LINUX CFS算法解析
文章目录
- 1. Linux调度器的发展历程
- 2. CFS设计思想
- 3. CFS核心数据结构
- 3.1 调度实体(sched_entity)
- 3.2 CFS运行队列(cfs_rq)
- 3.3 任务结构体中的调度相关字段
- 4. 优先级与权重
- 4.1 优先级范围
- 4.2 权重映射表 (`prio_to_weight[]`)
- 优先级计算
- 4.3.1. `static_prio` (静态优先级)
- 4.3.2. `normal_prio` (普通优先级 / 规范化优先级)
- 4.3.3. `prio` (动态优先级)
- 4.3.4. `rt_priority` (实时优先级)
- 总结与关系
- 5. CFS关键算法实现
- 5.1 虚拟运行时间计算 (`update_curr`)
- 5.2 进程选择 (`pick_next_task_fair`)
- 5.3 进程入队 (`enqueue_entity` / `enqueue_task_fair`)
- 5.4 最小虚拟运行时间更新 (`update_min_vruntime`)
- 6. 调度器调用入口
- 6.1 `schedule()`函数
- 6.2 周期性调度 (`scheduler_tick`)
- 7. CFS与其他调度方案对比
- 7.1 CFS vs O(1)调度器
- 7.2 CFS vs BFS
- 8. 实时调度与CFS的关系
- 9. 组调度机制 (Group Scheduling)
- 10. 多核负载均衡 (Multicore Load Balancing)
- 11. 总结与展望
- 参考
CFS 调度器旨在为每个进程提供 “公平” 的 CPU 份额。“公平” 并不意味着每个进程获得相等的时间,而是指与 它们的优先级成比例的时间。
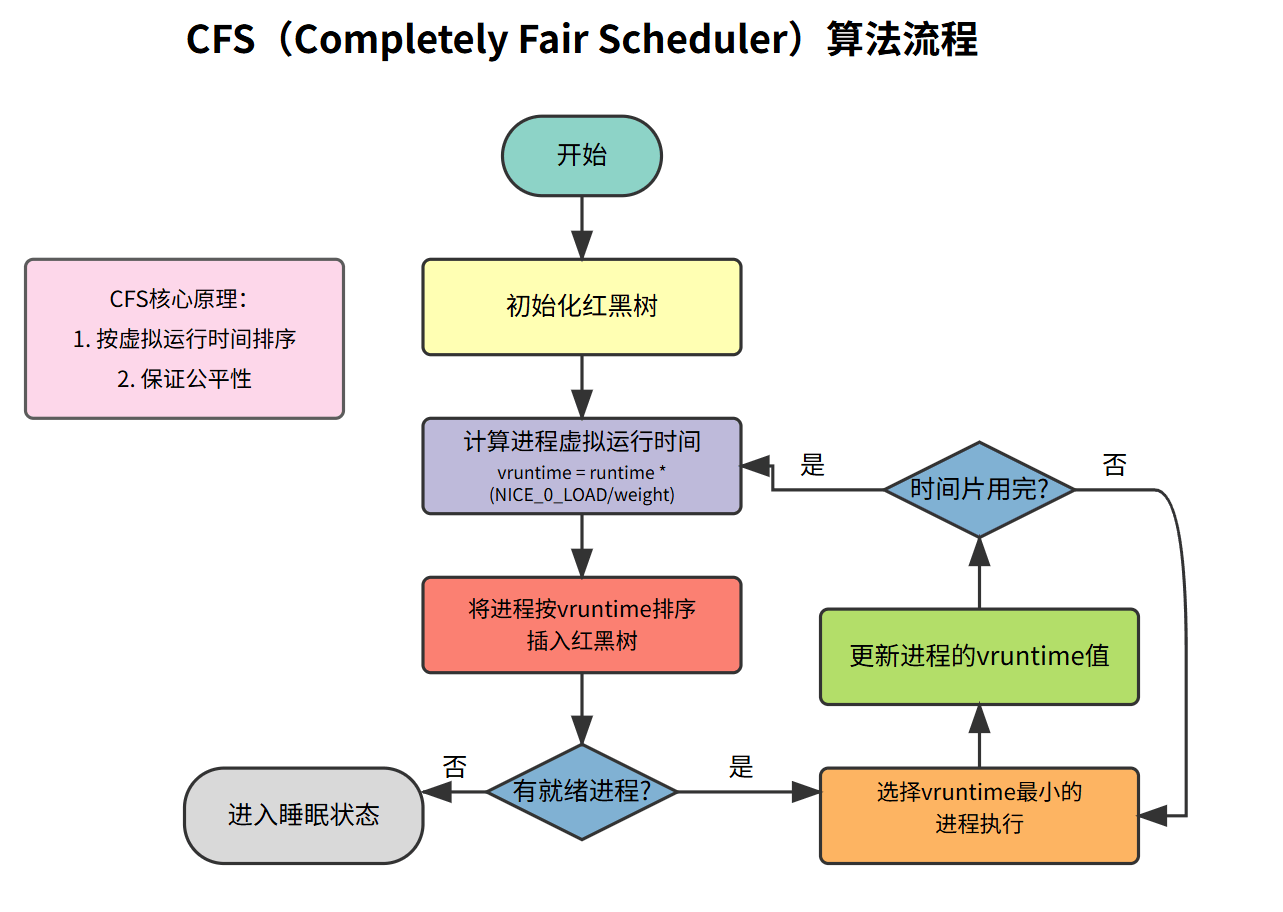
- 首先初始化红黑树数据结构
- 计算进程的虚拟运行时间
- 将进程按vruntime排序插入红黑树
- 检查是否有就绪进程
- 如果没有,进入睡眠状态
- 如果有,选择vruntime最小的进程执行
- 执行后更新进程的vruntime值
- 判断时间片是否用完
- 如果用完,重新计算vruntime
- 如果没用完,继续执行该进程
1. Linux调度器的发展历程
Linux调度器为了适应不断变化的硬件和应用需求,经历了多次重大变革:
-
初代O(n)调度器 (Linux 0.01 - 2.4):
- 机制: 每次调度时,内核会遍历系统中所有可运行进程,计算每个进程的"goodness"值(基于时间片剩余、优先级等)。选择goodness值最高的进程运行。当所有可运行进程时间片用完,则根据进程优先级重新分配时间片。
- 优点: 实现简单直观。
- 缺点: 调度开销与进程数量成正比,在进程数很多时性能低下。对实时性和交互性支持不佳。
-
O(1)调度器 (Linux 2.6.0 - 2.6.22):
- 机制: 引入了活动队列(active)和过期队列(expired)两个优先级数组(每个优先级一个队列)。调度器从活动队列中按最高优先级选择进程。时间片用完后,进程被移到过期队列。若活动队列为空,则交换活动队列和过期队列。
- 优点: 实现了常数时间复杂度的调度选择(选择下一个任务和切换队列的操作都是O(1))。
- 缺点: 代码相对复杂,启发式算法繁多,导致其行为有时难以预测。对nice值的调整效果不直观,且在某些交互式场景下表现不佳(例如,长时间运行的CPU密集型任务可能会损害桌面应用的响应速度)。
-
楼梯调度器 (Staircase Scheduler, Con Kolivas提出, 未纳入主线):
- 机制: 试图简化O(1)调度器的复杂性,并改善交互性。它为每个任务分配一个固定的时间配额,任务在用完配额后其优先级会"下降一级",直到达到最低优先级或再次变为活动状态。
- 优点: 简化了代码,对桌面交互性有较好的优化。
- 缺点: 在服务器等高负载场景下公平性有所欠缺。
-
CFS调度器 (Completely Fair Scheduler, Linux 2.6.23引入至今):
- 机制: 由Ingo Molnar开发,核心思想是模拟"理想的精确多任务处理器",确保每个进程获得公平的CPU时间。是目前Linux内核中用于普通进程的主流调度器。
- 优点: 公平性极佳,nice值调整效果符合预期,交互响应和吞吐量之间取得了较好的平衡。
- 缺点: 相对O(1)调度器,单次调度的开销略高(红黑树操作为O(log N)),但在现代CPU上此差异通常不显著。
-
BFS调度器 (Brain Fuck Scheduler, Con Kolivas提出, 未纳入主线):
- 机制: 针对桌面和小型系统(少于16个CPU核心)设计,采用全局单任务队列,算法非常简单,目标是实现最低的调度延迟。
- 优点: 简单,低延迟,对于目标系统表现良好。
- 缺点: 可扩展性较差,不适合大型多核服务器。
2. CFS设计思想
CFS的核心思想是模拟一个"理想的精确多任务处理器"。在这个理想模型中:
-
完全公平 (Perfect Fairness):
- 在任何可测量的时间段内,如果所有进程具有相同的权重(nice值),那么每个进程都应该获得完全相同的CPU时间份额(即CPU时间的1/N,N为可运行进程数)。
- 如果进程具有不同的权重,则它们按权重比例分配CPU时间。
-
虚拟运行时间 (vruntime):
- CFS不再使用固定的时间片概念,而是引入
vruntime。vruntime是进程实际运行时间根据其权重进行归一化(或加权)后的度量。 - 调度器总是选择当前
vruntime最小的进程来运行。 - 高优先级(权重高)的进程,其
vruntime增长得慢;低优先级(权重低)的进程,其vruntime增长得快。这样,高优先级进程就能获得更多的CPU执行机会。
- CFS不再使用固定的时间片概念,而是引入
-
红黑树 (Red-Black Tree):
- CFS使用红黑树来组织所有可运行进程(调度实体)。红黑树按
vruntime值进行排序。 - 选择下一个运行的进程即是找到红黑树中最左边的节点(
vruntime最小的节点)。 - 进程的入队和出队操作对应红黑树的插入和删除,时间复杂度为O(log N),N是可运行进程数。
- CFS使用红黑树来组织所有可运行进程(调度实体)。红黑树按
-
权重计算 (Weight Calculation):
- 进程的nice值(-20到+19)被映射为一个权重值。nice值越低(优先级越高),权重越大。
- 这个权重直接影响
vruntime的增长速度和CPU时间的分配比例。
-
组调度 (Group Scheduling):
- 支持按控制组(cgroup)进行层次化的资源分配。CPU时间首先在不同的任务组之间分配,然后在每个组内部的进程间分配。这使得系统管理员可以更精细地控制不同用户或服务所能使用的CPU资源。
-
目标延迟 (Target Latency) 和最小粒度 (Minimum Granularity):
- CFS试图在一个称为“调度周期”或“目标延迟”(
sysctl_sched_latency)的时间段内让所有可运行任务至少运行一次。 - 每个任务运行的实际时间片长度是根据其权重在目标延迟内按比例分配的,但不能低于“最小粒度”(
sysctl_sched_min_granularity),以避免过于频繁的上下文切换。 - 实际时间片 =
sched_latency * (task_weight / total_cfs_rq_weight),并受到最小/最大粒度的限制。
- CFS试图在一个称为“调度周期”或“目标延迟”(
3. CFS核心数据结构
3.1 调度实体(sched_entity)
每个task_struct中都嵌入了一个sched_entity,代表该任务参与CFS调度的实例。对于组调度,task_group也拥有sched_entity。
struct sched_entity {struct load_weight load; /* 进程的负载权重,基于nice值计算 */struct rb_node run_node; /* 红黑树节点,用于插入cfs_rq->tasks_timeline */unsigned int on_rq; /* 标记此实体是否在运行队列中 (1表示在, 0表示不在) */u64 exec_start; /* 本次开始执行的时间戳 (由rq_clock_task()获取) */u64 sum_exec_runtime; /* 进程总的实际执行时间 (累积值) */u64 vruntime; /* 虚拟运行时间,CFS调度的关键 */u64 prev_sum_exec_runtime; /* 上一次调度出队时的sum_exec_runtime,用于计算本次运行的delta_exec *//* ... 还有其他用于组调度、统计等的字段 ... */struct sched_avg avg; /* 用于PELT (Per-Entity Load Tracking) 的平均负载统计 */
};
3.2 CFS运行队列(cfs_rq)
每个CPU核心都有一个运行队列struct rq,其中包含一个CFS运行队列struct cfs_rq,专门管理该CPU上使用CFS调度的普通进程。
