transformer 笔记 tokenizer moe
(超爽中英!) 2025吴恩达大模型【Transformer】原理解析教程!附书籍代码 DeepLearning.AI_哔哩哔哩_bilibili
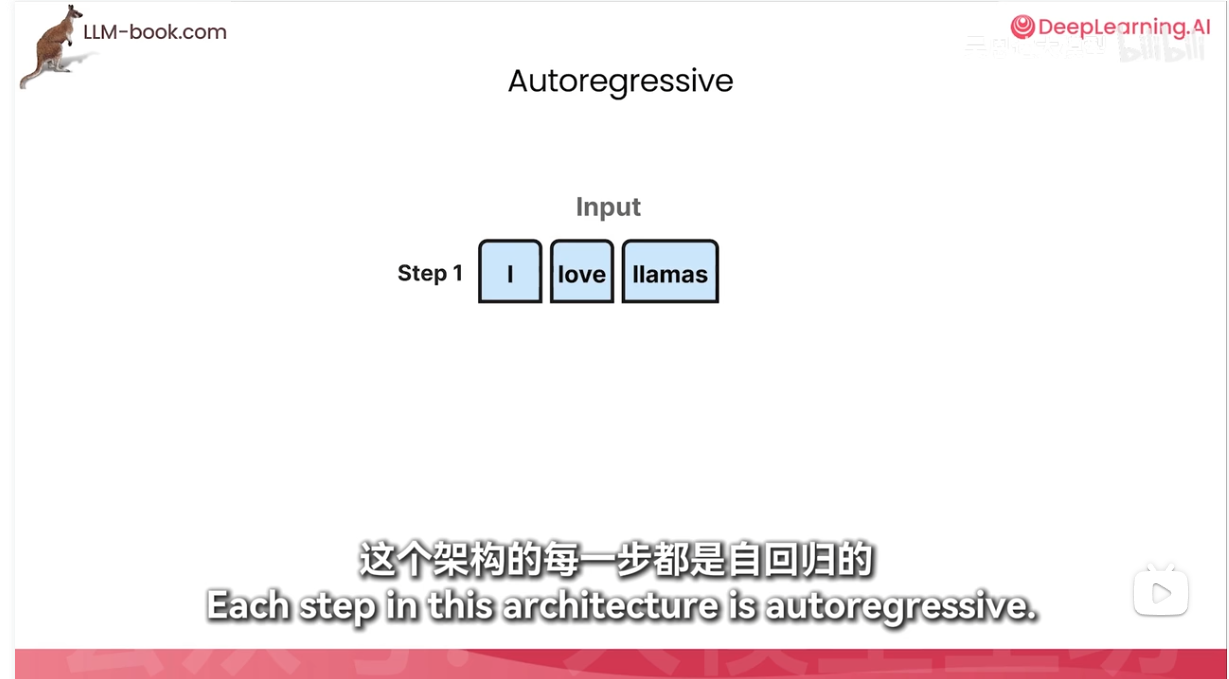
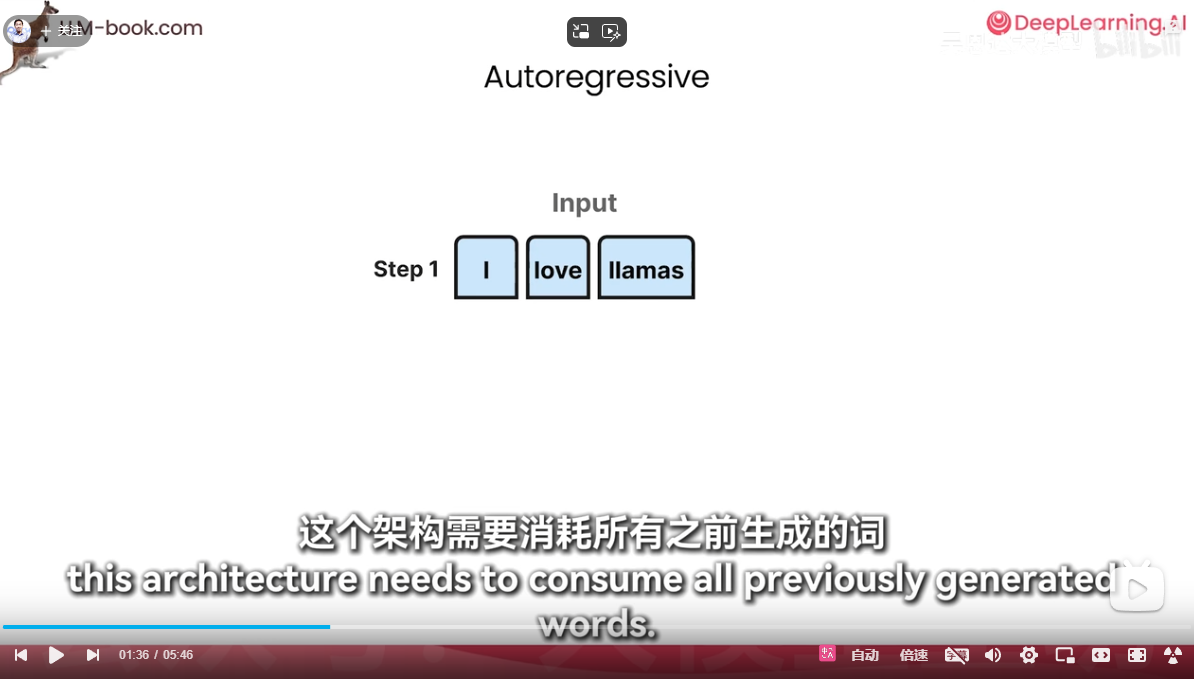
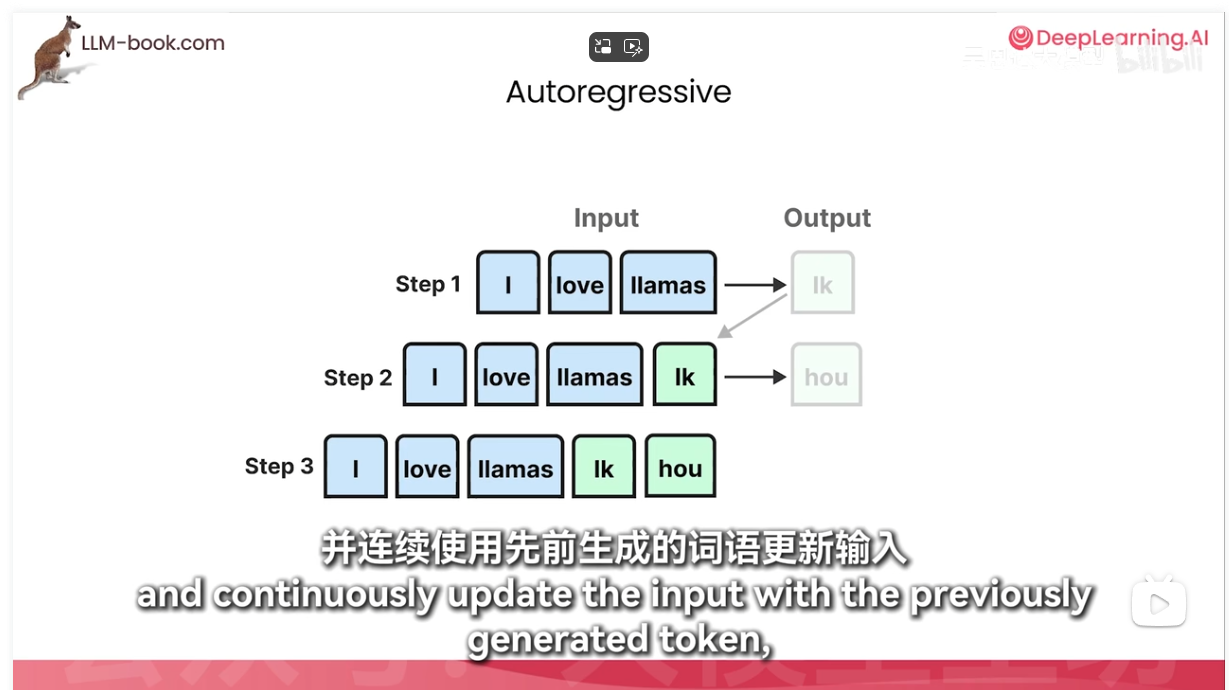
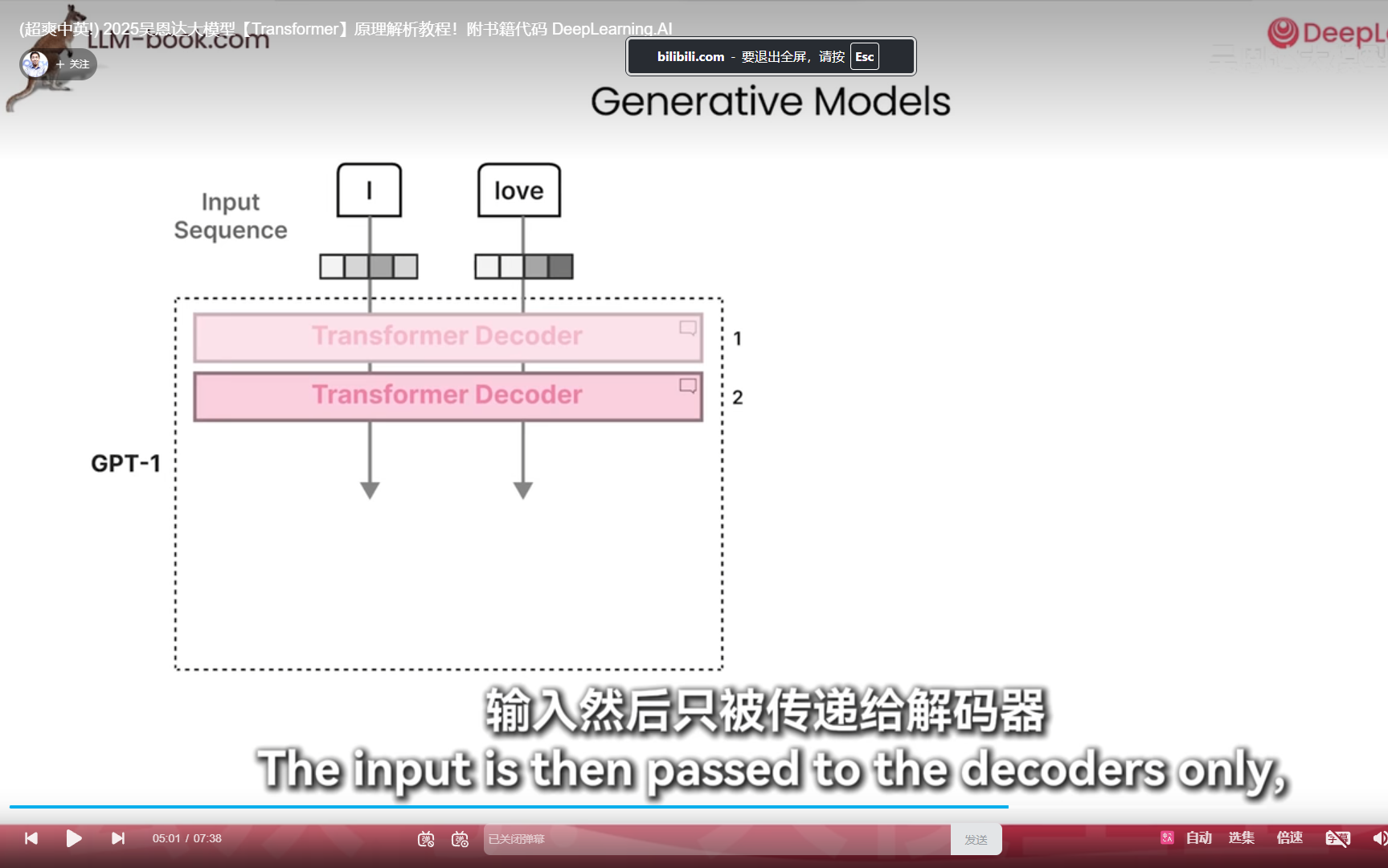
自回归就是上文全部阅读
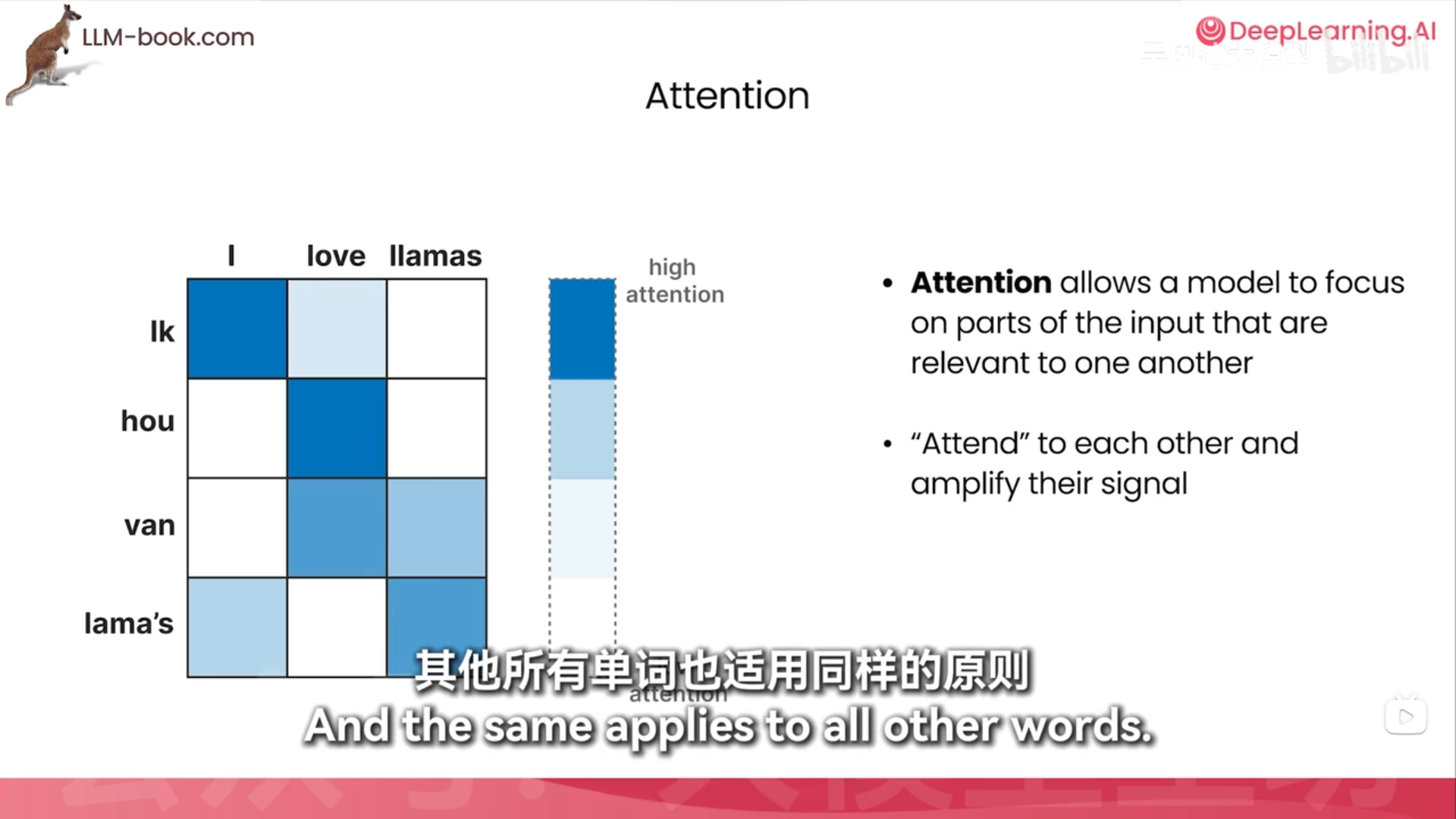
好像学过了,向量互乘好像

