【Java基础】——JVM
目录
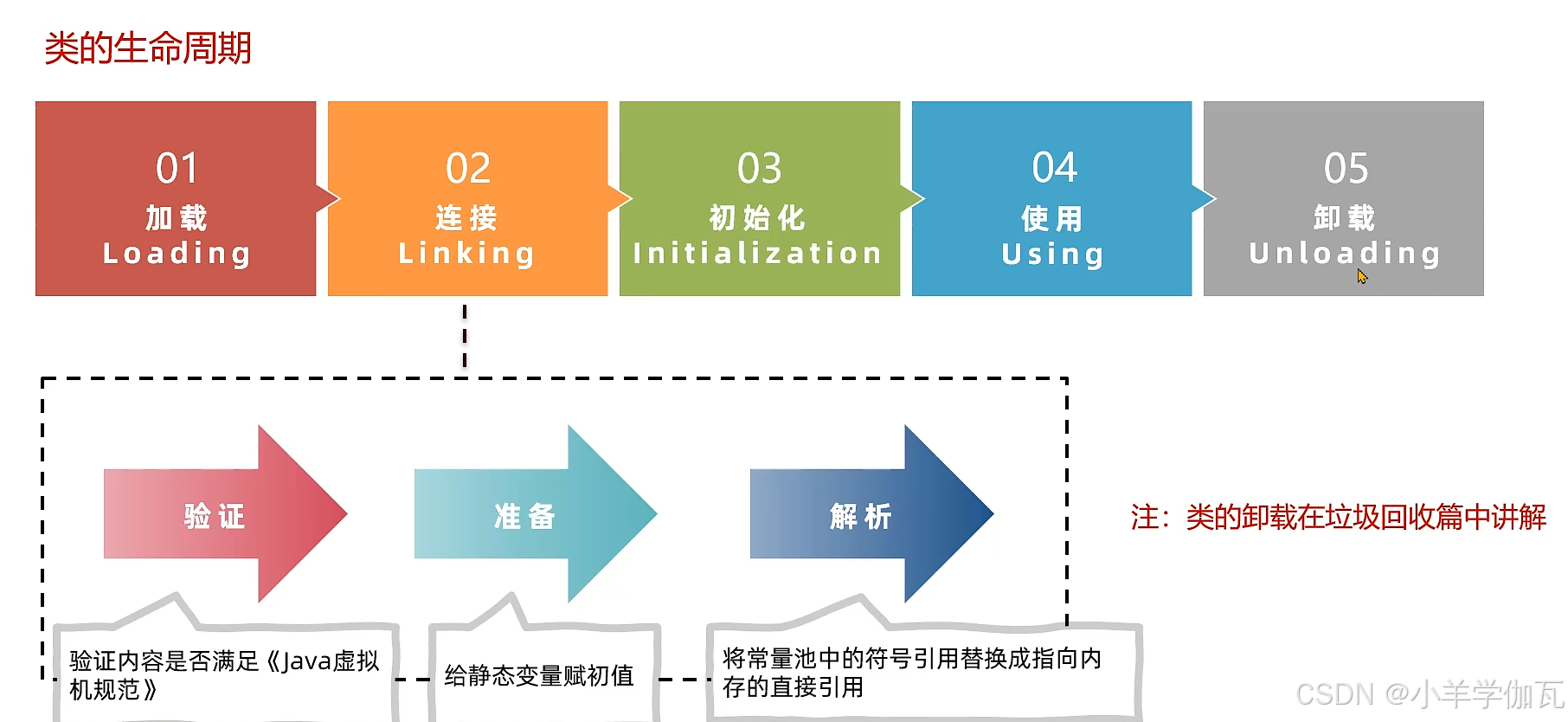
一.类的生命周期
1.概述
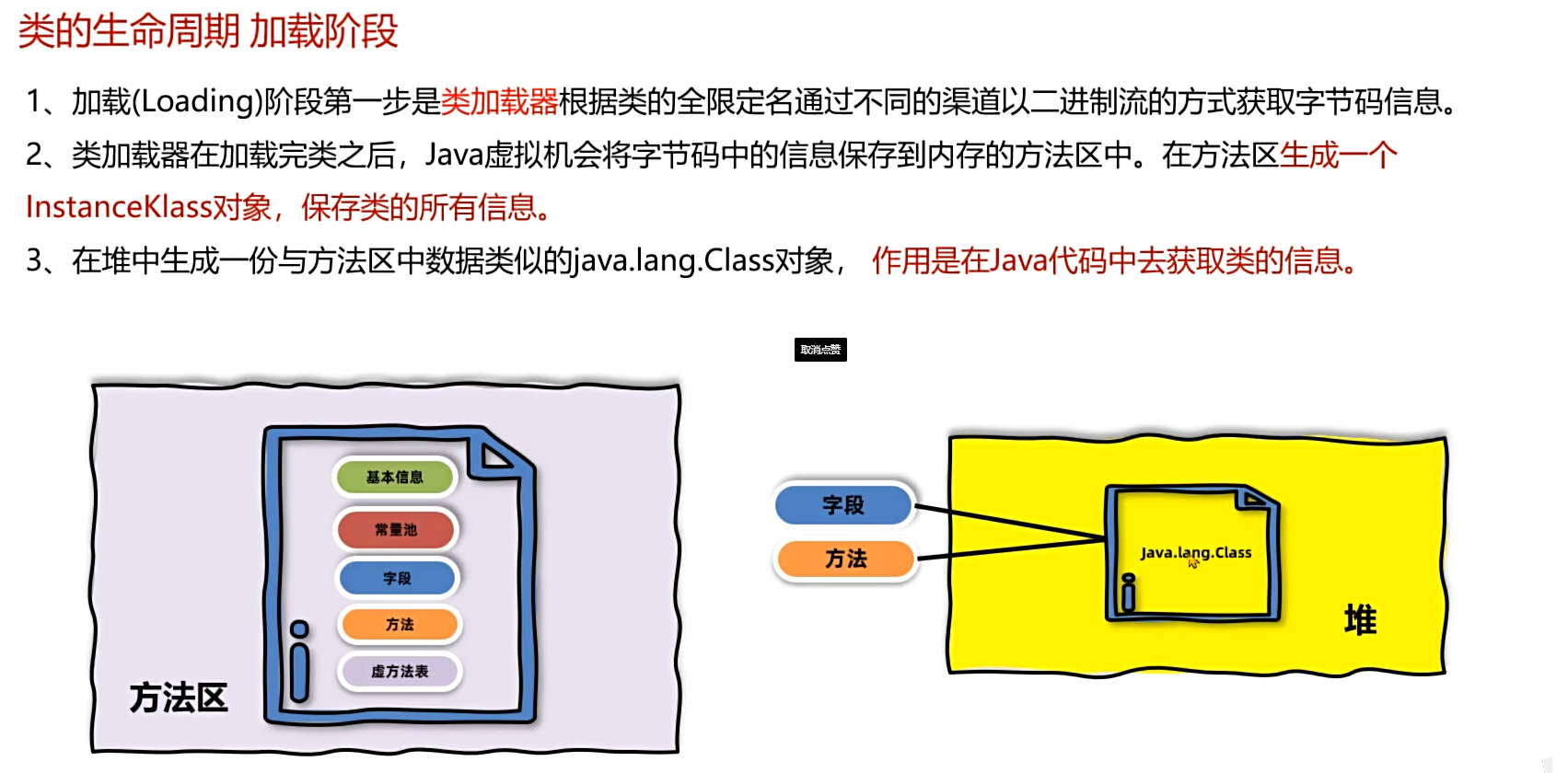
2.加载阶段
编辑
3.连接阶段
1.验证
2.准备
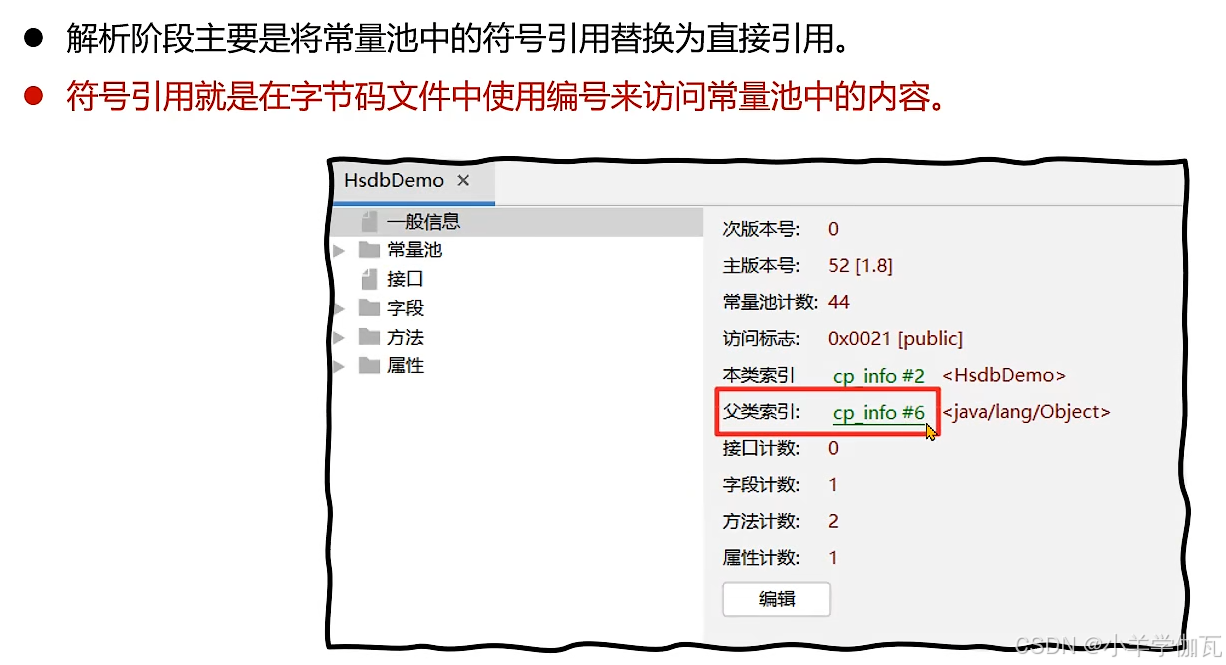
3.解析
4.初始化阶段
二.类加载
1.类加载器的分类
2.启动类加载器
3.
4.双亲委派机制
1.流程
2.问题
3.总结
5.打破双亲委派机制
1.自定义类加载器
编辑 2.JDBC案例打破双亲委派机制
三.运行时数据区
1.目标
2.程序计数器
1.介绍
2.作用
3.问题
3.虚拟机栈
1.简单介绍
2.局部变量表
总结
3.操作数栈和帧数据
4.堆
对象在堆上是如何存储的?
5.方法区
1.
2.字符串常量池(StringTable)
1.题目
6.直接内存
五.垃圾回收
1.方法区的回收
2.堆回收
编辑
1.引用计数法
2.****可达性分析***(GC Root)
3.五种对象引用
1.软引用
2.弱引用
4.垃圾回收算法
1.算法的评价标准
1.吞吐量
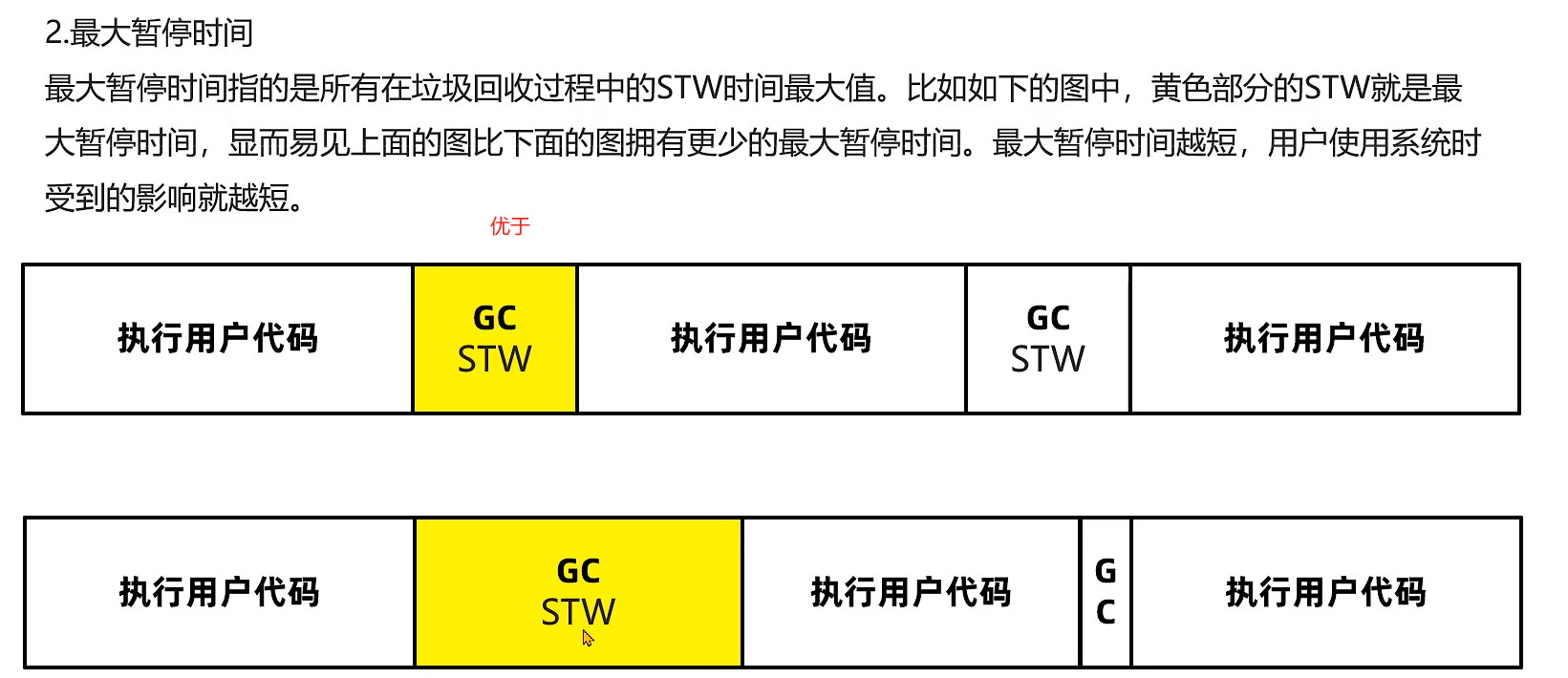
2.最大暂停时间
3.堆使用效率
2.标记清除算法
3.复制算法
4.标记整理算法
5.分代GC
编辑
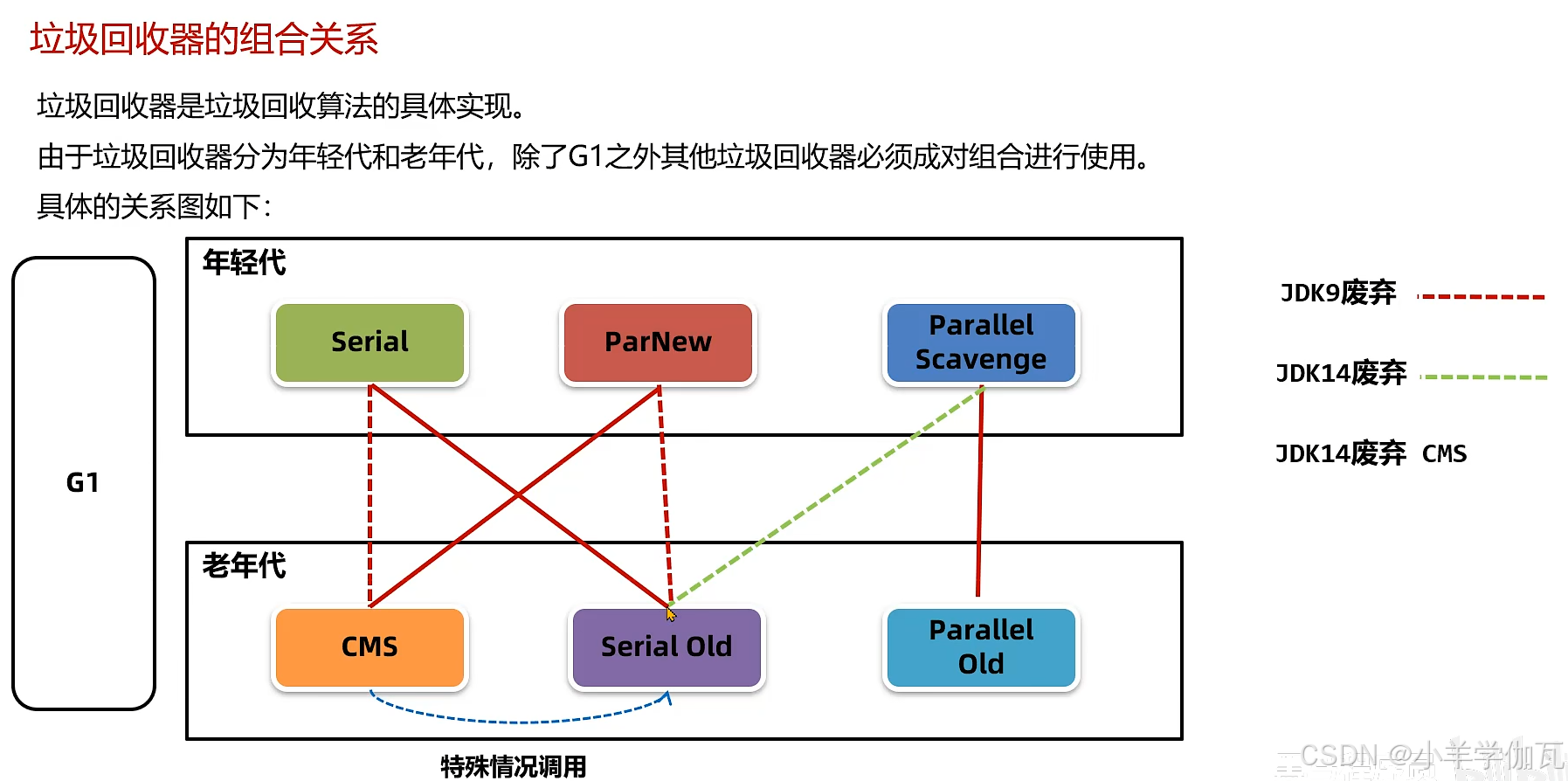
5.垃圾回收器
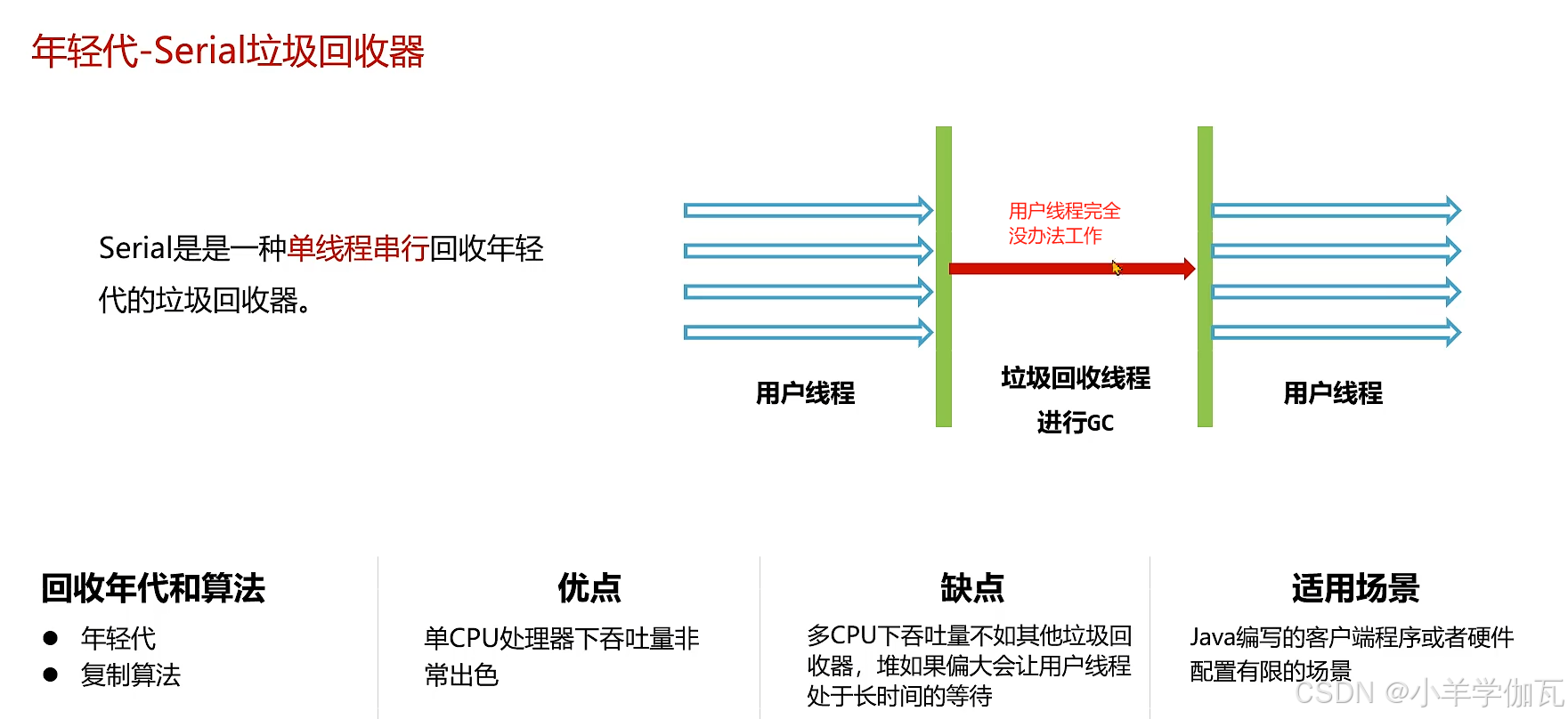
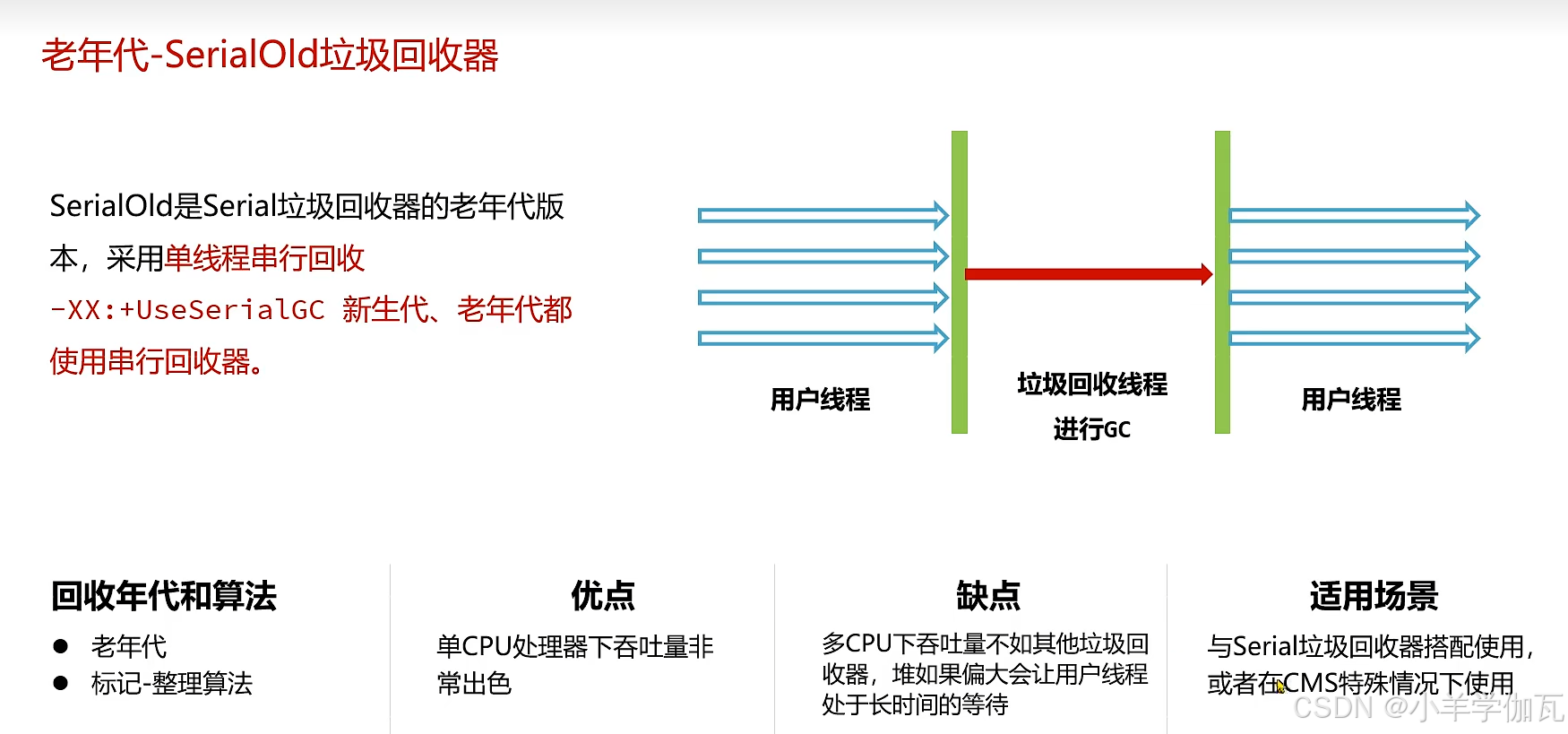
1.年轻代——Serial垃圾回收器与老年代——SerialOld垃圾回收器
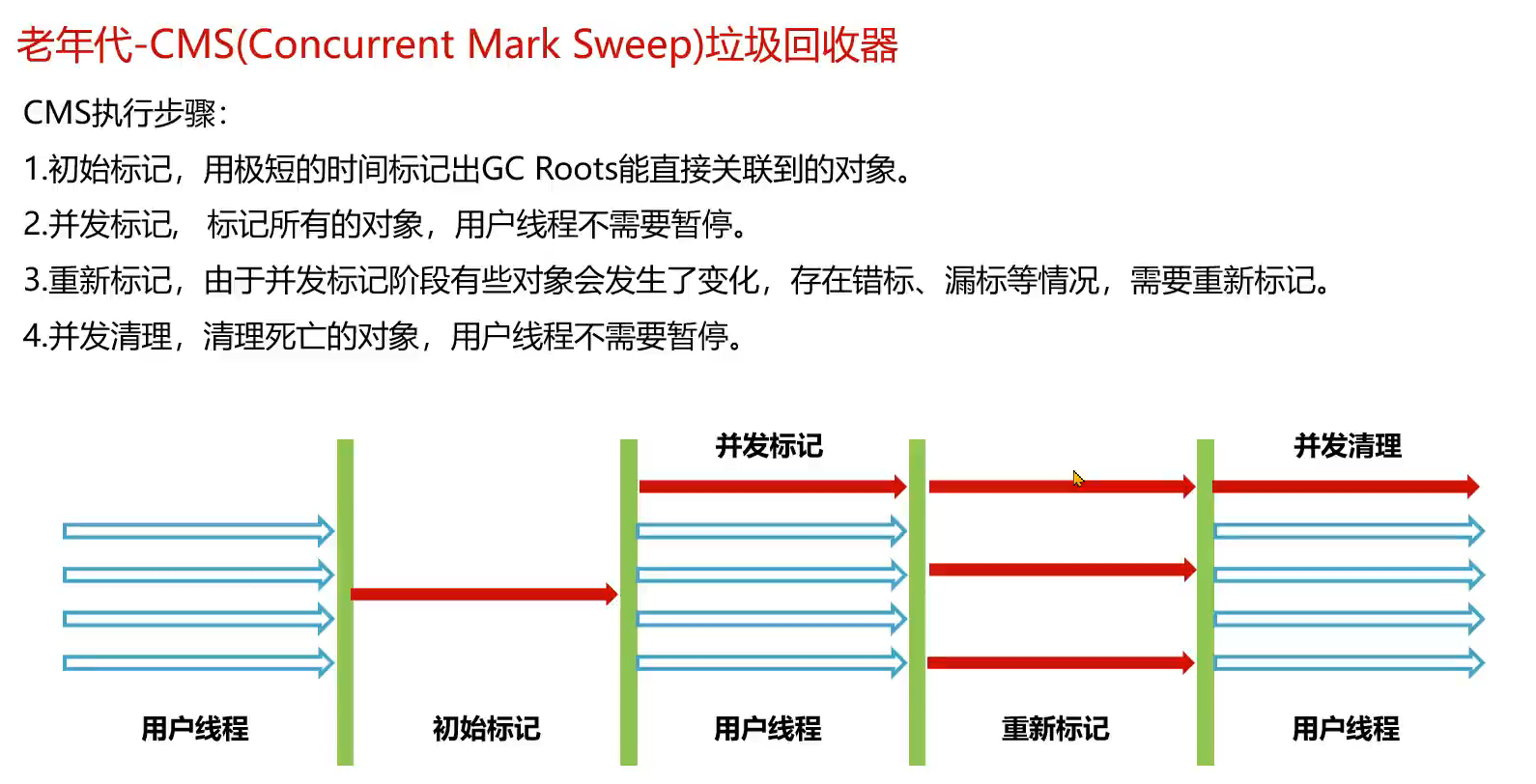
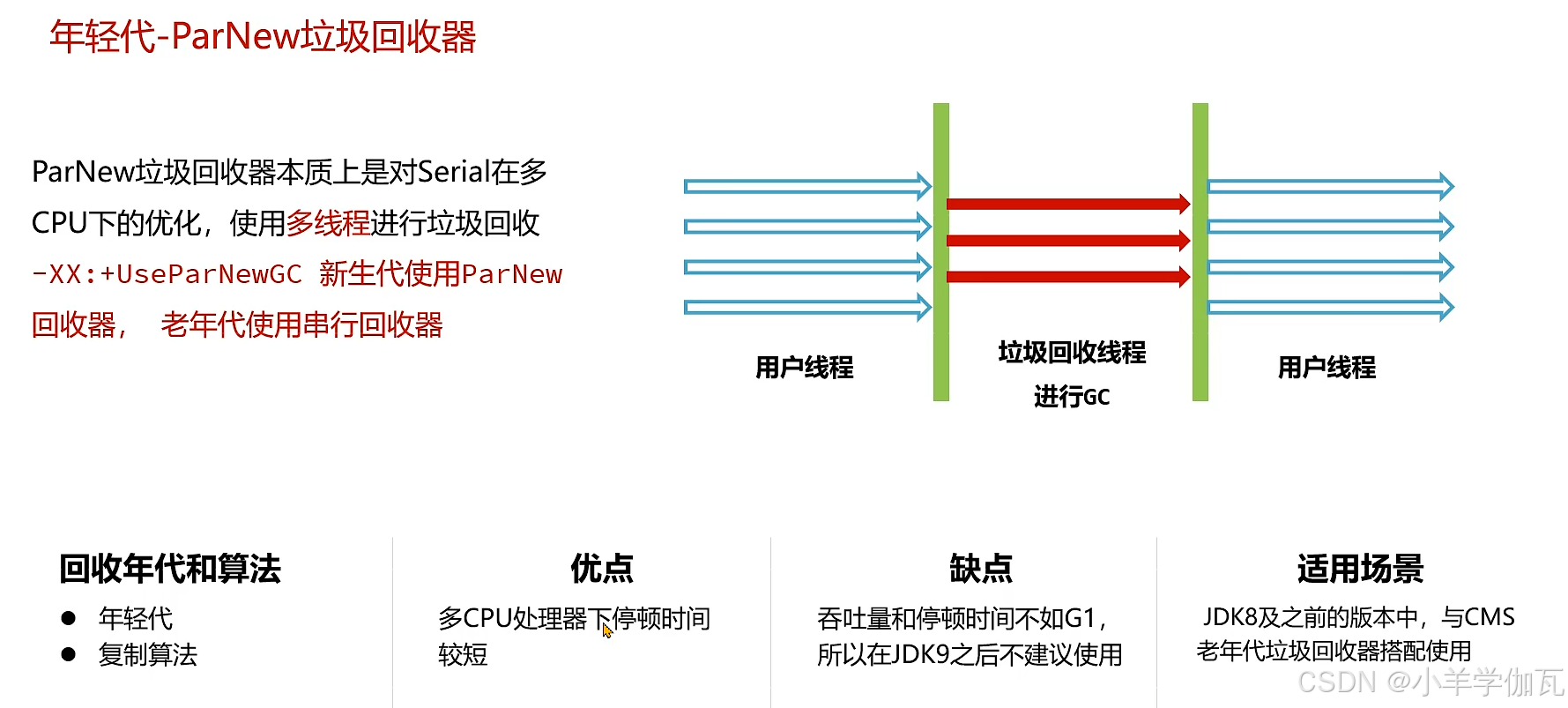
2.年轻代——ParNew垃圾回收器与老年代——CMS垃圾回收器
缺点:
3.G1垃圾回收器
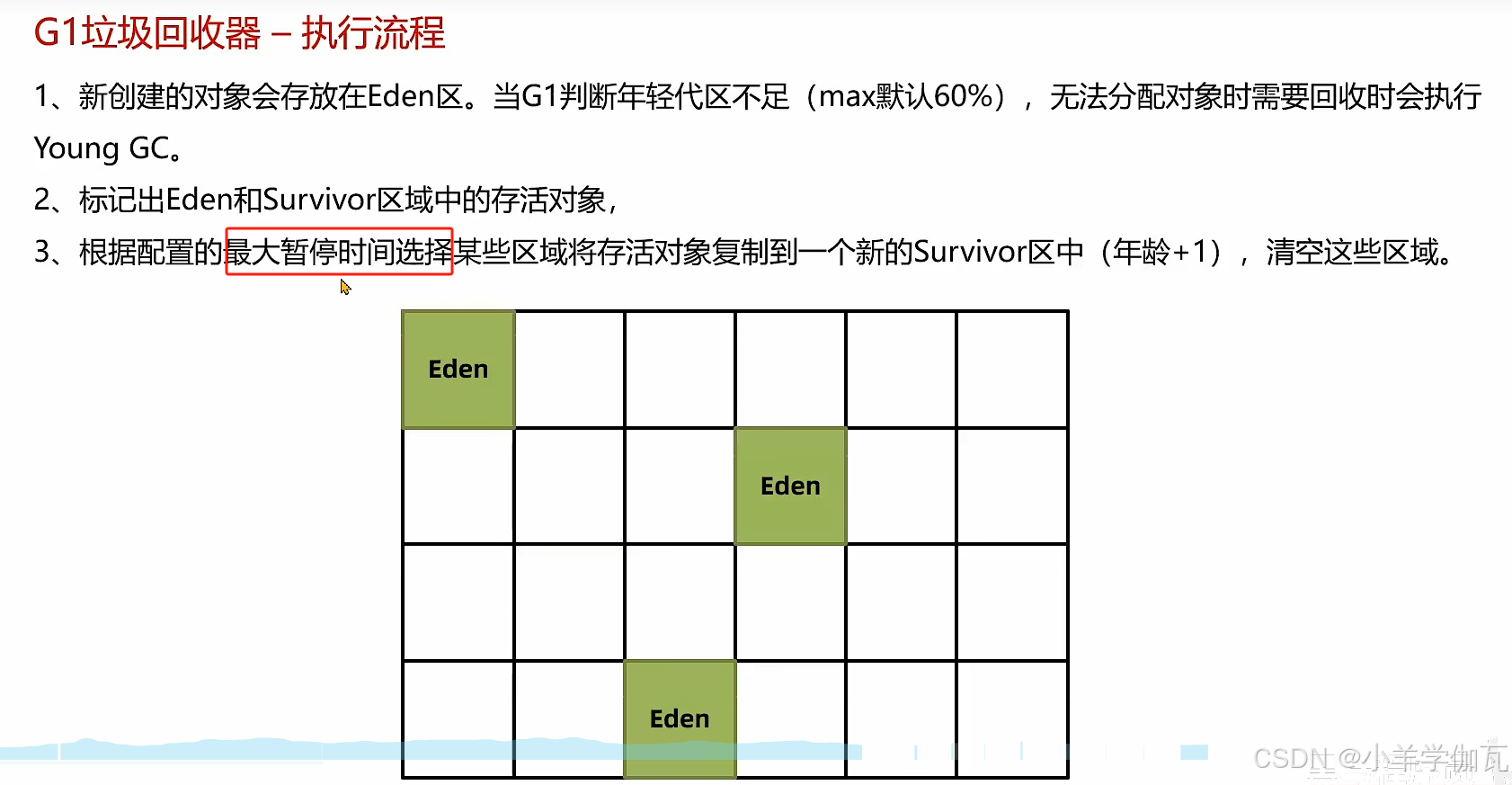
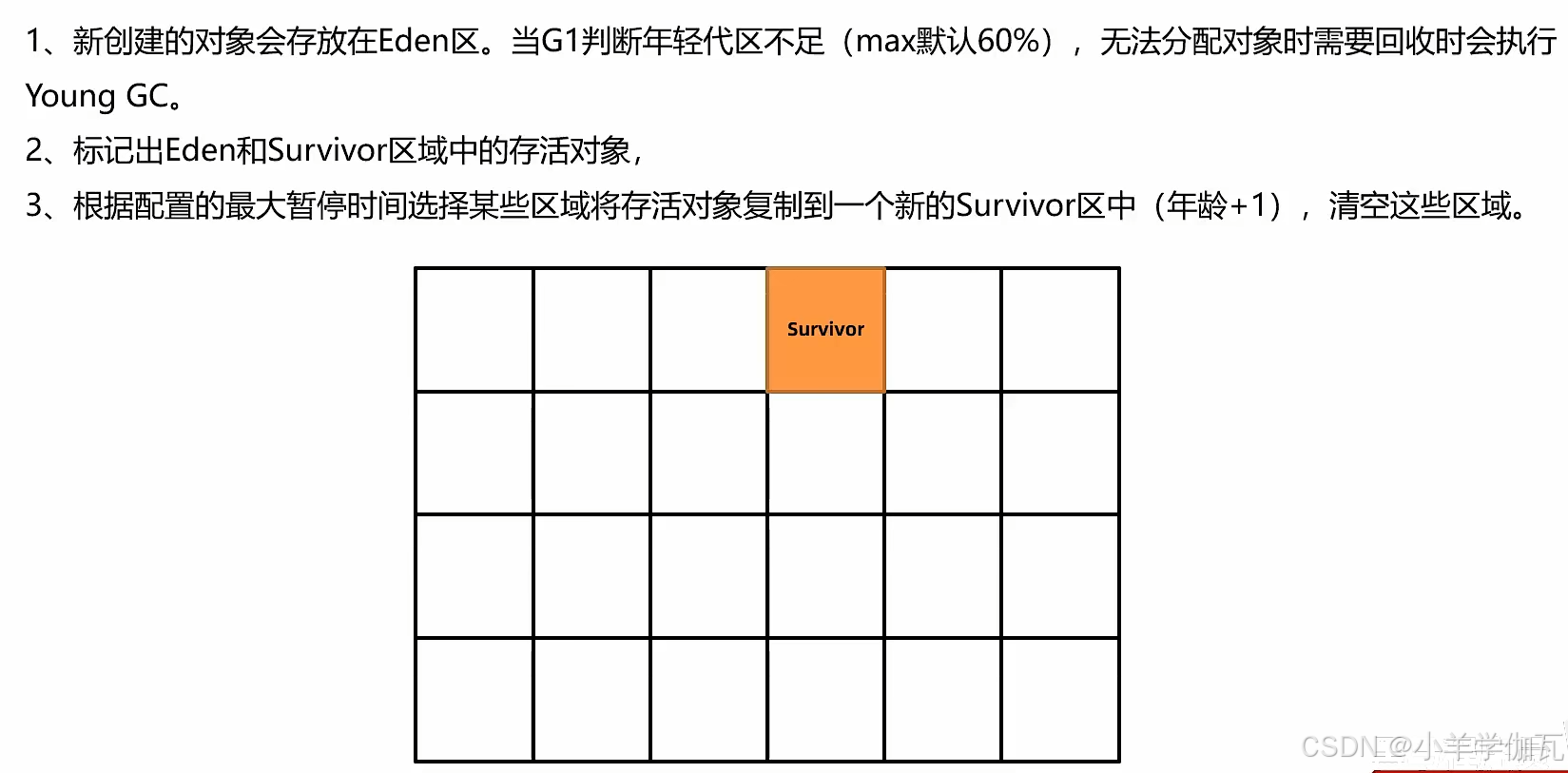
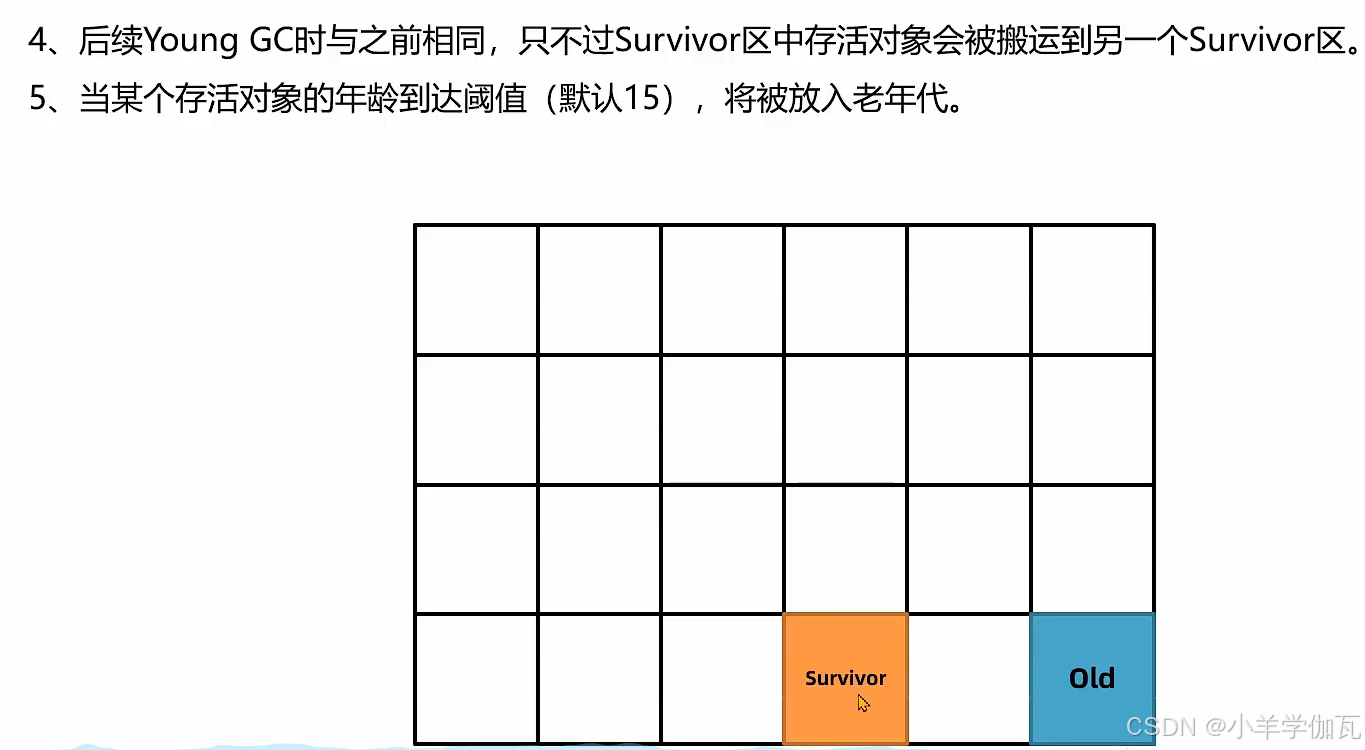
1.年轻代回收——YoungGC
跨代引用的问题(老年代引用了年轻代)
2.混合回收(Mixed GC)
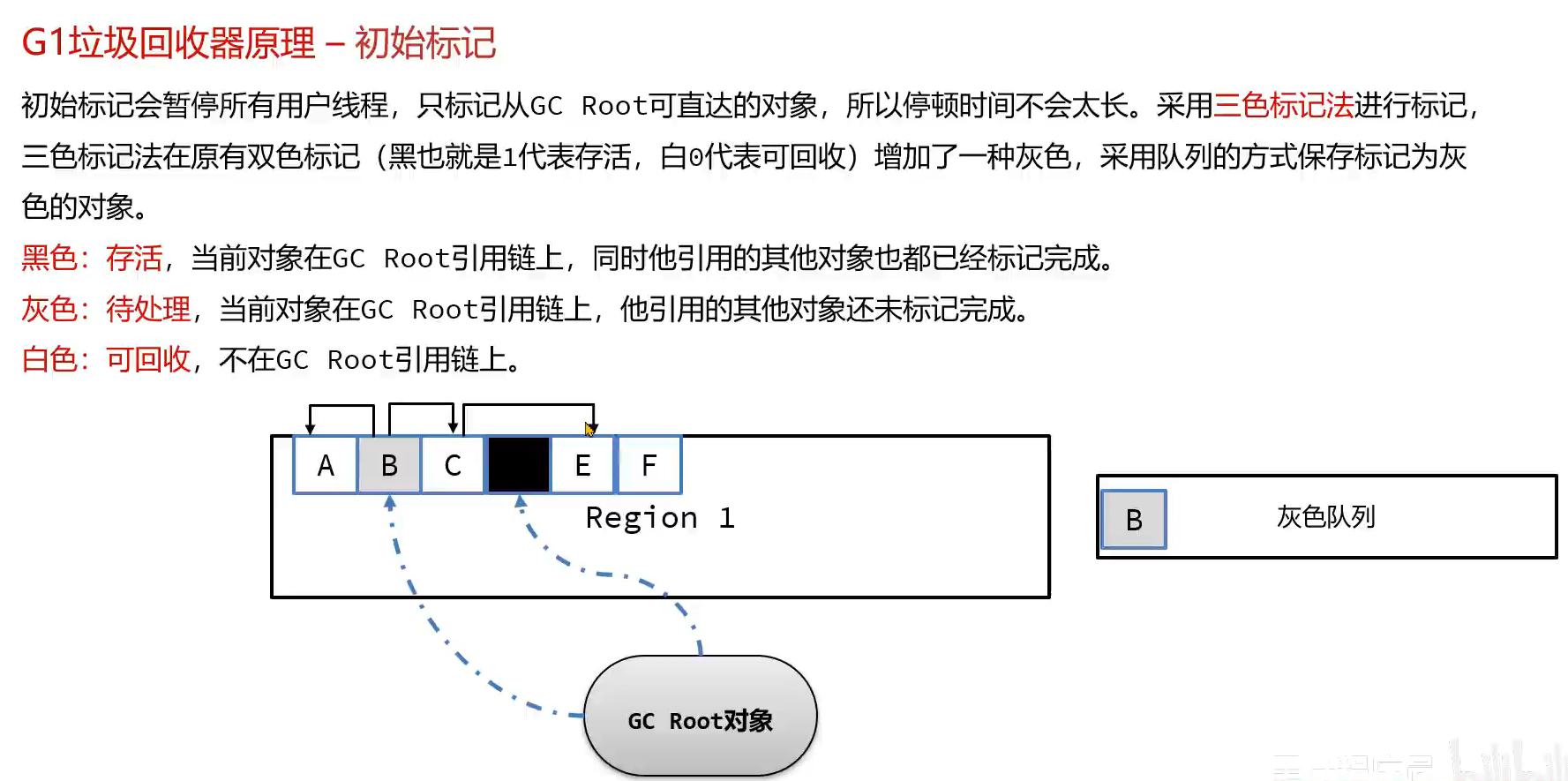
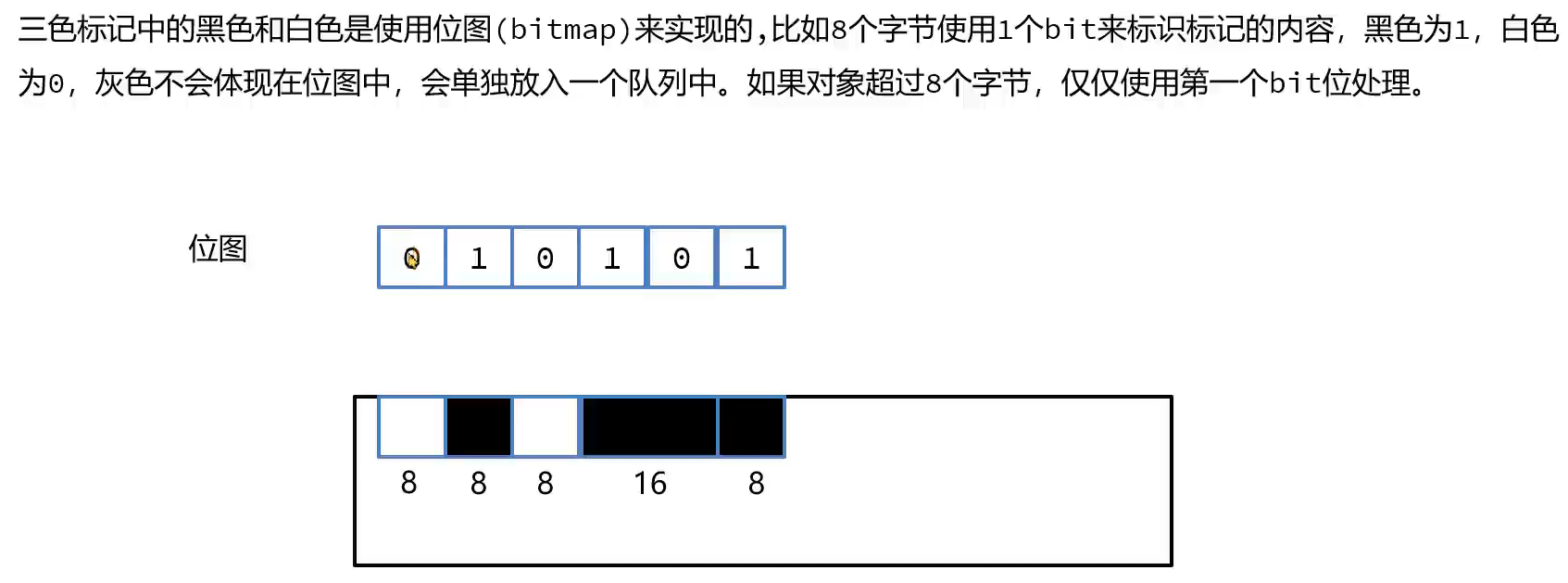
1.初始标记(三色标记法)
编辑
编辑2.并发标记阶段
3.最终标记阶段
编辑
4.转移(先复制再删除,看起来像转移)
一.类的生命周期
1.概述
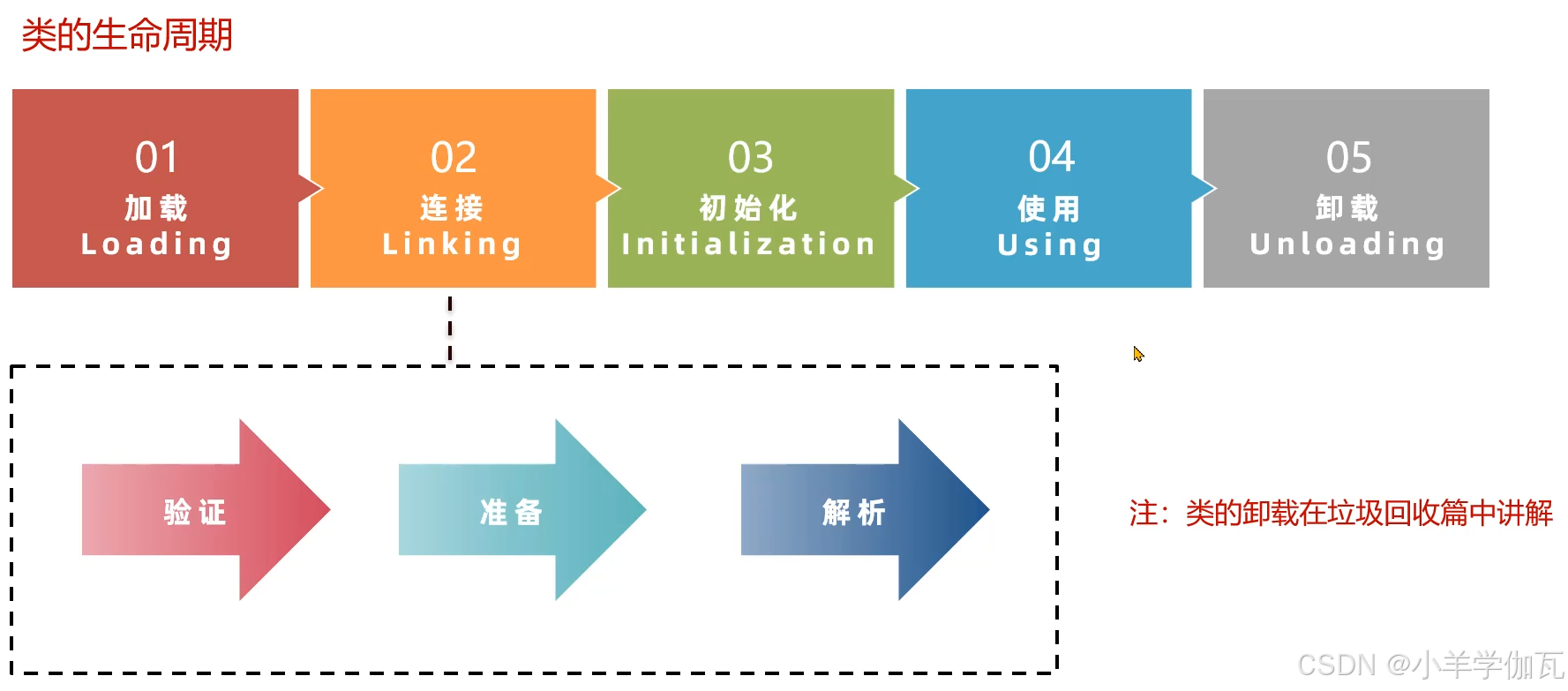
2.加载阶段
3.连接阶段
1.验证


