【论文阅读】FreePCA
FreePCA: Integrating Consistency Information across Long-short Frames in Training-free Long Video Generation via Principal Component Analysis
-
原文摘要
-
问题背景
-
核心挑战:
-
长视频生成通常依赖在短视频上训练的模型,但由于视频帧数增加会导致数据分布偏移(distribution shift)。这表现为:
-
局部信息需保持视觉和运动质量。
-
全局信息需确保整体外观一致性。
-
-
-
现有方法缺陷:
- 当前训练无关的方法难以平衡局部与全局信息,因为视频中的外观和运动高度耦合,导致生成结果出现运动不一致或视觉质量下降。
-
-
核心发现
-
PCA的应用:
-
作者发现,通过主成分分析(PCA),可以将视频特征解耦为:
-
全局一致性外观(由主要成分主导,表征稳定特征)。
-
局部运动强度(由次要成分主导,表征动态变化)。
-
-
-
关键优势:
- 这种解耦允许分别优化全局一致性和局部质量,避免两者相互干扰。
-
-
FreePCA
-
特征解耦:
-
在PCA空间中,通过余弦相似度度量分离外观和运动特征:
-
外观特征:从主成分中提取,确保跨帧一致性。
-
运动特征:从次要成分中提取,保留动态细节。
-
-
-
渐进式融合:
-
逐步整合解耦后的特征,以:
-
保持原始短视频的生成质量。
-
实现长视频中帧间的平滑过渡。
-
-
-
噪声统计复用:
- 重用初始噪声的均值统计量,进一步强化时间一致性。
-
-
1. Introduction
1.1 研究背景与问题定义
-
长视频生成的瓶颈:
-
现有视频扩散模型通常在短视频数据集上训练,直接生成长视频会导致分布偏移(distribution shift),表现为:
-
质量下降
-
运动缓慢
-
语义丢失
-
-
-
现有方法的局限性:
- 全局对齐方法(Global Aligned):
- 直接输入长序列噪声生成视频,但忽略局部质量,导致运动贫乏。
- 局部拼接方法(Local Stitched):
- 通过滑动窗口生成短视频再拼接,但窗口间一致性差。
- 频域融合方法:
- 如通过全局噪声增强一致性,但依赖长帧特征,牺牲了生成灵活性。
- 全局对齐方法(Global Aligned):
-
核心问题:如何平衡全局一致性(长视频稳定性)与局部质量(短视频细节)?
1.2 核心发现与动机
- 局部与全局信息的互补性:
- 局部信息(通过滑动窗口提取):保留模型训练分布,确保视觉和运动质量。
- 全局信息(通过长序列生成):提供跨帧一致性,但质量较低。
- PCA的启发性应用:
- 受背景分割任务启发(PCA分离静态背景与动态前景),作者发现:
- 时间维度的PCA可将视频特征解耦为:
- 一致外观(全局主成分,表征稳定特征)
- 运动强度(局部次要成分,表征动态变化)
