一、数据仓库基石:核心理论、分层艺术与 ETL/ELT 之辨
随着企业数据的爆炸式增长,如何有效地存储、管理和分析这些数据,从中提炼价值,成为现代企业的核心竞争力之一。数据仓库 (Data Warehouse, DW) 正是为此而生的关键技术。理解其基础理论对于构建高效的数据驱动决策体系至关重要。
一、数据库 vs 数据仓库:日常运营与战略决策的“左右手” 🤝
虽然数据库 (Database, DB) 和数据仓库 (Data Warehouse, DW) 都存储数据,但它们的设计目标、应用场景和特性有着本质的区别。
-
数据库 (DB) - 面向日常运营 (OLTP - Online Transaction Processing)
- 核心目标:支持企业的日常业务操作,如订单处理、库存管理、客户注册等。
- 数据特点:
- 实时性高:数据频繁更新,反映当前最新状态。
- 原子性操作:强调事务的ACID特性 (原子性、一致性、隔离性、持久性)。
- 规范化程度高:通常采用三范式等设计,减少数据冗余,保证数据一致性。
- 查询特点:多为简单的、点状的查询和小范围的增删改操作。
- 用户群体:业务人员、操作员、应用程序。
- 数据量级:通常相对较小 (GB级别)。
-
数据仓库 (DW) - 面向分析决策 (OLAP - Online Analytical Processing)
- 核心目标:支持管理层的战略决策和业务分析,如趋势分析、市场洞察、绩效评估等。
- 数据特点:
- 历史性数据:数据通常是从多个业务系统 定期抽取、清洗、转换而来,积累了大量历史记录。
- 主题集成:数据围绕特定的业务主题 (如客户、产品、销售) 进行组织和集成。
- 相对稳定:数据一旦写入数仓,一般不轻易修改,主要用于查询分析。
- 非规范化/反规范化:为了提高查询性能,可能存在一定的数据冗余,采用星型模型或雪花模型。
- 查询特点:多为复杂的、聚合性的查询,涉及大量数据的扫描和分析。
- 用户群体:数据分析师、业务决策者、管理层。
- 数据量级:通常非常庞大 (TB、PB级别)。

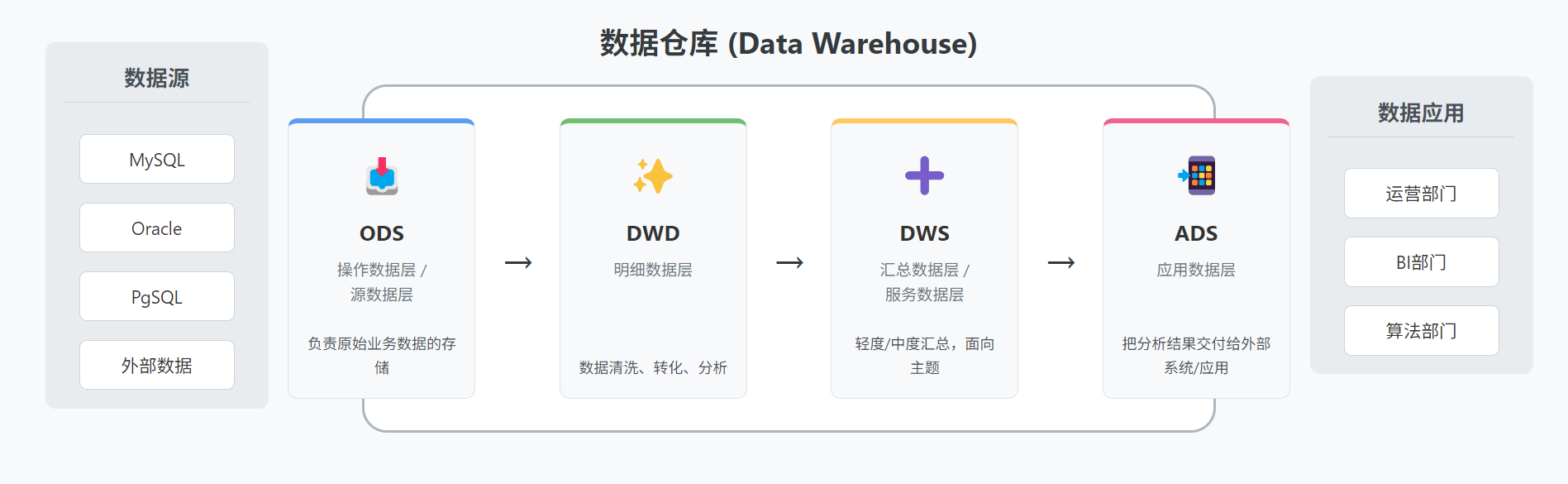
二、数据分层的艺术:构建清晰、高效的数仓架构 🏛️
直接将来自各个业务系统的原始数据 堆砌在一起进行分析,往往会导致 混乱、低效和难以维护。因此,现代数据仓库通常采用分层架构的思想。
-
典型的数据分层架构 (以常见的三/四层为例):
-
ODS (Operational Data Store) - 操作数据层 / 数据引入层
- 作用:作为数据仓库的数据入口,直接对接 各个业务系统 (如ERP, CRM, SCM等)。
- 数据特点:尽可能 保留业务系统原始数据的原貌 (或只做少量格式转换和清洗),数据粒度与源系统保持一致。ODS层的数据通常是临时的、可覆盖的,主要用于后续数据抽取和加工。
- 好处:解耦数据仓库与源业务系统,减少对源系统的直接访问压力。
-
DWD (Data Warehouse Detail) - 数据明细层 / 公共维度层
- 作用:对 ODS 层的数据进行清洗、转换、规范化处理,去除脏数据,统一数据格式。同时,在此层构建企业级的公共维度模型 (如时间维度、地区维度、产品维度等)。
- 数据特点:数据相对干净、一致,粒度仍然较细,但已经过初步的整合和标准化。此层数据通常会长期保留。
- 好处:为后续的数据聚合和分析提供高质量、一致性的明细数据基础。
-
DWS (Data Warehouse Summary/Service) - 数据汇总层 / 服务层