2.准备
特殊情况:

3.解析
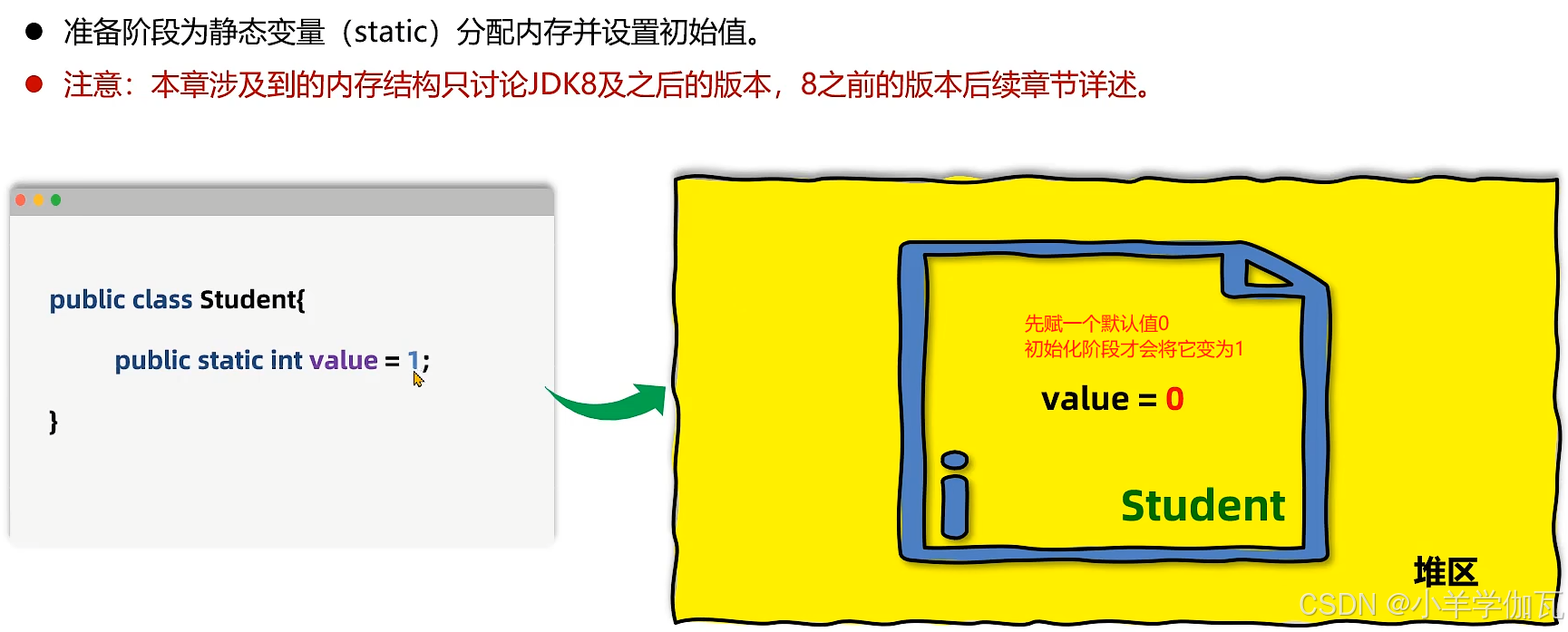
4.初始化阶段
为静态变量赋值


有静态变量的声明,但是没有赋值语句,不会初始化。
![]()
有final修饰,也不会初始化
![]()
有静态变量的声明,也有赋值语句,则会初始化。
public static int i =10;
二.类加载
1.类加载器的分类
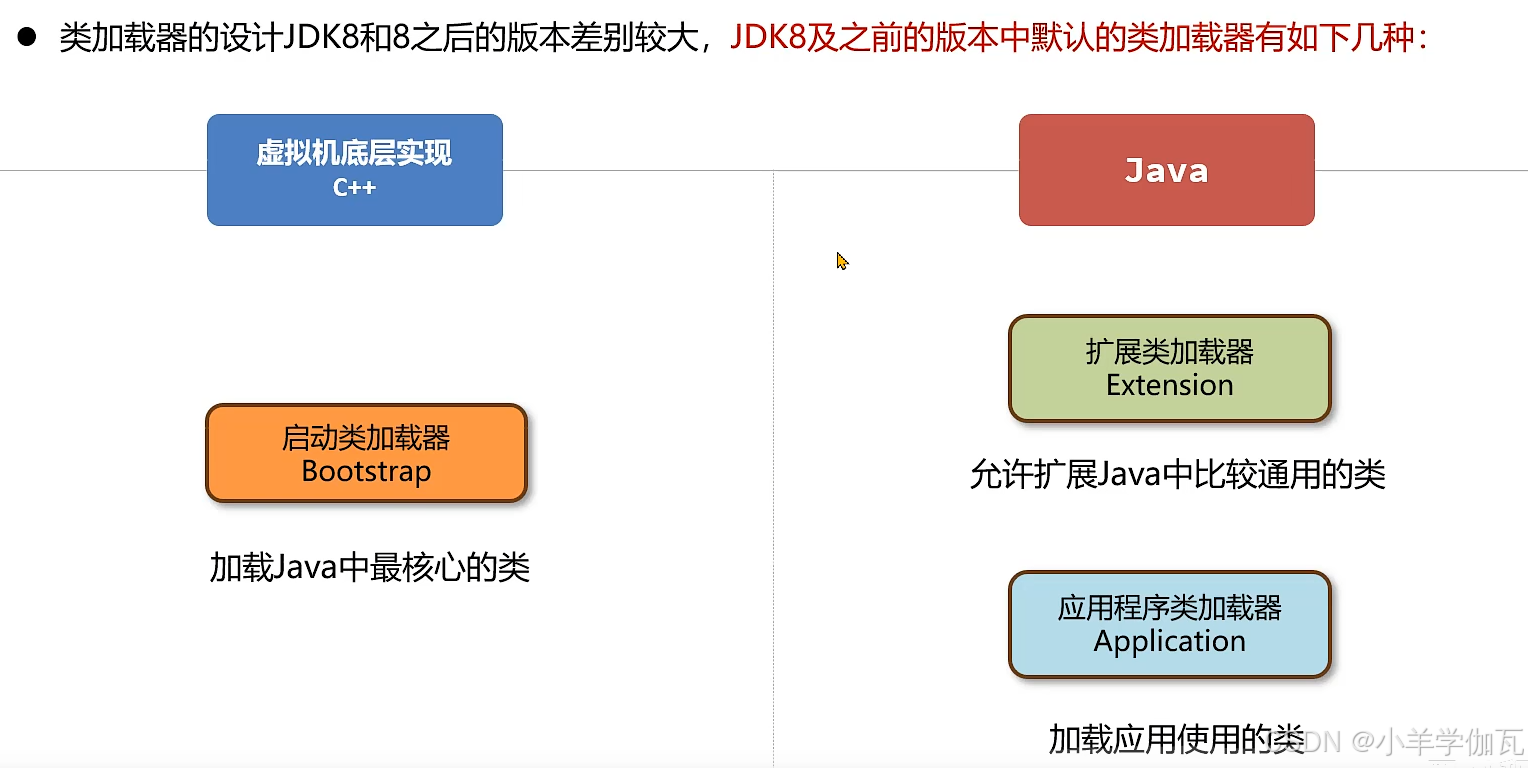
2.启动类加载器
3.
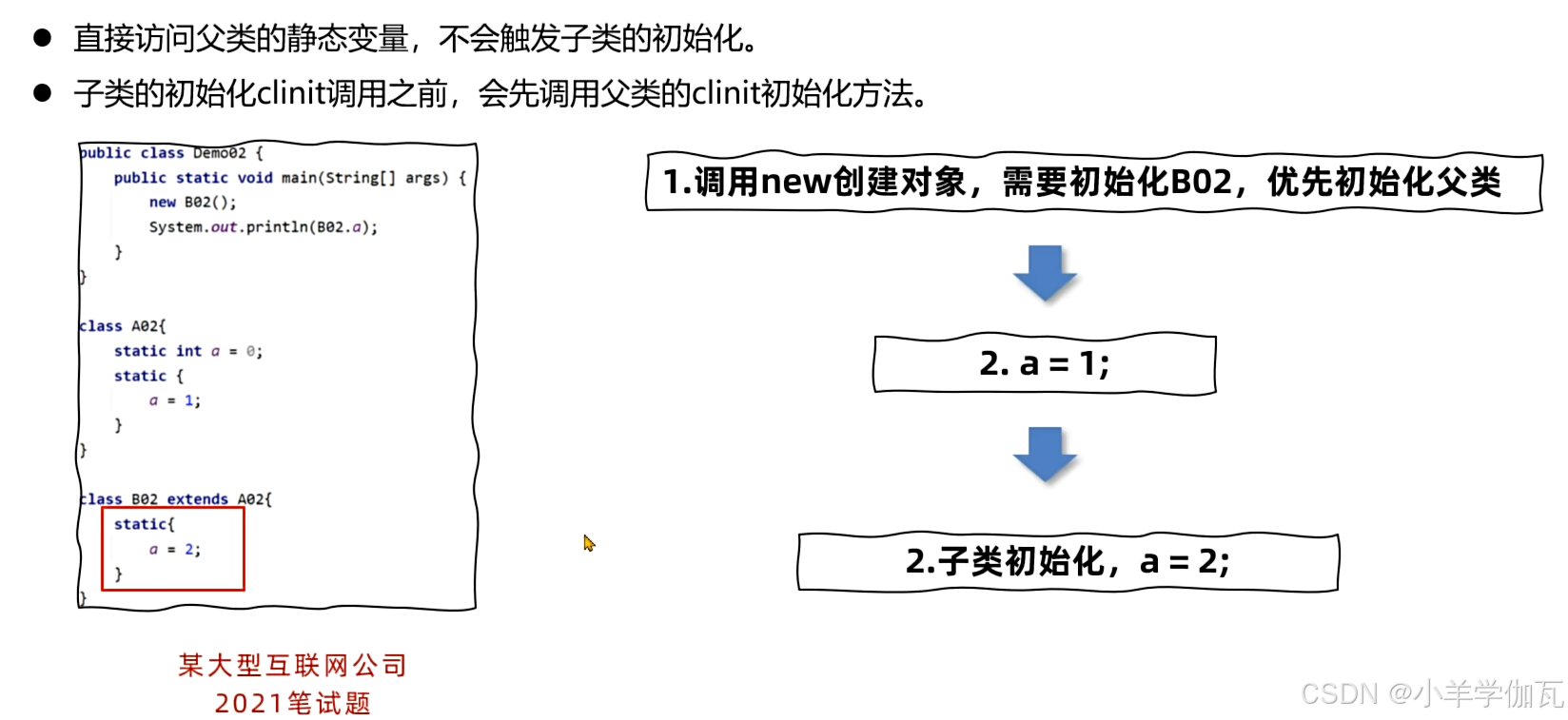
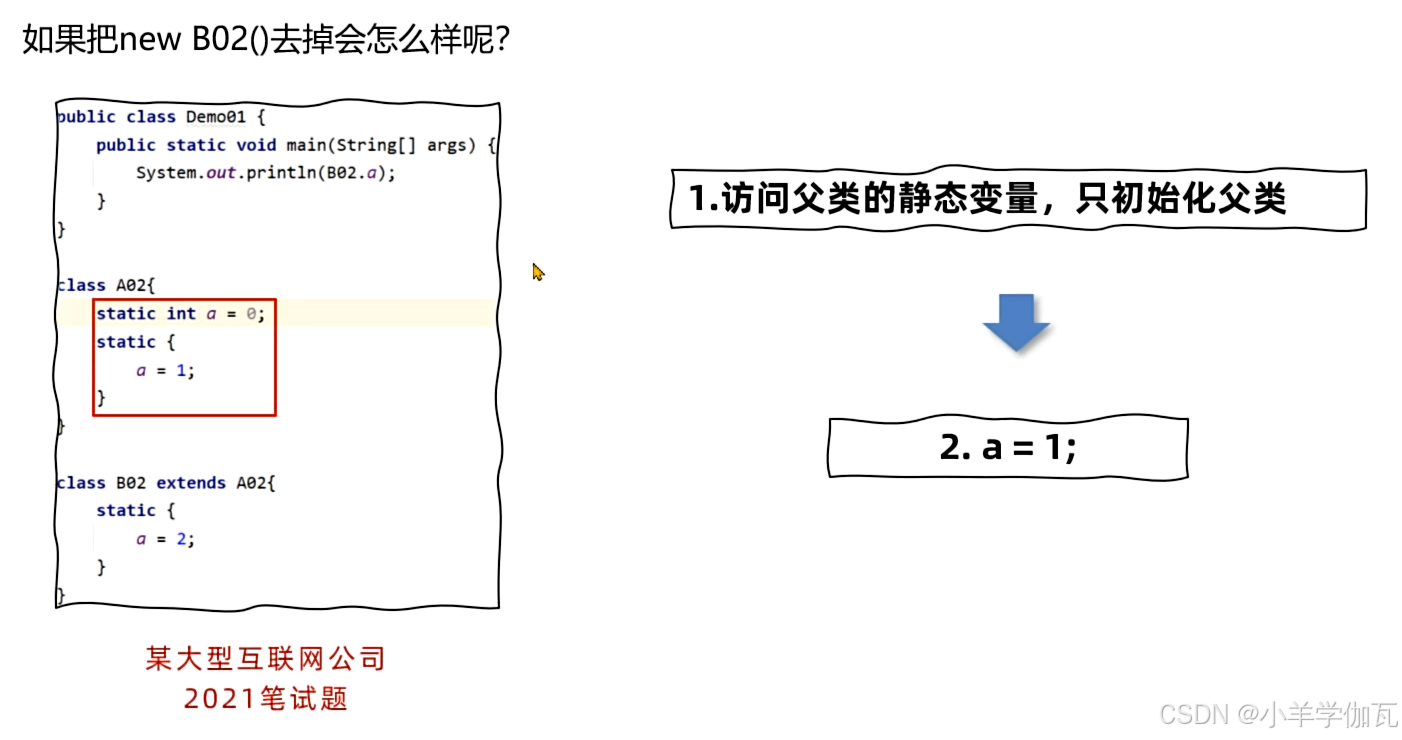
4.双亲委派机制
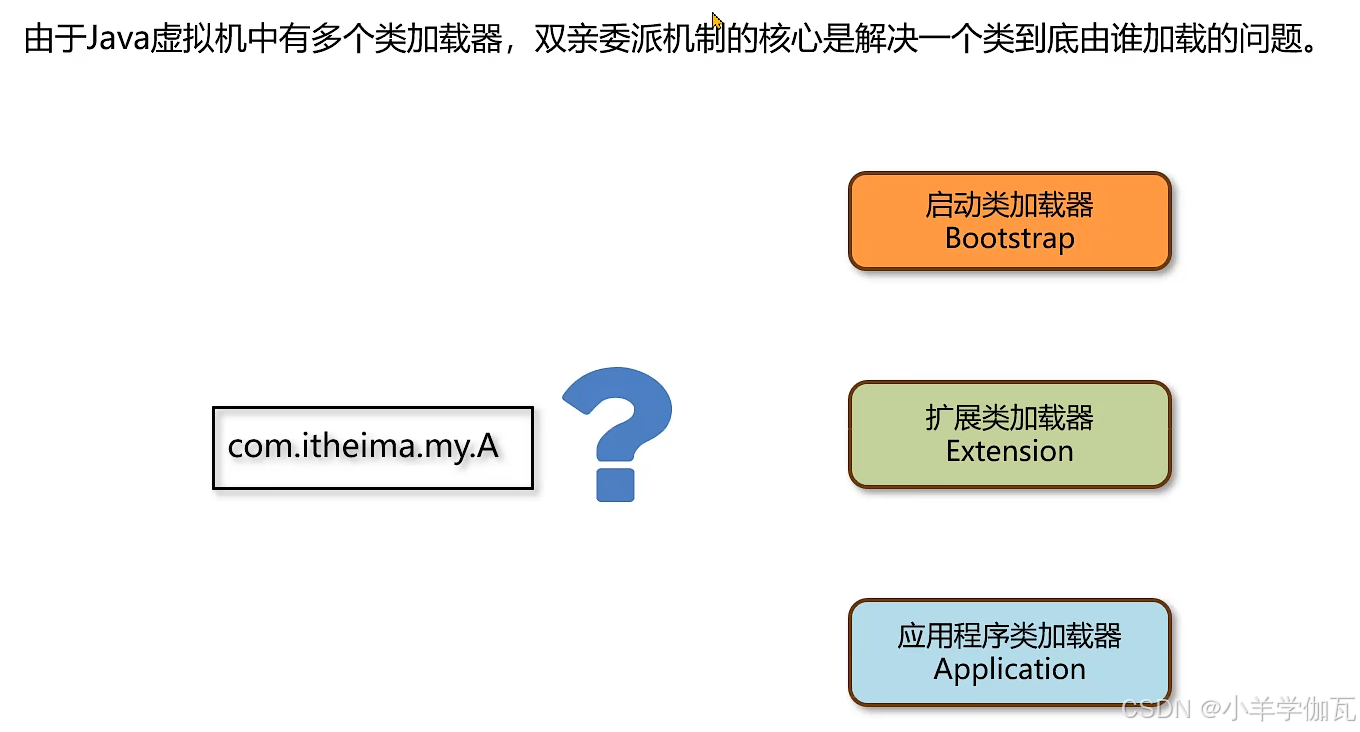