transformer不需要rnn
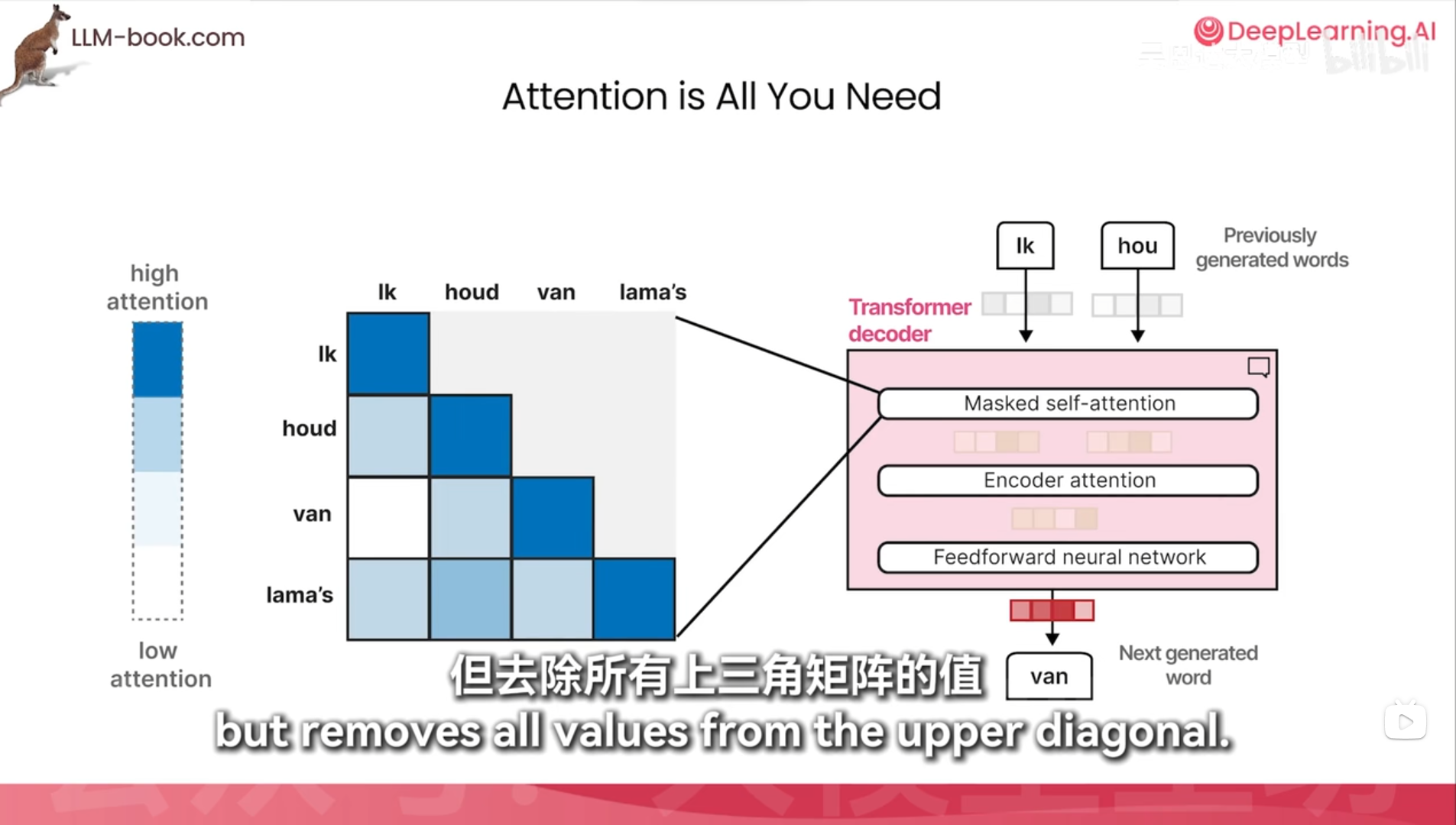
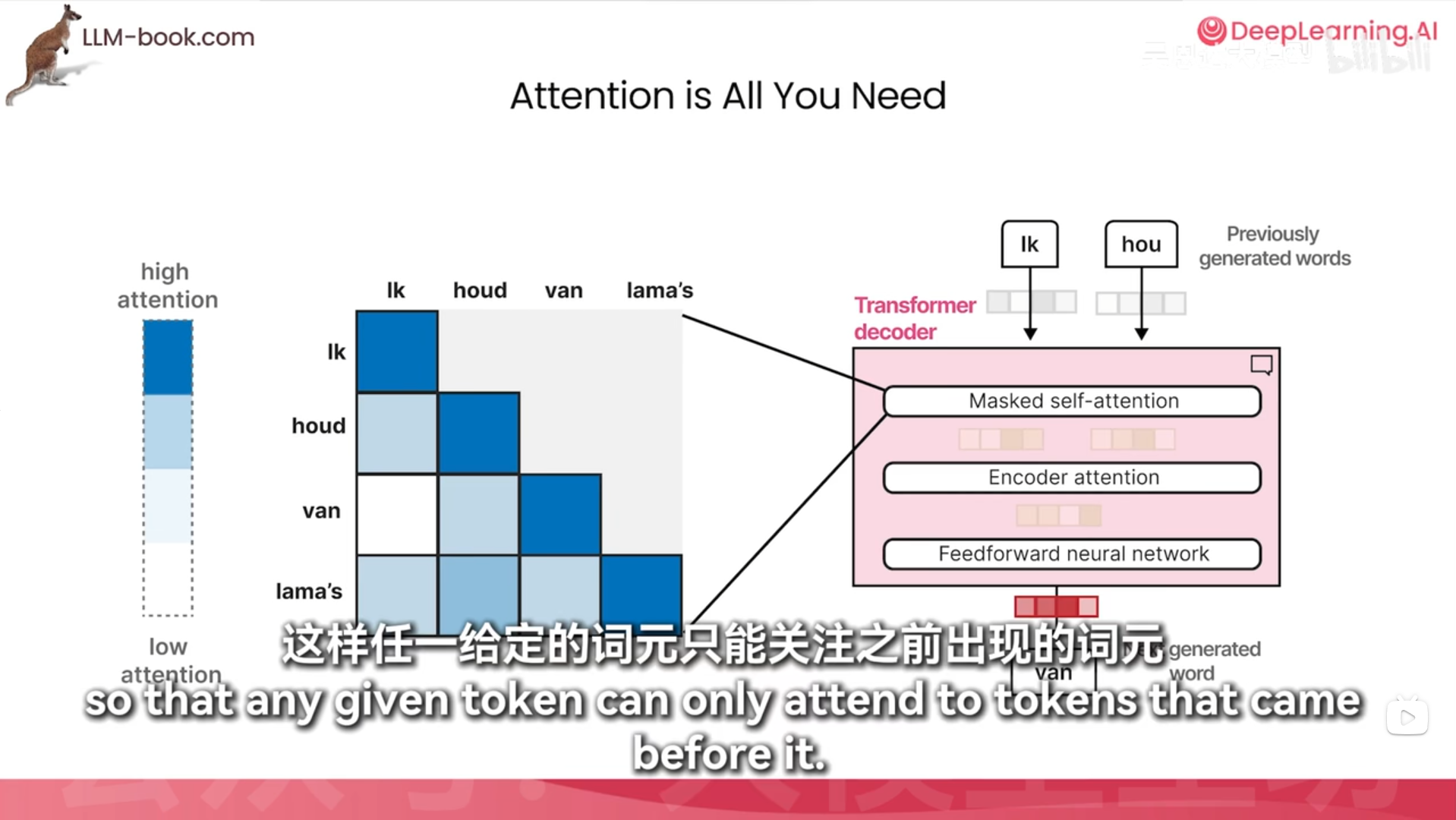
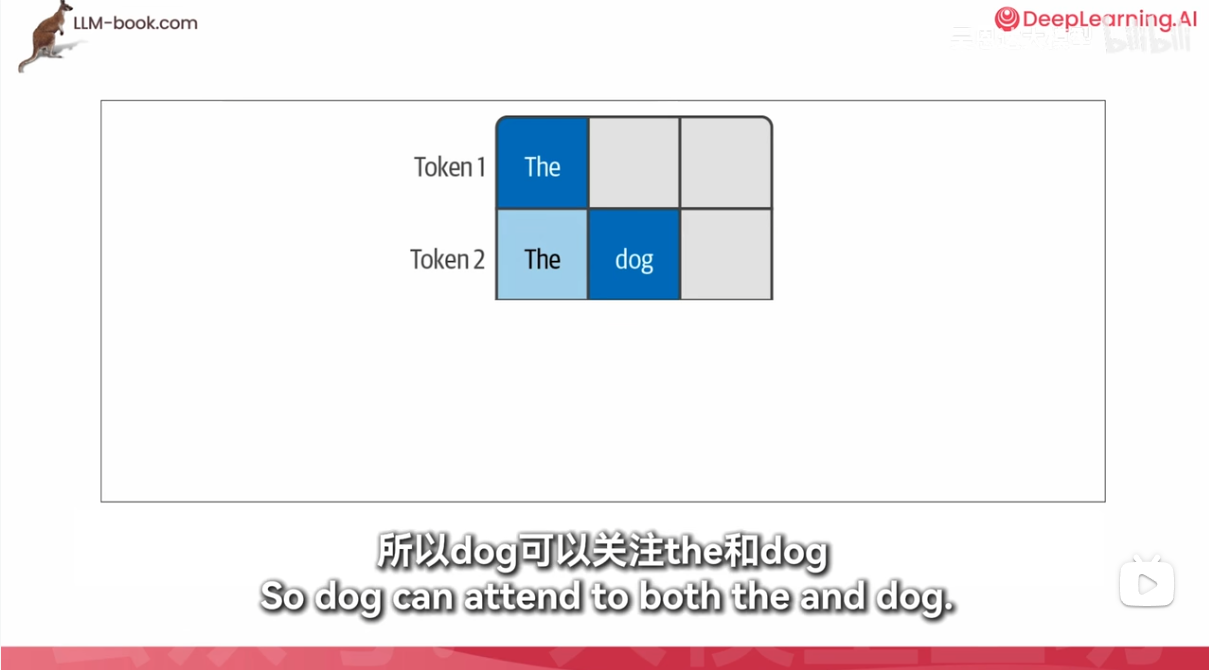
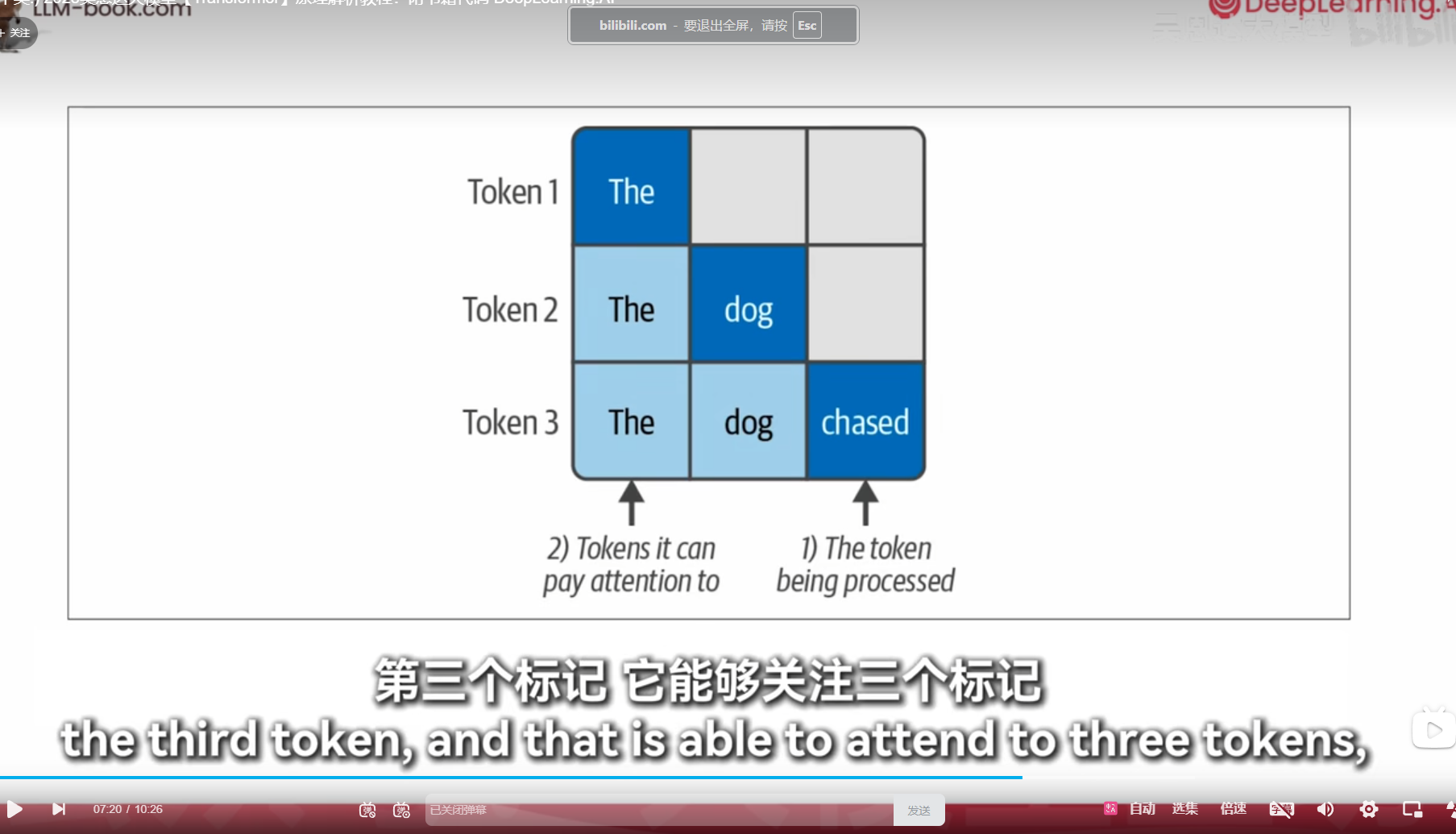
掩码自注意力
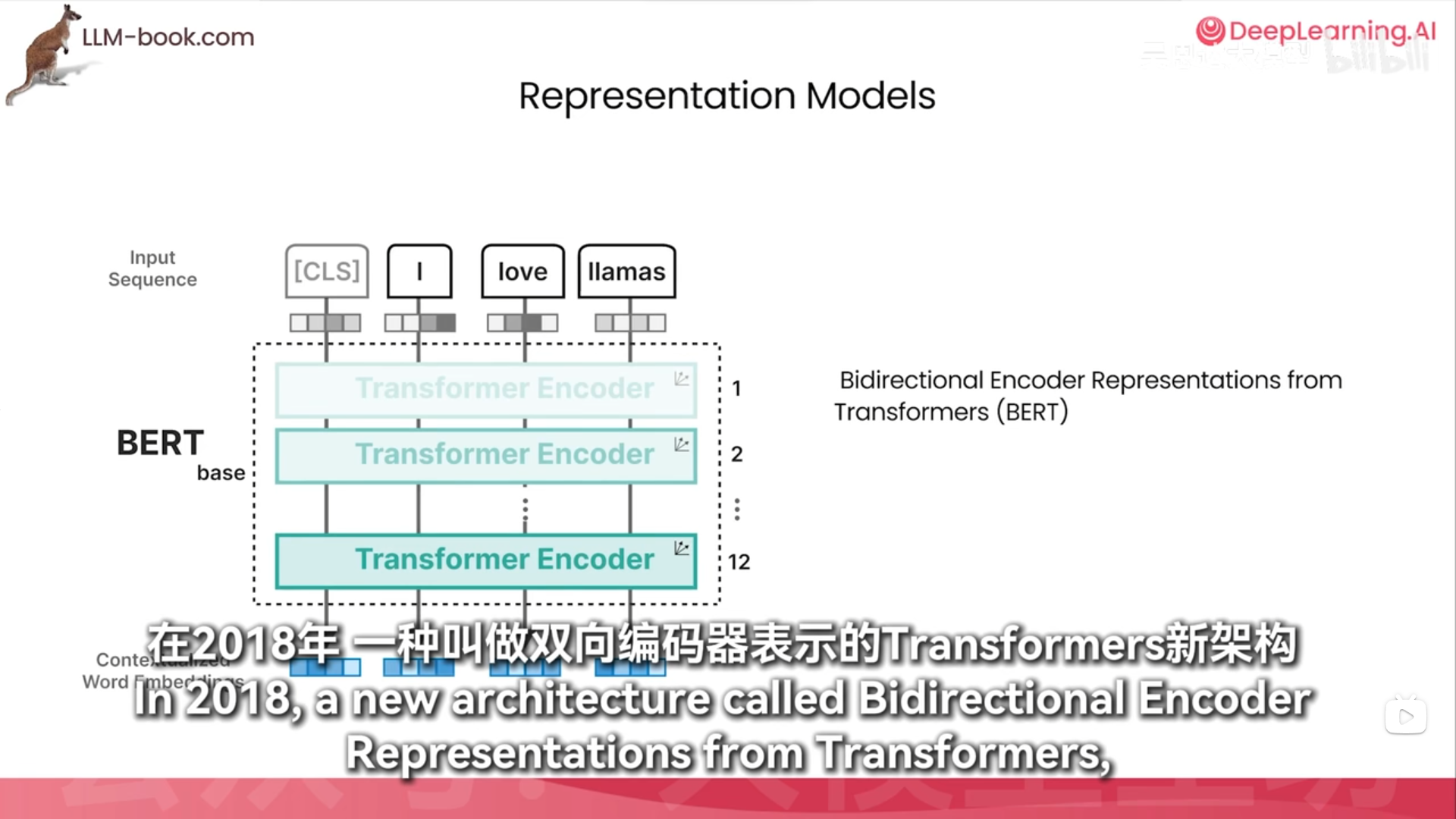
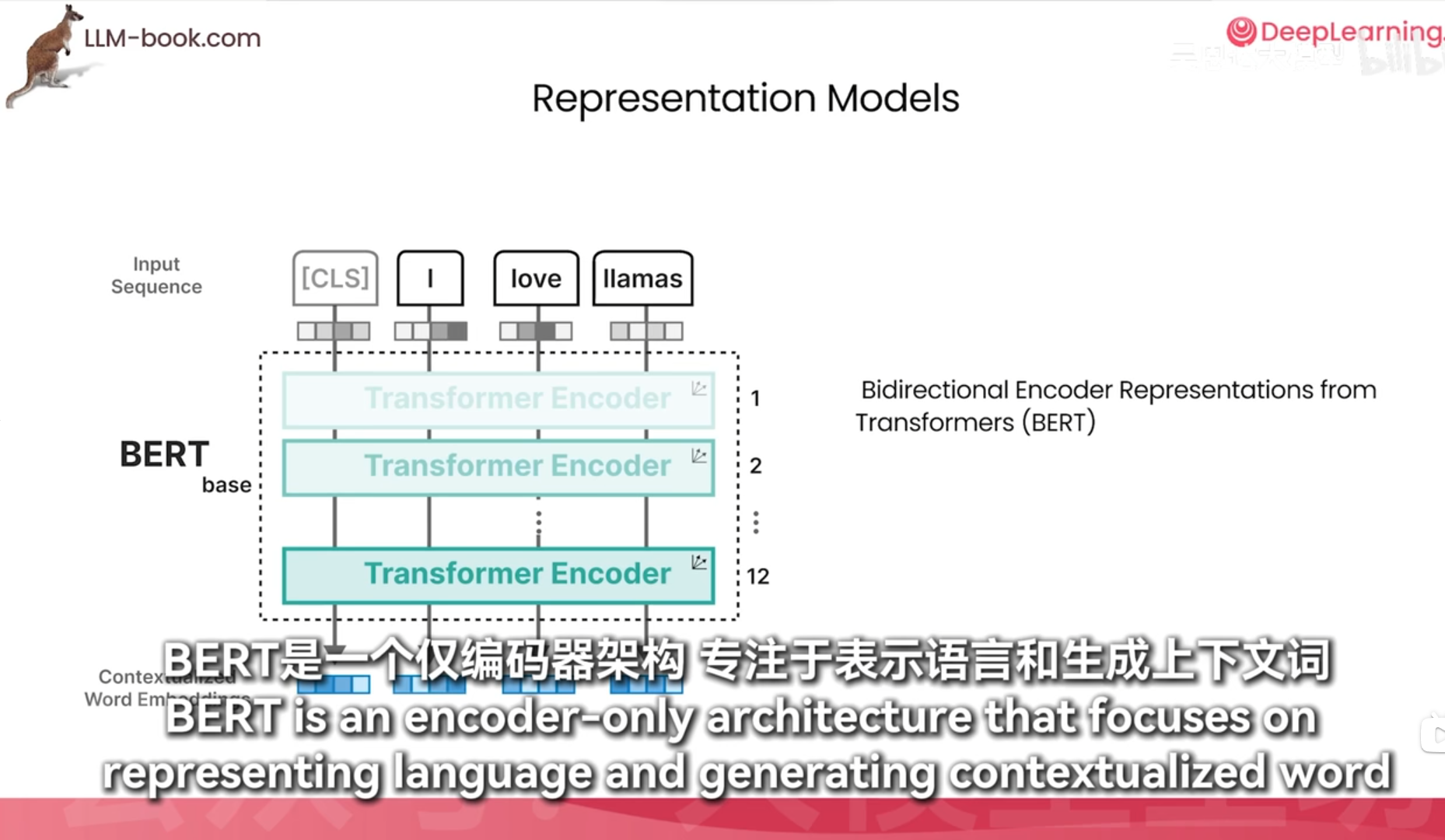
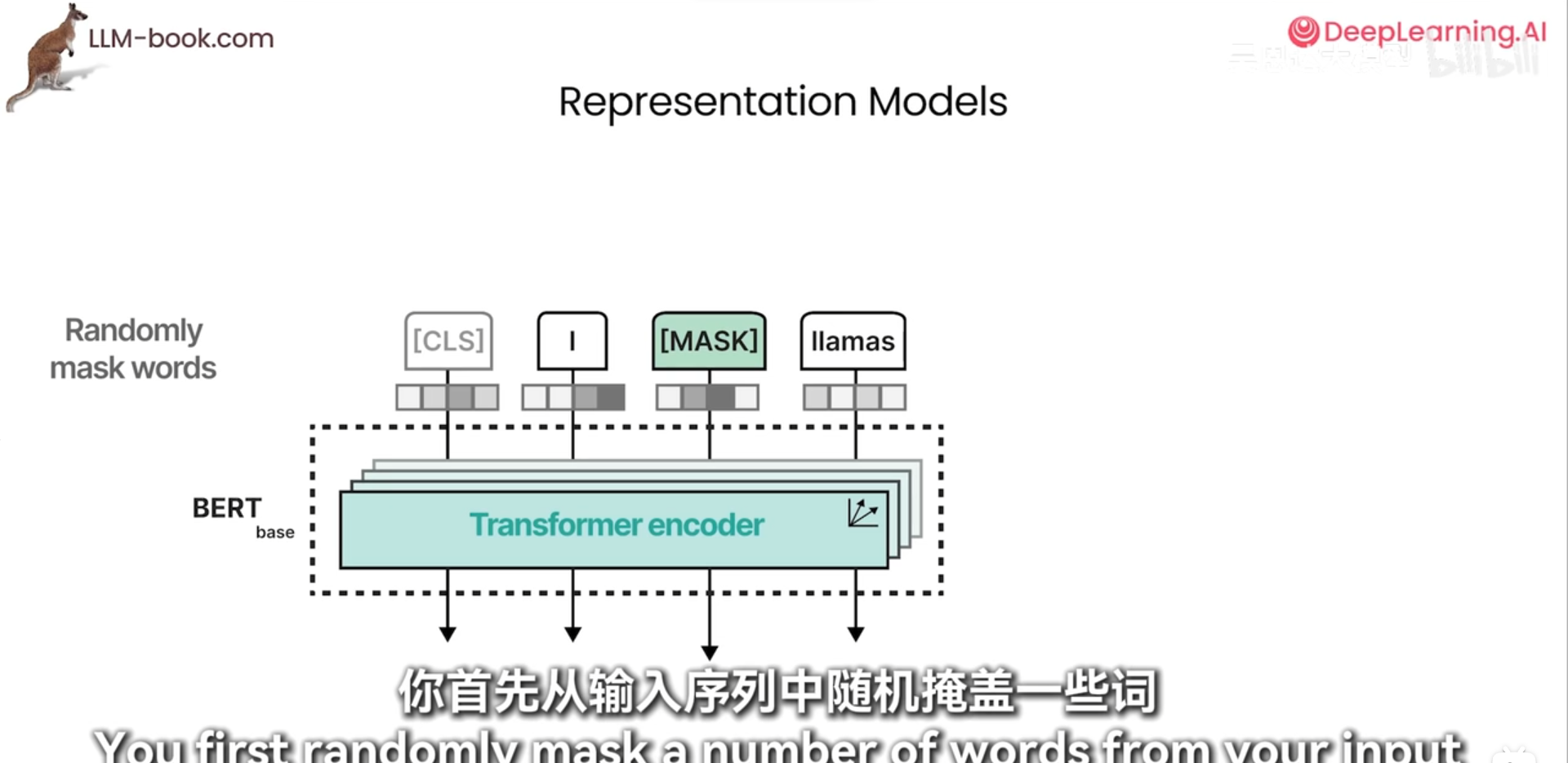
训练bert
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, embed_size, bias=False)self.keys = nn.Linear(self.head_dim, embed_size, bias=False)self.queries = nn.Linear(self.head_dim, embed_size, bias=False)self.fc_out = nn.Linear(embed_size, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into self.heads different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.embed_size)out = self.fc_out(out)return outclass TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size),)self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass GPT1Decoder(nn.Module):def __init__(self, vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):super(GPT1Decoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion,)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)out = self.fc_out(out)return out# 参数设置
embed_size = 256
heads = 8
num_layers = 6
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
forward_expansion = 4
dropout = 0.1
max_length = 100# 初始化模型
model = GPT1Decoder(1000, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length).to(device)
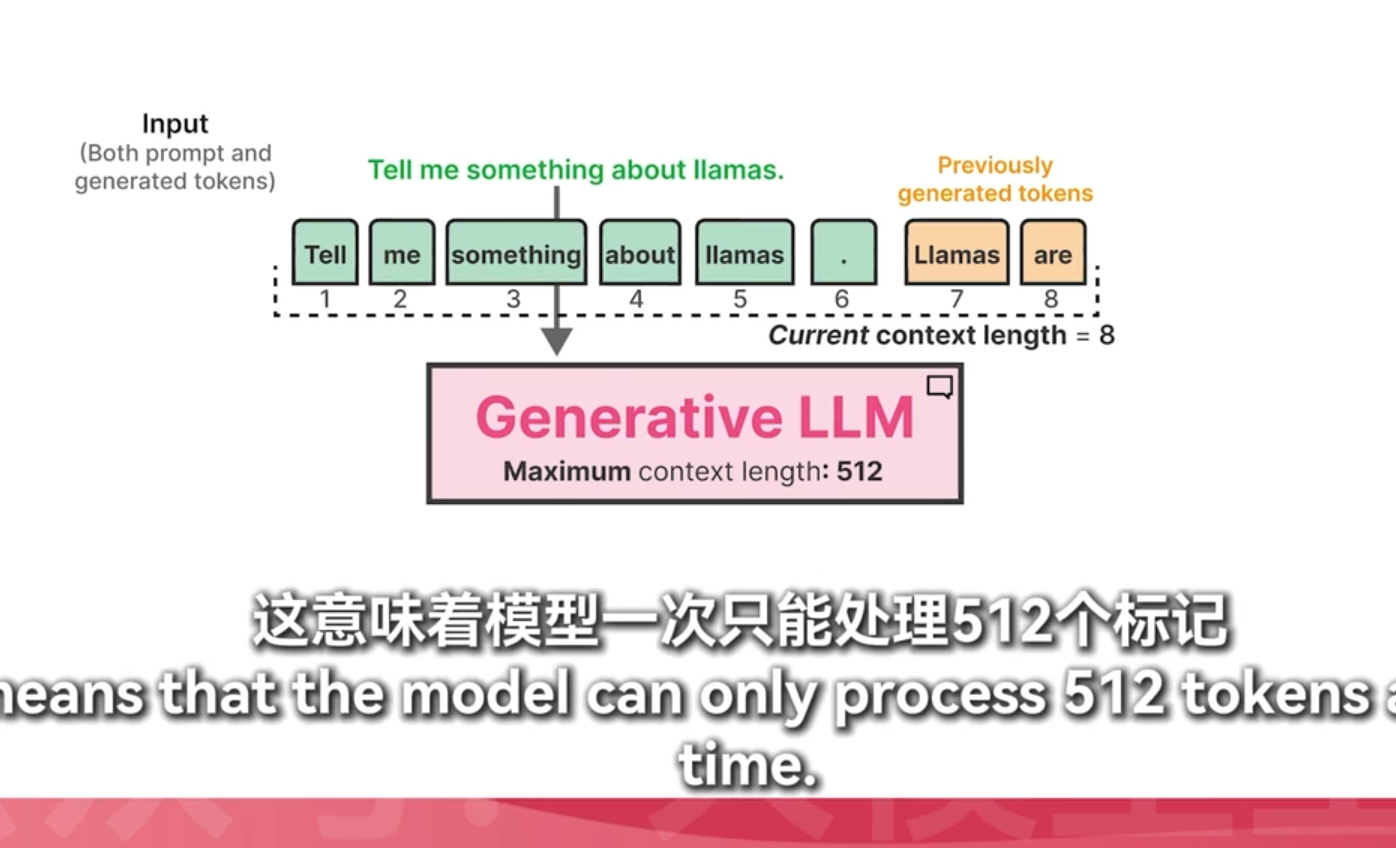
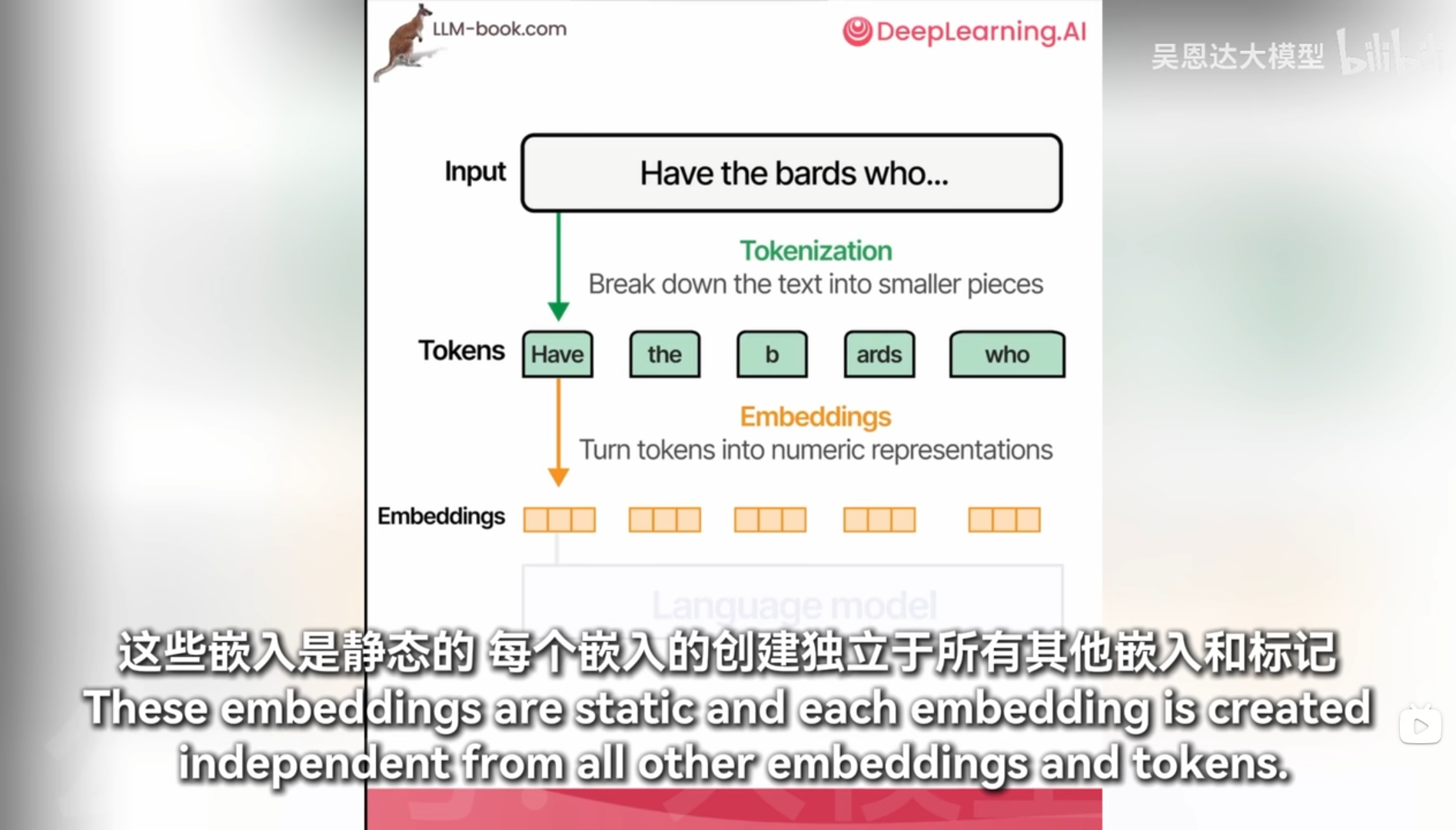
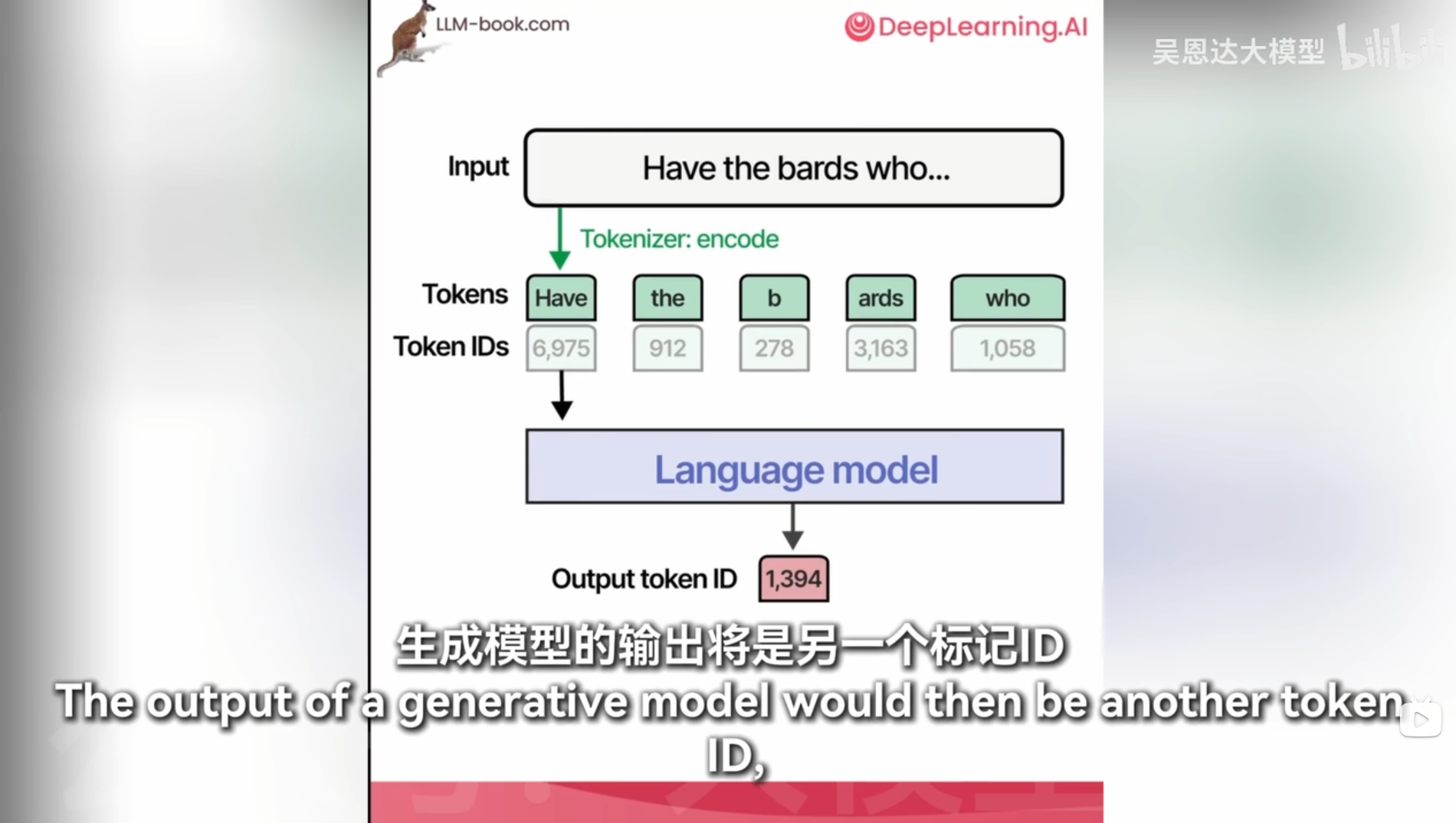
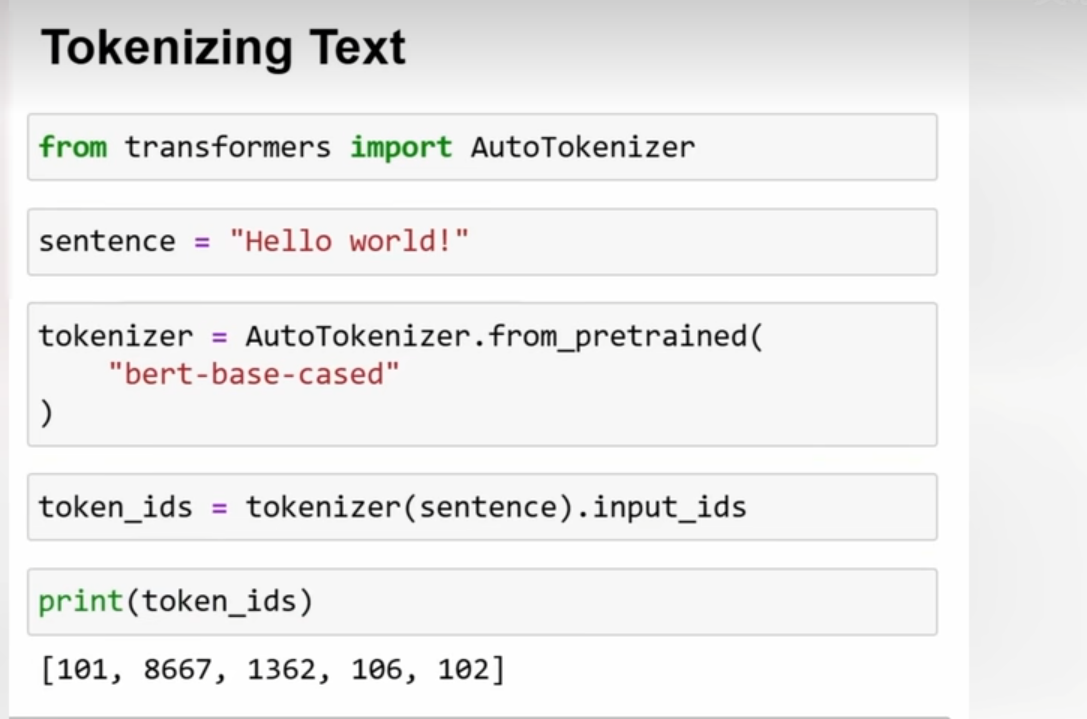
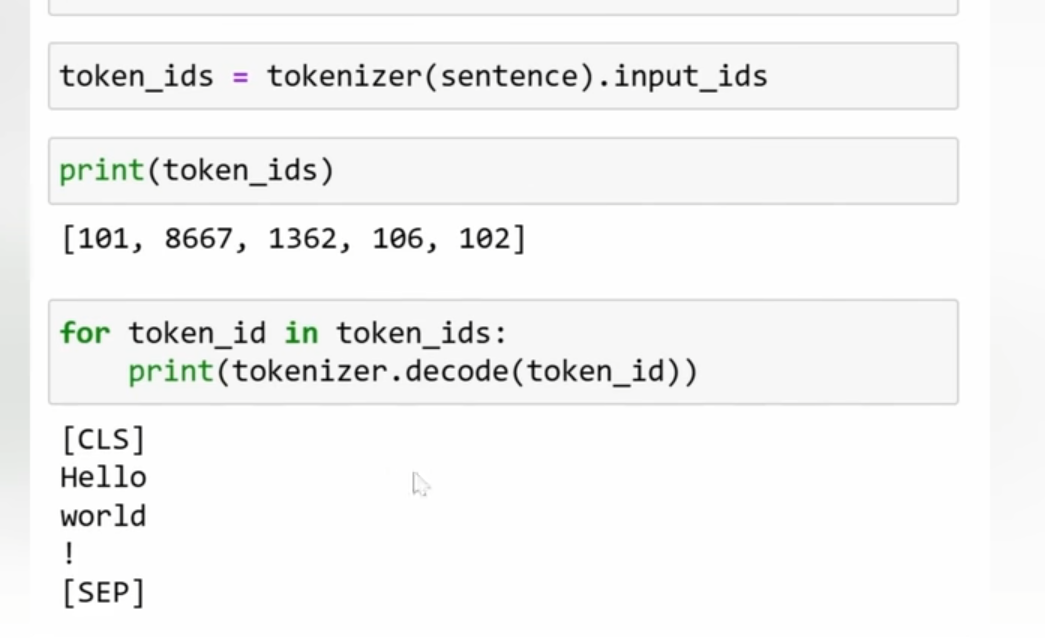


