5月9日复盘-混合注意力机制
5月9日复盘
四、混合注意力
混合注意力机制(Hybrid Attention Mechanism)是一种结合空间和通道注意力的策略,旨在提高神经网络的特征提取能力。
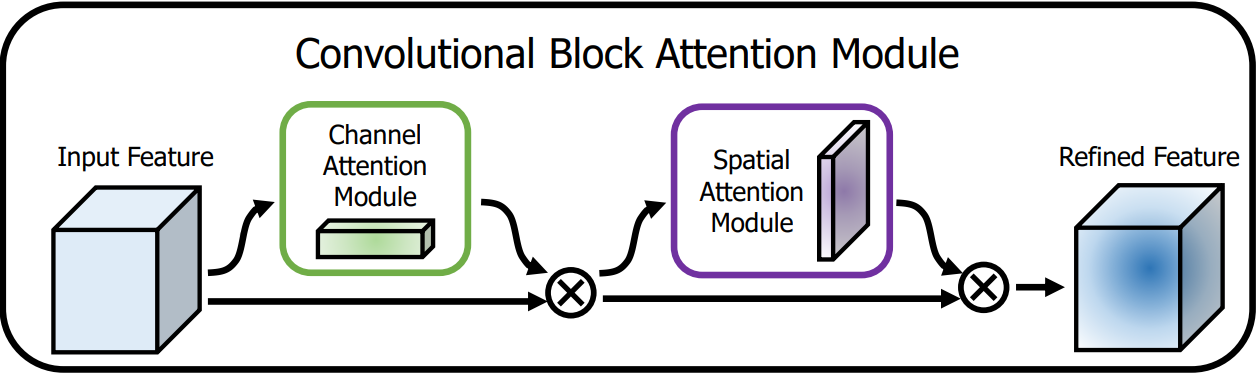
1. CBAM
Convolution Block Attention Module ,卷积块注意力模块
论文地址:https://arxiv.org/pdf/1807.06521
1.0 基本认知
CBAM是一种轻量级的注意力模块,它通过增加空间和通道两个维度的注意力,来提高模型的性能。
一维的通道注意力图: M c ∈ R C × 1 × 1 \mathcal{M}_{\mathbf{c}}\in\mathbb{R}^{C\times1\times1} Mc∈RC×1×1
二维的空间注意力图: M s ∈ R 1 × H × W \mathbf{M_s}\in\mathbb{R}^{1\times H\times W} Ms∈R1×H×W
整个注意力过程可以概括为:
F ′ = M c ( F ) ⊗ F , F ′ ′ = M s ( F ′ ) ⊗ F ′ \begin{aligned}\mathbf{F^{\prime}}&=\mathbf{M_{c}}(\mathbf{F})\otimes\mathbf{F},\\\mathbf{F^{\prime\prime}}&=\mathbf{M_{s}}(\mathbf{F^{\prime}})\otimes\mathbf{F^{\prime}}\end{aligned} F′F′′=Mc(F)⊗F,=Ms(F′)⊗F′
