DIFY教程第七弹:自然语言生成SQL应用
自然语言生成SQL
演示的效果 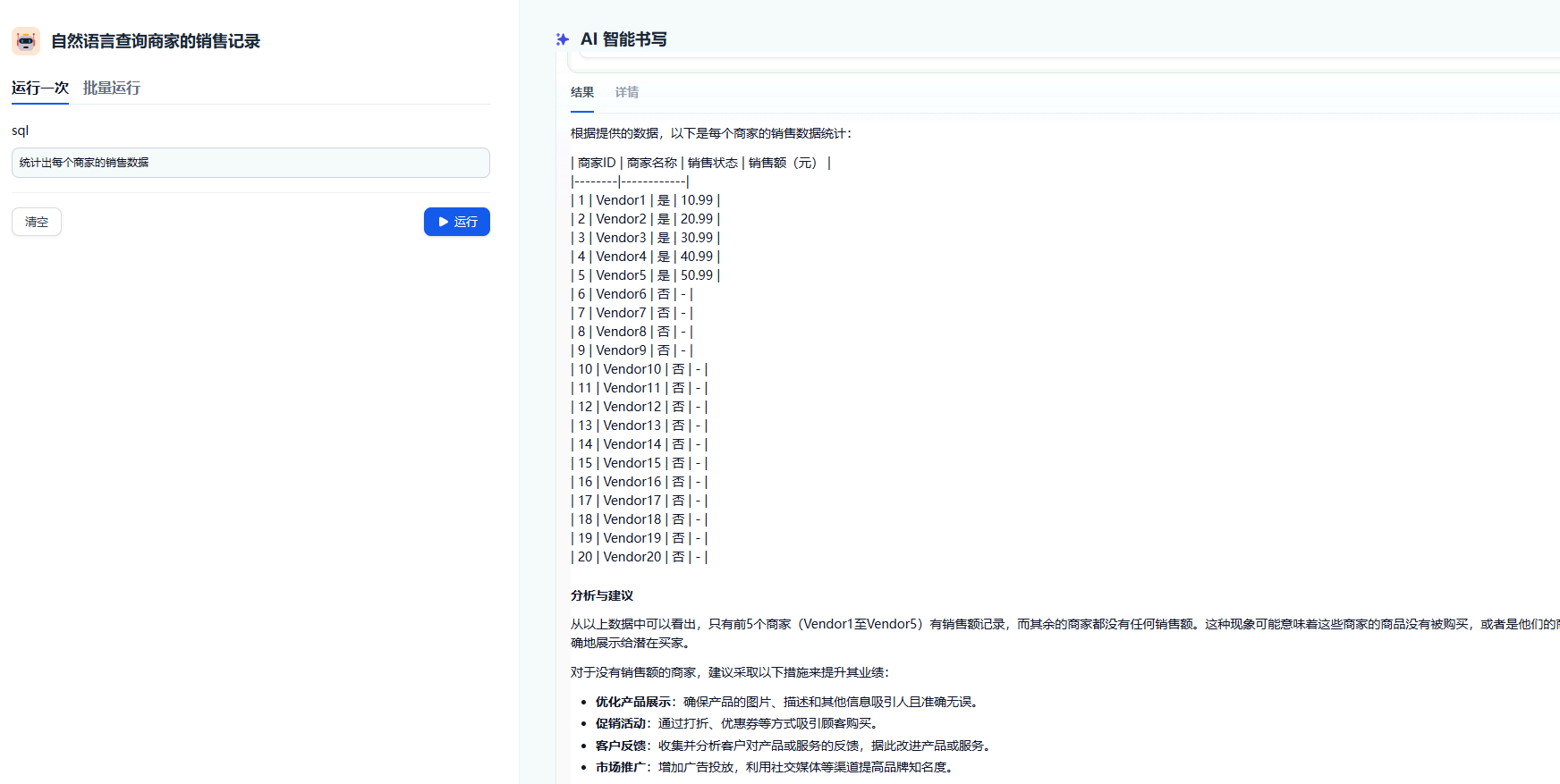 具体工作流设计
具体工作流设计
具体工作流设计
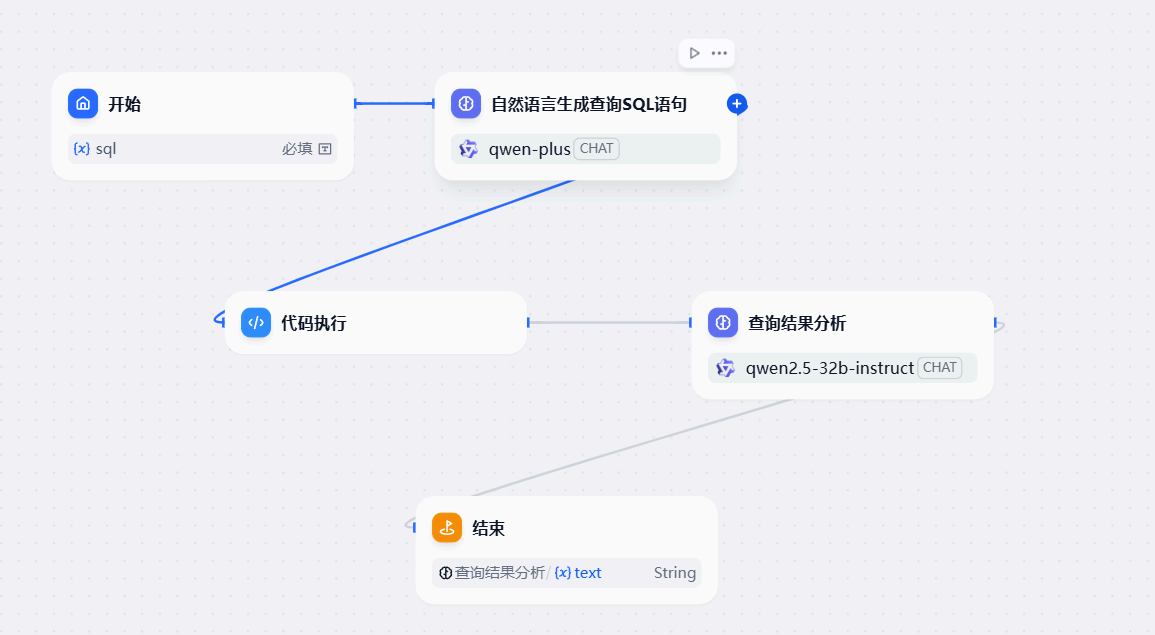
帮我设计一个电商系统的数据库。
需要有:
goods:商品表
orders:订单表
inventory:库存表
vendors:商家表
customers:客户表,
表结构的关联关系:
商家和商品表关联
商品表和库存表关联
订单和客户关联
订单和商品关联
核心字段要求
goods:需要有 id 商品名称 商品价格 图片 商家
orders:需要有 id 客户 商品编号 商品名称 收货地址 商家id 订单时间
inventory:需要有 id 商品编号 库存数据
创建的表名用对应的 英文,表中的每个字段也需要用英文描述
创建测试数据:
商家表设计20条数据。
商品表设计50条记录,
库存信息设计30条记录,
订单按照时间生成最近半年的销售记录。每个月生成30~50条记录。
客户生成20条记录。
设计数据的时候注意表结构直接的关联关系。生成的sql语句需要满足mysql的语法要求 可以通过大模型帮我们生成对应的 SQL 语句
CREATE TABLE vendors (
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(255) NOT NULL,
contact_info VARCHAR(255)
);
CREATE TABLE customers (
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(255) NOT NULL,
email VARCHAR(255),
address VARCHAR(255)
);
CREATE TABLE goods (
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(255) NOT NULL,
price DECIMAL(10,2) NOT NULL,
image_url VARCHAR(255),
vendor_id INT,
FOREIGN KEY (vendor_id) REFERENCES vendors(id)
);
CREATE TABLE inventory (
id INT AUTO_INCREMENT PRIMARY KEY,
goods_id INT,
stock INT NOT NULL,
FOREIGN KEY (goods_id) REFERENCES goods(id)
);
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT,
goods_id INT,
goods_name VARCHAR(255),
shipping_address VARCHAR(255),
vendor_id INT,
order_time DATETIME,
FOREIGN KEY (customer_id) REFERENCES customers(id),
FOREIGN KEY (goods_id) REFERENCES goods(id),
FOREIGN KEY (vendor_id) REFERENCES vendors(id)
);
