想更好应对突发网络与业务问题?需要一款“全流量”工具
目录
什么是“全流量”?
为什么“全流量”在突发问题中如此重要?
1. 抓住问题发生的“第一现场”
2. 绕开日志盲区
3. 精准应对安全威胁
实战场景下的“全流量”价值体现
实施“全流量”需要注意哪些点?
1. 数据量巨大,需要高效存储与索引能力
2. 隐私合规问题不容忽视
3. 对网络架构的部署要求
“全流量”并不意味着监控的一切
写在最后
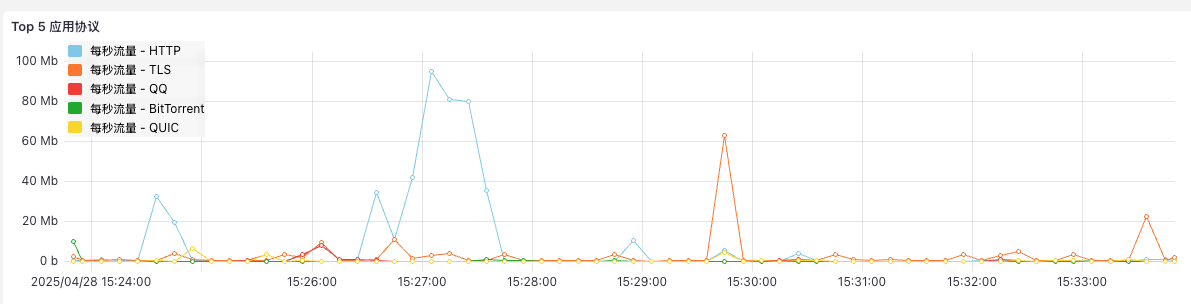
在如今这个数字化高压环境中,任何一秒钟的业务中断都可能意味着成千上万的损失。当系统“看起来”一切正常,用户却报障频发,你有没有想过:是不是你遗漏了什么关键的“盲点”?如果你只依赖于传统日志和采样监控,你可能已经错过了关键线索。答案也许就在一个词里——全流量可视化。
全流量采集、监控、分析、回溯![]() http://anatraf.com
http://anatraf.com
什么是“全流量”?
“全流量”指的是对网络中所有进出流量的无丢失采集、分析和回溯,而不是仅仅依赖于采样数据或应用日志。它涵盖L2-L7层的完整数据包,能够提供最原始、最还原真实场景的洞察基础。
与之相对的是采样型监控工具,它们往往只对一定比例的流量进行记录与分析。虽然可以减轻系统压力,但在应对突发网络异常、业务中断、甚至安全攻击时,往往无能为力。因为真正关键的异常,恰恰可能出现在被采样丢弃的那一小部分里。

为什么“全流量”在突发问题中如此重要?
1. 抓住问题发生的“第一现场”
一旦网络抖动、延迟飙升、或服务崩溃,“全流量”记录可以让你在事后按时间轴还原全部通信过程,准确定位问题源头。是哪个IP连接突增?是哪个API接口响应慢?有没有外部恶意扫描?所有答案都藏在原始流量里。
2. 绕开日志盲区
日志是宝贵的,但它依赖于应用本身的日志策略和记录完整性。某些业务模块若未打点,或日志服务本身挂了,就会留下巨大的盲区。而“全流量”不会依赖于业务开发,它从网络层出发,无感知、不依赖、不遗漏。
3. 精准应对安全威胁
面对内网横向移动、数据泄露、或加密通道中的恶意行为,传统IDS/IPS和防火墙很多时候只能基于特征识别进行粗略检测。而“全流量”结合行为分析,可以深度识别异常访问模式、非正常加密流量行为、甚至流量通道中的隐写信息。
