MYSQL库表设计:范式
1.1.1. 概念

- MySQL 的库表设计,在很多时候我们都是率性而为,往往在前期的设计中考虑并不全面,同时对于库表结 构的划分也并不明确,所以很多时候在开发过程中,代码敲着敲着会去重构某张表结构,甚至大面积重构 多张表结构,这种随心所欲的设计方式,无疑给开发造成了很大困扰。
- 范式( Normal Form )是指设计数据库时要遵守的一些原则
- 在设计 DB 库表结构时,需要遵守该规范,可以让在项目之初,设计的库表结构更为合理且优雅。数据库范 式中,声名远扬的有三大范式,但除此之外也有一些其他设计规范,如:
- 数据库三大范式( 1NF、2NF、3NF )
- 第四范式( 4NF )和第五范式:完美范式( 5NF )
- 巴斯-科德范式( BCNF )
- 域键范式
- 反范式设计
- 小结:三大范式之间,是递进的关系,后续的范式都基于前一个范式的基础上推行,比如:今天我要先炒 菜,然后吃饭,最后洗碗,这三者属于递进关系,后者都建立在前者之上,其顺序不能颠倒,比如先吃饭 再炒菜,这必然是行不通的。数据库的三大范式也一样,第二范式必须建立在第一范式的基础之上,如若 设计的库表第一范式都不满足,那定然是无法满足第二范式的。
1.1.2. 第一范式(1NF)
- 原则:库表设计时为了确保原子性,其存储数据具备不可再分性,,例:
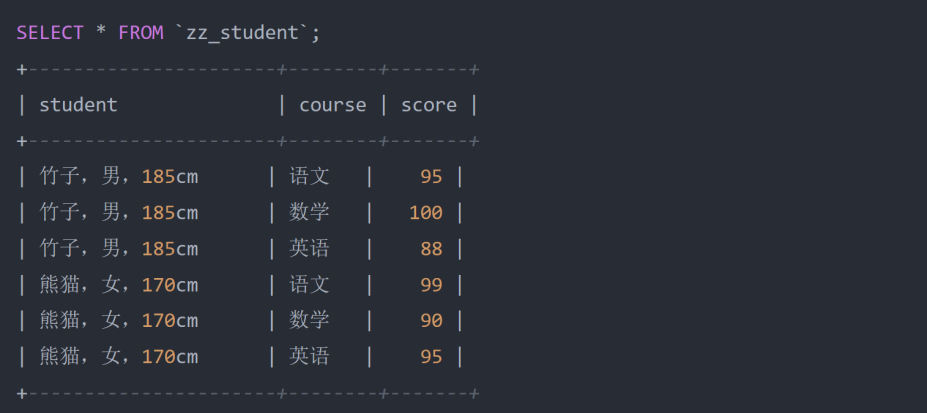
- 在上述的学生表中,其中有一个 student 学生列,这一列存储的数据则明显不符合第一范式:原子性的规 定,因为这一列的数据还可以再拆分为姓名、性别、身高三项数据,因此为了符合第一范式,应该将表结 构更改为:
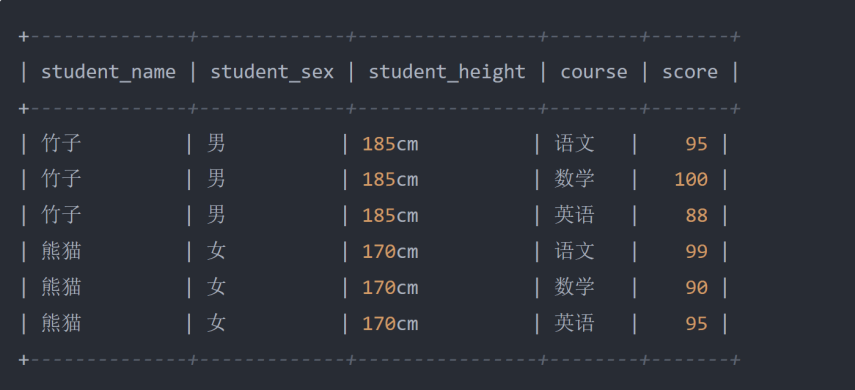
- 如果不去拆分列满足第一范式,会造成什么影响?
