提示编码器:接收语言模块生成的提示特征,生成稀疏引导信息;
-
解码器:融合视觉特征与提示特征,生成最终的农田分割掩膜;
-
参数优化:视觉编码器参数冻结,仅训练解码器和提示引导模块;为提高效率,使用 LoRA 进行轻量级微调。
模态融合流程
-
图像输入 → 提取图像特征;
-
文本输入(包括提示+描述)→ 语言模型处理,生成分割引导;
-
将图像特征与引导特征融合 → 解码器输出分割结果。
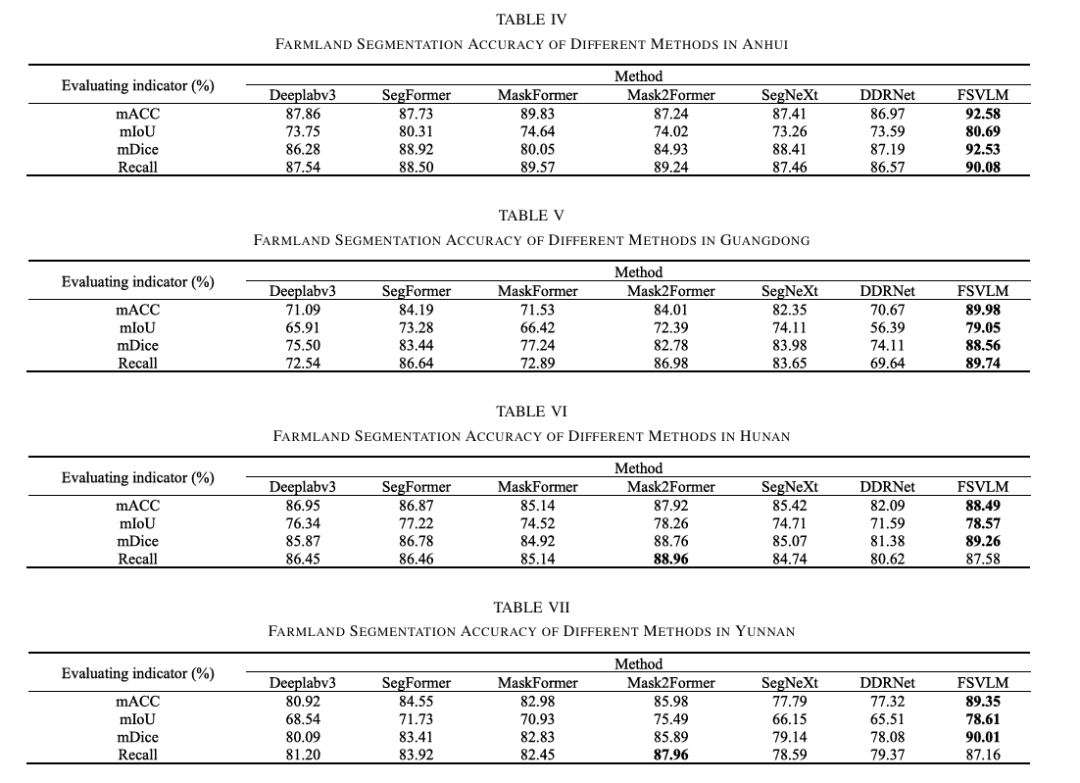
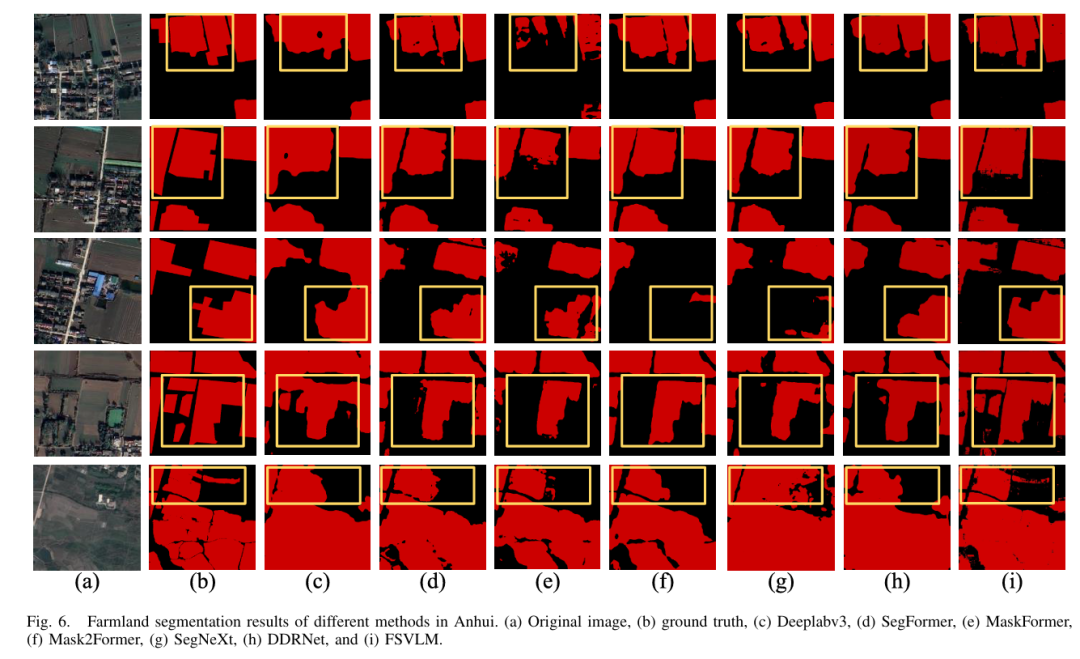
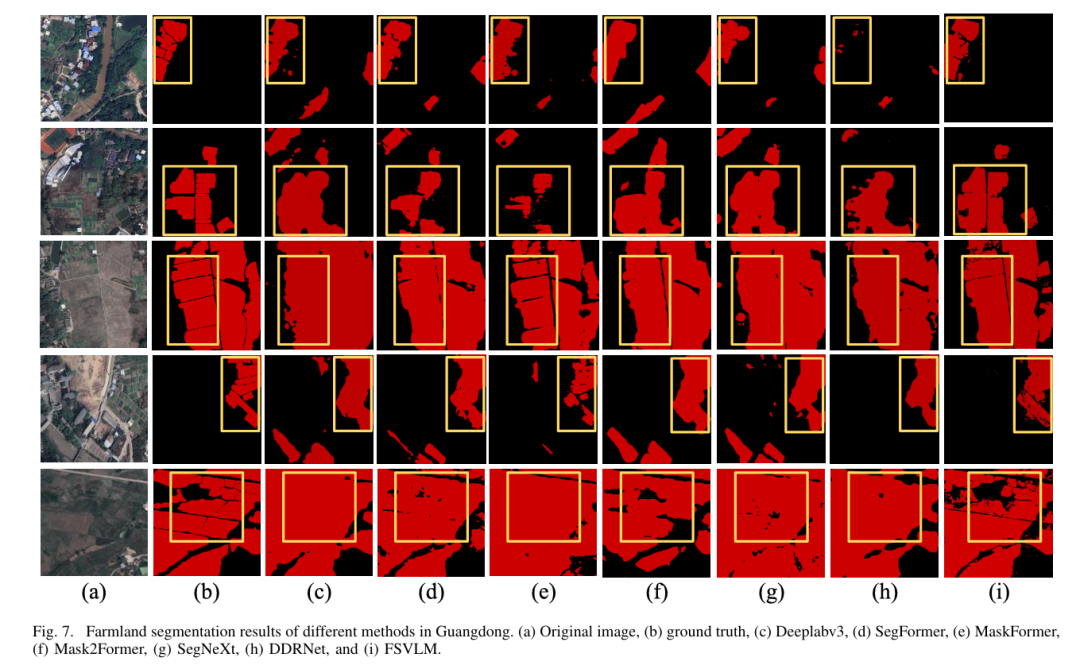