struct cfs_rq {struct load_weight load; /* 队列中所有调度实体的总负载权重 */unsigned int nr_running; /* 队列中可运行任务(调度实体)的数量 */unsigned int h_nr_running; /* 层次化的nr_running,用于组调度 */u64 exec_clock; /* 此cfs_rq上流逝的执行时钟 */u64 min_vruntime; /* 队列中所有调度实体的最小虚拟运行时间。* 这个值单调递增,用于给新唤醒或新创建的任务设定初始vruntime,* 以保证公平性,避免新任务饿死或获得不当优势。*/struct rb_root_cached tasks_timeline; /* 红黑树根节点 (rb_root_cached包含rb_root和rb_leftmost缓存) *//* tasks_timeline.rb_root 是红黑树的根 *//* tasks_timeline.rb_leftmost 是指向vruntime最小的节点的缓存指针 */struct sched_entity *curr; /* 当前正在此cfs_rq上运行的调度实体 */struct sched_entity *next; /* 下一个可能被调度的实体 (用于唤醒抢占) */struct sched_entity *last; /* 上一个被调度的实体 */struct sched_entity *skip; /* 在pick_next时可能被跳过的实体 *//* ... 还有用于组调度、负载均衡、统计的字段 ... */
};
注意:新版内核将rb_leftmost字段整合到了rb_root_cached结构中,原笔记中的rb_leftmost字段可能指的这个缓存。
3.3 任务结构体中的调度相关字段
task_struct是Linux内核中描述进程的核心数据结构。
struct task_struct {/* ... 大量其他字段 ... */int prio; /* 动态优先级,调度器实际使用的优先级 */int static_prio; /* 静态优先级,基于nice值和调度策略设定,通常不变 */int normal_prio; /* 普通优先级,基于static_prio计算,不受优先级继承影响 */unsigned int rt_priority; /* 实时优先级 (0-99),仅对SCHED_FIFO/RR有效 */const struct sched_class *sched_class; /* 指向该任务所属调度类 (fair_sched_class, rt_sched_class等)* 这是实现调度策略多态性的关键 */struct sched_entity se; /* CFS调度实体 */struct sched_rt_entity rt; /* 实时调度实体 */
#ifdef CONFIG_CGROUP_SCHEDstruct sched_task_group *sched_task_group; /* 指向所属的task_group,用于组调度 */
#endifunsigned int policy; /* 调度策略 (SCHED_NORMAL, SCHED_FIFO, SCHED_RR, SCHED_BATCH, SCHED_IDLE) */cpumask_t cpus_allowed; /* CPU亲和性掩码,指定任务可以在哪些CPU上运行 *//* ... */unsigned int flags; /* 包含 PF_KTHREAD (内核线程) 等标志 */int exit_state; /* 进程退出状态 */pid_t pid; /* 进程ID */struct mm_struct *mm; /* 内存管理结构,用户进程有,内核线程无 (除非特定情况) */
};
像这样的大型结构肯定会占用大量内存空间。鉴于每个进程的内核堆栈体积较小(可通过编译时选项配置,但默认限制为一页,即 32 位架构严格为 4KB,64 位架构严格为 8KB(操作系统虚拟内存分页的内容) – 内核堆栈没有扩展或收缩的奢侈能力),以这种浪费的方式使用资源不是很方便。因此,决定在堆栈中放置一个更简单的结构,并带有指向实际task_struct的指针。
#include <linux/types.h> // 为了 __u32 等类型
#include <linux/sched.h> // 为了 struct task_struct (假设) 和其他调度相关定义
#include <asm/current.h> // 为了 addr_limit 定义 (mm_segment_t)
#include <linux/restart_block.h> // 为了 struct restart_blockstruct thread_info {struct task_struct *task; /* 指向主任务结构体 (task_struct) 的指针 */// struct exec_domain *exec_domain; /* 执行域指针 (在现代内核中可能已废弃或不常用) */__u32 flags; /* 低级别线程标志位 (例如 TIF_NEED_RESCHED, TIF_SIGPENDING 等) */__u32 status; /* 线程同步状态标志 (例如用于调试、单步执行等) */__u32 cpu; /* 当前或上次运行此线程的CPU编号 */int preempt_count; /* 抢占计数器 (0 表示可抢占, >0 表示禁止抢占) */// int saved_preempt_count; /* 保存的抢占计数 (在某些特定上下文中可能使用) - 通常 thread_info 中是 preempt_count */mm_segment_t addr_limit; /* 地址空间限制 (用于区分用户空间/内核空间内存访问, 通常是 USER_DS 或 KERNEL_DS) */struct restart_block restart_block; /* 用于可重启系统调用的数据结构 */void __user *sysenter_return; /* sysenter/syscall 的用户空间返回地址 (特定于架构,例如x86) */unsigned int uaccess_err : 1; /* 标志用户空间内存访问 (如copy_to_user/copy_from_user) 是否失败 (1表示失败) *//* ... 其他特定于架构的字段 ... */
};
要使用线程,我们需要经常访问它们的task_structs,甚至更频繁地我们需要访问当前正在运行的任务。循环访问系统上的所有可用进程是不明智的且耗时的。这就是为什么我们有一个名为 current 的宏。由于堆栈或内存页的大小可变,此宏必须与每个体系结构单独实现。一些架构将指向当前正在运行的进程的指针存储在 register 中,而其他架构由于可用 registers 的数量非常少,因此每次都必须计算它。
4. 优先级与权重
4.1 优先级范围
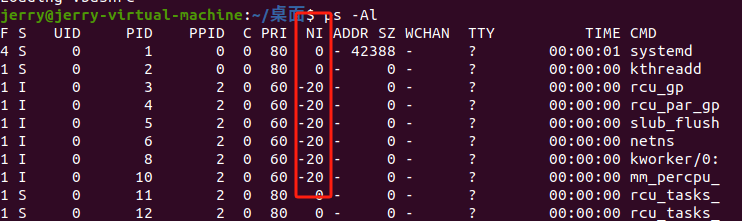
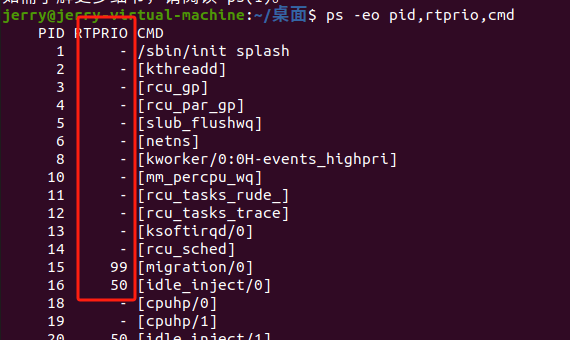
内核看到的任务优先级和用户看到的并不相同,在计算和管理优先级时也需要考虑很多方面。Linux 内核中使用 0~139 表示任务的优先级,并且,值越小,优先级越高(注意和用户空间的区别)。其中 0~99 保留给实时进程,100~139(映射成 nice 值就是 -20~19)保留给普通进程。
可以在 <include/linux/sched/prio.h> 头文件中看到内核表示进程优先级的单位(scale)和宏定义(macros),它们用来将用户空间优先级映射到到内核空间。
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
…
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
/*
* 'User priority' is the nice value converted to something we
* can work with better when scaling various scheduler parameters,
* it's a [ 0 ... 39 ] range.
*/
#define USER_PRIO(p) ((p)-MAX_RT_PRIO)
#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
-
用户空间nice值: 通过
nice()或setpriority()系统调用设置。- 范围: -20 (最高优先级) 到 +19 (最低优先级)。默认值为0。

- 范围: -20 (最高优先级) 到 +19 (最低优先级)。默认值为0。
-
内核优先级: 内核内部使用的优先级表示。
- 范围: 0-139。数值越小,优先级越高。
- 0-99: 实时进程优先级 (RT)。对应
rt_priority字段。SCHED_FIFO和SCHED_RR使用此范围。
- 100-139: 普通进程优先级 (NORMAL)。由nice值映射而来。
static_prio = MAX_RT_PRIO + nice + 20(其中MAX_RT_PRIO通常是100)。- 所以nice -20 对应
100 - 20 + 20 = 100(内核优先级)。 - nice +19 对应
100 + 19 + 20 = 139(内核优先级)。 prio和normal_prio通常基于static_prio。