- 客户端语言和表之间无法很好的生成映射关系。
- 查询到数据后,需要处理数据时,还需要对 student 字段进行额外拆分。
- 插入数据时,对于第一个字段的值还需要先拼装后才能进行写入。
1.1.3. 第二范式(2NF)
原则:表中的所有列,其数据都必须依赖于主键,也就是一张表只存储同一类型的数据,不能有任何一列 数据与主键没有关系,例:
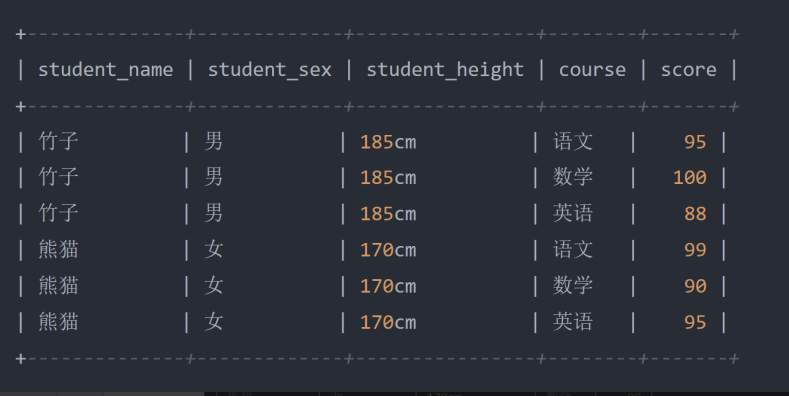
- 虽然此时已经满足了数据库的第一范式,但此刻观察 course 课程、 score 分数这两列数据,跟前面的几 列数据实际上依赖关系并不大,同时也由于这样的结构,导致前面几列的数据出现了大量冗余,所以此时 可以再次拆分一下表结构:
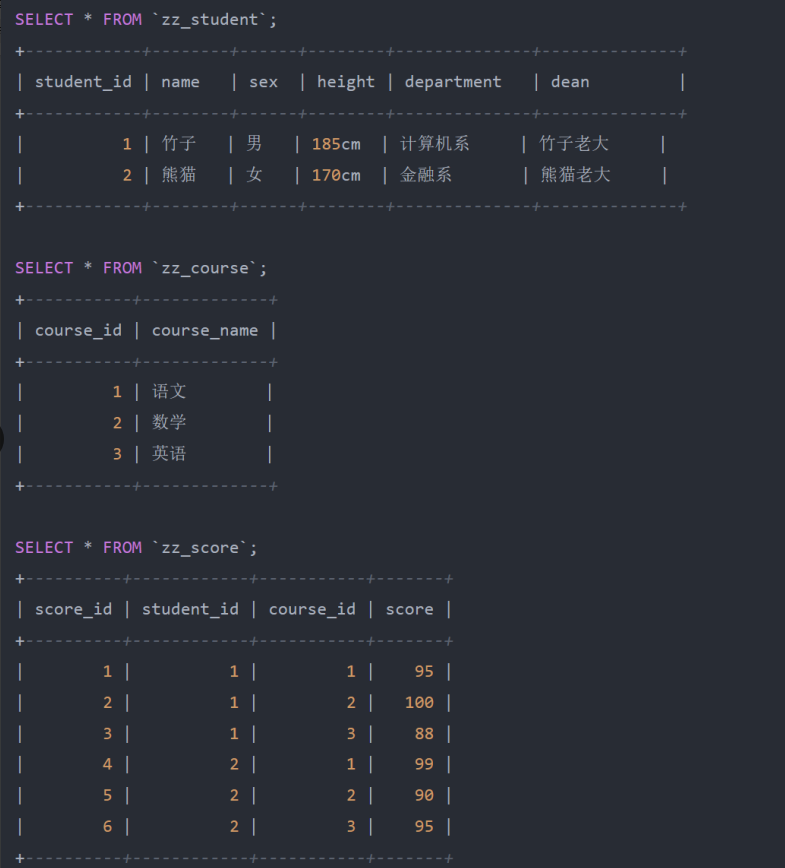
- 经过上述结构优化后,之前的一张表被拆分成学生表、课程表、成绩表三张,每张表中的 id 字段作为主 键,其他字段都依赖这个主键。无论在那张表中,都可以通过 id 主键确定其他字段的信息,每张表的业务 属性都具备“唯一性”,也就是每张表都只会描述了“一件事情”,不会存在一张表中会出现两个业务属性。
1.1.4. 第三范式(3NF)
- 原则:表中每一列数据不能与主键之外的字段有直接关系,例:
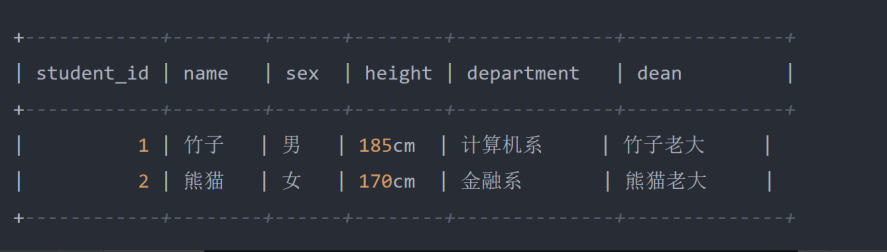 比如这张学生表,目前即符合第一范式,也符合第二范式,但看最后的两个字段, department 表示当前 学生所属的院校, dean 则表示这个院系的院长是谁。一般来说,一个学生的院长是谁,首先是取决于学生 所在的院系的,因此最后的 dean 字段明显与 department 字段存在依赖关系,因此需要进一步调整表结 构:
比如这张学生表,目前即符合第一范式,也符合第二范式,但看最后的两个字段, department 表示当前 学生所属的院校, dean 则表示这个院系的院长是谁。一般来说,一个学生的院长是谁,首先是取决于学生 所在的院系的,因此最后的 dean 字段明显与 department 字段存在依赖关系,因此需要进一步调整表结 构:
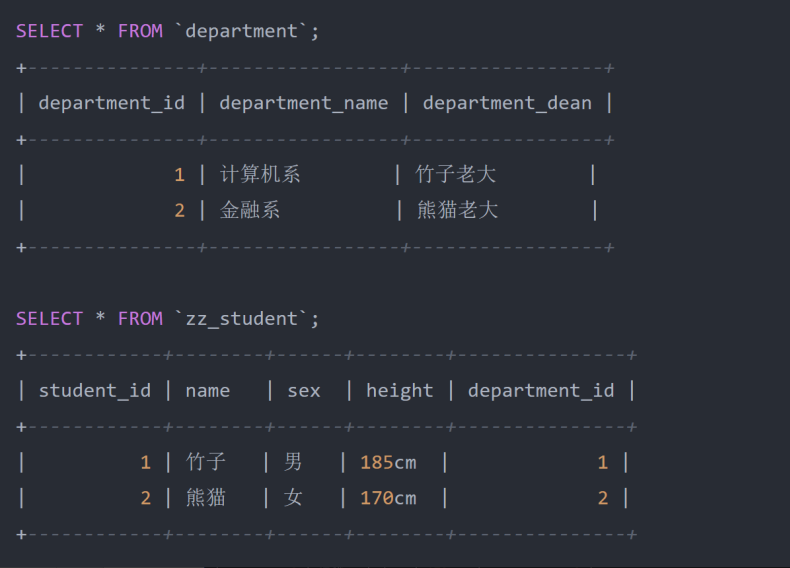
