【论文解读】| ACL2024 | LANDeRMT:基于语言感知神经元路由的大模型机器翻译微调框架
LANDeRMT:基于语言感知神经元路由的大模型机器翻译微调框架

论文地址:https://aclanthology.org/2024.acl-long.656/
一、研究背景与核心问题
1.1 大语言模型(LLM)在机器翻译中的潜力与挑战
- 潜力:BLOOM、LLaMA2等多语言LLM仅需少量示例即可实现跨语言翻译(In-Context Learning, ICL)
- 核心挑战:
- 灾难性遗忘:微调新语言对时,原有语言知识丢失
- 参数干扰:翻译任务微调影响LLM其他任务性能
- 传统方案局限:适配器(Adapter)、LoRA等方法未解决参数共享导致的冲突
1.2 关键研究问题
如何设计一种微调方法,在提升特定语言对翻译质量的同时:
- 避免灾难性遗忘
- 减少参数干扰
- 保持模型原有任务能力
二、方法创新:LANDeRMT框架
2.1 整体架构
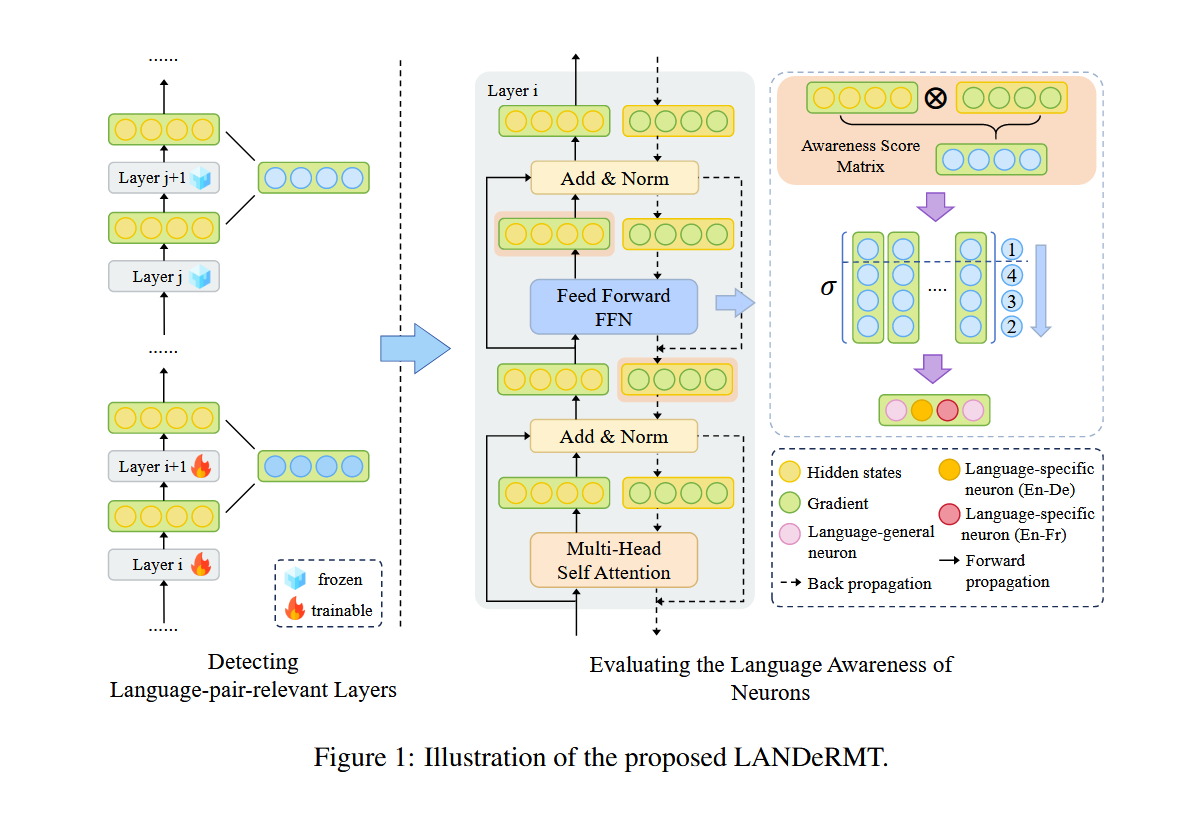
包含三个核心组件:
- 语言对相关层检测
- 神经元语言感知评估
- 条件感知路由机制