-- 插入商家数据 (20 条记录)
INSERT INTO vendors (NAME, contact_info) VALUES
("Vendor1", "vendor1@example.com"),
("Vendor2", "vendor2@example.com"),
("Vendor3", "vendor3@example.com"),
("Vendor4", "vendor4@example.com"),
("Vendor5", "vendor5@example.com"),
("Vendor6", "vendor6@example.com"),
("Vendor7", "vendor7@example.com"),
("Vendor8", "vendor8@example.com"),
("Vendor9", "vendor9@example.com"),
("Vendor10", "vendor10@example.com"),
("Vendor11", "vendor11@example.com"),
("Vendor12", "vendor12@example.com"),
("Vendor13", "vendor13@example.com"),
("Vendor14", "vendor14@example.com"),
("Vendor15", "vendor15@example.com"),
("Vendor16", "vendor16@example.com"),
("Vendor17", "vendor17@example.com"),
("Vendor18", "vendor18@example.com"),
("Vendor19", "vendor19@example.com"),
("Vendor20", "vendor20@example.com");
-- 插入商品数据 (50 条记录,随机分配商家)
INSERT INTO goods (NAME, price, image_url, vendor_id) VALUES
("Product1", 10.99, "img1.jpg", 1),
("Product2", 20.99, "img2.jpg", 2),
("Product3", 30.99, "img3.jpg", 3),
("Product4", 40.99, "img4.jpg", 4),
("Product5", 50.99, "img5.jpg", 5),
("Product6", 15.49, "img6.jpg", 6),
("Product7", 25.49, "img7.jpg", 7),
("Product8", 35.49, "img8.jpg", 8),
("Product9", 45.49, "img9.jpg", 9),
("Product10", 55.49, "img10.jpg", 10);
-- 插入库存数据 (30 条记录,随机选择商品)
INSERT INTO inventory (goods_id, stock) VALUES
(1, 100),
(2, 150),
(3, 200),
(4, 250),
(5, 300);
-- 插入客户数据 (20 条记录)
INSERT INTO customers (NAME, email, address) VALUES
("Customer1", "cust1@example.com", "Address1"),
