如何处理oracle 12c DG归档日志缺失(gap)导致备库同步中断问题
DG实验环境介绍:
| instance_name | 架构 | |
| 主库 | orcl | 单实例 |
| 备库 | orclstd | 单实例 |
若着急处理故障,可跳过下面‘一 故障模拟’这一步,直接看‘二 解决办法’
一 故障模拟
这里通过在主库禁用归档日志传输,在主库mv几个归档日志,期间造几条数据,在主库新增个数据文件,模拟下归档日志丢失导致的备库同步中断,丢失数据的情况。
1.1 在主库禁用归档日志传输
alter system set log_archive_dest_state_2 =defer;
1.2 查看主备当前最新归档日志
SELECT NAME,SEQUENCE#, FIRST_TIME, NEXT_TIME FROM V$ARCHIVED_LOG ORDER BY SEQUENCE#;
![]()
1.3 在主库造几条数据,切几次归档

这3条数据没同步到备库。
#主库
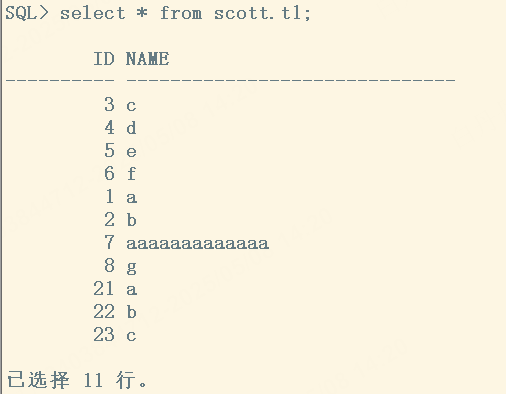
#备库

1.4 在主库模拟删除这几个归档
[oracle@host01 arch]$ mv 1_1173_1164727119.dbf 1_1173_1164727119.dbf_bak
[oracle@host01 arch]$ mv 1_1174_1164727119.dbf 1_1174_1164727119.dbf_bak
[oracle@host01 arch]$ mv 1_1175_1164727119.dbf 1_1175_1164727119.dbf_bak
1.5 在主库开启归档日志传输
alter system set log_archive_dest_state_2 =enable;
1.6 在备库查看归档日志gap
SQL> select * from v$archive_gap;
THREAD# LOW_SEQUENCE# HIGH_SEQUENCE# CON_ID
---------- ------------- -------------- ----------
1 1173 1175 1
可以看到产生了gap。
之后主库产生的归档日志同步到备库了,但是SEQUENCE为1173和1175的没同步到备库。
而且故障之后的数据也没同步到备库。
1.7 在主库新增个表空间及数据文件
create tablespace user2 datafile '/data/app/oracle/oradata/orcl/users2_01.dbf' size 10m;
二 解决办法
2.1 查看备库v$dataguard_status有何报错
select message from v$dataguard_status;
最新报错:
FAL[client]: Error fetching gap sequence, no FAL server specified
SQL> alter system set fal_server=orcl;
select message from v$dataguard_status;
最新报错:
FAL[client]: Failed to request gap sequence
GAP - thread 1 sequence 1173-1175
DBID 1692507853 branch 1164727119
2.2 刷新备库控制文件
2.2.1 在备库查询当前SCN
select current_scn from v$database;