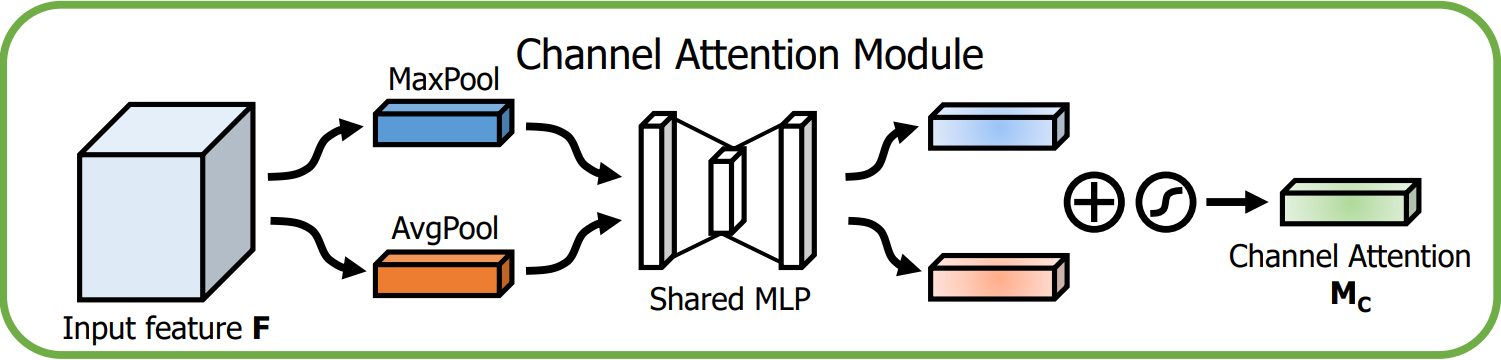
1.1 通道注意力模块
通道注意力模块的目的是为每个通道生成一个注意力权重,整体流程如下图:
通道注意力模块机制公式如下:
M c ( F ) = σ ( M L P ( A v g P o o l ( F ) ) + M L P ( M a x P o o l ( F ) ) ) = σ ( W 1 ( W 0 ( F a v g c ) ) + W 1 ( W 0 ( F m a x c ) ) ) , \begin{gathered} \mathrm{M_{c}(F)} =\sigma(MLP(AvgPool(\mathbf{F}))+MLP(MaxPool(\mathbf{F}))) \\ =\sigma(\mathbf{W_1}(\mathbf{W_0}(\mathbf{F_{avg}^c}))+\mathbf{W_1}(\mathbf{W_0}(\mathbf{F_{max}^c}))), \end{gathered} Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favgc))+W1(W0(Fmaxc))),
其中: r r r是缩放因子,用以减少参数量
W 0 ∈ R C / r × C W 1 ∈ R C × C / r \mathrm{W}_0\in\mathbb{R}^{C/r\times C} \\ \mathrm{W}_1\in\mathbb{R}^{C\times C/r} W0∈RC/r×CW1∈RC×C/r
通道注意力模块机制详情如下:
-
输入特征:输入特征图 F F F 的尺寸为 H × W × C H × W × C H×W×C。
-
全局池化:
- 首先对 F F F 进行全局的MaxPool和AvgPool,得到两个特征图,尺寸为 1 × 1 × C 1×1×C 1×1×C。
- MaxPool提取了局部强响应特征,AvgPool提取了全局视角。
-
共享多层感知器(MLP):
- 池化后的2个特征向量分别送入一个共享MLP,它包含两个全连接层,用来处理和生成通道注意力。
- MLP的共享权重减少了参数量,同时确保两个特征向量的变换方式是一致的。
- MLP首先会降维为 C / r C/r C/r,然后升维为 C C C。
-
加法与激活:
MLP输出的两个特征向量逐元素相加后经Sigmoid后,生成维度为 1 × 1 × C 1 × 1 × C 1×1×C的通道注意力图 M c M_c Mc,表示每个通道的重要性。
-
输出:
通道注意力图 M c M_c Mc 与输入特征图 F F F 逐通道相乘,生成经过通道注意力增强的特征图,维度不变的。
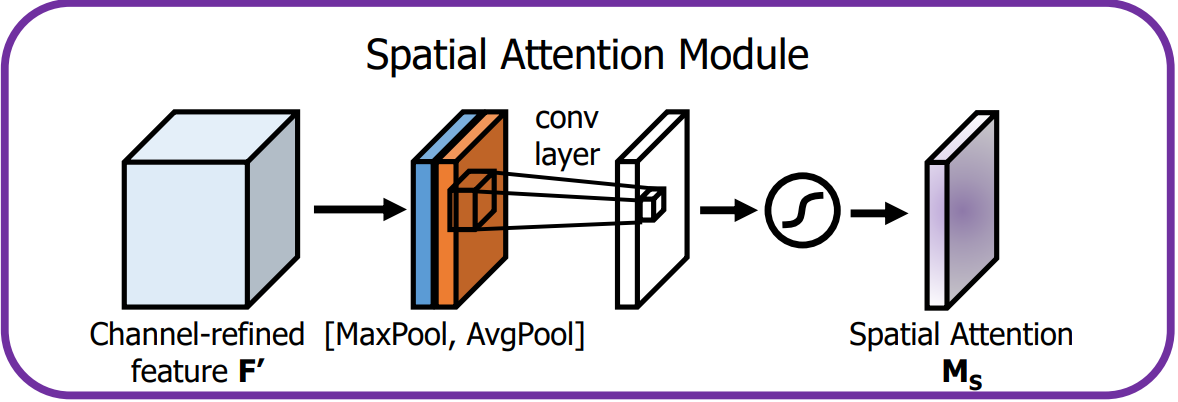
1.2 空间注意力模块
空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域。
空间注意力模块机制公式如下:
M s ( F ) = σ ( f 7 × 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( f 7 × 7 ( [ F a v g s ; F m a x s ] ) ) , \begin{aligned} \mathbf{M_s}(\mathbf{F})& \begin{aligned}&=\sigma(f^{7\times7}([AvgPool(\mathbf{F});MaxPool(\mathbf{F})]))\end{aligned} \\ &=\sigma(f^{7\times7}([\mathbf{F_{avg}^s};\mathbf{F_{max}^s}])), \end{aligned} Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favgs;Fmaxs])),
其中:
F a v g s ∈ R 1 × H × W F m a x s ∈ R 1 × H × W \mathbf{F_{avg}^s}\in\mathbb{R}^{1\times H\times W} \\ \mathbf{F_{max}^s}\in\mathbb{R}^{1\times H\times W} Favgs∈R1×H×WFmaxs∈R1×H×W
空间注意力模块机制详情如下:
-
输入特征:通道注意力模块的输出 F ′ F' F′ 就是空间注意力模块的输入。
-
池化操作:
- 首先在 F ′ F' F′ 的通道维度上进行全局的MaxPool和AvgPool,生成2个二维特征图,维度为 H × W × 1 H × W × 1 H×W×1。
- 这样可以分别提取空间上最重要的局部和全局信息。
-
卷积层:
将池化得到的两个特征图按通道维度进行连接,形成一个 H × W × 2 H × W × 2 H×W×2 的特征图,并通过大小为 7 × 7 7 × 7 7×7 的卷积层处理。