- 时间维度的PCA可将视频特征解耦为:
- 这一发现为解耦与融合全局/局部信息提供了理论依据。
- 受背景分割任务启发(PCA分离静态背景与动态前景),作者发现:
1.3 FreePCA方法概述
提出一种Training-Free的长视频生成框架,通过PCA实现:
- 一致性特征分解(Consistency Feature Decomposition):
- 将全局特征(长帧生成)和局部特征(滑动窗口生成)投影到PCA空间。
- 通过余弦相似度划分主次成分:
- 高相似成分(外观一致)→ 从全局特征中提取,补充局部特征。
- 因为一致性特征在全局特征中更稳定,所以用全局补充局部。
- 低相似成分(运动变化)→ 保留局部特征的动态细节。
- 高相似成分(外观一致)→ 从全局特征中提取,补充局部特征。
- 渐进式融合(Progressive Fusion):
- 滑动窗口时,逐步增加全局一致性特征的融合比例,确保平滑过渡。
- 噪声均值复用:重用初始噪声的统计量,进一步强化时间一致性。
-
优势:
-
training-free,兼容多种视频扩散模型
-
支持多提示生成(multi-prompt)和连续视频生成
-
2. Related Work
2.1 Text-to-Video Diffusion Models
- 早期方法:
- 基于VAE(变分自编码器)和GAN(生成对抗网络)的视频生成技术,但受限于生成质量和时序一致性。
- 扩散模型的发展:
- 扩散模型(Diffusion Models)凭借高保真生成能力成为主流
- 关键技术改进:
- 3D卷积与时序注意力:增强帧间连贯性。
- 运动模块微调:兼容LoRA,提升实用性和适配性。
- 潜空间视频扩散:通过降维提升生成效率。
- 高质量图像引导:利用图像数据提升视频视觉质量。
-
现存问题:
-
受计算资源和高质量视频数据稀缺的限制,现有模型仅能生成固定长度的短视频,难以直接扩展至长视频。
-
FreePCA的定位:无需额外训练,基于短视频扩散模型生成长视频。
-
2.2 Long Video Generation
- 基于训练的方法:
- GAN-based和Diffusion-based方法需大量计算资源。
- 训练无关的方法(FreePCA的对比基线):
- 外推法(Extrapolation):
- 优点:保留原始生成质量。
- 缺点:窗口间一致性差。
- 内插法(Interpolation):
- 优点:全局一致性较好。
- 缺点:牺牲运动多样性和局部细节。
- 外推法(Extrapolation):
-
FreePCA的创新点:
-
结合外推与内插的优势:
- 从外推法中保留局部质量(滑动窗口生成)。
- 从内插法中提取全局一致性(PCA解耦外观与运动)。
-
无需训练:避免资源消耗,直接适配现有模型。
-
3. Observation and Analysis
3.1 PCA的动机与发现
-
动机:
-
PCA的启发性应用:
-