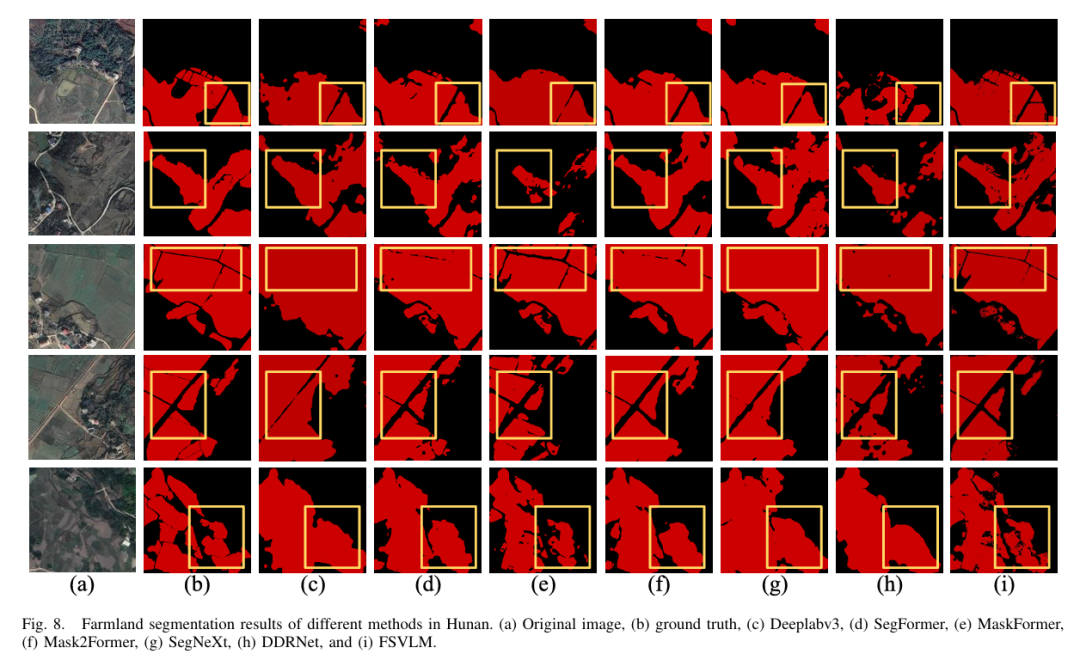
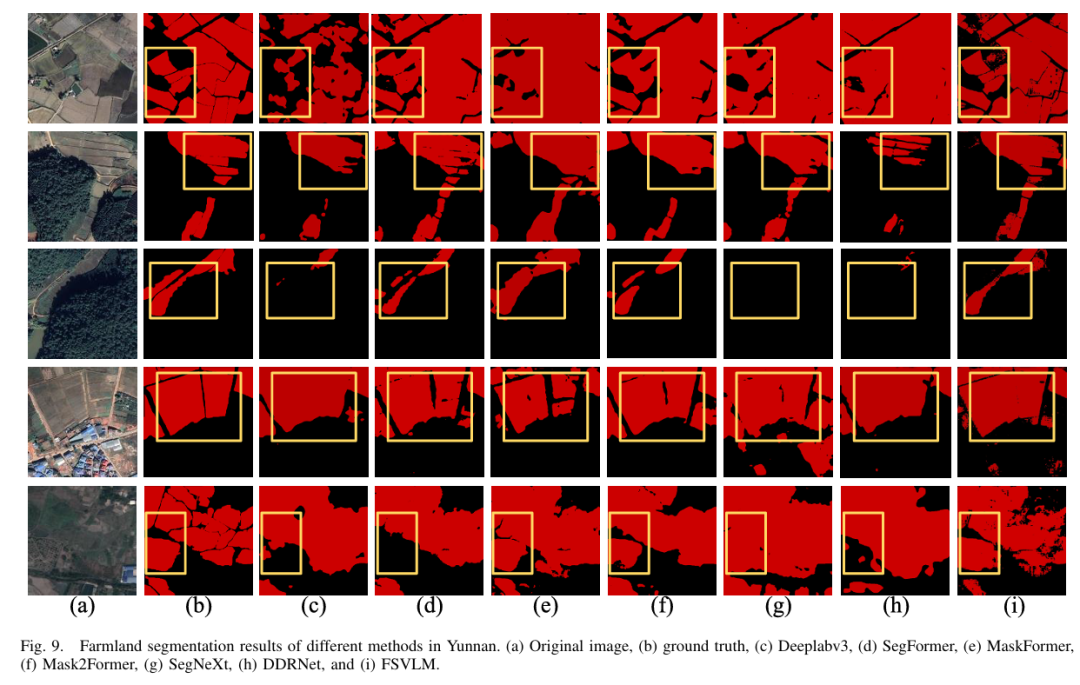
结果与分析
FSVLM 通过融合图像与语言信息,显著提升了遥感农田分割的精度与鲁棒性。实验结果表明,FSVLM 在多区域、多模型对比中均取得最佳表现,具备出色的泛化能力。