2.2 核心技术细节
2.2.1 语言对相关层检测
通过激活差异定位关键翻译层:
D i = ∣ 1 N ∑ n = 1 N A i , n − 1 N ∑ n = 1 N A i + 1 , n ∣ ( 1 ) D_{i}=\left|\frac{1}{N} \sum_{n=1}^{N} A_{i, n}-\frac{1}{N} \sum_{n=1}^{N} A_{i+1, n}\right| \quad (1) Di= N1n=1∑NAi,n−N1n=1∑NAi+1,n (1)
- A i , n A_{i,n} Ai,n:第 n n n次前向传播时第 i i i层的激活值
- 选择激活差异最大(Top-k)的层作为语言对相关层
- 实验设置:k=4时效果最佳
2.2.2 神经元语言感知评估
采用泰勒展开评估神经元重要性:
Φ ( i ) = ∣ Δ L ( h i ) ∣ = ∣ ∂ L ∂ h i h i ∣ ( 2 ) \Phi(i)=\left|\Delta \mathcal{L}\left(h_{i}\right)\right|=\left|\frac{\partial \mathcal{L}}{\partial h_{i}} h_{i}\right| \quad (2) Φ(i)=∣ΔL(hi)∣= ∂hi∂Lhi (2)
- Φ ( i ) \Phi(i) Φ(i):神经元 i i i对语言任务的感知分数
- 方差阈值 λ ( i ) \lambda(i) λ(i)区分通用/特定神经元:
λ ( i ) = sort ( σ ( X i ) ) ⌊ ϵ × p ⌋ ( 3 ) \lambda(i)=\text{sort}(\sigma(X_i))_{\lfloor\epsilon × p\rfloor} \quad (3) λ(i)=sort(σ(Xi))⌊ϵ×p⌋(3)- ϵ = 0.9 \epsilon=0.9 ϵ=0.9时保留前10%高方差特定神经元
2.2.3 条件感知路由机制(CAR)
动态分配神经元资源:
C A R ( x t ) = ∑ i = 1 N Φ ( i ) ∑ i = 1 N Φ ( i ) + ∑ j = 1 M Φ ( j ) ( 4 ) CAR(x_t)=\frac{\sum_{i=1}^{N} \Phi(i)}{\sum_{i=1}^{N} \Phi(i)+\sum_{j=1}^{M} \Phi(j)} \quad (4) CAR(xt)=∑i=1NΦ(i)+∑j=1MΦ(j)∑i=1NΦ(i)(4)