受视频分割任务中PCA分离静态背景(一致性)与动态前景(运动)的启发,作者发现PCA在时间维度上可解耦视频特征:
-
高一致性成分:对应全局外观(如场景、主体结构)。
-
低一致性成分:对应局部运动(如动态细节)。
-
-
-
-
验证方法:
-
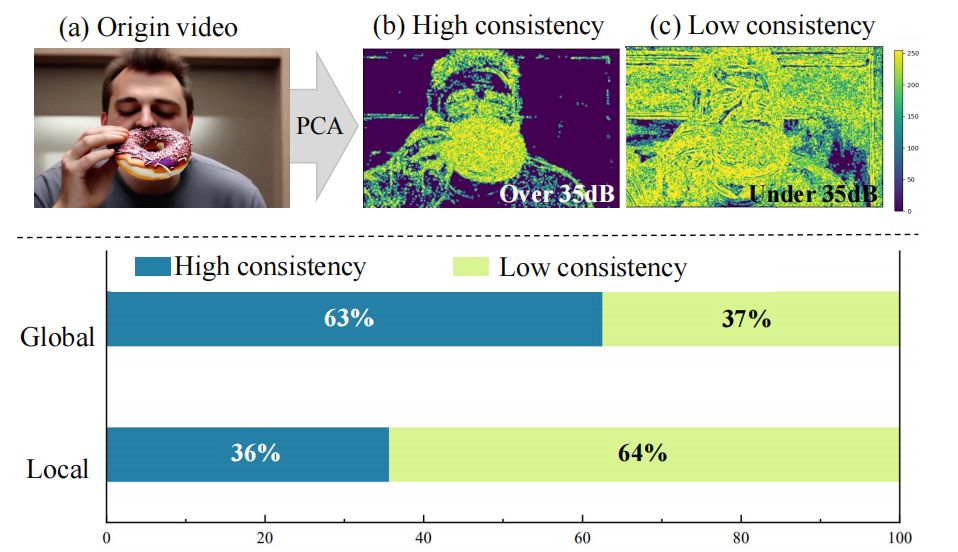
边缘检测与PSNR量化:
- 对PCA分解后的各成分,用Canny边缘检测生成叠加边缘图。
- 一致性判定:
- 若边缘集中且结构清晰(下图中的b),则PSNR > 35dB;
- 若分散混乱(下图中的c),则PSNR < 35dB。
-
统计对比全局与局部方法:
-
对100组生成视频的PCA分析显示(下图中的表格):
- 全局方法(长帧生成):64%视频含高一致性成分。
- 局部方法(滑动窗口):仅37%视频含高一致性成分。
-
结论:全局方法更易保留一致性,但牺牲运动多样性;局部方法反之。
-
-
3.2 特征解耦与互补性分析
-
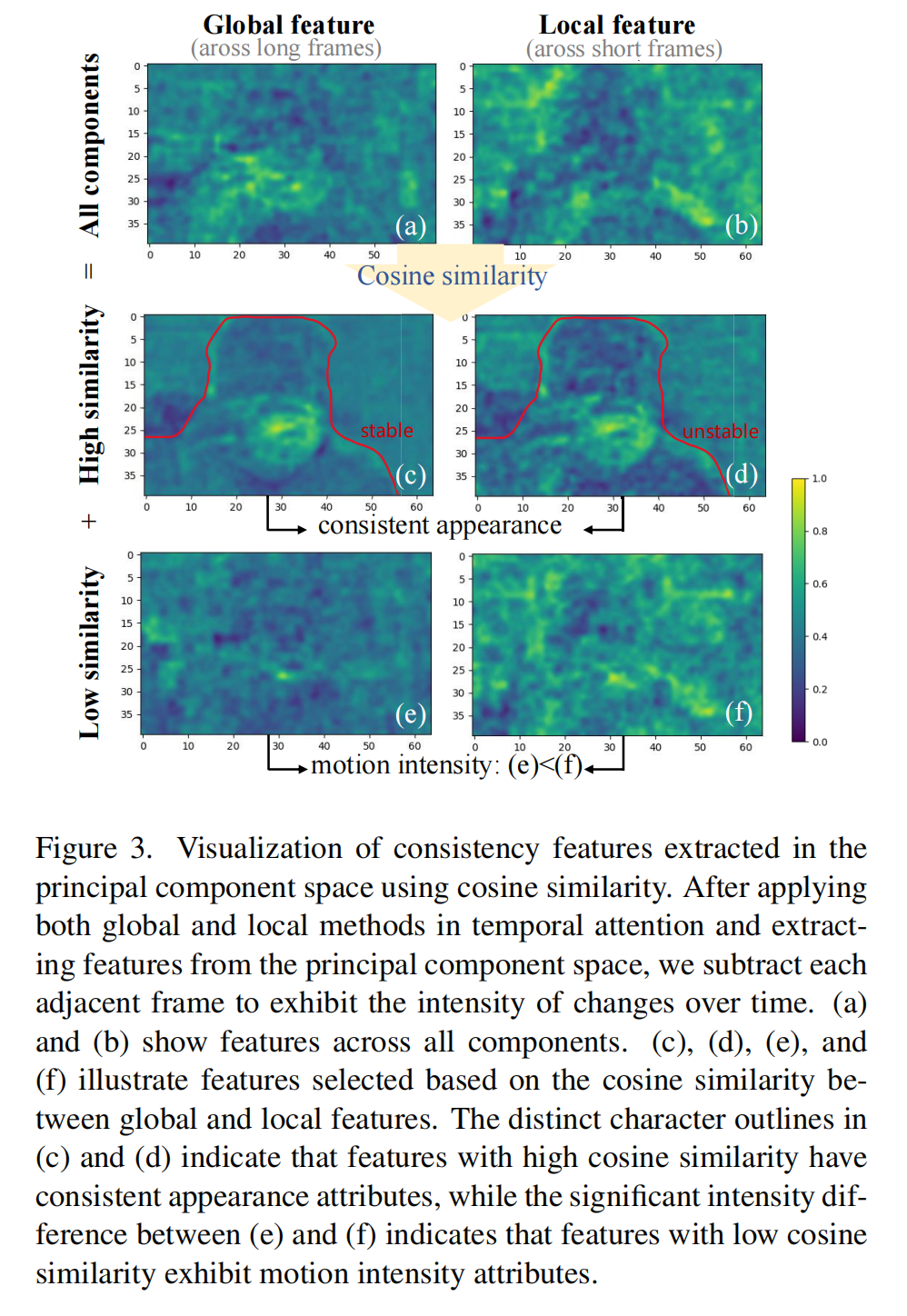
可视化PCA观察
-
余弦相似度划分特征:
在PCA空间中,比较全局与局部特征的余弦相似度:
- 高相似成分(外观一致):全局特征更平滑(下图中的c),局部特征更混沌(下图中的d)。
- 低相似成分(运动变化):局部特征变化强度比全局特征变化强度大(下图中的f),保留丰富动态信息。
-
-
物理意义:
-
外观与运动的解耦:
- PCA明确分离了两种特征,而传统方法因耦合性难以区分。
-
互补必要性:
-
全局特征的高一致性可修正局部窗口的闪烁问题。
-
局部特征的高运动强度可弥补全局生成的动态贫乏。
-
-
3.3 与现有方法的差异
-
对比方法:
-
局部拼接法:
- 依赖滑动窗口,未显式建模全局一致性,导致窗口间不连贯。
-
频域融合法:
- 直接融合全局与局部特征,但未解耦外观与运动,导致细节丢失。
-
-
FreePCA的创新:
-
解耦能力:PCA提供明确的特征分离(外观vs运动),而传统方法仅隐式混合。
-
精准融合:
- 仅用全局的高相似成分增强一致性。
- 保留局部的低相似成分维持运动多样性。
-
4. Method
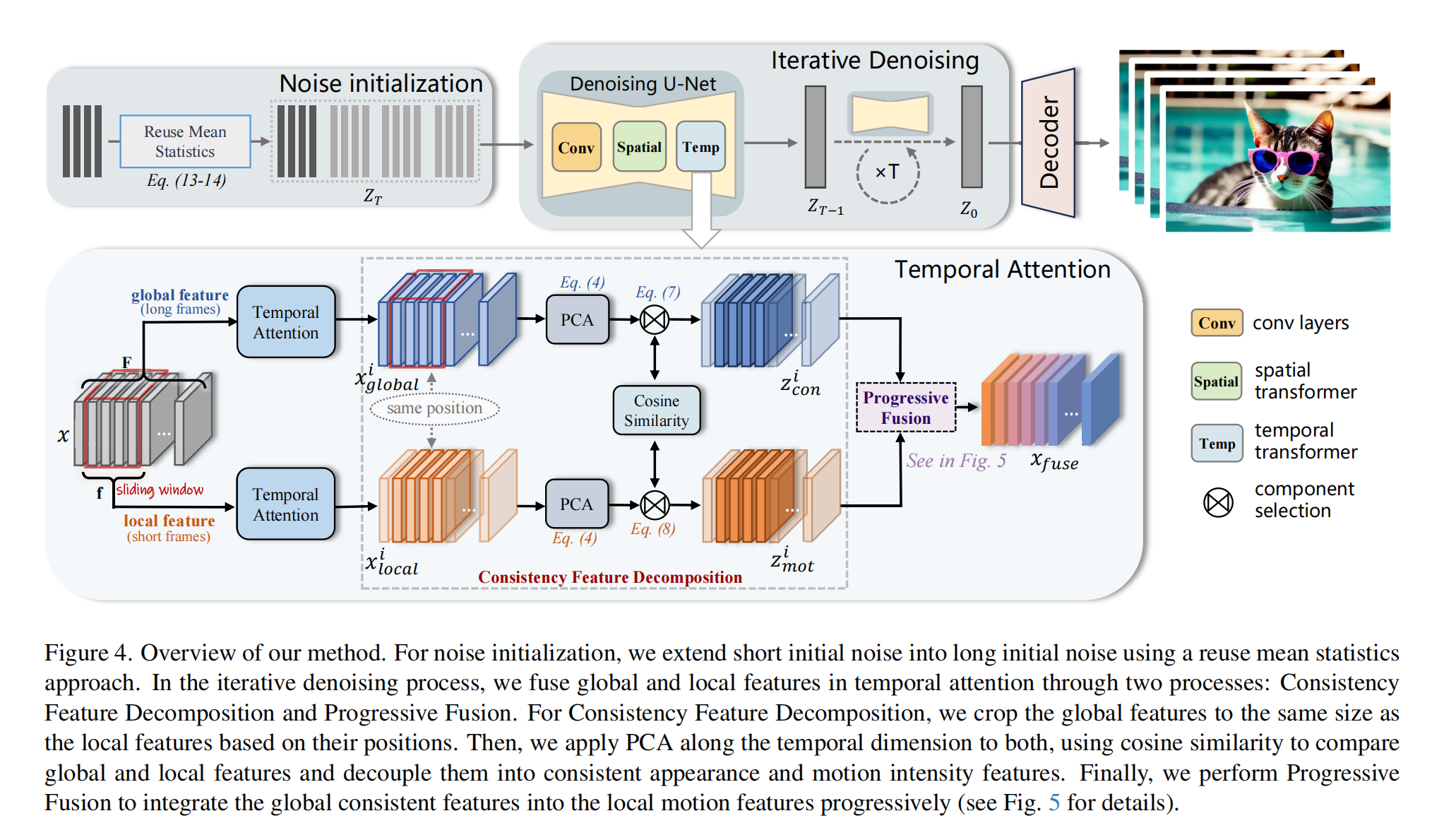
4.1 Consistency Feature Decomposition
-
输入特征:
时空Transformer模块的输入特征为 x ∈ R ( b × h × w ) × F × c x \in \mathbb{R}^{(b \times h \times w) \times F \times c} x∈R(b×h×w)×F×c,其中:-
b , h , w b, h, w b,h,w:批大小、高度、宽度
-
F F F:长视频的总帧数(目标帧数)
-
c c c:通道数
-
预训练模型限制:模型仅在短视频( f f f帧, f < F f < F f<F)上训练,直接输入长序列会导致分布偏移。
