android HashMap和List该如何选择
目录
一,ArrayList
1.1 数组
1.2 扩容
1.3 查询
1.4 插入,删除
1.5 小结
二,LinkedList
2.1 链表
2.2 查找
2.3 插入
2.4 小结
三,HashMap
扩容
四,SparseArray
五,ArrayMap
一,ArrayList
1.1 数组
ArrayList底层是基于数组实现的,数组也就是一种用连续的内存空间存储相同数据类型数据的线性数据结构。其源码如下:
transient Object[] elementData;1.2 扩容
默认情况下,当创建一个新的 ArrayList 时,如果没有指定初始容量,它的初始容量是 10。
private static final int DEFAULT_CAPACITY = 10;//默认数组大小当向ArrayList中添加元素,且当前数组已满时(即当前元素数量等于数组容量),ArrayList 会自动扩容。扩容是通过创建一个新的数组并将旧数组的元素复制到新数组来实现的。默认的扩容策略是新容量为旧容量的 1.5 倍(即旧容量加上旧容量的 50%)。例如,如果当前容量是 10,新容量将是 15。
从 Java 7 开始,为了提高性能,扩容策略有所改变。在添加元素时,如果添加元素后的大小超过当前容量的 75%,则会进行扩容,扩容大小为当前容量的 1.5 倍。
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);