1.流程
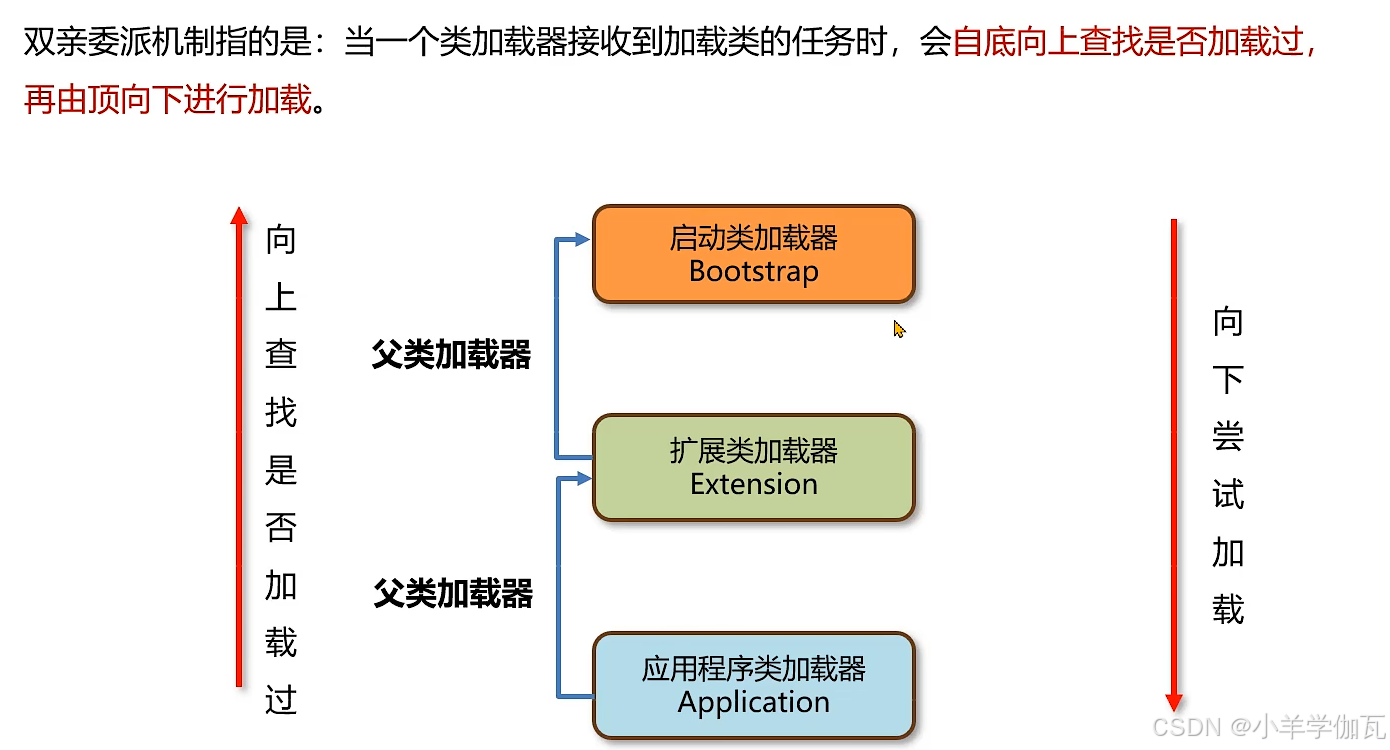
向上查找,从底部不断向上查找,看有没有哪个类加载过,加载过就返回
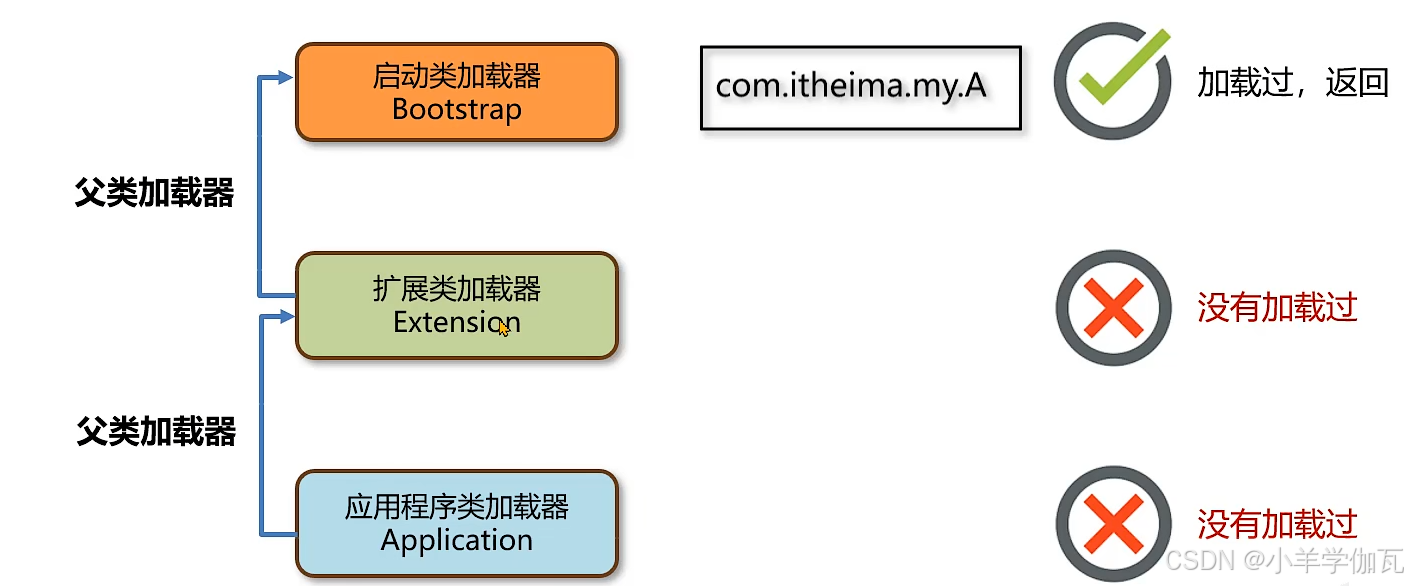
向下加载,看自己能不能加载,能加载就加载,不能加载就委派给下面的加载,知道可以加载。向下委派加载起到了加载优先级的作用。
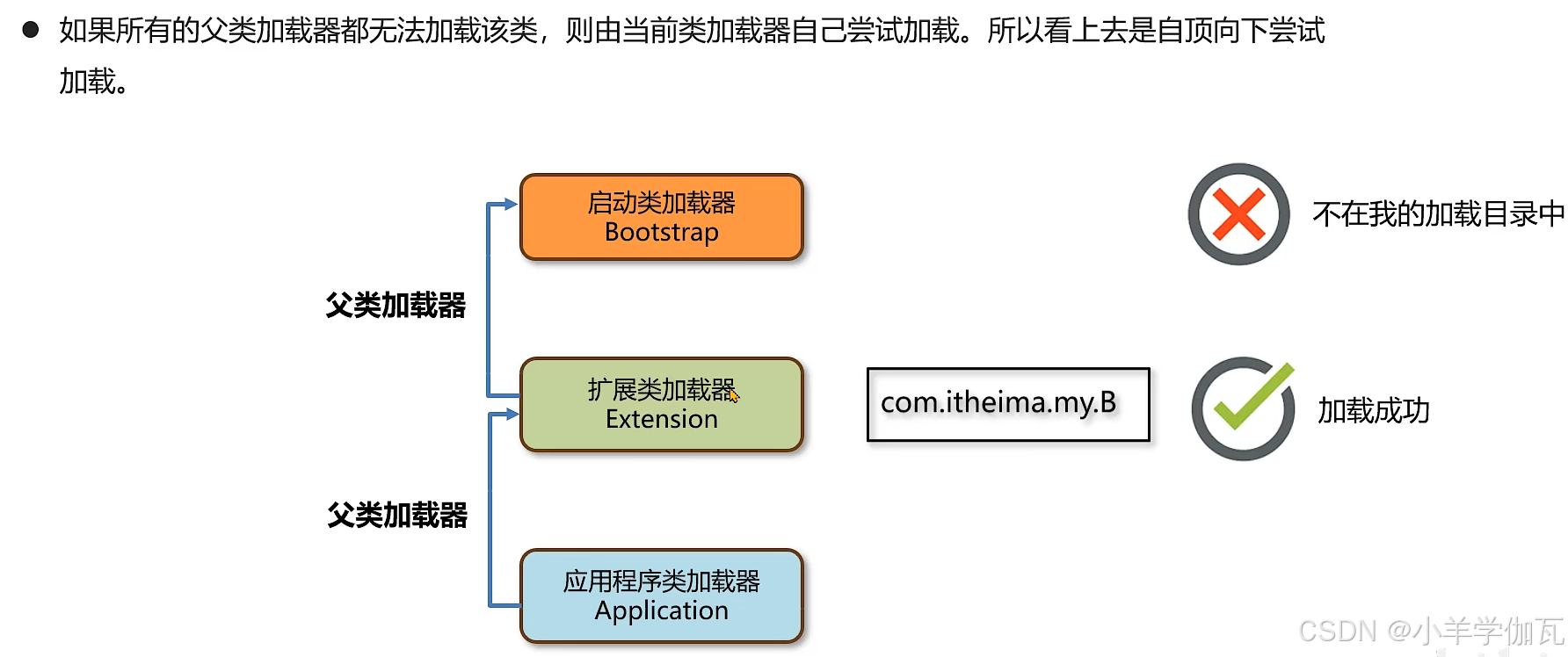
这时如果B再来加载,就是向上查找,发现已经加载过了,就直接返回。这样就避免了类被重复加载。
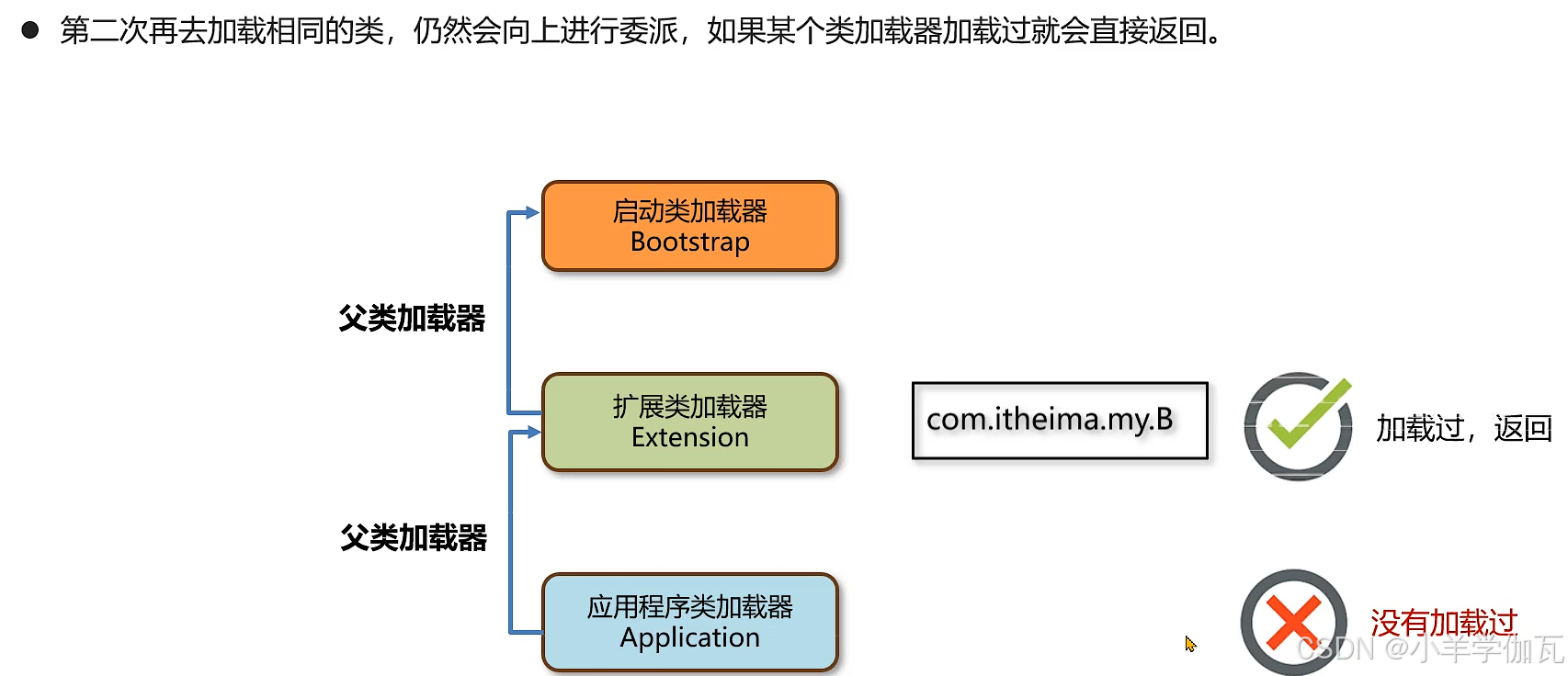
2.问题

3.总结

5.打破双亲委派机制

1.自定义类加载器

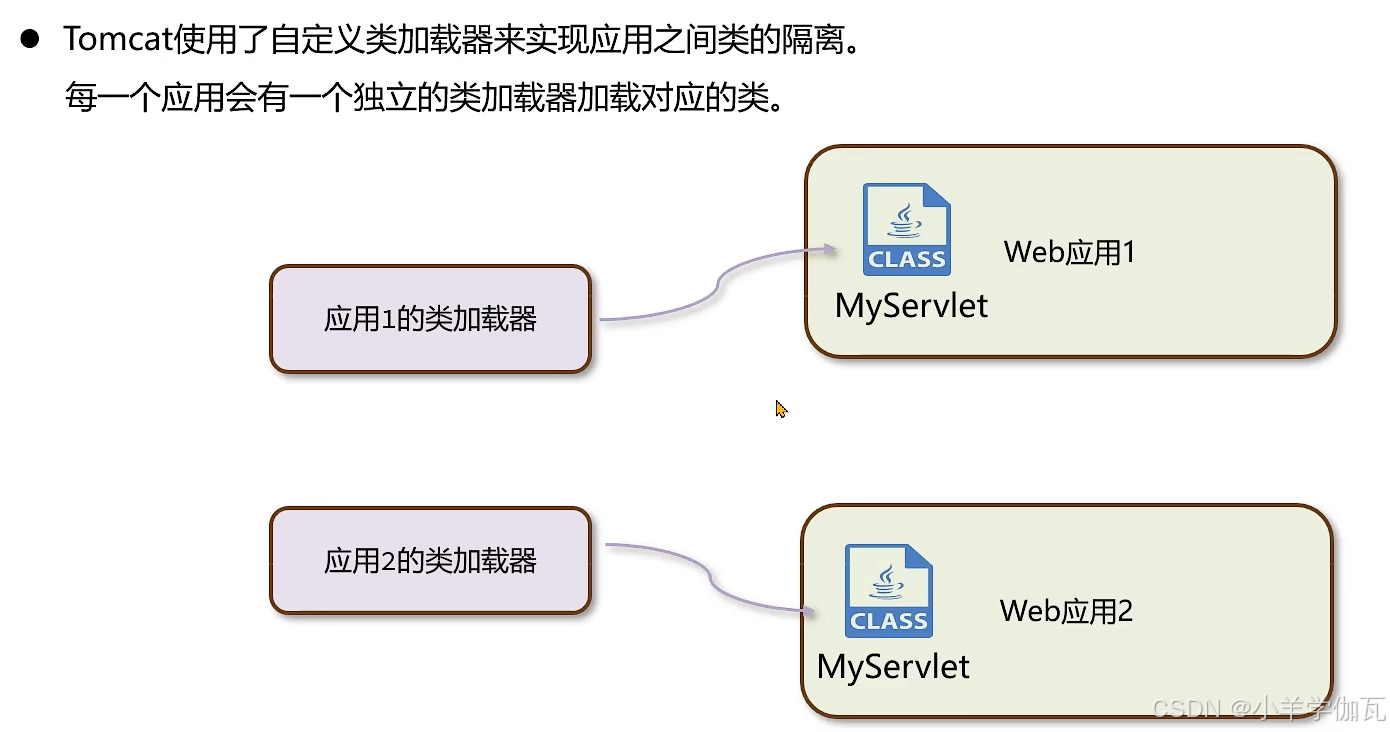
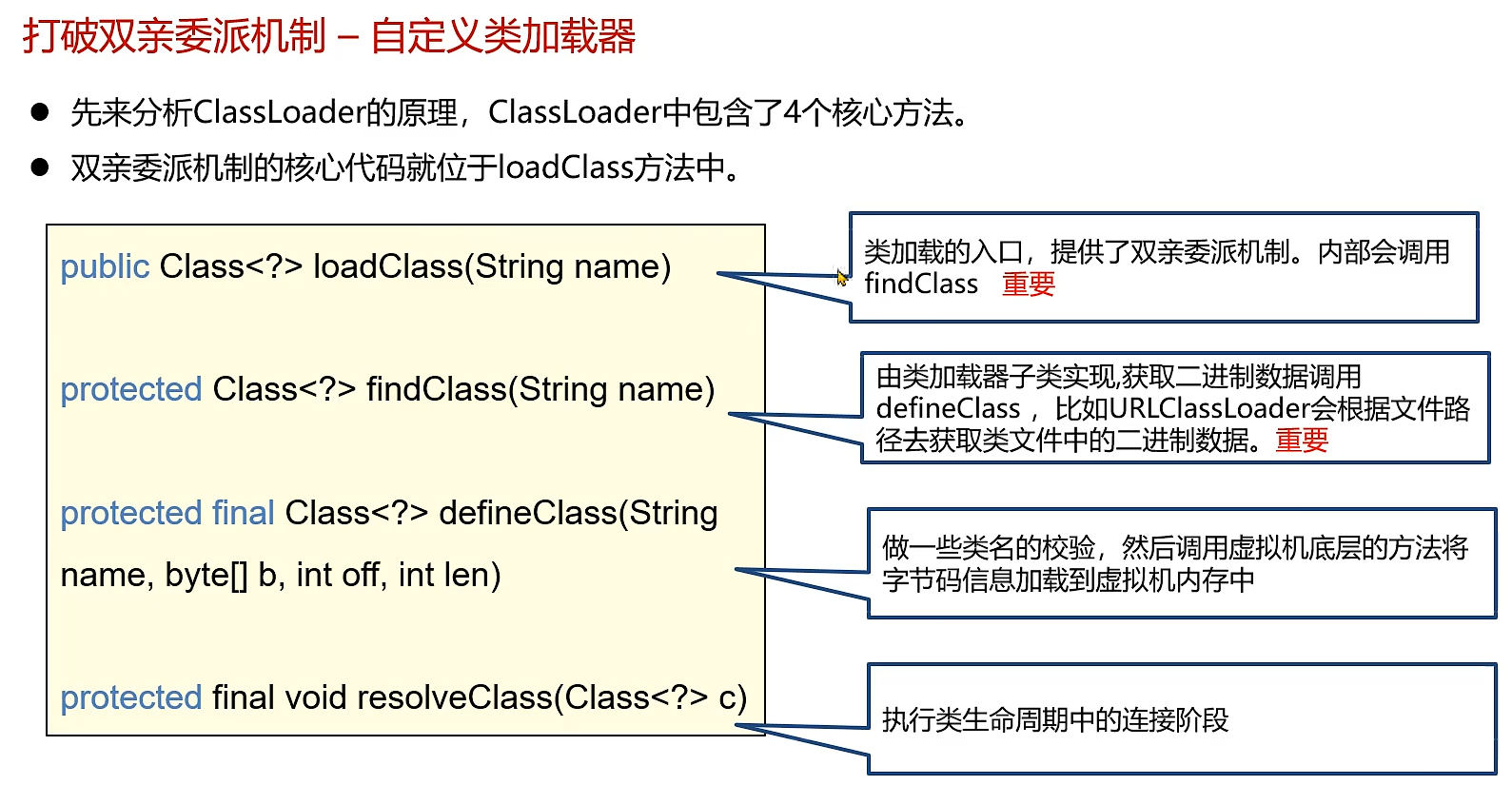
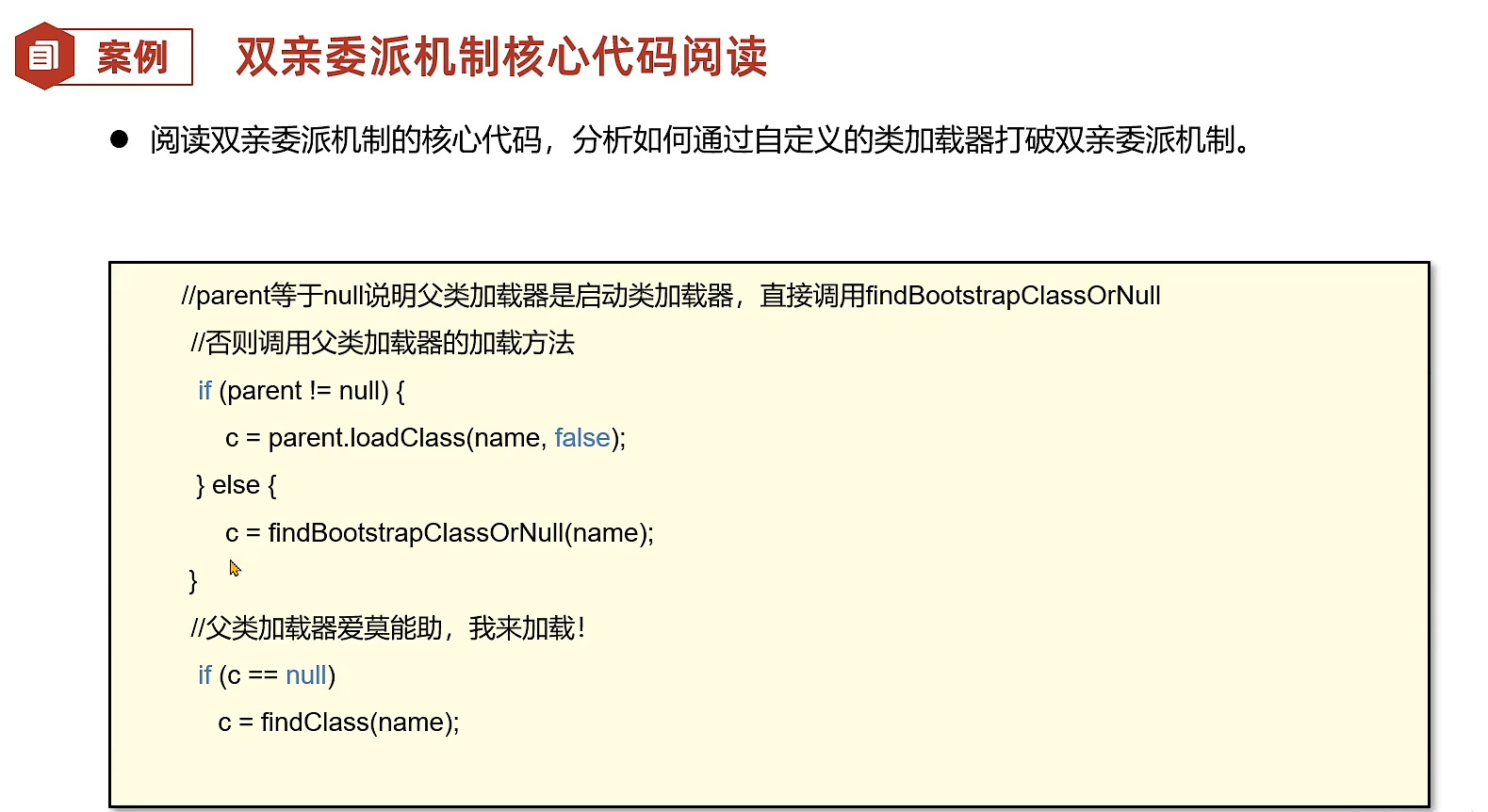
所以我们可以重写loadclass方法
看不打到双亲委派的踪影了,根据类的全限定名找到对应的字节码文件加载到内存中变成一个二进制数组。然后通过defineclass在堆和方法区生成对应的数据。

 2.JDBC案例打破双亲委派机制
2.JDBC案例打破双亲委派机制

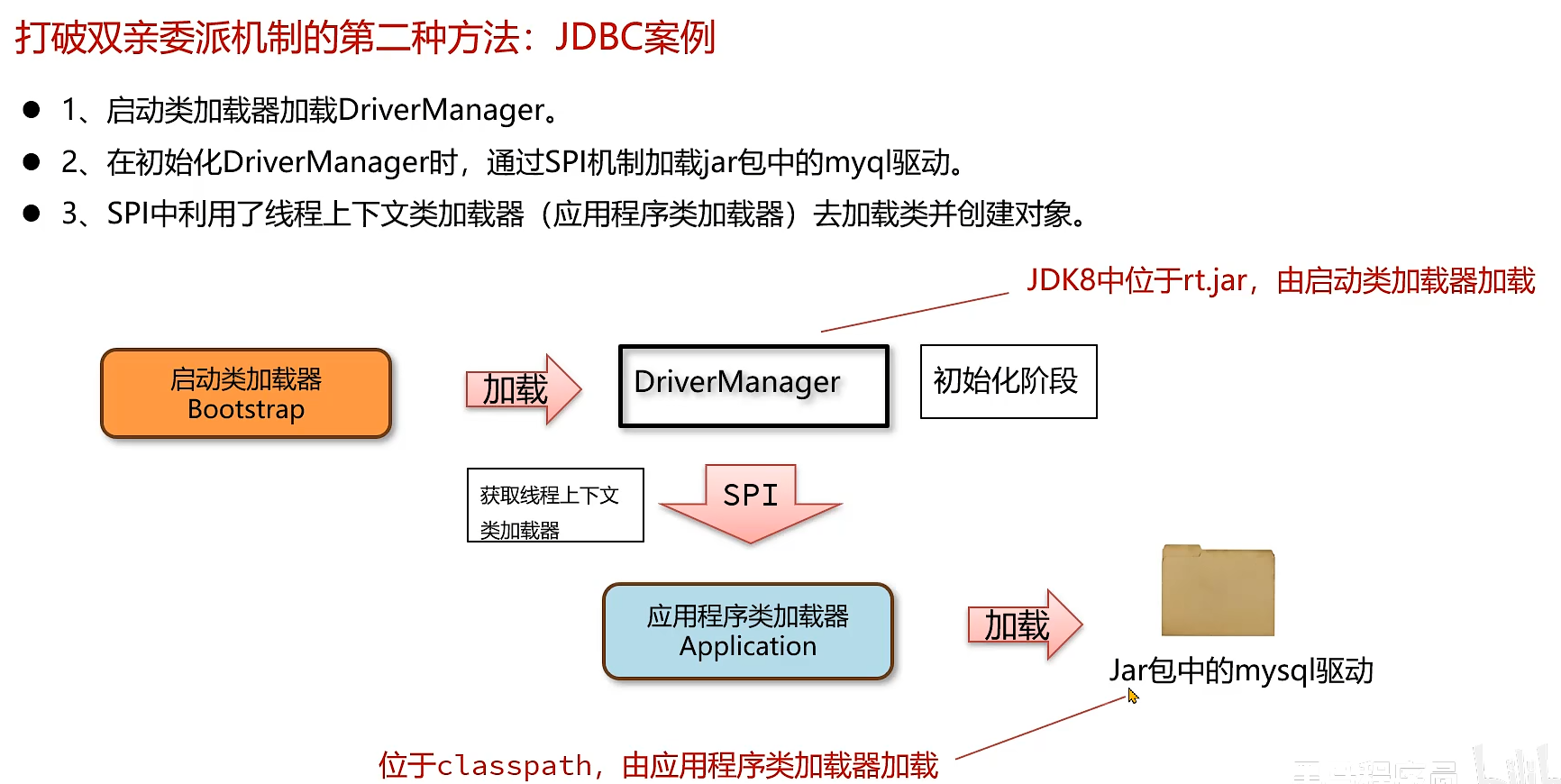
三.运行时数据区
1.目标
2.程序计数器
1.介绍
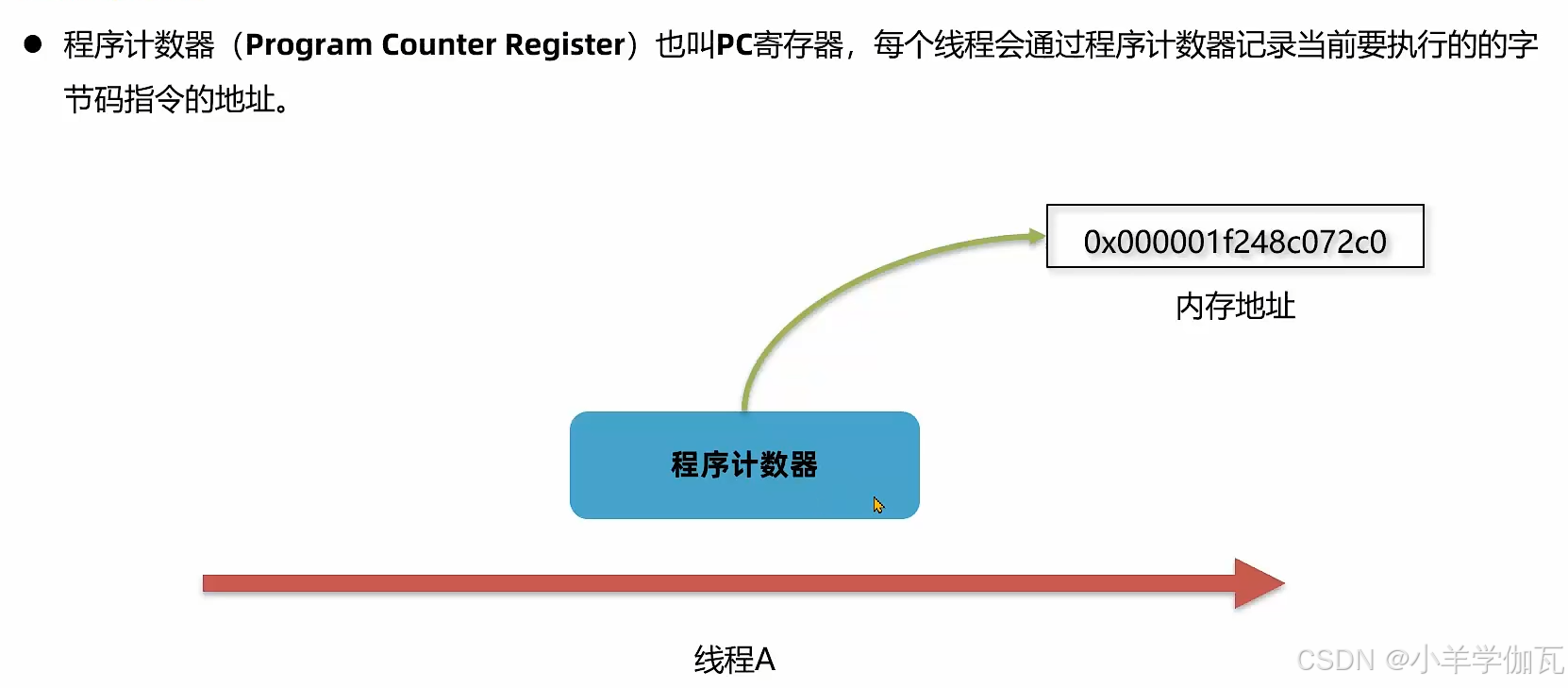
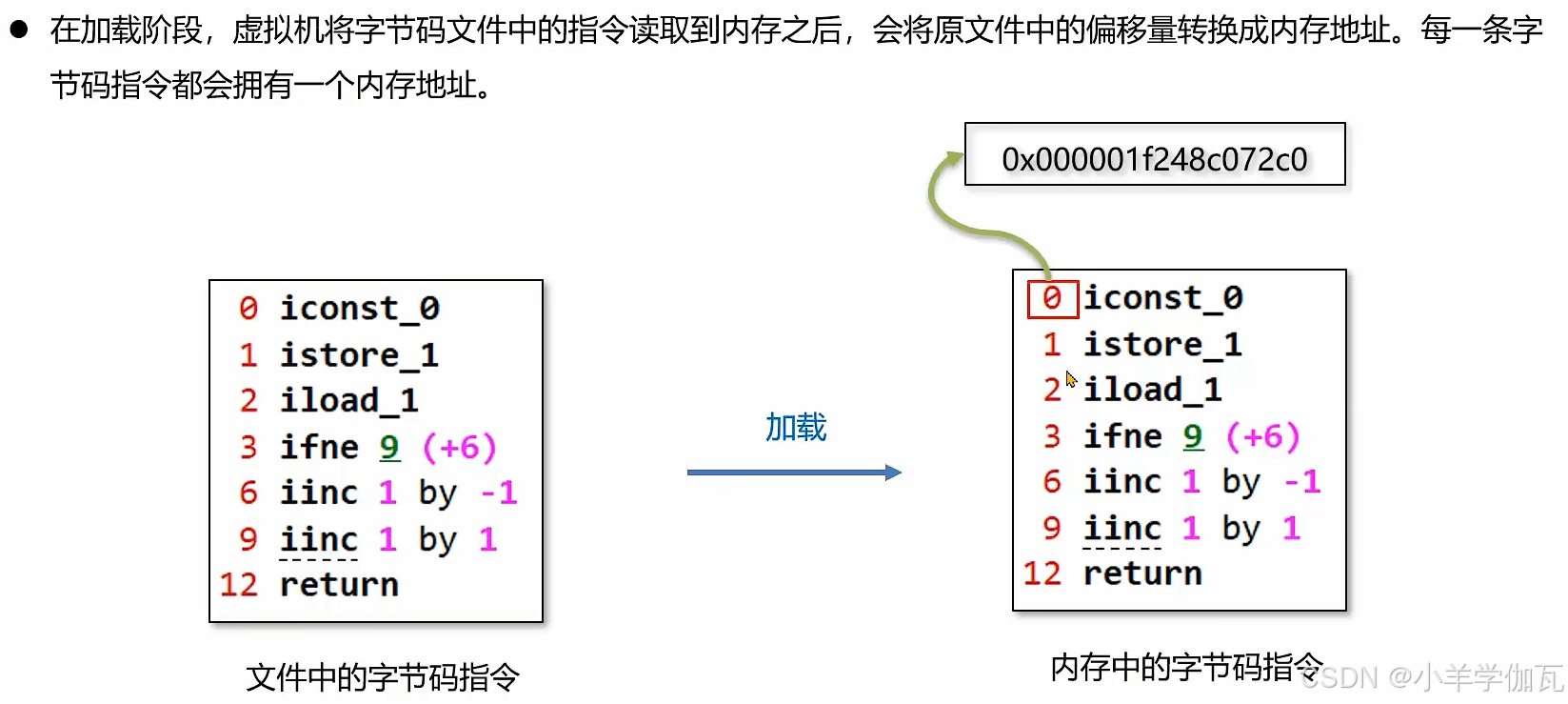
代码是需要解释器去执行的,解释器只需要去找程序计数器要这个地址,就知道要执行的字节码指令是什么了。
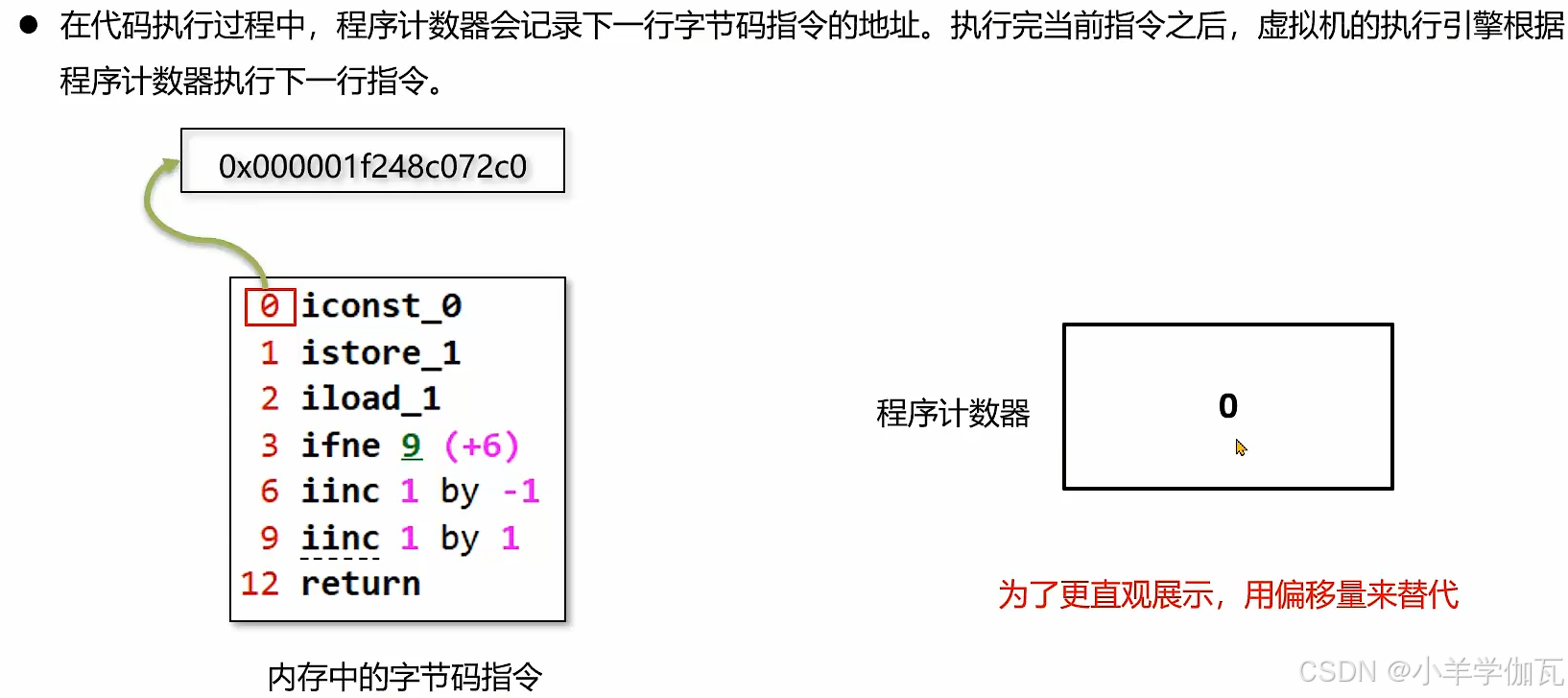
多线程的情况下,cpu来回切换。
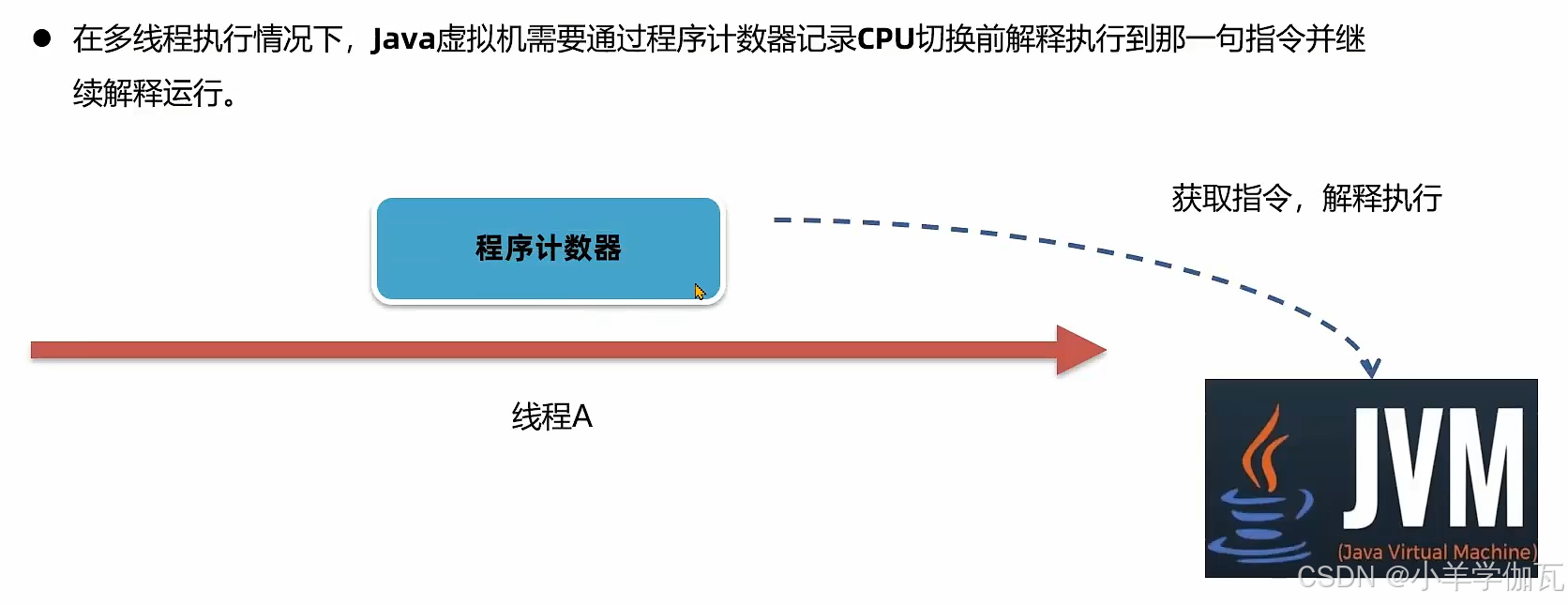
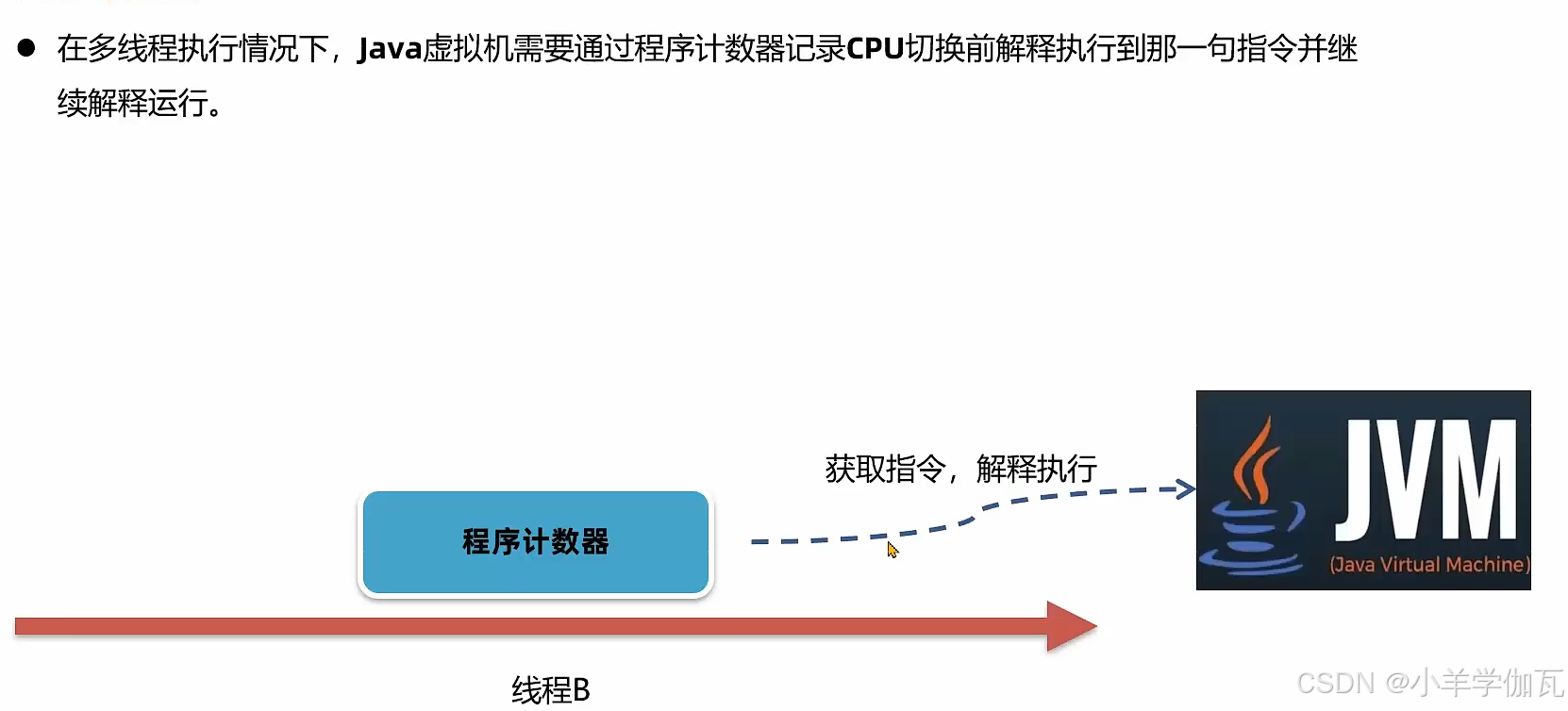
2.作用
从上面这些我们就可以看出程序计数器有两个作用
1.来控制解释器来执行指令的顺序
2.在多线程的情况下,cpu来回切换,程序计数器可以记录切换前执行到了哪一句指令,来进行后续的运行。
3.问题