- N N N:特定语言神经元数量
- M M M:通用语言神经元数量
- 输出融合:
H f = F F N G ( C A R ⋅ x t ) + F F N S ( ( 1 − C A R ) ⋅ x t ) ( 5 ) H^{f}=FFN_G(CAR \cdot x_t) + FFN_S((1-CAR) \cdot x_t) \quad (5) Hf=FFNG(CAR⋅xt)+FFNS((1−CAR)⋅xt)(5)
三、实验验证与分析
3.1 数据集与基线
- 训练数据:WMT通用翻译赛道数据(200K句对/语言对)
- 测试集:WMT16、WMT14、OPUS-100等
- 基线模型:
- 0-shot/In-context(ICL)
- Adapter/LoRA/Adapter-LoRA
- 全参数微调
3.2 主要结论
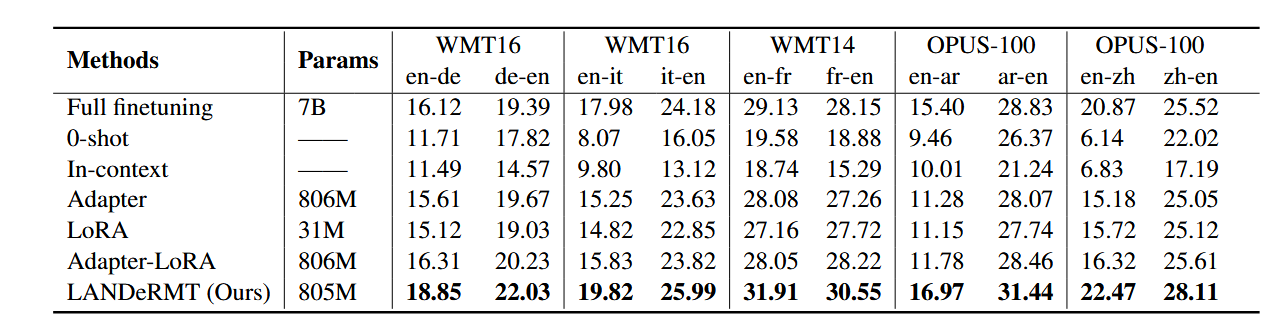
表 1:xx 到英语和英语到 xx 翻译的 10 个语言对的 BLEU 分数。每个平移方向的最高分以粗体突出显示。
关键发现:
