大模型微调算法原理:从通用到专用的桥梁
前言
本文聚焦大模型落地中的核心矛盾——理论快速发展与实际应用需求之间的脱节,并系统探讨微调技术作为解决这一矛盾的关键手段。尽管大模型展现出强大的通用能力,但其在垂直领域的直接应用仍面临适配性不足、计算成本高等挑战。微调通过在预训练模型基础上进行针对性优化,平衡通用知识与领域需求,成为实现高效部署的核心技术
1)本文重点:本文系统梳理微调方法论,旨在为研究者和开发者提供技术选型方法论支持;
2)本文缺陷:本文重方法论和思路梳理,不注重数学推导和代码实现;由于笔者才疏学浅,如有错误或疏漏敬请批评指正。
目录
1.大模型在实际使用中的痛点
2.微调为什么能解决问题
3.微调在整个AI开发中的位置
4.微调都有哪些玩法
5.微调技术的工作原理
6.总结与展望
一 大模型在实际使用中的痛点
当我们将GPT-4、deepseek等大语言模型,或是Stable Diffusion等多模态模型真正应用到具体业务场景时,往往会遇到几个典型的"水土不服"现象:
1 "博而不精"的专业短板
通用知识难以精准匹配专业场景,存在“学得广但用不精”的问题;就像一位通晓各科的学霸,在面对具体专业问题时反而显得束手束脚;具体领域的专业问题,往往需要深度的领域知识,术语以及需要遵守的特定规范,预训练模型直接应用于特定领域,往往给出的建议明显缺乏领域针对性,显得"假大空"。
2 "参数巨兽"式的调整困境
千亿级参数的全量调整如同给恐龙做针灸——成本高昂且风险巨大,稍有不慎便会摧毁预训练模型历经海量数据淬炼的通用认知能力。
3 "挑食"的数据需求
行业数据集往往存在小样本、高成本的问题,使预训练模型的调整愈加困难,效果也常常不如人意。
这些挑战就像三道关卡,阻碍着大模型从"实验室明星"转变为"业务能手"。而突破这些关卡的关键,就在于接下来要介绍的模型微调技术——它如同为通用模型量身定制的"职业培训",能让AI快速掌握专业技能,同时保持原有的通用智慧。
二 微调为什么能解决问题
大模型就像个刚毕业的学霸,书本知识很丰富但实际工作经验不足。这时候,微调技术就像是给学霸安排的'岗前特训':
1 专业速成班:保留学霸原有的广博知识,只针对具体工作补充专业技能,使大模型具备T型知识结构;
2 高效学习法:只需要调整很少的核心能力(0.1%-5%),就能快速适应新岗位;
3 立竿见影:经过特训后,处理专业任务的能力能提升20%-50%。
三 微调在AI应用中的'地位'
1 微调在AI应用方法中的定位
就像培养一个人才不能只靠岗前培训一样,要让大模型真正胜任实际工作,我们需要一整套"培养方案"。微调就是其中最重要的培养手段之一,其他方法还包括:
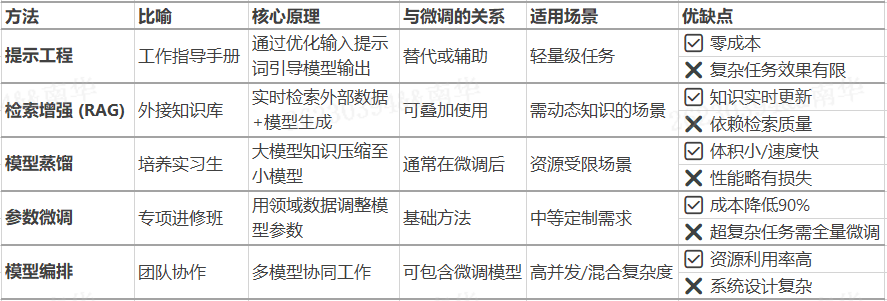
(1)提示词工程: 相当于'工作指导手册',教模型如何理解问题,通过精心设计问题描述和示例,直接引导模型输出专业回答;
(2)检索增强(RAG): 相当于'随身知识库',给模型配备参考资料,结合检索结果生成回答;
(3)模型蒸馏: 相当于培养'实习生',把大模型的知识教给小模型,大模型当老师→小模型当学生→保留90%能力,体积缩小10倍;
(4)模型编排:相当于'团队协作',让多个模型各司其职,像医院"分诊台→专科医生"的工作流程;
就像管理团队要因人施策,处理大模型也要"看菜下饭"——根据预算、硬件、任务复杂度选择最适合的组合拳;方法选型口决:
*试提示工程:轻量级任务优先尝试改提示词
*加RAG:需要实时更新知识的场景必选
*用PEFT:中等定制需求的首选方案
*做蒸馏:必须上手机/边缘设备时采用
*搞编排:面对流量高峰时的性价比之选
2 微调在AI开发流程中的定位
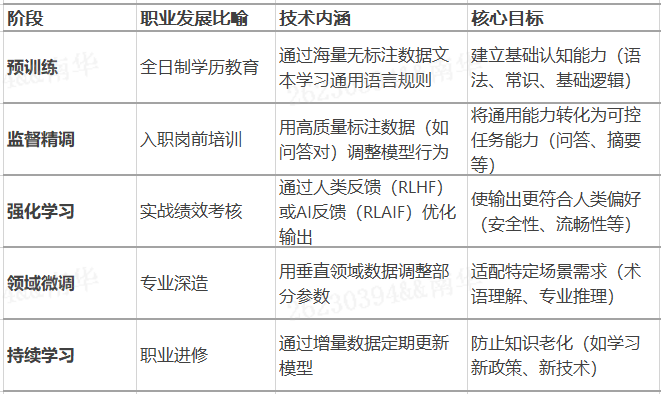
大模型的成长过程就像一个人的职业发展:


(1)预训练:建立底层能力,类似于基础教育,模型学习语言规则 ≈ 学生掌握读写算数,模型吞食TB级文本 ≈ 学生完成12年义务教育课程
(2)监督精调:针对性适应,类似于入职培训,模型学习问答格式 ≈ 新员工掌握公司邮件模板,模型训练1-2周 ≈ 企业入职培训周期
(3)强化学习:结果导向优化,类似于实战考核,RLHF调整输出 ≈ 根据KPI调整工作方式,反馈机制:AI安全评分 ≈ 客户满意度调查
(4)领域微调:垂直突破,类似于专业深造,医疗模型微调 ≈ 医生考专科医师执照,LoRA微调 ≈ 周末在职进修班
(5)持续学习:防知识老化,类似于终身学习,模型增量更新 ≈ 专业人士参加行业研讨会,灾难性遗忘 ≈ 职场技能退化风险
"微调" 是大模型从"通才"蜕变为"专家"的关键步骤,就像一位全科医生通过专科进修成为某一领域的资深专家。通过微调,我们能让大模型在保留广泛认知的同时,精准掌握特定场景的专业技能,最终实现从实验室到真实业务场景的无缝衔接。是模型落地前必不可少的"最后一公里"。