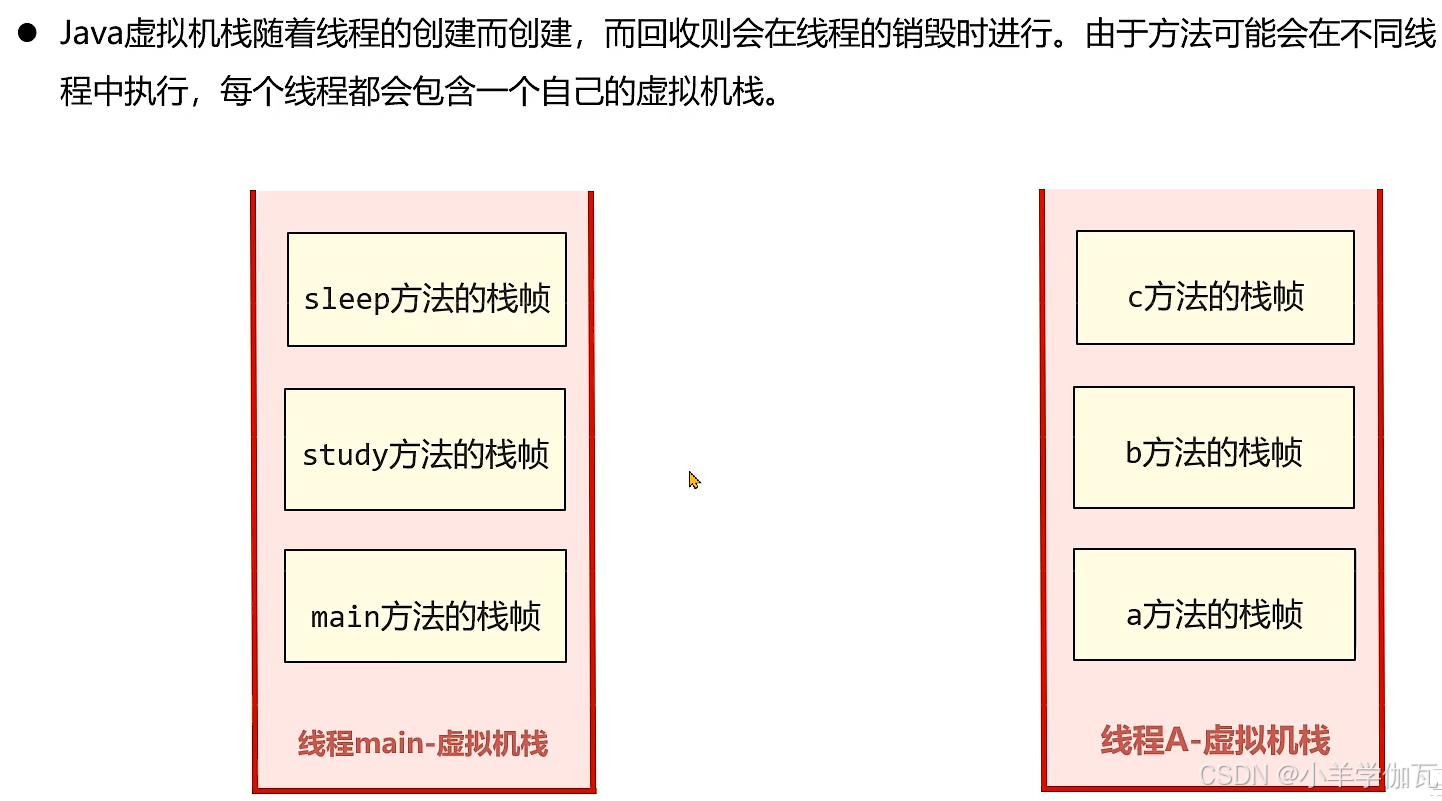
3.虚拟机栈
1.简单介绍
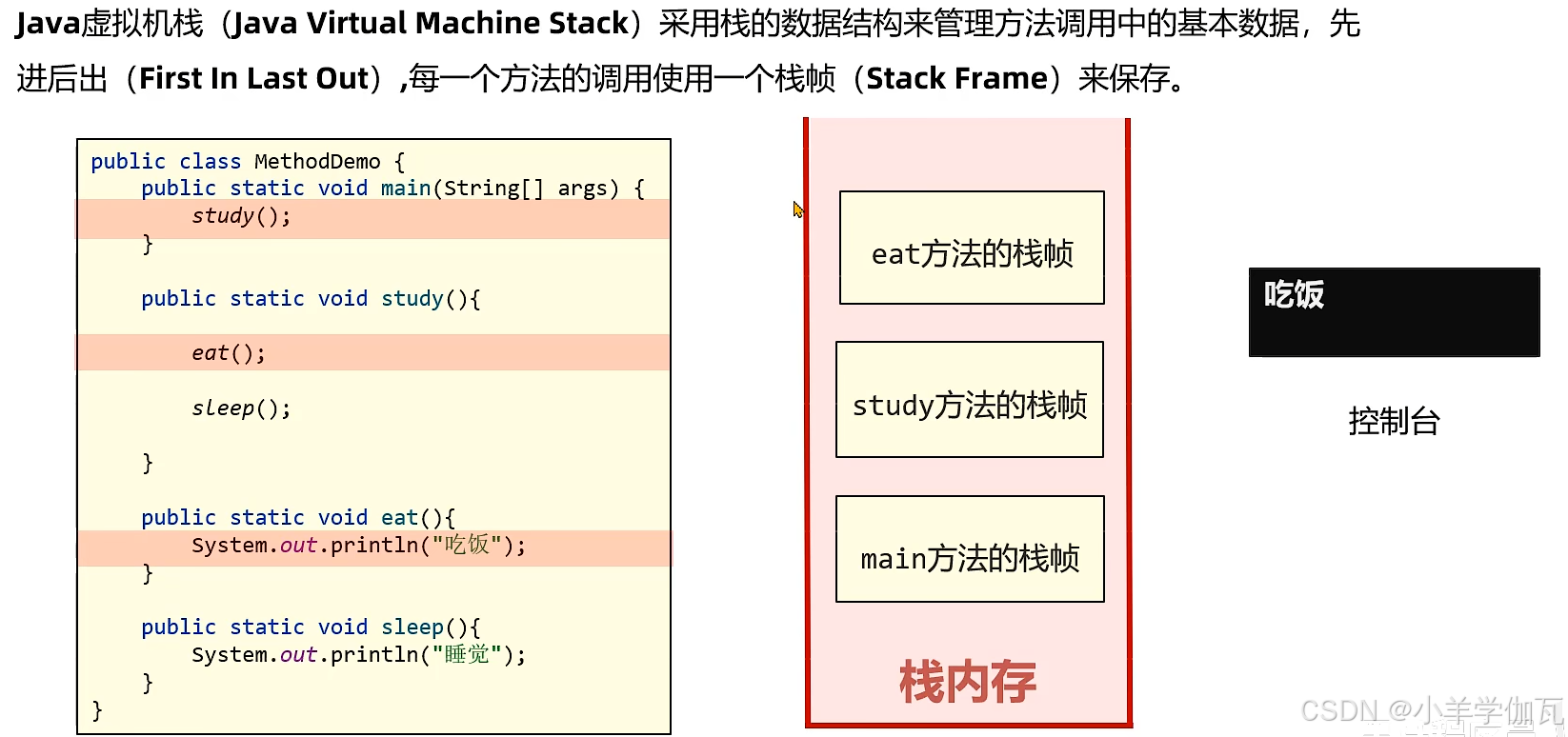

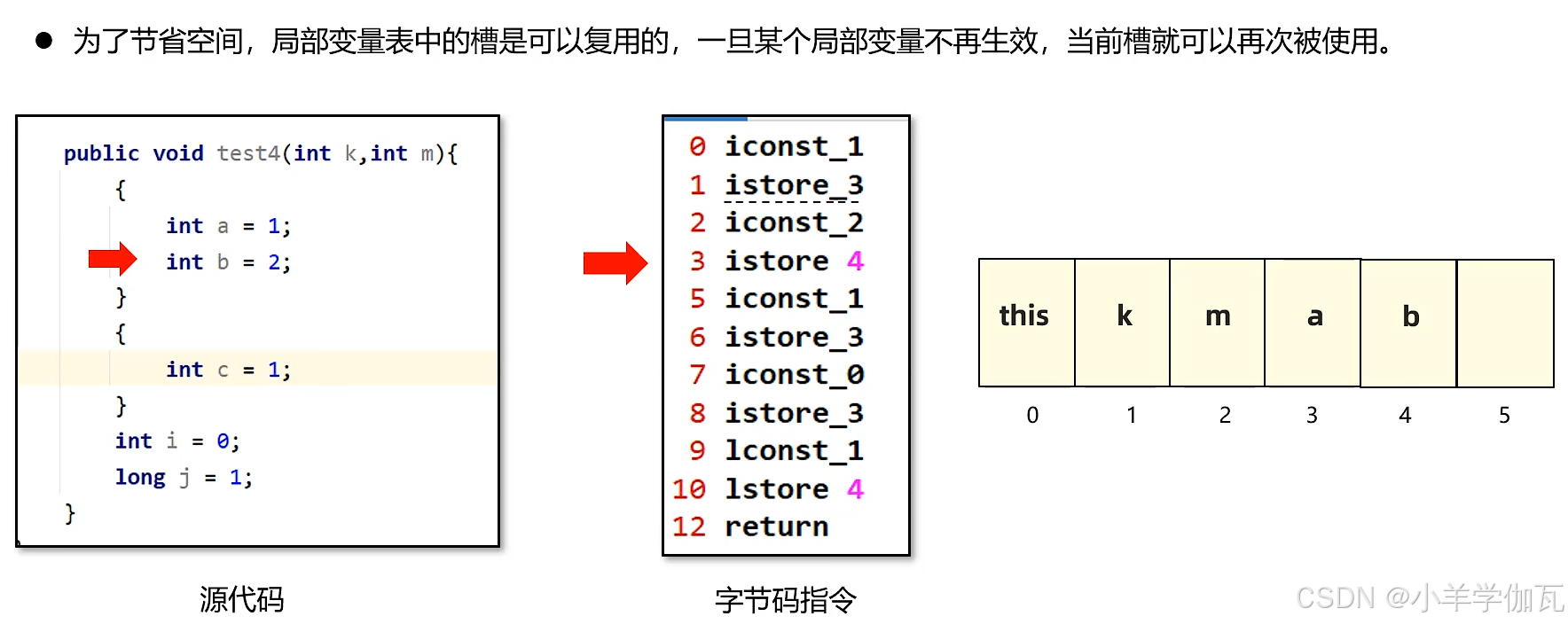
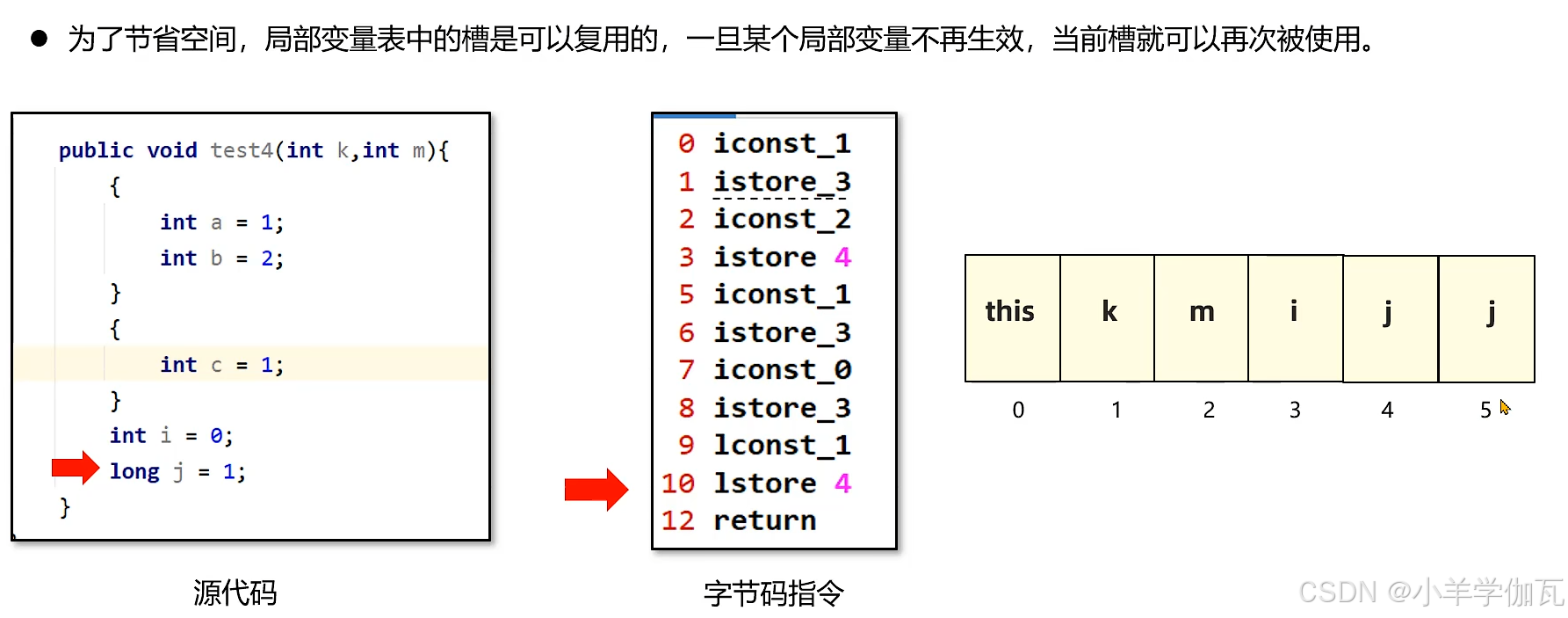
2.局部变量表
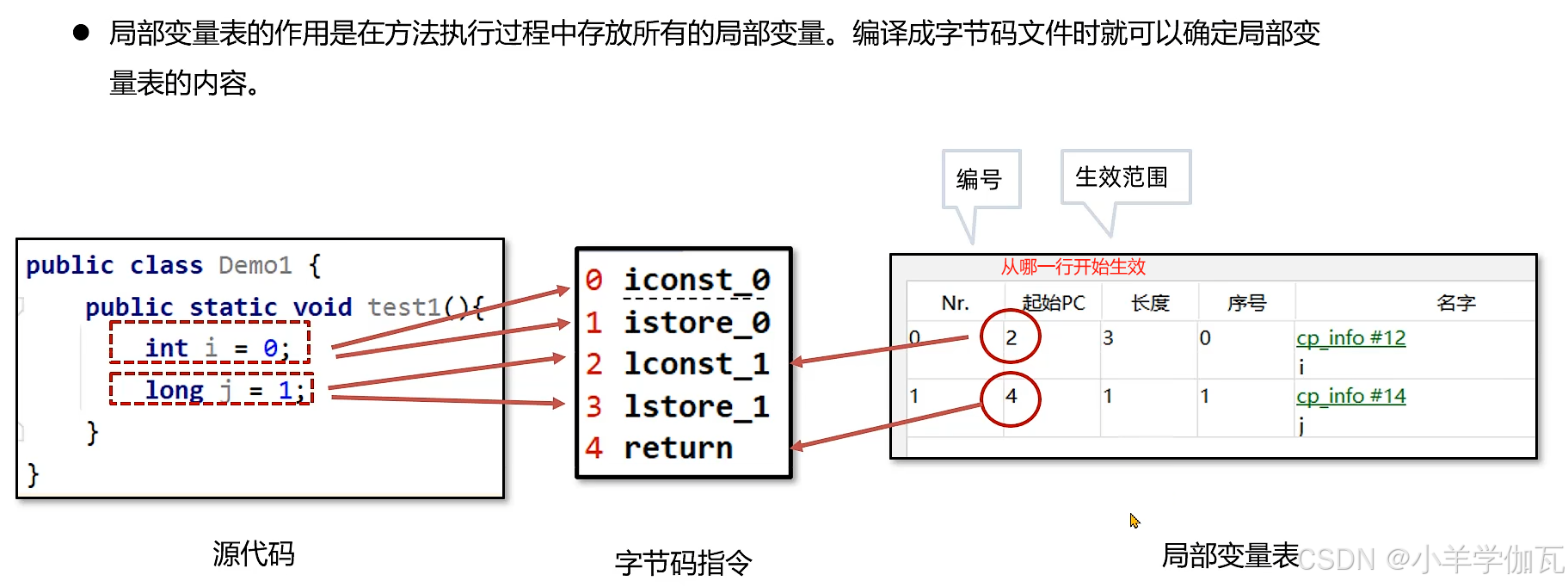