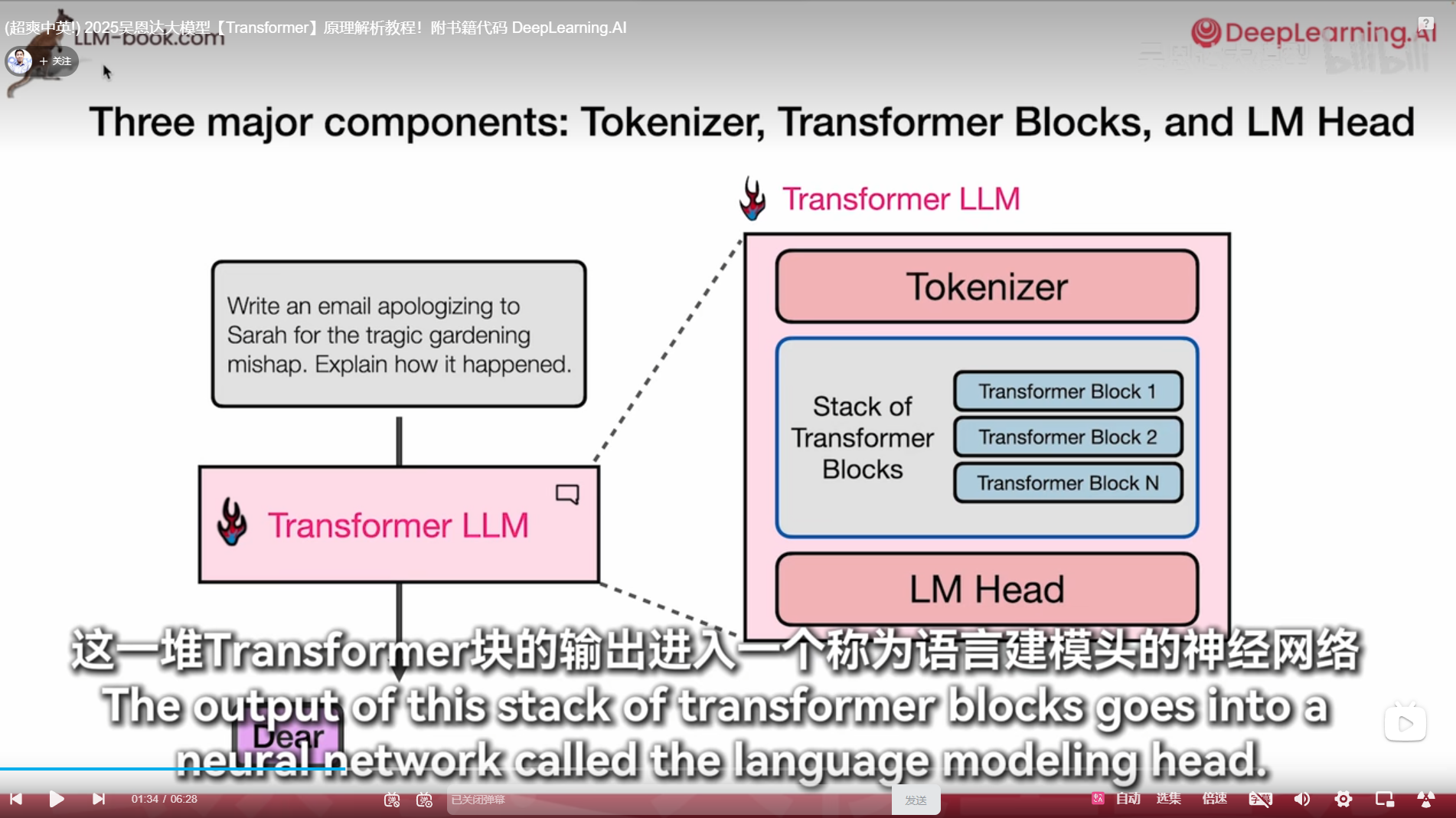
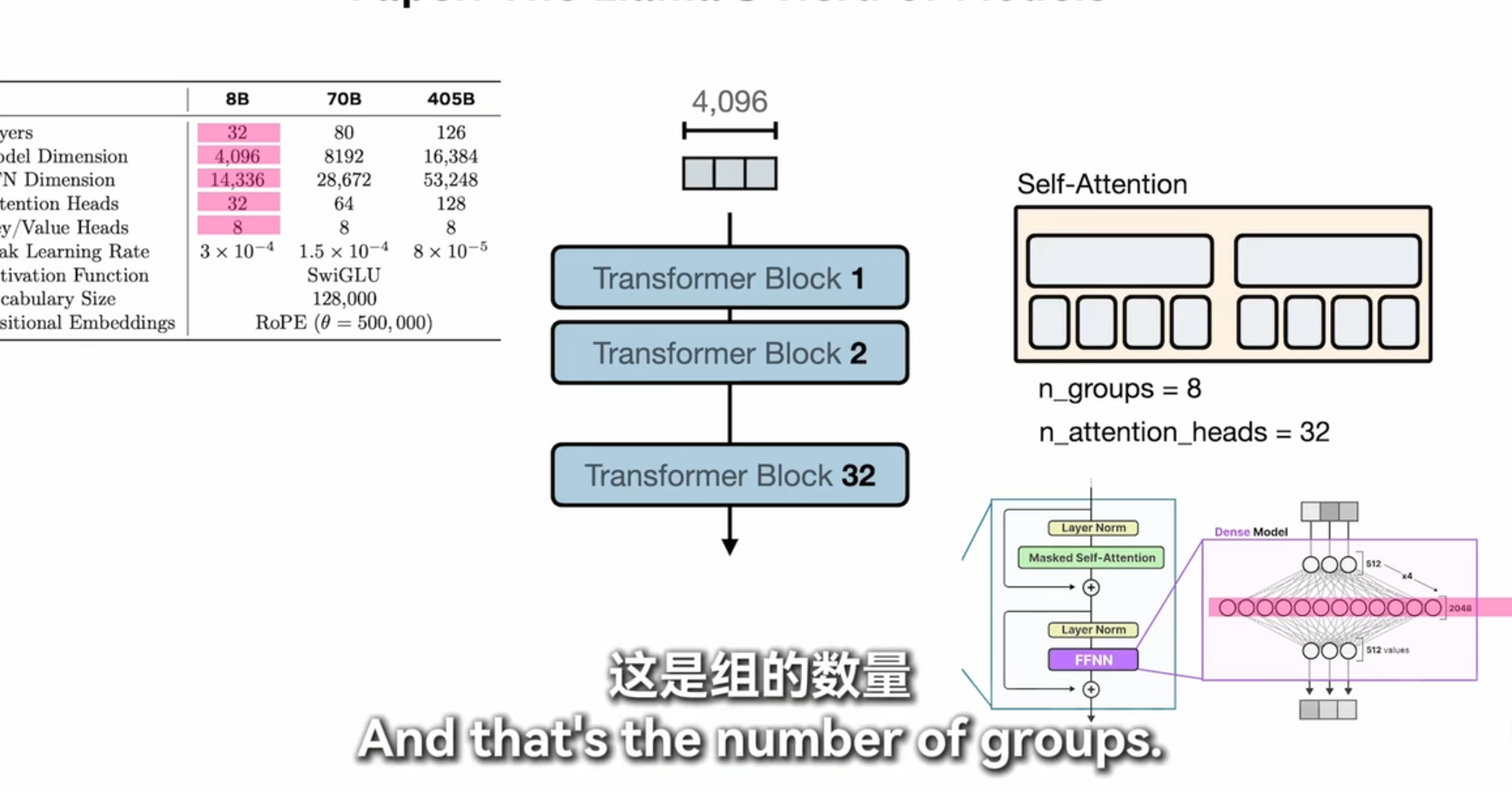
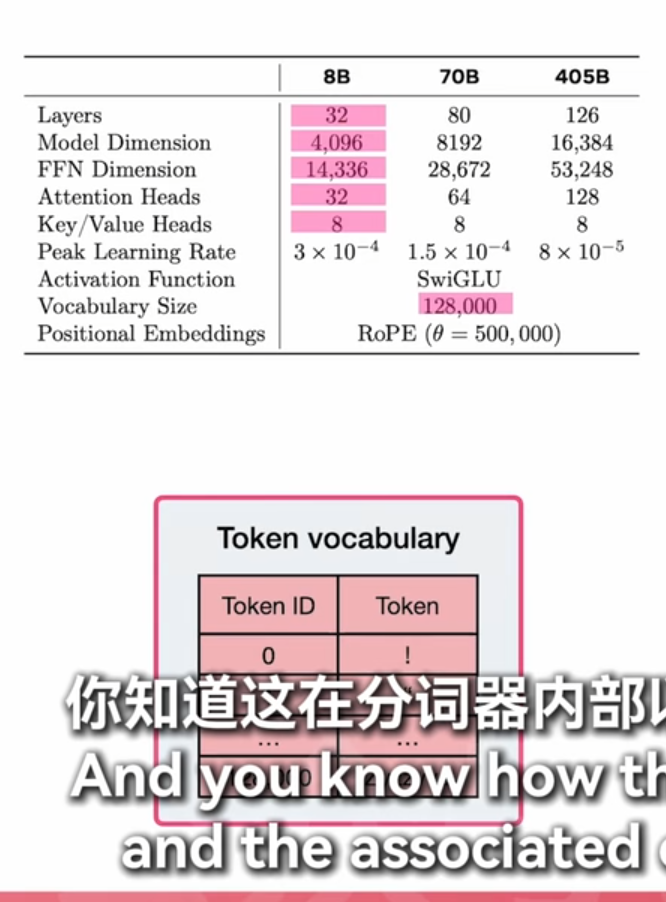
词汇量多一次读取的消耗token就少
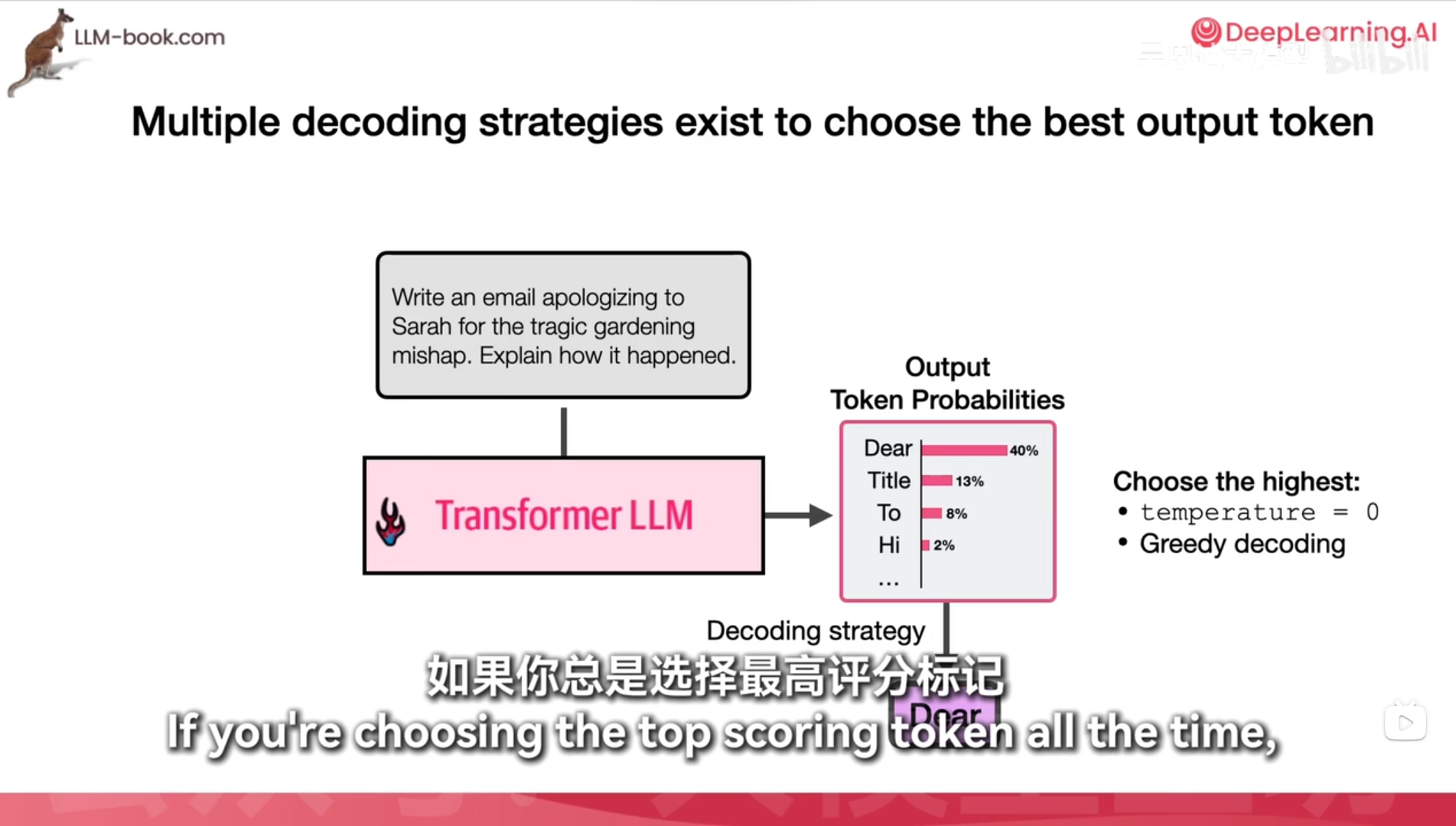
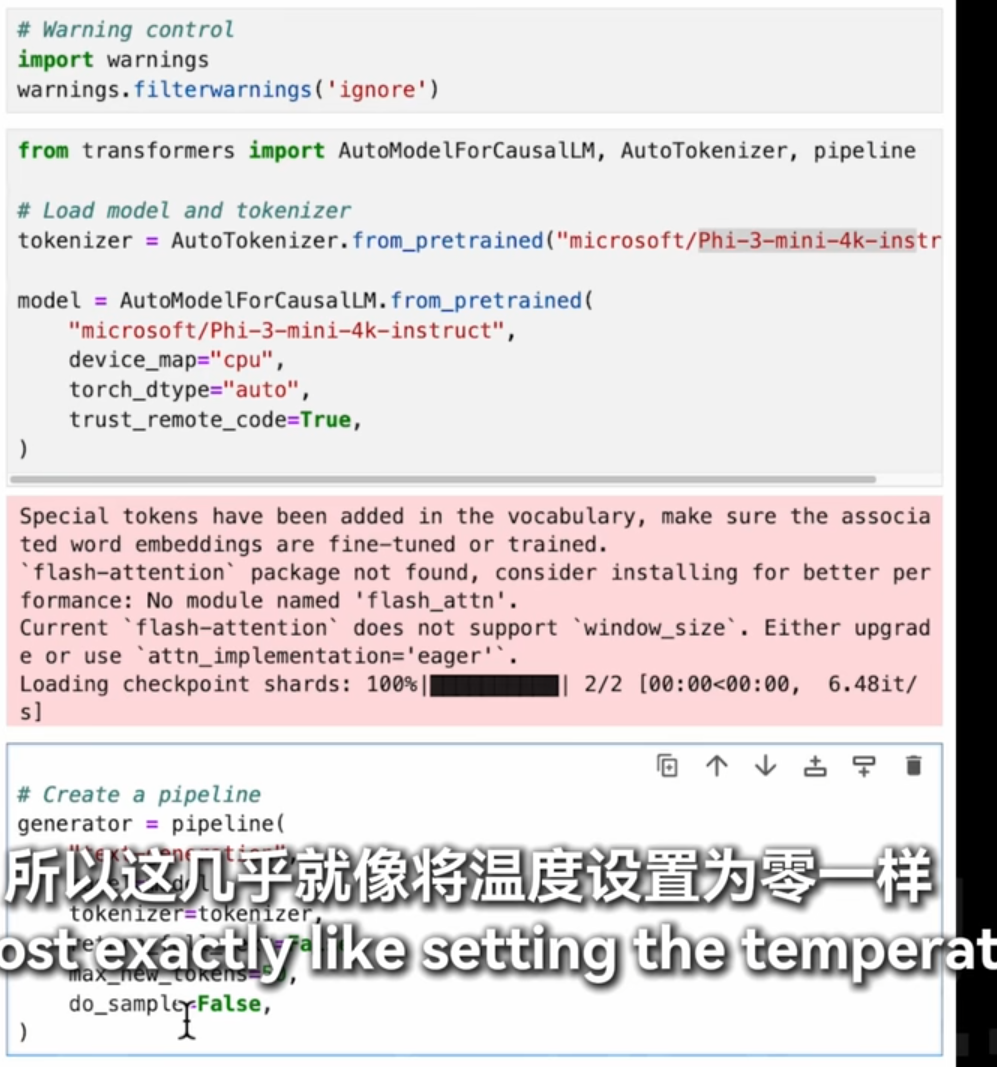
一直选择最高分temperature=0
看着看着睡过去了
盗梦空间了
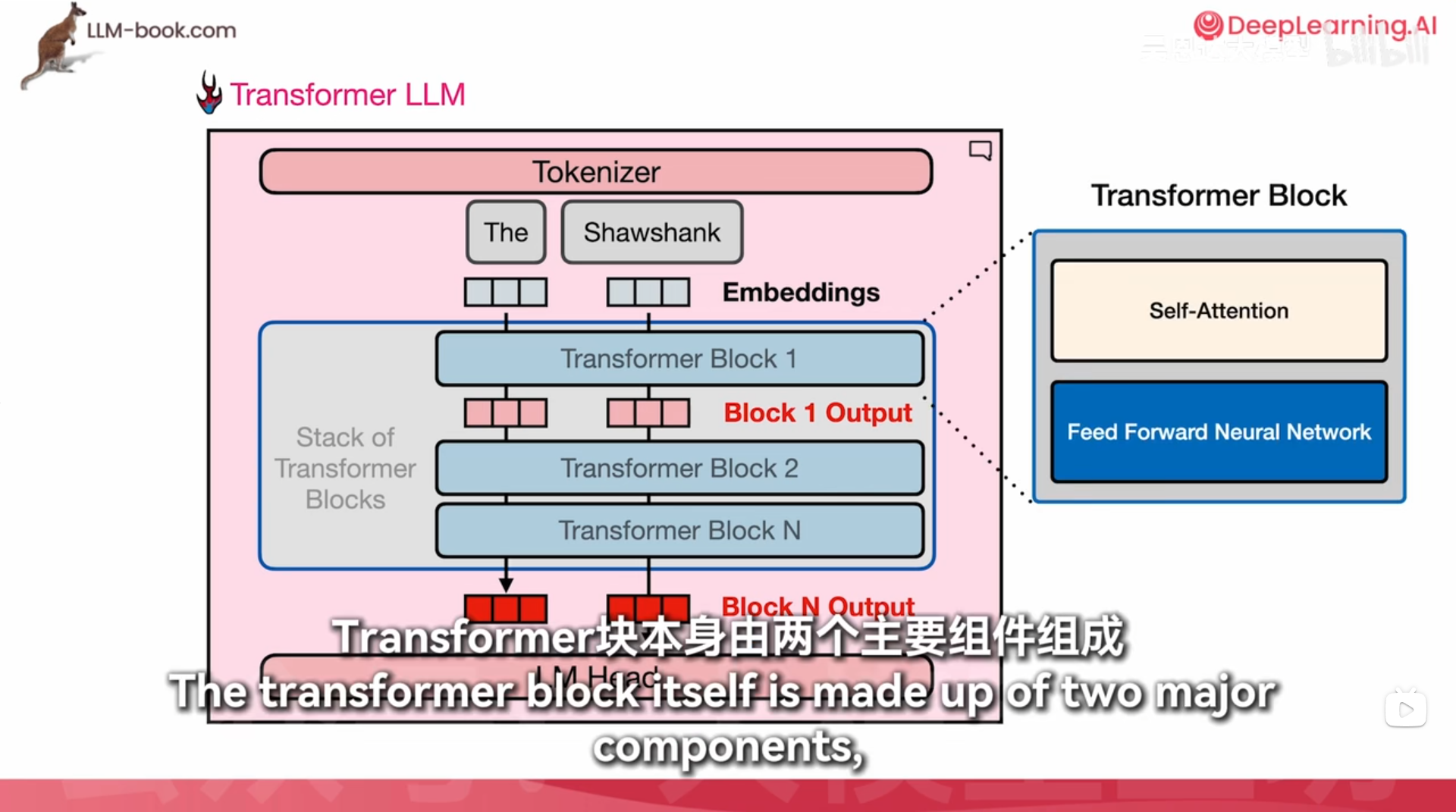
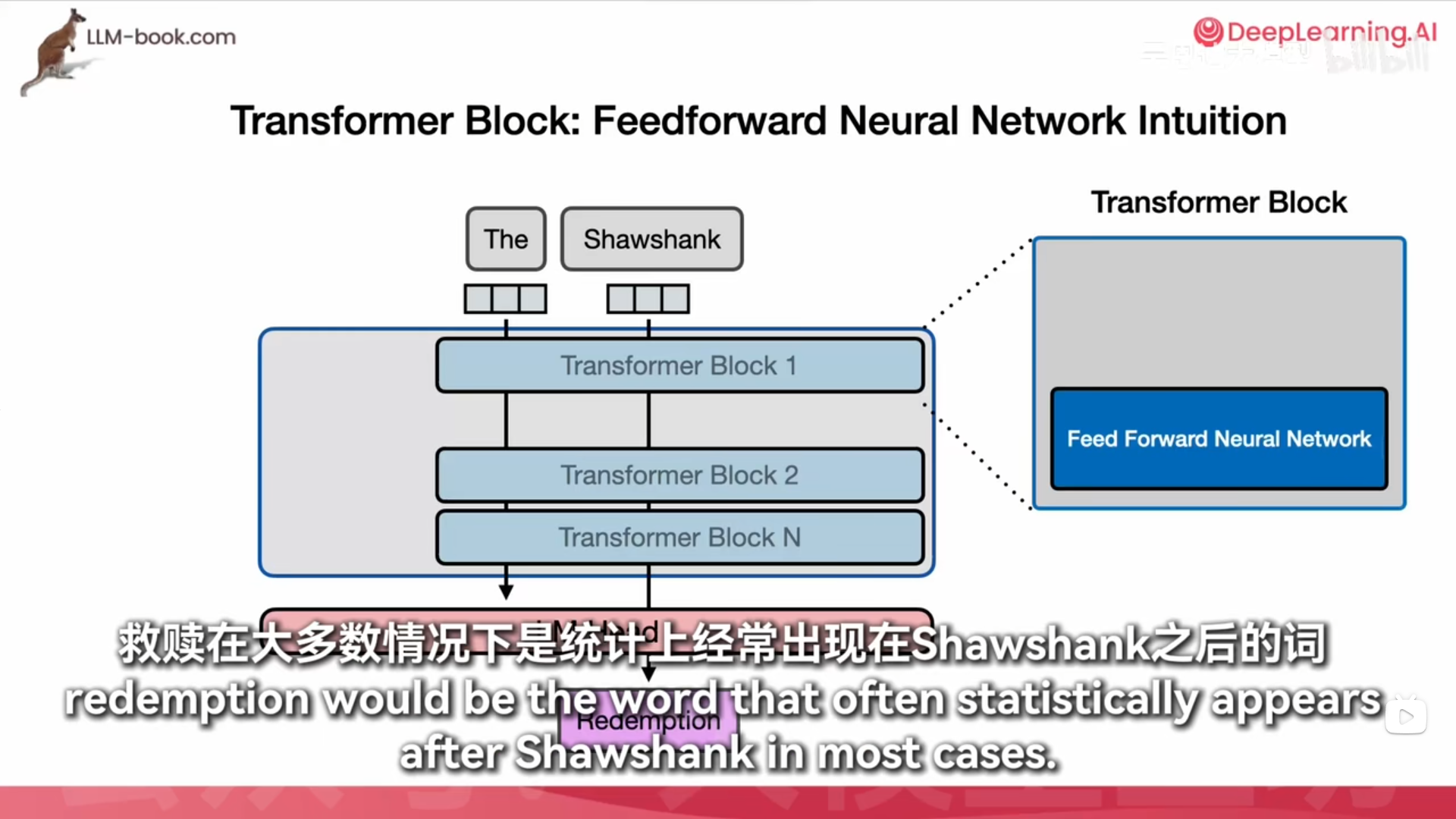
肖申克救赎是吧