-
核心任务:
- 从长视频(全局)和滑动窗口(局部)的特征中,解耦出一致性外观和运动强度特征。
-
-
全局与局部特征提取
-
全局特征(Global Feature):
-
输入整个长序列 x x x 到时序注意力模块(
Temp),得到 x global ∈ R ( b × h × w ) × F × c x_{\text{global}} \in \mathbb{R}^{(b \times h \times w) \times F \times c} xglobal∈R(b×h×w)×F×c。 -
对齐操作:按滑动窗口位置切片,得到与局部特征对齐的 x global i ∈ R ( b × h × w ) × f × c x^i_{\text{global}} \in \mathbb{R}^{(b \times h \times w) \times f \times c} xglobali∈R(b×h×w)×f×c:
x global i = Slice i ( Temp ( x ) ) x^i_{\text{global}} = \text{Slice}^i(\text{Temp}(x)) xglobali=Slicei(Temp(x))
-
-
局部特征(Local Feature):
-
对第 i i i 个滑动窗口( f f f帧)应用时序注意力,得到 x local i ∈ R ( b × h × w ) × f × c x^i_{\text{local}} \in \mathbb{R}^{(b \times h \times w) \times f \times c} xlocali∈R(b×h×w)×f×c:
x local i = Temp ( Slice i ( x ) ) x^i_{\text{local}} = \text{Temp}(\text{Slice}^i(x)) xlocali=Temp(Slicei(x)) -
关键差异:
- 全局特征因长序列输入存在分布偏移,需通过注意力熵缩放(缩放因子 λ = log f F \lambda = \sqrt{\log_f F} λ=logfF)调整Query值。
-
-
-
PCA投影与特征解耦
-
PCA投影矩阵计算:
-
对全局特征 x global i x^i_{\text{global}} xglobali 进行PCA预处理(数据归一化、协方差矩阵分解、特征值排序),得到变换矩阵 P ∈ R f × f P \in \mathbb{R}^{f \times f} P∈Rf×f:
P = T PCA ( x global i ) P = \mathbb{T}_{\text{PCA}}(x^i_{\text{global}}) P=TPCA(xglobali) -