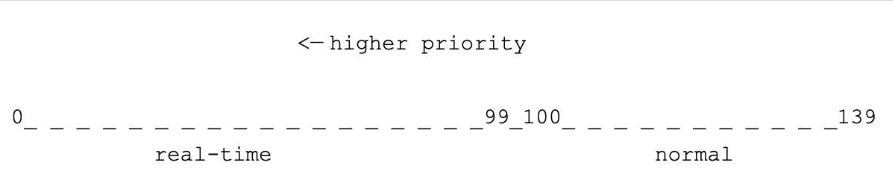
4.2 权重映射表 (prio_to_weight[])
CFS不直接使用nice值或内核优先级,而是将它们转换为"权重" (load_weight)。权重决定了进程在CPU时间分配中的相对比例。
优先级会让一些任务比别的任务更重要,因此也会获得更多的 CPU 使用时间。nice 值和时间片的比例关系是通过负载权重(Load Weights)进行维护的,我们可以在 task_struct->se.load 中看到进程的权重,定义如下:
struct sched_entity { struct load_weight load; /* for load-balancing */ …
}
struct load_weight { unsigned long weight; u32 inv_weight;
};
/** Nice levels are multiplicative, with a gentle factor of 1.25* per nice level.*/
static const int prio_to_weight[40] = {/* -20 */ 88761, 71755, 56483, 46273, 36291,/* -15 */ 29154, 23254, 18705, 14949, 11916,/* -10 */ 9548, 7620, 6100, 4904, 3906,/* -5 */ 3121, 2501, 1991, 1586, 1277,/* 0 */ 1024, 820, 655, 526, 423, // NICE_0_LOAD is 1024/* 5 */ 335, 272, 215, 172, 137,/* 10 */ 110, 87, 70, 56, 45,/* 15 */ 36, 29, 23, 18, 15,
};
// prio_to_weight[0] 对应 nice -20
// prio_to_weight[19] 对应 nice 0
// prio_to_weight[39] 对应 nice +19
-
从nice 0到nice -20 (数组索引19到0):
prio_to_weight[19](nice 0) =1024prio_to_weight[18](nice -1) ≈ 1024 × 1.25 = 1280 \approx 1024 \times 1.25 = 1280 ≈1024×1.25=1280。表中的值为1277。prio_to_weight[17](nice -2) ≈ 1277 × 1.25 ≈ 1596.25 \approx 1277 \times 1.25 \approx 1596.25 ≈1277×1.25≈1596.25 (或者 1024 × 1.2 5 2 = 1600 1024 \times 1.25^2 = 1600 1024×1.252=1600)。表中的值为1586。- …
prio_to_weight[0](nice -20) ≈ 1024 × ( 1.25 ) 20 ≈ 1024 × 86.736 ≈ 88817.984 \approx 1024 \times (1.25)^{20} \approx 1024 \times 86.736 \approx 88817.984 ≈1024×(1.25)20≈1024×86.736≈88817.984。表中的值为88761。
-
从nice 0到nice +19 (数组索引19到39):
prio_to_weight[19](nice 0) =1024prio_to_weight[20](nice +1) ≈ 1024 / 1.25 = 819.2 \approx 1024 / 1.25 = 819.2 ≈1024/1.25=819.2。表中的值为820。prio_to_weight[21](nice +2) ≈ 820 / 1.25 = 656 \approx 820 / 1.25 = 656 ≈820/1.25=656 (或者 1024 / ( 1.2 5 2 ) ≈ 655.36 1024 / (1.25^2) \approx 655.36 1024/(1.252)≈655.36)。表中的值为655。- …
prio_to_weight[39](nice +19) ≈ 1024 / ( 1.25 ) 19 ≈ 1024 / 74.5058 ≈ 13.743 \approx 1024 / (1.25)^{19} \approx 1024 / 74.5058 \approx 13.743 ≈1024/(1.25)19≈1024/74.5058≈13.743。表中的值为15。
-
“10%规则”: 这是一个近似的说法。更准确地说,nice值每降低1(优先级提高),获得的CPU时间份额大约增加25% (1.25倍)。反之,nice值每增加1,CPU时间份额大约减少20% (1/1.25 = 0.8倍)。
-
举例说明:
- 场景 1:两个
nice 0任务,权重均为 1024,各占 50% CPU 时间。 - 场景 2:一个
nice 0(1024)和一个nice 5(335)任务,CPU 时间分配为:1024/(1024+335) ≈ 75%vs.335/(1024+335) ≈ 25%,即nice 5任务比nice 0少约 66% CPU 时间(因累计多次 10% 变化)。
- 场景 1:两个
完整的计算函数定义在 <kernel/sched/core.c> 中:
优先级参考task_struct里面的注释
static void set_load_weight(struct task_struct *p)
{// 1. 计算相对优先级 (prio)// p->static_prio 是任务的静态优先级 (内核内部表示, 100-139 对应 nice -20 到 +19)// MAX_RT_PRIO 通常是 100 (实时优先级的上限)// prio 的范围将是 0 到 39,正好对应 prio_to_weight 和 prio_to_wmult 数组的索引。// 例如:// nice -20 (static_prio 100) -> prio = 100 - 100 = 0// nice 0 (static_prio 120) -> prio = 120 - 100 = 20 (注意这里与之前注释的 prio_to_weight[19] 对应 nice 0 有偏差,// 实际prio_to_weight[nice_to_prio(nice)],而nice_to_prio(0)=20)// nice +19 (static_prio 139) -> prio = 139 - 100 = 39int prio = p->static_prio - MAX_RT_PRIO;// 2. 获取指向任务调度实体负载权重结构的指针// p->se 是 task_struct 中嵌入的 sched_entity (CFS调度实体)// load 指向该实体的 load_weight 结构struct load_weight *load = &p->se.load;/** SCHED_IDLE 任务获得最小权重:*/// 3. 处理 SCHED_IDLE 调度策略的任务// SCHED_IDLE 策略用于运行优先级非常低的后台任务,只有在系统完全空闲时才运行。if (p->policy == SCHED_IDLE) {// 为 SCHED_IDLE 任务设置一个预定义的、非常小的权重。// WEIGHT_IDLEPRIO 通常是系统允许的最小权重 (例如 3,而 NICE_0_LOAD 是 1024)。load->weight = scale_load(WEIGHT_IDLEPRIO);// WMULT_IDLEPRIO 是这个最小权重的预计算乘数,用于优化 vruntime 计算。// inv_weight (inverse weight, 权重的倒数) 用于计算 vruntime:// delta_vruntime = delta_exec * NICE_0_LOAD / weight// 为了避免除法,会预计算 NICE_0_LOAD / weight,即 inv_weight (经过适当缩放的)。// 更准确地,vruntime 更新公式可能是 delta_vruntime = (delta_exec * inv_weight) >> WMULT_SHIFT// 其中 WMULT_SHIFT 是一个固定的移位值。load->inv_weight = WMULT_IDLEPRIO;return; // 设置完毕,直接返回}// 4. 处理非 SCHED_IDLE 的普通任务 (例如 SCHED_NORMAL, SCHED_BATCH)// 使用前面计算的 prio (0-39)作为索引,从 prio_to_weight 数组中查找对应的权重。load->weight = scale_load(prio_to_weight[prio]);// 同样,从 prio_to_wmult 数组中查找预计算的权重倒数乘数。load->inv_weight = prio_to_wmult[prio];
}
优先级计算
task_struct 中有几个关键字段用来表示和管理进程的优先级。
