【AI论文】绝对零度:基于零数据的强化自博弈推理
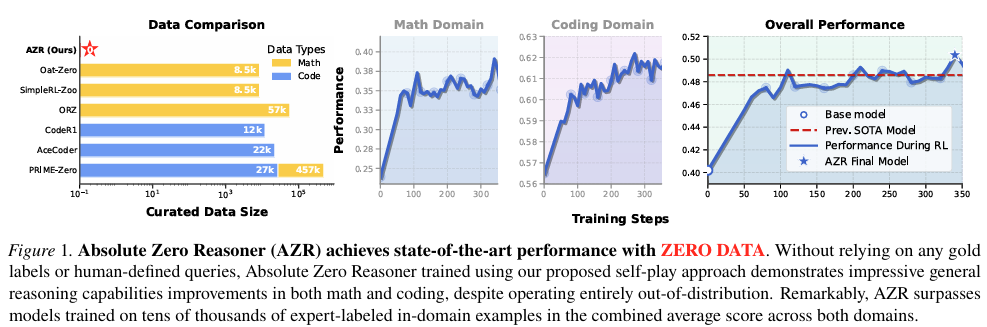
摘要:基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)已展现出通过直接从基于结果的奖励中学习来增强大型语言模型推理能力的潜力。最近的RLVR研究在零设置(zero setting)下运作,避免了在标注推理过程时的监督需求,但仍然依赖于人工精心策划的问题和答案集合进行训练。高质量、人类生成示例的稀缺性引发了人们对长期依赖人类监督的可扩展性的担忧,这一问题在语言模型预训练领域已经显而易见。此外,在一个假设的未来中,如果人工智能超越了人类智能,那么人类提供的任务对于超级智能系统来说可能提供的学习潜力有限。为了解决这些担忧,我们提出了一种新的RLVR范式,称为“绝对零度”(Absolute Zero),在该范式中,单个模型学习提出能够最大化其自身学习进展的任务,并通过解决这些任务来改进推理能力,而无需依赖任何外部数据。在这一范式下,我们引入了绝对零度推理器(Absolute Zero Reasoner, AZR),这是一个通过使用代码执行器来验证所提出的代码推理任务和答案的系统,作为引导开放式但有根据学习的统一可验证奖励来源。尽管完全在没有外部数据的情况下进行训练,AZR在编码和数学推理任务上实现了总体上的最先进(SOTA)性能,超越了依赖数万个领域内人工策划示例的现有零设置模型。此外,我们还证明了AZR可以有效地应用于不同规模的模型,并且与各种模型类别兼容。Huggingface链接:Paper page,论文链接:2505.03335
研究背景和目的
研究背景
近年来,强化学习与可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)的结合在提升大型语言模型(Large Language Models, LLMs)的推理能力方面展现出了巨大潜力。通过直接从结果导向的奖励中学习,RLVR方法能够绕过传统监督学习中的标注瓶颈,使模型在各种复杂任务中展现出更强的适应性和泛化能力。然而,现有的RLVR方法仍然依赖于人工策划的问题-答案对集进行训练,这不仅限制了数据的规模和多样性,还增加了对人类监督的依赖,从而限制了模型自主学习的潜力和长期可扩展性。
此外,随着人工智能技术的不断进步,未来AI系统有望超越人类智能。在这一背景下,完全依赖人类监督的任务提供方式可能无法满足超级智能系统对学习材料的需求,因为人类可能无法为这些系统提供足够复杂和多样化的学习任务。因此,探索一种无需外部数据、完全自主的学习范式,对于推动AI技术的长远发展具有重要意义。
研究目的
本文的研究目的在于提出一种全新的RLVR范式——“绝对零”(Absolute Zero),旨在消除对任何外部数据的依赖,使模型能够自主生成学习任务并通过自我对弈(self-play)的方式进行强化学习。具体而言,本研究旨在:
- 消除对人类监督的依赖:通过设计一种完全自主的学习机制,使模型能够在没有人类策划的数据集的情况下进行训练。
- 提升模型的自主推理能力:通过引入长思维链(Chains-of-Thought, CoT)推理,增强模型在复杂任务中的推理能力和决策水平。
- 探索模型自主进化的可能性:研究模型在自我对弈过程中如何通过不断生成和解决新任务来提升自身能力,实现自我进化。
- 验证新范式的有效性:通过在数学和编程任务上的广泛实验,验证“绝对零”范式在提升模型性能方面的有效性和优越性。
研究方法
方法概述
本文提出的“绝对零”范式通过以下步骤实现模型的自主训练:
- 冷启动阶段(Cold Start):使用少量精心挑选的种子任务初始化模型,使模型初步掌握长思维链推理的格式和结构。
- 自我对弈阶段(Self-play):模型同时扮演任务提出者(Proposer)和解决者(Solver)的角色,通过自我对弈的方式不断生成新任务并尝试解决。提出者负责设计具有挑战性的新任务,解决者则尝试解决这些任务,双方通过环境反馈(即可验证奖励)进行学习和优化。