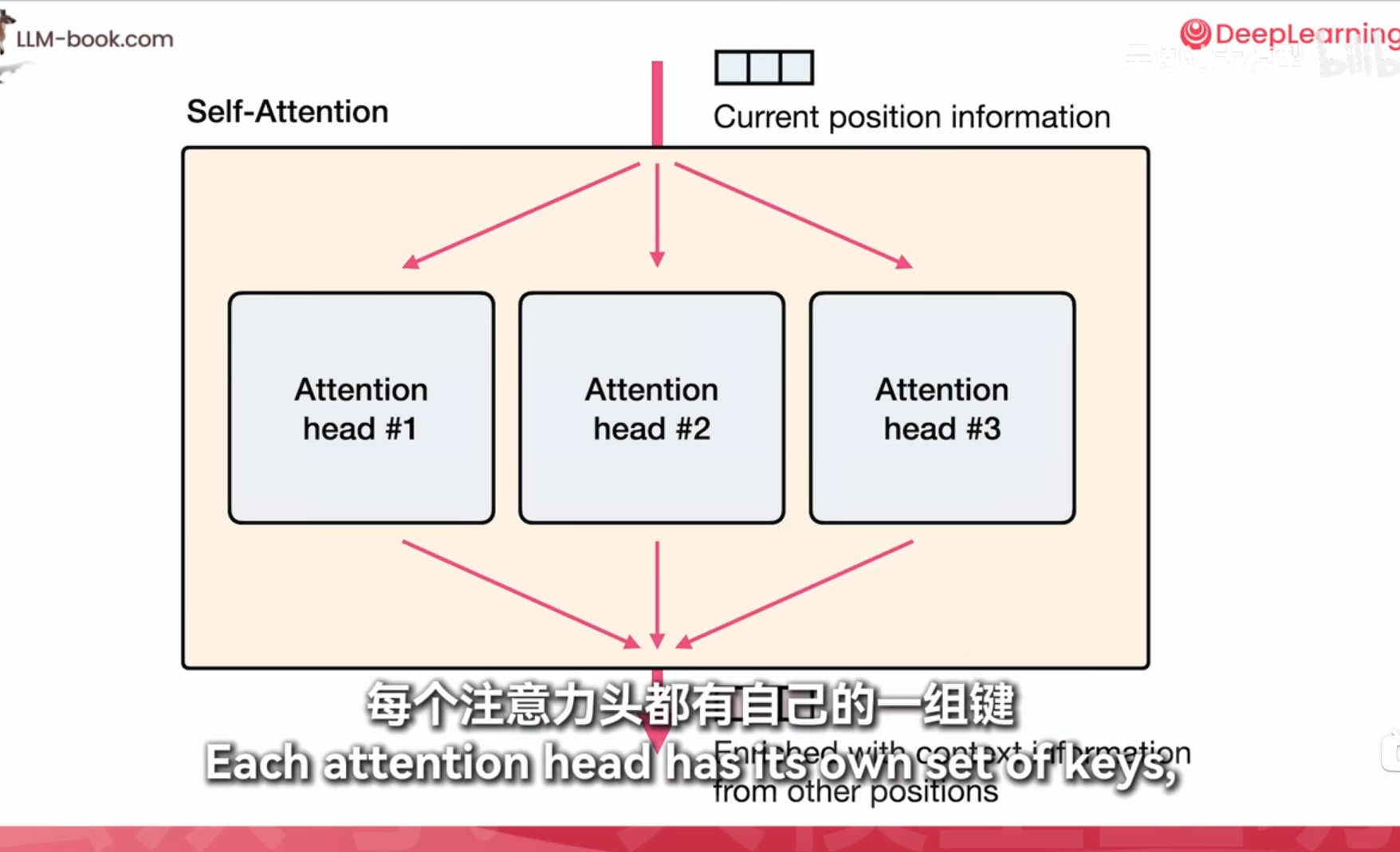
self-attention
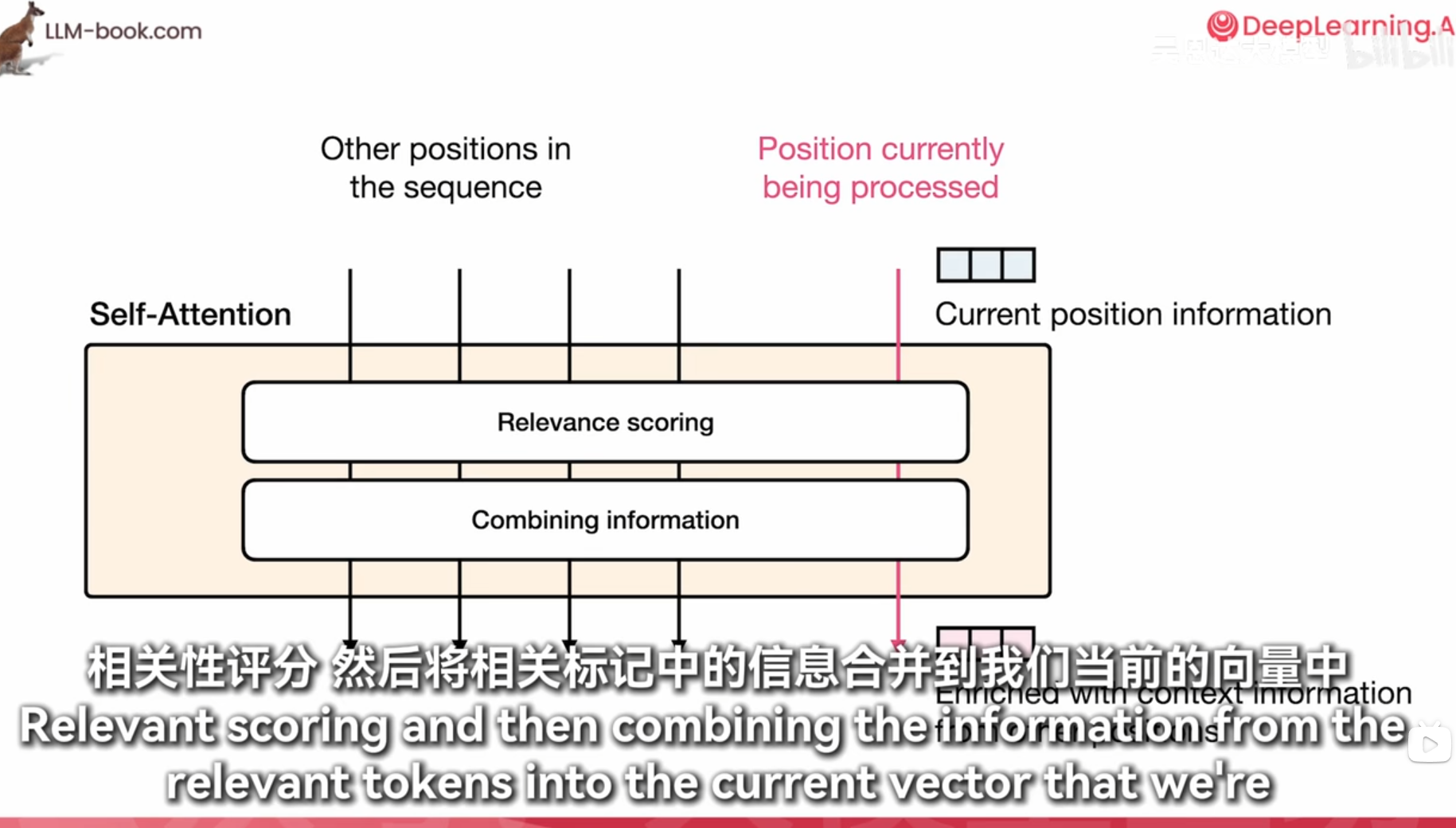

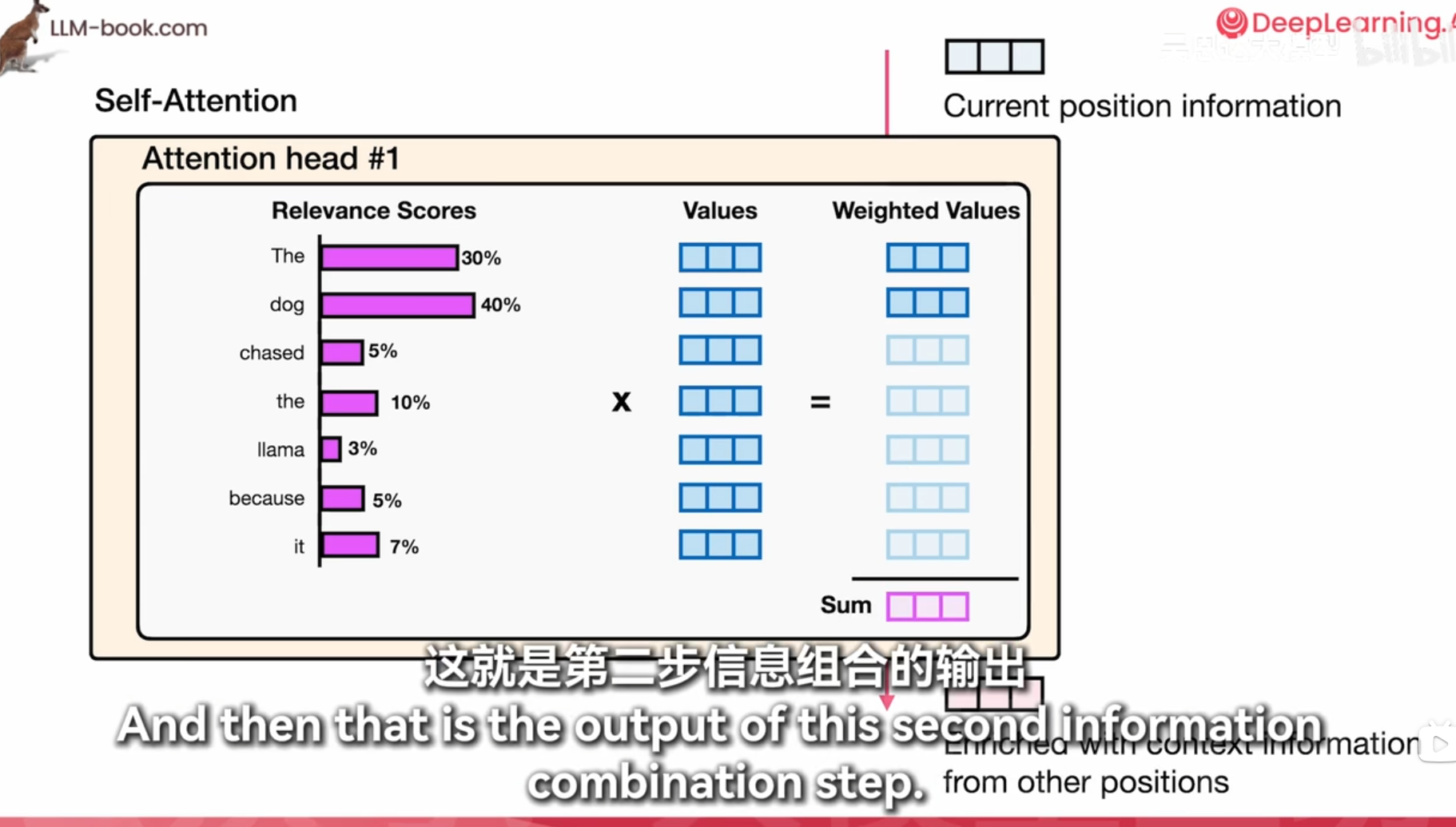
每个词算一个重要程度然后全部加权求和得到上下文信息
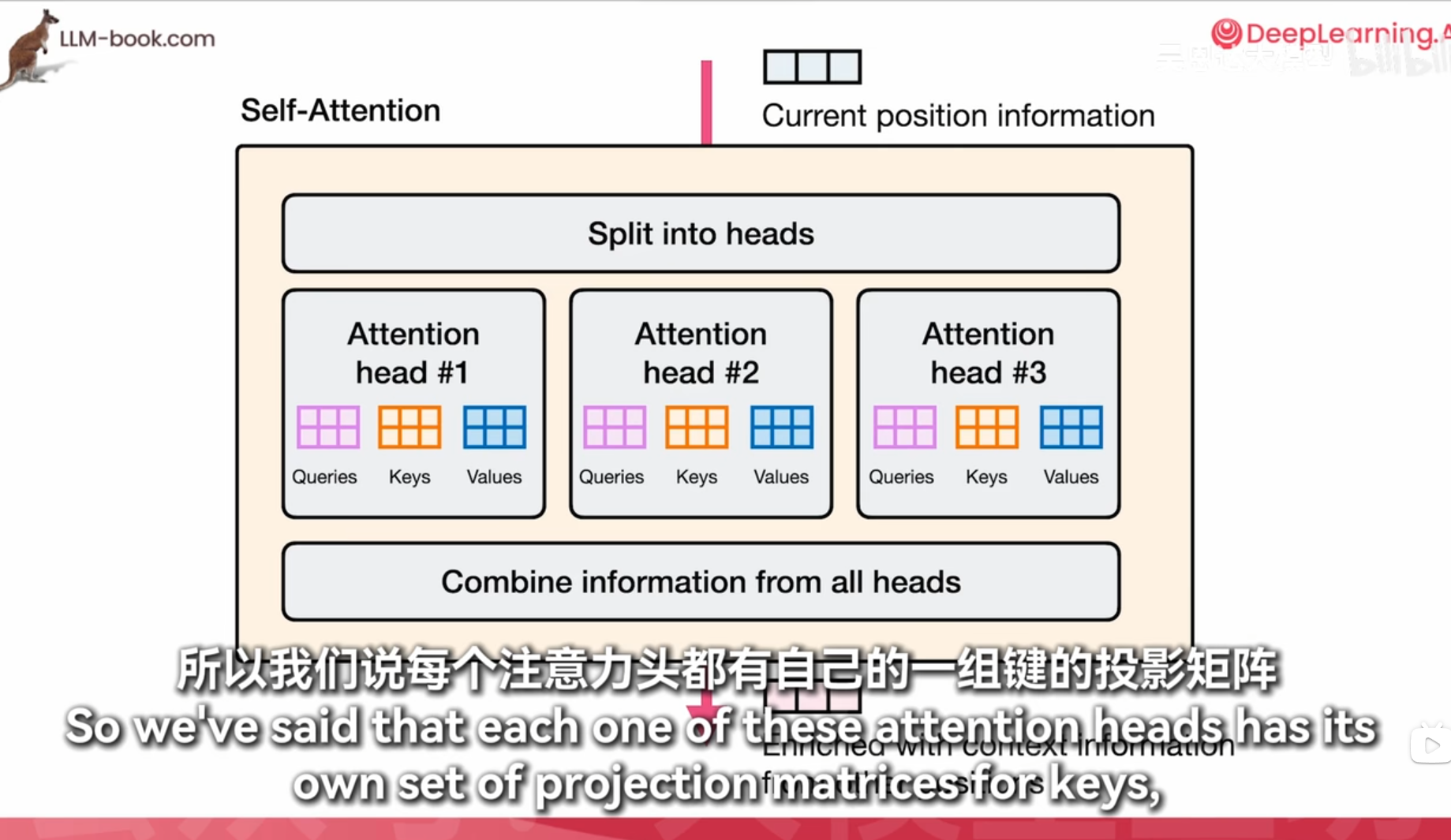
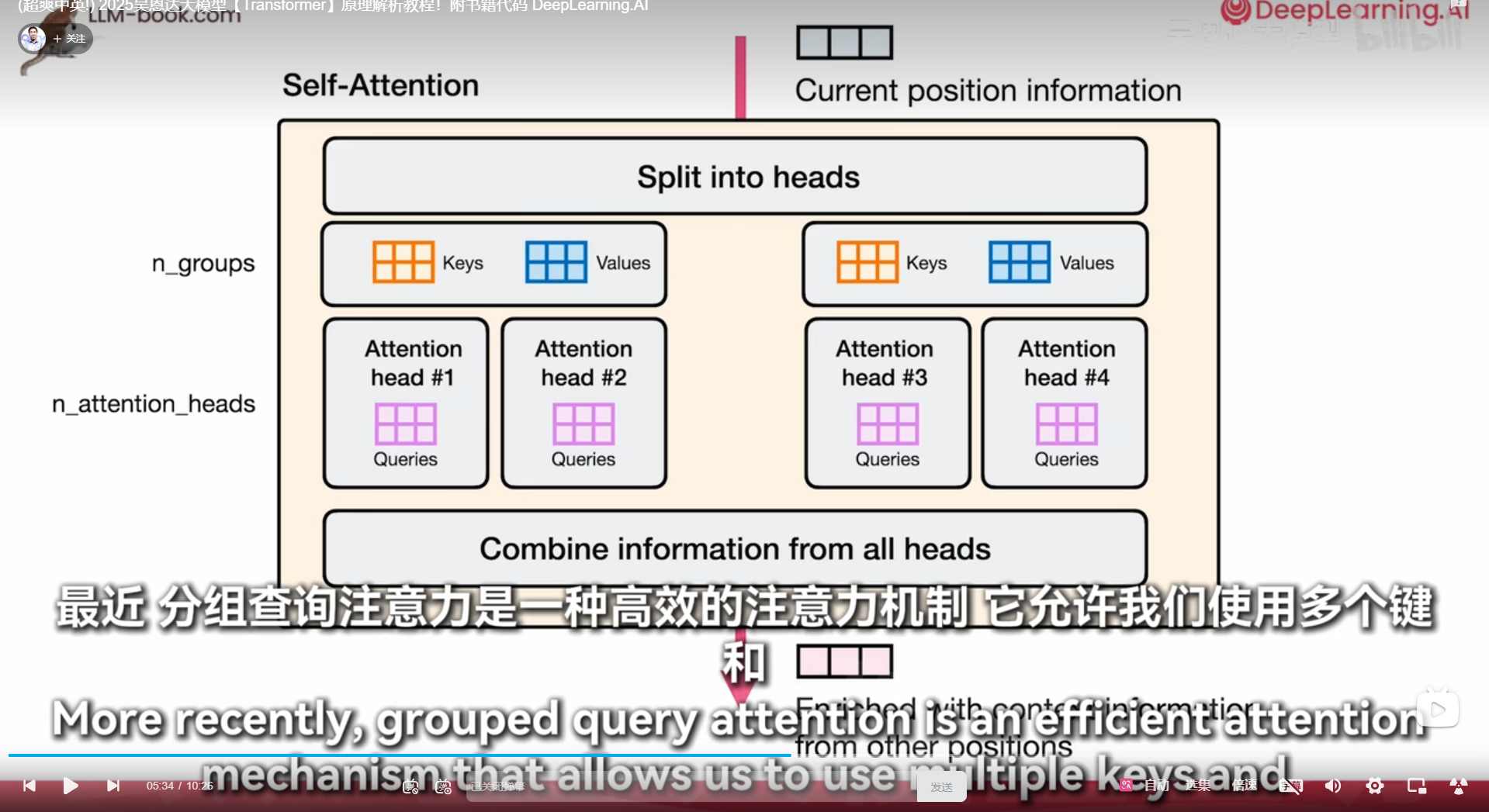
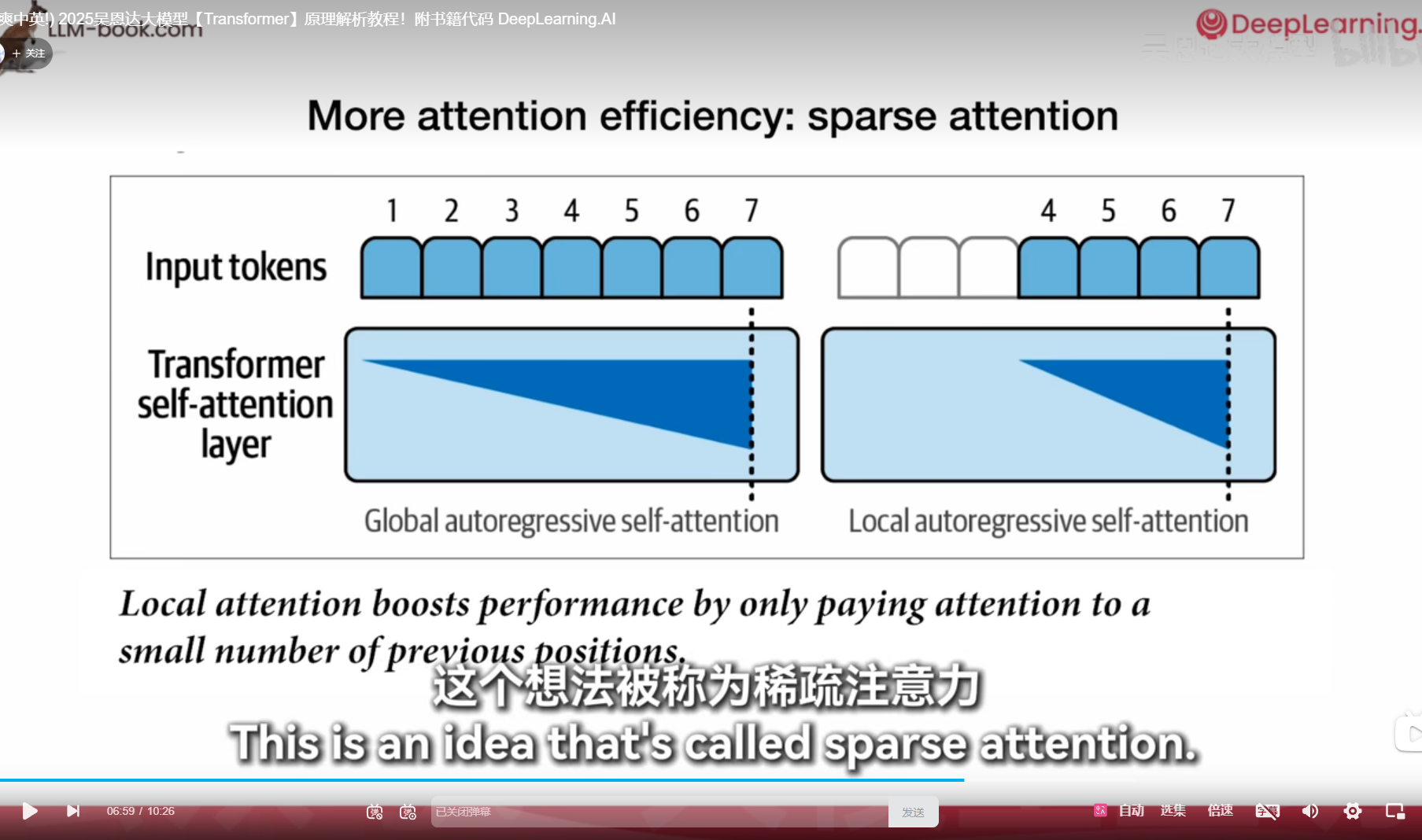
历史记录不全看,稀疏注意力