struct task_struct {// ... 其他众多字段 ...int prio; /* 动态优先级 (Dynamic Priority) */int static_prio; /* 静态优先级 (Static Priority) */int normal_prio; /* 普通优先级 (Normal Priority) */unsigned int rt_priority; /* 实时优先级 (Real-Time Priority) */unsigned int policy; /* 调度策略 (Scheduling Policy) */const struct sched_class *sched_class; /* 指向调度类的指针 */struct sched_entity se; /* CFS调度实体 */struct sched_rt_entity rt; /* 实时调度实体 */// ... 其他字段 ...
};
4.3.1. static_prio (静态优先级)
static_prio 是由用户通过 nice() 或 setpriority() 系统调用设置的“nice值”(范围-20到+19,对应普通进程)或者通过 sched_setscheduler() 设置的实时优先级(范围0-99,对应实时进程),经过内核映射转换后的内部表示。
-
对于普通进程 (SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE):
- 内核会将nice值(-20 到 +19)映射到一个内部优先级范围。这个范围通常是
MAX_RT_PRIO到MAX_PRIO - 1。 MAX_RT_PRIO通常是100(定义了实时优先级的上限)。MAX_PRIO通常是140。- 映射公式(近似):
static_prio = MAX_RT_PRIO + nice + 20nice -20(最高普通优先级) ->static_prio = 100 - 20 + 20 = 100nice 0(默认普通优先级) ->static_prio = 100 + 0 + 20 = 120nice +19(最低普通优先级) ->static_prio = 100 + 19 + 20 = 139
- 注意:在内核中,优先级数值越小,实际优先级越高。所以
static_prio = 100比static_prio = 139优先级高。
- 内核会将nice值(-20 到 +19)映射到一个内部优先级范围。这个范围通常是
-
对于实时进程 (SCHED_FIFO, SCHED_RR):
static_prio直接等于用户设置的实时优先级,范围是 0 到MAX_RT_PRIO - 1(即 0-99)。rt_priority字段也会存储这个值。- 例如,实时优先级为50,则
static_prio = 50。
static_prio 的特点:
- 顾名思义,它是“静态的”,一旦设定,通常不会被调度器自身动态改变(除非用户再次通过系统调用修改它)。
- 它是计算其他优先级(如
normal_prio和prio)的基础。
4.3.2. normal_prio (普通优先级 / 规范化优先级)
normal_prio 存放的是基于 static_prio 和进程调度策略 (policy) 决定的优先级。它的主要作用是提供一个不受“优先级继承”影响的基准优先级。
-
计算方式:
- 对于实时进程:
normal_prio通常与其static_prio相同。// 伪代码示意 if (task_is_realtime(p)) { // 检查 p->policy 是否为 SCHED_FIFO 或 SCHED_RRp->normal_prio = p->static_prio; } - 对于普通进程:
normal_prio通常也与其static_prio相同。// 伪代码示意 else { // 普通进程p->normal_prio = p->static_prio; } - 所以,在很多情况下,
normal_prio就是static_prio的一个副本。它的存在更多是为了在优先级继承等复杂场景下,保留一个原始的、未被临时修改的基准优先级。
- 对于实时进程:
-
继承性:
- 子进程在
fork()时,会继承父进程的normal_prio。这意味着子进程的初始优先级基准与父进程相同(除非之后被显式修改)。 static_prio也会被继承。
- 子进程在
-
用途:
- 在O(1)调度器中,当任务从过期队列移回活动队列时,其动态优先级可能会基于
normal_prio(或static_prio)重新计算。 - 在CFS调度器中,
normal_prio主要用于初始化任务的权重,它间接通过static_prio计算得出。 - 在优先级继承机制(Priority Inheritance Protocol, PIP)中,当一个低优先级任务持有一个被高优先级任务等待的锁时,低优先级任务的动态优先级 (
prio) 可能会被临时提升到高优先级任务的级别。但其normal_prio(和static_prio)保持不变,以便在锁释放后恢复其原始优先级。
- 在O(1)调度器中,当任务从过期队列移回活动队列时,其动态优先级可能会基于
4.3.3. prio (动态优先级)
prio 是调度器实际使用的优先级,它可能因为多种原因而动态改变,即使 static_prio 和 normal_prio 保持不变。
-
初始值:
- 通常情况下,
prio的初始值等于其normal_prio(也就意味着常常等于static_prio)。
// 伪代码示意 (在任务创建或优先级设置时) p->prio = p->normal_prio; - 通常情况下,
-
动态变化的场景:
- O(1)调度器的动态调整 (针对普通任务):
- O(1)调度器会根据任务的“交互性”动态调整普通任务的
prio。如果一个任务被认为是交互式的(例如,经常睡眠等待I/O),它的prio可能会被临时提高(数值减小)。反之,CPU密集型任务的prio可能会被降低(数值增大)。这种调整是基于static_prio进行的奖惩。
- O(1)调度器会根据任务的“交互性”动态调整普通任务的
- 优先级继承 (Priority Inheritance):
- 这是
prio动态变化的一个典型场景。如果任务A(低优先级)持有一个互斥锁,而任务B(高优先级)正在等待这个锁,那么任务A的prio会被临时提升到任务B的prio级别(或者至少是任务B的normal_prio级别),以避免优先级反转问题,确保任务A能尽快执行并释放锁。当锁被释放后,任务A的prio会恢复到其normal_prio。
- 这是
- 实时调度策略中的特殊情况:
- 虽然实时任务的
static_prio和normal_prio是固定的,但在极少数情况下(例如与某些类型的锁或内核机制交互时),其prio也可能发生临时变化,但这种情况远不如普通任务或优先级继承常见。
- 虽然实时任务的
- 调度器内部的临时提升:
- 系统有时可能会为了特定目的(例如,确保某个关键内核任务能快速运行)而临时提升某个任务的
prio,使其能够抢占其他高优先级任务。
- 系统有时可能会为了特定目的(例如,确保某个关键内核任务能快速运行)而临时提升某个任务的
- O(1)调度器的动态调整 (针对普通任务):
-
计算方式的笼统描述:
- “一旦
static_prio确定,prio字段就可以通过下面的方式计算” —— 这句话比较笼统。更准确地说,prio的初始值通常基于static_prio(通过normal_prio)。之后,它会根据上述动态场景进行调整。 - 没有一个单一的、固定的公式总是从
static_prio直接计算出当前的prio,因为prio的动态性恰恰体现在它会偏离static_prio。 - 恢复时的计算: 当动态调整的因素消失时(例如锁被释放,或者O(1)调度器的交互性奖惩周期结束),
prio通常会恢复到其normal_prio。// 伪代码示意 (例如,在优先级继承结束时) p->prio = p->normal_prio;
- “一旦
4.3.4. rt_priority (实时优先级)
- 这个字段专门用于存储实时任务的优先级(0-99)。
- 对于非实时任务,此字段的值通常为0或未定义。
- 对于实时任务,
rt_priority通常与static_prio和normal_prio的值(在0-99范围内)一致。
p->prio = effective_prio(p);
// kernel/sched/core.c 中定义了计算方法
static int effective_prio(struct task_struct *p)
{ p->normal_prio = normal_prio(p); /* * If we are RT tasks or we were boosted to RT priority, * keep the priority unchanged. Otherwise, update priority * to the normal priority: */ if (!rt_prio(p->prio)) return p->normal_prio; return p->prio;
} static inline int normal_prio(struct task_struct *p)
{ int prio; if (task_has_dl_policy(p)) prio = MAX_DL_PRIO-1; else if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority; else prio = __normal_prio(p); return prio;