-
激活与输出:
- 卷积层的输出经Sigmoid激活后,生成单通道的空间注意力图 M S M_S MS,维度为 H × W × 1 H \times W \times 1 H×W×1。
- 空间注意力图与经过通道注意力增强后的特征图 F ′ F' F′ 逐元素相乘,输出最终的增强特征图。
1.3 不同策略效果对比
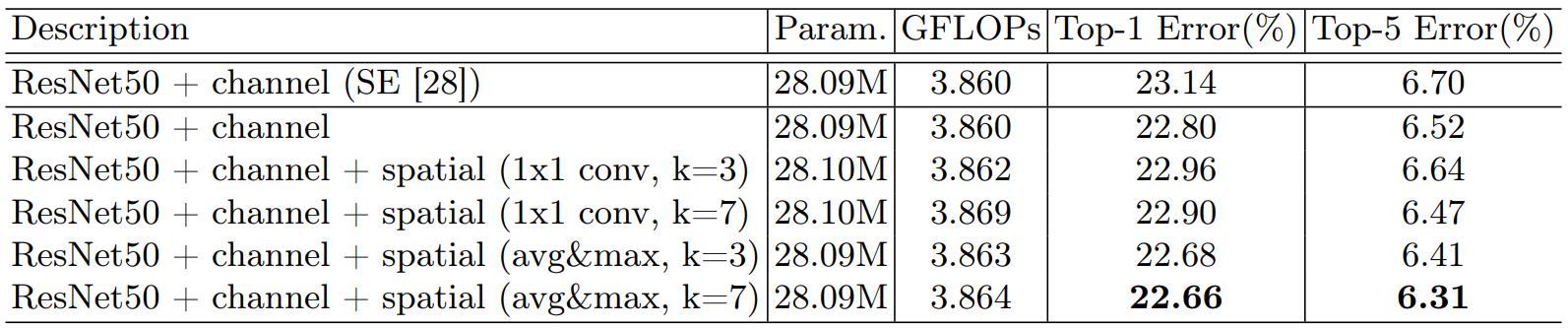
1.3.1 通道注意力
加入通道注意力:可以看的出来都比不用(baseline)效果要好

1.3.2 叠加空间注意力
在通道注意力的基础之上加入空间注意力,就是混合注意力:效果最好的就是CBAM,并且池化不需要参数
1.3.3 叠加顺序
空间注意力和通道注意力位置调整效果对比:还是CBAM的效果好

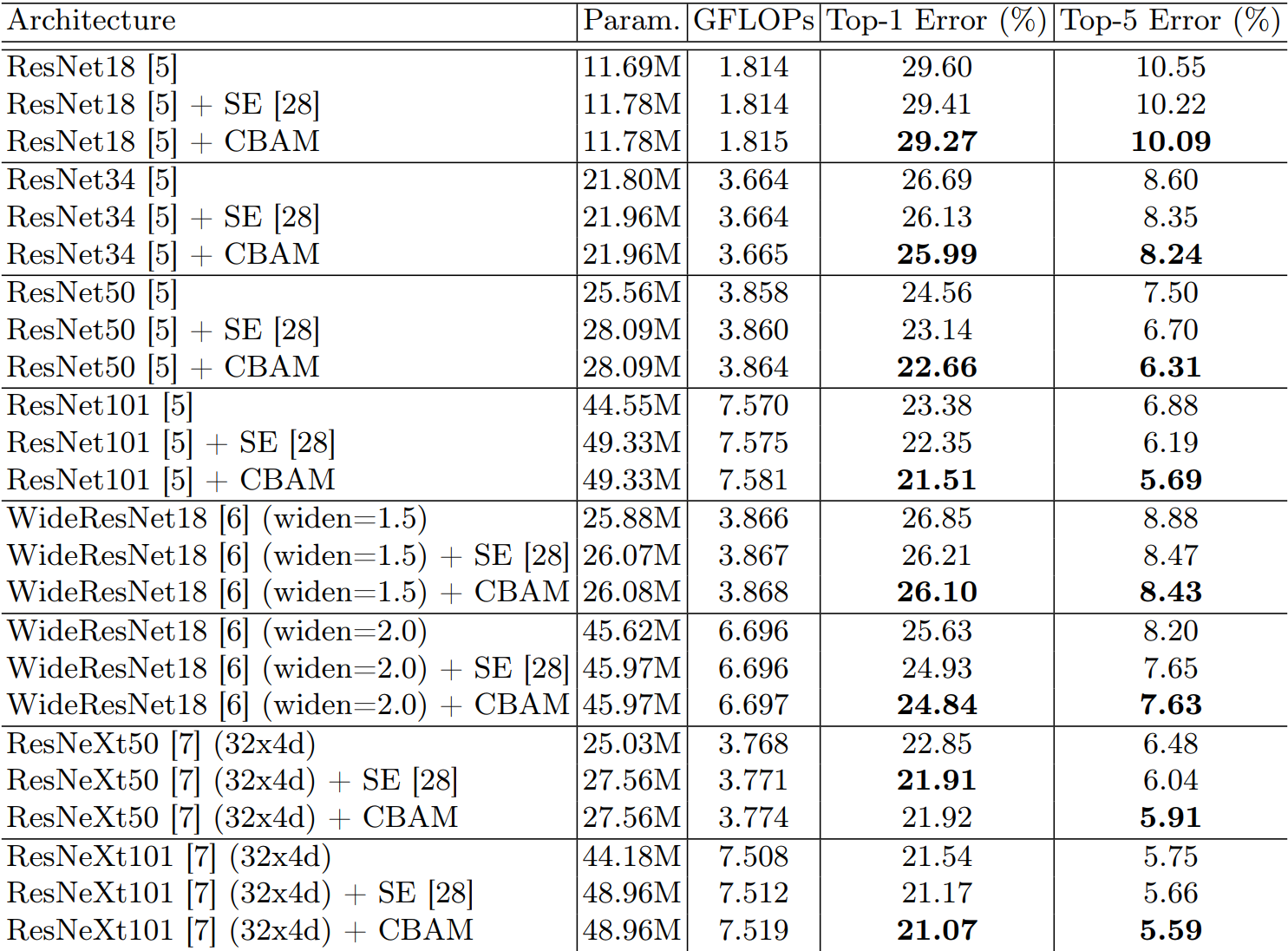
1.3.4 不同模型
不同模型对比:主打一个CBAM就是好
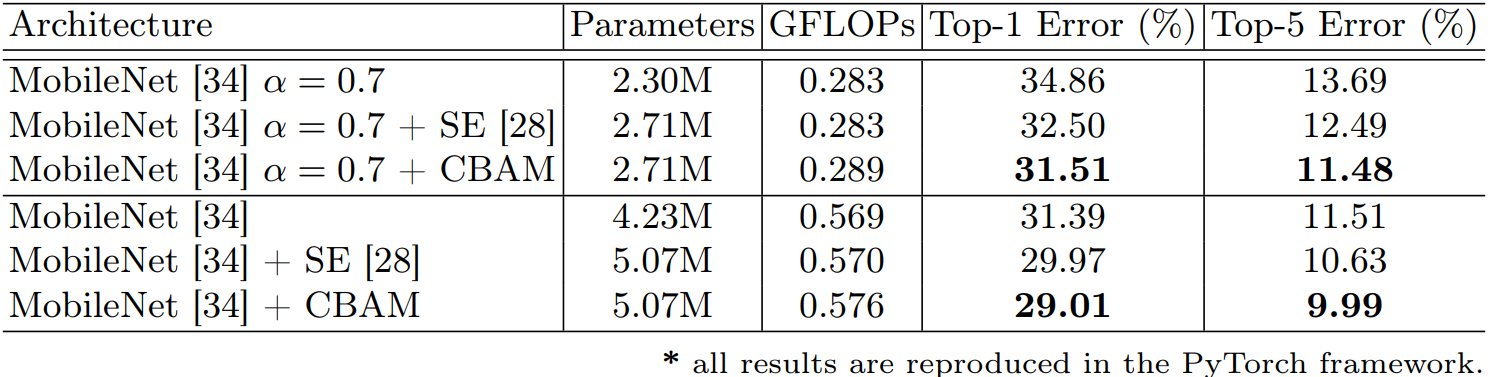
1.3.5 轻量级模型
在一些轻量级模型上的效果还是很明显的
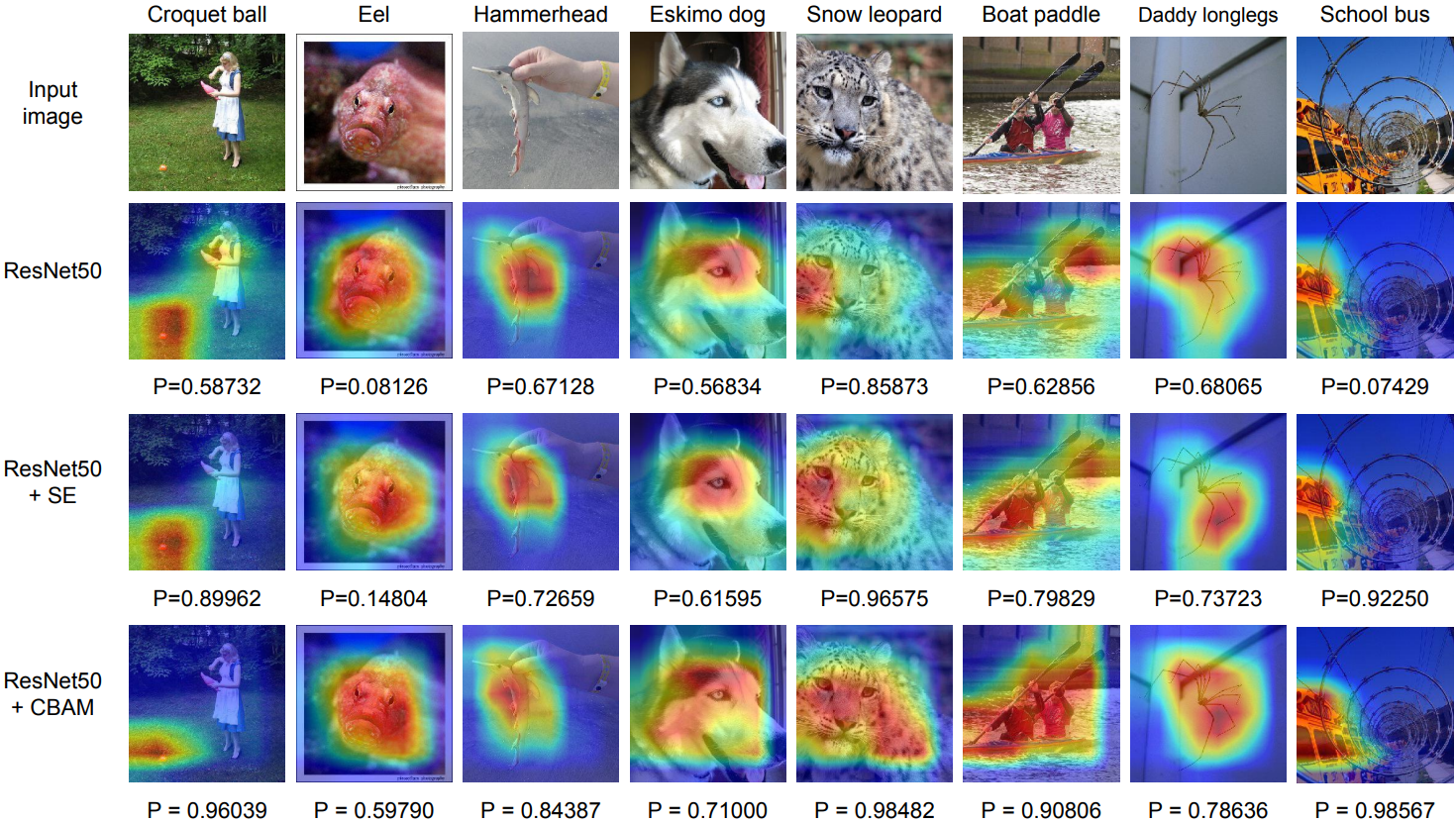
1.3.6 注意力可视化
可视化的方式对比:

2. BAM
Bottleneck Attention Module,瓶颈注意力模块。
论文地址:https://arxiv.org/pdf/1807.06514
2.0 基本认知
BAM是通过在空间和通道两个维度上分别构建注意力模块,它们是并行处理的。
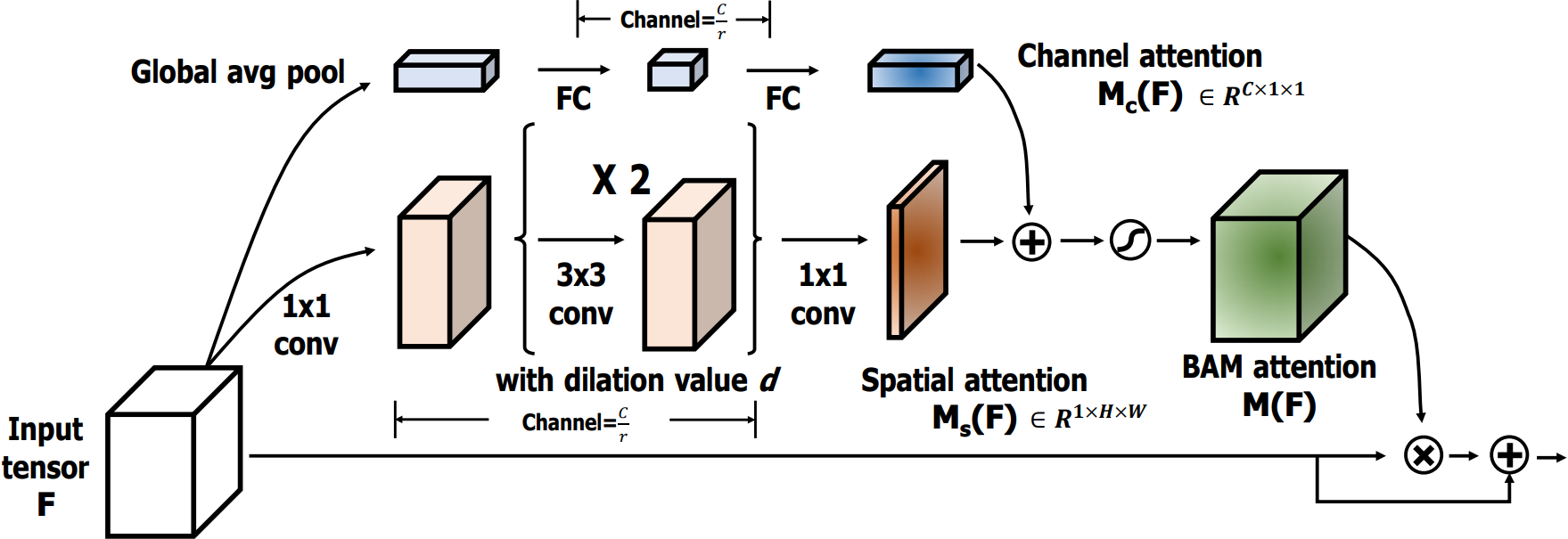
