主题分析建模用法介绍
1.主题建模分析介绍
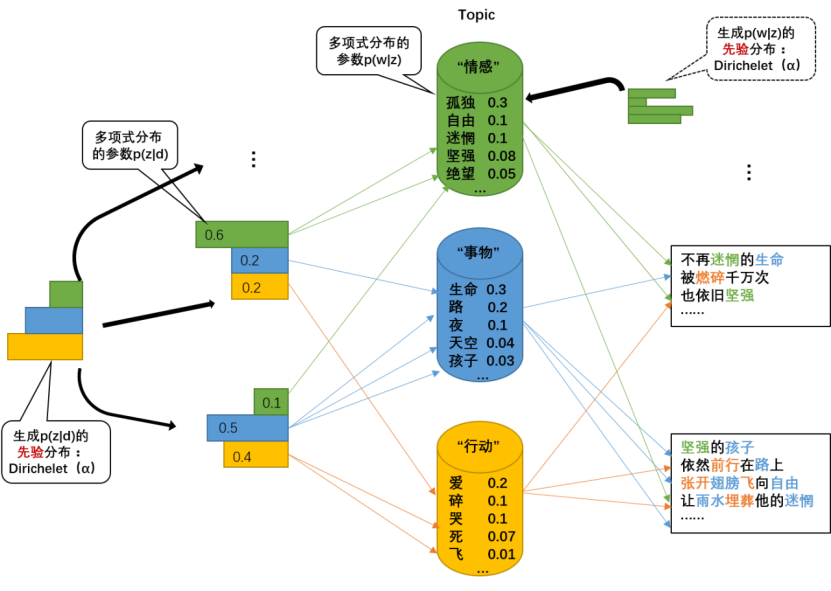
主题分析建模(LDA)是一种文本分析方法,用于从大量文本数据中提取潜在的主题或话题,它可以帮助我们理解和概况文本数据集中的内容,并发现其中的相关模式和趋势。
在文本分析建模中,文本数据集通常被表示为一个文档——词矩阵,其中每个文档都由一组词语构成,主题模型的目标是通过分析这些文档——词矩阵,将文本数据集中的词语聚类成不同的主题。
主题可以理解为概念、主要内容或者感兴趣的话题,在文本数据集中,每个主题都由一组相关的词语组成,而最常见的狄利克雷分配模型能够通过统计模型和机器学习算法来识别并提取这些主题。
通过主题分析建模,可以得到以下信息:
(1) 主题关键词:每个主题都有与之相关的关键词,这些关键词可以用来描述和概况该主题。
(2) 文档的主题分布:对于每个文档,我们可以了解到它属于哪些主题以及在这些主题上的权重分布,这可以用来比较文档之间的相似性和差异性。
(3) 文本聚类和分类:通过将文档归类到不同的主题上,可以进行文本聚类和分类,从而组织和理解大量的文本数据。
2.用法
2.1主题分析建模训练函数
下面的表解释了参数:
| 入参 | 类型 | 意义 | 说明 |
| data_table | TEXT | 存储训练数据集的表的名称 | |
| model_table | TEXT | 生成的一个输出表,包含学习到的模型,为一行。 | |
| output_data_table | TEXT | 由LDA生成的表,存储输出数据,它的名称称为数据表。 | |
| voc_size | INTEGER | 词汇表的大小。 | 如前面提到的输入的’ data_table’,由从0到voc_size之间连续的整数组成。 |
| topic_num | INTEGER | 期望的主题数量。 | |
| iter_num | INTEGER | 最大迭代次数,如果设置了’ perplexity_tol’,当达到容限时,LDA可能进行的迭代次数会少于最大迭代次数。 | |
| alpha | DOUBLE PRECISION | 每个文档的主题多项式的狄利克雷先验。 | 根据Griffiths和Steyvers,50/topic_num是一个合理的起始值。 |
| beta | DOUBLE PRECISION | 每次主题的词多项式的狄利克雷先验。 | 0.01是一个合理的起始值。 |
| evaluate_every(可选) | INTEGER | 评估困惑度的频率。 | 默认值为0。将其设置为0或者负数,以完全不在训练中评估困惑度,评估困惑度可以帮助您在训练过程中检查收敛性,但也会增加总体训练时间。例如,每次迭代评估困惑度可能会将训练时间增加一倍。 |
| perplexity_tol | DOUBLE | 停止迭代的困惑度容限(默认值:0.1)。 | 仅在参数’evaluate_every’大于1时使用。 |
<data_table>l
| 列名 | 类型 | 含义 |
| docid | INTEGER | 文档id。为非负整数。 |
| wordid | INTEGER | 词汇表中的词id(词在词汇表中的索引) 注:wordid必须为0到voc_size-1之间的连续整数。 |
| count | INTEGER | 词在文档中出现的次数。非负整数。 |
注:可以使用术语频率(Term Frequency)函数从原始文档中生成所需格式的词汇表。
<model_table>
| 列名 | 类型 | 含义 |
| voc_size | INTEGER | 词汇表的大小,为0到voc_size-1之间的连续整数组成。 |
| topic_num | INTEGER | 主题的数量。 |
| alpha | DOUBLE PRECISION | 用于每个文档的主题多项式的狄利克雷先验。 |
| beta | DOUBLE PRECISION | 用于每个主题的词多项式的狄利克雷先验。 |
| model | BIGINT[] | 编码的模型描述(人类不可读)。 |
| num_iterations | INTEGER | 训练运行的迭代次数。如果达到了困惑度容忍限度,可能会少于参数’iter_num’指定的最大值。 |
