MySQL——七、索引
优势:极高查询效率;极高排序效率
劣势:占用磁盘空间;降低更新表的速度(可忽略,磁盘相对便宜;增删改比例较小)
索引结构
MYSQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构。
B+Tree索引: 最常见的索引类型,大部分引擎都支持B+树索引
Hash索引: 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询
为什么InnoDB存储引擎选择使用B+tree索引结构
- 相对于二叉树,层级更少,搜索效率高
- 对于B-tree,无论是叶子结点还是非叶子结点,都会保存数据,这导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低。
- 相对Hash索引,B+tree支持范围匹配及排序操作。
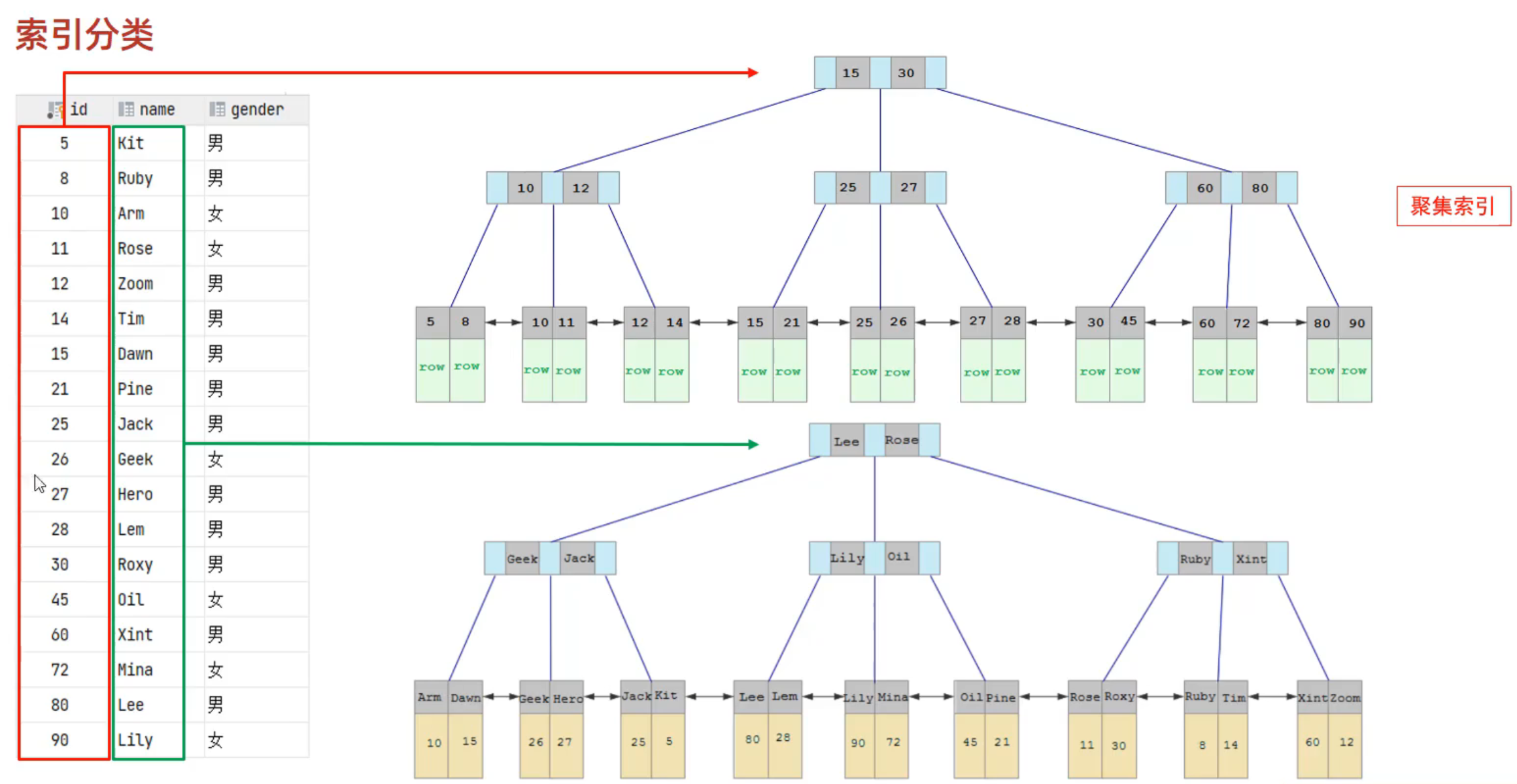
索引分类


索引语法
创建索引:
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_col_name,...);
查看索引:
SHOW INDEX FROM table_name;
删除索引:
DROP INDEX index_name ON table_name;
性能分析
SQL执行频率
通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session是查看当前会话
-- global是查询全局数据
SHOW [SESSION|GLOBAL] status LIKE 'COM_______';
通过SQL的执行频次可以确定数据库是以增删改为主,还是查询为主。
慢查询日志
慢查询日志记录了所有执行时间超过指定参数的所有SQL语句的日志。可借此定位查询语句进行优化。