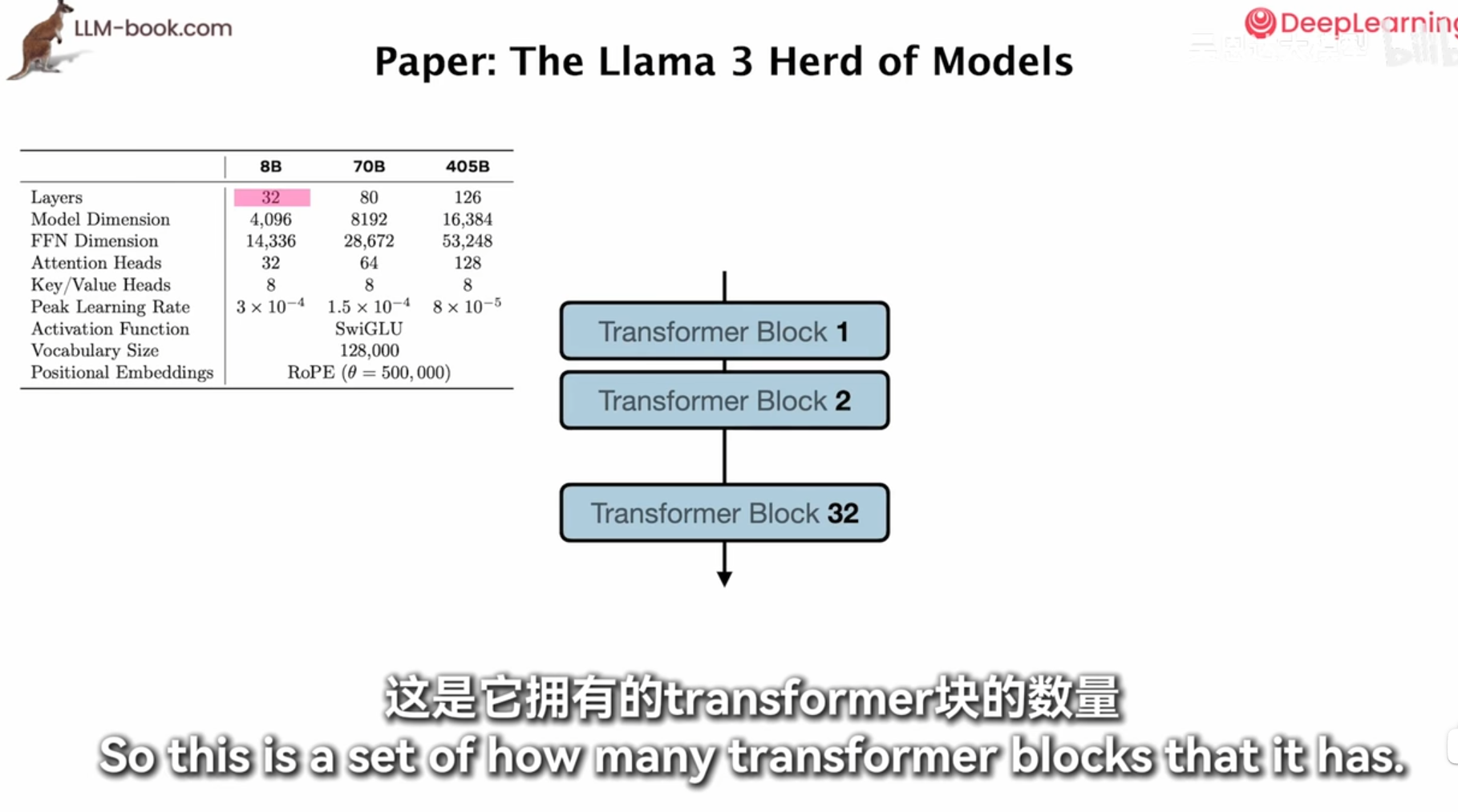

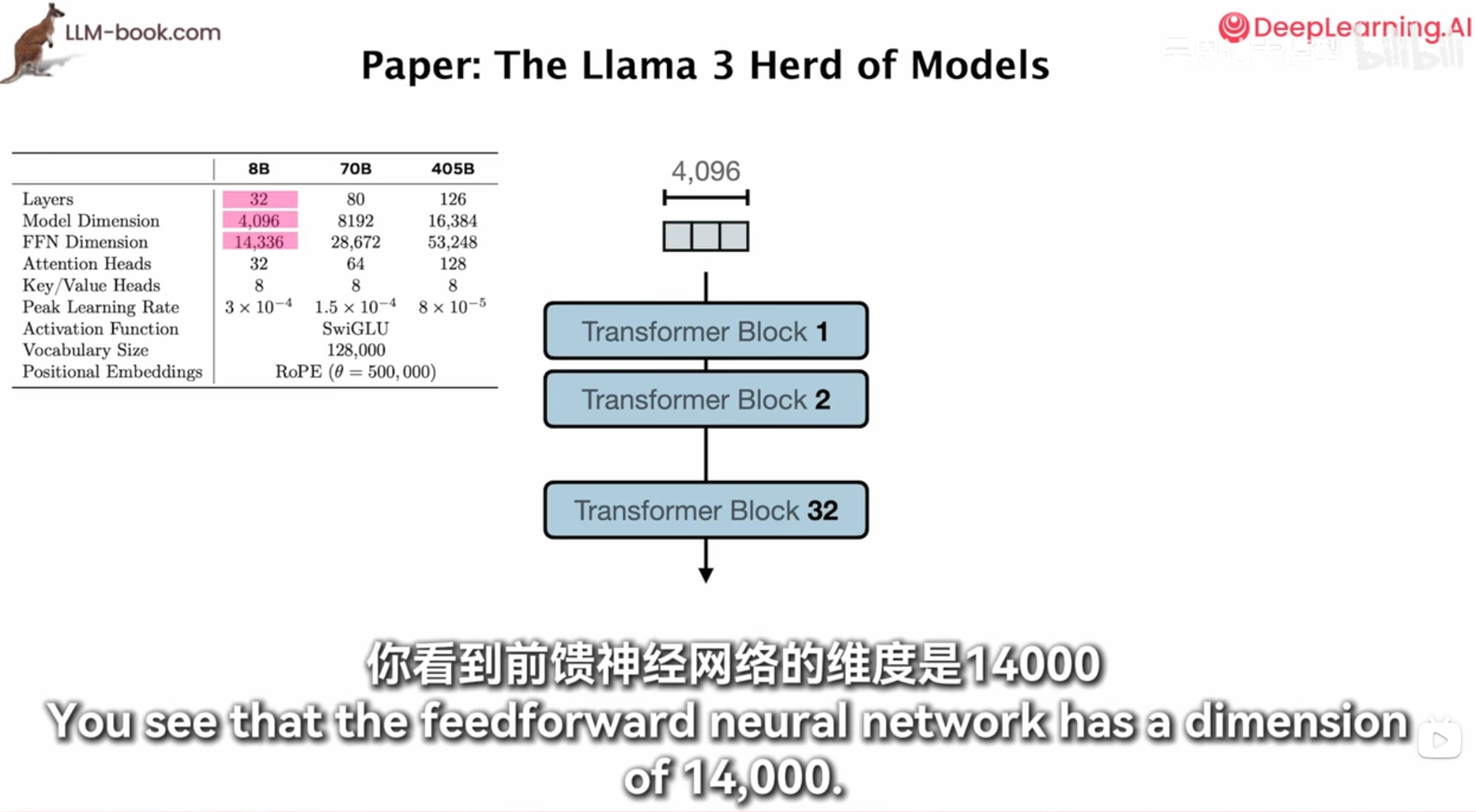

model
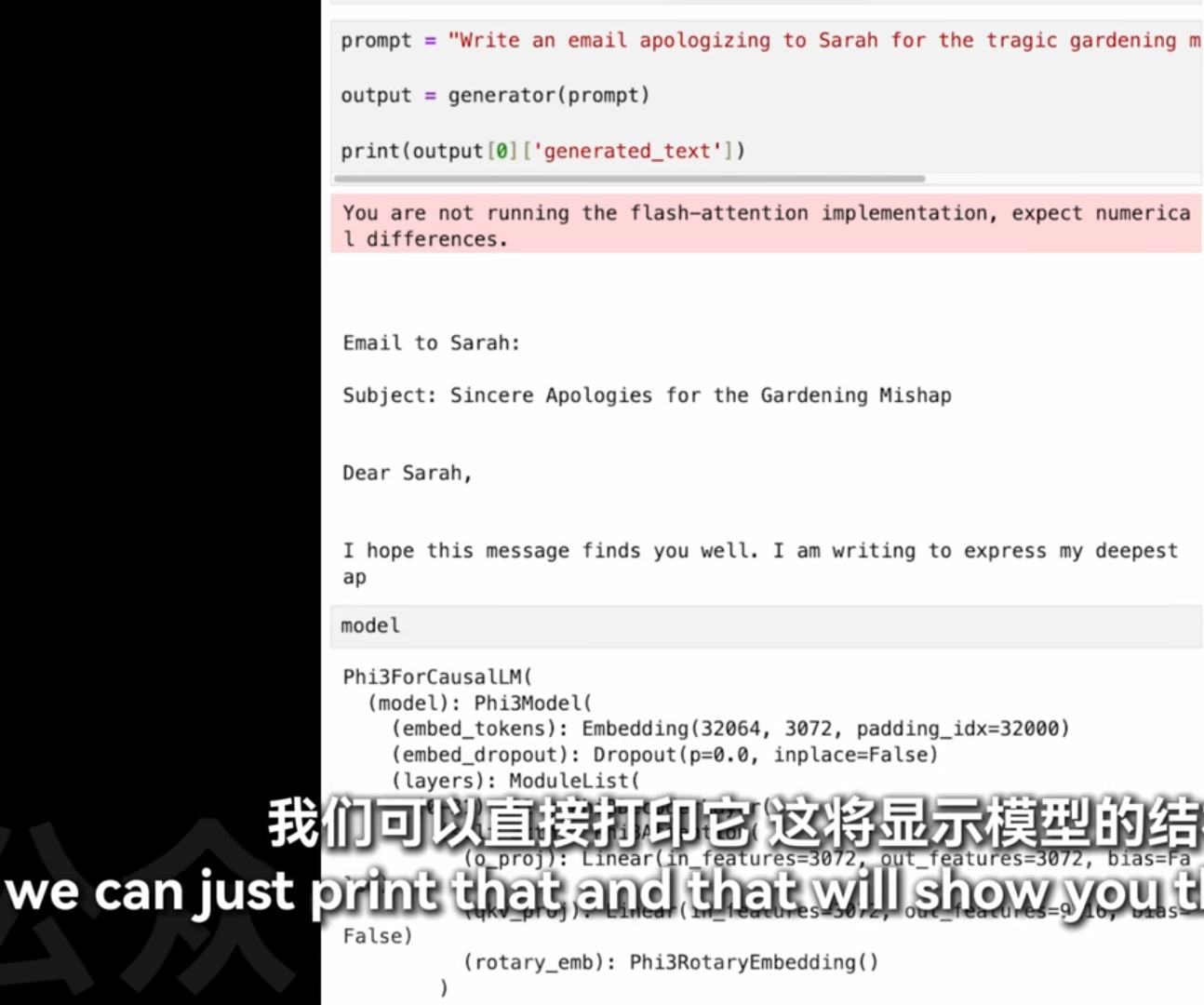
在你提供的代码片段中,32064 和 3072 是与模型的嵌入层(Embedding)相关的参数。具体来说:
-
32064:这是嵌入层的词汇表大小(vocabulary size)。这意味着模型可以处理的唯一词或标记的数量为32064个。这通常对应于训练数据集中所有可能的单词或子词单元的数量。
-
3072:这是嵌入维度(embedding dimension),即每个词或标记被转换成的向量的长度。在这个例子中,每个词或标记会被映射到一个3072维的向量空间中,这个向量包含了该词或标记的语义信息。
这些参数对于理解模型如何表示和处理文本数据至关重要。较大的词汇表大小允许模型处理更广泛的词汇,而较高的嵌入维度则意味着模型能够捕捉到更复杂的语言特征和上下文信息。
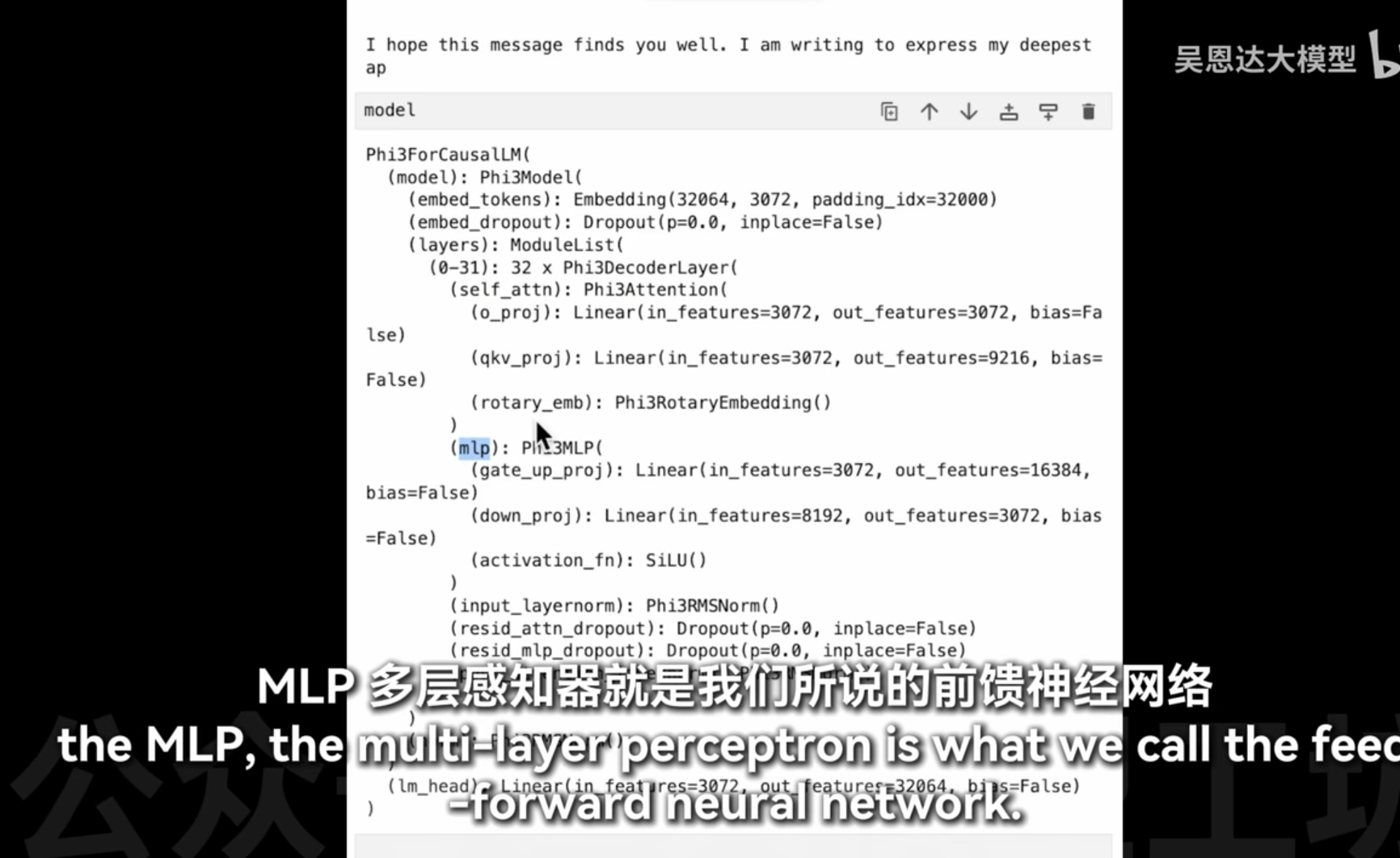
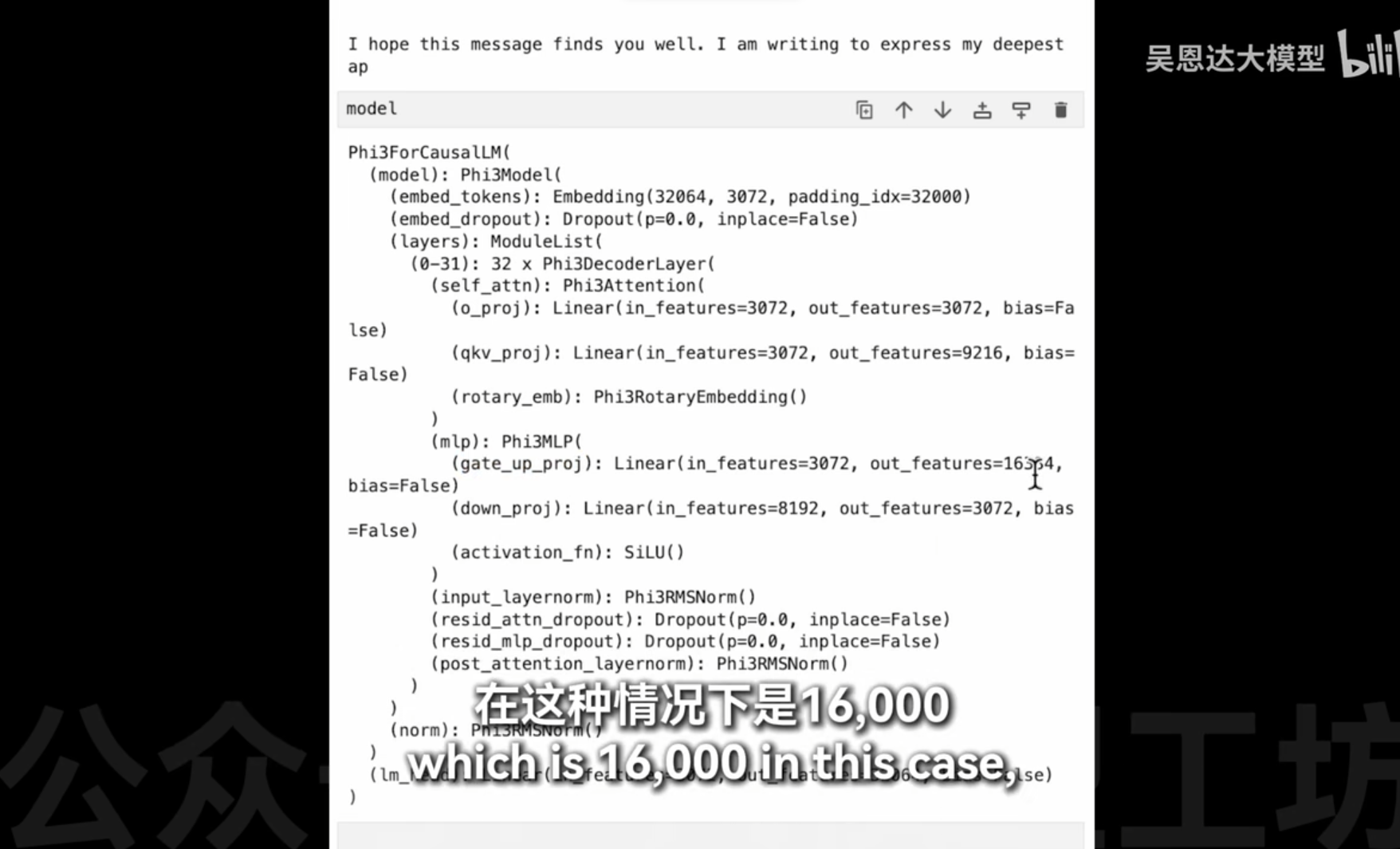
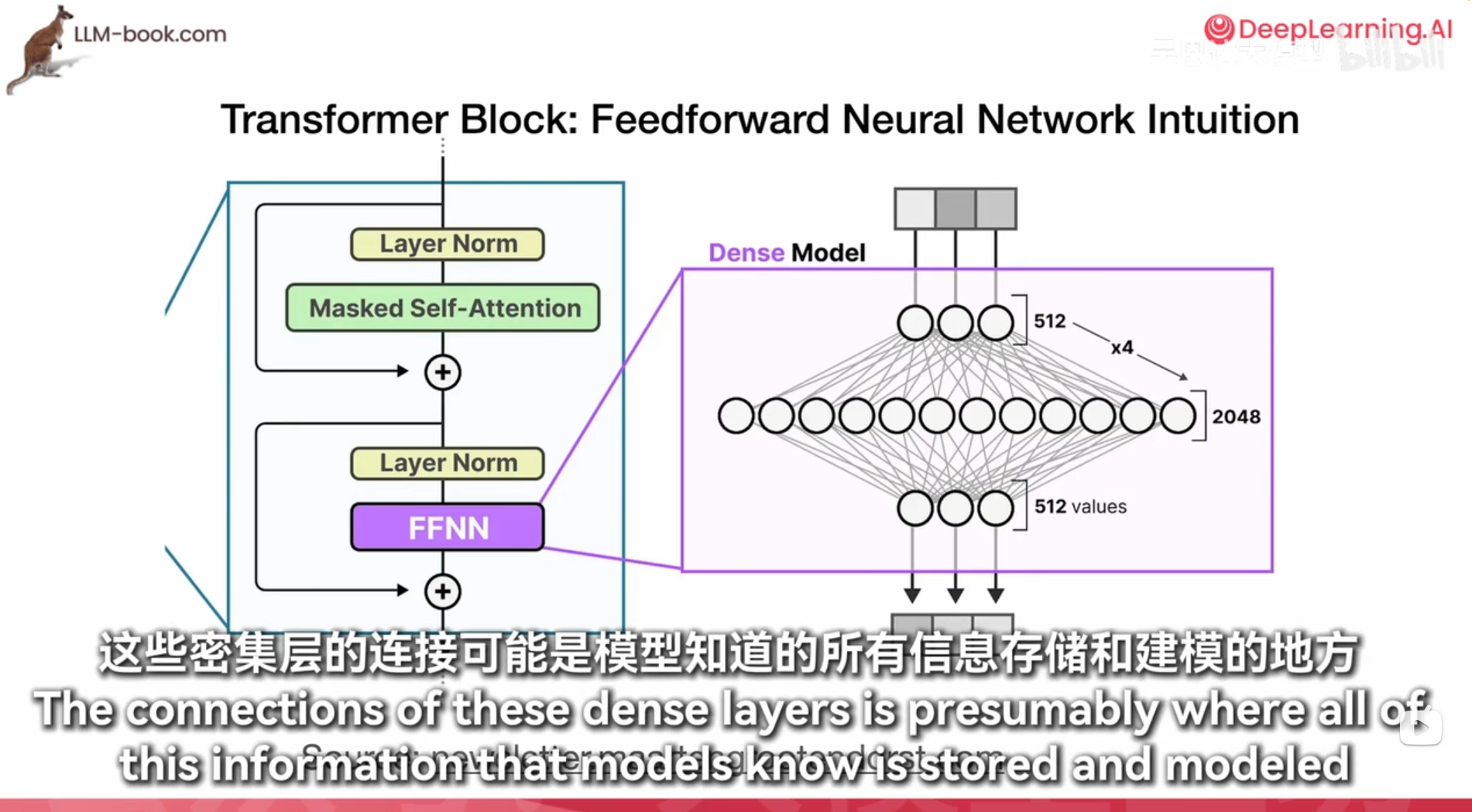
ffn 16000维


