基于Transformer与SHAP可解释性分析的神经网络回归预测模型【MATLAB】
基于Transformer与SHAP可解释性分析的神经网络回归预测模型【MATLAB】
在当今的数据科学与人工智能领域,构建一个高精度的预测模型固然重要,但越来越多的应用场景开始关注模型的可解释性。尤其在金融、医疗、工业控制等对决策透明度要求较高的领域,我们不仅需要知道“预测结果是什么”,还需要理解“为什么是这个结果”。
本文将介绍一种结合Transformer架构与SHAP(Shapley Additive Explanations)方法的回归预测模型,并探讨其在MATLAB平台上的实现逻辑与优势。
一、什么是Transformer?它为何适合做回归预测?
Transformer是一种源于自然语言处理(NLP)领域的深度学习架构,最初用于处理文本数据中的长程依赖关系。它的核心机制是自注意力机制(Self-Attention),可以让模型在处理当前输入时“关注”到其他相关输入的信息。
虽然Transformer最初用于文本任务,但它的能力并不局限于语言。在时间序列预测、传感器数据分析等回归问题中,我们也常常面对多变量之间的复杂交互关系,而Transformer能够很好地捕捉这些关系。
例如,在工业预测维护中,多个传感器数据之间可能存在复杂的相互作用,传统的RNN或LSTM难以高效建模这种非线性依赖,而Transformer则可以通过注意力机制自动识别出哪些变量在什么时候“最重要”。
因此,将Transformer引入回归预测任务,有助于提升模型对复杂数据模式的理解能力与泛化性能。
二、什么是SHAP?它如何帮助我们理解模型?
尽管深度学习模型在许多任务上表现出色,但它们通常被视为“黑箱”——即使预测准确率很高,我们也很难知道模型是如何做出判断的。
这就引出了“模型可解释性”的需求。SHAP(Shapley Additive Explanations) 是一种基于博弈论的方法,用于解释机器学习模型中每个特征对预测结果的具体贡献。