- 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,将会被销毁。
- 访问修饰符不能用于局部变量。
- 局部变量只在声明它的方法、构造方法或者语句块中可见。
- 局部变量是在栈上分配的。
- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
总结
局部变量表在运行过程中存放所有的局部变量,以及方法的参数以及实例方法中的this对象。
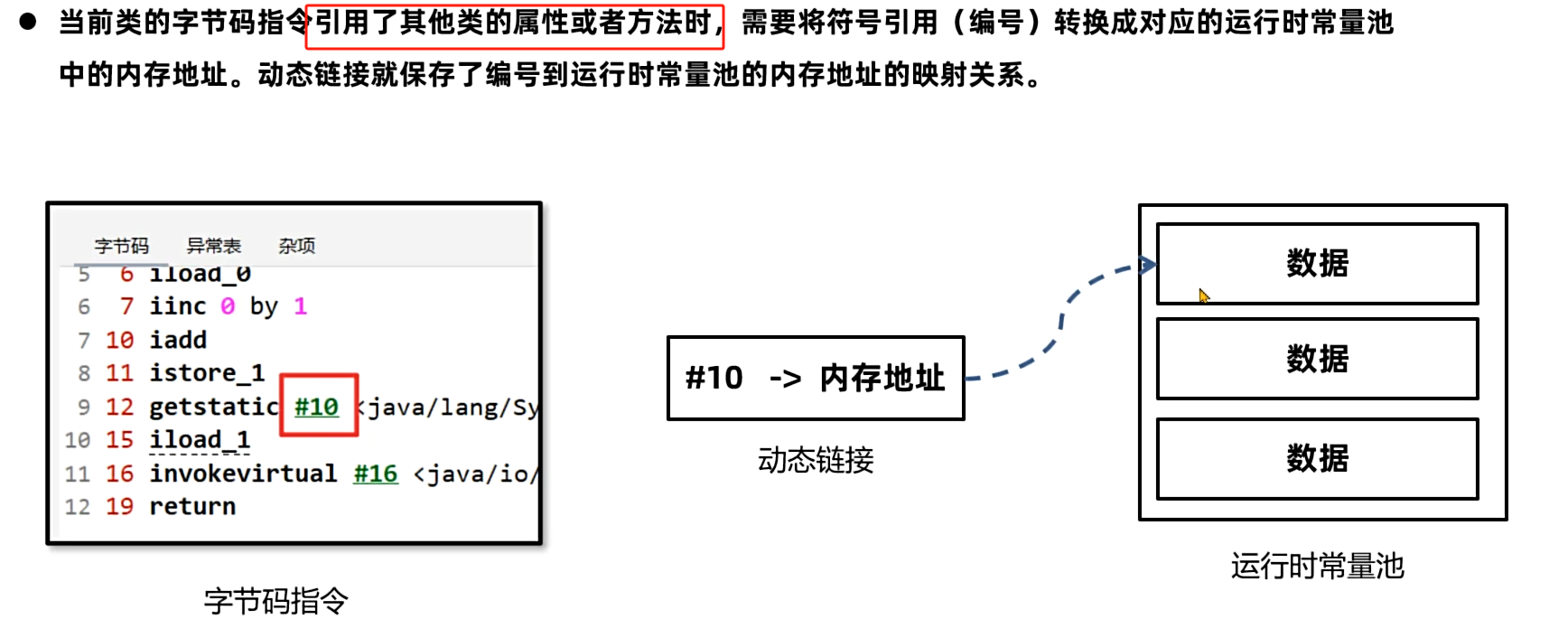
3.操作数栈和帧数据
动态链接
程序计数器
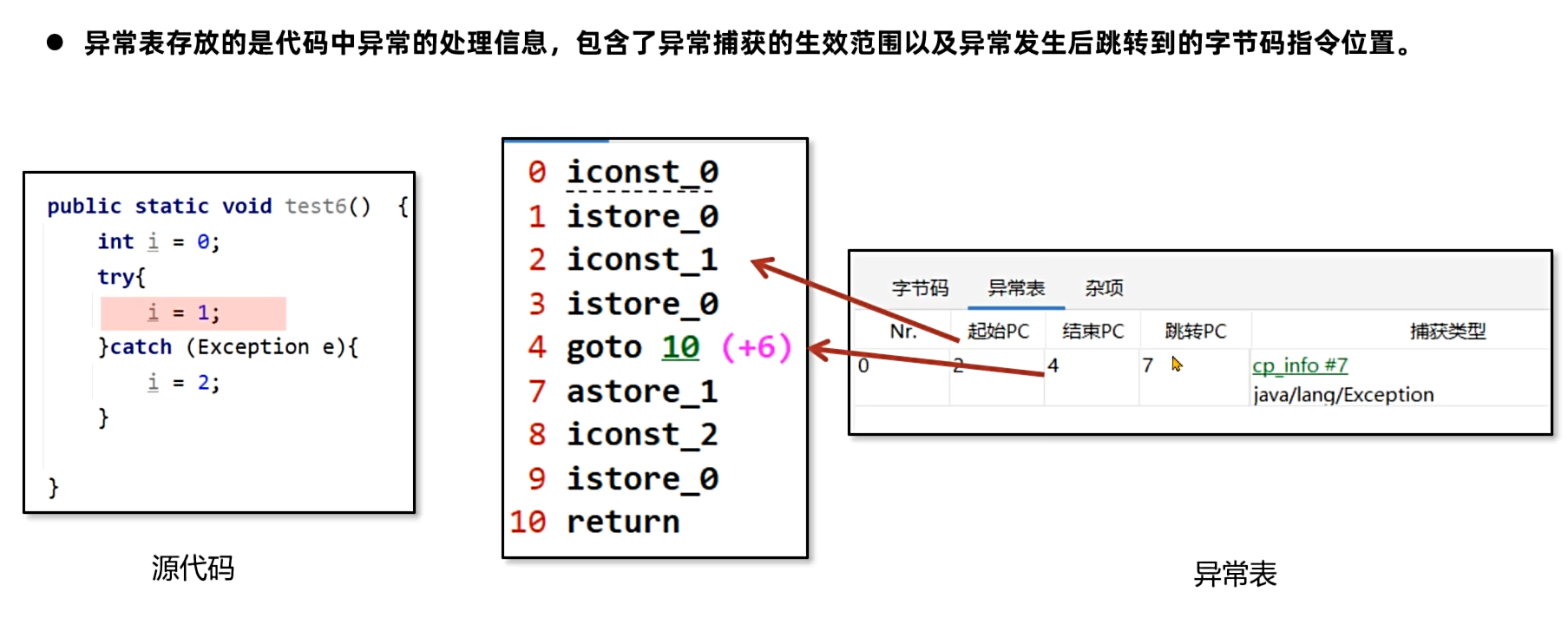
异常表
4.堆
对象在堆上是如何存储的?
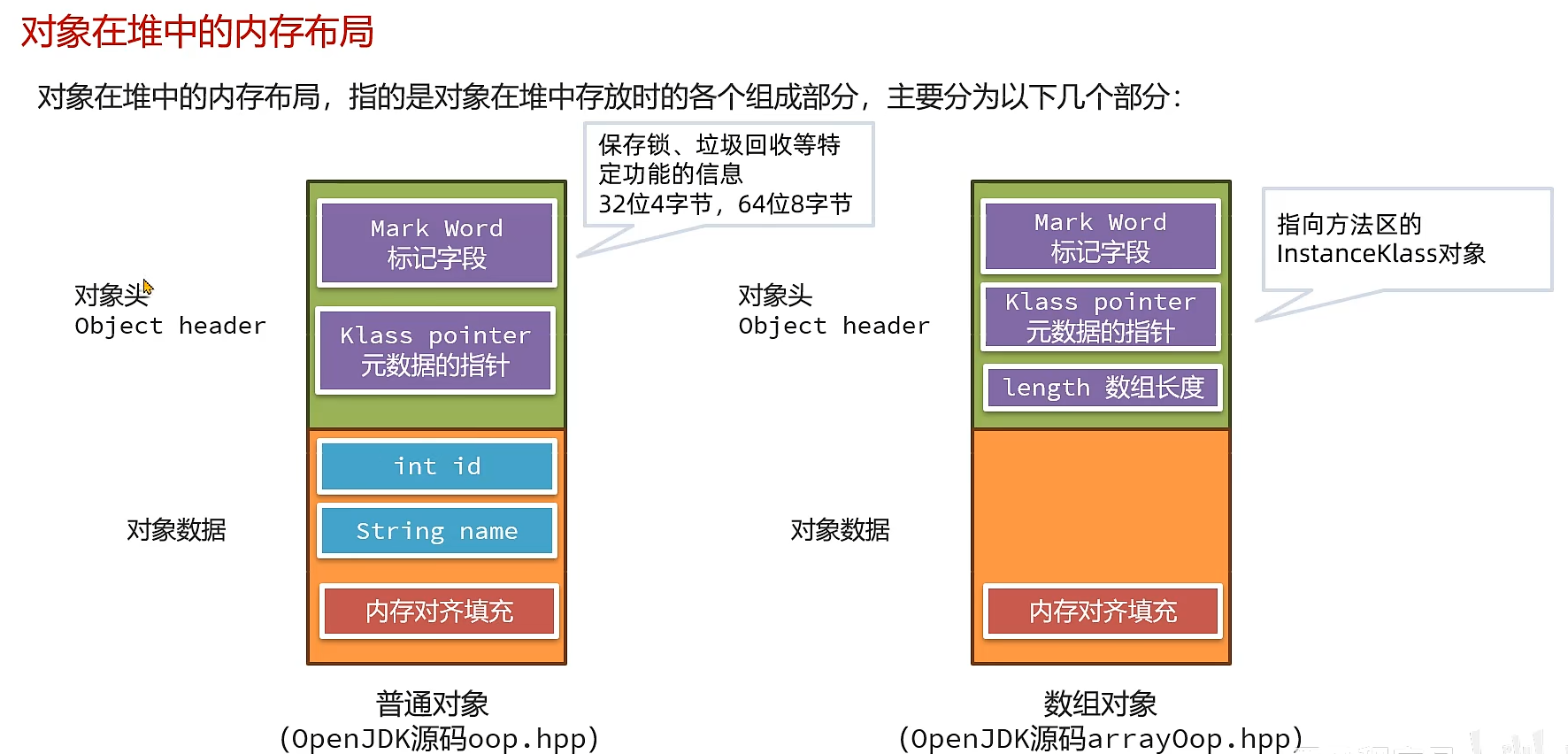
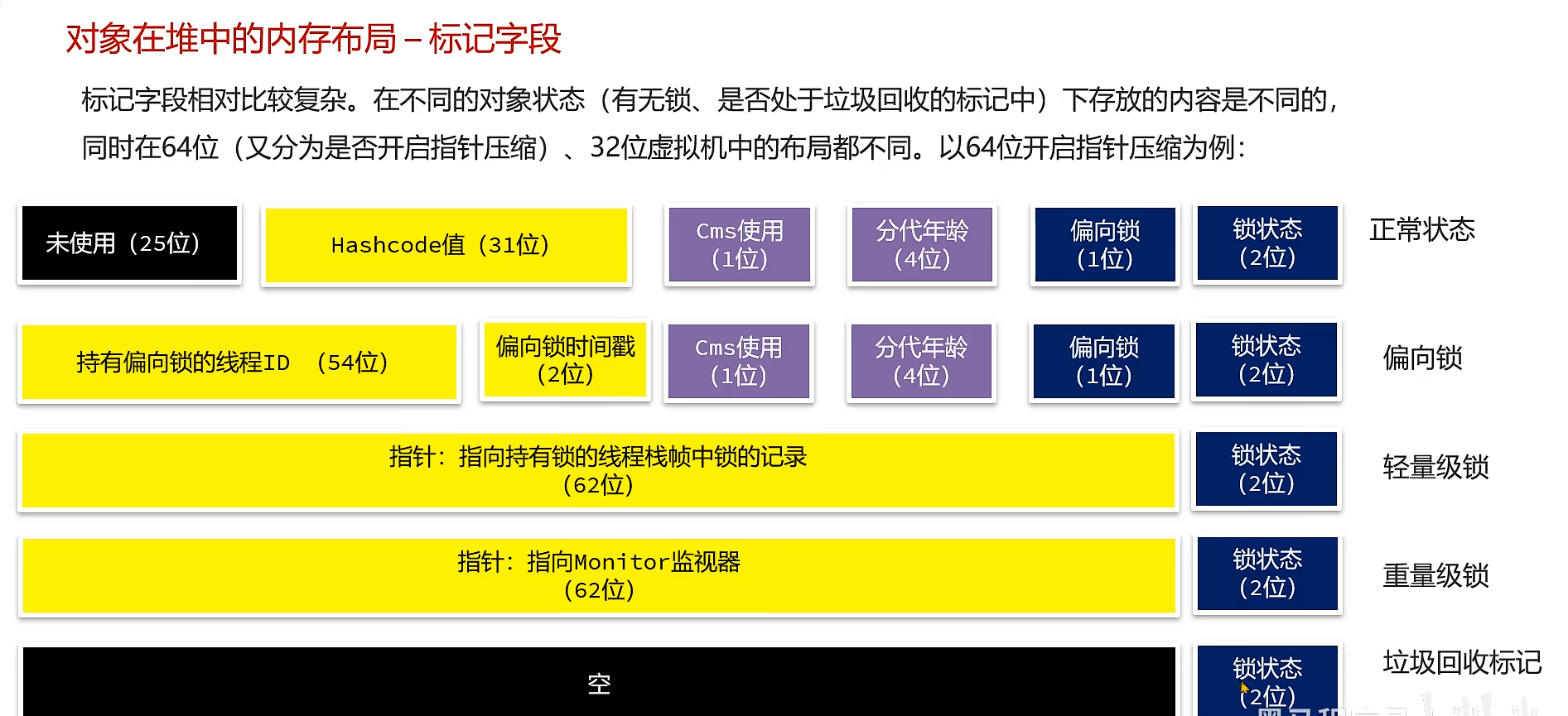
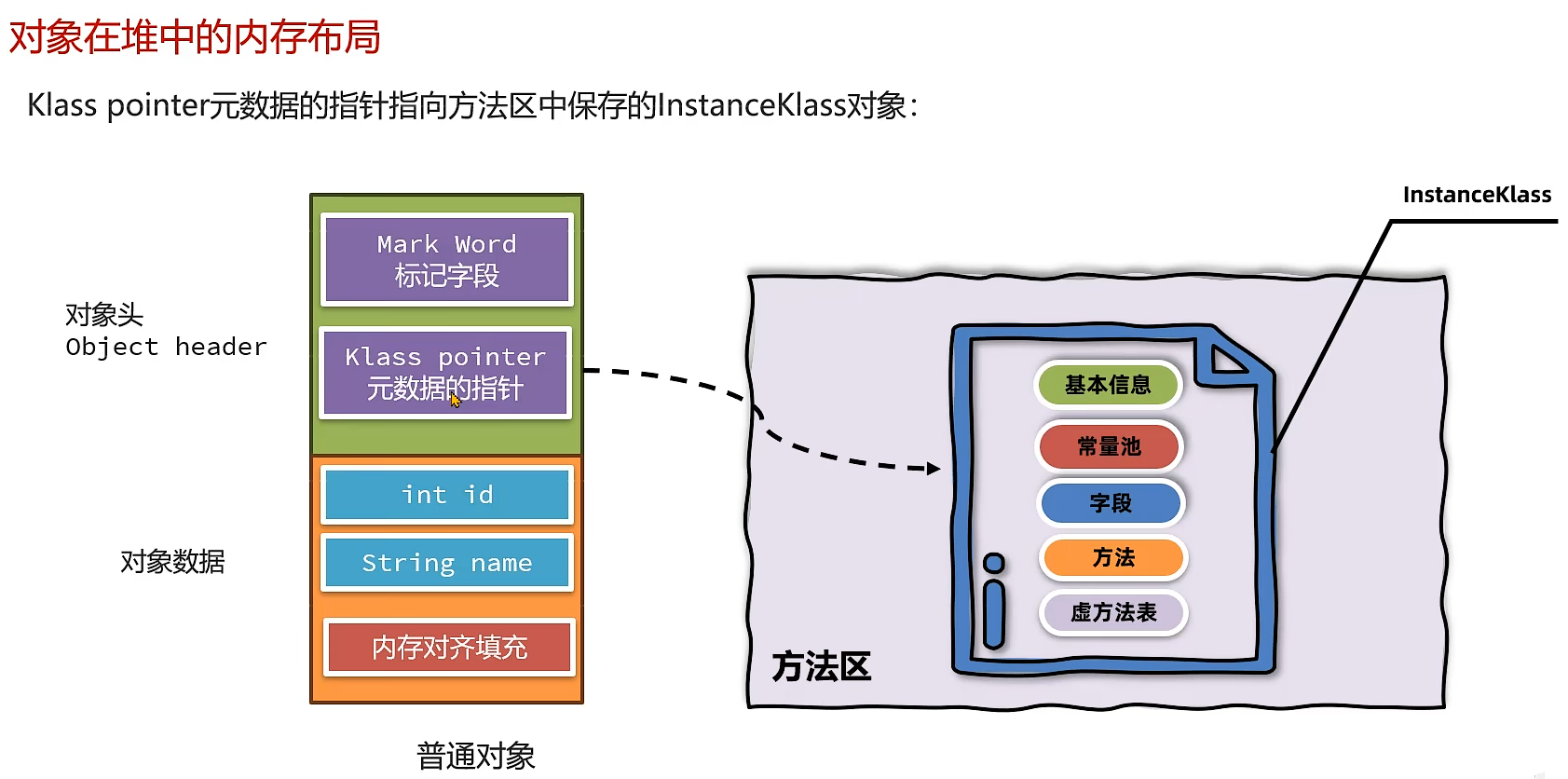
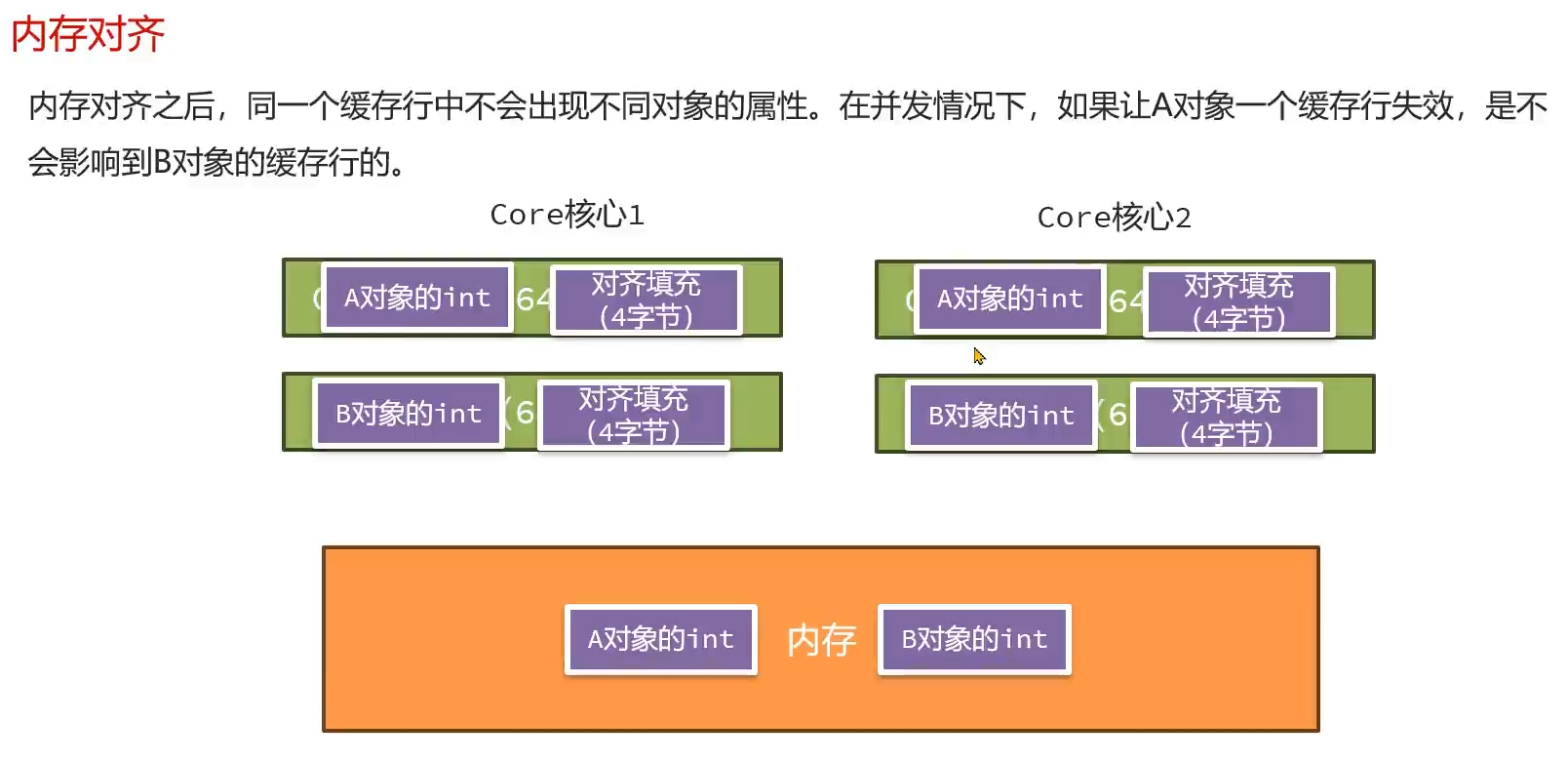
内存对齐填充:
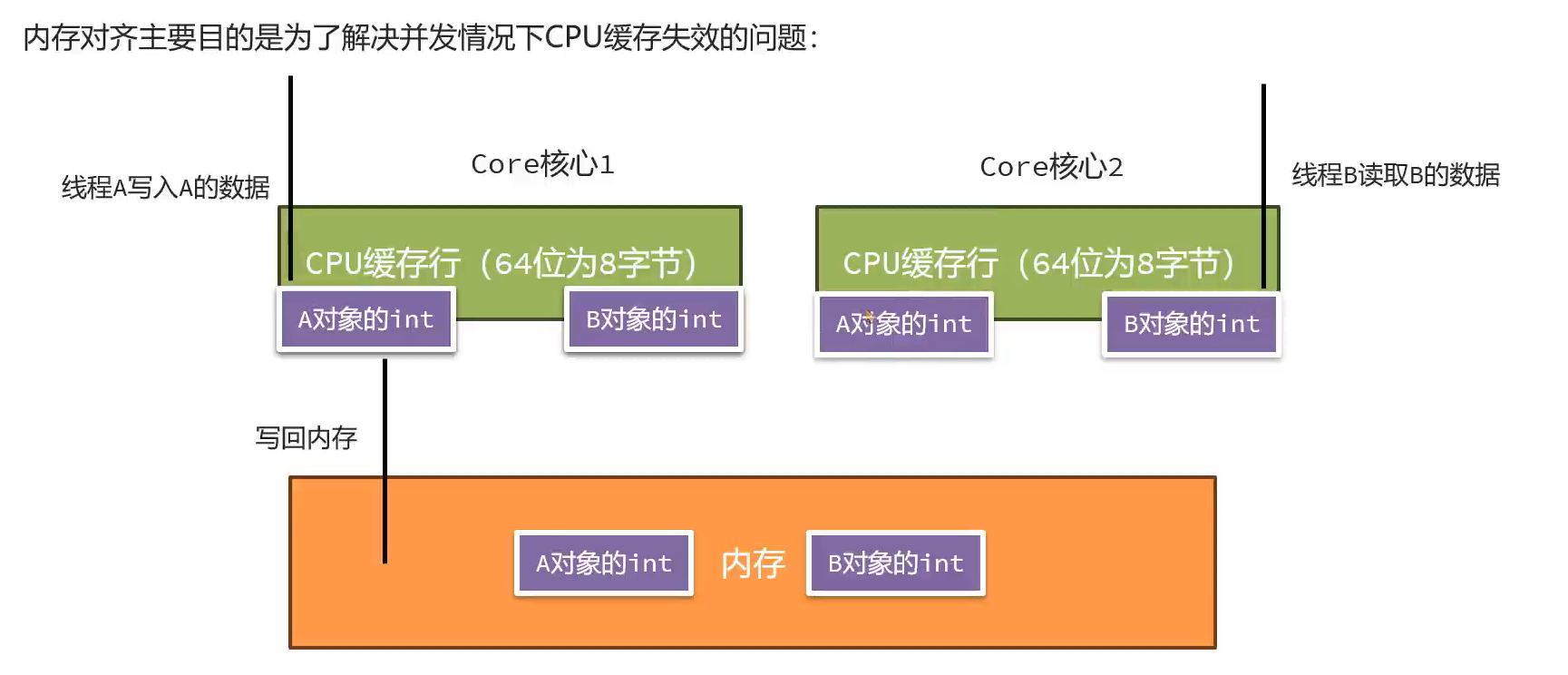
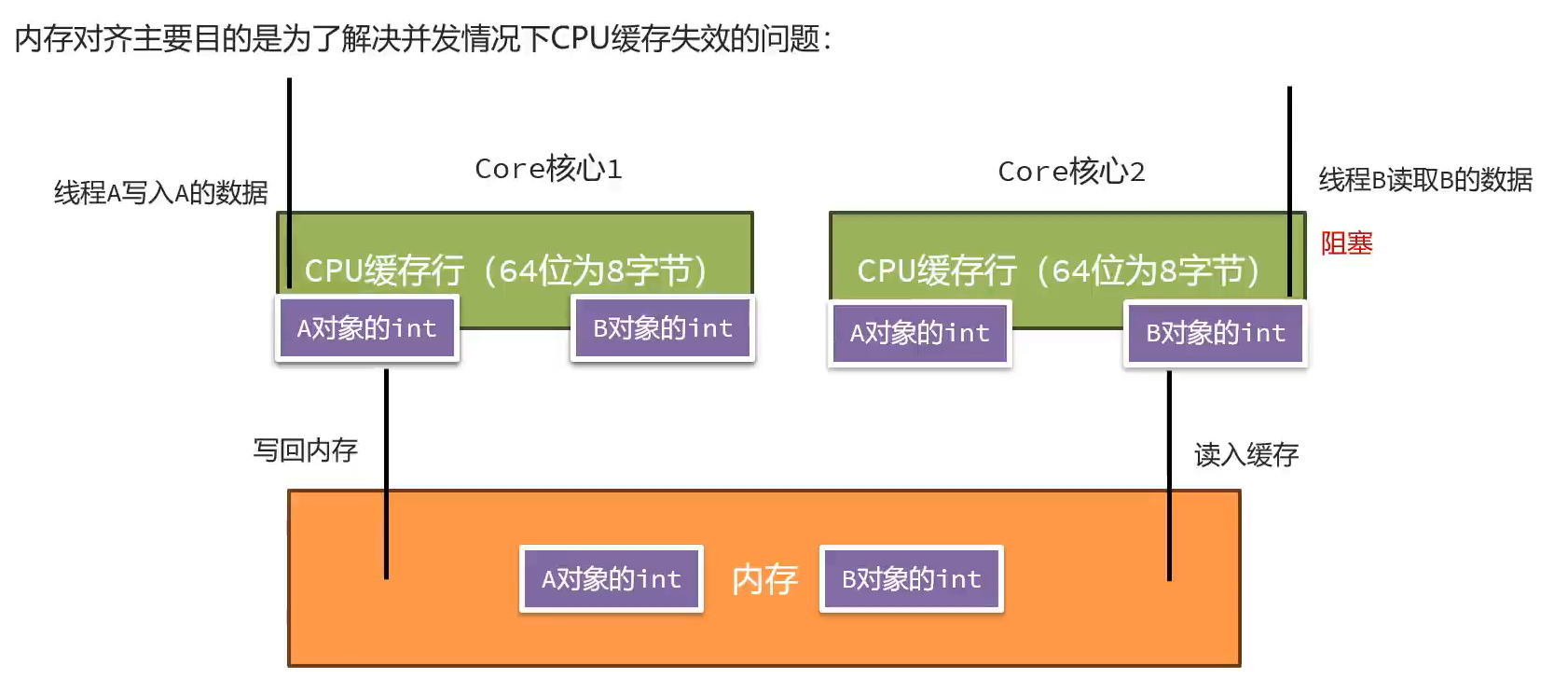
解决就是内存对齐
5.方法区
1.方法区介绍
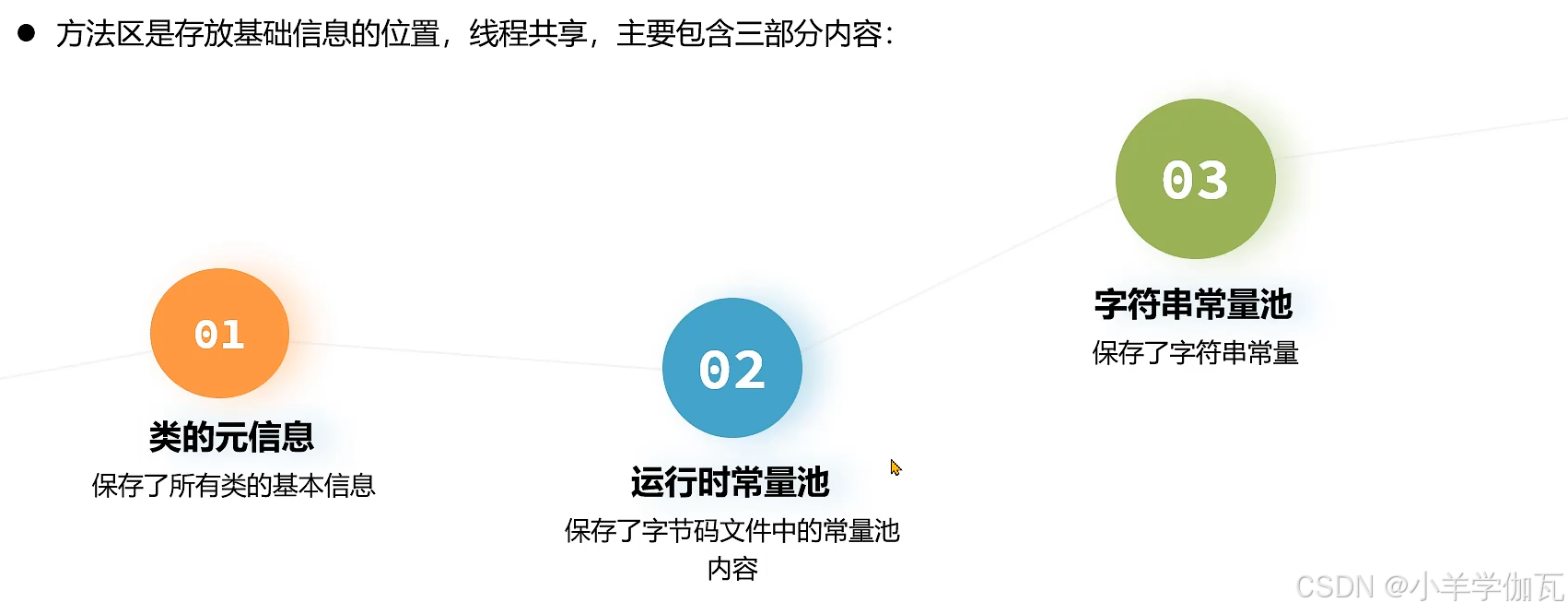
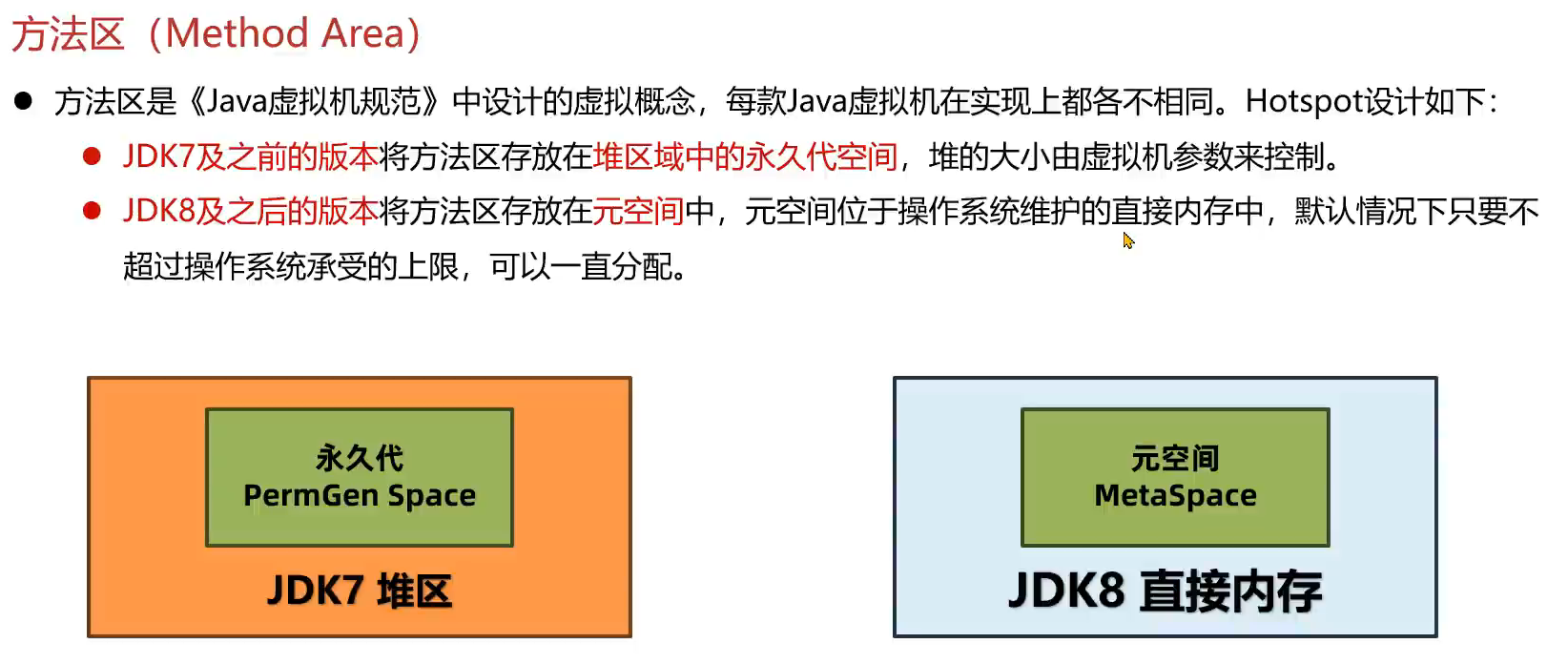
2.类的元信息
3.运行时常量池和常量池
4.字符串常量池(StringTable)
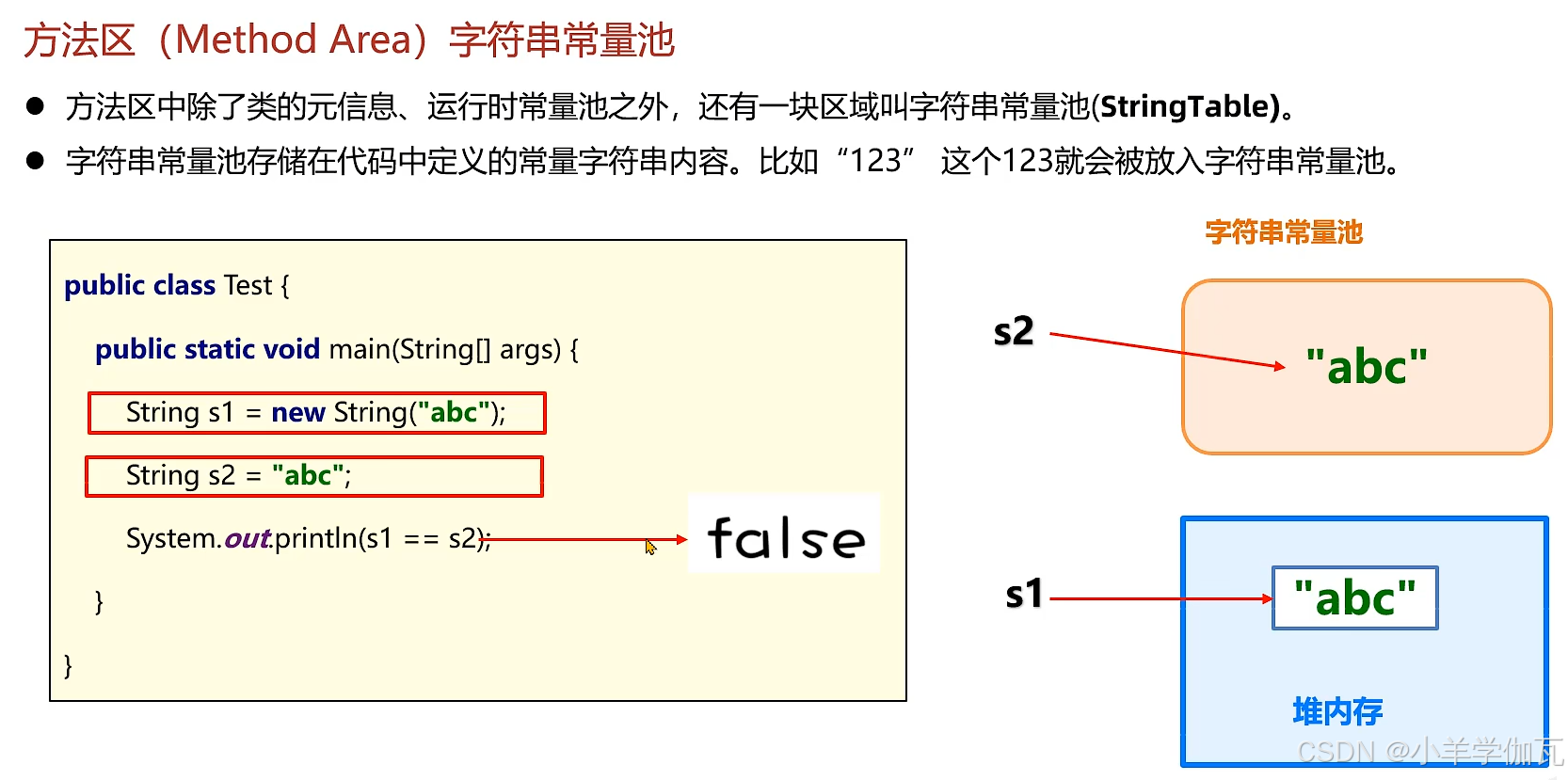
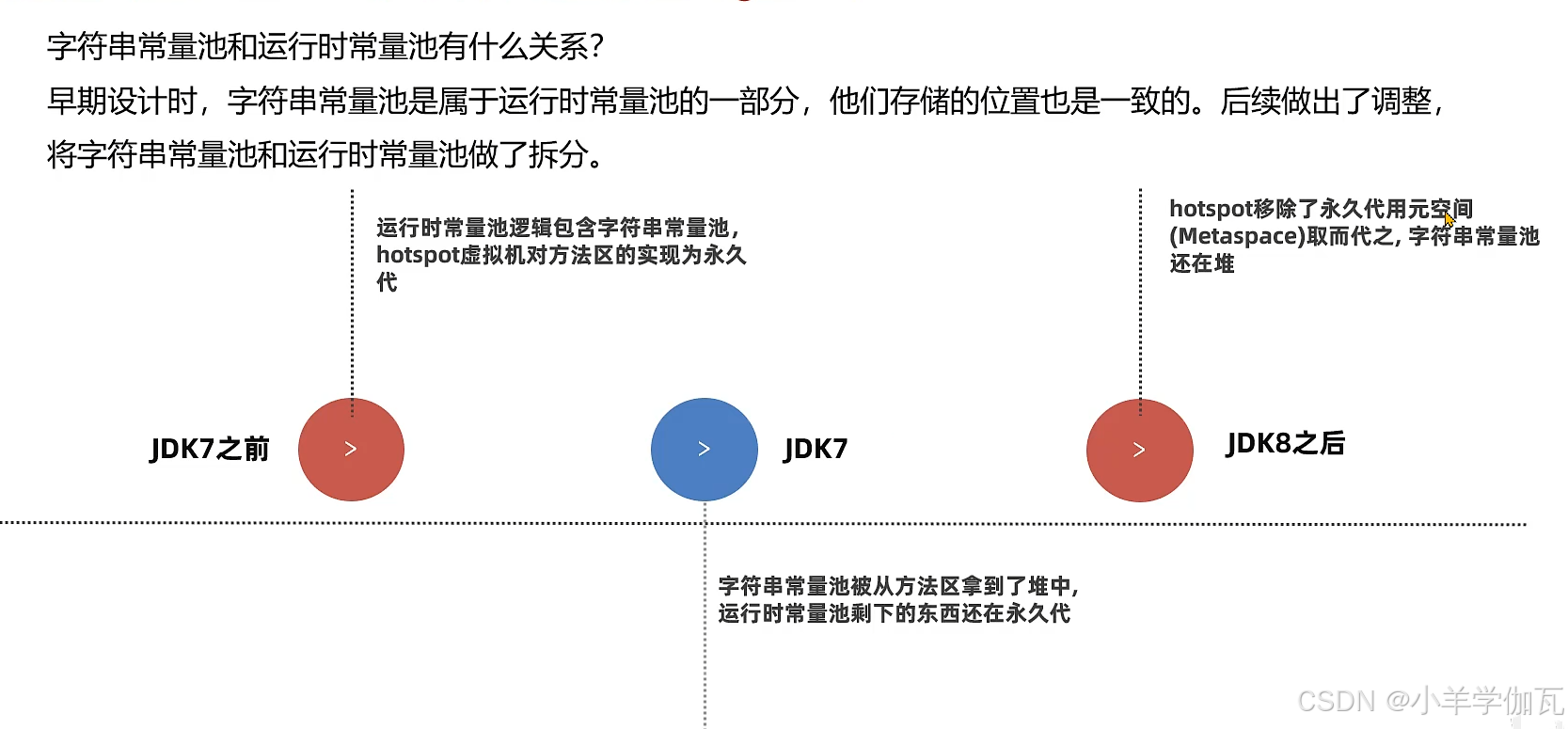
1.题目


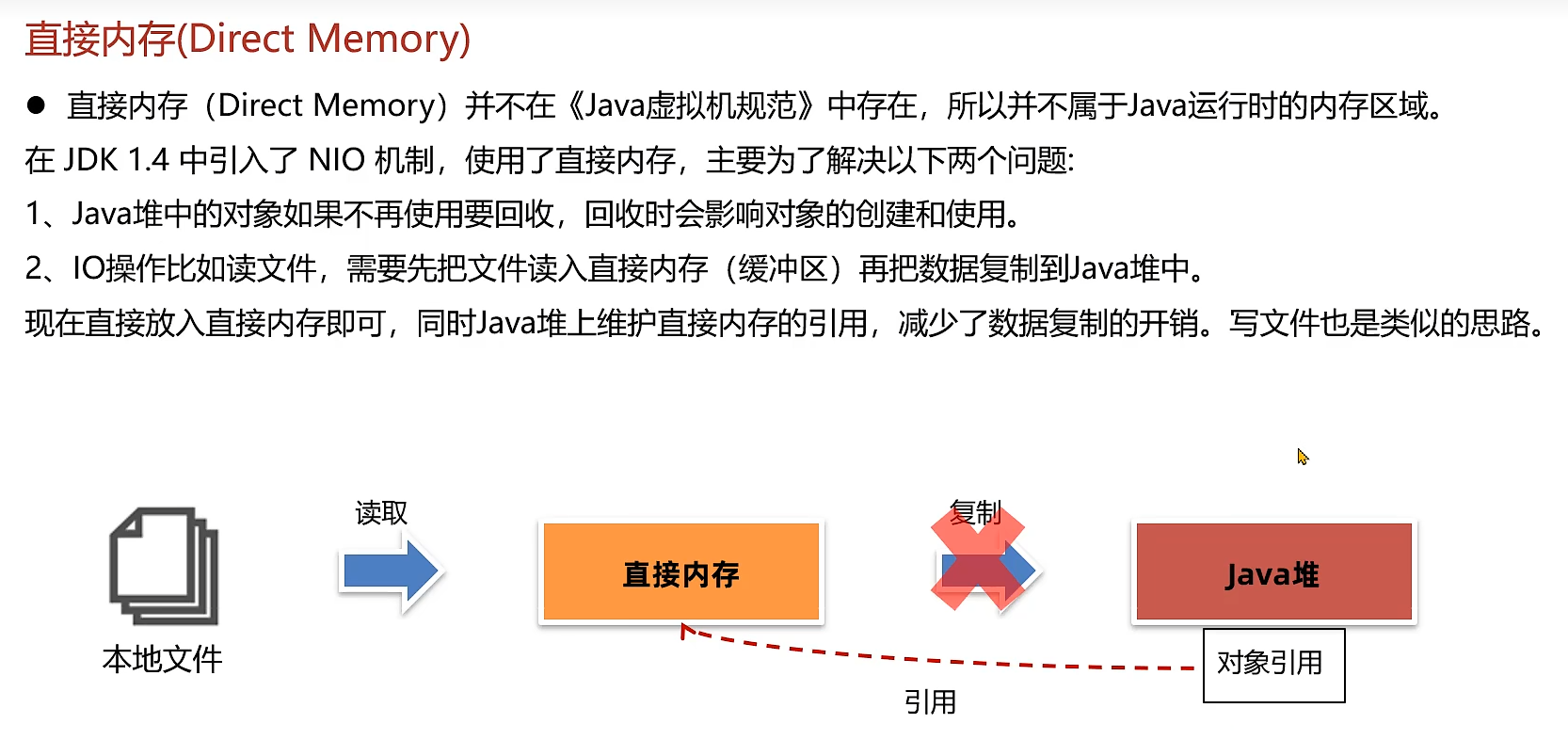
6.直接内存
五.垃圾回收
1.方法区的回收

2.堆回收

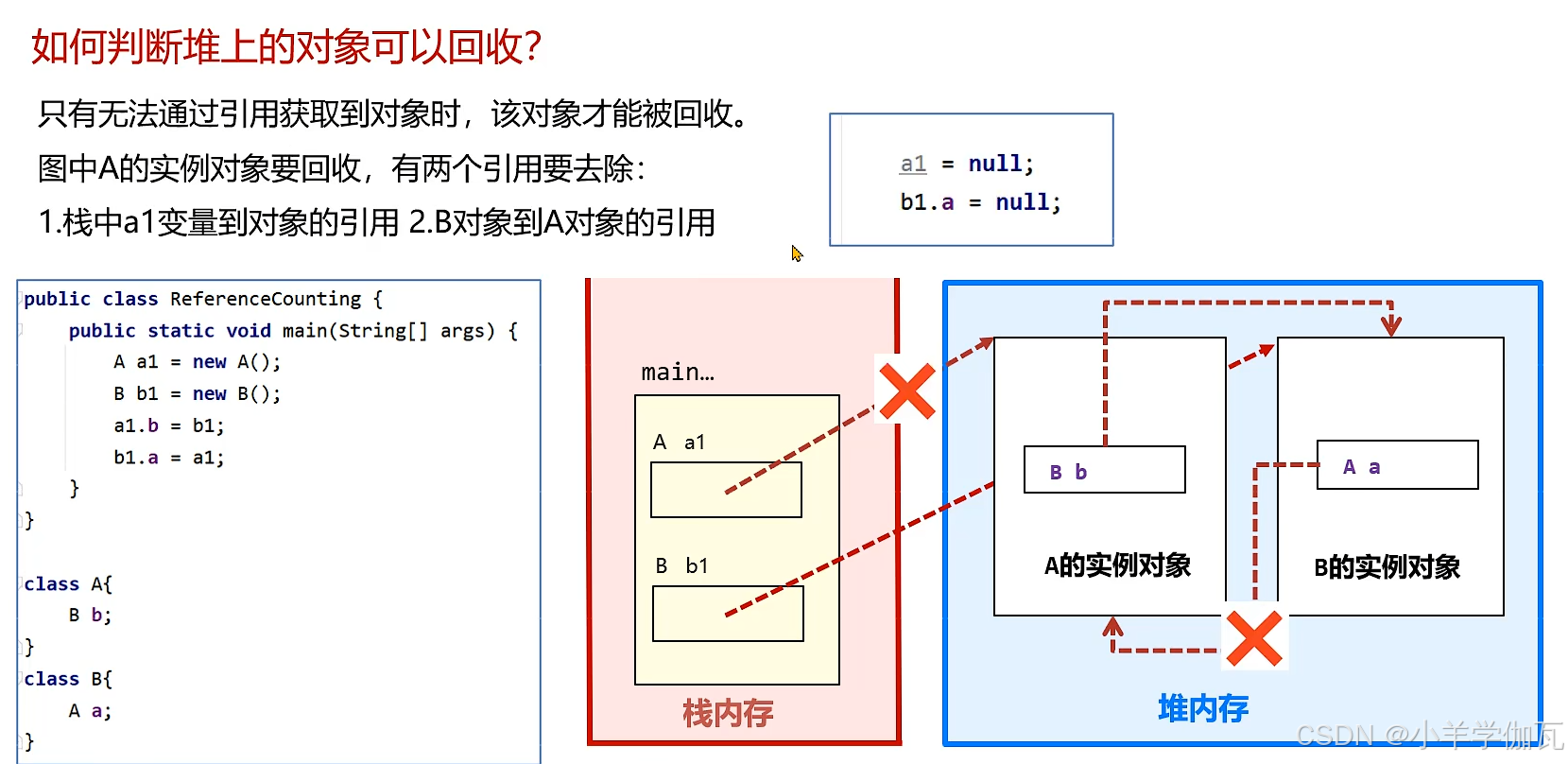
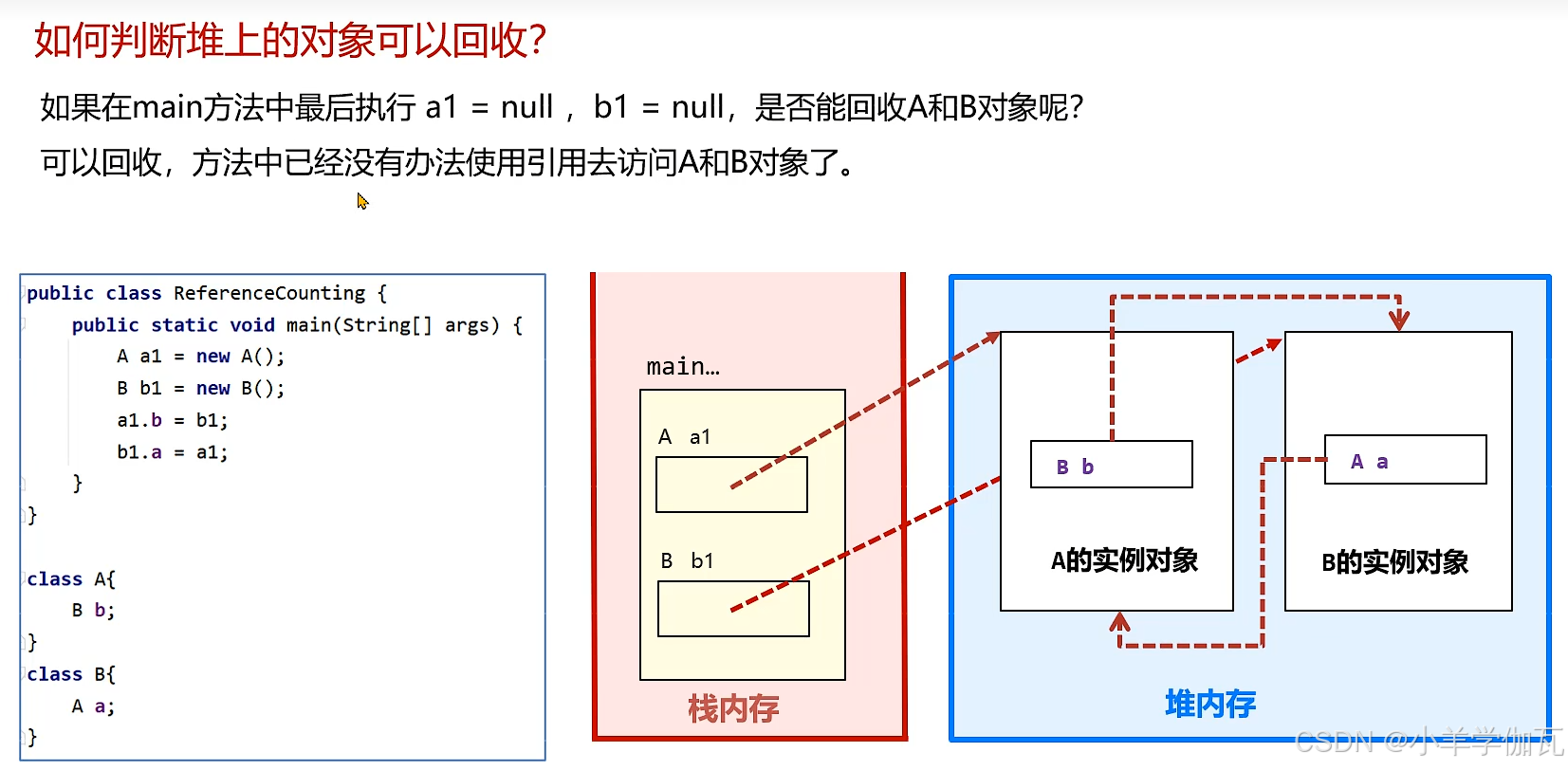
1.引用计数法
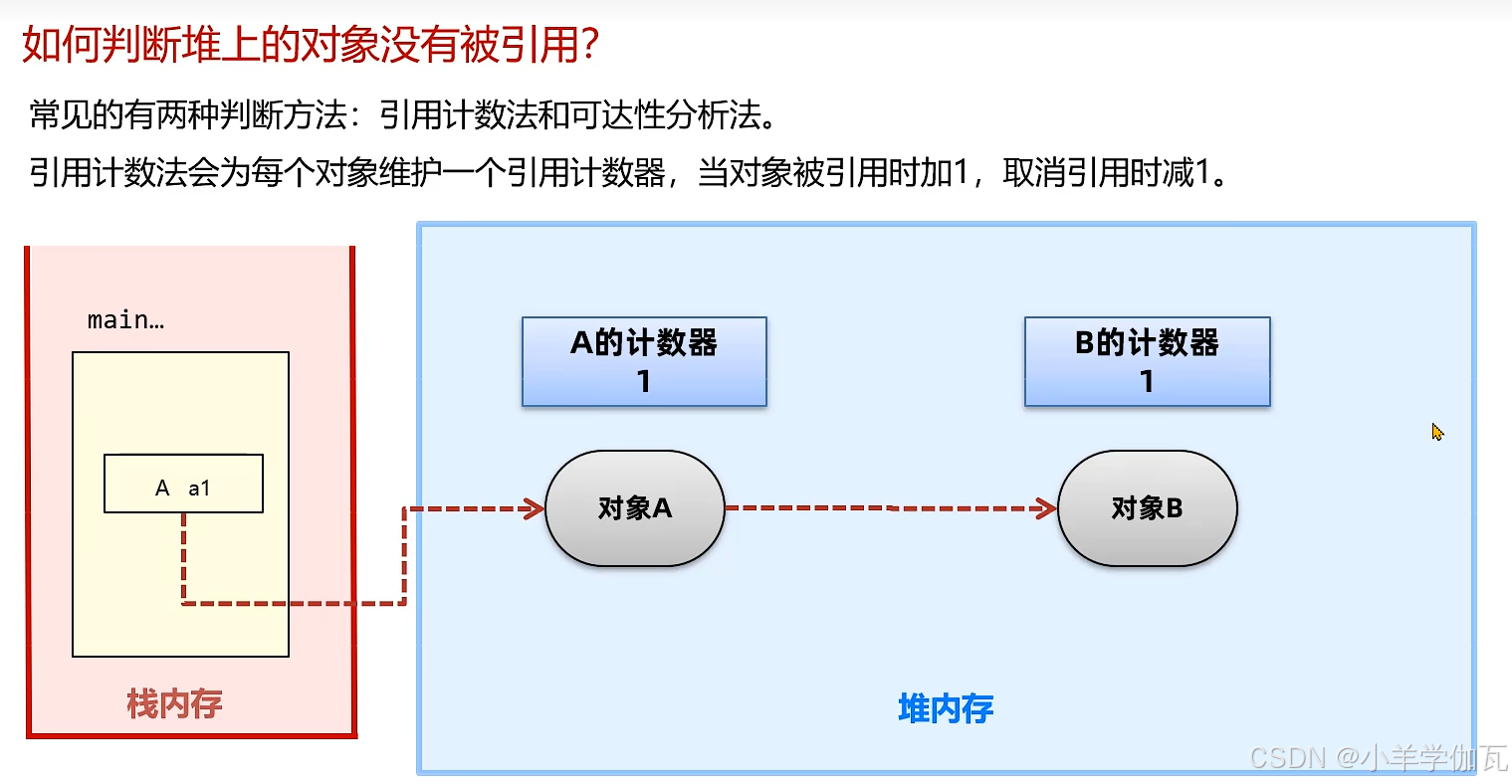
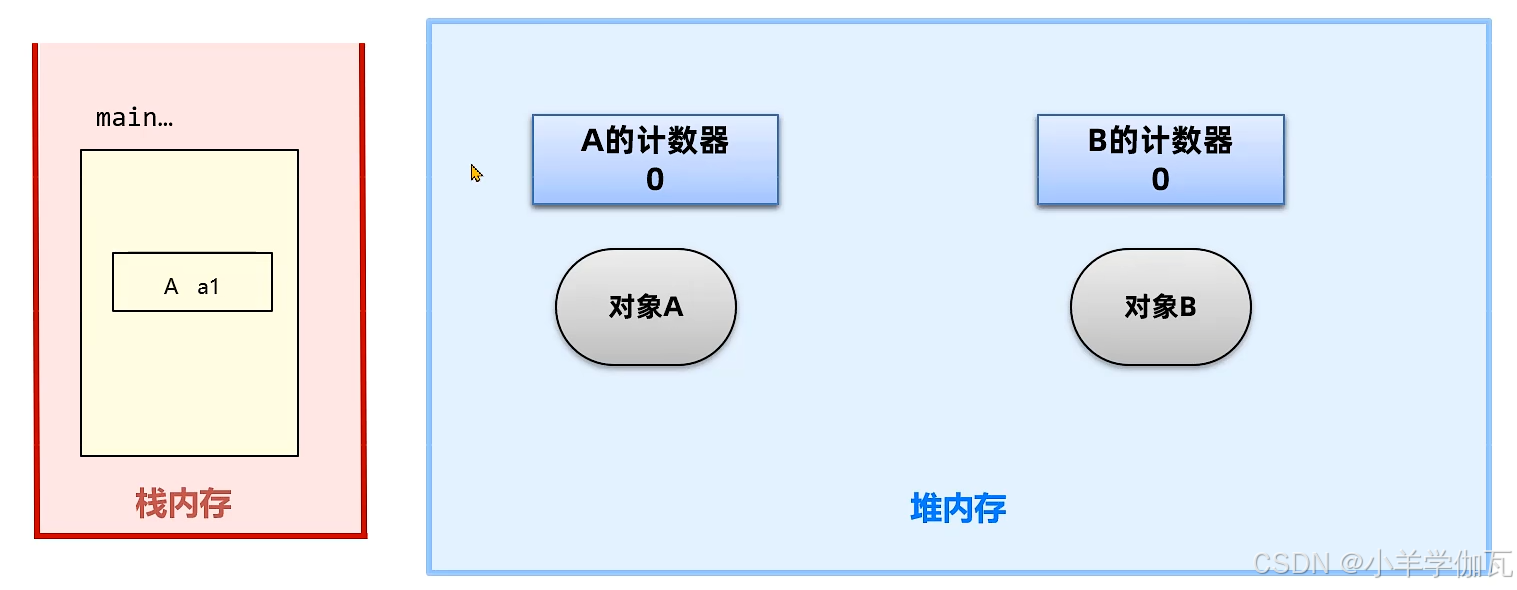
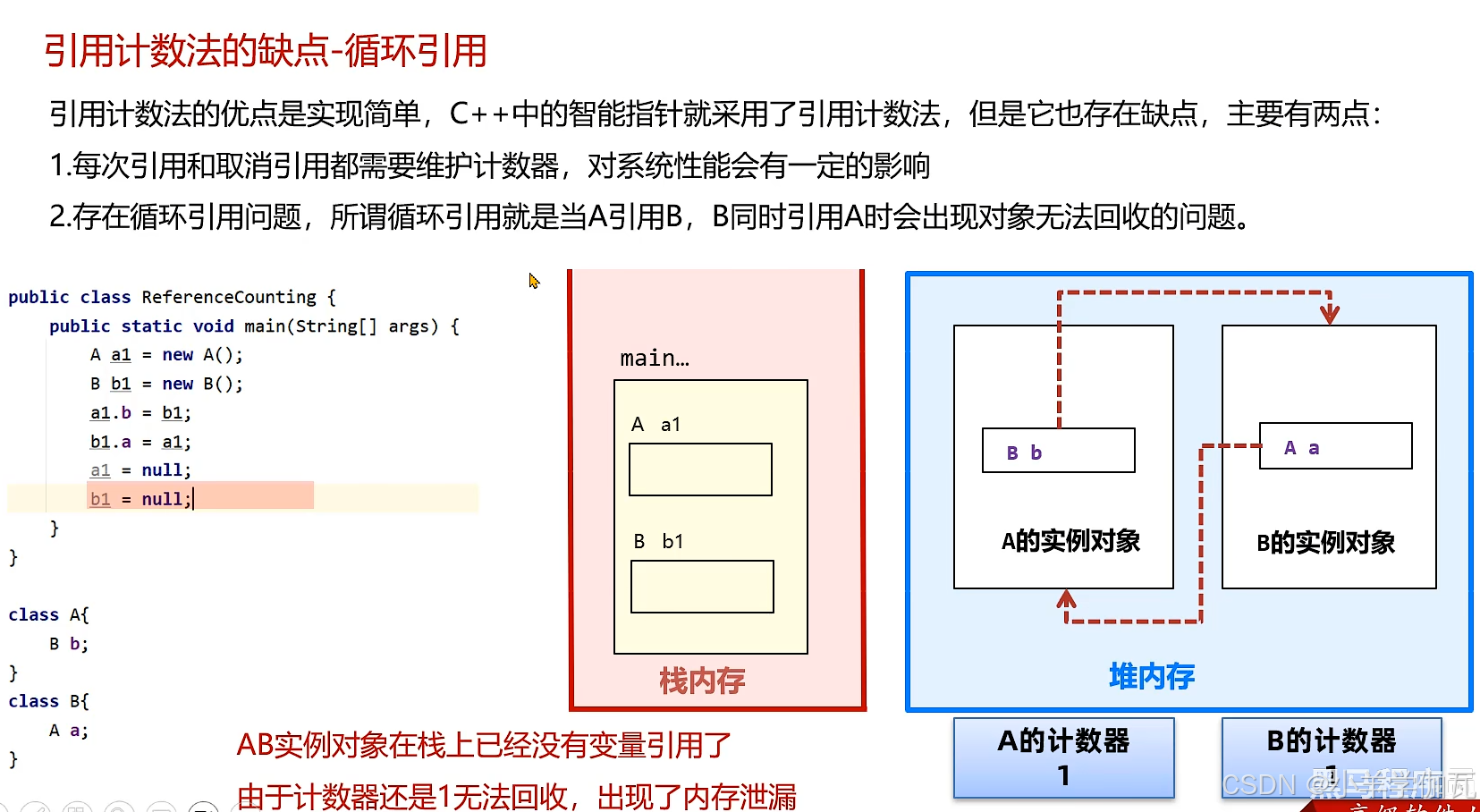
2.****可达性分析***(GC Root)
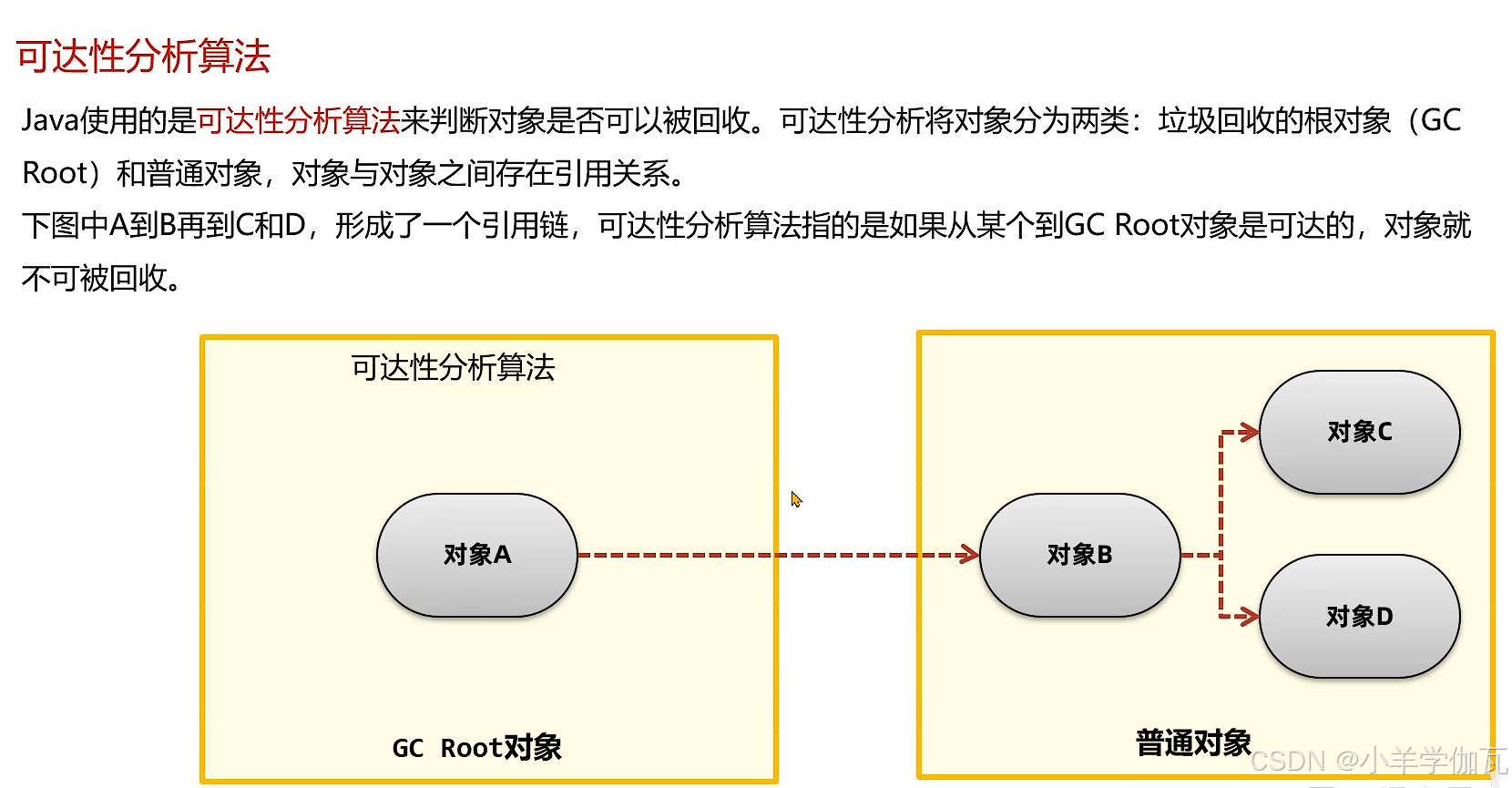