使用sacreBLEU评估翻译性能。与ICL方法相比,LANDeRMT能利用新的并行训练数据提升LLMs翻译能力,在多个测试集和语言对中表现优异。
与其他微调基线模型相比,LANDeRMT在所有翻译方向上均取得最佳结果,尤其在低资源语言对(如英 - 中)上提升显著。
且相比全参数微调,其需调整的参数少,在参数数量上优势明显;与其他高效微调方法(如Adapter基线方法)相比,虽微调参数数量相近,但翻译质量更优。
3.3 消融实验
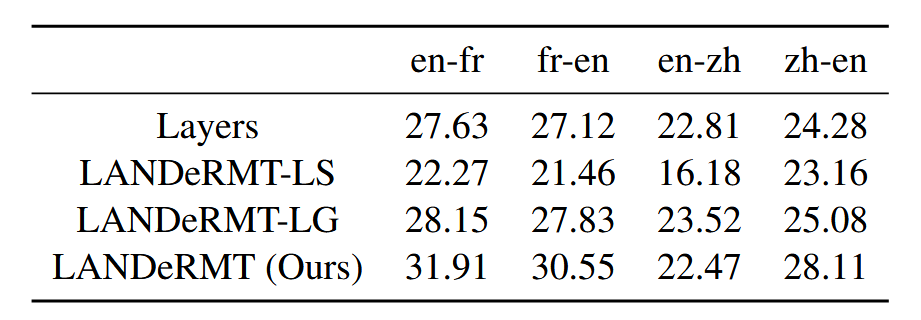
设置四种实验设置:Layers(微调语言对相关层的所有参数)、LANDeRMT - LS(仅微调选定层的特定语言参数)、LANDeRMT - LG(仅微调选定层的通用语言参数)、LANDeRMT(同时微调通用和特定语言参数)。
结果显示,LANDeRMT - LS因参数规模小(仅为Layers的10%)性能不如Layers;LANDeRMT在多个语言对上相比Layers、LANDeRMT - LS和LANDeRMT - LG均有显著BLEU分数提升,证明了CAR机制的有效性。
此外,LANDeRMT - LG虽微调参数少于Layers,但因有效捕获语言对齐信息,翻译性能较好,不过仅微调通用语言参数无法充分获取特定语言信息。