- 经过进一步的结构优化后,又将原本的学生表拆为了院系表、学生表两张,学生表中则是只存储一个院系 ID ,由院系表存储院系相关的所有数据。至此,学生表中的每个非主键字段与其他非主键字段之间,都是 相互独立的,之间不会再存在任何依赖性,所有的字段都依赖于主键。
- 为什么要这样调整?不调整会发生什么问题:
- 当一个院系的院长换人后,需要同时修改学生表中的多条数据。
- 当一个院长离职后,需要删除该院长的记录,会同时删除多条学生信息。
- 如果设计的表结构,无法满足第三范式,在操作表时就会出现异常,使得整个表较难维护。
1.1.5. 三范式小结
- 范式小结
- 1NF:确保原子性,表中每一个列数据都必须是不可再分的字段。
- 2NF:确保唯一性,每张表都只描述一种业务属性,一张表只描述一件事。
- 3NF:确保独立性,表中除主键外,每个字段之间不存在任何依赖,都是独立的。
- 没有按照范式设计表时,会存在几个问题
- 整张表数据比较冗余,同一个学生信息会出现多条。
- 表结构特别臃肿,不易于操作,要新增一个学生信息时,需添加大量数据。
- 需要更新其他业务属性的数据时,比如院系院长换人了,需要修改所有学生的记录。
- 经过三范式的设计优化后,整个库中的所有表结构,会显得更为优雅,灵活性也会更强。
1.1.6. 巴斯-科德范式(BCNF)
- 概念:
- 前题:一般在一张表中,可以用于区分每行数据的一个列,通常会被咱们设为主键,例如常用的 ID 字段就是如此,这类主键通常被称为单一主键,即一个列组成的主键。但除此之外,还有一个联合主 键的概念,也就是由多个列组成的主键
- 巴斯-科德范式也被称为 3.5NF ,是第三范式的补充版
- 第三范式的要求是:任何非主键字段不能与其他非主键字段间存在依赖关系,也就是要求每个非主键 字段之间要具备独立性。而巴斯-科德范式在第三范式的基础上,进一步要求:任何主属性不能对其他 主键子集存在依赖。
- 大白话:规定了联合主键中的某列值,不能与联合主键中的其他列存在依赖关系
- 例:
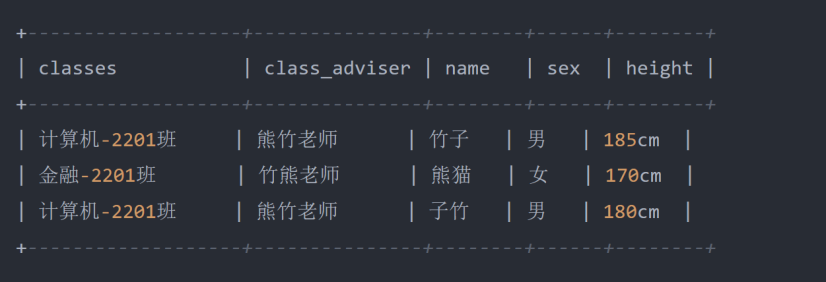
- 分析