model.model
1. 嵌入层 (embed_tokens)
- Embedding(32064, 3072, padding_idx=32000): 这个嵌入层将输入的词或标记转换为固定长度的向量表示。参数说明如下:
32064: 词汇表大小,即模型可以识别的不同词或标记的数量。3072: 嵌入维度,每个词或标记被映射到一个3072维的向量空间中。padding_idx=32000: 指定填充标记的索引,在计算嵌入时会被忽略。
2. Dropout 层 (embed_dropout)
- Dropout(p=0.0, inplace=False): 在嵌入层之后应用Dropout正则化技术,以防止过拟合。在这个例子中,
p=0.0表示不进行Dropout操作。
3. 解码器层 (layers)
- ModuleList: 包含了32个
Phi3DecoderLayer层,这些层是模型的核心部分,负责对输入序列进行编码和解码。
解码器层内部结构:
- Self-Attention (
self_attn): 自注意力机制,允许模型关注输入序列中的不同位置,以捕捉长距离依赖关系。- Linear(in_features=3072, out_features=3072, bias=False): 输出投影层。
- Linear(in_features=3072, out_features=9216, bias=False): 查询、键和值投影层。
- PhiRotaryEmbedding(): 旋转位置嵌入,用于在自注意力机制中引入位置信息。
- MLP (
mlp): 多层感知机,用于增加模型的非线性表达能力。- Linear(in_features=3072, out_features=16384, bias=False): 上行投影层。
- Linear(in_features=8192, out_features=3072, bias=False): 下行投影层。
- SiLU(): 激活函数,使用SiLU(Sigmoid Linear Unit)激活函数。
- Normalization Layers:
- PhiRMSNorm(): RMS归一化层,用于稳定训练过程。
- Dropout Layers:
- Dropout(p=0.0, inplace=False): 在自注意力和MLP模块后应用Dropout正则化。
4. 最终归一化层 (norm)
- PhiRMSNorm(): 在模型输出之前应用的最终归一化层,确保输出的稳定性
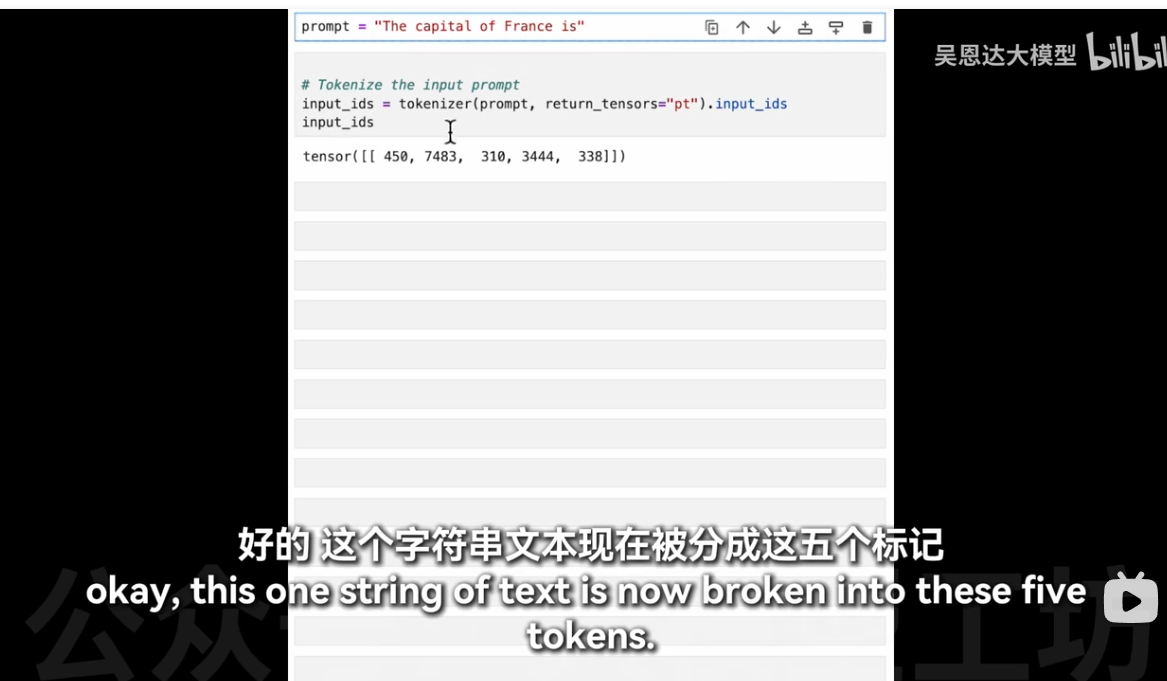
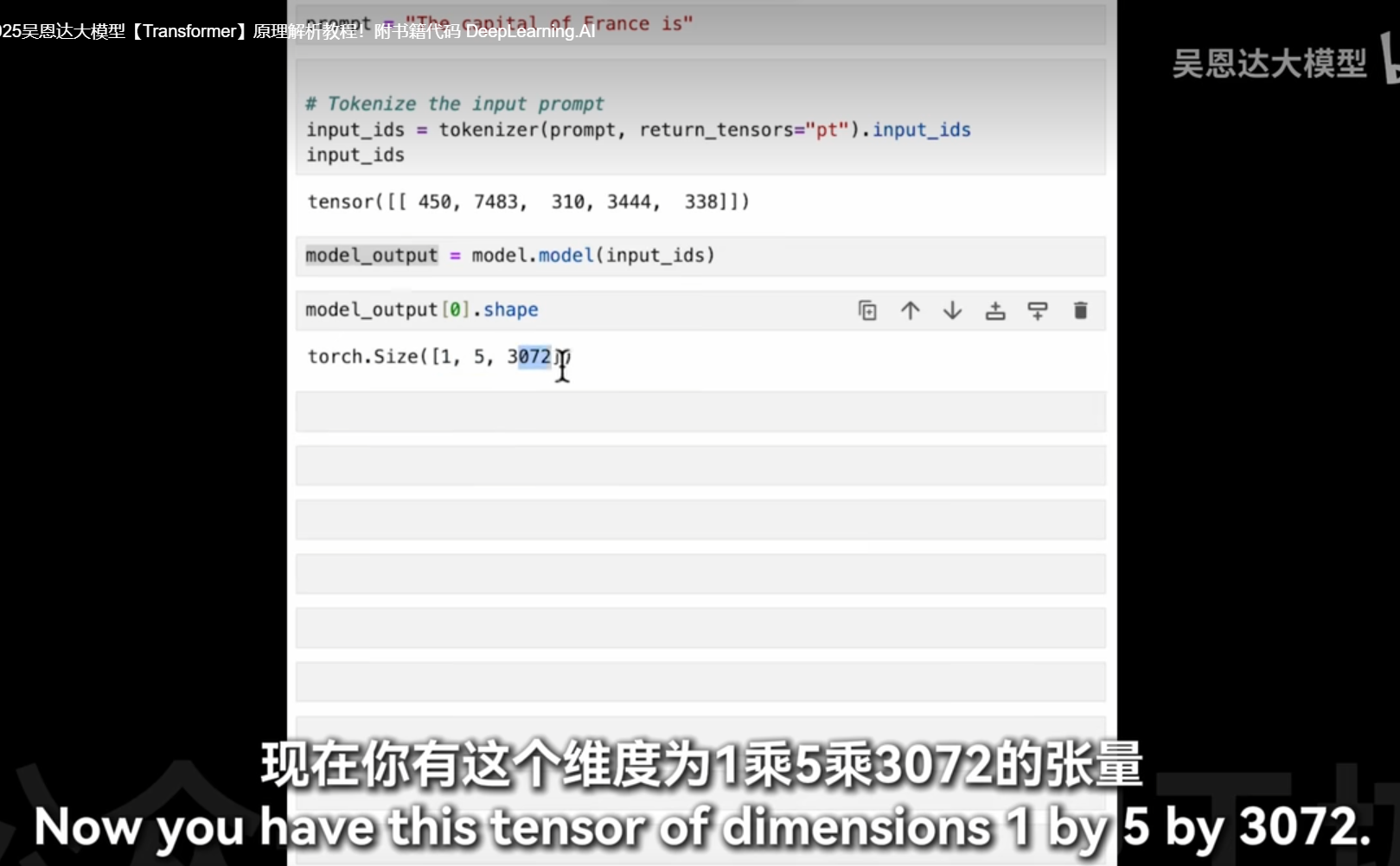
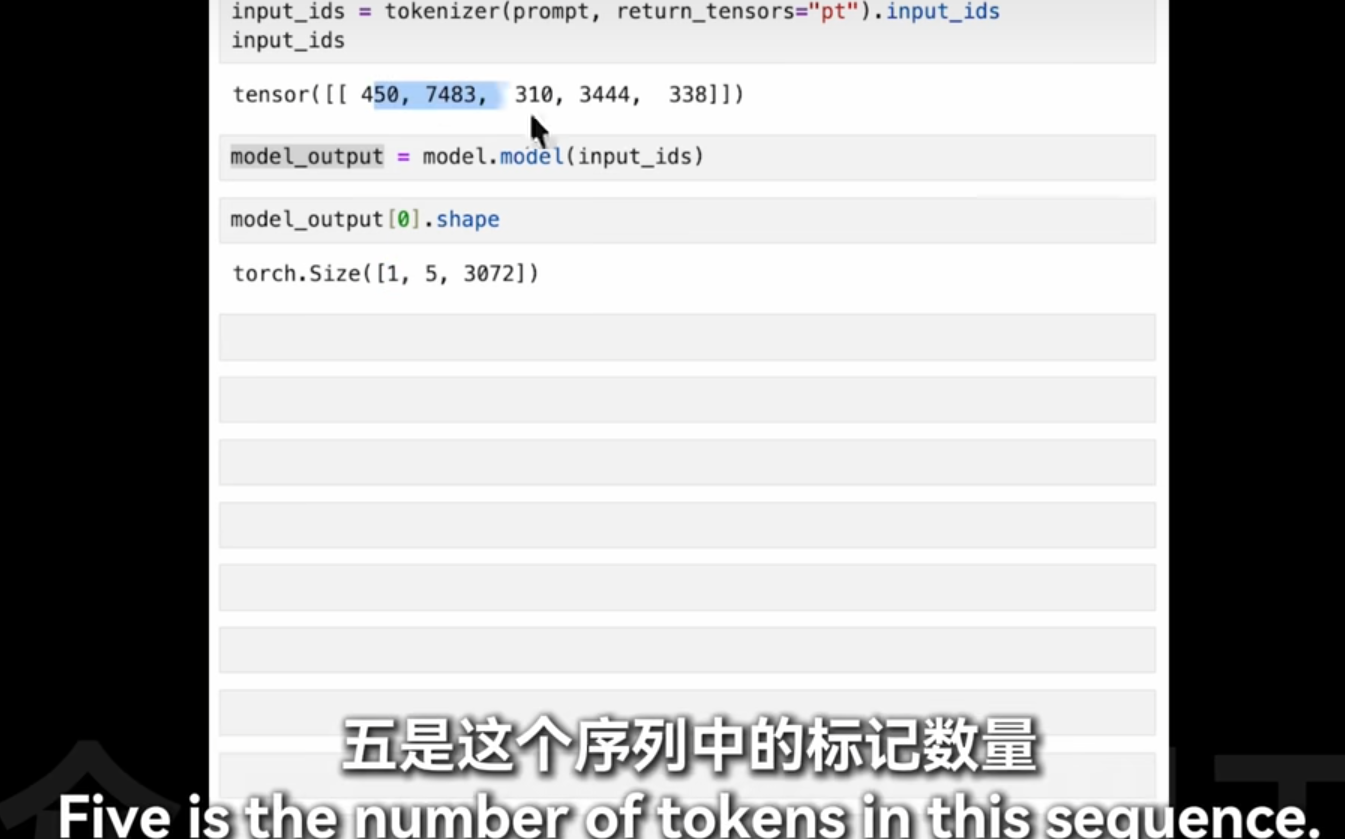
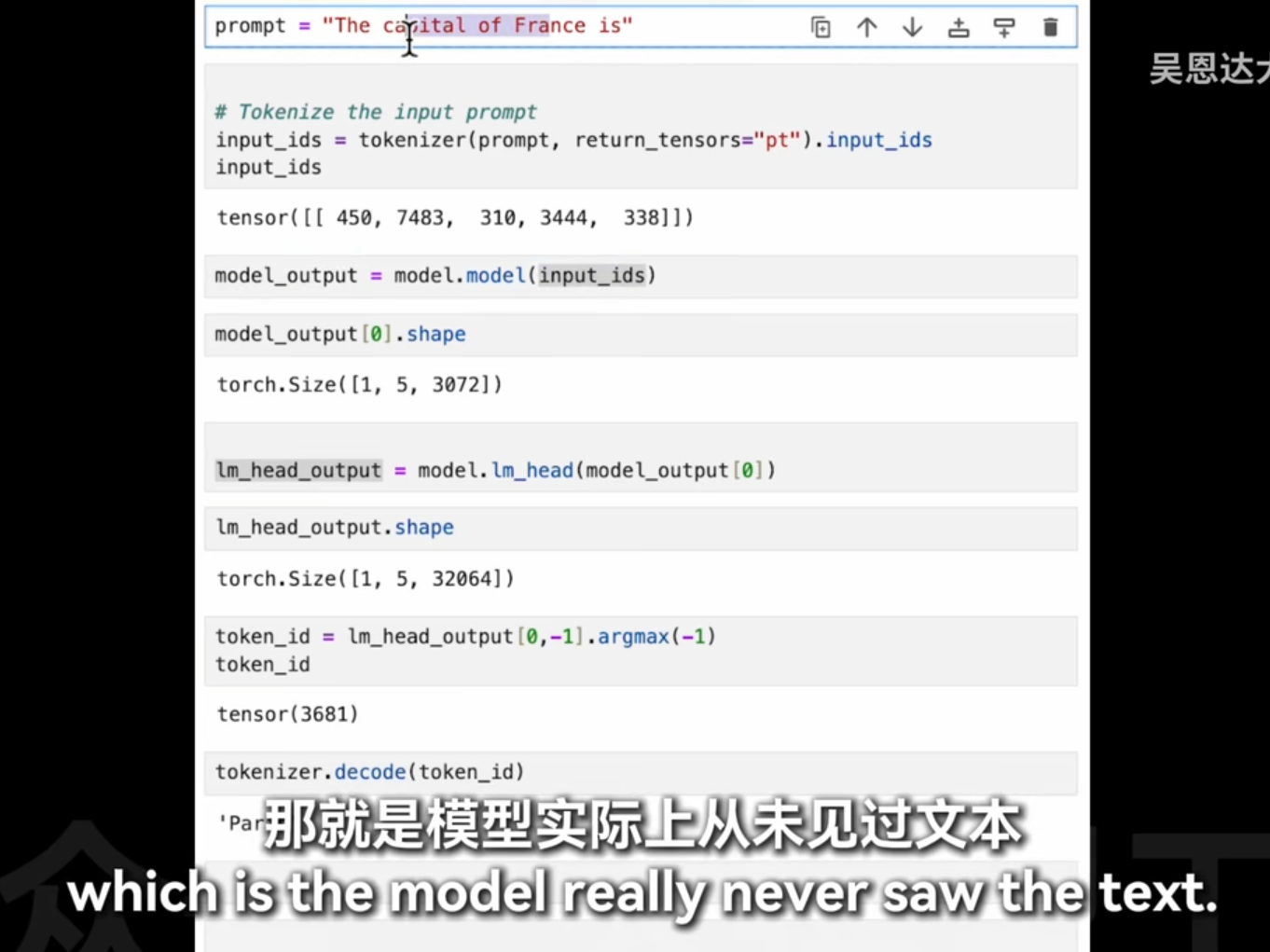
之前例子是1*2*3072
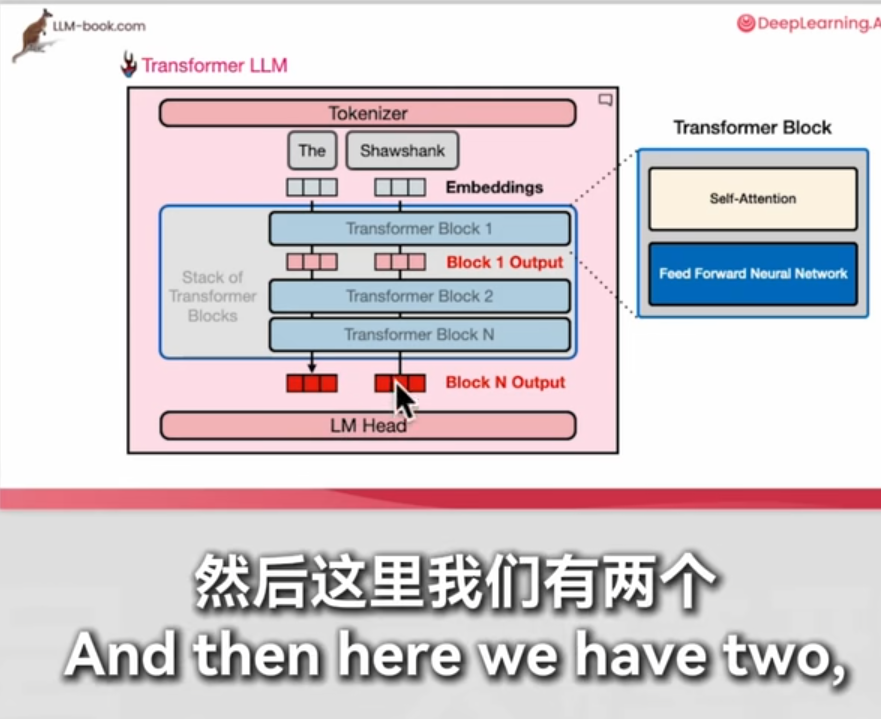
原来llm还能拆开用的 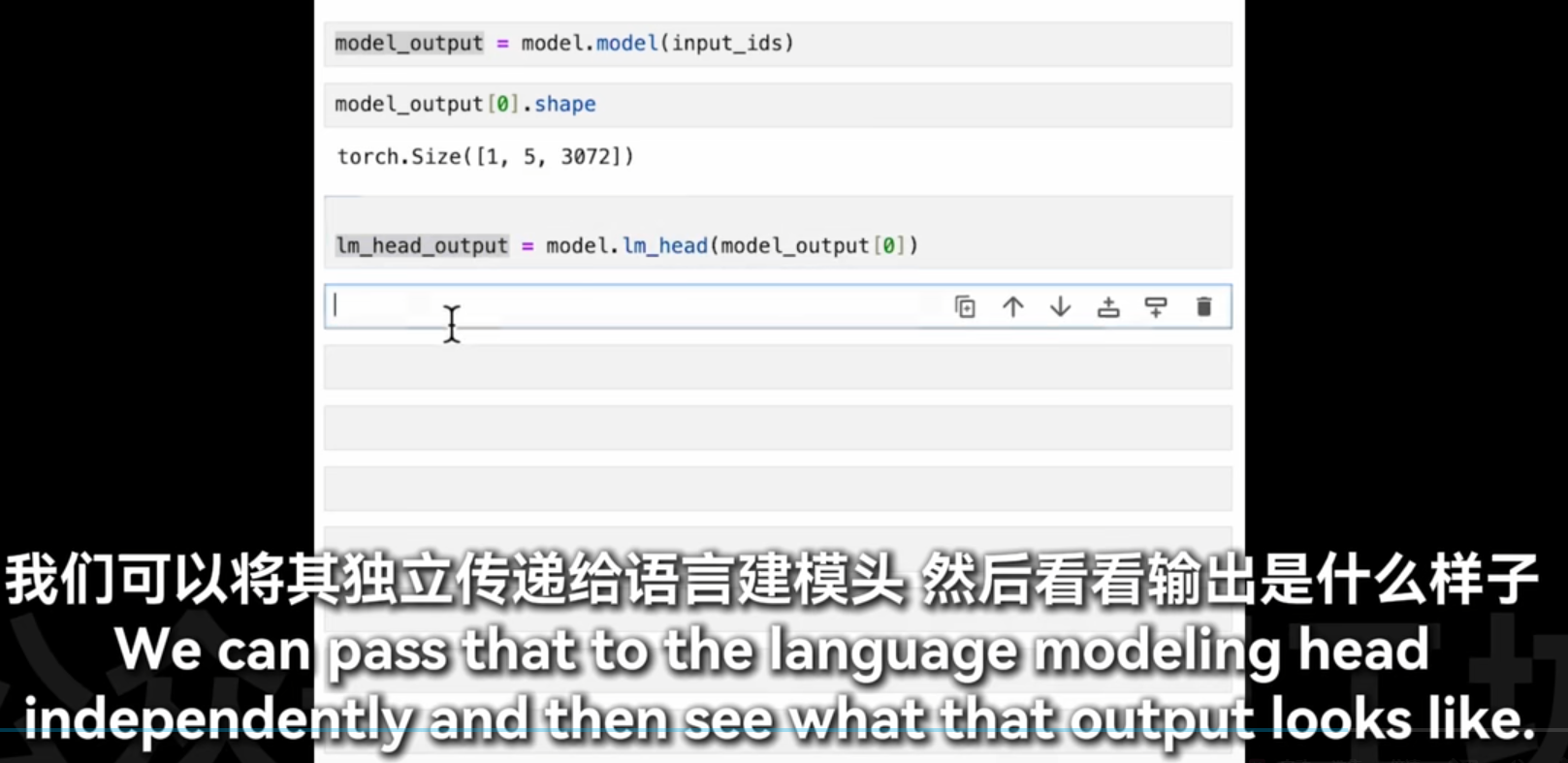
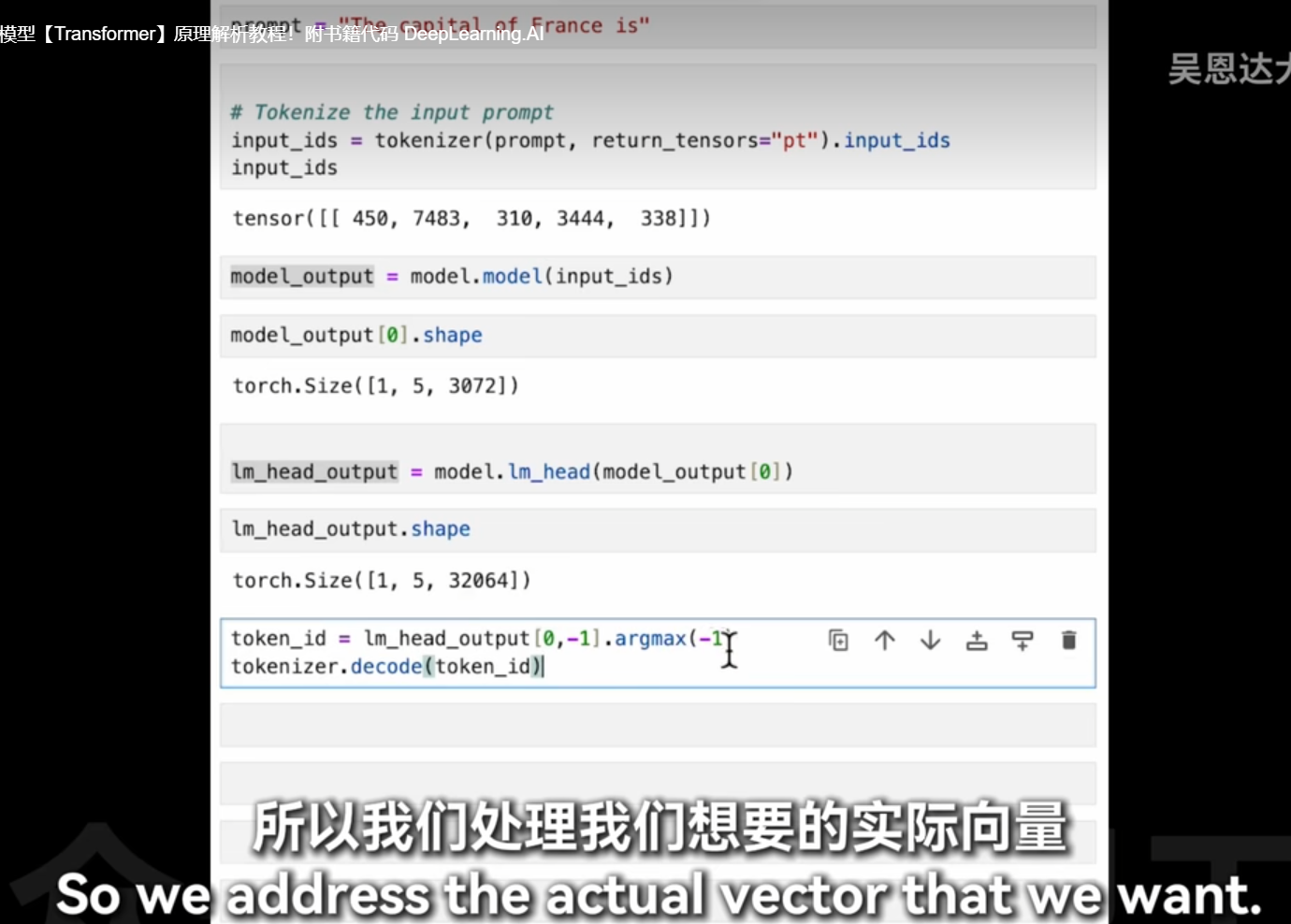
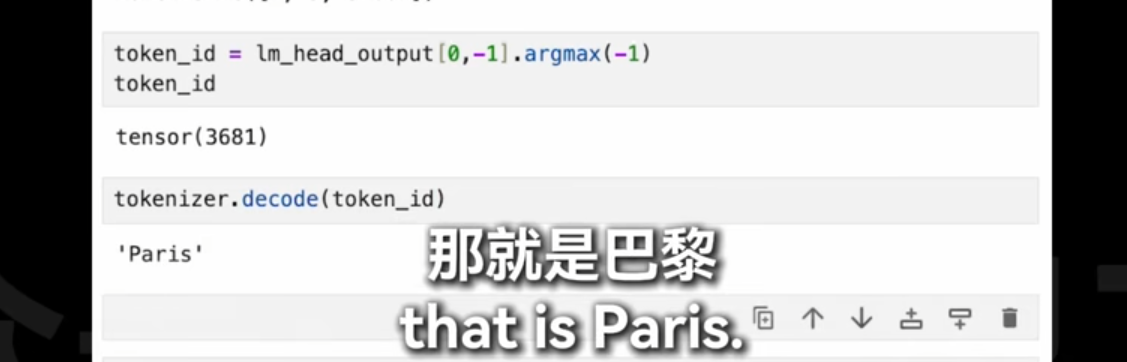
这段代码的目的是从模型的输出中获取预测的词或标记,并将其解码为可读的文本。让我们逐步解析这段代码:
1. lm_head_output[0, -1]
lm_head_output: 这是语言模型(Language Model)头部的输出,通常是一个三维张量,形状为[batch_size, sequence_length, vocab_size]。batch_size: 批处理中的样本数量。sequence_length: 输入序列的长度。vocab_size: 词汇表大小,即模型可以生成的不同词或标记的数量。
[0, -1]: 这是对lm_head_output张量进行索引操作。0: 表示选择批处理中的第一个样本。-1: 表示选择该样本序列中的最后一个时间步的输出。这通常用于生成任务,其中我们关注的是序列的下一个词预测。
2. .argmax(-1)
.argmax(-1): 在指定的维度上找到最大值的索引。这里的-1表示在最后一维(即词汇表维度)上进行操作。- 这一步的作用是从模型输出的概率分布中选择最可能的词或标记。
argmax返回的是这个最可能词或标记在词汇表中的索引。
3. tokenizer.decode(token_id)
token_id: 经过argmax操作后得到的词或标记的索引。tokenizer.decode(): 使用分词器(Tokenizer)将词或标记的索引转换为实际的文本。- 分词器是训练时使用的同一工具,它能够将词汇表中的索引映射回原始的词或字符。
总结
这段代码的主要功能是从模型的输出中提取出最可能的下一个词或标记,并将其转换为人类可读的文本形式。具体步骤如下:
- 从模型输出中选择第一个样本的最后一个时间步的输出。
- 在词汇表维度上找到概率最大的词或标记的索引。
- 使用分词器将这个索引解码为实际的词或字符。
这种操作常见于文本生成任务,如自动补全、机器翻译和文本摘要等场景。


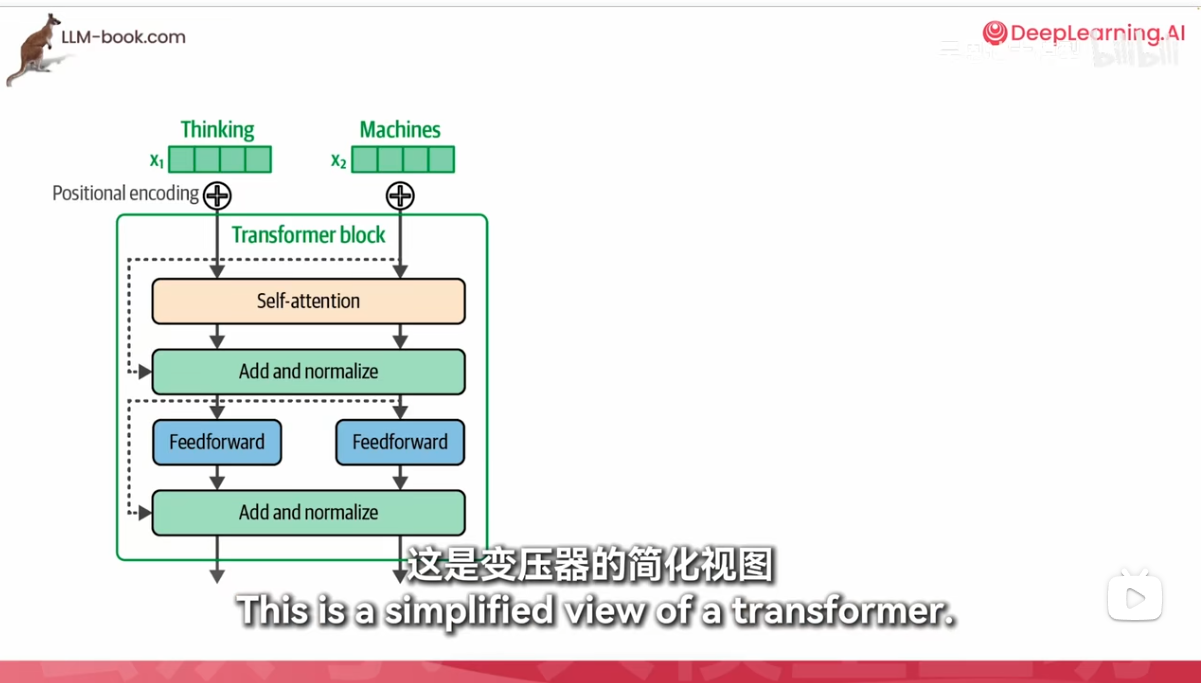
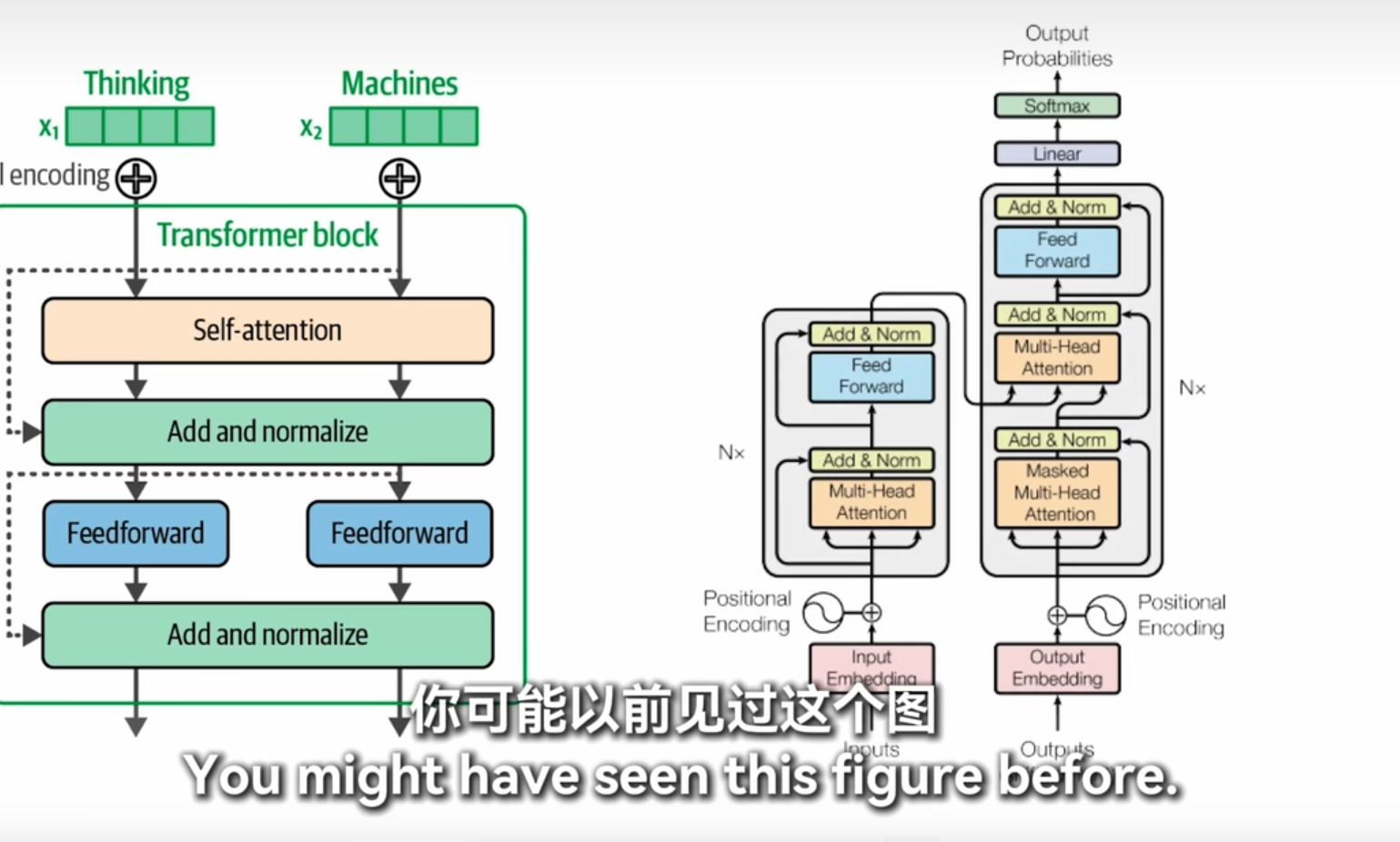
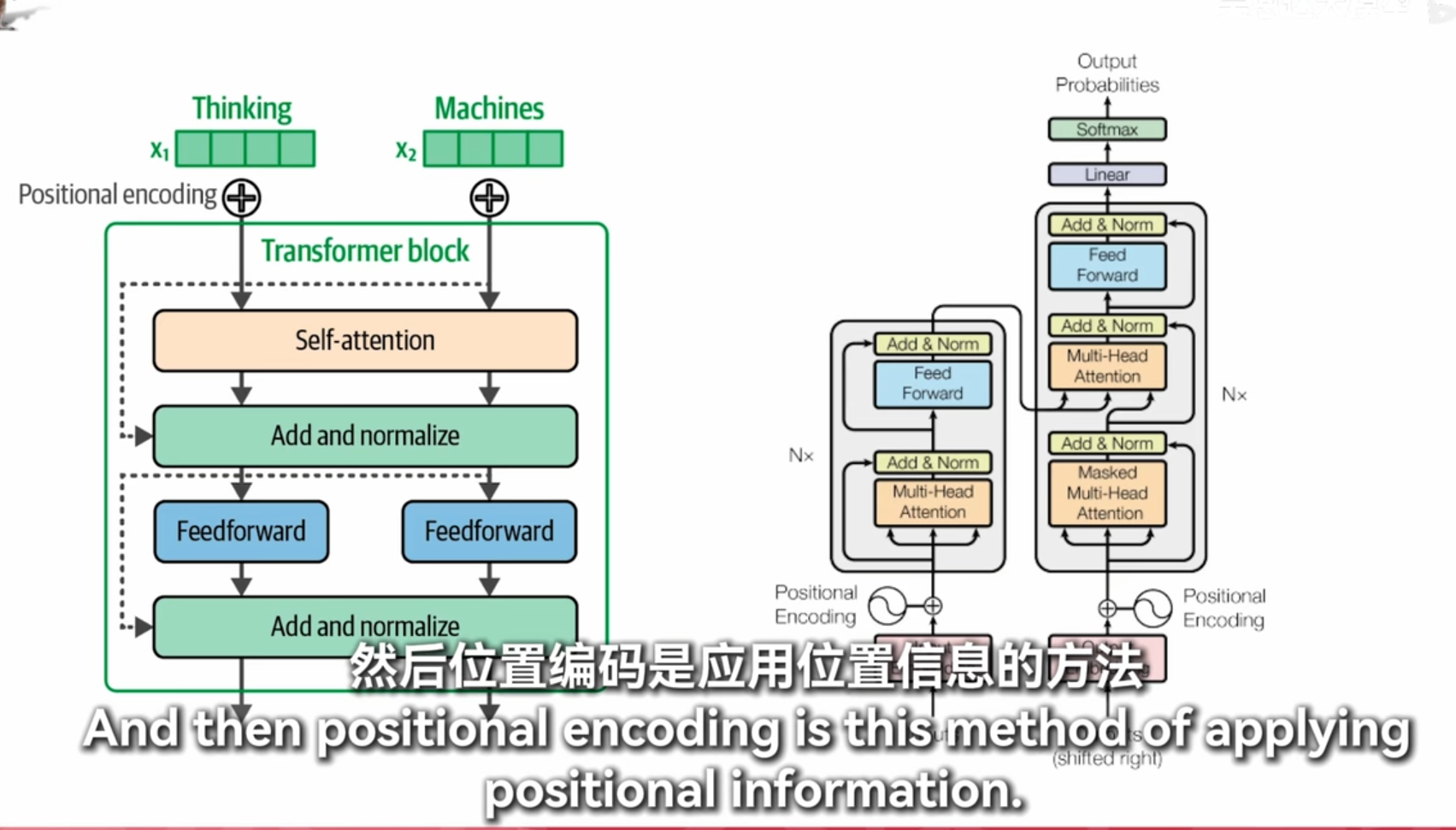
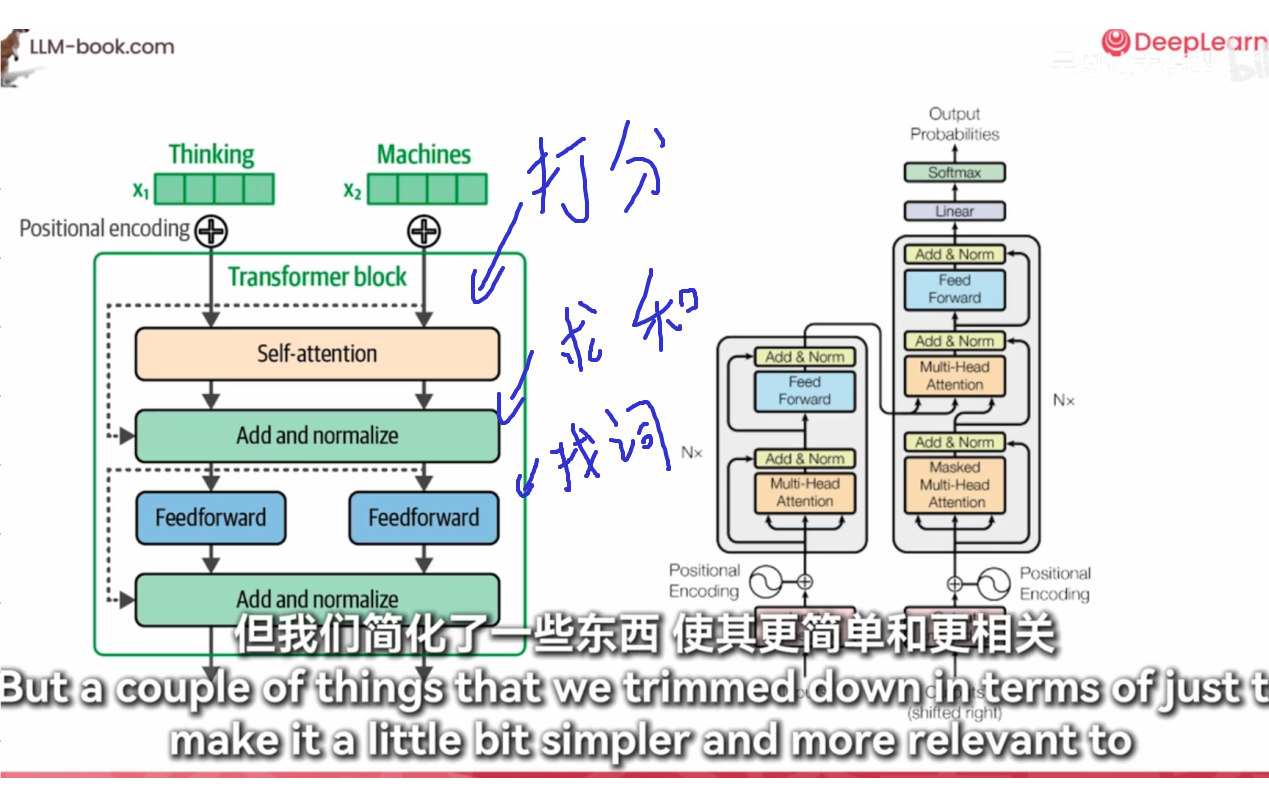
1. 打分
- Self-Attention: 在Transformer中,“打分”实际上是指自注意力机制(Self-Attention)中的计算过程。具体来说,它涉及计算输入序列中每个词与其他词的相关性分数。这些分数用于确定在生成当前词的表示时,应该赋予其他词多少权重。
- 计算方式: 这个过程通常通过查询(Query)、键(Key)和值(Value)向量的点积来实现,并通过Softmax函数进行归一化,得到注意力权重。
2. 求和
- Add & Norm: “求和”指的是“Add & Norm”层的操作。在这个层中,模型将自注意力机制或前馈神经网络(Feed Forward)的输出与输入相加,然后进行归一化处理。这一步骤有助于保持梯度稳定,并允许模型学习残差连接(Residual Connections),从而提高训练的效率和效果。
- 作用: 残差连接使得深层网络更容易训练,因为它们可以缓解梯度消失或爆炸的问题。
3. 找词
- Feed Forward: “找词”可以理解为前馈神经网络(Feed Forward)的作用。这个模块是一个全连接的两层神经网络,用于对自注意力机制的输出进行非线性变换,以捕捉更复杂的特征和模式。
- 功能: 前馈神经网络增强了模型的表达能力,使其能够更好地理解和生成文本