a.一些活动线程
线程内会涉及到一些方法的调用,在栈帧中就存在着一些方法参数,局部变量等

b.一些核心类(由启动类加载器加载的一些类)
如Object,string等等
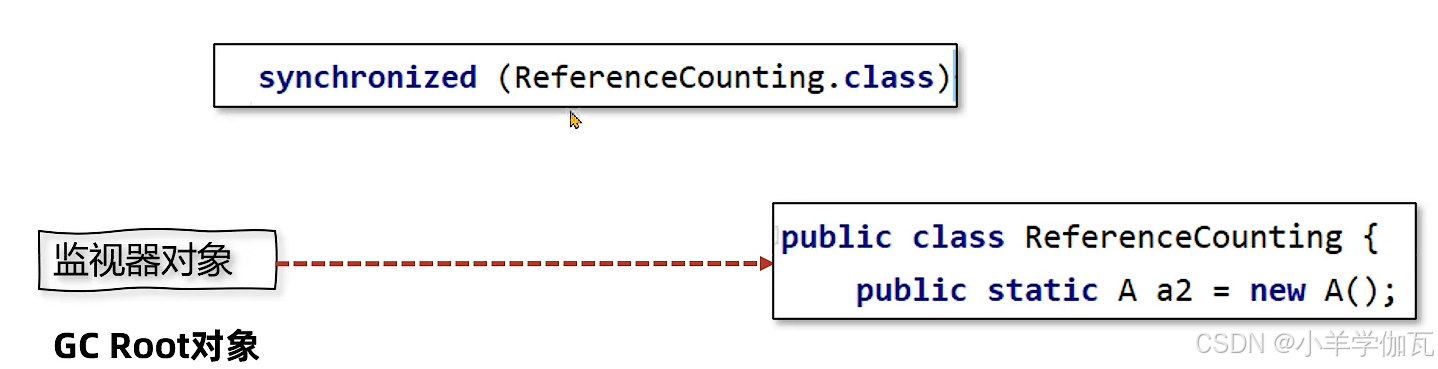
c.被锁住的对象 synchronized(对象)
3.五种对象引用
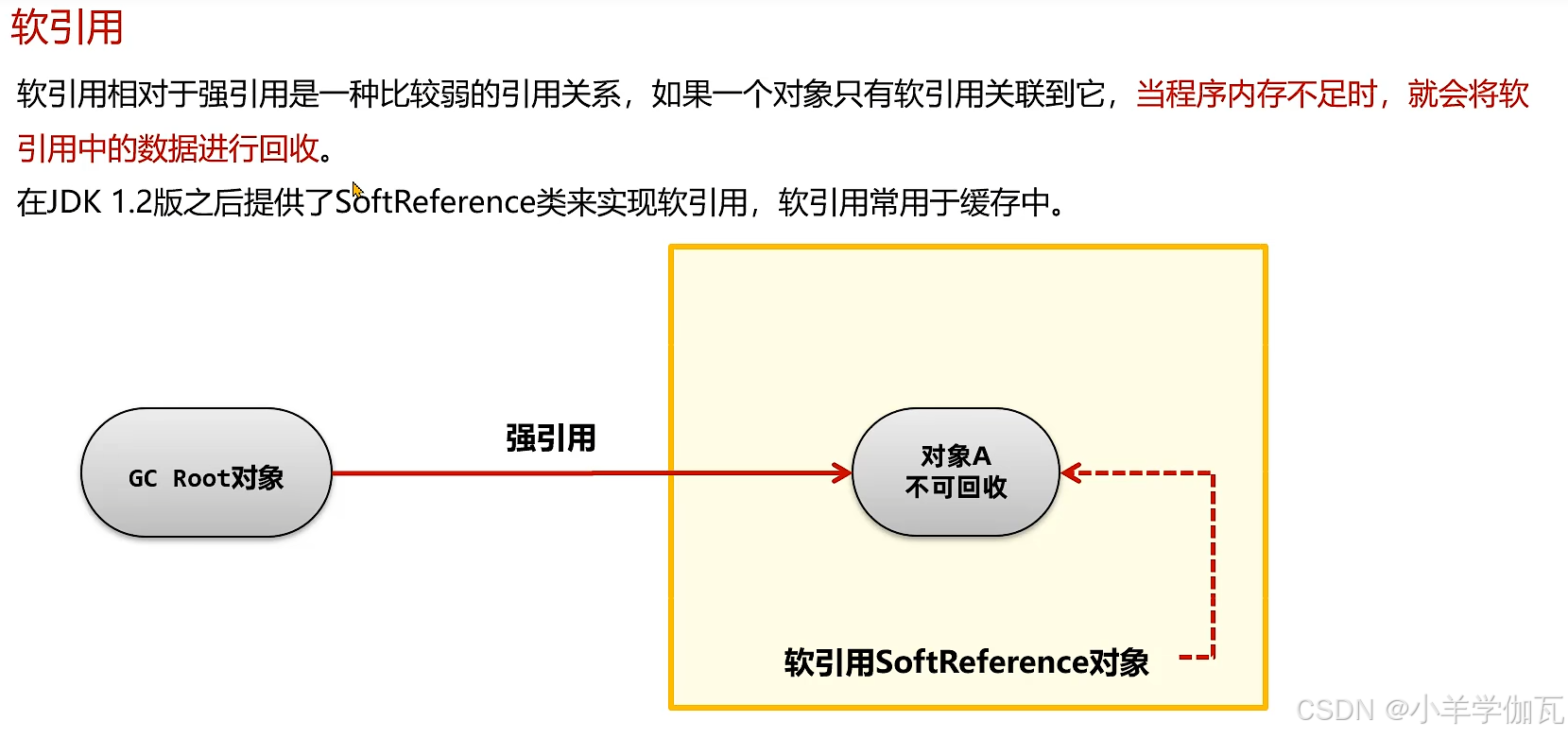
1.软引用

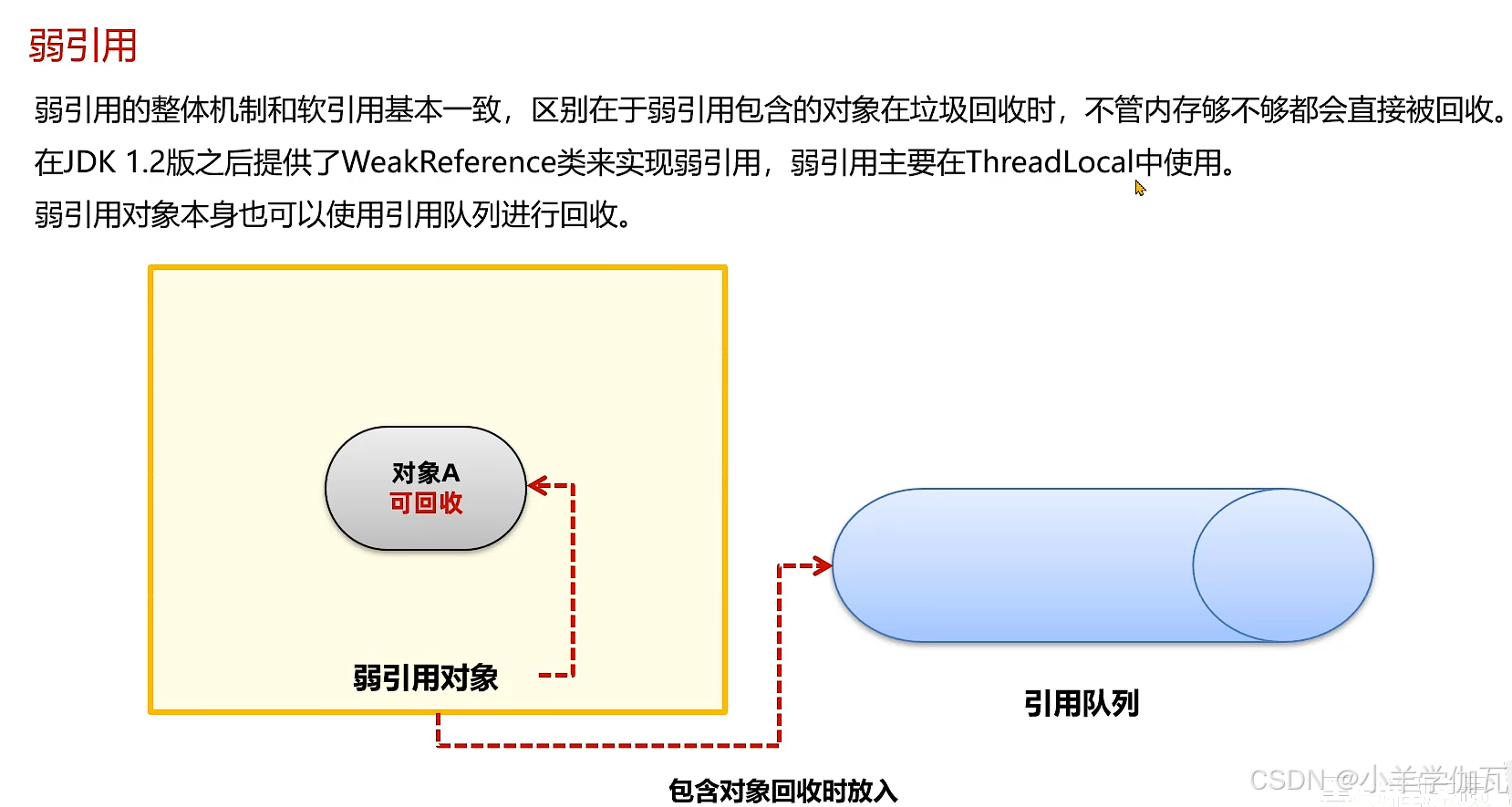
2.弱引用
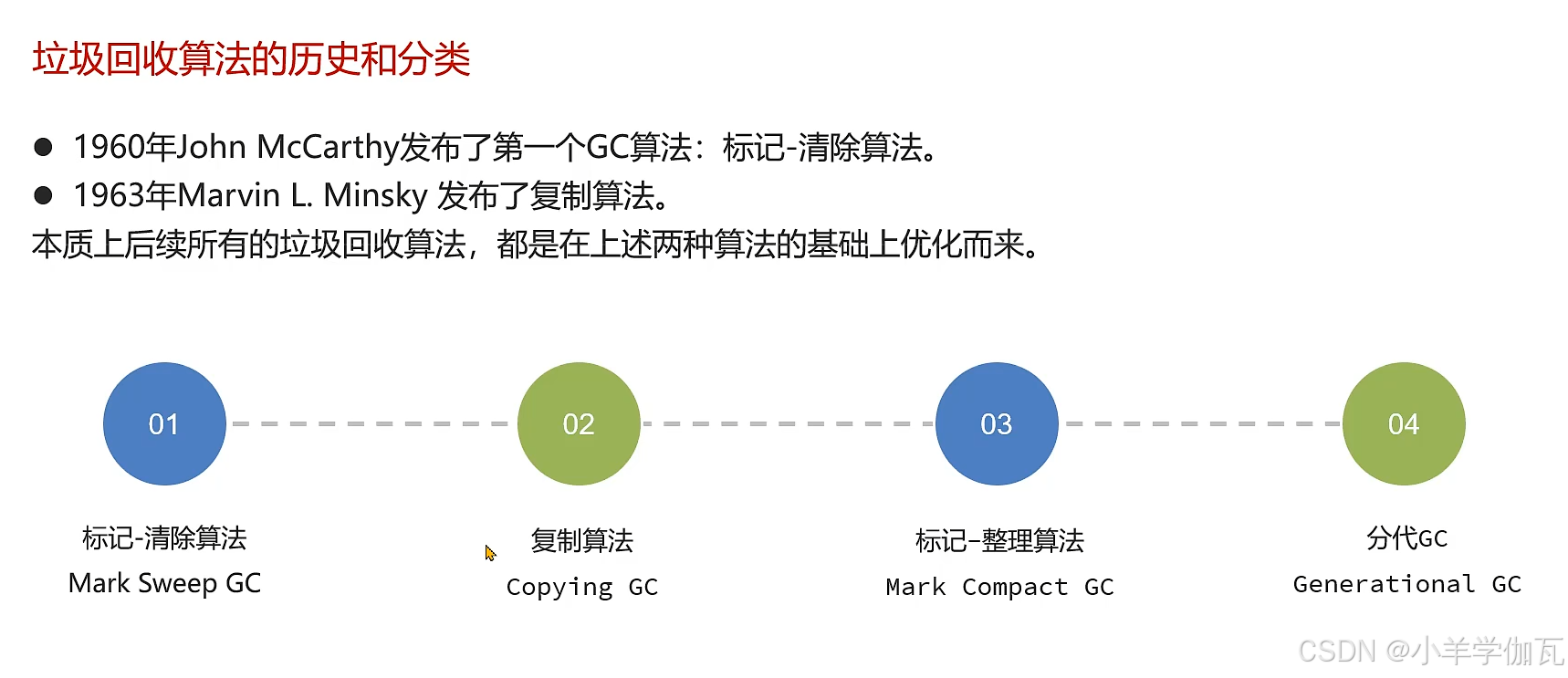
4.垃圾回收算法

1.算法的评价标准
1.吞吐量

2.最大暂停时间
3.堆使用效率

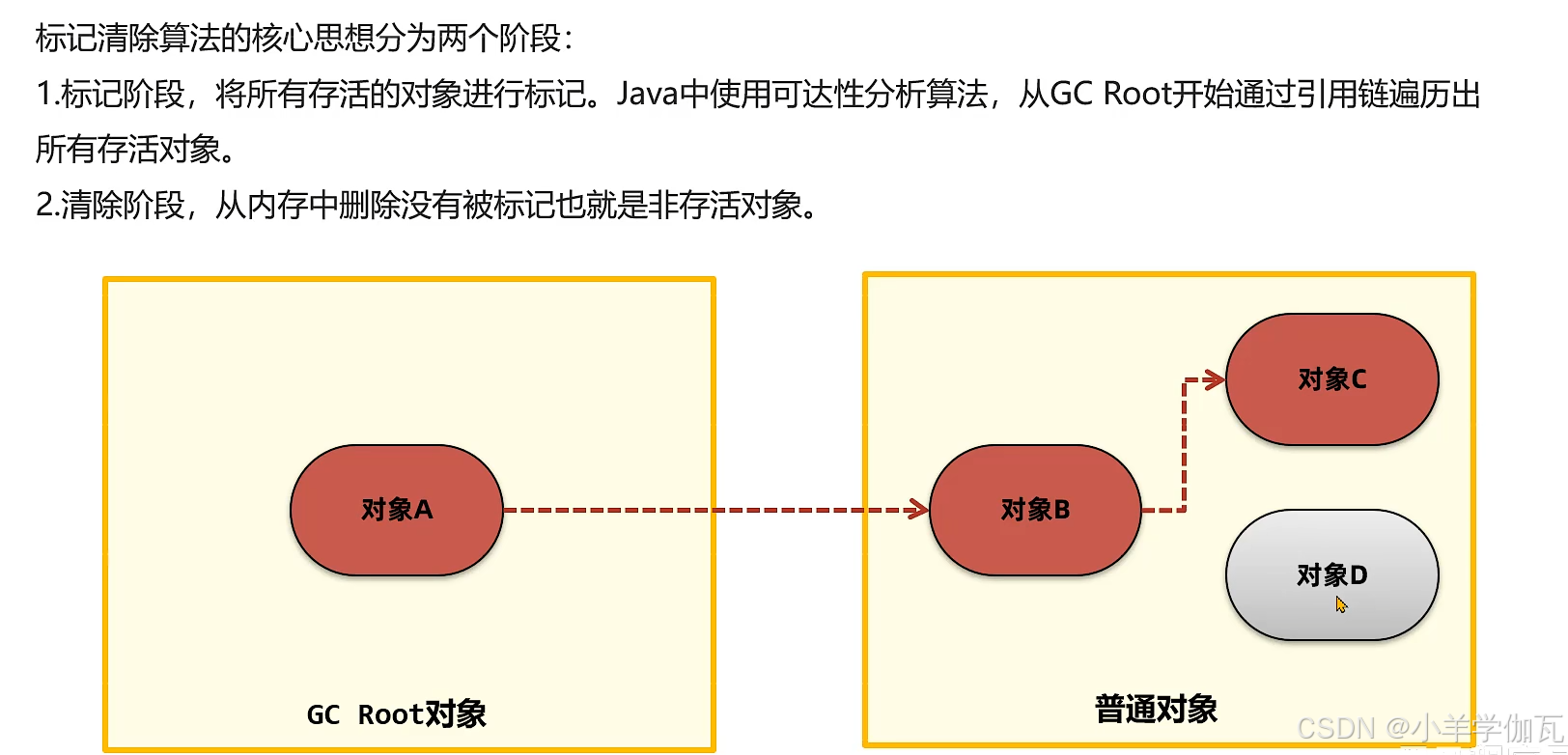
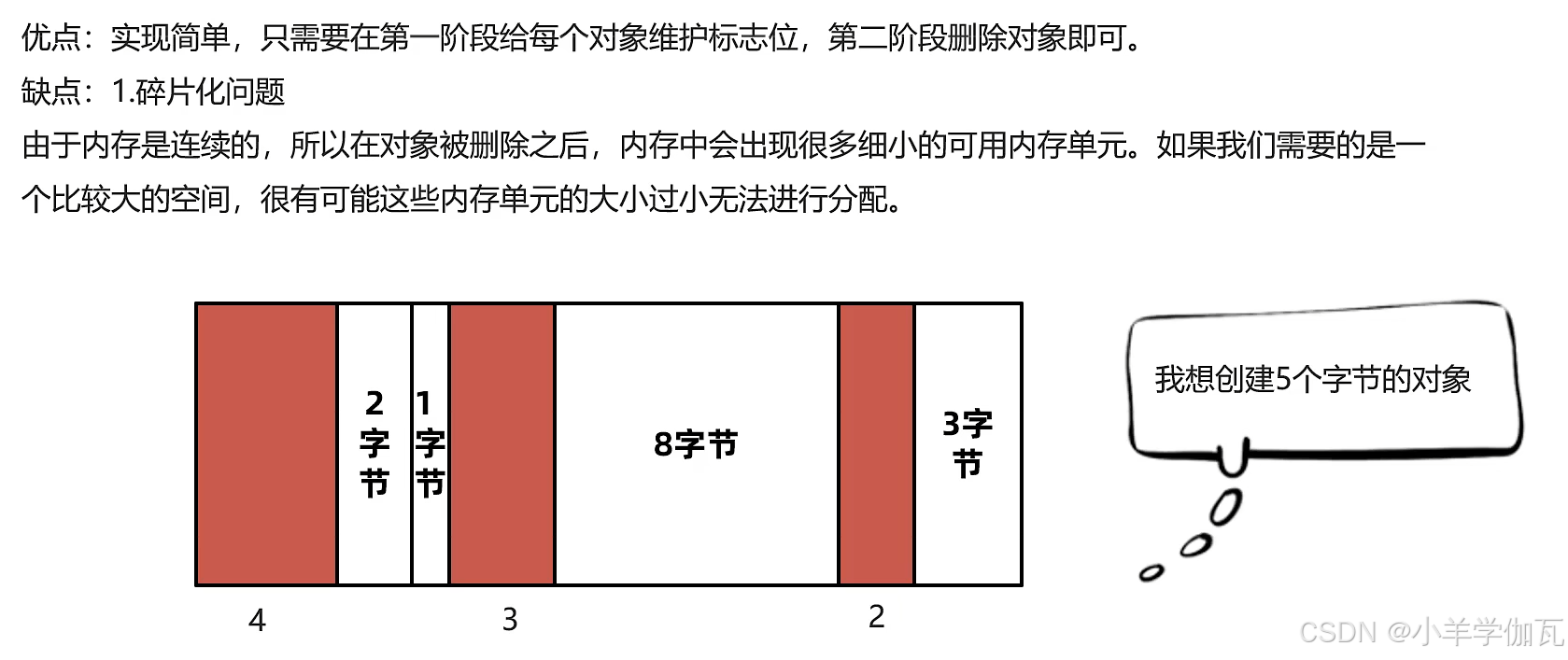
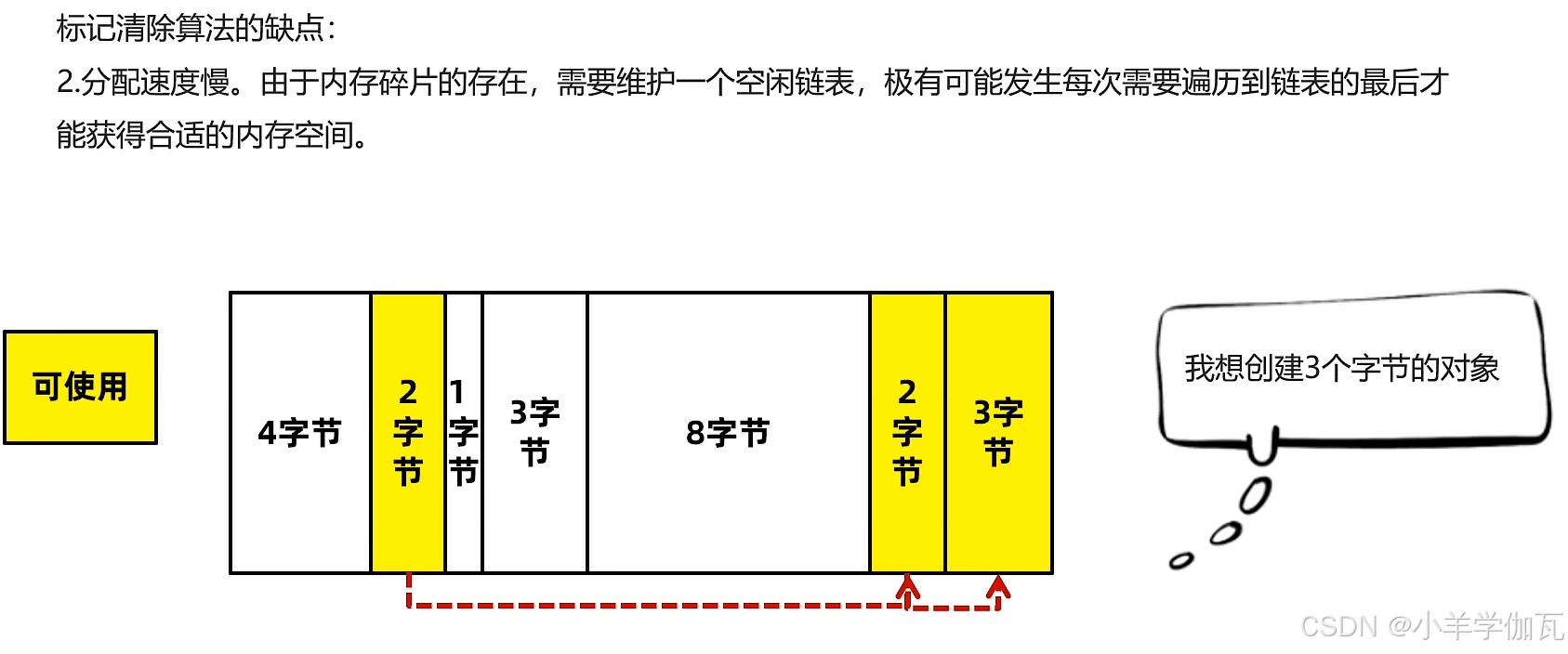
2.标记清除算法
3.复制算法
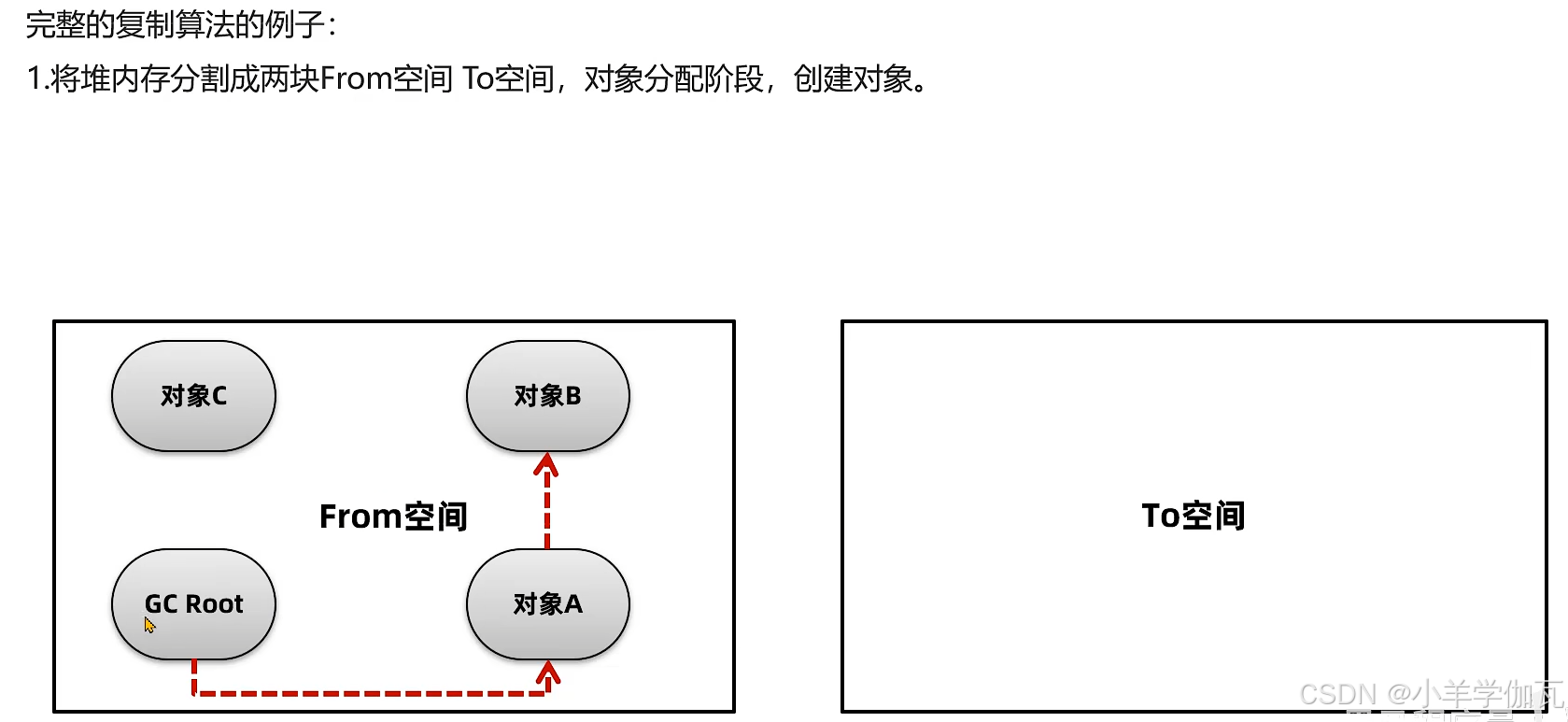
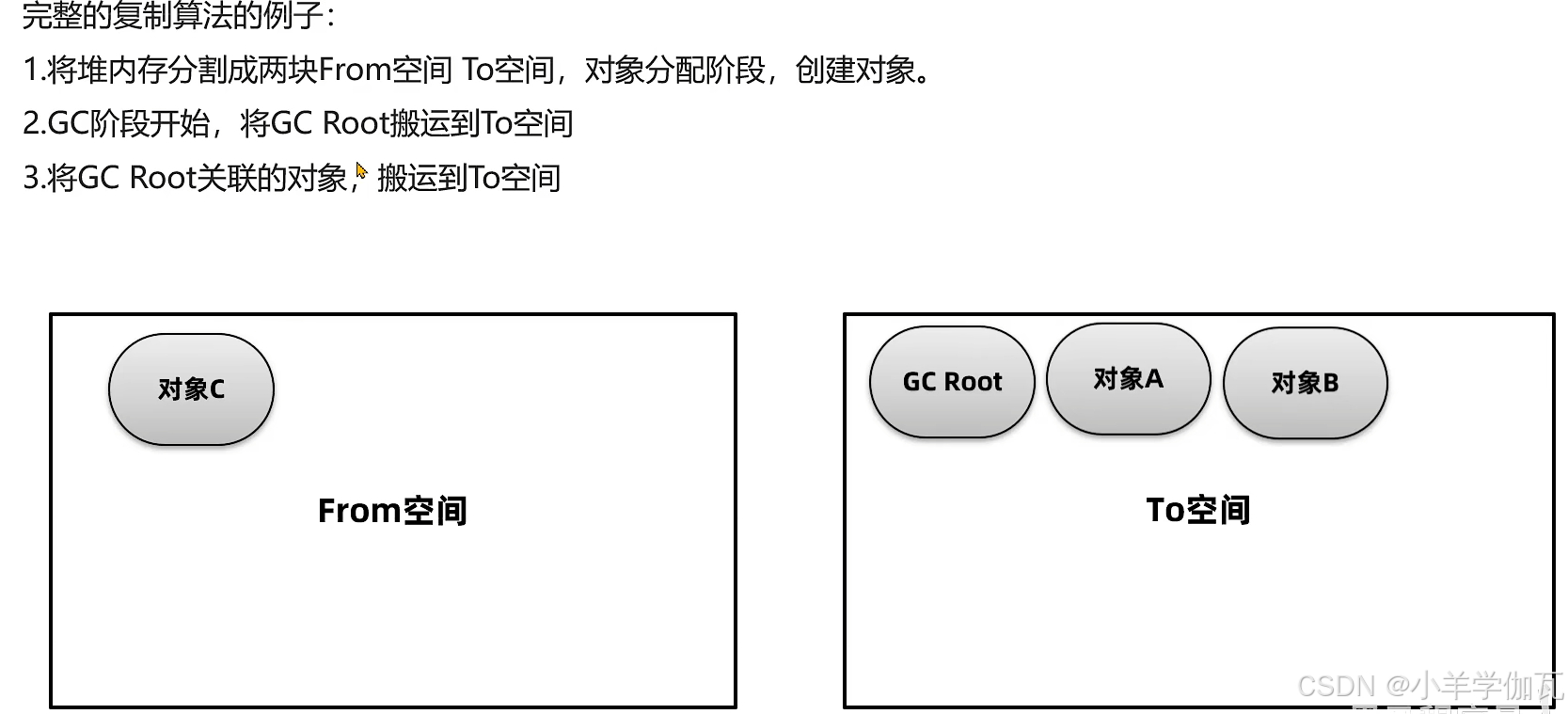