| perplexity | DOUBLE PRECISION[] | 根据参数”evaluate_every’生成困惑度值的数组,以及最后一个迭代的困惑度值。 |
| perplexity_iters | INTEGER[] | 指示计算困惑度的迭代次数的数组,根据参数’iter_num’和’evaluate_every’得出。例如,如果’ iter_num=5’, ‘evaluate_every=2’,那么’ perplexity_iters’的值将为{2,4,5},表示在迭代2、4和5(最后)计算困惑度,除非由于’ perplexity_tol’而提前终止。如果’ iter_num=5’, ‘evaluate_every=1’,那么’ perplexity_iters’的值将为{1,2,,3,4,5},表示在每个迭代都计算困惑度(假设运行了全部迭代次数)。 |
<output_data_table>
这是一个由LDA生成的表,存储输出数据,它的名称称为数据表。
| 列名 | 类型 | 含义 |
| docid | INTEGER | 输入数据表的文档id。 |
| wordcount | INTEGER | 文档中的单词数,包括重复出现的单词。例如,如果单词在文档中出现3次,则它在计数器中被计算为3次。 |
| words | INTEGER[] | 文档中不包括重复单词的单词数组。例如,如果单词在文档中出现3次,则它在数组中只会出现1次。 |
| counts | INTEGER[] | 单词在文档中出现的频率,索引与上面的数组相同。例如,如果数组的第2个元素是4,表示数组中第2个元素对应的单词在文档中出现了4次。 |
| topic_count | INTEGER[] | 文档中对应于每个主题的单词计数数组。该数组的长度为主题数量,主题ID是连续的整数,从0到主题数量减1。 |
| topic_assignment | INTEGER[] | 指示文档中每个单词对应的主题的数组。该数组的长度为单词数,重复出现的单词将连续出现多次。 |
2.2主题分析建模预测函数
| 入参 | 类型 | 意义 | 说明 |
| data_table | TEXT | 测试数据集的表名 | |
| model_table | TEXT | 训练过程中生成的模型表 | |
| output_predict_table | TEXT | 预测输出表 | 表中的每一行存储了数据集中一个文档的主题分布和主题分配,该表的列和解释与上述训练函数的’output_data_table’完全相同。 |
2.3主题分析模型困惑度
模型困惑度通过计算单词似然值的平均数来描述模型与数据的拟合程度,该函数返回一个单一的模型困惑度值。
参数介绍如下所示:
| 入参 | 类型 | 意义 | 说明 |
| model_table | TEXT | 训练过程中生成的模型表。 | |
| output_data_table | TEXT | 由训练或者预测函数生成的输出表,包含按单词进行的主题分配。 |
对于主题模型而言,选定的算法一旦确定,需要人为确定的选项(超参),通常是主题数量,LDA算法也不例外:主题数量通常视不同场景进行调整,即通过评估不同主题数模型的困惑度来选择最优的模型主题数。
计算困惑度公式:
其中,M是测试语料的大小(文档的数量),
是第d篇文档大小(word或者token个数)。
其中,z是主题,w是文档,r是基于训练集学习的文本-主题分布,简而言之,perplexity对数函数的分子部分是生成整个文档集的似然估计(表示训练集训练出的参数生成能力)的负数,由于概率取值范围为[0,1],按照对数函数的定义,分子值是一个正值且与文本生成能力正相关;而分母是整个文档集的单词数目。所以,模型生成能力越强,perplexity的值越小。
3.总结
主题分析建模是一种文本分析方法,用于从大量文本数据中提取潜在的主题或话题,它可以帮助我们理解和概况文本数据集中的内容,并发现其中的相关模式和趋势。
在文本分析建模中,文本数据集通常被表示为一个文档——词矩阵,其中每个文档都由一组词语构成,主题模型的目标是通过分析这些文档——词矩阵,将文本数据集中的词语聚类成不同的主题。
主题可以理解为概念、主要内容或者感兴趣的话题,在文本数据集中,每个主题都由一组相关的词语组成,而最常见的狄利克雷分配模型能够通过统计模型和机器学习算法来识别并提取这些主题。