简单来说,SHAP值告诉我们:对于某一次预测,某个输入变量是起到了正向推动还是负向影响,以及影响的程度有多大。
比如,在预测某个设备剩余寿命的任务中,温度传感器的读数可能是一个关键因素。通过SHAP分析,我们可以直观地看到该变量在不同时间点对预测值的影响变化,从而帮助工程师做出更有依据的判断。
三、Transformer + SHAP = 高精度 + 可解释性的双赢
本模型的核心思想是:
- 使用Transformer作为主干网络,从多变量时间序列中提取复杂的特征关系;
- 在模型训练完成后,利用SHAP方法对预测结果进行逐样本解释,揭示各个输入变量的重要性分布;
- 将整个流程集成在MATLAB环境中,借助其强大的工具箱支持快速开发与部署。
这样的组合不仅提升了预测精度,还增强了模型的透明度和可信度。用户不仅能获得预测值,还能理解背后的原因,这对于模型的实际落地应用至关重要。
四、应用场景举例
这种模型特别适用于以下几类任务:
- 工业预测性维护:通过多传感器数据预测设备故障时间;
- 金融市场预测:基于历史价格、成交量等指标预测未来走势;
- 环境监测:根据气象、污染等数据预测空气质量指数;
- 医疗健康:基于患者生理信号预测疾病风险等级。
在这些场景中,模型不仅要“猜得准”,还要“讲得清”。
五、总结
在本篇文章中,我们介绍了如何将Transformer这一强大的深度学习结构应用于回归预测任务,并结合SHAP技术增强模型的可解释性。这种组合不仅继承了Transformer在处理复杂时序数据方面的优势,也弥补了传统深度学习模型“黑箱”的不足。
随着AI技术在各行各业的深入应用,可解释性将成为衡量模型是否具备实用价值的重要标准之一。
六、部分实现代码
%% 清空环境变量
warning off% 关闭报警信息
close all% 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');%% 导入数据
res = xlsread('data.xlsx');%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