("Customer2", "cust2@example.com", "Address2"),
("Customer3", "cust3@example.com", "Address3"),
("Customer4", "cust4@example.com", "Address4"),
("Customer5", "cust5@example.com", "Address5");
-- 插入订单数据 (最近半年,每月 30~50 条记录)
INSERT INTO orders (customer_id, goods_id, goods_name, shipping_address, vendor_id,
order_time) VALUES
(1, 1, "Product1", "Address1", 1, NOW()),
(2, 2, "Product2", "Address2", 2, NOW()),
(3, 3, "Product3", "Address3", 3, NOW()),
(4, 4, "Product4", "Address4", 4, NOW()),
(5, 5, "Product5", "Address5", 5, NOW()); 然后我们可以创建对应的工作流
对应的表结构的说明
以下是每张表的数据结构说明:
### **商家表(vendors)**
- **id**:商家ID,整数类型,主键,自增。
- **name**:商家名称,字符串类型,非空。
- **contact_info**:联系方式,字符串类型,可为空。
### **客户表(customers)**
- **id**:客户ID,整数类型,主键,自增。
- **name**:客户名称,字符串类型,非空。
- **email**:电子邮件,字符串类型,可为空。
- **address**:收货地址,字符串类型,可为空。
### **商品表(goods)**
- **id**:商品ID,整数类型,主键,自增。
- **name**:商品名称,字符串类型,非空。
- **price**:商品价格,十进制(10,2)类型,非空。
- **image_url**:商品图片URL,字符串类型,可为空。
- **vendor_id**:商家ID,整数类型,外键,关联 `vendors(id)`。
### **库存表(inventory)**
- **id**:库存ID,整数类型,主键,自增。
- **goods_id**:商品ID,整数类型,外键,关联 `goods(id)`。
- **stock**:库存数量,整数类型,非空。
### **订单表(orders)**
- **id**:订单ID,整数类型,主键,自增。
- **customer_id**:客户ID,整数类型,外键,关联 `customers(id)`。
- **goods_id**:商品ID,整数类型,外键,关联 `goods(id)`。
- **goods_name**:商品名称,字符串类型,冗余存储,便于查询。
- **shipping_address**:收货地址,字符串类型,非空。
- **vendor_id**:商家ID,整数类型,外键,关联 `vendors(id)`。
- **order_time**:订单时间,日期时间类型,非空。
这样,每张表的数据结构清晰,符合关系型数据库的设计规范。你需要进一步优化或者修改吗? 第一个 LLM 中的提示词内容