}1.3 查询
ArrayList 是 Java 中的一个动态数组实现,它继承自 AbstractList 并实现了 List 接口。由于其内部实现是基于数组的,所以在某些操作上,特别是在随机访问元素时,它的性能通常优于链表结构。ArrayList 支持快速的随机访问。当我们通过索引访问元素时(例如 get(index)),因为数组是连续存储的,可以直接通过计算偏移量来访问任何位置的元素,这通常是非常快的(接近 O(1) 的时间复杂度)。
但是当我们需要查找数组中是否存在某个特定元素(例如使用 contains(Objecto) 或 indexOf(Object o) 方法)时,ArrayList 的性能就不那么好了。这是因为这些操作通常需要遍历整个列表来查找元素,其时间复杂度接近 O(n),其中 n 是列表的大小。
1.4 插入,删除
先来看看插入元素的代码:
public void add(int index, E element) {if (index > size || index < 0)throw new IndexOutOfBoundsException(outOfBoundsMsg(index));ensureCapacityInternal(size + 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index + 1,size - index);elementData[index] = element;size++;
}可以看到插入元素是通过移动整个数组来实现,其原理如下图:
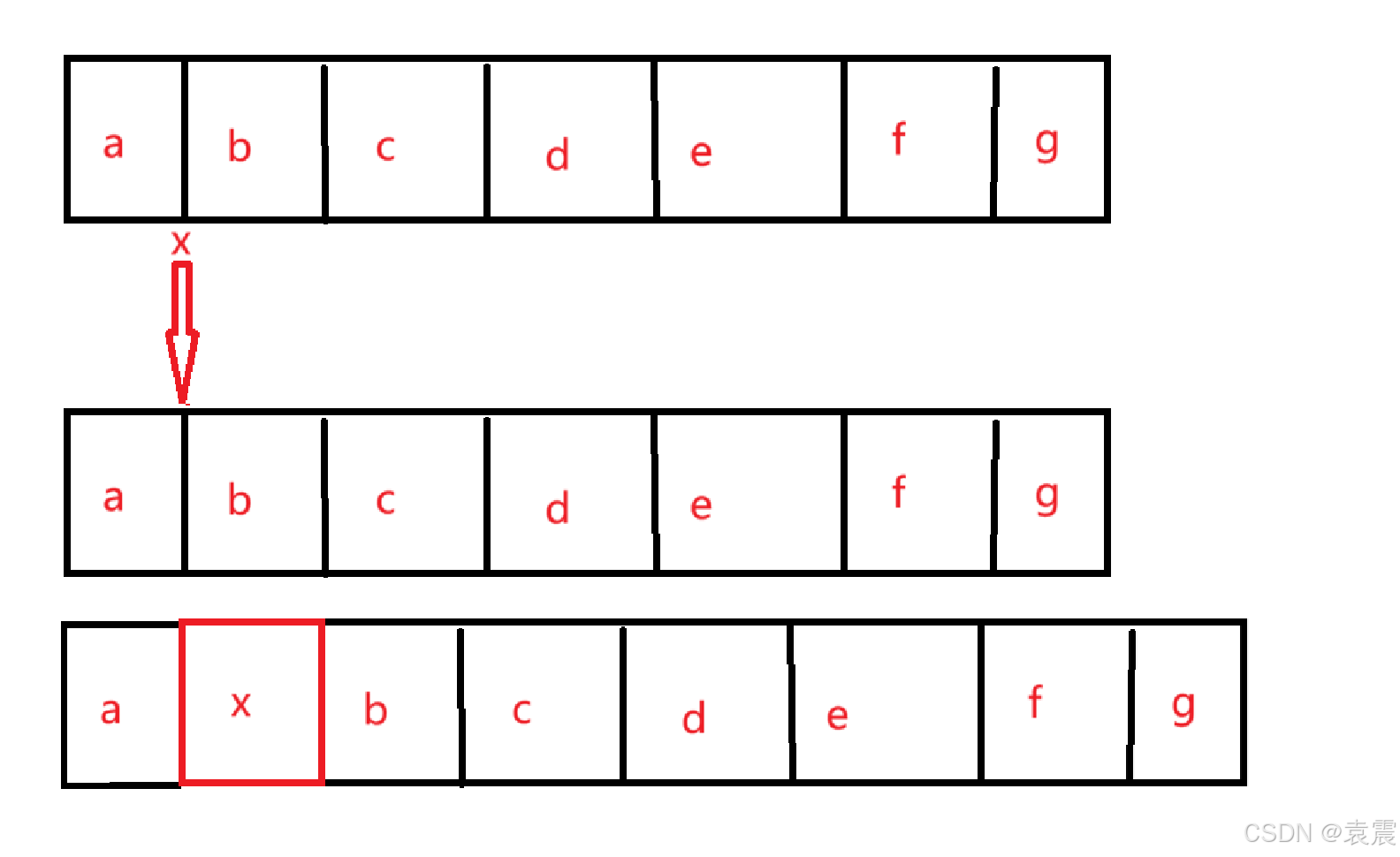
所以ArrayList的插入和删除操作是很消耗性能的。
1.5 小结
结合以上我们可以看出,ArrayList的特点就是查询快,插入和删除慢
二,LinkedList
2.1 链表
LinkedList是基于链表实现的,链表是一种常见的数据结构,用于存储一系列的元素。与数组相比,链表在内存中的存储方式有所不同。
链表的内存管理是通过指针实现的。每个节点仅知道其直接后继节点的地址。当删除一个节点时,通常只需要断开该节点的next指针即可,而不需要移动其他节点的内存位置。这使得内存的分配和释放非常灵活和高效。
2.2 查找
先看以下LinkedList的源码:
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}从上面源码可以看出,查找时需要遍历,所以性能损耗比较大。
2.3 插入
我们看一下插入的图片:
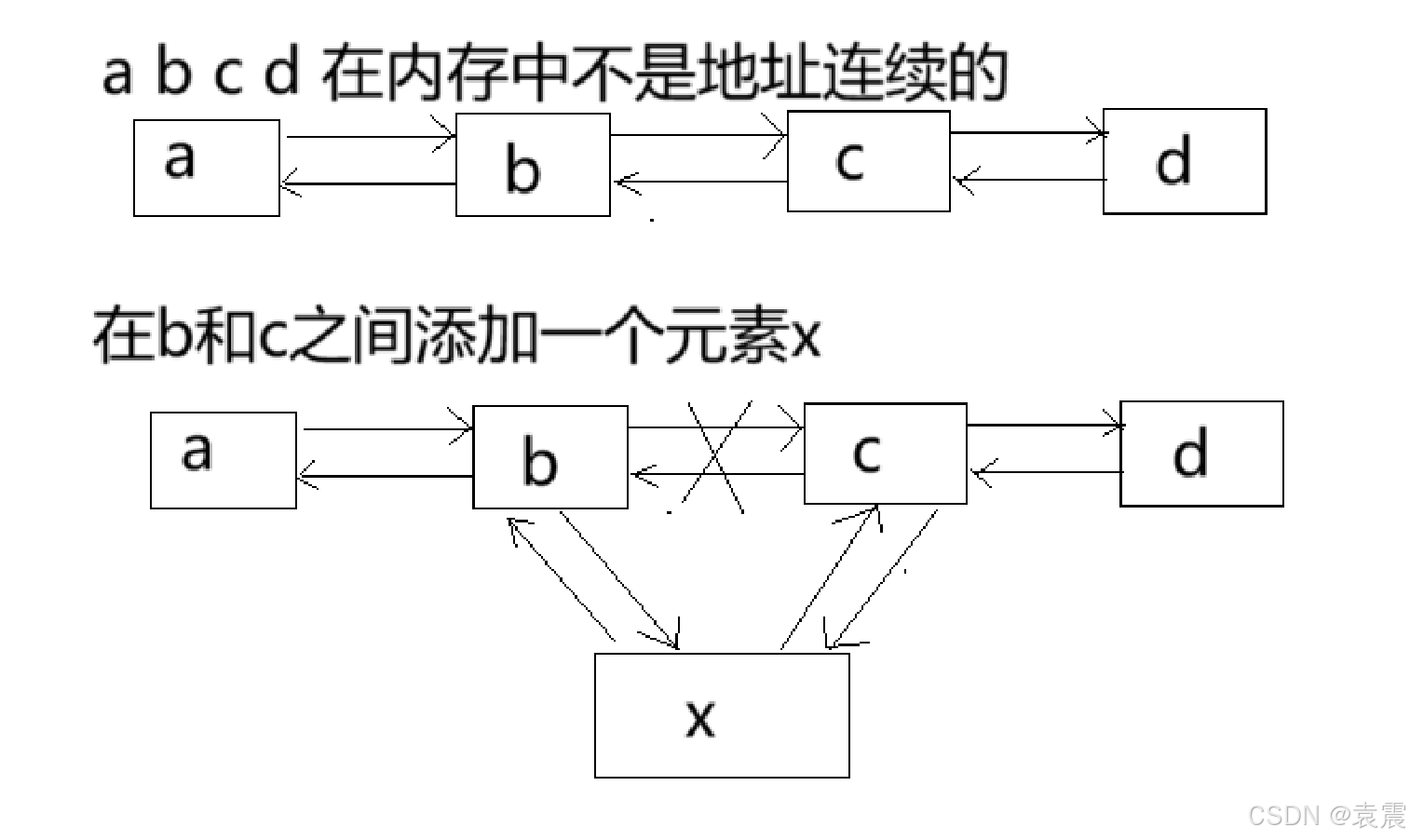
从上面这个图片可以看出,插入时只需要将前后元素的指针指向对应元素即可。所以链表的结构在执行插入和删除的操作时效率是非常高的。
2.4 小结
结合以上我们可以看出,LinkedList的特点就是查询慢,插入和删除快
三,HashMap
从上面我们可以看出ArrayList和LinkedList各自有各自的优缺点,那么有没有一种数据结构查询和插入删除都快呢?