其中:形状不同的张量会自动进行广播机制
M ( F ) = σ ( M c ( F ) + M s ( F ) ) , F ′ = F + F ⊗ M ( F ) , \mathbf{M(F)=\sigma(M_c(F)+M_s(F)),} \\ \mathbf{F^{\prime}=F+F\otimes M(F),} M(F)=σ(Mc(F)+Ms(F)),F′=F+F⊗M(F),
2.1 通道注意力模块
通道注意力公式表达如下:
M c ( F ) = B N ( M L P ( A ν g P o o l ( F ) ) ) = B N ( W 1 ( W 0 A ν g P o o l ( F ) + b 0 ) + b 1 ) , 其中: W 0 ∈ R C / r × C , b 0 ∈ R C C / r , W 1 ∈ R C × C / r , b 1 ∈ R C . \begin{aligned} \mathbf{M_c(F)}& =BN(MLP(A\nu gPool(\mathbf{F}))) \\ &=BN(\mathbf{W_1}(\mathbf{W_0}A\nu gPool(\mathbf{F})+\mathbf{b_0})+\mathbf{b_1}), \\ \text{其中:} \mathbf{W_0}\in\mathbb{R}^{C/r\times C},\mathbf{b_0}\in\mathbb{R}^{C}& ^{C/r},\mathbf{W_1}\in\mathbb{R}^{C\times