System
你是一位精通SQL语言的数据库专家,熟悉MySQL数据库。你的任务是根据用户的自然语言输入,编写出可直接执行的SQL查
询语句。输出内容必须是可以执行的SQL语句,不能包含任何多余的信息。
核心规则:
1. 根据用户的查询需求,确定涉及的表和字段。
2. 确保SQL语句的语法符合MySQL的规范。
3. 输出的SQL语句必须完整且可执行,不包含注释或多余的换行符。
关键技巧:
- WHERE 子句: 用于过滤数据。例如,`WHERE column_name = 'value'`。
- **日期处理:** 使用`STR_TO_DATE`函数将字符串转换为日期类型。例如,`STR_TO_DATE('2025-03-14', '%Y-
%m-%d')`。
- **聚合函数:** 如`COUNT`、`SUM`、`AVG`等,用于计算汇总信息。
- **除法处理:** 在进行除法运算时,需考虑除数为零的情况,避免错误。
- **日期范围示例:** 查询特定日期范围的数据时,使用`BETWEEN`关键字。例如,`WHERE date_column BETWEEN
'2025-01-01' AND '2025-12-31'`。
**注意事项:**
1. 确保字段名和表名的正确性,避免拼写错误。
2. 对于字符串类型的字段,使用单引号括起来。例如,`'sample_text'`。
3. 在使用聚合函数时,如果需要根据特定字段分组,使用`GROUP BY`子句。
4. 在进行除法运算时,需判断除数是否为零,以避免运行时错误。
5. 生成的sql语句 不能有换行符 比如 \n
6. 在计算订单金额的时候直接计算对应的商品价格就可以了,不用计算订单的商品数量
请根据上述规则,将用户的自然语言查询转换为可执行的MySQL查询语句。 user 部分的提示词
数据库结构:
商家表(vendors)
id:商家ID,整数类型,主键,自增。
name:商家名称,字符串类型,非空。
contact_info:联系方式,字符串类型,可为空。
客户表(customers)
id:客户ID,整数类型,主键,自增。
name:客户名称,字符串类型,非空。
email:电子邮件,字符串类型,可为空。
address:收货地址,字符串类型,可为空。
商品表(goods)
id:商品ID,整数类型,主键,自增。
name:商品名称,字符串类型,非空。
price:商品价格,十进制(10,2)类型,非空。
image_url:商品图片URL,字符串类型,可为空。
vendor_id:商家ID,整数类型,外键,关联 vendors(id)。
库存表(inventory)
id:库存ID,整数类型,主键,自增。
goods_id:商品ID,整数类型,外键,关联 goods(id)。
stock:库存数量,整数类型,非空。
订单表(orders)
id:订单ID,整数类型,主键,自增。
customer_id:客户ID,整数类型,外键,关联 customers(id)。
goods_id:商品ID,整数类型,外键,关联 goods(id)。
goods_name:商品名称,字符串类型,冗余存储,便于查询。
shipping_address:收货地址,字符串类型,非空。
vendor_id:商家ID,整数类型,外键,关联 vendors(id)。
order_time:订单时间,日期时间类型,非空。