下面我们要说的HashMap就满足上面的要求。
在JDK1.7之前,HashMap的数据结构为数组加链表的结构
在JDK1.8之后,HashMap的数据结构为数组加链表加红黑树的结构
先看下面HashMap的数据结构图片:
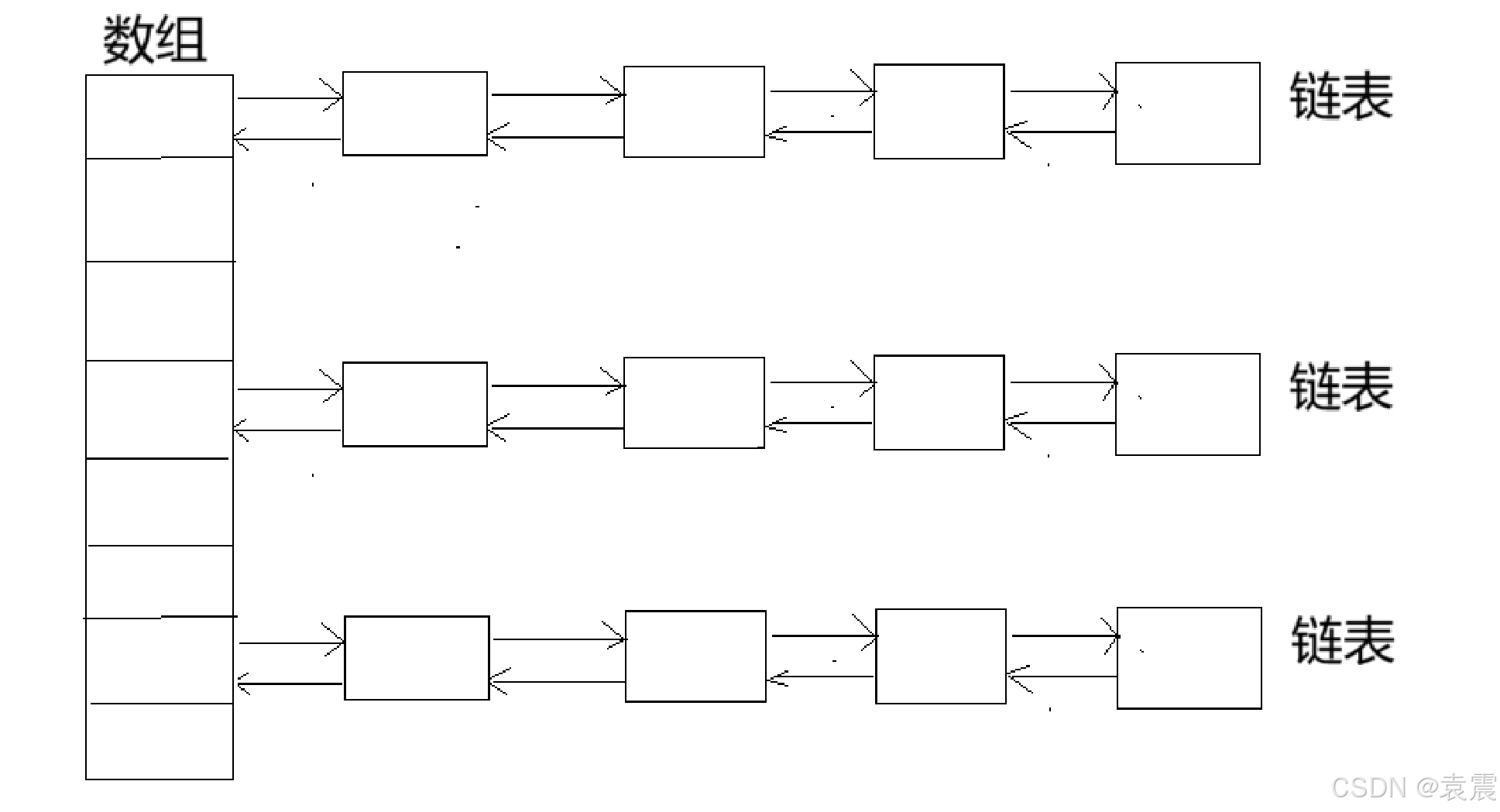
这就是数组加链表的结构
那么一个数据是如何插入到HashMap中的?下面我们来分析下。
首先,我们先看看源码:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这段代码是得到一个对象的Hash值,并且通过 h ^ (h >>> 16) 将哈希码的高16位与低16位进行异或操作。这样做的目的是将高位的信息融入低位,提升低位的随机性。哈希表通常用 (n-1) & hash 计算索引(n 是桶的数量,为2的幂),这仅利用了哈希码的低位。若低位重复率高,会导致冲突。通过异或混合高位,使低位同时受高位影响,分布更均匀。