降维操作:将 x global i x^i_{\text{global}} xglobali 和 x local i x^i_{\text{local}} xlocali 从 R ( b × h × w ) × f × c \mathbb{R}^{(b \times h \times w) \times f \times c} R(b×h×w)×f×c 重塑为 R f × ( b × h × w × c ) \mathbb{R}^{f \times (b \times h \times w \times c)} Rf×(b×h×w×c),再投影到主成分空间:
z global i , z local i = P ⋅ x global i , P ⋅ x local i z^i_{\text{global}}, z^i_{\text{local}} = P \cdot x^i_{\text{global}}, P \cdot x^i_{\text{local}} zglobali,zlocali=P⋅xglobali,P⋅xlocali
-
-
基于余弦相似度的特征选择:
-
计算全局与局部特征在主成分空间中的余弦相似度 s s s,按相似度排序:
s ( 1 ) , … , s ( f ) = CosSim ( z global i , z local i ) s_{(1)}, \dots, s_{(f)} = \text{CosSim}(z^i_{\text{global}}, z^i_{\text{local}}) s(1),…,s(f)=CosSim(zglobali,zlocali)n ( 1 ) , … , n ( f ) = argsort ( s ( 1 ) , … , s ( f ) ) n_{(1)}, \dots, n_{(f)} = \text{argsort}(s_{(1)}, \dots, s_{(f)}) n(1),…,n(f)=argsort(s(1),…,s(f))
-
解耦策略:
-
一致性外观特征( z con i z^i_{\text{con}} zconi):选取相似度最高的前 k k k 个主成分(来自全局特征):
z con i = z global i [ n ( 1 ) , … , n ( k ) ] z^i_{\text{con}} = z^i_{\text{global}}[n_{(1)}, \dots, n_{(k)}] zconi=zglobali[n(1),…,n(k)] -
运动强度特征( z mot i z^i_{\text{mot}} zmoti):保留剩余主成分(来自局部特征):
z mot i = z local i [ n ( k + 1 ) , … , n ( f ) ] z^i_{\text{mot}} = z^i_{\text{local}}[n_{(k+1)}, \dots, n_{(f)}] zmoti=zlocali[n(k+1),…,n(f)]
-
-
-
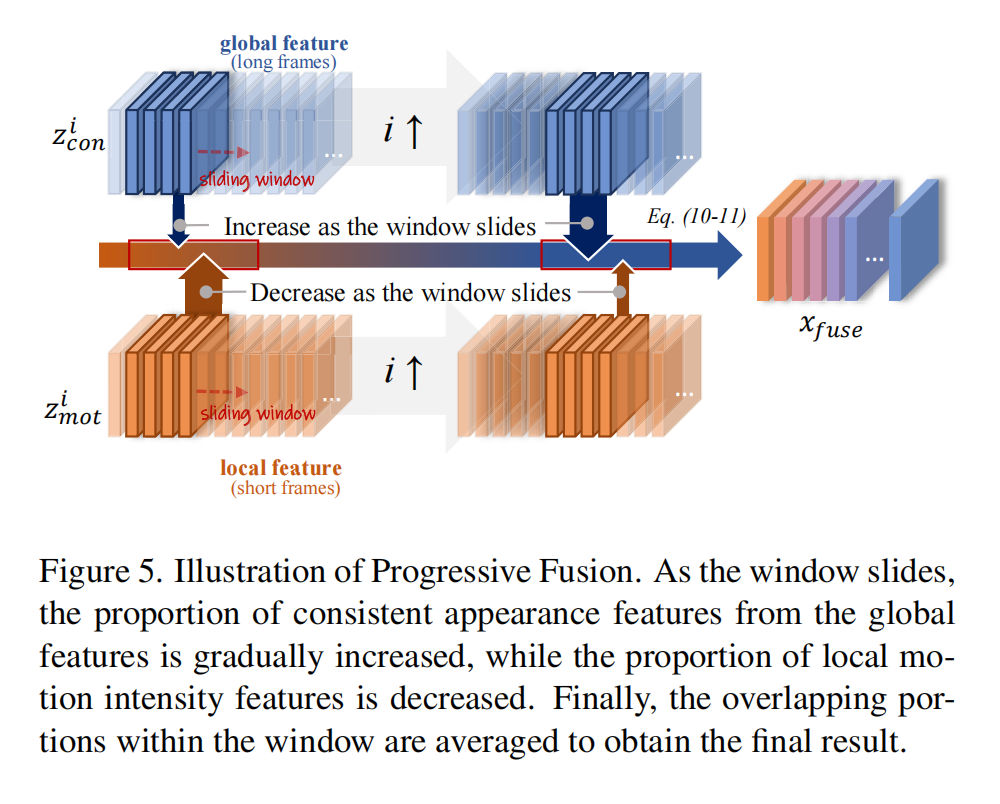
4.2 Progressive Fusion