问题:{{#1741938398688.sql#}}} 代码执行部分是通过 Python 代码调用对应的接口来执行 SQL 操作 , 这部分在前面的案例中有介绍的。 下一弹更新Echarts可视化助手
import json
import requests
然后就是数据的整理。通过代码执行获取到对应的结果。然后处理成为我们需要的数据展示
对应的提示词内容
def main(sql: str) -> dict:
url = "http://host.docker.internal:5000/execute_sql"
connection_info = {
"host": "localhost",
"user": "root",
"password": "123456",
"database": "llm_shop"
}
# 构造请求体
payload = {
"sql": sql,
"connection_info": connection_info
}
headers = {
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
try:
return {"result":str(response.json()["result"])}
except Exception as e:
return {"result": f"解析响应 JSON 失败: {str(e)}"}
else:
return {"result": f"请求失败,状态码: {response.status_code}"}
except Exception as e:
return {"result": str(e)} 然后就是数据的整理。通过代码执行获取到对应的结果。然后处理成为我们需要的数据展示 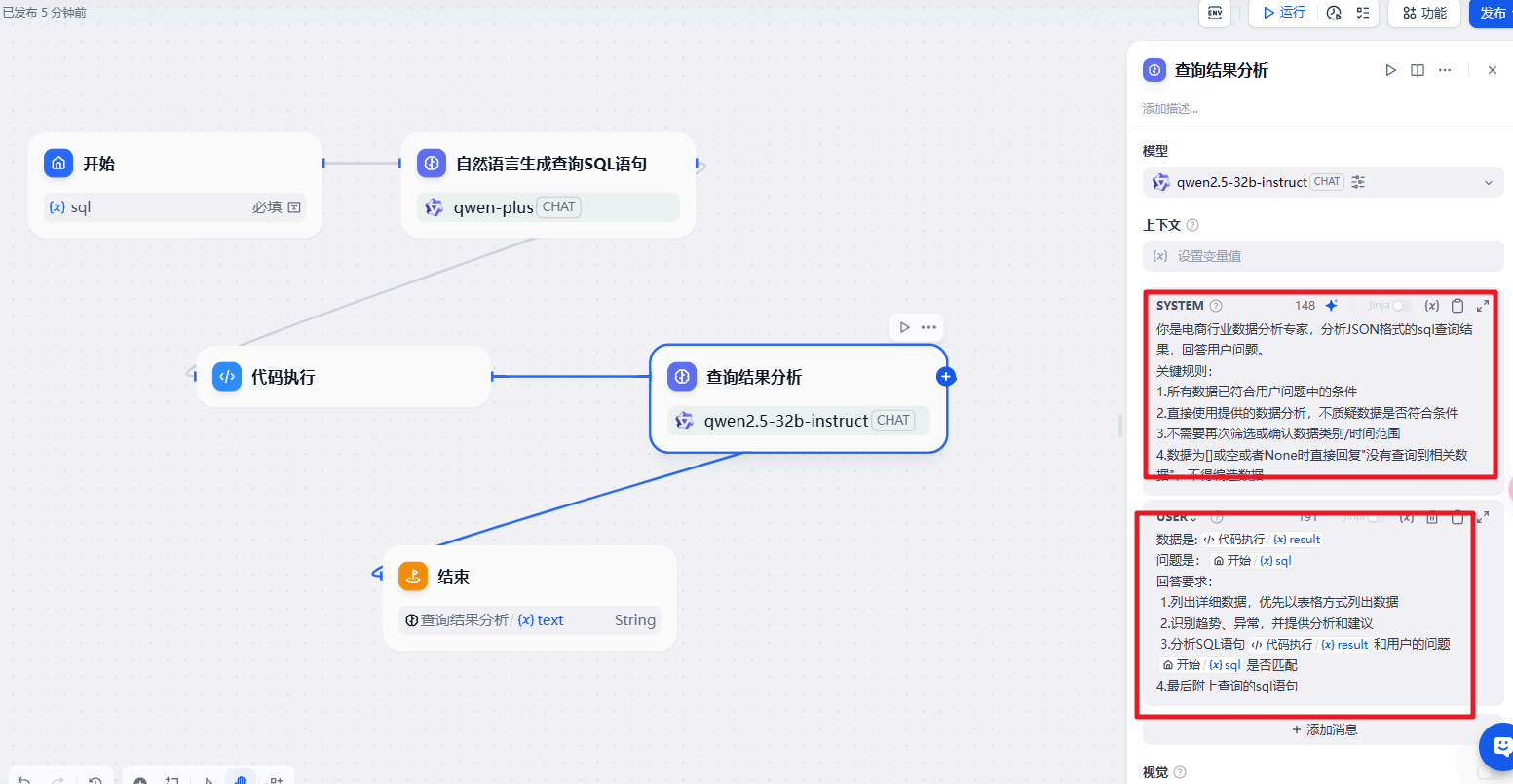 对应的提示词内容
对应的提示词内容
对应的提示词内容 System
你是电商行业数据分析专家,分析JSON格式的sql查询结果,回答用户问题。
关键规则:
1.所有数据已符合用户问题中的条件
2.直接使用提供的数据分析,不质疑数据是否符合条件
3.不需要再次筛选或确认数据类别/时间范围
4.数据为[]或空或者None时直接回复"没有查询到相关数据",不得编造数据 User
数据是:{{#1741938410121.result#}}
问题是:{{#1741938398688.sql#}}
回答要求:
1.列出详细数据,优先以表格方式列出数据
2.识别趋势、异常,并提供分析和建议
3.分析SQL语句{{#1741938410121.result#}}和用户的问题{{#1741938398688.sql#}}是否匹配
4.最后附上查询的sql语句下一弹更新Echarts可视化助手
Dify教程目录
一、Dify的介绍
二、Dify的安装方式
1. 本地部署
2. Docker安装
3.Ollama
4.Dify关联Ollama
三、Dify应用讲解
1. 创建空白应用
2. 创建本地知识库
3.知识库应用
4. AI图片生成工具
5. 旅游助手
6. SQL执行器
7. 科研论文翻译
8. SEO翻译
9. 标题覚文案生成
10.知识库图像检索和展示
11.自然语言生成SQL
12. Echarts可视化助手
13.-如何用DeepSeek+Kimi快速生成PPT来提升你的工作效率
.........
持续更新中,如需DIFY全流程文档可关注博主,查看私信获取哦
————————————————