- 强化微调阶段(Reinforcement Fine-tuning):基于组相对策略优化(Group Relative Policy Optimization, GRPO)的强化学习算法,对模型进行微调,以优化其任务生成和解决能力。
关键技术
-
长思维链推理:通过将长思维链推理融入奖励推理过程中,增强模型在复杂任务中的推理深度和可靠性。模型在生成和解决任务时,需要展示出清晰的思维链条,确保每一步推理都有据可依。
-
自我对弈机制:模型在自我对弈过程中,同时扮演提出者和解决者的角色。提出者负责设计新任务,解决者则尝试解决这些任务。双方通过环境反馈进行学习和优化,形成一种动态的博弈过程,促进模型能力的不断提升。
-
可验证奖励:环境作为可验证的奖励源,为模型提供明确的反馈信号。当模型成功解决任务时,获得正奖励;当任务失败时,获得负奖励。这种明确的反馈机制有助于模型快速收敛到最优策略。
-
组相对策略优化(GRPO):基于GRPO的强化学习算法用于微调模型。GRPO通过比较不同任务组之间的相对性能来优化策略,有效避免了全局基线带来的高方差问题,提高了训练的稳定性和效率。
研究结果
实验设置
本文在数学和编程任务上进行了广泛实验,以验证“绝对零”范式的有效性。实验采用了多种基准测试集,包括AIME、OlympiadBench、MATH500等数学推理任务,以及HumanEval+、MBPP+等编程任务。同时,为了全面评估模型的性能,还设计了不同规模的模型变体(如3B、7B、14B参数模型)进行对比实验。
主要结果
-
超越零设置模型:在数学和编程任务上,“绝对零”模型(AZR)均取得了显著优于现有零设置模型(即无需外部数据训练的模型)的性能。特别是在数学推理任务上,AZR模型在多个基准测试集上实现了平均超过1.8个百分点的性能提升。
-
跨领域泛化能力:AZR模型在跨领域任务上展现出了强大的泛化能力。即使在没有直接训练过的任务上,AZR模型也能通过自我对弈和强化学习快速适应并取得优异成绩。这一结果表明,“绝对零”范式有助于模型学习到更通用的推理能力。
-
模型规模效应:实验结果表明,随着模型规模的增大,AZR模型的性能提升更加显著。特别是在14B参数模型上,AZR模型在数学和编程任务上的性能提升均超过了10个百分点。这一发现为未来更大规模模型的研究提供了有力支持。
-
任务类型的重要性:通过消融实验发现,不同任务类型(如归纳、演绎、溯因)在模型训练过程中发挥着不可或缺的作用。去除任何一种任务类型都会导致模型性能显著下降。这一结果表明,多样化的任务类型对于模型学习到全面的推理能力至关重要。
研究局限
尽管“绝对零”范式在提升模型自主推理能力方面取得了显著成果,但仍存在以下局限:
-
计算资源需求高:自我对弈和强化学习过程需要大量的计算资源支持。特别是在模型规模较大时,训练过程对硬件的要求更高,限制了该方法的广泛应用。
-
训练时间长:由于模型需要通过自我对弈不断生成和解决新任务,训练过程相对漫长。即使在小规模模型上,也需要数天甚至数周的时间才能完成训练。
-
潜在的安全风险:在自我对弈过程中,模型可能会生成一些意想不到的思维链条,甚至产生有害或偏见的输出。这要求未来研究在提升模型性能的同时,加强对模型输出安全性的监控和管理。
未来研究方向
针对“绝对零”范式的局限性和挑战,未来研究可以从以下几个方面展开:
-
优化训练效率:探索更高效的自我对弈和强化学习算法,减少计算资源需求和训练时间。例如,可以采用分布式训练、模型剪枝等技术来加速训练过程。
-
增强模型安全性:设计更加完善的安全机制来监控和管理模型的输出。例如,可以引入对抗训练、安全约束等技术来防止模型生成有害或偏见的输出。
-
拓展应用领域:将“绝对零”范式应用于更多领域和任务中,验证其通用性和可扩展性。例如,在自然语言处理、计算机视觉等领域探索该范式的应用潜力。
-
深入研究模型自主进化机制:进一步探索模型在自我对弈过程中如何通过不断生成和解决新任务来提升自身能力。例如,可以研究模型在不同任务类型上的学习偏好和进化路径,为模型自主进化提供更深入的理论支持。
-
结合多模态信息:探索如何将多模态信息融入“绝对零”范式中,进一步提升模型的推理能力和决策水平。例如,在视觉问答、图像生成等任务中利用图像和文本等多模态信息来丰富模型的推理过程。