四、模型特性分析
4.1 跨语言迁移能力
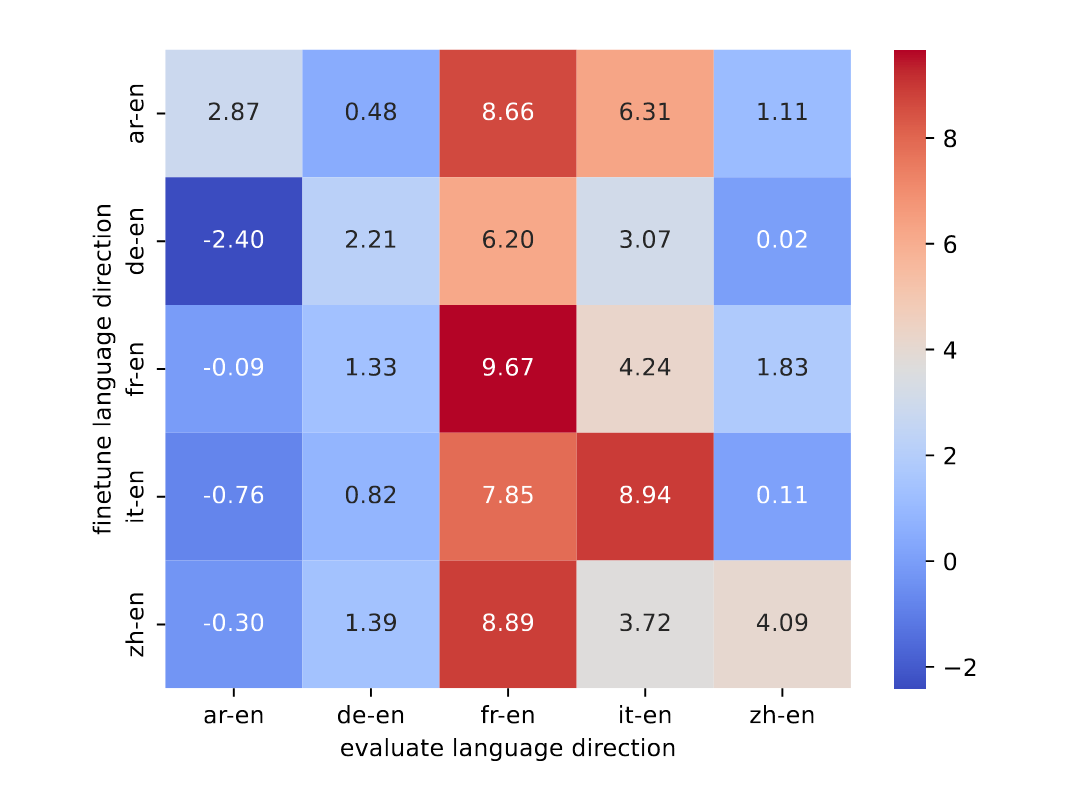
图 3:在 BLOOM7b 模型上使用 LANDeRMT 方法仅微调一个语言对,在其他语言对上实现 BLEU 分数提高。
- 语言相似性影响:罗曼语系(fr/it/es)间迁移效果显著
4.2 神经元可视化
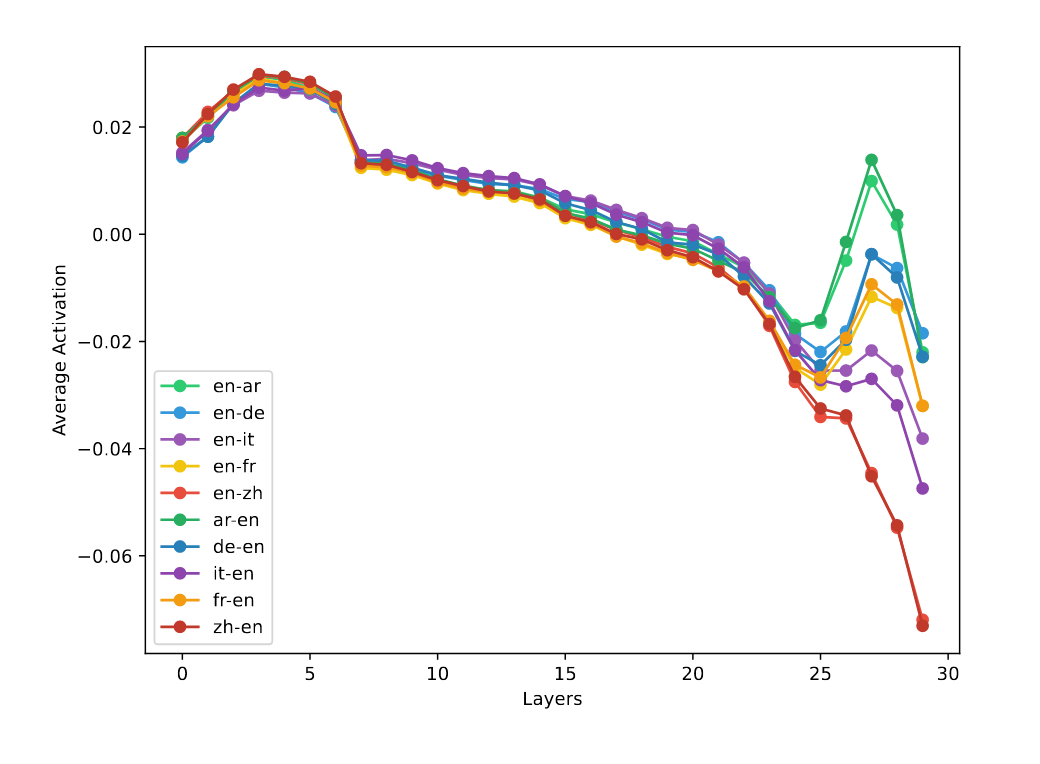
图 4:BLOOM-7b 模型中各种语言对设置的分层平均激活。
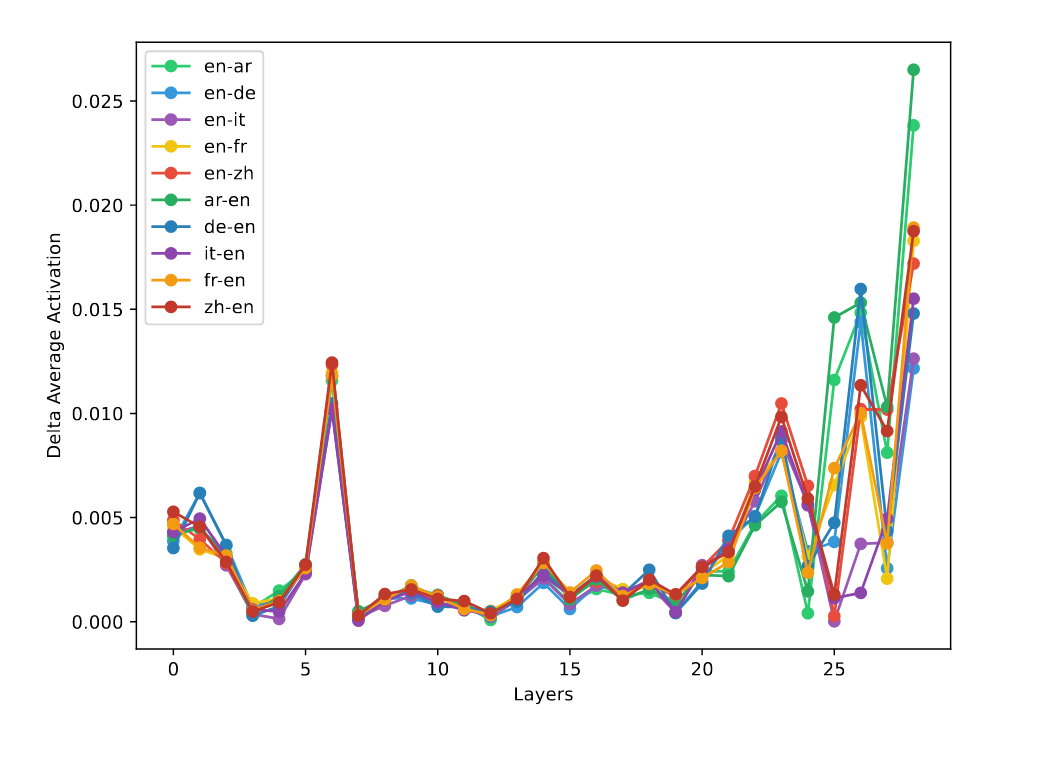
图 5:BLOOM-7b 模型中各种语言对设置的逐层增量平均激活。
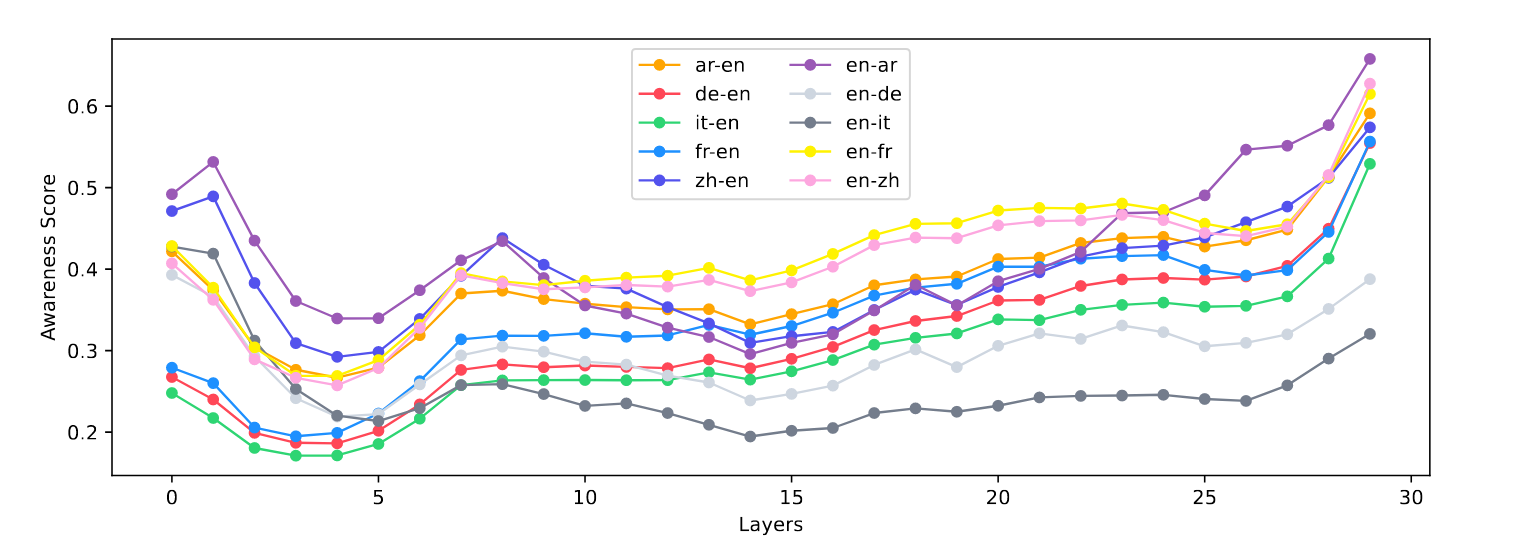
图 6:BLOOM-7b1 模型中不同语言设置下各层语言通用神经元感知分数的平均情况。
- 通用神经元:跨语言重叠度高
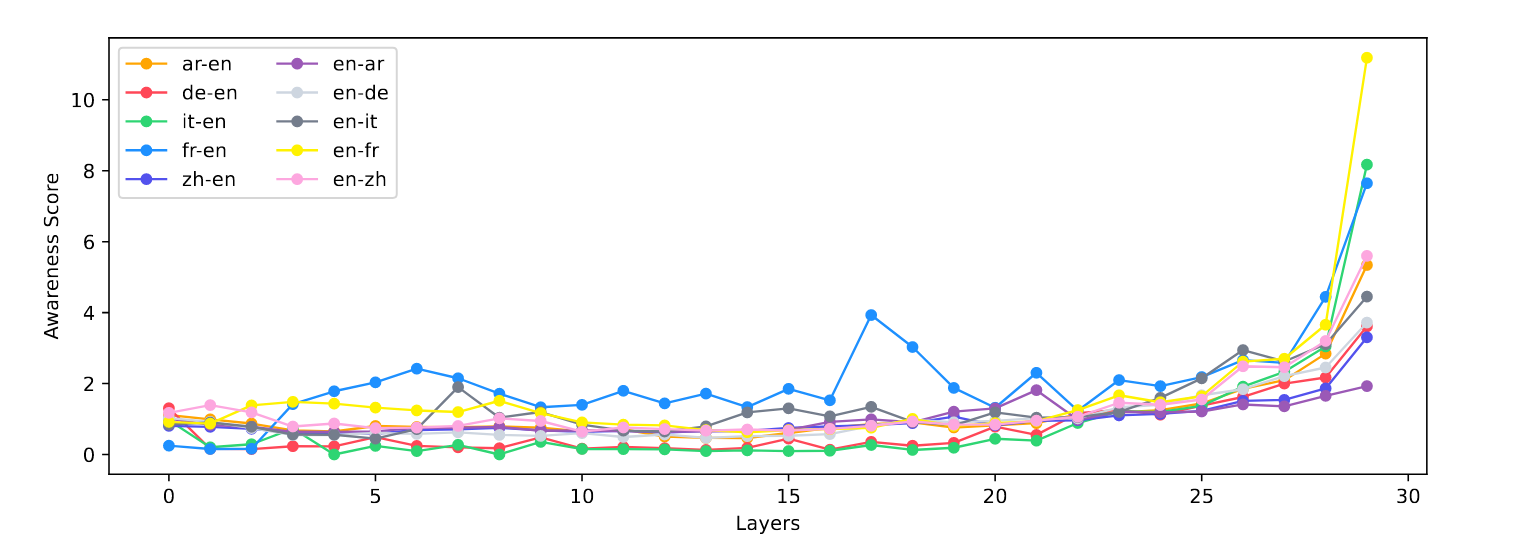
图 7:BLOOM-7b1 模型中不同语言设置下各层特定语言神经元感知分数的平均情况