下面我们通过图片来演示下:

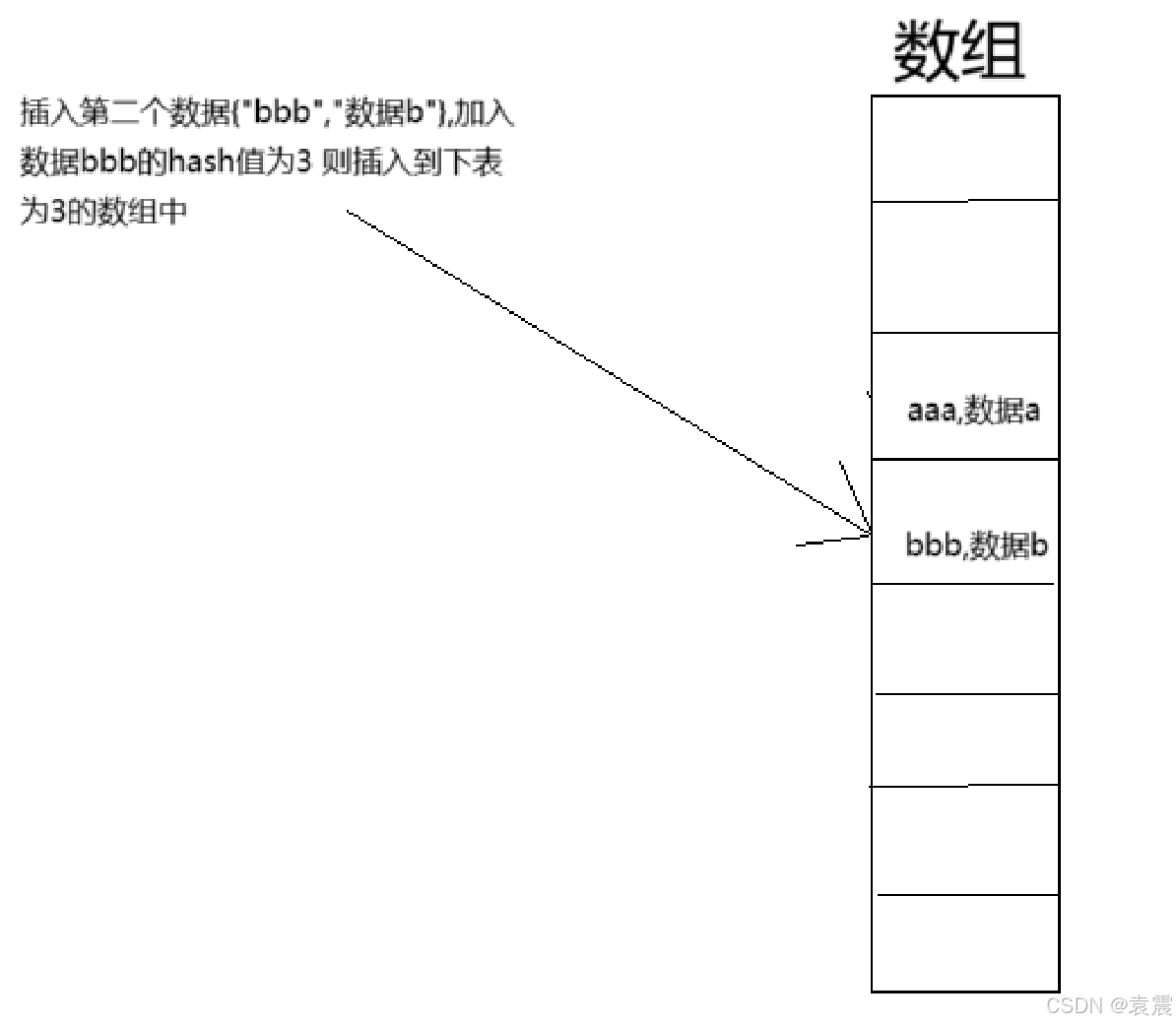
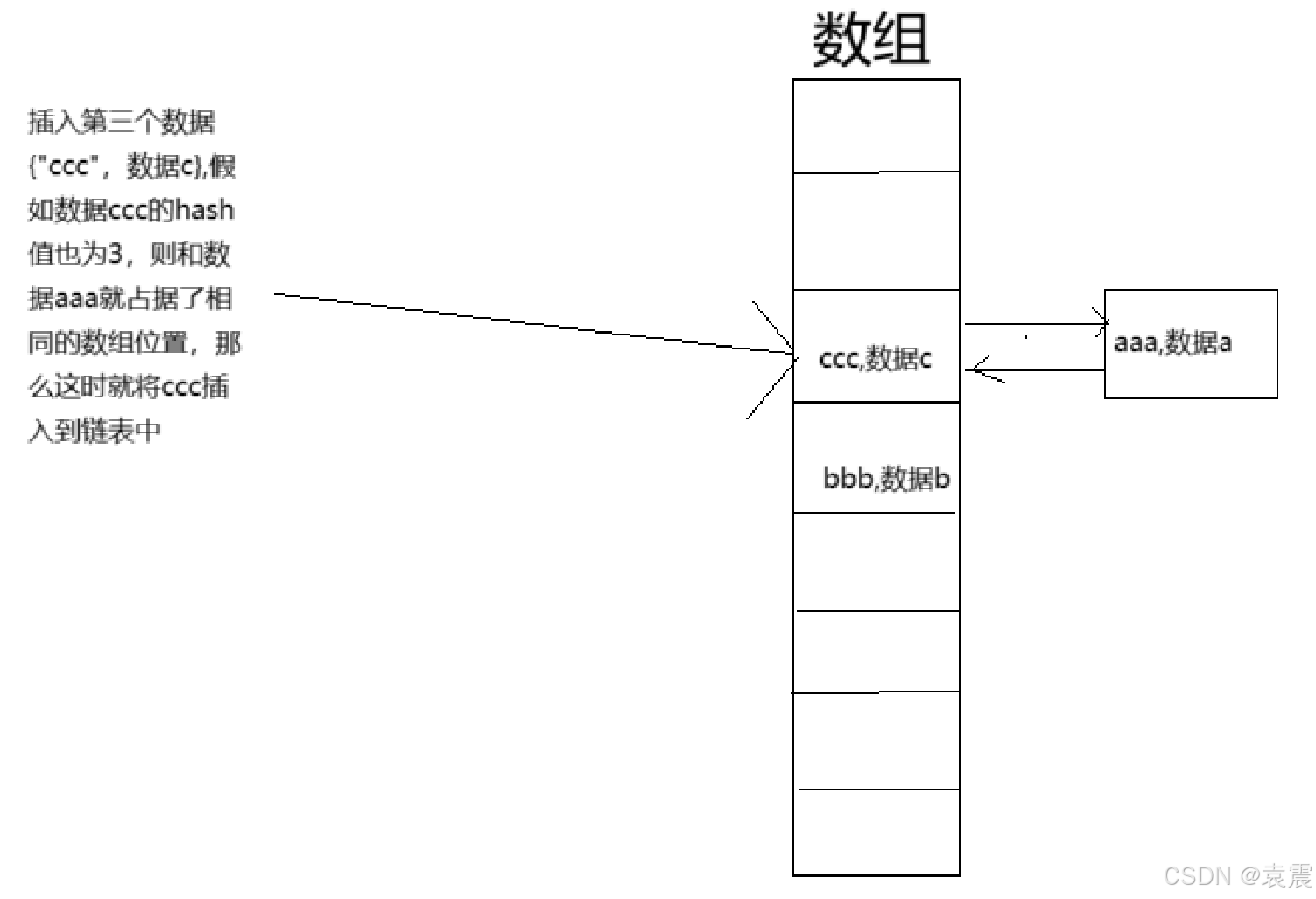
上面这种情况就是所谓的hash碰撞,hashmap就是通过链表解决了hash碰撞的问题。
扩容
首先我们需要理解一下为什么需要扩容?
如果不扩容,hash碰撞会越来越多,必然会导致链表的长度越来越长,这时查询的效率就会非常慢,这时就需要增加数组的长度来避免链表的长度过长。
HashMap的扩容我们需要了解几个概念:
1,负载因子,一个决定 HashMap 扩容策略的参数。默认值是 0.75。它用于衡量 HashMap 中使用的空间与实际容纳的空间之间的比率。当 HashMap 中的元素数量超过这个比率所计算的阈值时,它将扩容。
static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子默认值0.75
final float loadFactor;//负载因子public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
} 2,扩容阈值,即当 HashMap 中的元素数量达到该值时,将触发扩容。阈值由 capacity * load factor 计算得出。它帮助管理 HashMap 的容量和负载因子,防止在高负载下性能下降。
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;比如一个数组的长度是16,负载因子是0.75 那么阈值就是16 * 0.75 =12
当元素的个数大于12时,就会触发hashmap的扩容机制。
这里需要注意一下的是,数组的长度我们最好使用的是2的次幂。
为什么是2的次幂呢?