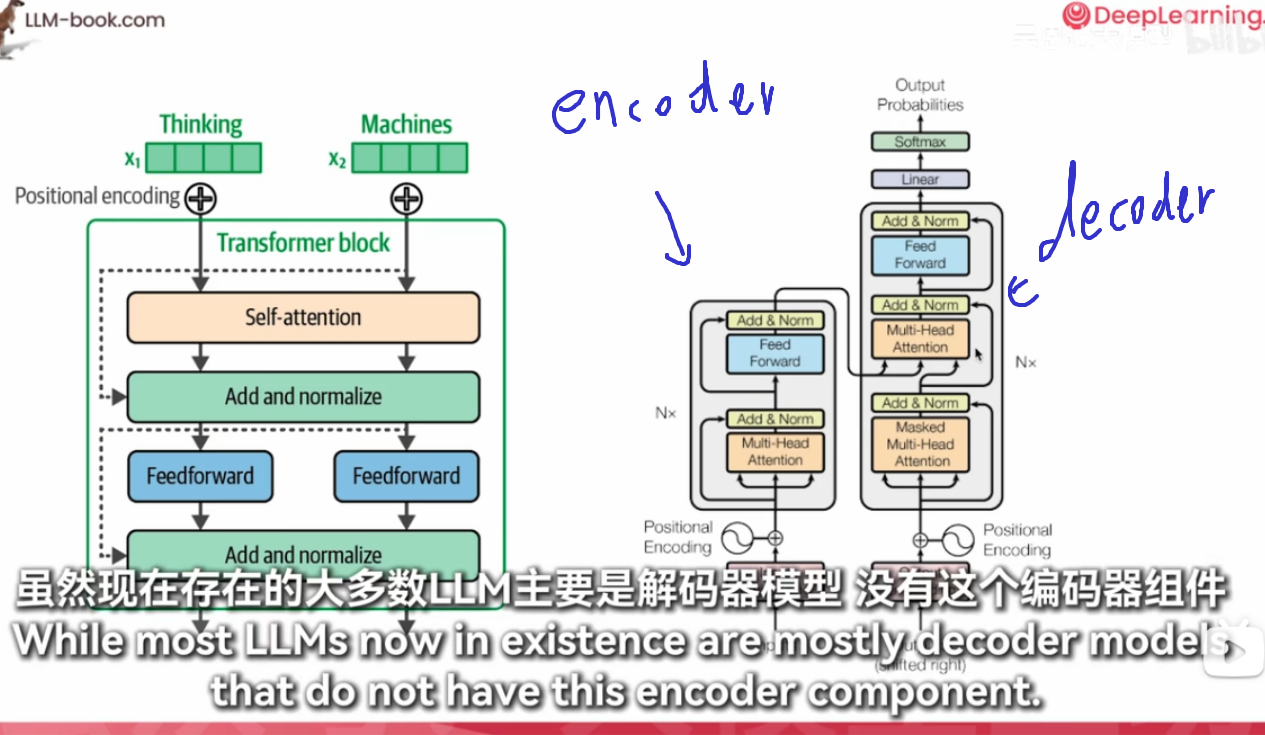
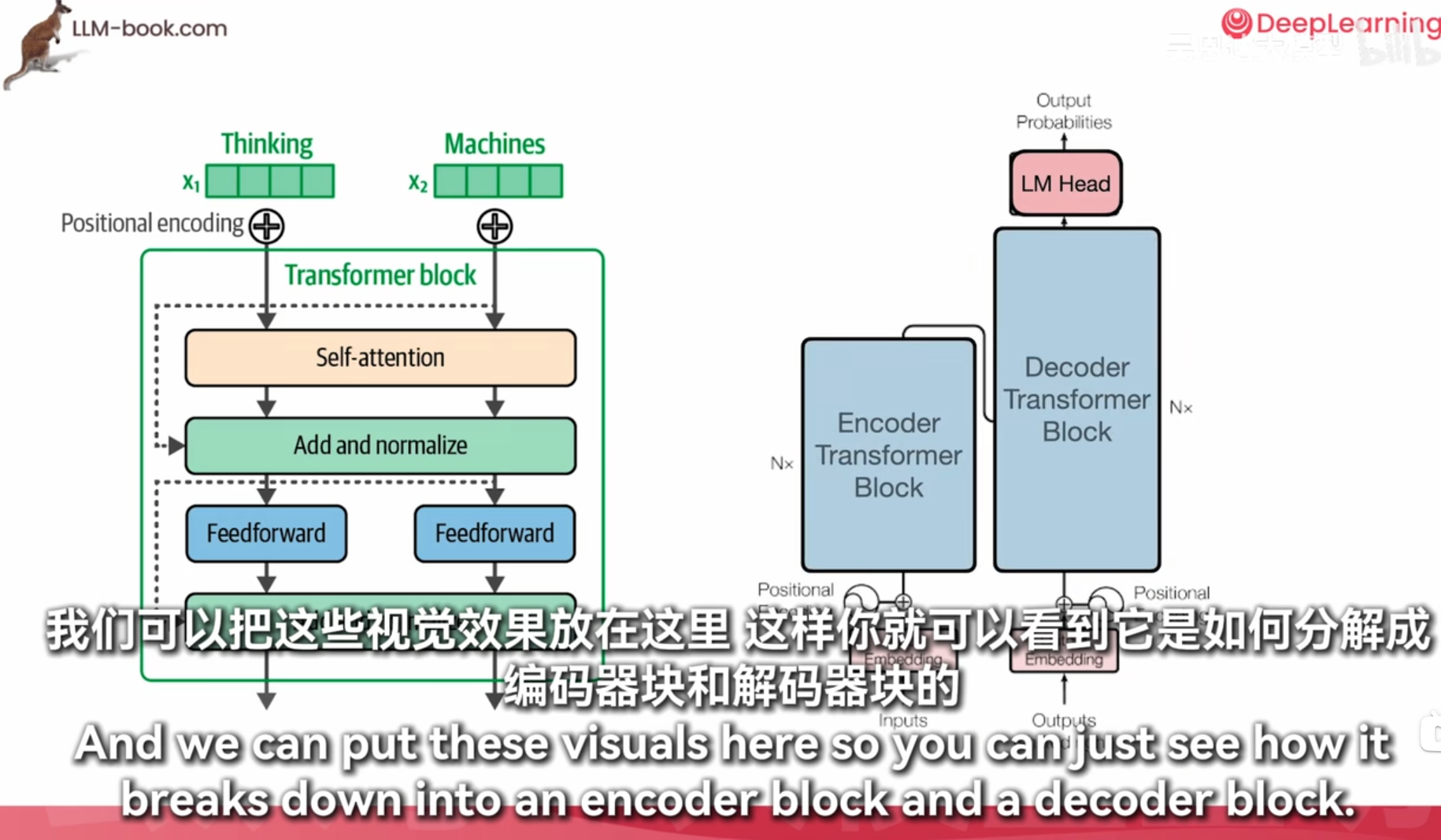

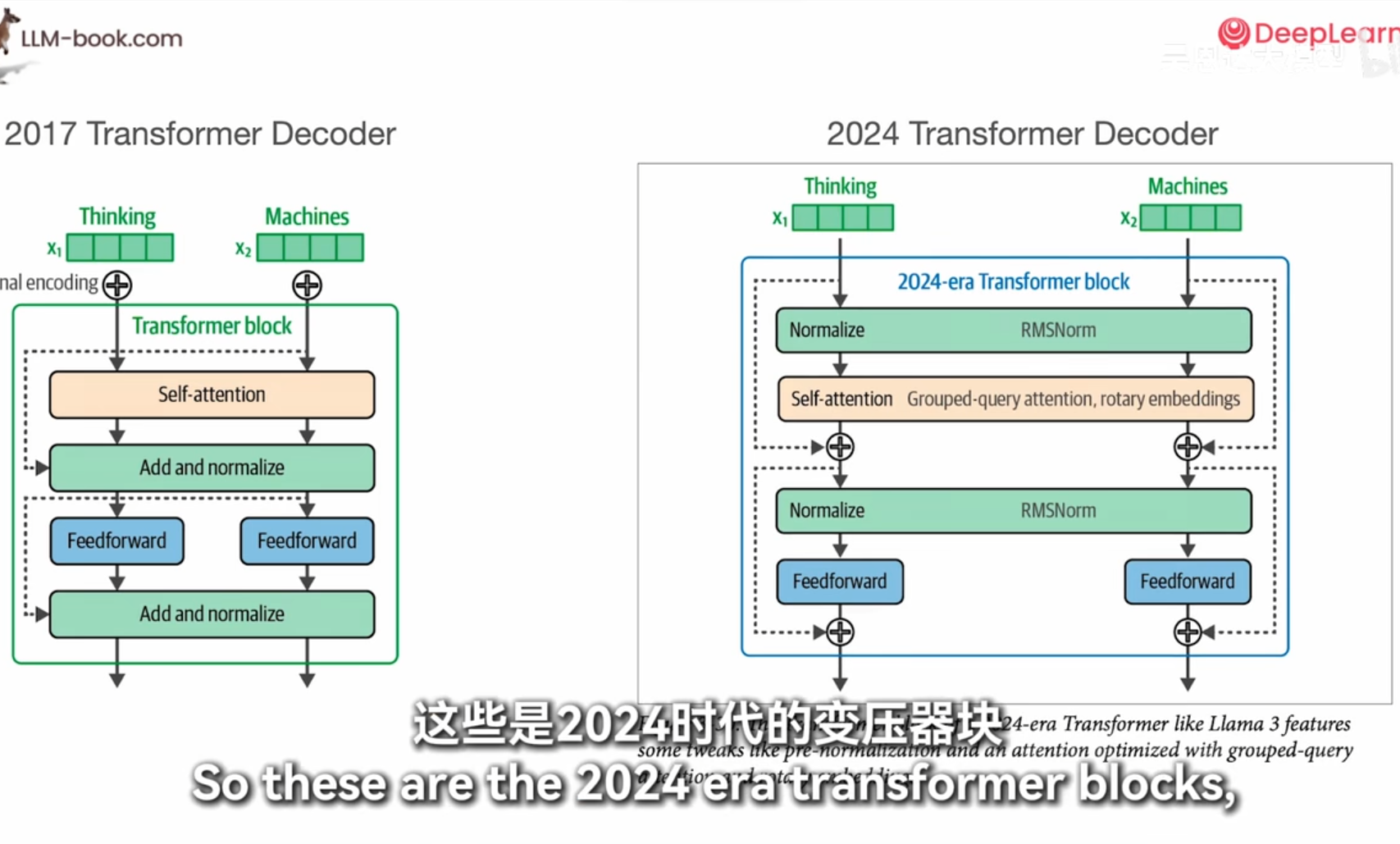
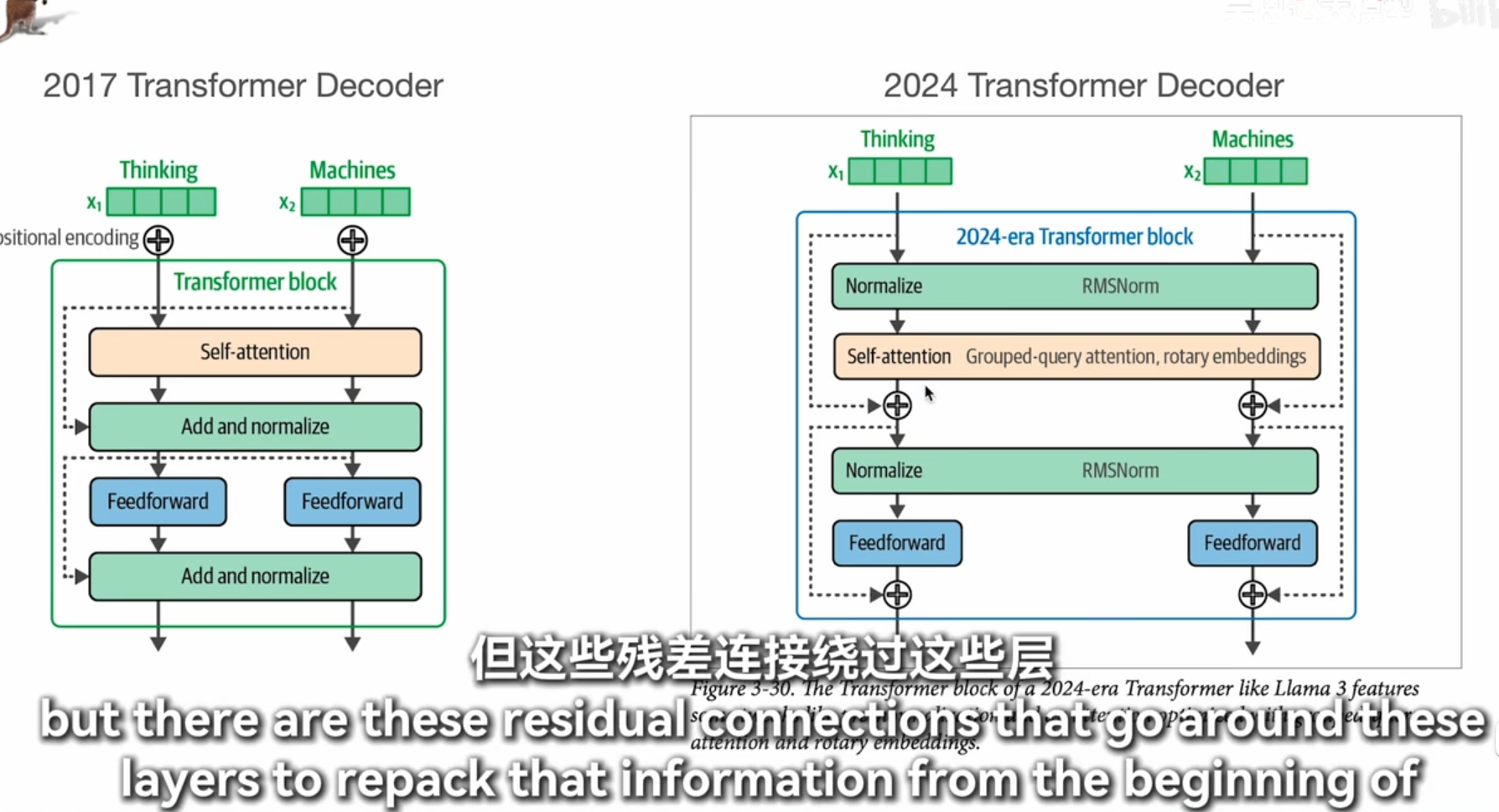

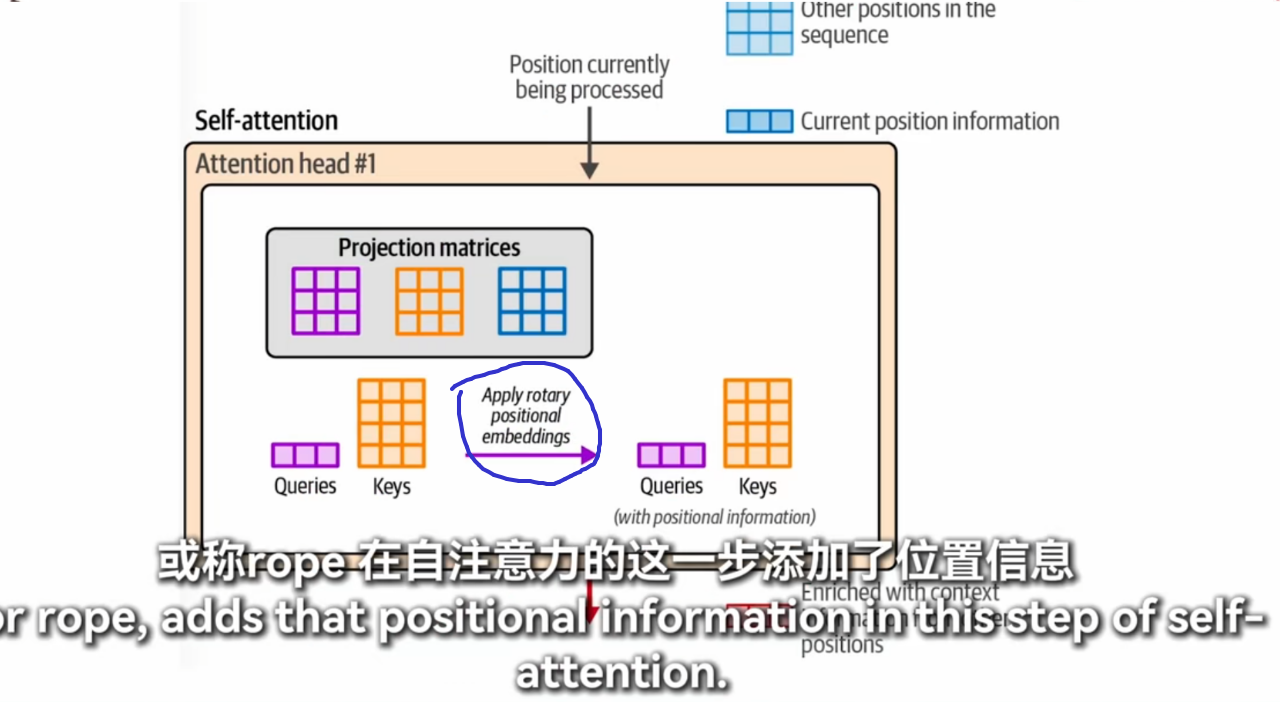
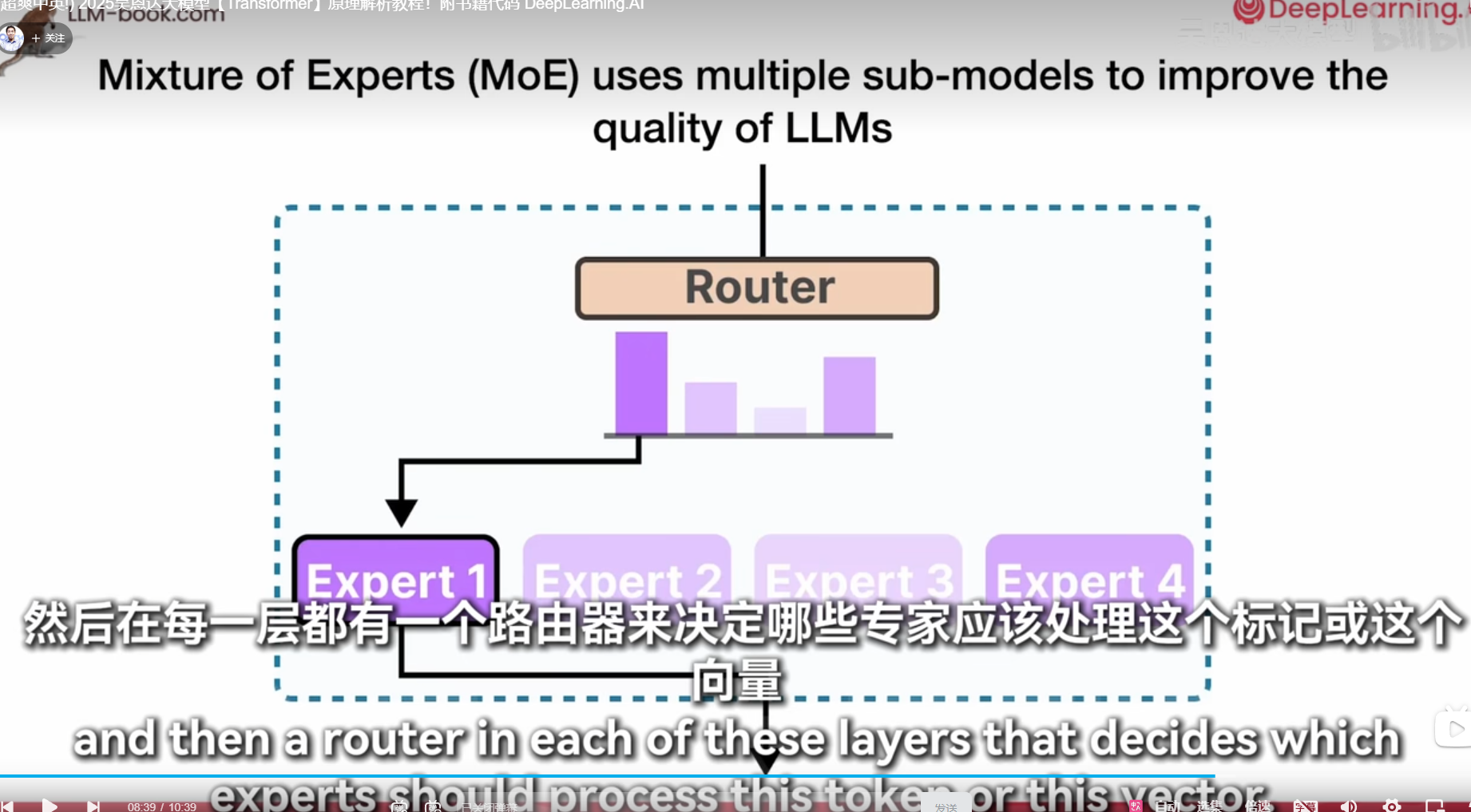
moe
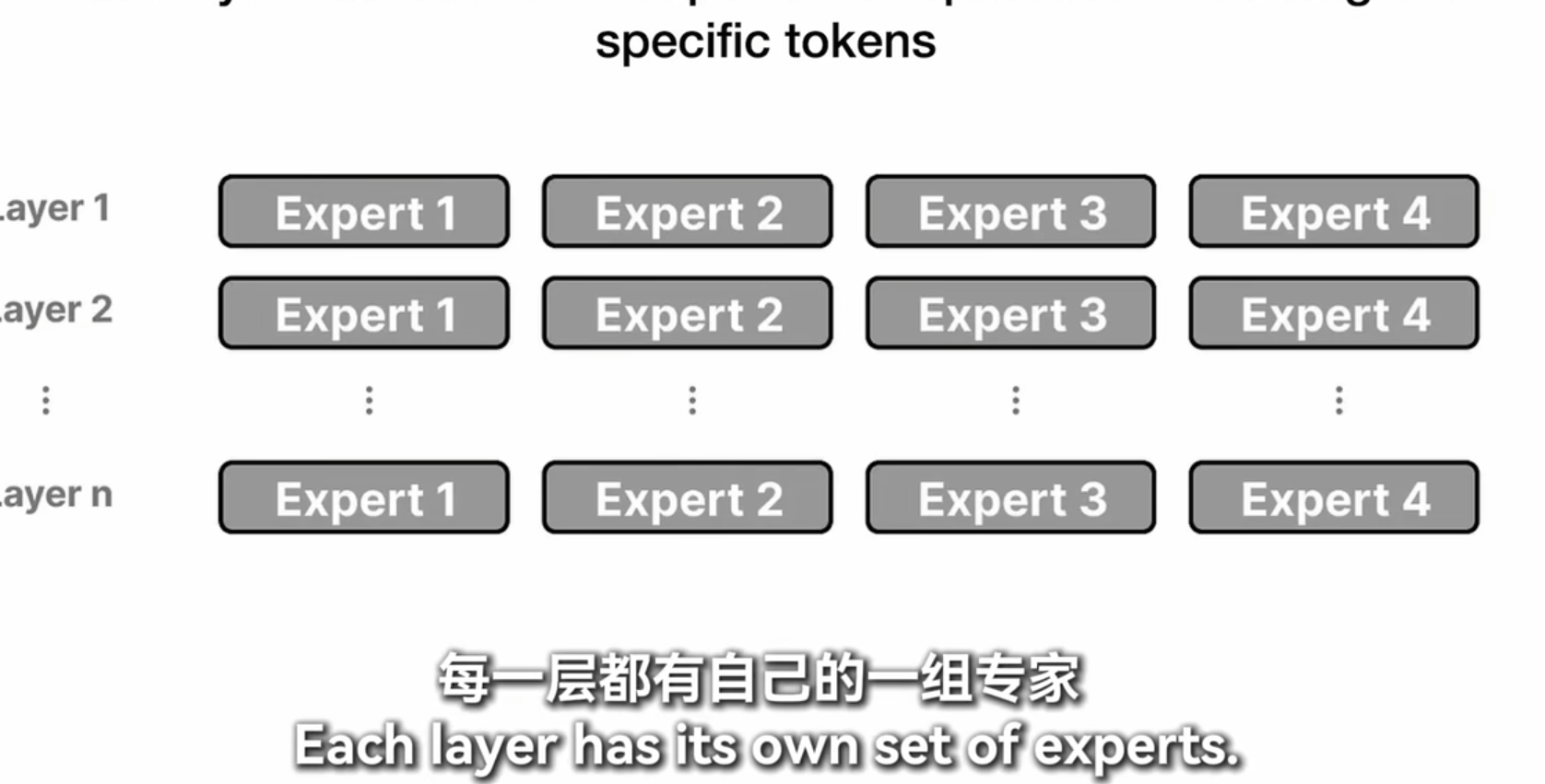