- 特定神经元:语言边界清晰
计算层间激活值变化绝对值发现,模型早期和后期层包含语言对相关信息,早期层信息具有通用性,不同语言对重叠度高;后期层信息更具特定性,不同语言对重叠度低。
五、创新点总结
| 创新维度 | 具体贡献 |
|---|---|
| 方法论 | 提出首个基于神经元分析的LLM选择性微调框架 |
| 技术突破 | 1. 激活差异检测关键层 2. 泰勒展开量化神经元重要性 3. 动态路由机制 |
六、局限与未来方向
6.1 当前局限
- 计算成本:单卡A100微调BLOOM-7b需3天
- 低资源瓶颈:阿拉伯语等低资源语言提升有限
6.2 未来工作
- 动态神经元选择:根据输入语言实时调整微调神经元
- 知识蒸馏方案:将微调结果压缩到更小模型
- 多模态扩展:将方法应用于图文翻译任务
七、研究启示
- 神经元分工理论:LLM存在明确的语言通用/特定神经元分工
- 高效微调范式:为LLM任务定制化微调提供新思路
- 跨领域迁移:方法可扩展至文本摘要、对话理解等任务
本文提出的LANDeRMT框架为解决LLM灾难性遗忘提供了可解释性强、参数效率高的解决方案,其神经元级分析方法为模型压缩与知识迁移开辟了新的研究方向。