} static inline int __normal_prio(struct task_struct *p)
{ return p->static_prio;
}
总结与关系
- 基础是
static_prio:由用户设定(nice值或实时优先级),并映射到内核表示。 normal_prio是基准:通常等于static_prio,作为不受优先级继承等临时因素影响的“正常”优先级。子进程继承它。prio是实际使用的动态优先级:以normal_prio为基础,并可能因为调度器策略(如O(1)的交互性调整)、优先级继承等原因发生动态变化。调度器做调度决策时,主要看的是prio(对于O(1)调度器)或通过vruntime间接体现的优先级(对于CFS)。rt_priority专用于实时任务:明确记录其实时优先级等级。
在现代CFS调度器中,对于普通进程,static_prio 和 normal_prio 主要用于计算任务的权重 (load_weight),这个权重再用于计算vruntime的增长。CFS不太直接使用prio字段进行排序决策,而是依赖vruntime。但prio字段在与旧代码、某些内核子系统或特定调度场景(如与实时任务交互)中仍可能扮演角色。对于实时任务,这些优先级字段仍然直接重要。
5. CFS关键算法实现
5.1 虚拟运行时间计算 (update_curr)
当一个任务正在运行时,它的vruntime需要不断更新,以反映它消耗的CPU时间。这通常在时钟中断处理(scheduler_tick)或任务状态改变(如阻塞、唤醒)时由update_curr()函数完成。
// kernel/sched/fair.c
static void update_curr(struct cfs_rq *cfs_rq)
{struct sched_entity *curr = cfs_rq->curr; // 当前正在此cfs_rq上运行的实体u64 now = rq_clock_task(rq_of(cfs_rq)); // 获取当前运行队列的任务时钟u64 delta_exec;if (unlikely(!curr)) // 如果没有当前运行任务 (例如CPU刚启动或变为空闲)return;/* 计算自上次更新以来实际运行的时间 (delta_exec) */delta_exec = now - curr->exec_start;if (unlikely((s64)delta_exec <= 0)) // 时间未前进或回拨,则不更新return;curr->exec_start = now; // 更新开始执行时间戳为当前时间curr->sum_exec_runtime += delta_exec; // 累加总实际执行时间// prev_sum_exec_runtime 在出队时更新,这里不需要/* 根据权重将实际运行时间 delta_exec 转换为虚拟运行时间 delta_vruntime *//* 并累加到 curr->vruntime */curr->vruntime += calc_delta_fair(delta_exec, curr);update_min_vruntime(cfs_rq); // 更新cfs_rq的min_vruntime
}
calc_delta_fair函数将实际运行时间delta_exec转换为加权的虚拟运行时间delta_vruntime:
// kernel/sched/fair.c
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{// 如果进程权重不是 NICE_0_LOAD (1024)if (unlikely(se->load.weight != NICE_0_LOAD))// __calc_delta 进行加权计算: delta_vruntime = delta_exec * (NICE_0_LOAD / se->load.weight)// NICE_0_LOAD 是基准权重。权重越大的进程 (se->load.weight 大), 其vruntime增长越慢。// 权重越小的进程 (se->load.weight 小), 其vruntime增长越快。delta = __calc_delta(delta, NICE_0_LOAD, &se->load);return delta;
}// 在 __calc_delta 中 (大致逻辑):
// u64 __calc_delta(u64 delta_exec, unsigned long load_NICE_0, struct load_weight *lw)
// {
// return (delta_exec * load_NICE_0) / lw->weight;
// // 为了避免精度损失和溢出,实际实现会使用64位乘法和移位操作
// }
核心公式: delta_vruntime = delta_exec * (NICE_0_LOAD / task_weight)
这意味着:
- 权重越高的任务(
task_weight大),其vruntime增长得越慢,因此能更快地再次成为vruntime最小的任务,从而获得更多CPU时间。 - 权重越低的任务(
task_weight小),其vruntime增长得越快。
5.2 进程选择 (pick_next_task_fair)
当需要选择下一个要运行的进程时,调度器会调用相应调度类的pick_next_task方法。对于CFS,即pick_next_task_fair。
// kernel/sched/fair.c
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{struct cfs_rq *cfs_rq = &rq->cfs;struct sched_entity *se;if (!cfs_rq->nr_running) // 如果CFS运行队列为空return NULL;/* put_prev_task_fair(rq, prev) 会被调用,确保前一个任务的状态被正确更新并放回红黑树 (如果它仍然可运行) *//* 从红黑树中选择vruntime最小的调度实体 */se = pick_next_entity(cfs_rq, NULL); // 第二个参数是针对组调度的,简单情况下为NULLif (!se) // 理论上如果nr_running > 0,这里不应为NULLreturn NULL;/* 返回与该调度实体对应的task_struct */return task_of(se); // task_of是一个宏,通过sched_entity指针找到其宿主task_struct
}
pick_next_entity (内部调用 __pick_first_entity 或 __pick_next_entity for group scheduling) 实际从红黑树中选择最左边的节点:
// kernel/sched/fair.c
/** Pick the next process from the CFS runqueue.** This is a two-stage selection:** 1) pick the 'ideal' process -- ie. the task that is furthest* to the left in the rbtree.** 2) check whether we can run this ideal process. More specifically,* check whether we should instead run a new task that is waking* up, to achieve better latencies for new interactive tasks.* (this is the skip logic)*/
struct sched_entity *pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{/* 获取红黑树最左节点 (vruntime最小的) */struct sched_entity *left = __pick_first_entity(cfs_rq);struct sched_entity *se;/** If curr is set we have a current task and pick_next_entity() is called* to decide whether to schedule left or a new waking task.* The skip logic is only applicable if left exists.*/if (!left || (curr && sched_feat(NEXT_BUDDY) && entity_ πριν(curr, left))) // entity_before: curr->vruntime < left->vruntimeleft = curr; // 如果当前任务的vruntime比最左的还小 (例如刚被放回且未充分运行),或者没有最左任务,则考虑当前任务se = left; // 默认选择最左的或者修正后的left/** Prefer last buddy, try to return the task we ran last.