profile详情
了解时间耗费到哪里
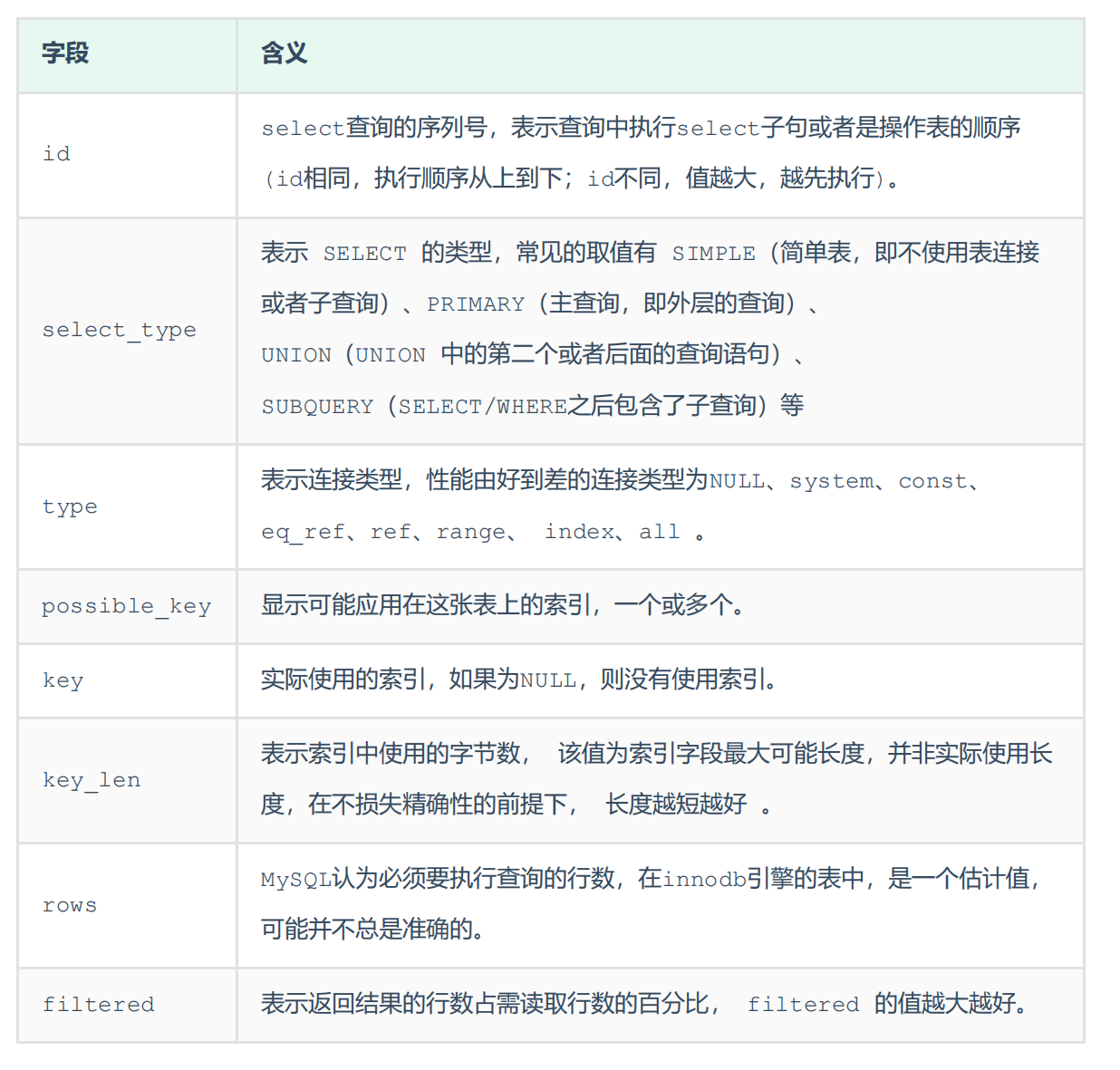
explain
explain或者DESC命令获取MySQL如何执行SELECT语句的信息,包括SELECT语句执行过程中表如何连接和连接的顺序。
索引使用
- 最左前缀法则: 如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将部分失效(后面的字段索引失效)
- 范围查询: 联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
- 索引列运算: 在索引列上进行运算操作,索引将失效
- 字符串不加引号: 字符串类型字段使用时,不加引号,索引将失效
- 模糊查询: 如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
- or连接的条件: 用or分割开的条件,如果or前的条件中的列有索引,而后面的列中,没有索引,那么涉及的索引都不会被用到
- 数据分布影响: 如果MySQL评估使用索引比全部更慢,则不使用索引
索引设计原则
- 针对数据量较大,且查询比较频繁的表建立索引
- 针对where,order by,group by操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段的长度较长,可以z针对字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引不是多多益善,索引越多,维护索引结构的代价也越大,会影响增删改的效率
- 如果索引列不能存储null值,在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询