4.标记整理算法
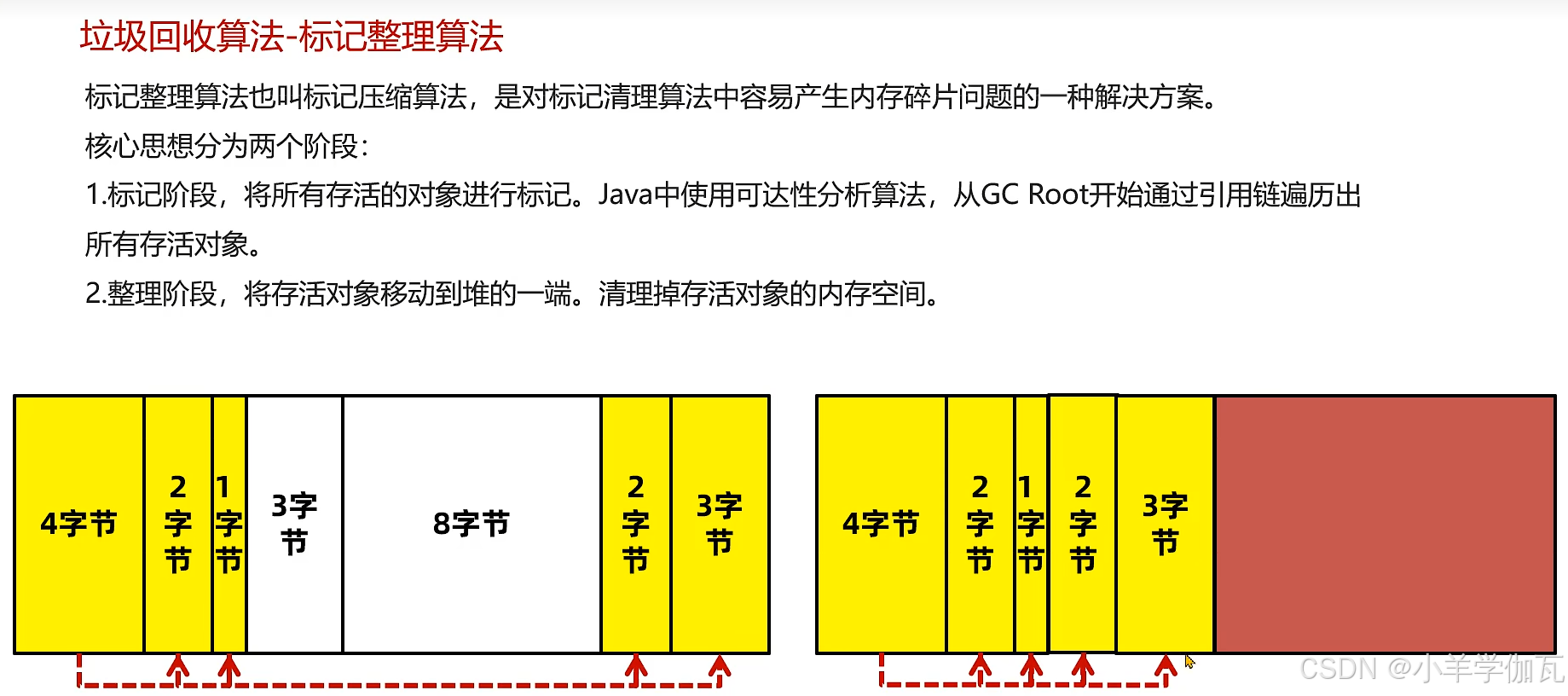

5.分代GC
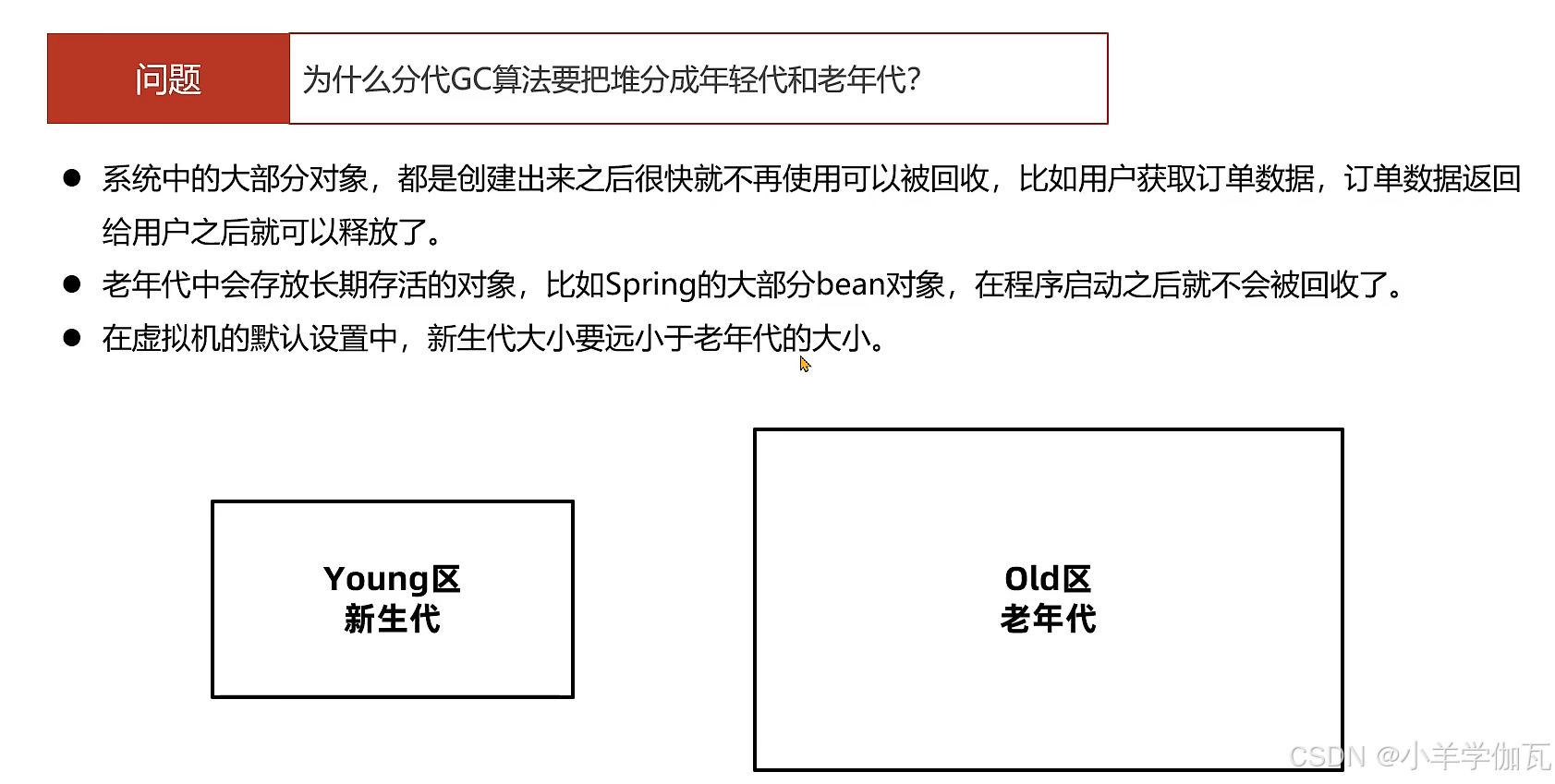

1.分成两个代程序员可以灵活调整年轻代和老年代的比例去适配不同的应用程序,如何用户的访问量很多,如去访问订单数据,如果新生代设置的很小,大量的对象都会进入新生代,频繁触发minor GC,有些对象还会进入老年代,可能这些对象的生命周期比较短,不希望它去占用老年代的位置,希望它在新年代就被回收而不进入老年代。
2.采用不同的回收算法,新生代采用复制算法,不会出现内存碎片而且吞吐量较高。而老年代空间一般较大,就不会采用复制算法,由于复制算法只能使用堆内存大的一半,所以使用标记清除和整理算法,但会(清除)产生内存碎片,(整理)停顿时间也较长。
3.只要新生代能够满足对象的分配,就可以只发生minor gc,而不会发生full gc,STW的时间就会变少。
核心就是降低垃圾回收对我们系统的影响!
5.垃圾回收器
1.年轻代——Serial垃圾回收器与老年代——SerialOld垃圾回收器
2.年轻代——ParNew垃圾回收器与老年代——CMS垃圾回收器
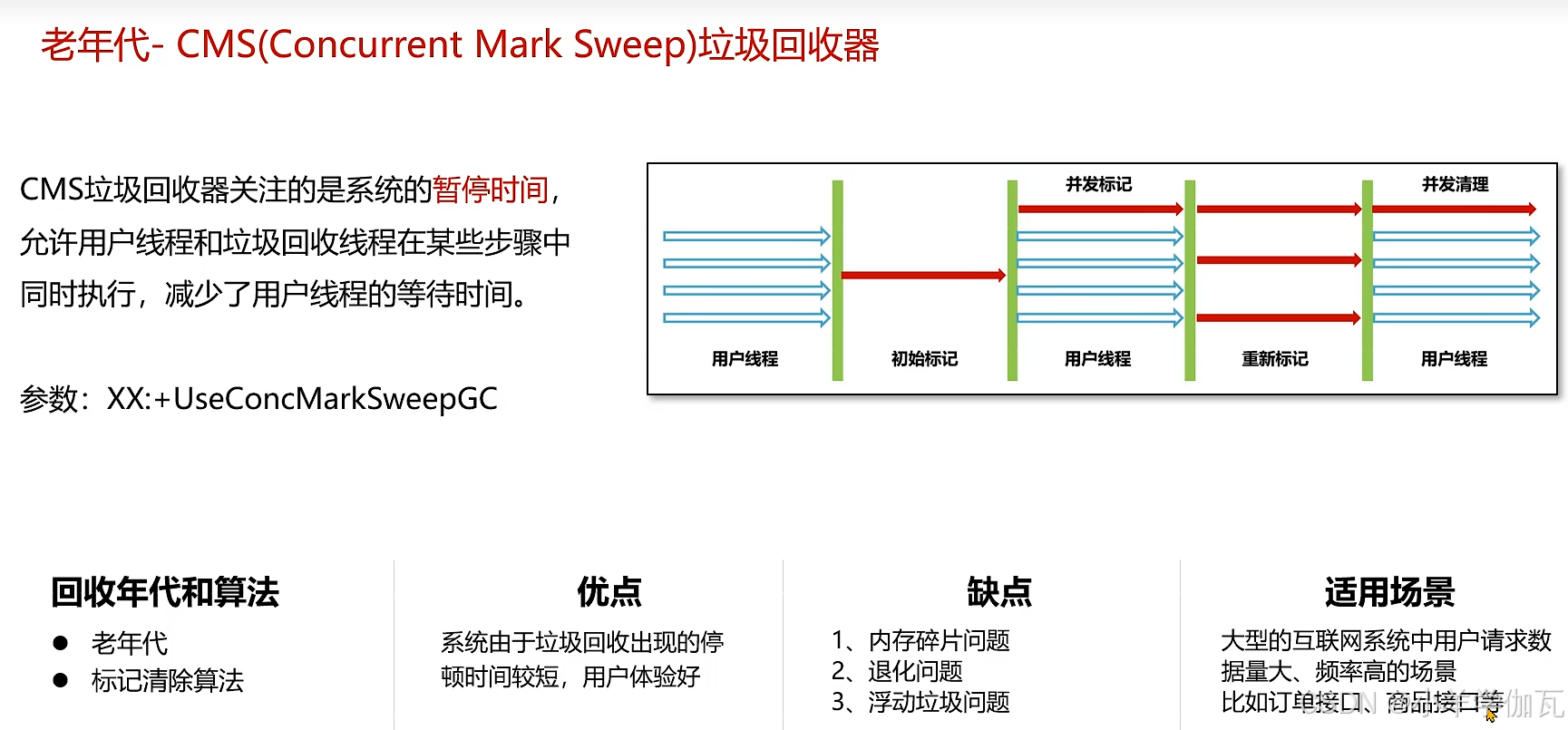
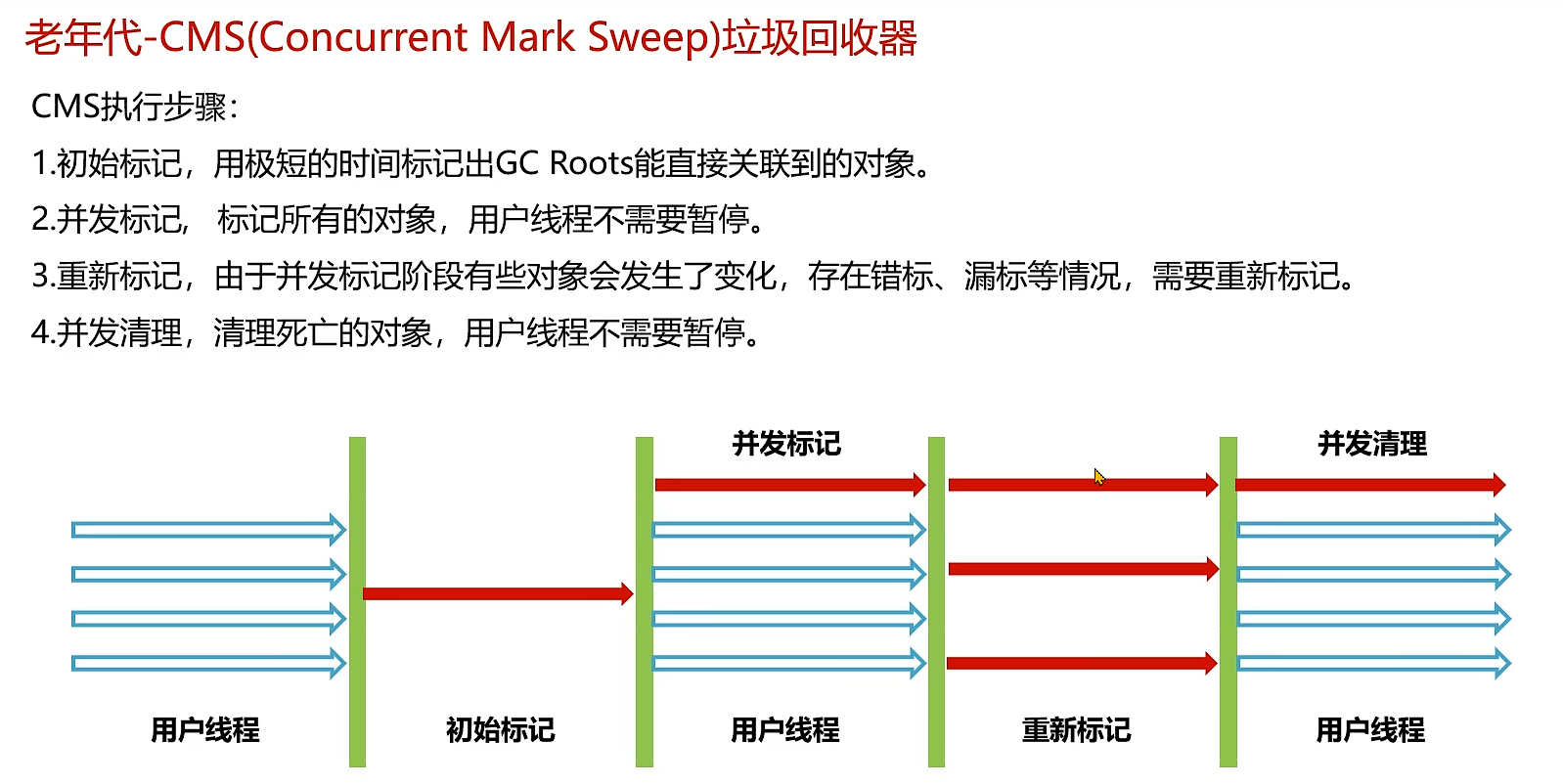
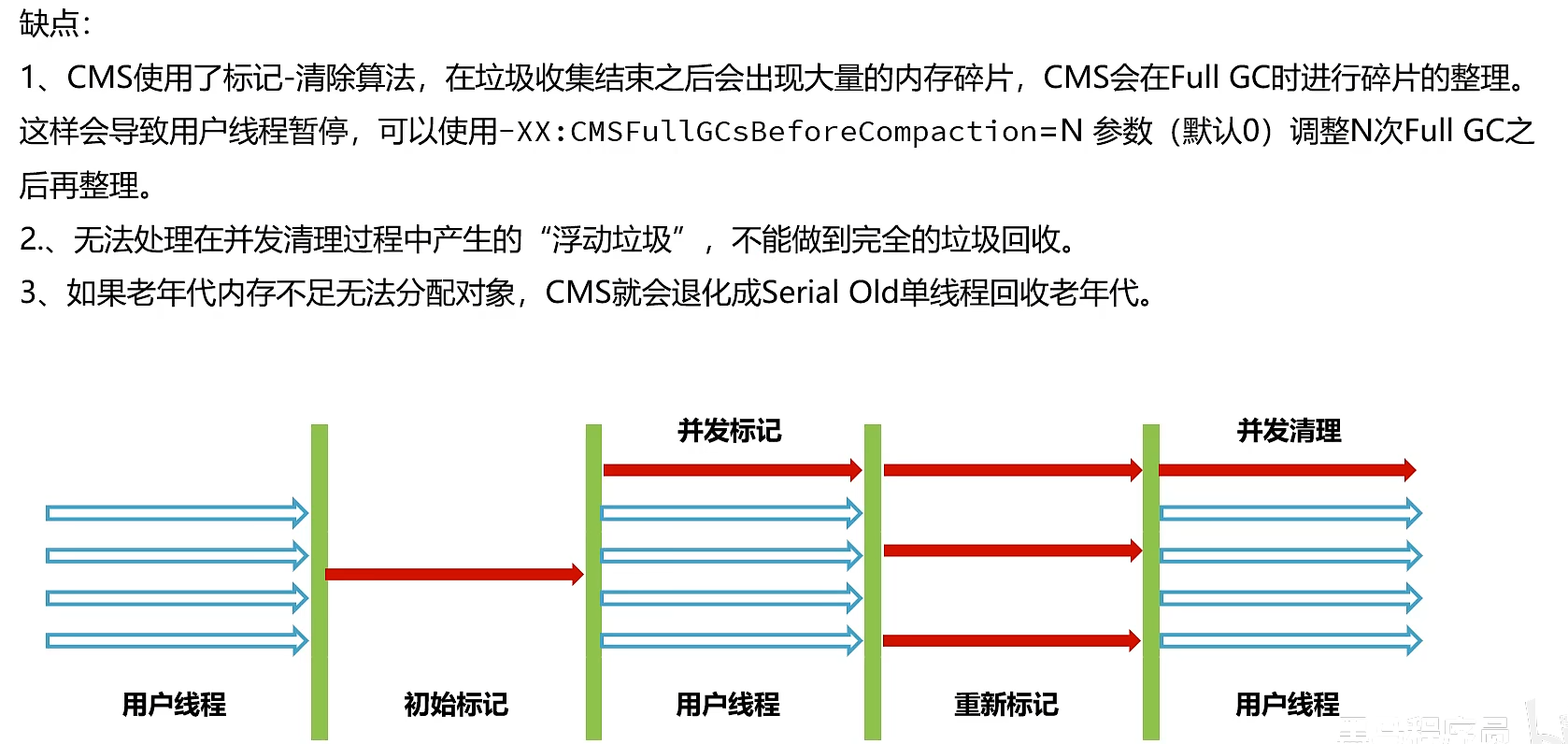
缺点:
1.使用了标记清除算法:会产生大量的内存碎片。导致无法分配稍微大一点的对象,触发full GC
2.由于在并发标记阶段,是和用户线程并发执行的,对象的引用可能出现变动,所以无法处理在这个过程中产生的“浮动垃圾”。
3.对于大对象是会直接放到old区,如果old区无法分配对象了,就会退化为单线程回收老年代,full gc(1 3条是一个意思)
3.G1垃圾回收器

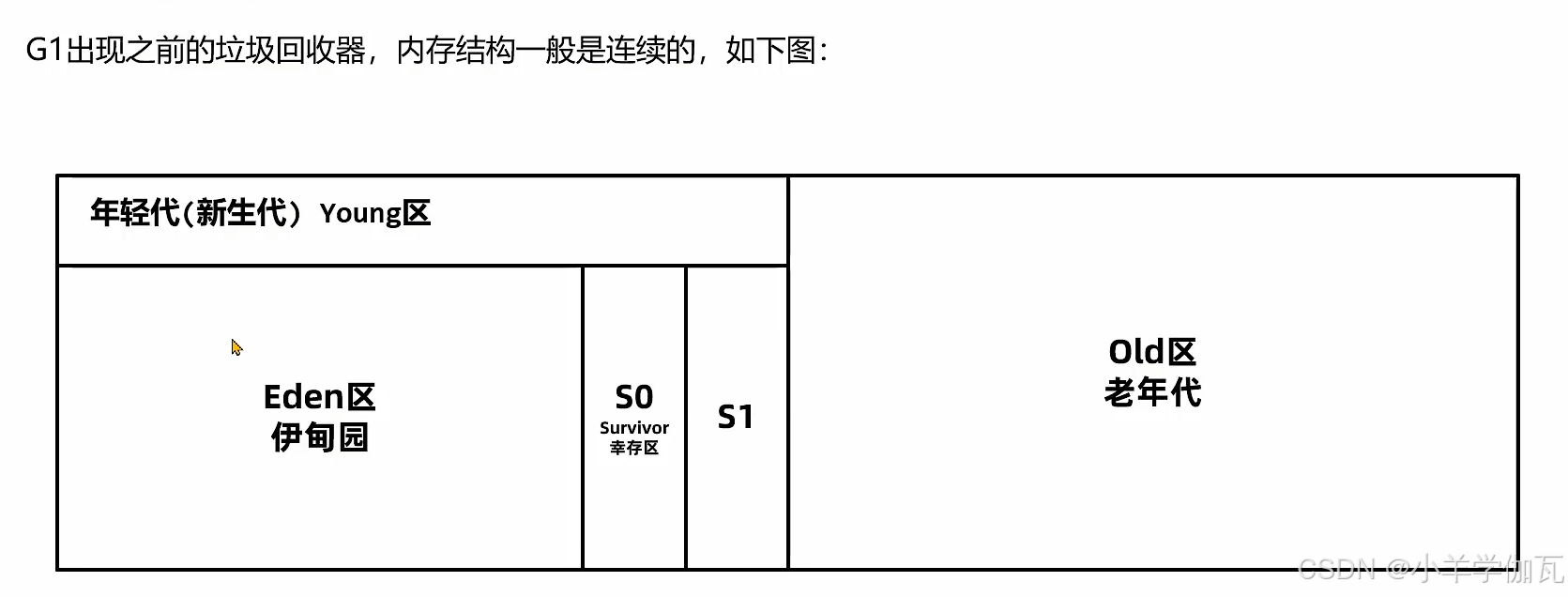
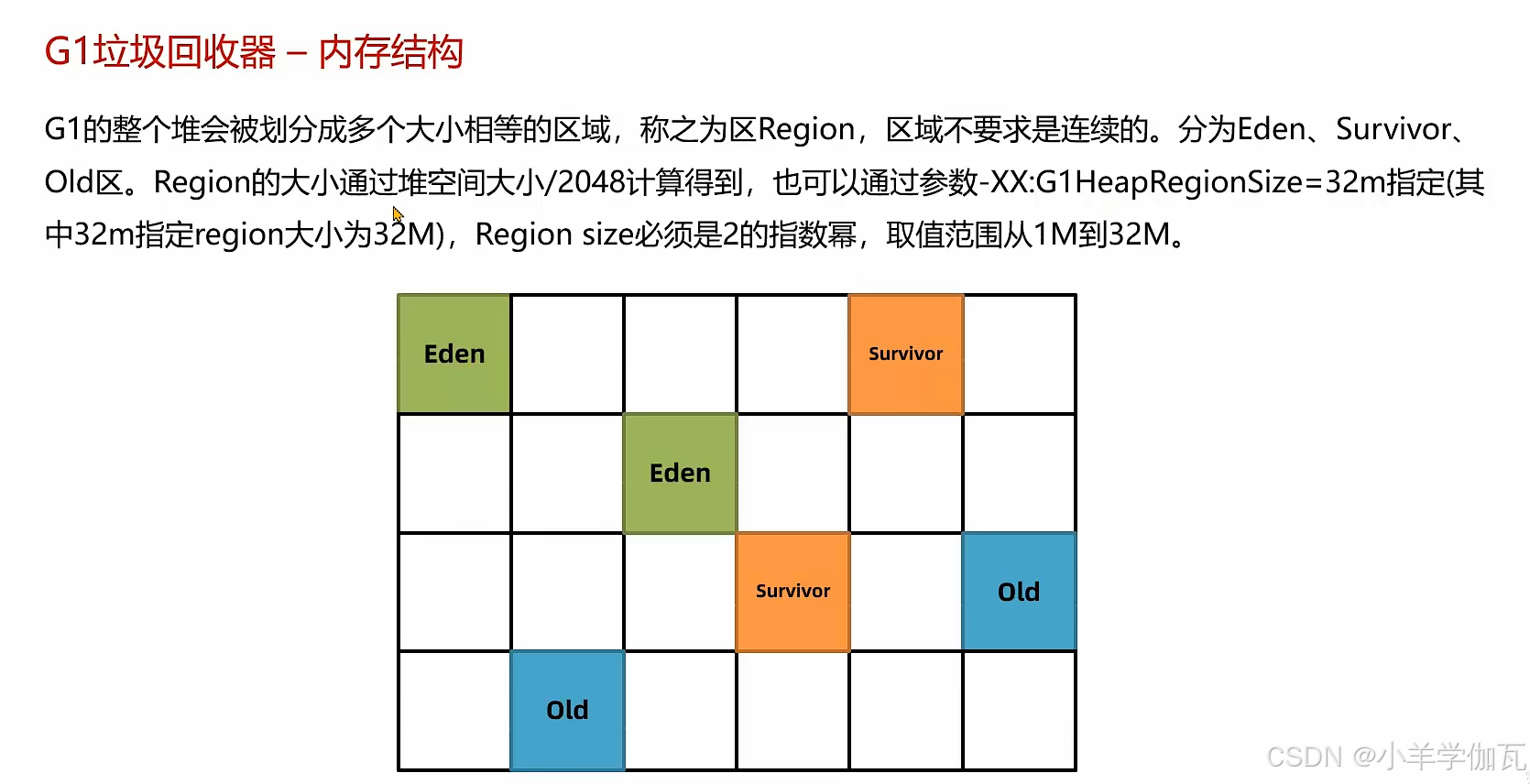
1.年轻代回收——YoungGC