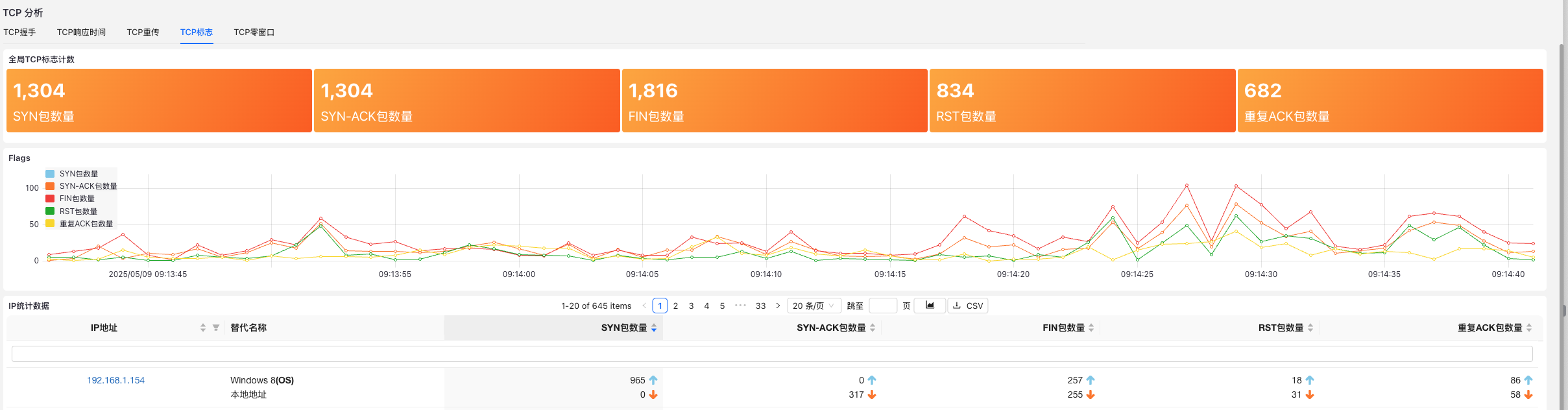
实战场景下的“全流量”价值体现
-
网络性能故障分析:例如用户反馈系统慢,但服务器负载正常,数据库响应正常,查日志也无异常。此时“全流量”分析可能会揭示——请求在出口NAT层严重排队,或者内网DNS查询重试不断,问题就迎刃而解。
-
突发DDoS攻击处置:高峰期被攻击时,仅凭采样数据无法准确评估攻击规模和入口IP。“全流量”不仅可以实时展现攻击源,还可以导出流量特征供防火墙动态封禁。
-
系统间调用异常排查:某服务偶发报错但无法复现,通过“全流量”数据分析,发现某些特定时间段内部RPC连接失败,并进一步追踪到底层连接建立失败的TCP三次握手丢包原因。
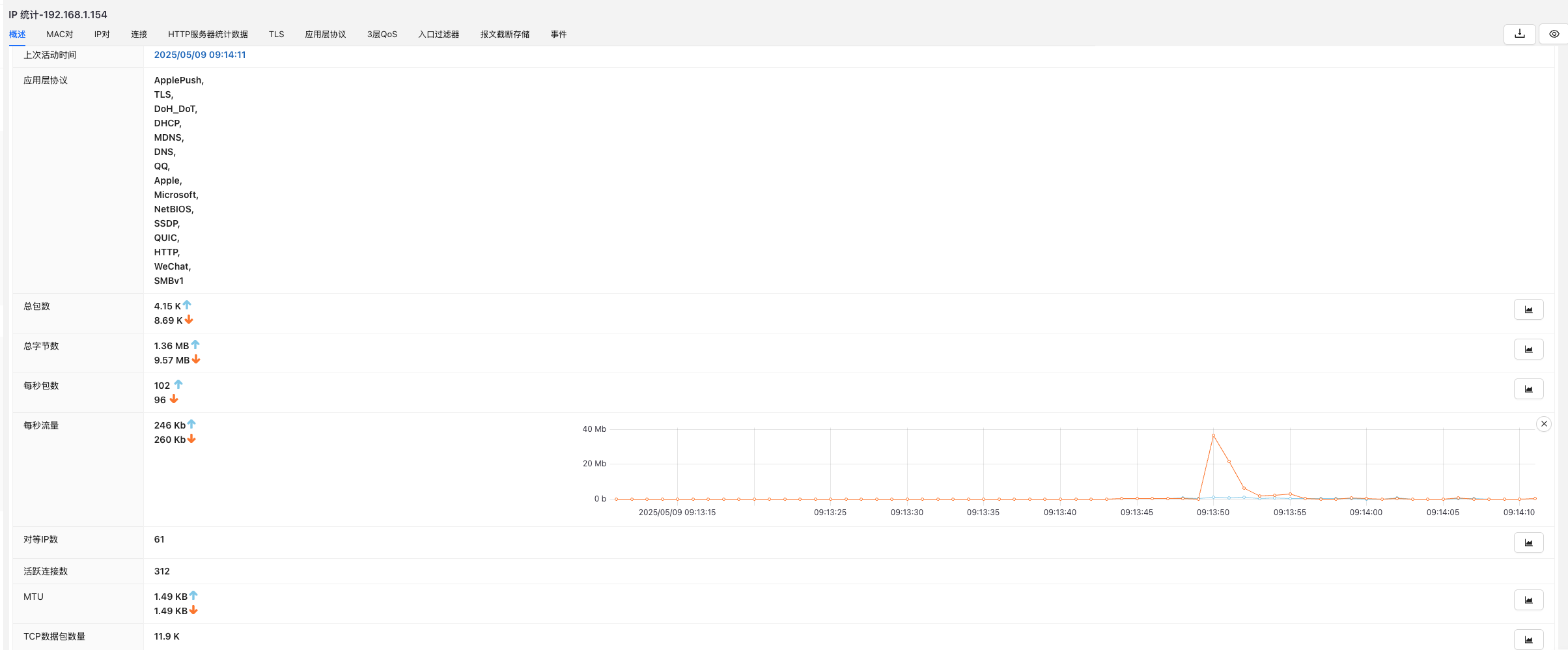
实施“全流量”需要注意哪些点?
虽然“全流量”提供了强大的分析基础,但也带来了挑战:
1. 数据量巨大,需要高效存储与索引能力
以千兆网络为例,每小时的流量数据可能以TB计。如何快速索引和调取关键片段,需要强大的流量归档与检索系统。
2. 隐私合规问题不容忽视
全流量意味着抓取了大量明文或加密数据,其中可能包含用户敏感信息。需要配合数据脱敏、权限控制、存储加密等手段合规操作。
3. 对网络架构的部署要求
实现全流量通常需要部署旁路探针、镜像流量或使用Tap设备,确保关键流量节点被完整覆盖。对于云环境,也需要配合云厂商的流量复制方案。
“全流量”并不意味着监控的一切
需要强调的是,“全流量”是一种补充而非替代。它不能替代业务日志,也不能替代APM、链路追踪系统。最理想的运维体系应是多维度协同:从日志到指标、从链路到流量,各司其职,相辅相成。
不过,在真正紧急、复杂的网络与业务异常场景下,唯有“全流量”能够让你有底气说出那句话——“我们能还原一切”。
写在最后
如果你经常陷入“查不到问题”的困境,或者每次排障都像“抓瞎”,那么该考虑引入“全流量”能力了。它并不是一个简单的工具,而是一种能力,一种让你真正掌控网络本质运行状态的能力。
未来的运维、安全和分析趋势,注定是更原生、更实时、更细粒度的数据支撑。而“全流量”,是这条路上不可或缺的基石。