* Or sibling if we're a new parent.*/if (sched_feat(LAST_BUDDY) && cfs_rq->last &&entity_ ennen(cfs_rq->last, se)) // entity_before: cfs_rq->last->vruntime < se->vruntimese = cfs_rq->last; // 如果上一个运行的任务仍然有较小的vruntime (缓存亲和性)/** Waker observe-then-pick logic:** Consider the case where a high-priority task wakes up.* We want to run it, because it will have a small vruntime.** The problem is that such a task might not be 'left' in the tree* because it is not yet in the tree.** Solution is to notice that a task is waking and specifically pick* it.** This is part of the wake-up preemption logic. If 'next' is set,* it indicates a recently woken task that might preempt the currently* selected 'se'.*/if (cfs_rq->next && entity_before(cfs_rq->next, se))se = cfs_rq->next; // 如果有刚唤醒的next任务且其vruntime更小,则选择它 (唤醒抢占)/** The skip logic needs to be careful not to hurt throughput,* so we only skip a task if it has been nominated for skipping* by the tick. The tick will not nominate a task that is* blocked on I/O or a task that has not been running for a* long time.*/if (cfs_rq->skip && entity_before(cfs_rq->skip, se))se = cfs_rq->skip; // 如果有标记为skip的任务且vruntime更小 (通常为了避免饥饿)clear_buddies(cfs_rq, se); // 清理cfs_rq->last, next, skipreturn se;
}// 真正获取最左节点
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{struct rb_node *left = rb_first_cached(&cfs_rq->tasks_timeline); // 使用缓存的红黑树最左节点if (!left)return NULL;return rb_entry(left, struct sched_entity, run_node); // 通过run_node指针获取宿主sched_entity
}
5.3 进程入队 (enqueue_entity / enqueue_task_fair)
当一个任务变为可运行状态时(例如,创建、唤醒、或当前任务放弃CPU但仍可运行时),它需要被加入到CFS运行队列的红黑树中。
// kernel/sched/fair.c
// enqueue_entity is the workhorse for enqueue_task_fair
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{/** If a task is queued with ENQUEUE_WAKEUP, its runtime is normalized* to 'now' before adding it to the cfs_rq. This is to ensure that* tasks that have been sleeping for a long time do not get an* unfair advantage.** It is also a key part of the vruntime placement logic that makes CFS* "spread" the vruntime of tasks across the timeline.*/if (flags & ENQUEUE_WAKEUP) // 如果是唤醒操作place_entity(cfs_rq, se, 0); // 调整se->vruntime,避免饥饿或不公平优势/** Update the current task's runtime statistics and place it among* the fair normal tasks when running in a different group.*/update_curr(cfs_rq); // 确保当前运行任务(cfs_rq->curr)的vruntime是最新的/* 如果不是从睡眠/唤醒路径 (例如新任务或 yield), 且没有指定初始vruntime,* 则可能需要根据cfs_rq->min_vruntime来设置se->vruntime (place_entity中已处理大部分情况)*/if (!(flags & ENQUEUE_WAKEUP))se->vruntime += cfs_rq->min_vruntime; // 确保vruntime是基于队列的最小值,防止其值过小account_entity_enqueue(cfs_rq, se); // 更新统计信息,如nr_running, load.weight/* 将调度实体插入红黑树 */if (flags & ENQUEUE_WAKEUP) { // 如果是唤醒,可能需要检查抢占// ... 检查是否需要抢占当前任务 ...// check_schedstat_required();}__enqueue_entity(cfs_rq, se); // 实际的红黑树插入操作// ...
}// 实际插入红黑树
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{rb_add_cached(&se->run_node, &cfs_rq->tasks_timeline, __entity_less); // 使用缓存优化的红黑树插入// __entity_less(a,b) 比较 a->vruntime 和 b->vruntime
}
place_entity函数非常关键,它为新进程或唤醒的进程设置初始vruntime,以避免不公平:
- 对于新创建的进程(fork):通常会继承父进程的一部分
vruntime或基于cfs_rq->min_vruntime进行设置。一个常见的做法是新任务的vruntime被设置为cfs_rq->min_vruntime。如果设置得太小,新任务会立即抢占;如果太大,则可能饥饿。 - 对于唤醒的进程:其
vruntime通常会设置为max(se->vruntime, cfs_rq->min_vruntime - sysctl_sched_latency_ns / 2)(近似值)。这确保了睡眠唤醒的任务不会因为其vruntime在睡眠期间没有增长而获得巨大优势,也不会因为vruntime远小于min_vruntime而饿死。它被放置在min_vruntime稍靠前的位置,给予一定的运行机会,但不至于破坏整体公平性。sched_wakeup_granularity_ns也用于此,保证唤醒的任务如果其vruntime与当前任务的vruntime差距足够大,才会引发抢占。
5.4 最小虚拟运行时间更新 (update_min_vruntime)
min_vruntime是CFS运行队列中所有任务的vruntime的一个“地板值”或“基准线”。它确保所有任务的vruntime都向前推进,并且新加入队列的任务的vruntime不会与队列中现有任务的vruntime相差过大。
// kernel/sched/fair.c
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{u64 vruntime = cfs_rq->min_vruntime; // 先取当前的min_vruntimeif (cfs_rq->curr) // 如果有当前运行的任务vruntime = cfs_rq->curr->vruntime; // 当前任务的vruntime是一个候选if (cfs_rq->nr_running > 0) { // 如果队列中有其他任务struct rb_node *leftmost = rb_first_cached(&cfs_rq->tasks_timeline); // 获取红黑树最左节点struct sched_entity *se = rb_entry(leftmost, struct sched_entity, run_node);if (!cfs_rq->curr) // 如果没有当前运行任务 (CPU空闲后刚有任务入队)vruntime = se->vruntime; // 最左节点的vruntime是候选else// 在当前任务的vruntime和最左任务的vruntime中取较小者vruntime = min_vruntime(vruntime, se->vruntime); }/* 核心:确保min_vruntime单调递增,并至少是上面计算出的vruntime */cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);/* max_vruntime 和 min_vruntime 考虑了vruntime回绕的可能性,* 使用有符号比较来判断大小 (e.g., (s64)(a-b) > 0 )*/