-
渐进式融合的核心动机
-
核心问题:直接替换局部特征中的全部一致性成分可能破坏原始生成质量,需平衡融合强度与灵活性。
-
解决思路:
- 动态调整融合比例:随着滑动窗口的推进,逐步增加一致性特征的融合量(避免突变)。
- 保护局部质量:限制最大融合比例(
K_max=3),确保运动细节不被过度覆盖。
-
-
渐进式融合的具体实现
-
动态选择主成分数量 k:
-
对第
i个滑动窗口,按以下规则选择融合的主成分数k:
k = min ( i , K max ) , K max = 3 k = \min(i, K_{\text{max}}), \quad K_{\text{max}}=3 k=min(i,Kmax),Kmax=3- 早期窗口(i ≤ 3):
k = i(逐步增加融合比例)。 - 后期窗口(i > 3):
k = 3(达到最大融合比例)。
- 早期窗口(i ≤ 3):
-
-
特征拼接与逆投影:
-
将解耦后的 z con i z^i_{\text{con}} zconi(一致性)与 z mot i z^i_{\text{mot}} zmoti(运动)沿时间维度拼接:
z fuse i = Concat ( z con i , z mot i ) z^i_{\text{fuse}} = \text{Concat}(z^i_{\text{con}}, z^i_{\text{mot}}) zfusei=Concat(zconi,zmoti) -
通过PCA逆变换矩阵 P T P^T PT 映射回原始空间:
x fuse i = P T ⋅ z fuse i x^i_{\text{fuse}} = P^T \cdot z^i_{\text{fuse}} xfusei=PT⋅zfusei
-
-
重叠窗口平均:
- 对重叠部分的帧特征取平均,消除边界伪影,最终输出 x fuse ∈ R ( b × h × w ) × F × c x_{\text{fuse}} \in \mathbb{R}^{(b \times h \times w) \times F \times c} xfuse∈R(b×h×w)×F×c。
-
-
去噪过程的阶段性策略
-
DDIM去噪步骤(50步)的分阶段处理:
- 前25步:完整应用FreePCA(优先建立全局一致性)。
- 后25步:仅用局部方法(保留细节生成能力)。
-
理论依据:
- 扩散模型早期生成场景布局和主体结构(需全局一致性),后期细化细节(需局部多样性)[6]。
-
4.3 Reuse Mean Statistics
-
动机:
- 直接噪声重调度会限制生成多样性,而时序均值能反映外观一致性。
-
实现步骤:
-
初始噪声生成:
ϵ t ∼ N ( 0 , 1 ) , t = 1 , 2 , . . . , F \epsilon_t \sim \mathcal{N}(0, 1), \quad t=1,2,...,F ϵt∼N(0,1),t=1,2,...,F -