% res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
L = size(res, 2) - outdim; % 输入特征维度%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: L)';
T_train = res(1: num_train_s, L + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: L)';
T_test = res(num_train_s + 1: end, L + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test1 = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test1 = mapminmax('apply', T_test, ps_output);
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, L, 1, 1, M));
p_test = double(reshape(p_test1 , L, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test1 )';
%% 数据格式转换
for i = 1 : MLp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : NLp_test{i, 1} = p_test( :, :, 1, i);
end
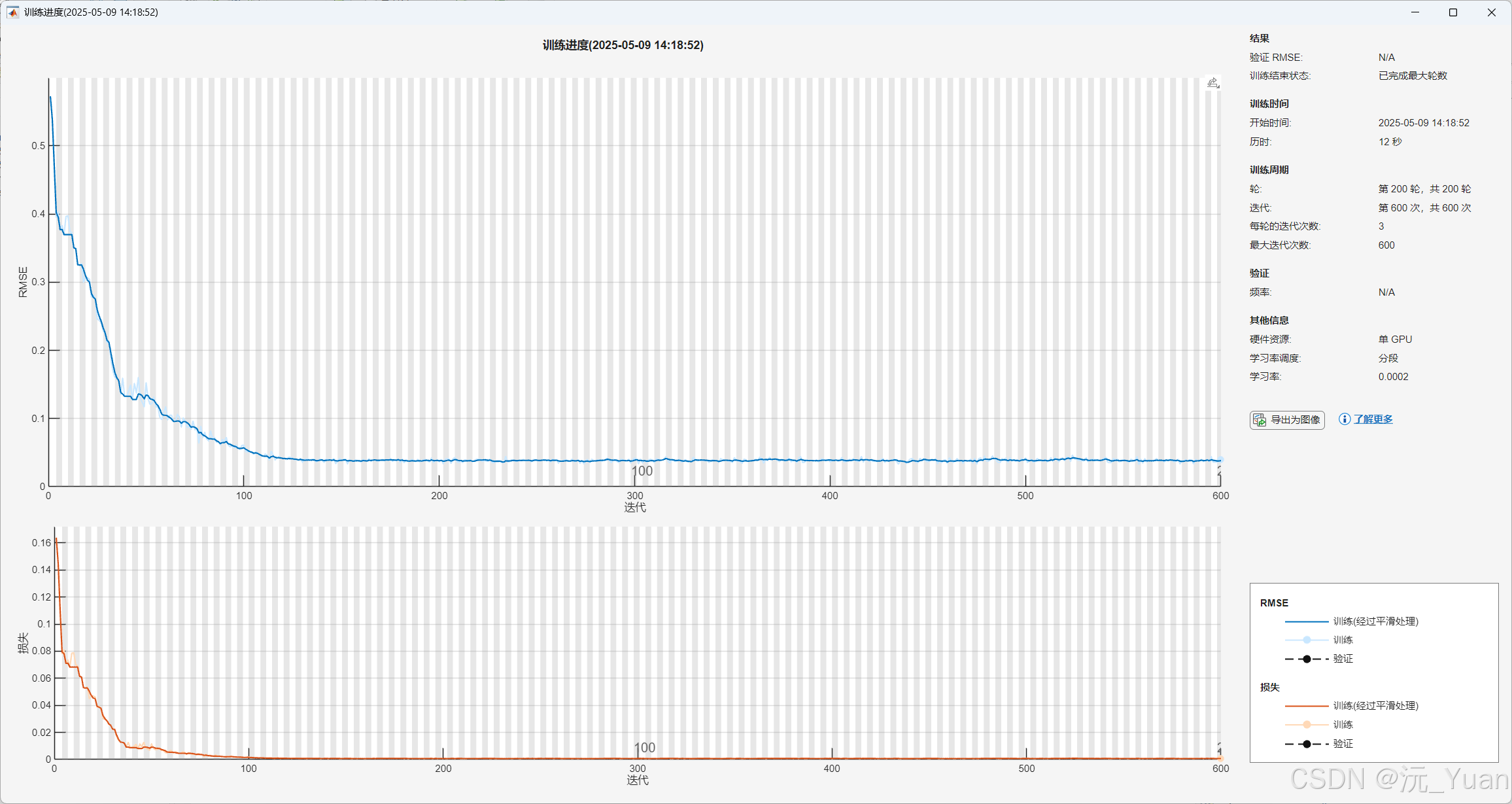
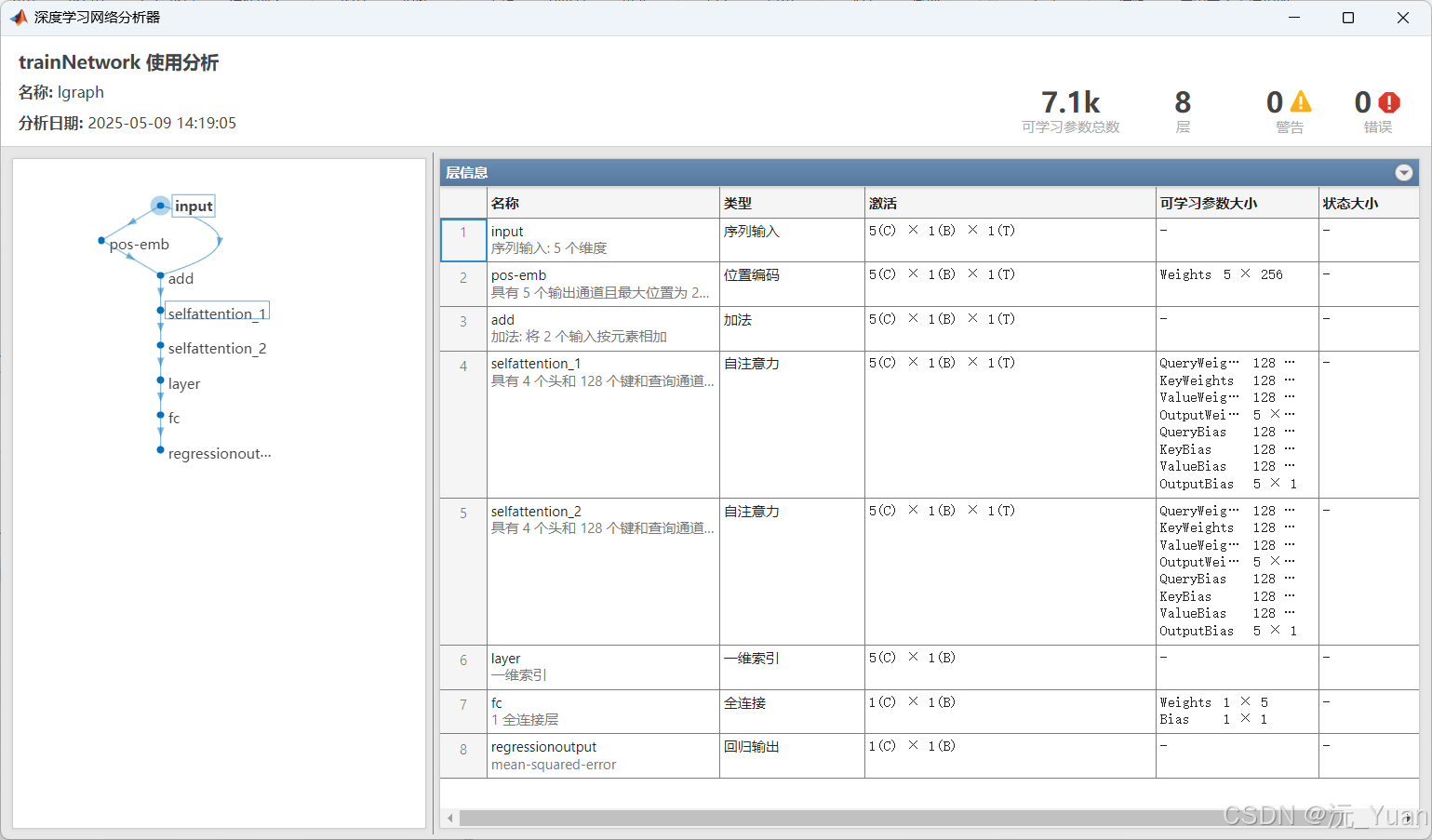
六、代码运行结果



七、代码下载
https://mbd.pub/o/bread/aZ6cm5hr