}
min_vruntime的单调递增特性非常重要,它防止了vruntime的全局值倒退,并为新任务和唤醒任务提供了一个公平的起点。
6. 调度器调用入口
6.1 schedule()函数
schedule()是Linux内核中请求CPU调度的核心函数。当内核的某部分认为应该让其他进程运行时,就会调用schedule()。
触发schedule()调用的主要场景:
- 当前进程主动放弃CPU:
- 进程进入睡眠状态(例如,等待I/O、锁、信号量):
sleep_on(),interruptible_sleep_on(),wait_event_interruptible()等最终会调用schedule()。 - 进程显式调用
sched_yield()。
- 进程进入睡眠状态(例如,等待I/O、锁、信号量):
- 需要抢占当前进程 (Preemption):
- 定时器中断(
scheduler_tick):如果当前进程的时间配额(CFS中非固定,但有理想运行时间)已耗尽,并且有其他更合适的进程,会设置TIF_NEED_RESCHED标志。当中断返回用户空间或内核抢占点时,会检查此标志并调用schedule()。 - 高优先级任务唤醒:当一个睡眠的进程被唤醒(例如I/O完成),如果其优先级(对CFS而言是
vruntime)高于当前运行进程,当前进程会被标记TIF_NEED_RESCHED,并在适当时机被抢占。
- 定时器中断(
- 进程终止或创建:
exit()和fork()路径中也会涉及调度。 - CPU变为空闲:当一个CPU上没有可运行任务时,会调用
schedule_idle(),它内部也会涉及schedule()。
schedule()的大致流程:
prev = current//current是指向当前运行task_struct的宏release_kernel_lock(prev)// 如果持有大内核锁 (BKL,已废弃)__schedule()// 核心调度逻辑rq = cpu_rq(cpu)// 获取当前CPU的运行队列task_struct *next = pick_next_task(rq, prev, &rf)// 调用调度类的pick_next_task选择下一个任务context_switch(rq, prev, next, &rf)// 进行上下文切换prepare_task_switch(rq, prev, next)switch_mm_irqs_off(prev->mm, next->mm, next)// 切换地址空间switch_to(prev, next, prev)// 切换CPU寄存器状态(栈指针、指令指针等),这是体系结构相关的汇编实现finish_task_switch(prev)
reacquire_kernel_lock(current)// (已废弃)
6.2 周期性调度 (scheduler_tick)
系统定时器(通常是HZ频率,如100Hz, 250Hz, 1000Hz)会周期性地产生中断,其处理函数中会调用scheduler_tick()。
// kernel/sched/core.c
void scheduler_tick(void)
{int cpu = smp_processor_id(); // 获取当前CPU IDstruct rq *rq = cpu_rq(cpu); // 获取当前CPU的运行队列struct task_struct *curr = rq->curr; // 当前运行的任务sched_clock_tick(); // 更新调度时钟// 更新运行队列的CPU时钟,这个时钟在update_curr中用于计算delta_execupdate_rq_clock(rq); // 调用当前任务所属调度类的task_tick方法// 对于CFS任务,这里会调用 fair_sched_class.task_tick -> task_tick_fair()curr->sched_class->task_tick(rq, curr, 0 /* 0 for non-queued wakeups */);// 更新CPU负载统计信息 (用于负载均衡等)update_cpu_load_active(rq);#ifdef CONFIG_NO_HZ_COMMON// 处理动态时钟 (tickless) 相关的逻辑if (rq->idle_balance && !need_resched())rq->nohz_balance_kick = 1;
#endif// ... 其他周期性任务,如触发负载均衡 ...trigger_load_balance(rq); // 可能会触发负载均衡
}
task_tick_fair() (由curr->sched_class->task_tick调用) 的主要工作:
- 调用
entity_tick()处理当前sched_entity。 - 在
entity_tick()中:- 调用
update_curr()更新当前任务的vruntime。 - 调用
check_preempt_tick()检查当前任务是否应该被抢占。这基于任务是否已运行了足够长的时间(相对于其应得的时间片,该时间片由sched_latency_ns、sched_min_granularity_ns和任务权重动态计算得出)。如果需要抢占,则设置TIF_NEED_RESCHED标志。
- 调用
7. CFS与其他调度方案对比
这一节内容
https://ifaceless.github.io/2019/11/17/guide-to-linux-scheduler/
这篇博客写的很详细就不再重复造车了。
7.1 CFS vs O(1)调度器
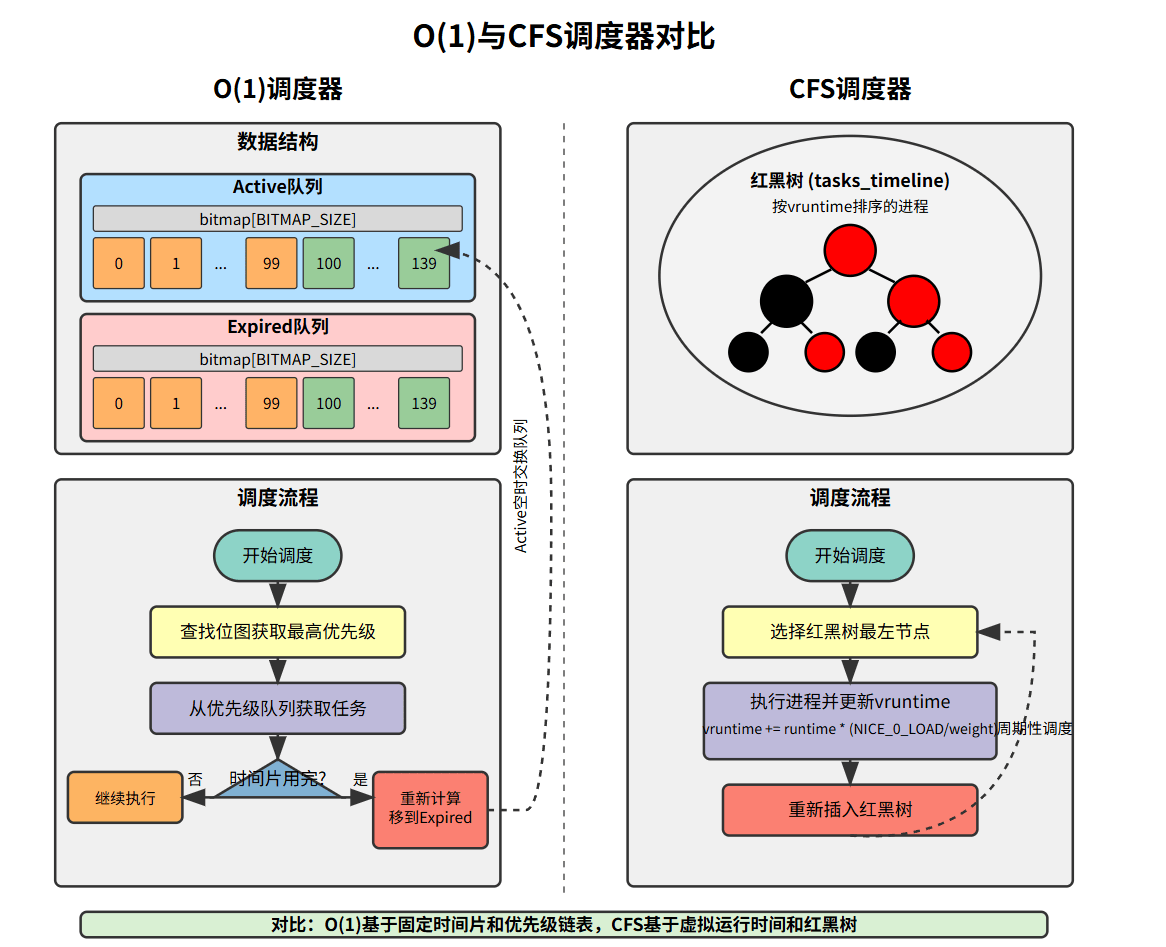
- 数据结构:
- O(1): 使用两个优先级数组(活动队列、过期队列),每个优先级对应一个链表。
- CFS: 使用每个CPU一个红黑树(
cfs_rq->tasks_timeline)按vruntime排序。
- 调度决策依据:
- O(1): 基于固定时间片和动态优先级。任务用完时间片后移到过期队列,优先级会动态调整。
- CFS: 基于虚拟运行时间 (
vruntime)。总是选择vruntime最小的任务。没有固定时间片,而是动态计算理想运行时间。
- 公平性:
- O(1): 试图通过动态优先级和奖惩机制实现公平,但对nice值的响应不总是线性的,公平性不如CFS。
- CFS: "完全公平"是核心设计目标,通过
vruntime机制精确按权重分配CPU时间。
- 复杂度:
- O(1): 调度决策(选择下一个任务)是O(1)的。但其内部逻辑和启发式规则较多。
- CFS: 调度决策(红黑树操作)是O(log N)的,N为可运行任务数。代码相对O(1)更简洁和模块化。
- 交互性:
- O(1): 交互式任务的判断和提升机制复杂,有时效果不佳。
- CFS: 通过
vruntime和抢占机制(如唤醒抢占、周期性抢占)能提供较好的交互响应。
7.2 CFS vs BFS
- 运行队列结构:
- CFS: Per-CPU运行队列 (
cfs_rq),需要复杂的多核负载均衡。 - BFS: 全局单一运行队列(使用双向链表实现优先级队列),天然负载均衡,但可能成为多核扩展瓶颈。
- CFS: Per-CPU运行队列 (
- 调度算法复杂度:
- CFS: O(log N) due to red-black tree.
- BFS: O(1) for task selection from its “Effective Dynamic Priority” (EDF-like) queue, but finding the exact slot for insertion can be O(N) in worst case, though typically much faster due to limited priority levels. Aims for simplicity.
- 目标系统:
- CFS: 通用调度器,设计用于从小型嵌入式到大型多核服务器的各种系统。
- BFS: 主要针对桌面系统和核心数较少(<16)的系统,追求最低延迟和简单性。
- 特性:
- CFS: 支持组调度、复杂的负载均衡、NUMA感知等高级特性。
- BFS: 设计极简,特性较少,不支持组调度。
8. 实时调度与CFS的关系
Linux内核支持多种调度策略,通过sched_class结构实现模块化。调度类之间存在优先级:
stop_sched_class > dl_sched_class (Deadline) > rt_sched_class (Real-Time) > fair_sched_class (CFS) > idle_sched_class.