- 作用:基于 DWD 层的数据,按照不同的业务主题或分析维度进行轻度或中度的聚合操作,形成面向特定分析场景的宽表或汇总表。
- 数据特点:数据粒度比 DWD 层更粗,包含了预计算的指标和统计值。
- 好处:提高常见分析查询的性能,减少重复计算。
-
ADS/APP (Application Data Store / Application Layer) - 应用数据层 / 数据集市层
- 作用:直接面向 最终用户或应用 (如报表、BI工具、数据挖掘模型等)。根据具体的业务需求,从 DWS 或 DWD 层抽取数据,进行高度聚合或个性化的数据组织,形成数据集市 (Data Mart) 或定制化的数据产品。
- 数据特点:数据高度定制化、面向特定应用,查询性能极高。
- 好处:满足不同业务部门或应用的个性化数据需求,提供 快速、便捷的数据服务。
-
- 数据分层的好处 ✨:
- 清晰的结构:使数据流向和数据关系更加清晰明了,易于理解和维护。
- 数据血缘追踪:方便追踪数据的来源和加工过程,快速定位数据问题。
- 减少重复开发:公共的计算逻辑 (如维度处理、基础指标计算) 可以在底层 统一完成,避免在不同应用中 重复建设。
- 提高数据质量:通过逐层清洗和校验,保证最终应用层数据的准确性和一致性。
- 提升开发效率:不同层次的开发人员可以并行工作,专注于各自负责的层面。
- 屏蔽底层复杂性:上层应用可以直接使用已经加工好的数据服务,无需关心底层的复杂数据处理逻辑。
三、ETL vs ELT:数据流转的两种“姿势” 🌊
将数据从源系统 加载到数据仓库,并进行必要的转换,是数仓建设的核心环节。ETL 和 ELT 是两种常见的数据集成模式。
-
ETL (Extract - Transform - Load) - “先处理,后加载”
- Extract (抽取):从源数据库或文件系统中抽取所需数据。
- Transform (转换):在专门的 ETL 服务器或引擎上对抽取出来的数据进行清洗、格式转换、数据校验、业务规则应用、数据集成等复杂操作。
- Load (加载):将转换后的高质量数据 加载到目标数据仓库中。
- 特点:
- 数据转换在加载到数仓前完成。
- 需要一个独立的处理引擎 (ETL 工具或平台)。
- 适合数据转换逻辑复杂、数据量中等的场景。
- 传统数据仓库中较为常见。
-
ELT (Extract - Load - Transform) - “先加载,后处理”
- Extract (抽取):从源系统中抽取原始数据。
- Load (加载):将原始数据 (或只做少量预处理) 直接加载到数据仓库 (通常是数据湖或 Staging Area) 中。
- Transform (转换):利用数据仓库本身 (如基于 SQL 的引擎、Spark 引擎等) 的计算能力,在数据仓库内部对已加载的数据进行清洗、转换和加工。
- 特点:
- 数据转换在加载到数仓后,利用数仓的计算资源完成。
- 可以处理 更大规模的原始数据。
- 更适合 云数据仓库和大数据平台 (如 Hadoop, Spark),这些平台本身就具备强大的分布式计算能力。
- 灵活性更高,可以先存储原始数据,后续根据不同需求进行多次不同的转换和分析。

四、总结 💡
数据仓库是企业数据资产的重要组成部分。理解其与日常操作数据库的区别,掌握数据分层的设计思想和优势,以及辨析 ETL 与 ELT 的不同模式,是构建一个 健壮、高效、可扩展的数据仓库的前提。这些基础理论将指导我们在实际项目中做出更明智的架构选择和技术决策,最终让数据为业务 创造更大的价值。