C/r},\mathbf{b_1}\in\mathbb{R}^C. \end{aligned} Mc(F)其中:W0∈RC/r×C,b0∈RC=BN(MLP(AνgPool(F)))=BN(W1(W0AνgPool(F)+b0)+b1),C/r,W1∈RC×C/r,b1∈RC.
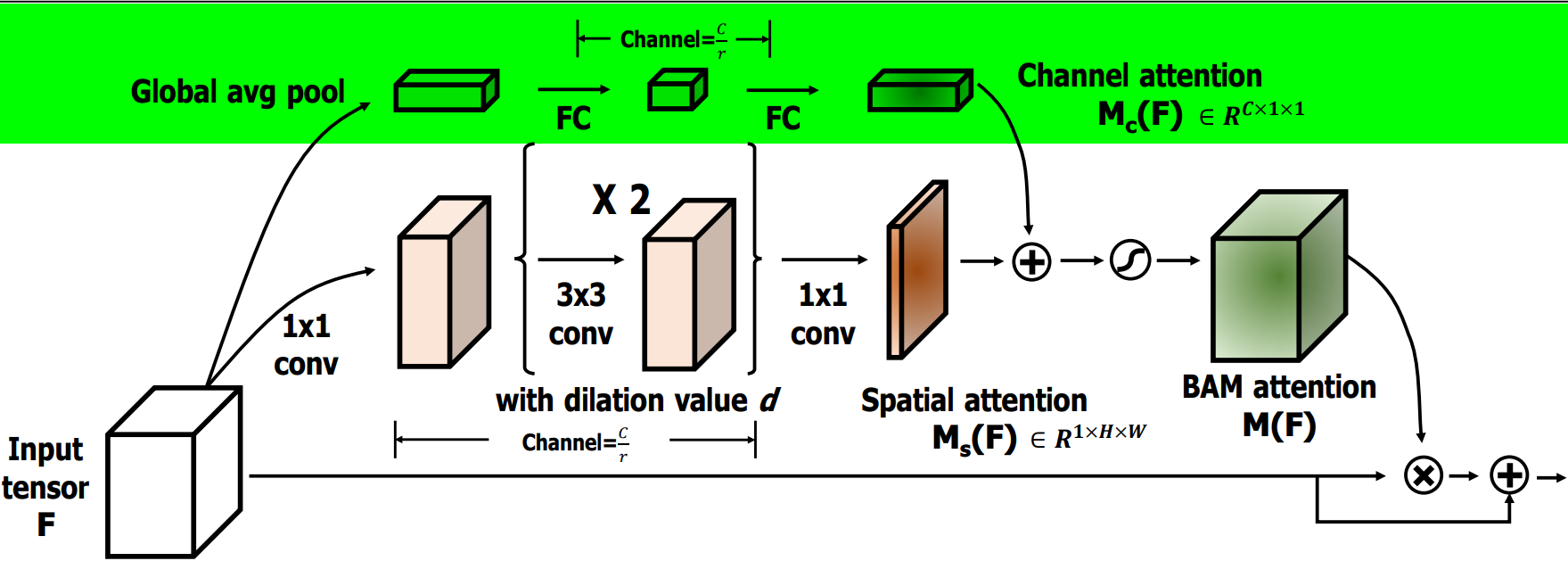
通道注意力流程如下:
-
全局平均池化:对输入特征 F F F 进行GlobalAvgPooling,保留通道的重要全局信息。
-
全连接层:池化后的特征通过两个FC,第一个FC降维,第二个FC则恢复到原通道数 C C C。这一过程可以学习通道间的依赖关系。
-
通道注意力:通过激活函数 S i g m o i d Sigmoid Sigmoid 生成通道注意力图 M c ( F ) M_c(F) Mc(F),用于对原始通道进行加权,强调重要通道,抑制不重要通道。
2.2 空间注意力模块
空间注意力公式表达如下:
M s ( F ) = B N ( f 3 1 × 1 ( f 2 3 × 3 ( f 1 3 × 3 ( f 0 1 × 1 ( F ) ) ) ) ) \mathbf{M_s}(\mathbf{F})=BN(f_3^{1\times1}(f_2^{3\times3}(f_1^{3\times3}(f_0^{1\times1}(\mathbf{F}))))) Ms(F)=BN(f31×1(f23×3(f13×3(f01×1(F)))))
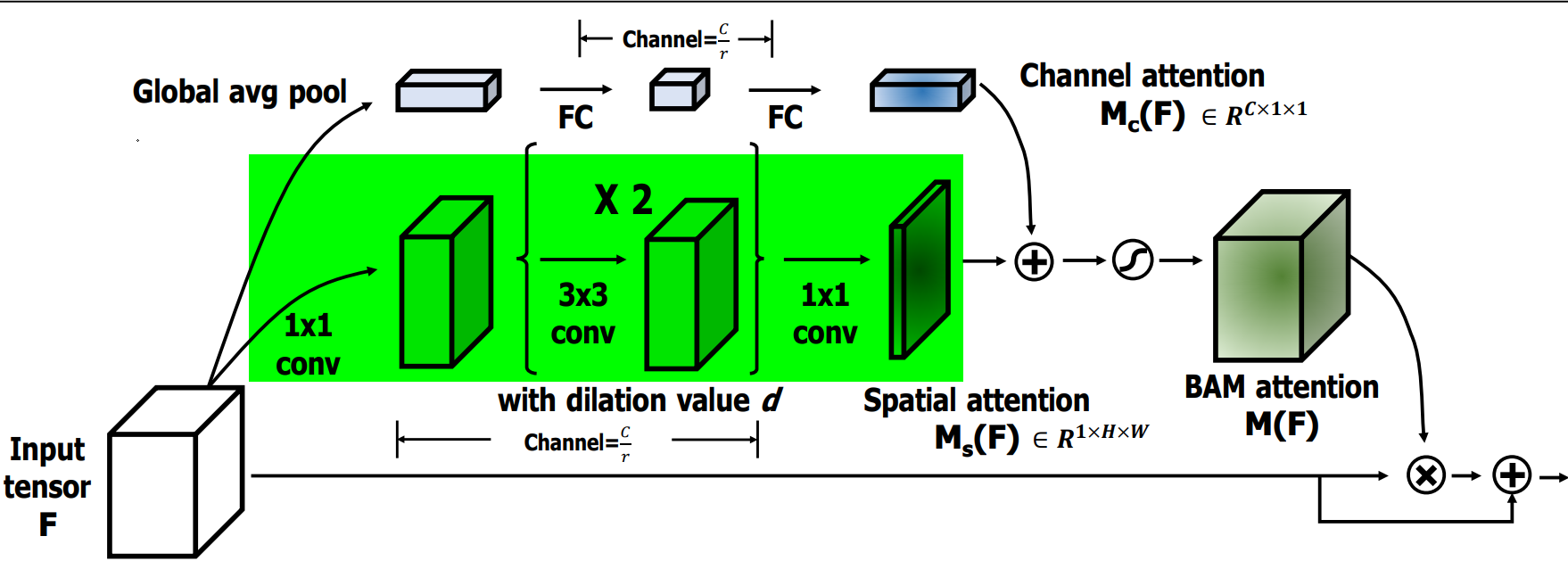
空间注意力流程如下:
-
1×1卷积:对输入特征 F F F 进行一次卷积操作,用于压缩通道维度并保持原始的空间信息,压缩因子是 r = 16 r=16 r=16。