- 这张学生表,此时假设以 classes 班级字段、 class_adviser 班主任字段、 name 学生姓名字段,组合成一个联合主键,在这里我们可以通过联合主键,确定学生表中任何一个学生的信息,比如:熊 竹老师管的计算机-2201班,哪个竹子同学有多高啊?可以通过上述的联合主键精准定位到表中第一 条数据,并且最终能够给出答案为 185cm 。
- 出现问题:在这张表中,一条学生信息中的班主任,取决于学生所在的班级,比如「竹子同学、子竹 同学」在「计算机-2201班」,所以它们的班主任都是「熊竹老师」,因此班主任字段其实也依赖于 班级字段。那会造成什么问题呢?
- 当一个班级的班主任老师换人后,需要同时修改学生表中的多条数据。
- 当一个班主任老师离职后,需要删除该老师的记录,会同时删除多条学生信息。
- 想要增加一个班级时,同时必须添加学生姓名数据,因为主键不允许为空。
- 通过上述分析可以明显得知,如果联合主键中的一个字段依赖于另一个字段,同样也会造成不小的问题, 使得整张表的维护性变差,因此这里需要进一步调整结构:
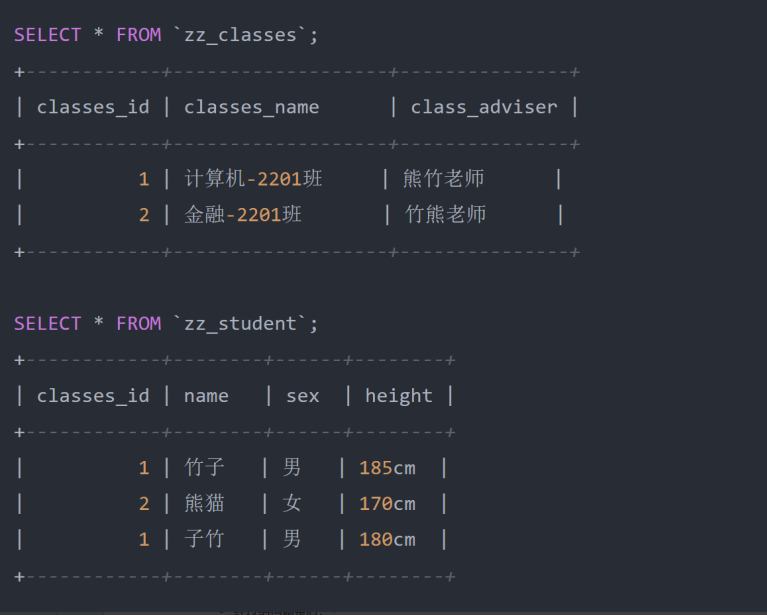
- 经过结构调整后:
- 原本的学生表则又被拆为了班级表、学生表两张,在学生表中只存储班级 ID ,然后使用 classes_id 班级 ID 和 name 学生姓名两个字段作为联合主键。
- 之前的三个问题也不存在,如换班主任后只需要更改班级表,无需修改学生表中的学生信息;增加班 级时,只需要在班级表中新增数据,也不会影响学生表。
- 小结:第三范式只要求非主键字段之间,不能存在依赖关系,但没要求联合主键中的字段不能存在依赖, 因此第三范式并未考虑完善,巴斯-科德范式修正的就是这点,是对第三范式的补充及完善,修正了第三范 式。
1.1.7. 第四范式(4NF)
- 多值依赖:表中的字段之间存在一对多的关系,也就是一个字段的具体值会由多个字段来决定(一个表中 至少需要有三个独立的字段才会出现多值依赖问题)
- 示例:
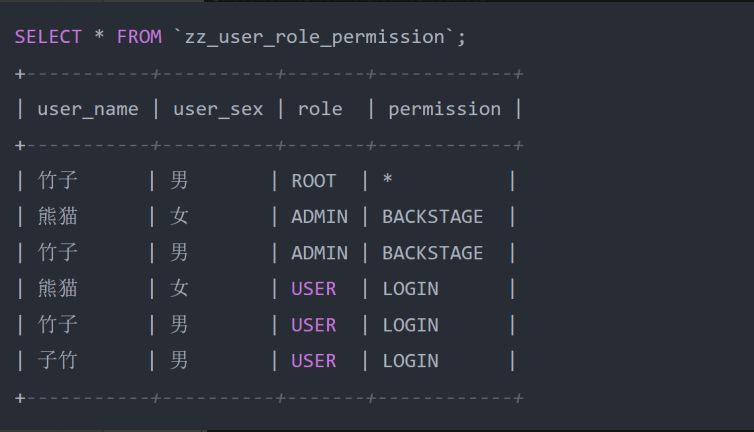 经典的业务,用户角色权限表,各字段含义:
经典的业务,用户角色权限表,各字段含义:
- user_name 字段 -- 用户名
- role 字段 -- 角色信息:
- USER :普通用户角色。ADMIN :管理员角色。