- CFS只调度普通进程: 即调度策略为
SCHED_NORMAL(或SCHED_OTHER),SCHED_BATCH,SCHED_IDLE的进程。 - 实时进程由
rt_sched_class处理:SCHED_FIFO(First-In, First-Out):- 没有时间片概念。
- 一旦获得CPU,会一直运行,直到它主动放弃CPU(如阻塞、
sched_yield())、被更高优先级的实时任务抢占、或被杀死。 - 相同优先级的
SCHED_FIFO任务,先进入运行队列的先运行。
SCHED_RR(Round-Robin):- 基于时间片的实时调度。
- 当任务用完其时间片后,如果队列中还有其他相同优先级的
SCHED_RR或SCHED_FIFO任务,它会被放到其优先级队列的末尾。 - 如果被更高优先级的实时任务抢占,其剩余时间片保留。
- 抢占关系:
- 任何实时任务(
SCHED_FIFO或SCHED_RR)都会抢占任何普通CFS任务。 - 高优先级的实时任务会抢占低优先级的实时任务。
- 任何实时任务(
SCHED_DEADLINE: 比rt_sched_class优先级更高,基于最早截止期优先 (EDF) 思想,任务有(runtime, deadline, period)三个参数,保证在每个周期(period)内,任务可以运行runtime时间,并且必须在deadline之前完成。
当schedule()被调用时,它会按照调度类的优先级顺序查询:首先看stop_sched_class是否有任务,然后是dl_sched_class,再是rt_sched_class,最后才是fair_sched_class。只有高优先级调度类都没有可运行任务时,才会轮到低优先级调度类。
9. 组调度机制 (Group Scheduling)
CFS通过cgroup子系统支持组调度,允许将CPU资源在不同的任务组之间进行分层分配。
// 简化表示,实际结构更复杂
struct task_group {struct cgroup_subsys_state css; // cgroup子系统状态
#ifdef CONFIG_FAIR_GROUP_SCHED/* sched_entity for parent hierarchy */struct sched_entity **se; // 每个CPU上,此组作为一个调度实体参与父级cfs_rq的调度/* runqueue for this group */struct cfs_rq **cfs_rq; // 每个CPU上,此组拥有自己的cfs_rq,用于调度组内任务/子组unsigned long shares; // 此组的CPU shares (权重),类似于nice值对进程的作用
#endif// ... 其他调度类(如RT)的组调度字段 ...
};
- 层次化结构:
- 每个
task_group在它的父task_group的cfs_rq(或根cfs_rq)中表现为一个sched_entity。这个se的权重由该task_group的shares(或其他配置)决定。 - 当这个
group_se被选中运行时,分配给它的CPU时间片会进一步在其内部的cfs_rq中根据组内任务(或其他子组的se)的权重进行分配。
- 每个
- 资源分配:
- 管理员可以为不同的cgroup设置CPU
shares。shares越高的组,能获得的CPU时间比例就越大。 - 例如,有两个组A和B,A的
shares是1024,B的shares是2048。那么在竞争CPU时,B组理论上能获得A组两倍的CPU时间。
- 管理员可以为不同的cgroup设置CPU
- 实现:
- 当一个任务运行时,它的
vruntime更新会影响它自己的se以及它所属的所有祖先task_group的se。 - 调度决策也是分层的:首先在顶层
cfs_rq中选择一个se(可能是普通任务的se,也可能是group_se)。如果选中的是group_se,则再进入该group的cfs_rq中选择下一个se,依此类推,直到选中一个具体任务的se。
- 当一个任务运行时,它的
10. 多核负载均衡 (Multicore Load Balancing)
CFS为每个CPU维护一个独立的运行队列,这带来了良好的扩展性,但也引入了负载均衡的需求,以确保所有CPU的负载大致相当,避免某些CPU过载而其他CPU空闲。
// 主要负载均衡函数原型 (简化)
// kernel/sched/fair.c (旧版) 或 kernel/sched/core.c (新版)
static int load_balance(int this_cpu, struct rq *this_rq,struct sched_domain *sd, enum cpu_idle_type idle,int *continue_balancing);// 负载均衡的触发时机:
// 1. 周期性触发: scheduler_tick中,尤其当CPU空闲时 (idle_balance) 或非空闲但负载不均时。
// 2. CPU变为空闲时: nohz_idle_balance。
// 3. 任务唤醒时: try_to_wake_up -> ttwu_queue -> select_task_rq_fair,可能会选择一个空闲或负载较轻的CPU。
// 4. exec() / set_cpus_allowed() 等改变任务状态或亲和性时。// 主要步骤:
// static int load_balance(...)
// {// ... 统计当前CPU和调度域(sd)的负载信息 .../* 1. 查找调度域中最繁忙的CPU组 (find_busiest_group) */// 调度域 (sched_domain) 是CPU的层次化分组 (如物理核心、NUMA节点、整个系统)。// 负载均衡首先在最小的域内进行,然后逐步扩大到更大的域。// find_busiest_group会找到域内负载最不均衡的CPU组,并返回该组中最繁忙的CPU。struct sched_group *busiest = find_busiest_group(sd, this_cpu, &imbalance, idle, &env);if (!busiest)return 0; // 没有找到不平衡的组// struct rq *busiest_rq = busiest_cpu_rq(busiest); // 获取最繁忙组中最繁忙CPU的rq/* 2. 如果找到不平衡,则尝试从最繁忙的CPU组中迁移任务 (pull_tasks) */// load_balance -> detach_tasks -> detach_one_task -> move_one_task// 会尝试从busiest_rq迁移一个或多个任务到this_rq。// 迁移任务时会考虑任务的cache-hotness,尽量不迁移cache-hot的任务。// 也会考虑任务是否允许在该CPU上运行 (cpus_allowed)。if (ld_moved_tasks) // 如果成功迁移了任务return 1; // 表示发生了负载均衡
// return 0;
// }
(实际的load_balance函数在现代内核中更复杂,如nohz_idle_balance, active_load_balance, trigger_load_balance等,它们会调用核心的平衡逻辑。)
关键概念:
sched_domain: CPU的层次化分组,定义了负载均衡的范围和策略。例如,DIE(per-die),MC(multi-core, per-socket),NUMA(per-NUMA-node),PHY(physical package) 等。负载均衡优先在小域内进行,以利用缓存局部性。sched_group:sched_domain内的CPU子集,具有相似的调度属性。- 负载计算 (
PELT- Per-Entity Load Tracking): CFS使用PELT来跟踪每个调度实体和每个cfs_rq的平均负载。这个负载值不仅考虑了任务的权重,还考虑了其最近的运行历史,是一个衰减平均值。 - Pull vs Push: Linux主要使用"pull"模型,即负载较轻的CPU主动从负载较重的CPU拉取任务。在某些情况下(如任务唤醒时选择目标CPU),可以看作是一种"push"。
- NUMA感知: 对于NUMA系统,负载均衡会优先将任务保留在其内存所在的NUMA节点上,以减少远程内存访问的延迟。
11. 总结与展望
Linux CFS调度器通过其精巧的设计,在追求"完全公平"的核心理念下,实现了高效和可扩展的进程调度:
- 核心机制:
- 虚拟运行时间 (
vruntime): 作为公平性的基石,确保CPU时间按权重精确分配。 - 红黑树: O(log N)复杂度的任务管理,高效查找下一个运行任务。
- 权重系统: nice值到权重的非线性映射,提供了灵活的优先级控制。
- 虚拟运行时间 (
- 设计优点:
- 卓越的公平性: 这是CFS最显著的特点。
- 良好的交互响应: 通过唤醒抢占、周期性抢占和
vruntime补偿机制。 - 高吞吐量: 通过动态时间片和高效的负载均衡。
- 可扩展性: Per-CPU数据结构和分层负载均衡适应多核和NUMA架构。
- 模块化:
sched_class设计使得可以方便地集成和切换不同的调度策略(如RT、Deadline)。
- 关键特性:
- 组调度: 实现了基于cgroup的层次化资源控制。
- 负载均衡: 复杂的多核负载均衡机制,努力平衡CPU利用率和缓存局部性。
- 动态时钟 (
CONFIG_NO_HZ_FULL): 在CPU专用于单个任务时,可以停止调度器时钟中断,减少抖动,提升性能。
- 可调参数 (Tunables):
/proc/sys/kernel/sched_latency_ns: 目标调度周期,CFS试图在此时间内让所有任务运行一次。/proc/sys/kernel/sched_min_granularity_ns: 任务一次运行的最小时间,防止过于频繁切换。/proc/sys/kernel/sched_wakeup_granularity_ns: 唤醒任务比当前任务vruntime小多少才触发抢占。/proc/sys/kernel/sched_migration_cost_ns: 估计任务迁移的开销,影响负载均衡决策。- CPU
shares(通过cgroup) 控制组之间的CPU分配。
CFS调度器是Linux内核中一个持续演进和优化的组件。未来的发展可能会继续关注:
- 能效调度 (Energy-Aware Scheduling, EAS): 在异构CPU架构(如ARM big.LITTLE)上更智能地分配任务,以平衡性能和功耗。
- 对延迟更敏感型应用的优化: 如实时音视频、金融交易等。
- 更大规模系统的可扩展性: 进一步提升在数百甚至数千核心系统上的调度性能。
- 与虚拟化、容器技术的深度集成: 提供更细粒度和隔离性的调度策略。
参考
- https://ifaceless.github.io/2019/11/17/guide-to-linux-scheduler/
- https://arthurchiao.art/blog/linux-cfs-design-and-implementation-zh/
- CPU bandwidth control for CFS, google, 2009
- A complete guide to Linux process scheduling