我们计算hash值时之前使用的是 hashcode & (length -1)
比如一个数组的长度是16 ,hashCode 是110 那么计算就是:
0110
1111
结果为0110 它的三位110都生效了
假如一个数组的长度是10 ,hashCode是110 那么计算就是:
0110
1001
结果是0000 但是中间两位00得到的结果永远都是0,其实是不生效的,这样就会增加hash碰撞的概率。
那么hashmap有没有什么缺点呢?
其实是有的,当我们扩容的时候,会有25%的空间被浪费了,其实就是用空间来换时间。
但是空间对android来说是非常重要的。这一点还是需要了解的。
四,SparseArray
SparseArray从字面上可以理解为松散不连续的数组。虽然叫做Array,但它却是存储K-V的一种数据结构。其中Key只能是int类型,而Value是Object类型。
其数据结构如下:
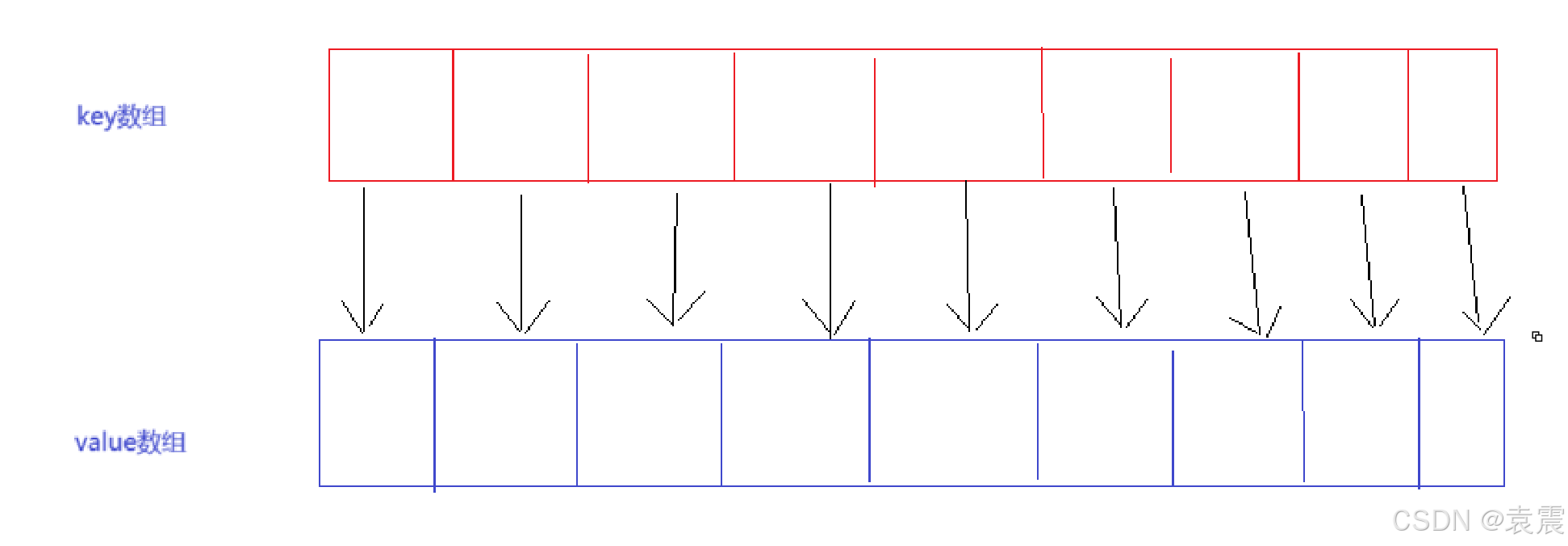
它的key是从小到大排序的有序数组,既然是有序数组,那么它的查找就是使用的二分法,这样就提升了查找的效率。
而且它有一个特点就是越用越快,为什么呢?因为它删除某个元素后,会将它的key标记为delete。当下次再有相同key的元素插入时,就可以直接插入到标记的位置,提高了效率。
但是它还有一个缺点,就是key必须是int类型,这样就限制很大。
五,ArrayMap
ArrayMap的内部结构同SparseArray一样,但是它的key没有必须是int。这样既提高了效率又提高了灵活性。比较推荐andaroid开发者使用ArrayMap。