均值替换:将后续窗口的噪声均值对齐到首窗口:
ϵ j : j + f ′ = ϵ j : j + f − mean ( ϵ j : j + f ) + mean ( ϵ 1 : f ) \epsilon'_{j:j+f} = \epsilon_{j:j+f} - \text{mean}(\epsilon_{j:j+f}) + \text{mean}(\epsilon_{1:f}) ϵj:j+f′=ϵj:j+f−mean(ϵj:j+f)+mean(ϵ1:f)- 其中 j = n f + 1 j = nf + 1 j=nf+1(
n为整数),确保覆盖所有窗口。
- 其中 j = n f + 1 j = nf + 1 j=nf+1(
-
帧顺序随机化:对调整后的噪声 ϵ \epsilon ϵ 进行帧间打乱( s h ( ⋅ ) sh(·) sh(⋅)),增强生成灵活性。
-
-
优势:
- 保持外观一致性的同时,避免严格噪声约束导致的场景单一化。
5. Experiments
5.1 Implement Details
-
Setup
-
目标模型:
- VideoCrafter2 和 LaVie(基于16帧短视频训练的公开扩散模型)。
- 目标:扩展生成长视频(64帧),无需微调,直接应用于推理阶段。
-
测试数据:
- 使用 VBench[20] 的 326个文本提示词(涵盖多样场景与动作)。
-
-
Evaluation Metrics
-
两类评估维度:一致性(Consistency) 和 质量(Quality),共6项指标:
维度 指标 计算方法 物理意义 一致性 Subject Consistency 基于 DINO 特征计算帧间物体相似度 主体(如人物、物体)是否稳定不变 Background Consistency 基于 CLIP 特征计算帧间背景相似度 场景(如天空、建筑)是否连贯 Overall Consistency 基于 ViCLIP 特征计算帧间语义与风格相似度 整体视频的语义和风格一致性 质量 Motion Smoothness 使用 AMT视频插值模型 评估运动平滑度 动作是否自然流畅 Dynamic Degree 基于 RAFT光流 计算相邻帧运动强度 视频动态丰富性(避免静态或卡顿) Imaging Quality 使用 MUSIQ(SPAQ数据集训练)评估单帧图像质量 画面清晰度、色彩、细节等 -
基线方法(Baseline)
-
对比三类训练无关的长视频生成方法:
-
Direct Sampling:
- 直接输入64帧噪声,用短视频模型生成(无任何优化)。
- 问题:分布偏移导致质量骤降(主体消失、运动迟缓)。
-
FreeNoise:
-
通过噪声重调度强制对齐帧间噪声分布,提升一致性。
-
局限:噪声约束过强,生成场景单一。
-
-
FreeLong:
-
在频域融合低频全局特征与高频局部注意力图。
-
局限:未解耦外观与运动,细节丢失。
-
-
-
-