- ROOT :超级管理员角色。
permission 字段 -- 权限信息:
- * :超级管理员拥有的权限级别, * 表示所有。
- BACKSTAGE :管理员拥有的权限级别,表示可以操作后台。
- LOGIN :普通用户拥有的权限级别,表示可以登录访问平台。
- 此时假设我们需要新增一条数据,那表中的权限字段究竟填什么?这个值是需要依赖多个字段决定的,权 限来自于角色,而角色则来自于用户。也就是说,一个用户可以拥有多个角色,同时一个角色可以拥有多 个权限,所以此时咱们无法单独根据用户名去确定权限值,权限值必须依赖用户、角色两个字段来决定, 这种一个字段的值取决于多个字段才能确定的情况,就被称为多值依赖。
- 因此第四范式的定义就是要消除表中的多值依赖关系,上述表格拆分为:
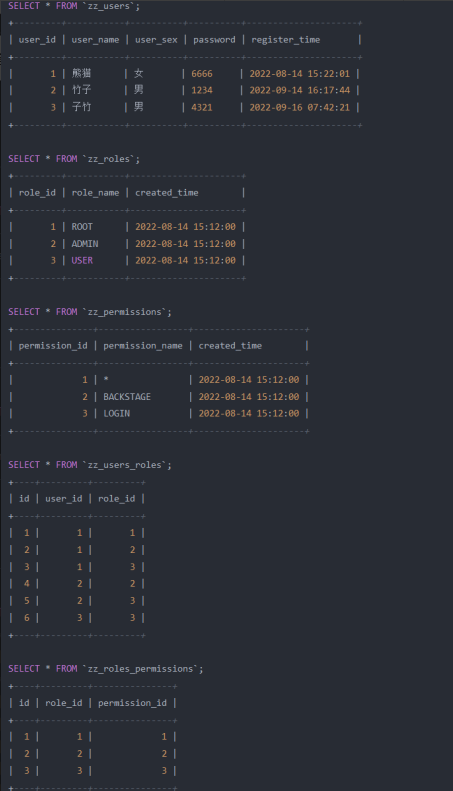
- 观察上述的五张表正是大名鼎鼎的权限五表,将原本的用户角色权限表,拆分成了用户表、角色表、权限 表、用户角色关系表、角色权限关系表。
- 经过这次拆分之后,一方面用户表、角色表、权限表中都不会有数据冗余,第二方面无论是要删除亦或新 增一个角色、权限时,都不会影响其他表。后面的两张关系表,主要是为了维护用户、角色、权限三者之 间的关系。
1.1.8. 第五范式(5NF)/完美范式
- 定义:建立在 4NF 的基础上,进一步消除表中的连接依赖,直到表中的连接依赖都是主键所蕴含的
- 第五范式解决的是无损连接问题,基本没有实际意义,了解即可,因为无损连接很少出现,而且难以察觉
1.1.9. 第六范式(6NF)/域键范式
- 域键范式,也被称之为终极范式,但目前也仅有学术机构在研究,在生产环境中实际的用途也不大
1.1.10. 反范式
- 概念:不遵循数据库范式设计的结构,就被称为反范式结构。
- 遵循数据库范式设计优点如下:
- 避免了大量的数据冗余
- 节省了大量存储空间
- 表整体结构更为优雅,能让 SQL 操作更加便捷且减少出错。
- 但随着范式的级别越高,设计出的结构会更加精细化,原本一张表的数据会被分摊到多张表中存储,表的 数量随之越来越多。会存在一个致命问题,也就是当同时需要这些数据时,只能采用联表查询的形式检索 数据,有时候甚至为了一个字段的数据,也需要做一次连表查询才能获得。这其中的开销无疑是花费巨大 的,尤其是当连接的表不仅两三张而是很多张时,有可能还会造成索引失效,这种情况带来的资源、时间 开销简直是一个噩梦,这会严重地影响整个业务系统的性能。