-
膨胀卷积:使用两层膨胀卷积(Dilated Convolution),膨胀率为 d = 4 d=4 d=4。这样既扩大了感受野,又不增加参数量,帮助模型在空间维度上捕捉更广的上下文信息。
-
空间注意力生成:卷积操作生成一个空间注意力图 M s ( F ) M_s(F) Ms(F),用于标识出空间维度上哪些位置更重要。
2.3 注意力融合
通道和空间注意力融合: M c ( F ) M_c(F) Mc(F) 和 M s ( F ) M_s(F) Ms(F)相加后,通过Sigmoid处理,生成最终的注意力图 M ( F ) M(F) M(F)。
2.4 注意力应用
-
BAM注意力图 M ( F ) M(F) M(F) 应用到 F F F 上,从而对特征图进行重新加权。
-
残差连接:将加权后的特征图与输入特征 F F F 进行相加,形成残差连接。
这样不仅保留了原始特征信息,还让网络学习到重要的注意力区域。
2.5 实验结果
对比不同情况下的模型效果。
2.5.1 超参数配置
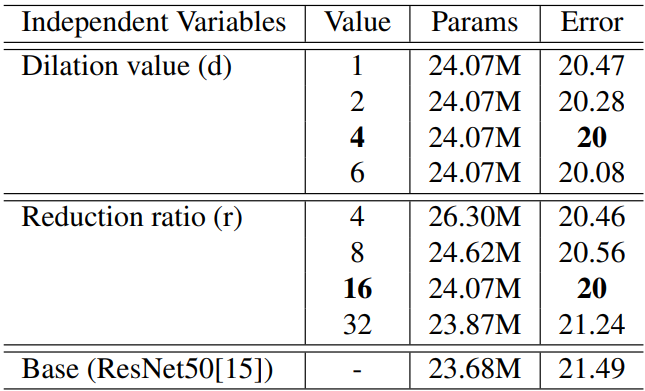
超参数:膨胀卷积的膨胀系数、FC的缩放因子
2.5.2 融合方式
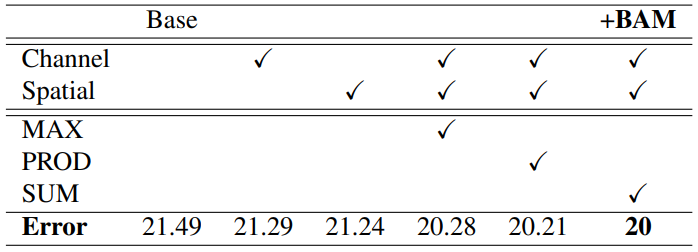
融合方式不同,效果也不同,最总就是两个注意力并行后相加效果最好。
2.5.3 模型横向对比
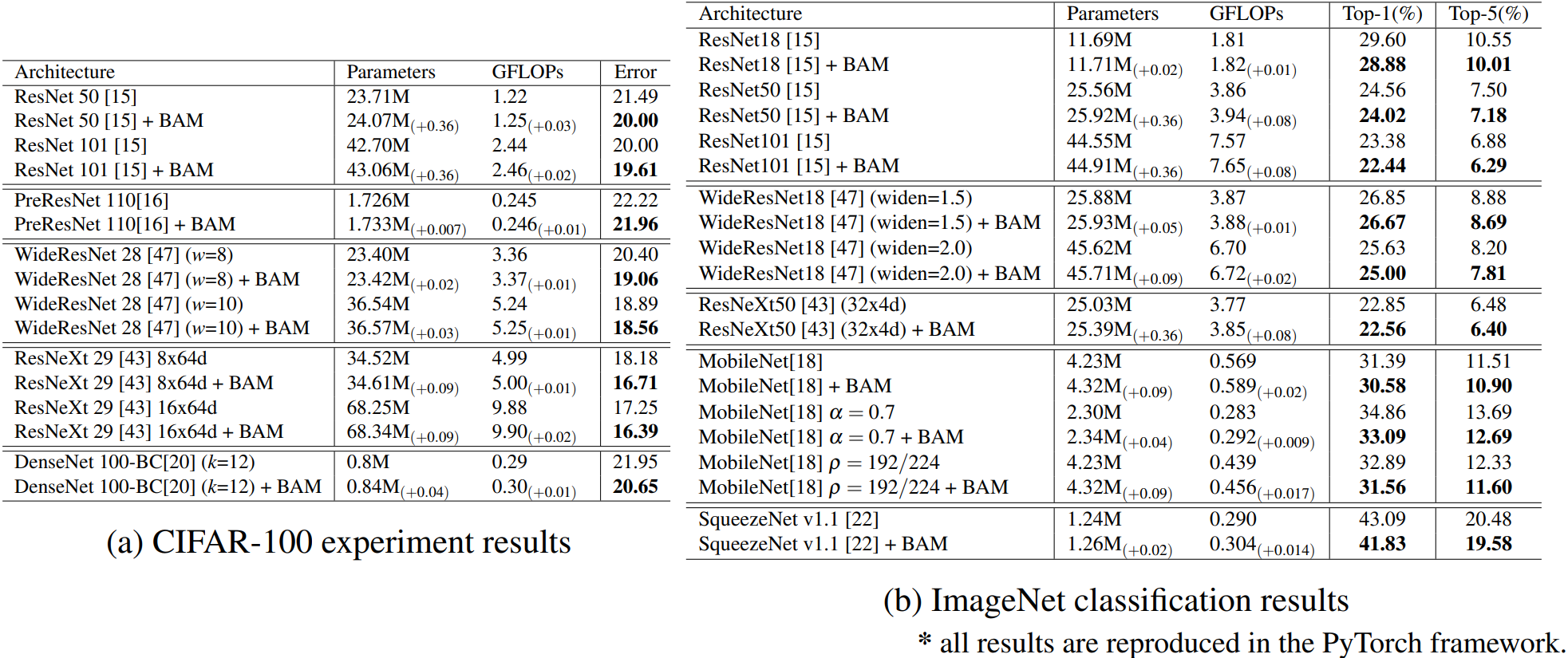
可以看的出来,加入BAM之后,都有明显的效果提升,说明这种方式是有效的且通用的。