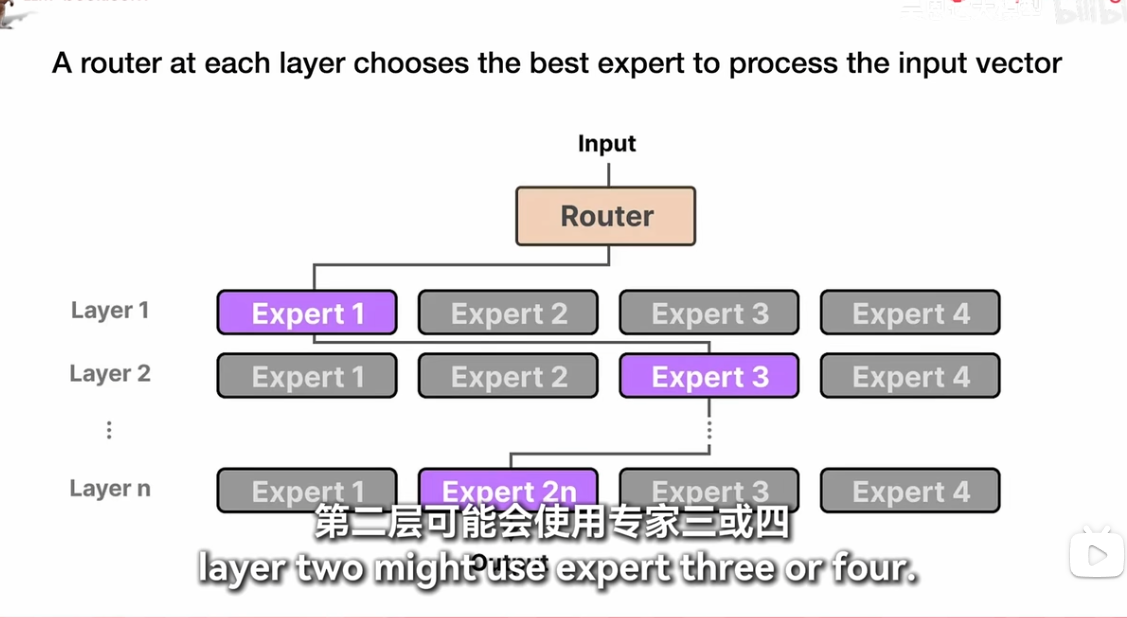
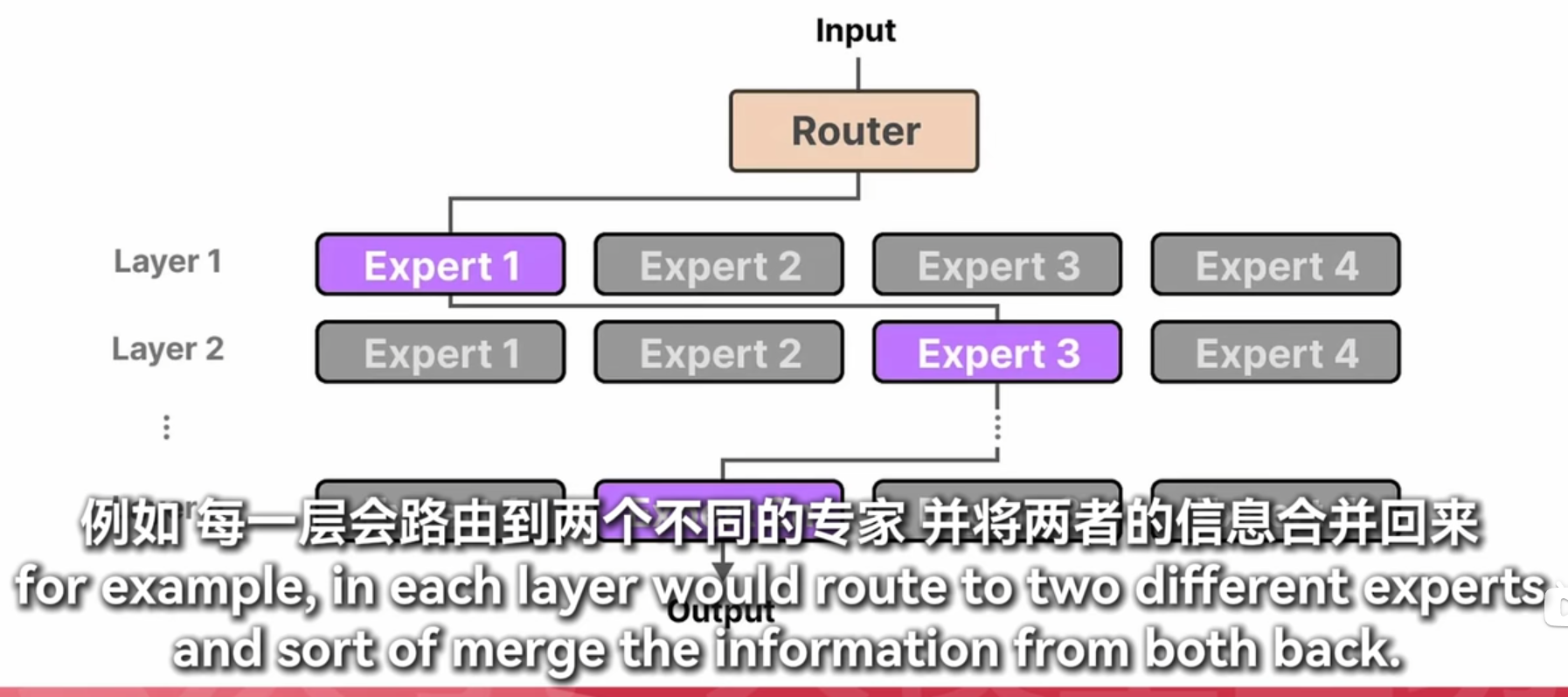
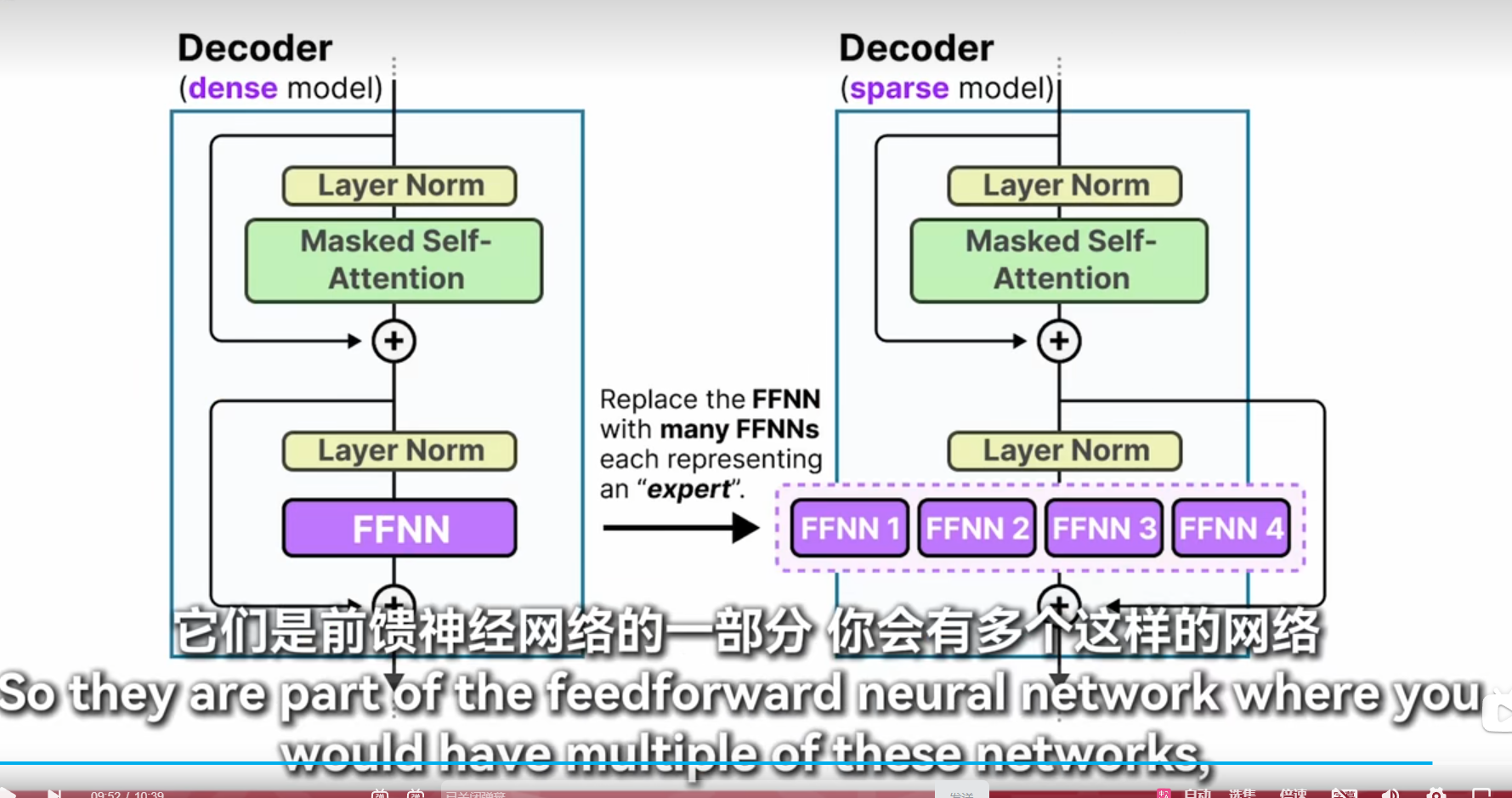
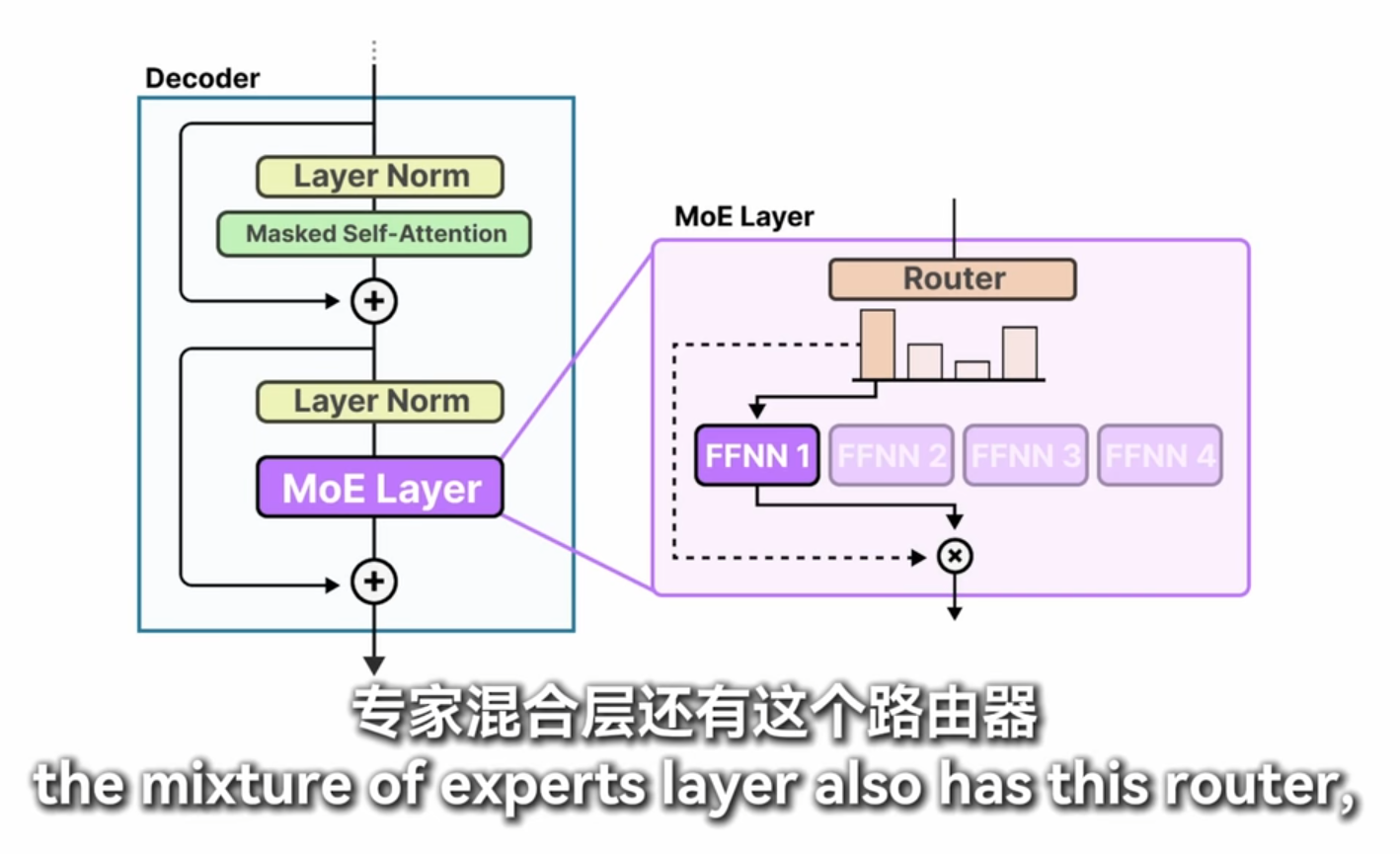

masked-self attention 和没有masked 的有什么区别

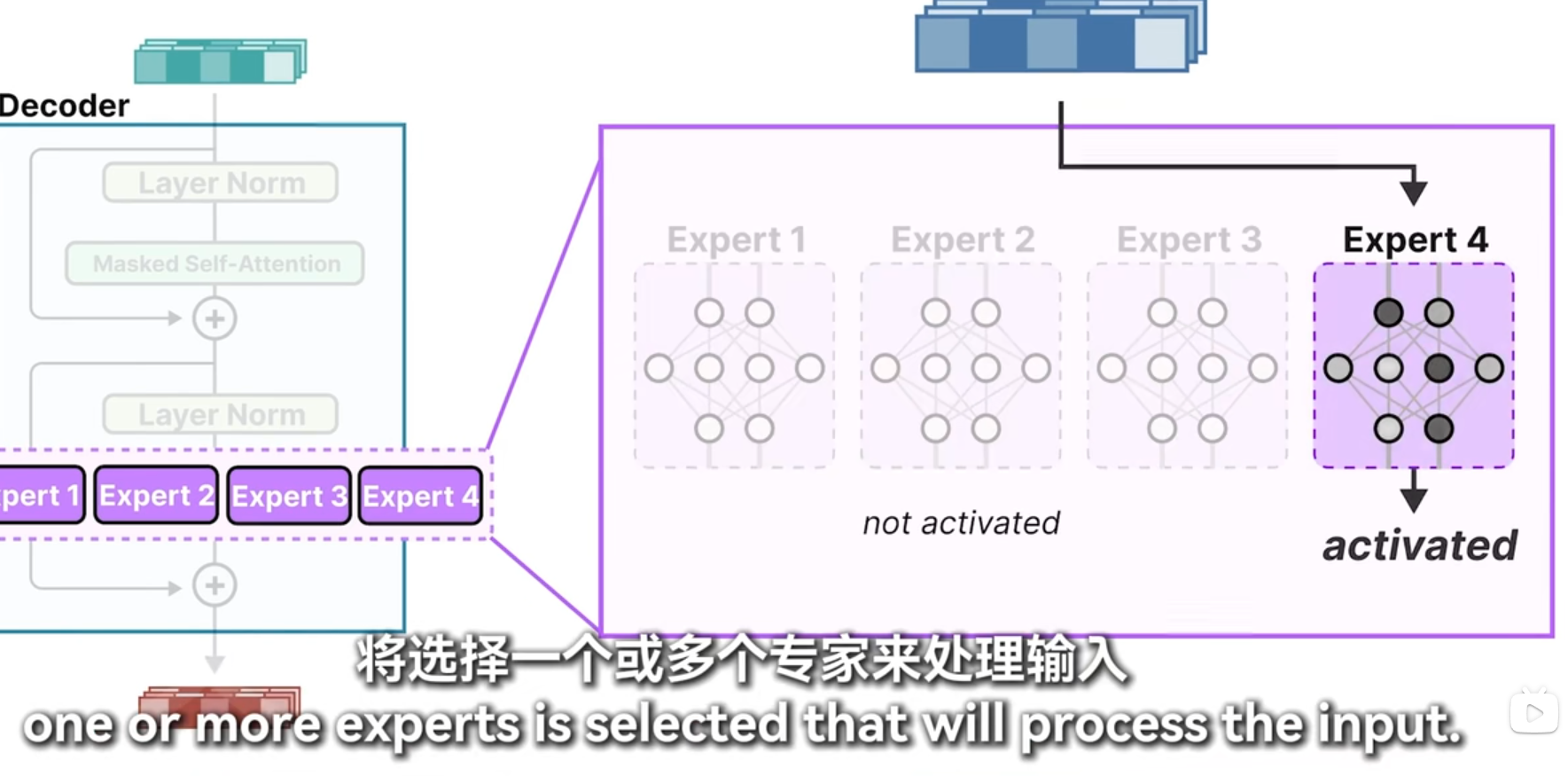
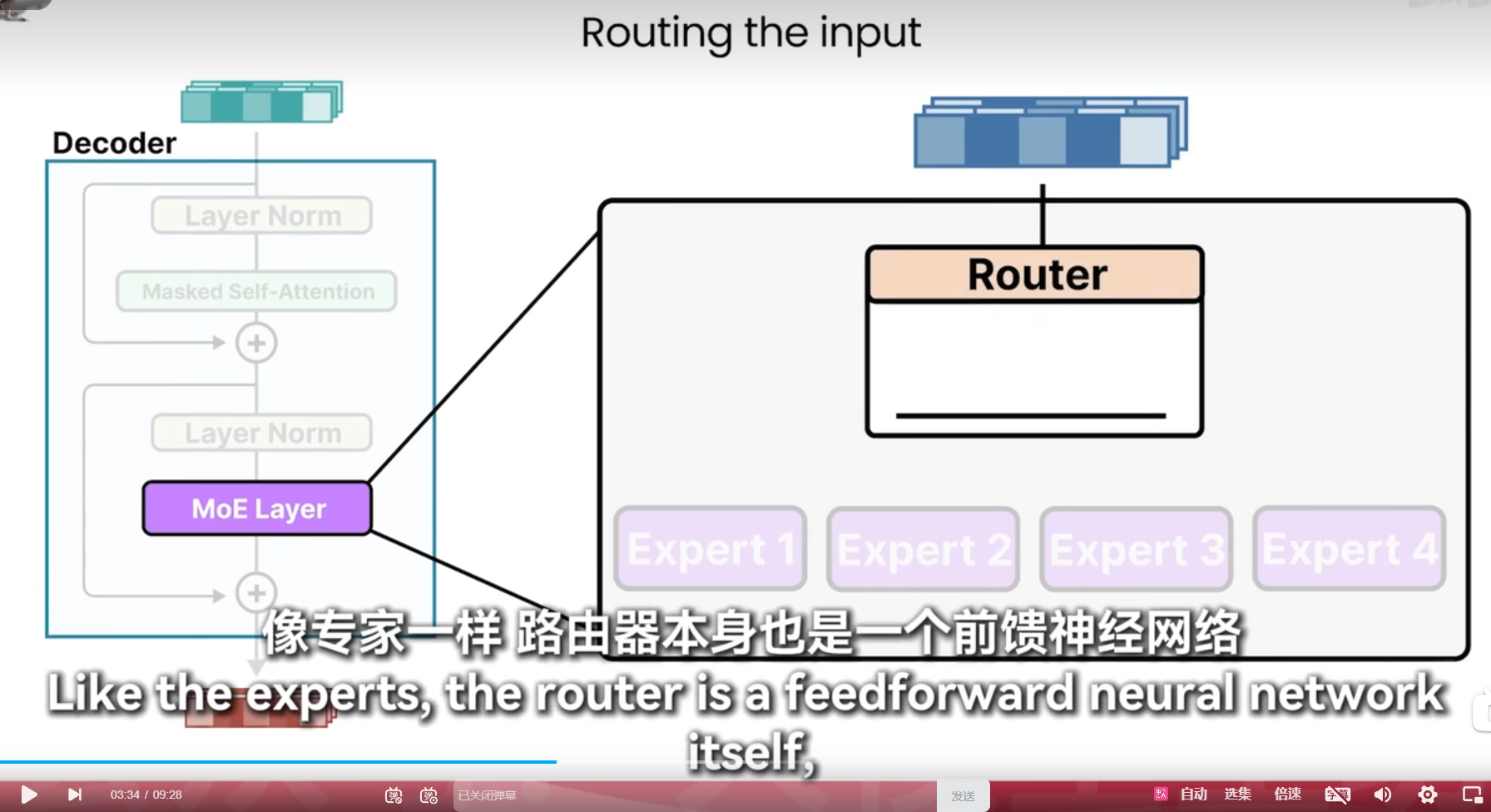
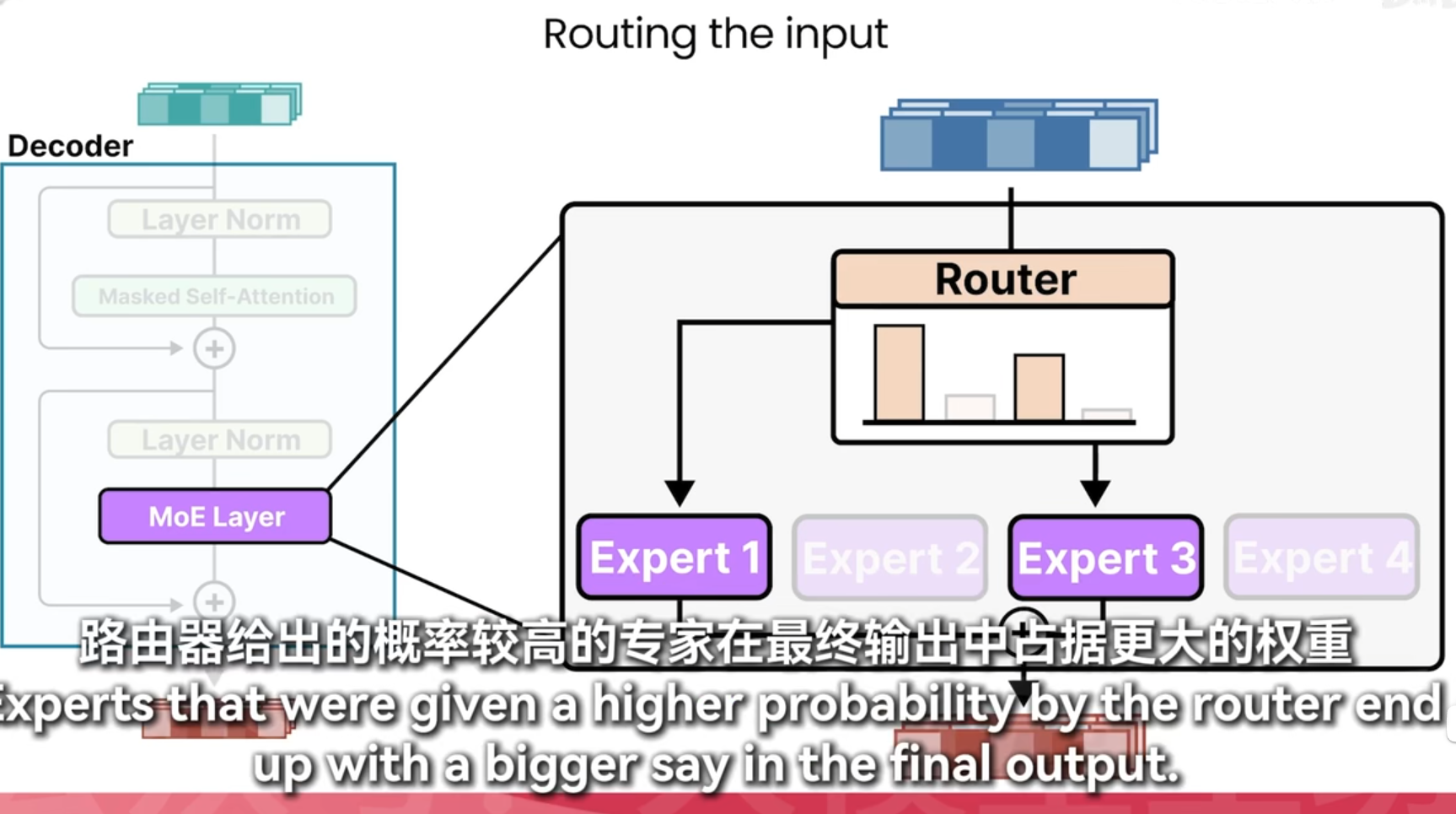





 加载要更多内存,推理要更少显存
加载要更多内存,推理要更少显存



动画讲解 Mamba 状态空间模型_哔哩哔哩_bilibili