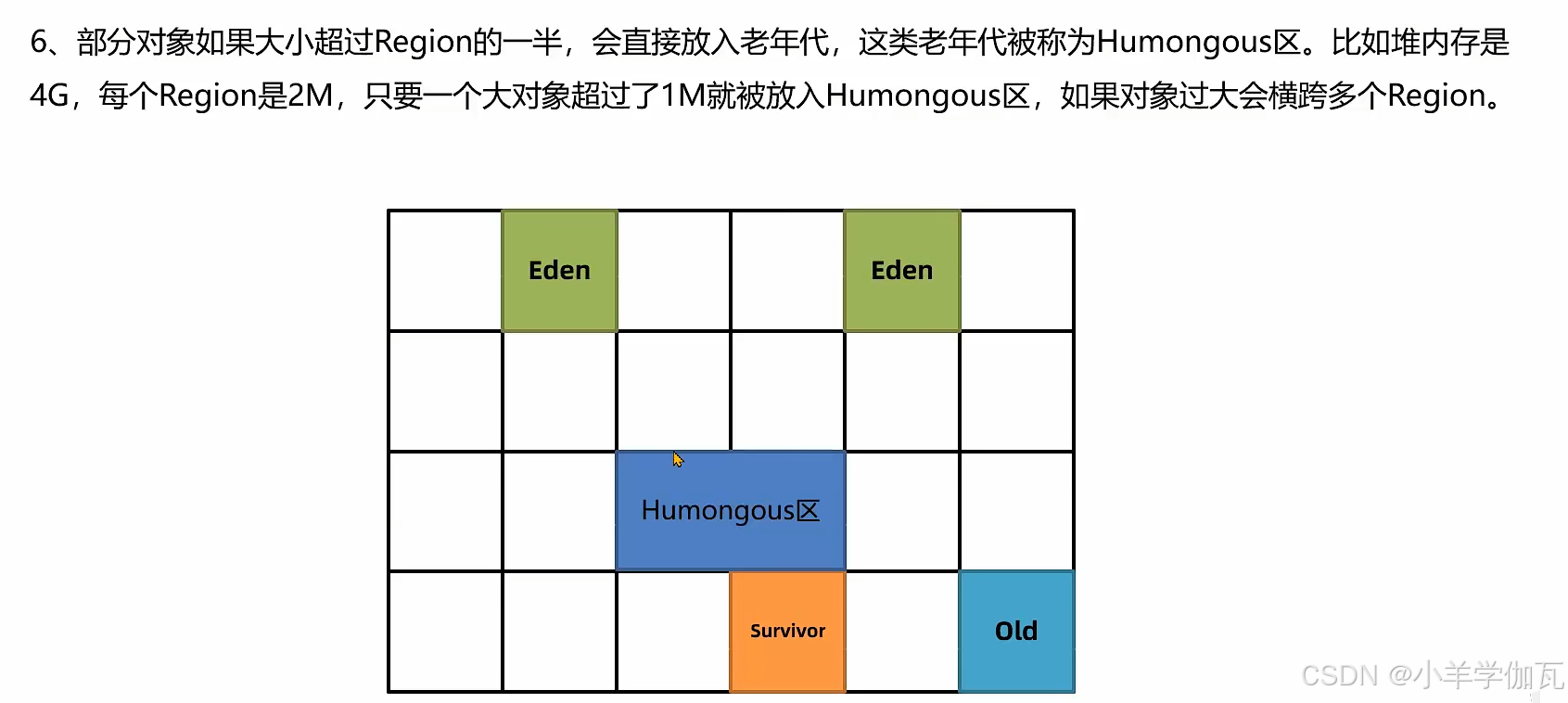
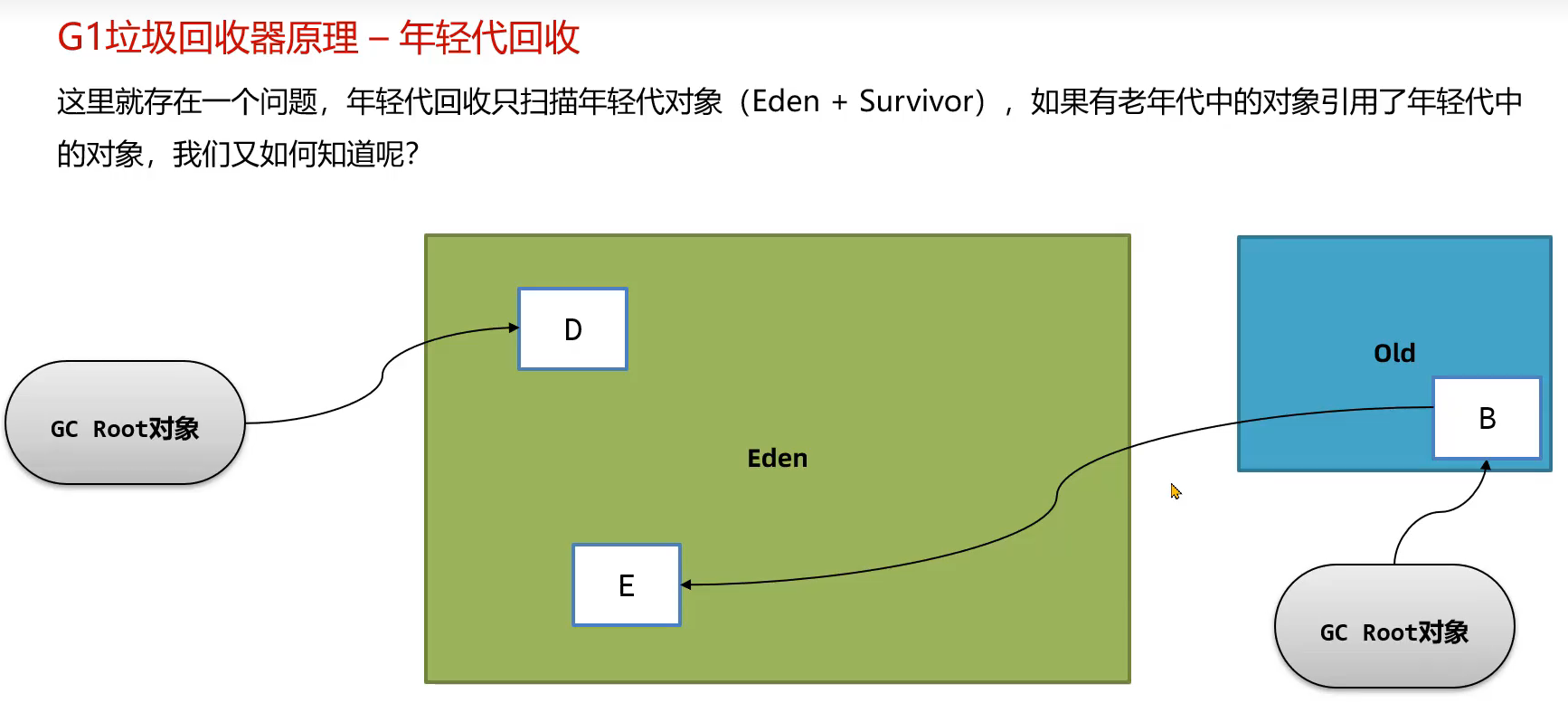
跨代引用的问题(老年代引用了年轻代)
由于young gc只标记的是eden和survivor区的对象,那如果有老年代的对象引用了年轻代的对象,如下图所示,这里的E对象不能被回收,但是并没有扫描old区的对象,就没有找到这个e对象,那怎么找到呢?
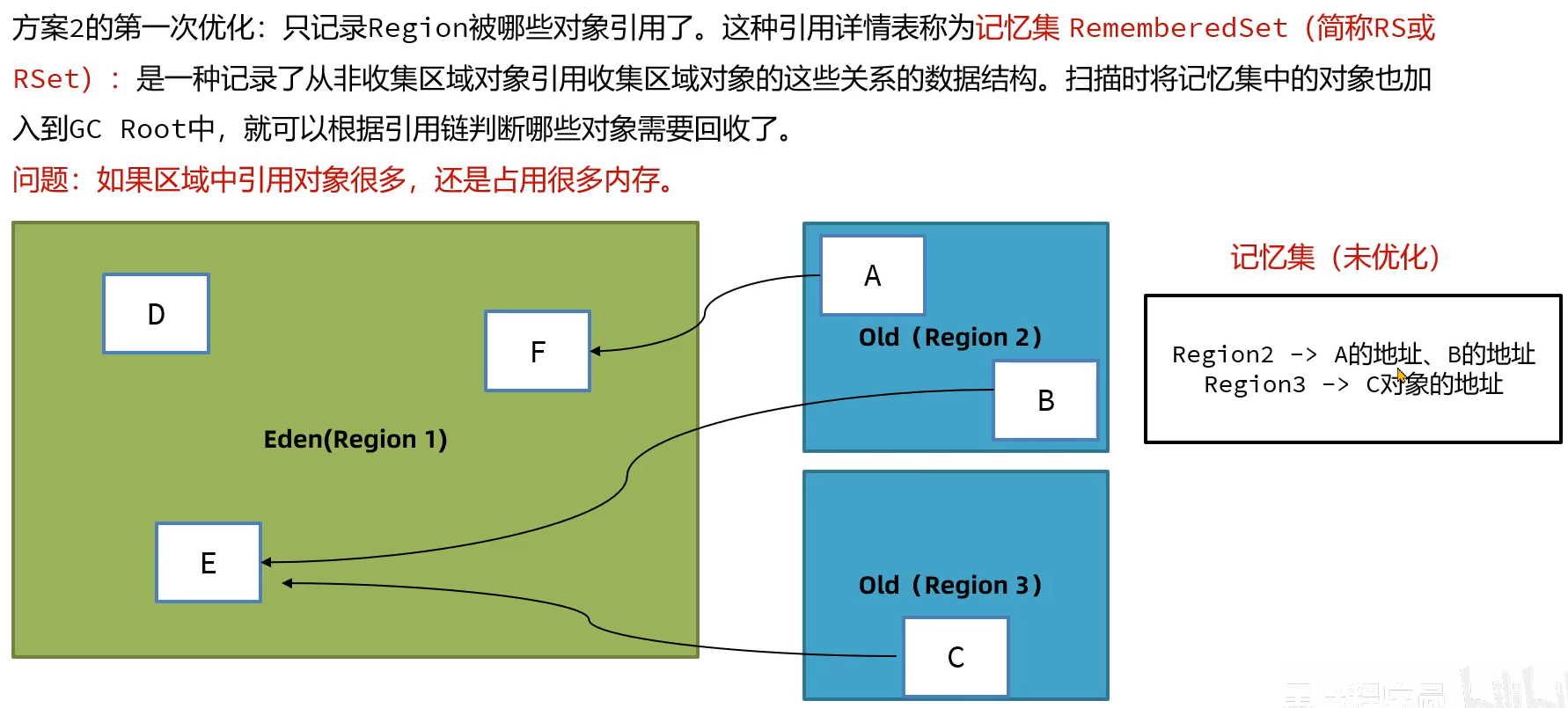
将A,B,C也要加入到GC root中
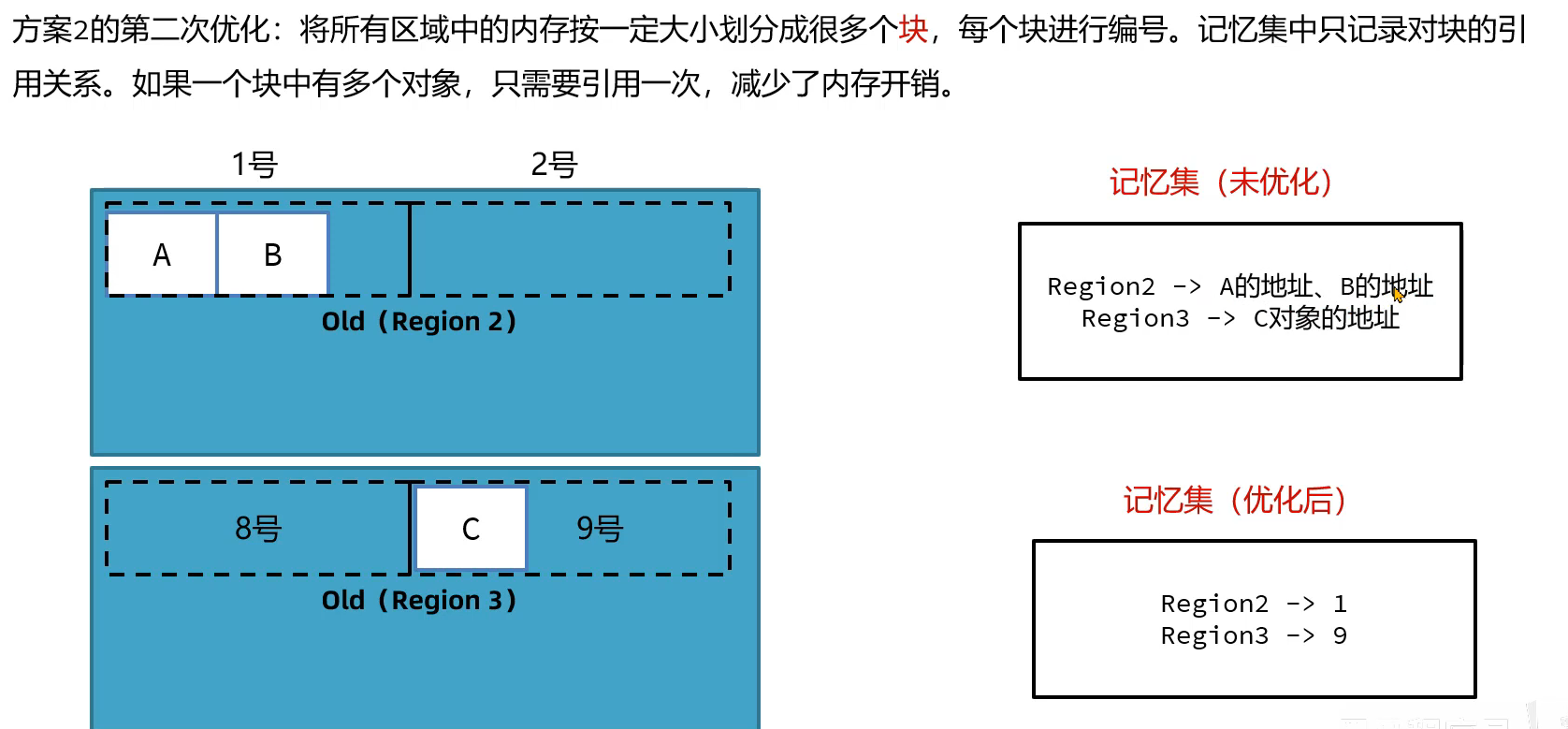
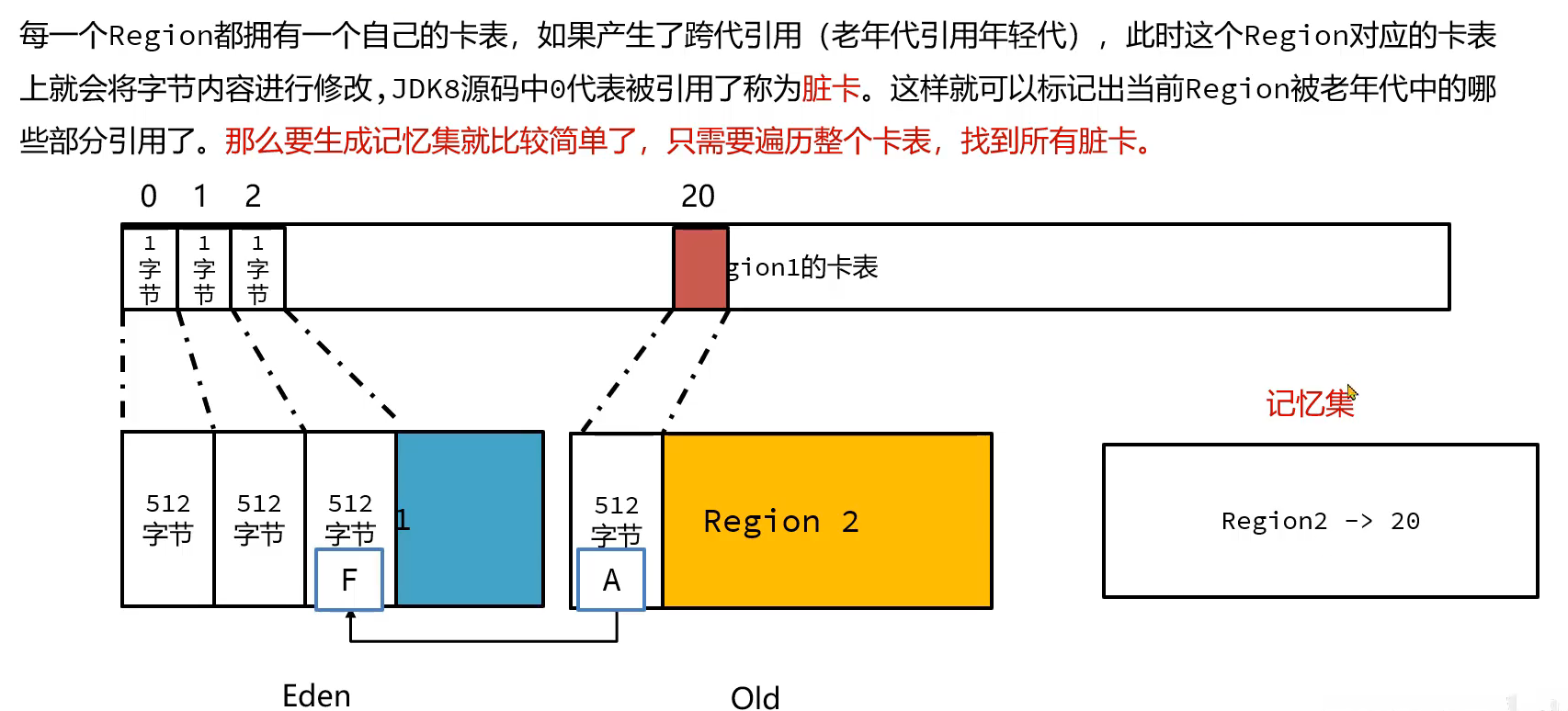
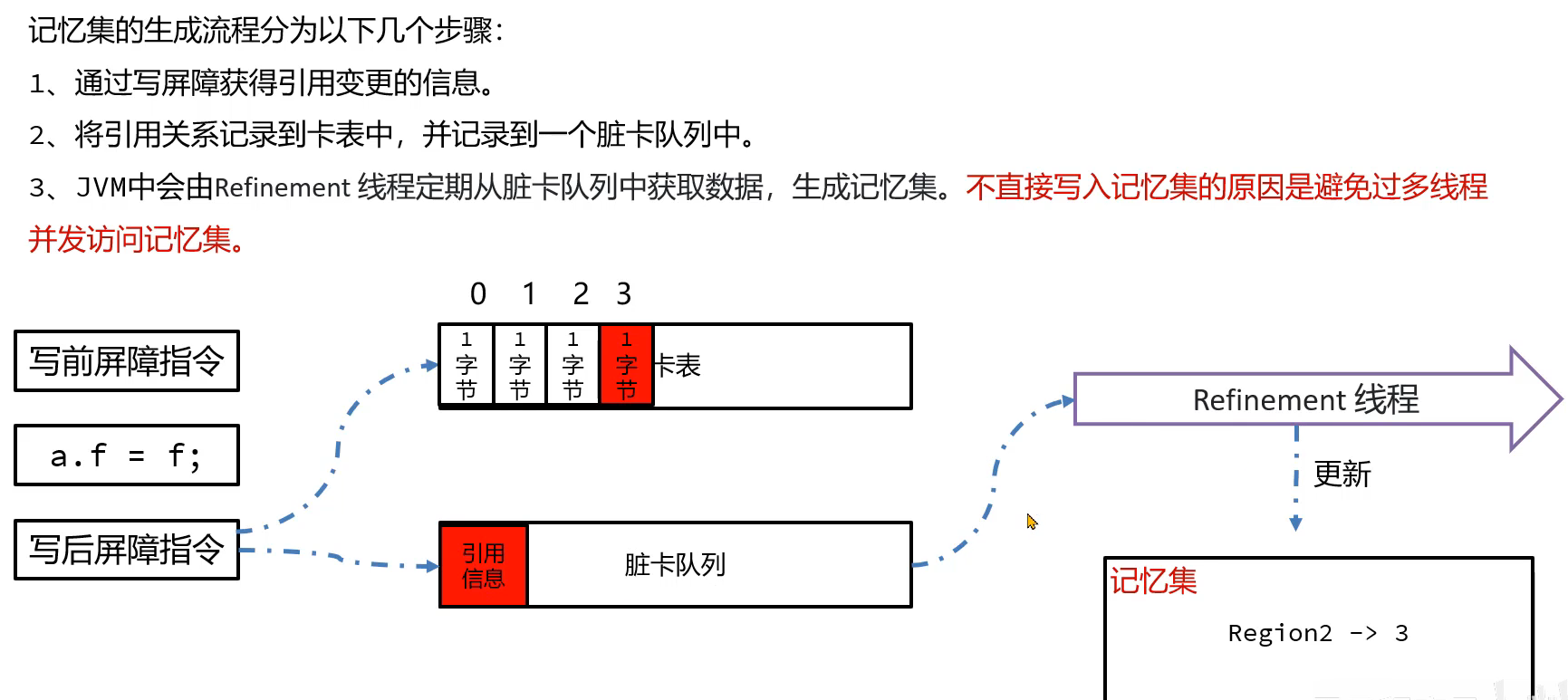
那如何维护这个卡表,或者说修改卡表的数据呢?运用写屏障技术

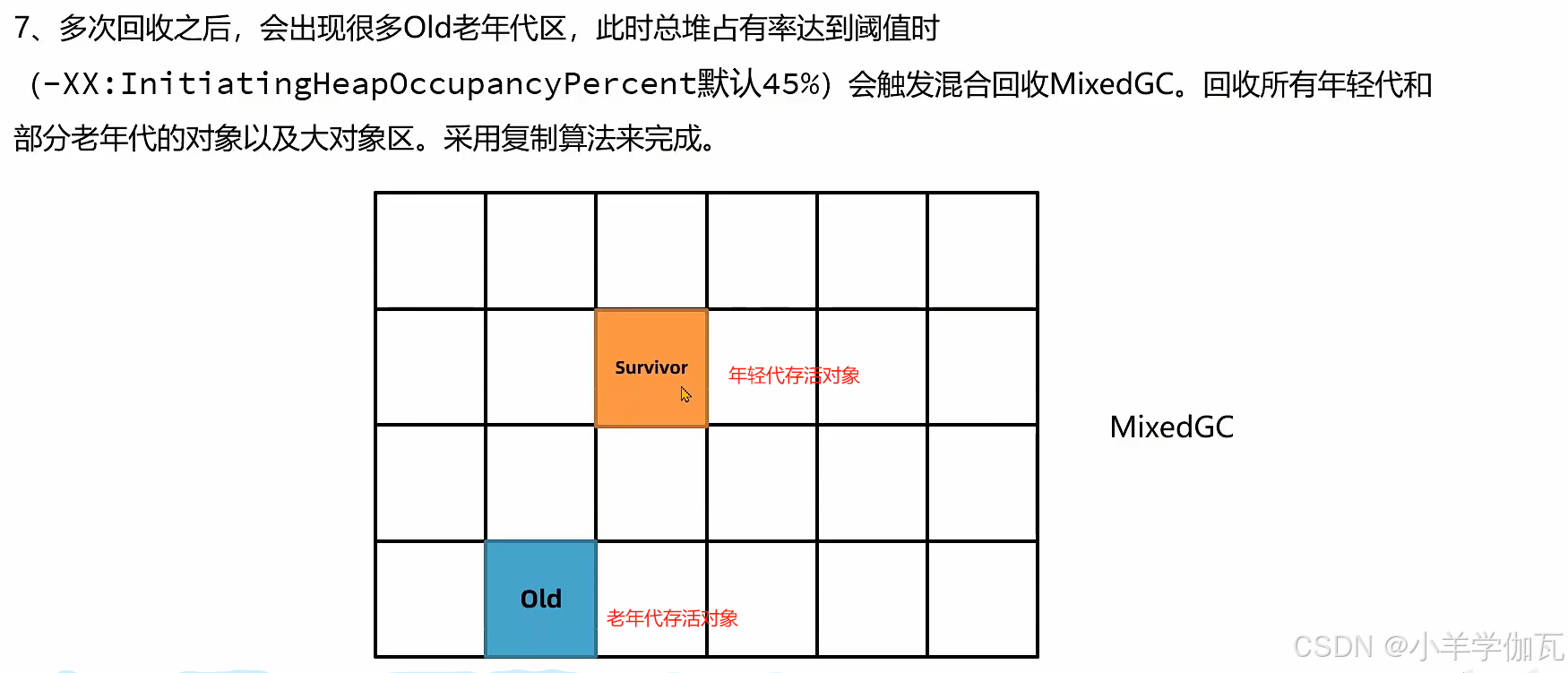
2.混合回收(Mixed GC)
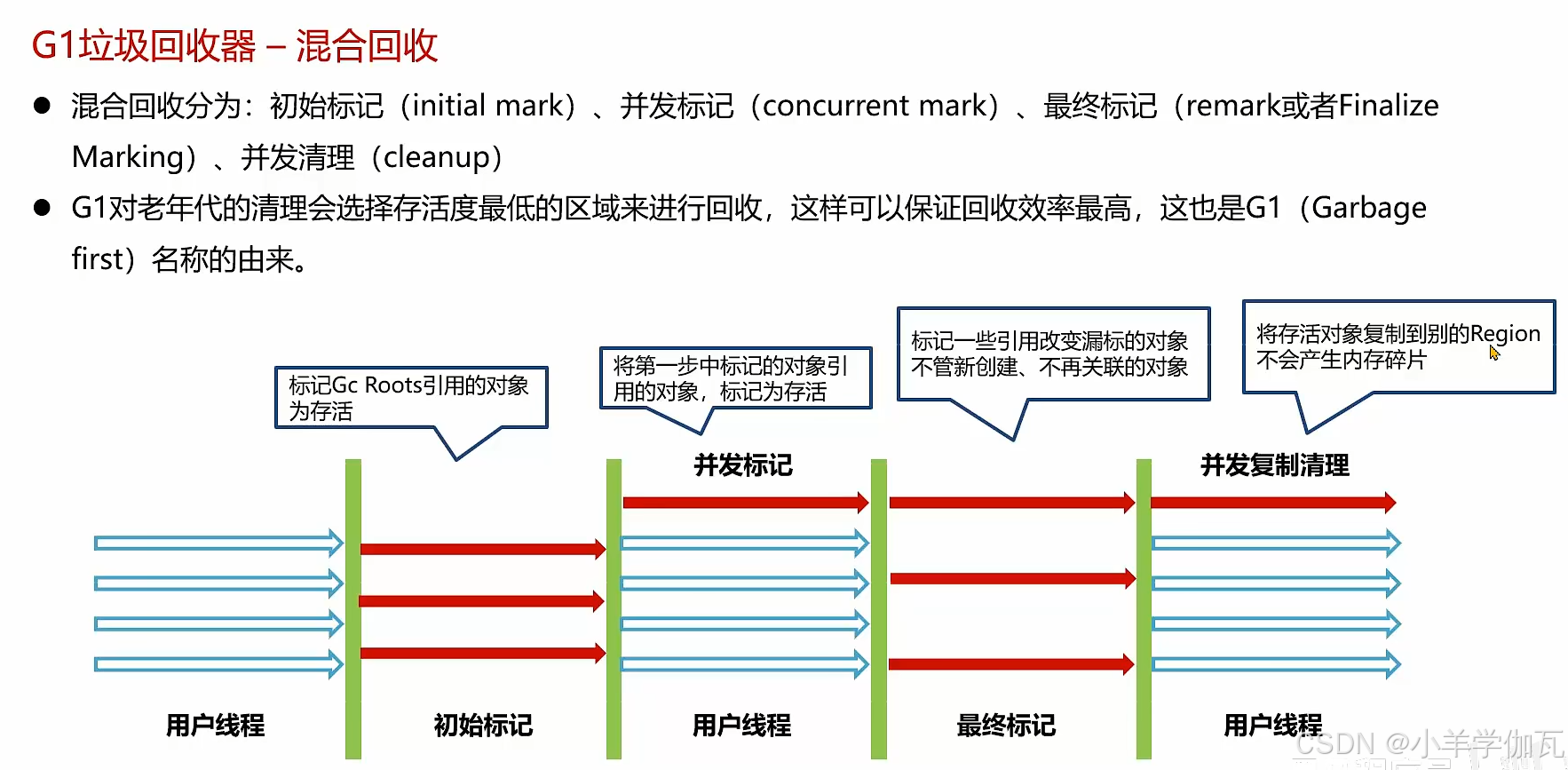

1.初始标记(三色标记法)
只是标记了从GC root可直达的对象
 2.并发标记阶段
2.并发标记阶段
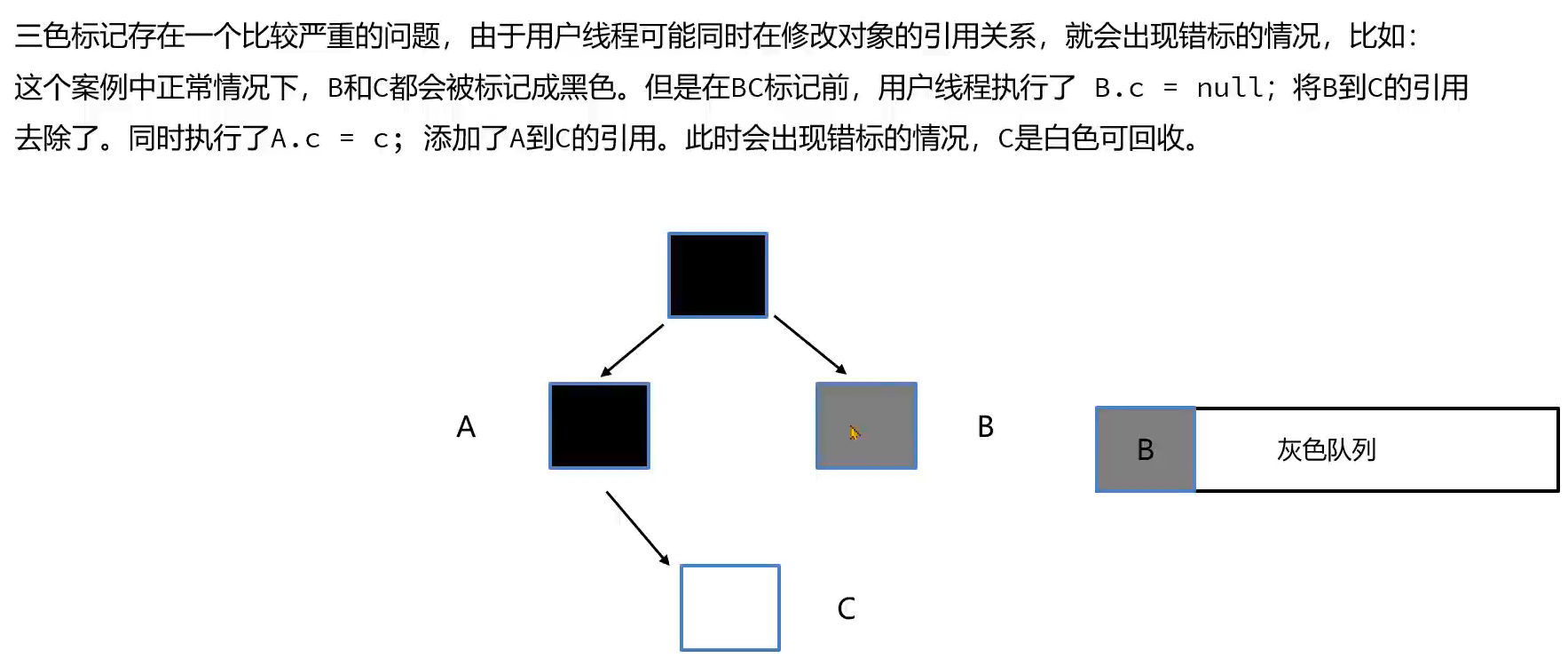
三色标记法存在的问题:
由于并发标记阶段是和用户线程一起工作的,并没有触发STW。用户线程可能修改了对象的引用关系,就出现了错标的情况。
标记开始时,先生成一个快照,记录下当前所有的对象
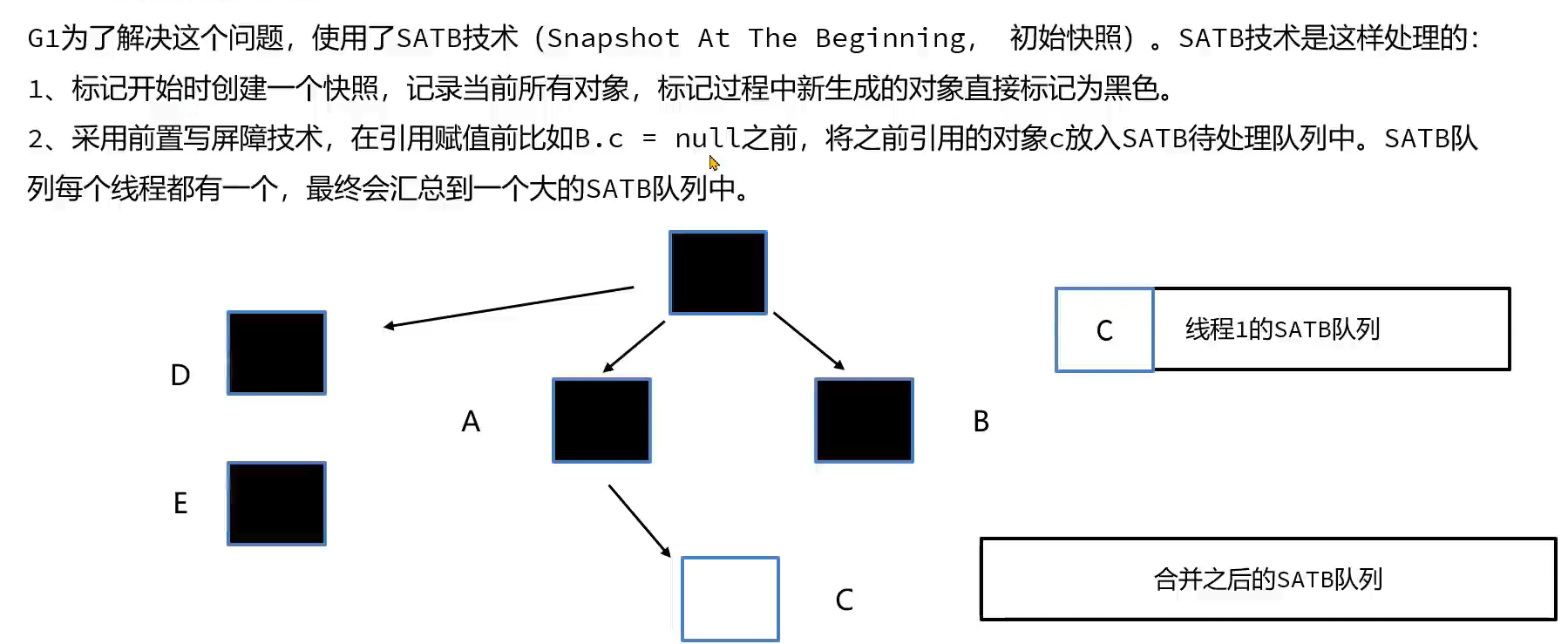
3.最终标记阶段
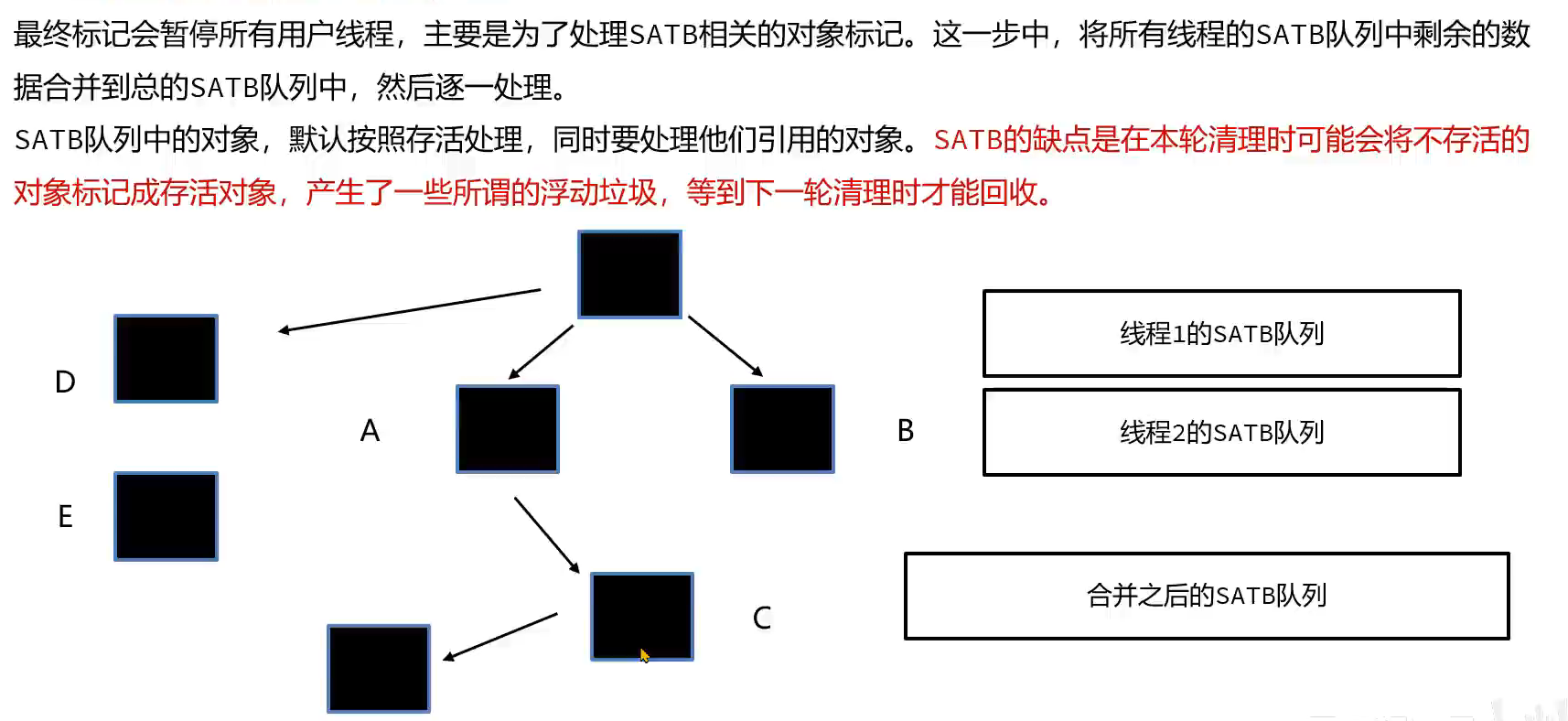
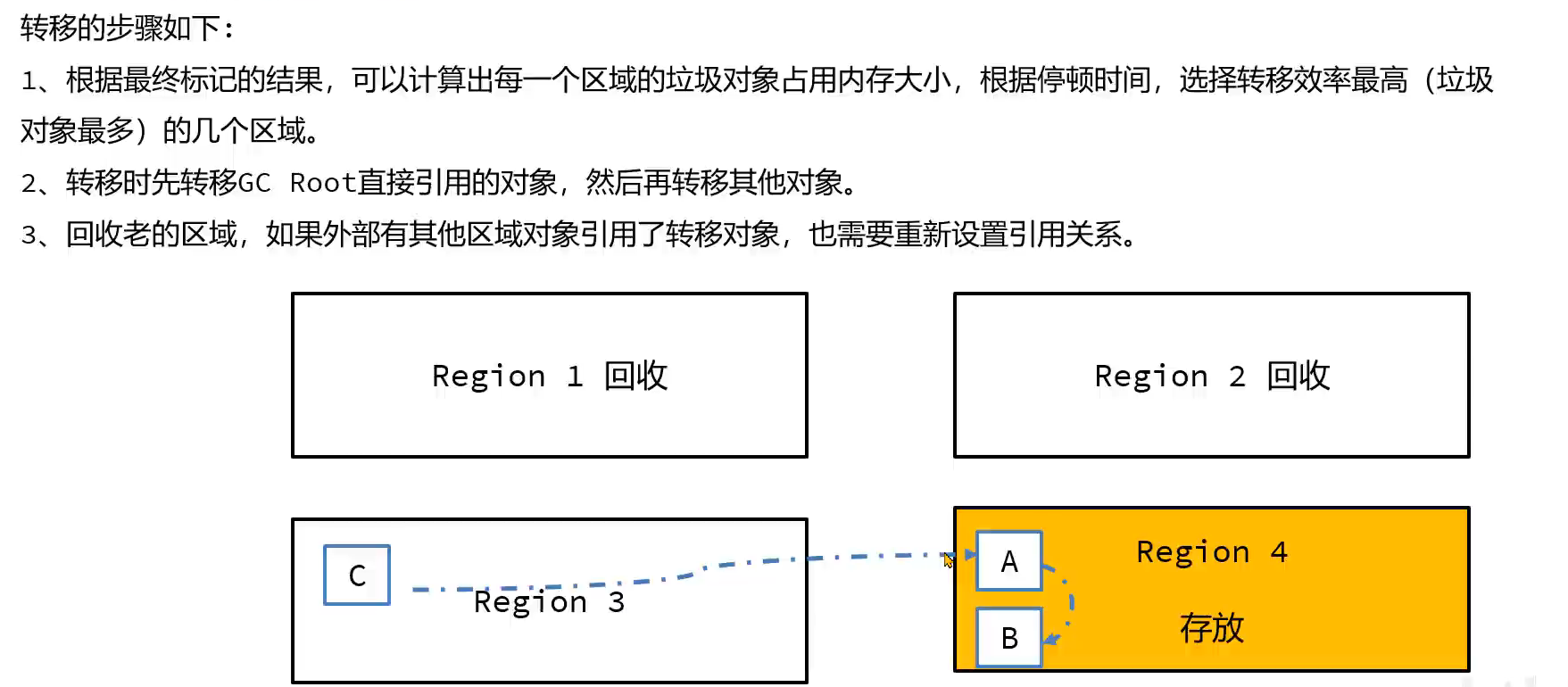
4.转移(先复制再删除,看起来像转移)

Full GC

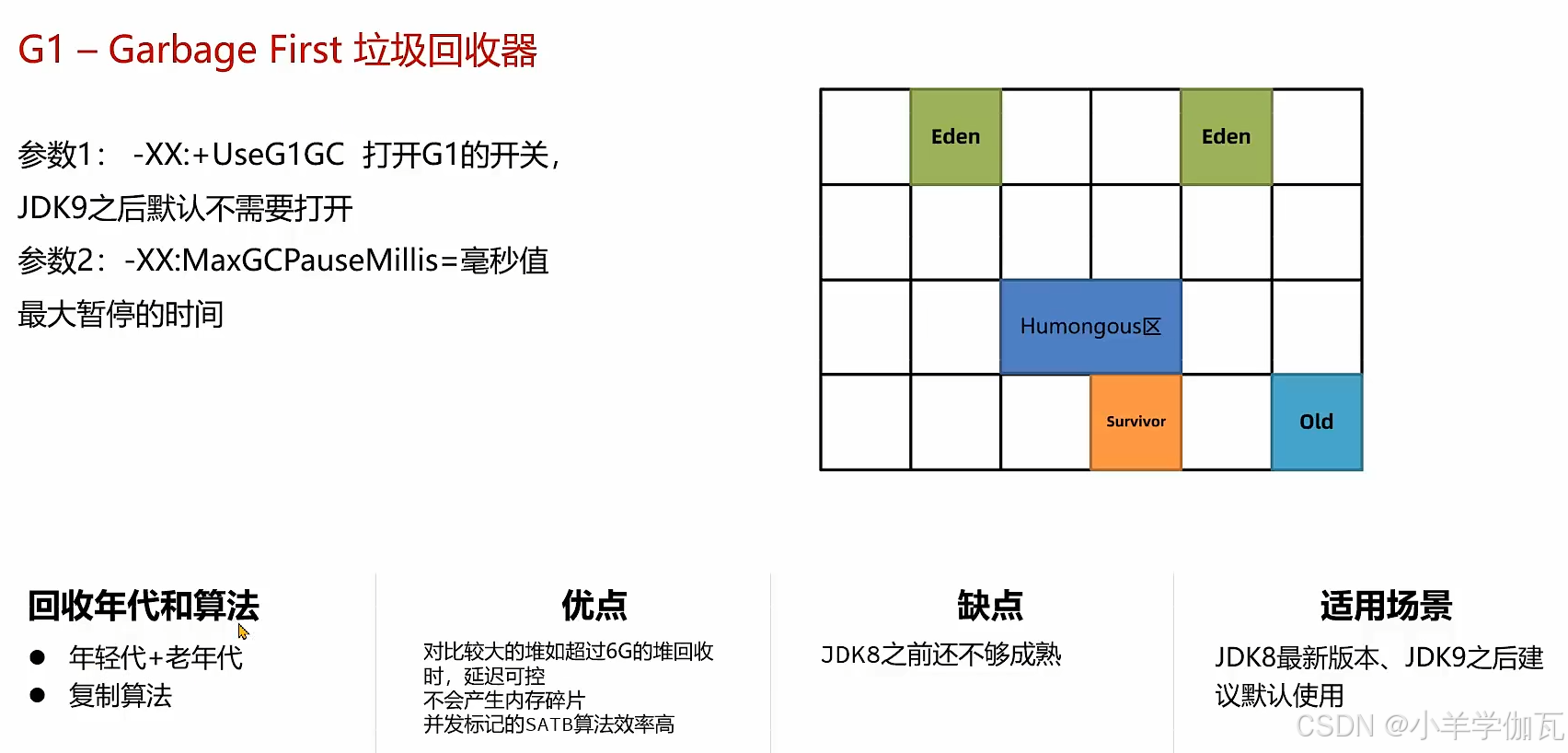
3.对比CMS