- 因此,也正是由于上述一些问题,在设计库表结构时,我们不一定要 100% 遵守范式准则。这种违反数据库 范式的设计方法,就被称之为 反范式设计。
- 设计原则:无论那种范式只要能够对业务有利,那就可以称之为好的设计方案。在设计时千万不要拘泥于 规则之内,一定要结合实际业务考虑,遵循业务优先的原则去设计结构.
- 注意:不是所有不遵循数据库范式的结构设计都被称为反范式,反范式设计是指自己知道会破坏范式,但 对业务带来好处大于坏处时,刻意设计出破坏范式的结构。
1.1.11. 数据库范式设计总结
- 经过一系列的阐述后,其实不难发现,越到后面的范式,越难令人理解,同时为了让表满足更高级别的范 式,越往后付出代价也越大,而且拆分出的表数量也会越多
- 一般项目中仅需满足到第三范式或 BC 范式即可,因为这个度刚刚好,再往后就会因为过于精细化设计,导 致整体性能反而下降。
- 控制到第三范式的级别,一方面数据不会有太多冗余,第二方面也不会对性能影响过大。同时,如若打破 范式的设定能对业务更有利,那也可以违背范式原则去设计。
- 生产项目中库表结构设计的是否合理,区别如下:
- 不合理的结构设计会造成的问题:
- 数据冗余,会浪费一定程度上的存储空间
- 不便于常规 SQL 操作(例如插入、删除),甚至会出现异常
- 合理的结构设计带来的好处:
- 节省空间, SQL 执行时能节省内存空间,数据存储时能节省磁盘空间
- 数据划分较为合理, DB 性能整体较高,并且数据也非常完整
- 结构便于维护和进行常规 SQL 操作
- 各范式之间的递进关系图:
- 范式概念:
- 第一范式:原子性,每个字段的值不能再分。
- 第二范式:唯一性,表内每行数据必须描述同一业务属性的数据。
- 第三范式:独立性,表中每个非主键字段之间不能存在依赖性。
- 巴斯范式:主键字段独立性,联合主键字段之间不能存在依赖性。
- 第四范式:表中字段不能存在多值依赖关系。
- 第五范式:表中字段的数据之间不能存在连接依赖关系。
- 域键范式:试图研究出一个库表设计时的终极完美范式。