记录下查询出来的scn,这里是41050771,后面会用到。
2.2.2 保存备库当前rman配置
#在备库上操作
su - oracle
rman target / nocatalog log=/tmp/RMAN_settings.log << EOF
show all;
EOF
#移除没用的信息
grep ^CONFIGURE /tmp/RMAN_settings.log | grep -v 'RETENTION POLICY' >/tmp/RMAN_settings.rman
rm /tmp/RMAN_settings.log
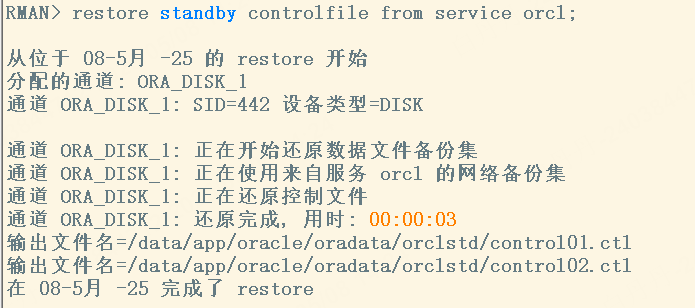
2.2.3 刷新备库控制文件 --关键步骤
#在备库操作
shutdown immediate;
rman target / nocatalog
RMAN> startup nomount
RMAN> restore standby controlfile from service <tns alias for primary database>;
这里是 restore standby controlfile from service orcl;
2.2.4 替换RMAN配置
#替换RMAN配置
RMAN> alter database mount;
RMAN> @/tmp/RMAN_settings.rman
2.2.5 Catalog Standby Database Files to the Refreshed Control File
2.2.5.1 CATALOG START WITH DATAFILE
此时,刷新的控制文件具有来自主数据库的文件位置和元数据。使用RMAN CATALOG命令用备用数据库文件位置更新控制文件。
catalog start with '数据文件路径';
这里是:
catalog start with '/data/app/oracle/oradata/orclstd';
/*
SQL> select name from v$datafile;
NAME
--------------------------------------------------------------------------------
/data/app/oracle/oradata/orclstd/system01.dbf
/data/app/oracle/oradata/orclstd/baidd02.dbf
/data/app/oracle/oradata/orclstd/sysaux01.dbf
/data/app/oracle/oradata/orclstd/undotbs01.dbf
/data/app/oracle/oradata/orclstd/baidd01.dbf
/data/app/oracle/oradata/orclstd/users01.dbf
*/
RMAN> catalog start with '/data/app/oracle/oradata/orclstd';
中间输入个YES
2.2.5.2 CATALOG START WITH REDO LOG
catalog start with '<RECO DISKGROUP>/<standby db_unique_name>/';
这里是:
/data/app/oracle/oradata/orclstd
/*
SQL> SELECT MEMBER FROM V$LOGFILE;
MEMBER
--------------------------------------------------------------------------------
/data/app/oracle/oradata/orclstd/redo03.log
/data/app/oracle/oradata/orclstd/redo02.log
/data/app/oracle/oradata/orclstd/redo01.log
/data/app/oracle/oradata/orclstd/STANDBYREDO04.LOG
/data/app/oracle/oradata/orclstd/STANDBYREDO05.LOG
/data/app/oracle/oradata/orclstd/STANDBYREDO06.LOG
/data/app/oracle/oradata/orclstd/STANDBYREDO07.LOG
已选择 7 行。
*/
2.2.6 restore丢失的文件
如果在备库的SCN和刷新的控制文件的SCN之间创建过数据文件,则文件将丢失。
识别任何丢失的文件并恢复它们。
SQL> select file#,name from v$datafile where creation_change# >= 41050771;
FILE# NAME
---------- --------------------------------------------------
8 /data/app/oracle/oradata/orclstd/users2_01.dbf
41050771是2.2.1 ‘在备库查询当前SCN’那里查询出来的值。
如果查询结果为空,则跳过该步骤,如果查询返回有内容,则必须还原文件。
run
{
set newname for database to orclstd;
restore datafile 8 FROM SERVICE orcl;
}
#上面标黄的orclstd是备库instance_name,8是备库比主库少的数据文件的FILE#,orcl是主库instance_name

2.2.7 Switch Database to Copy
RMAN> switch database to copy;
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: 位于 05/08/2025 14:45:18 的 switch to copy 命令失败
RMAN-06571: 数据文件 1 没有可恢复的副本
报这个错没关系,继续往下进行。
2.2.8 Clean Up Orphaned Files
如果在备用的SCN和刷新的控制文件的SCN之间删除了任何文件,则该文件仍将是RMAN中的数据文件副本。删除任何数据文件副本以删除不需要的文件。
RMAN> list datafilecopy all;
RMAN> delete datafilecopy all;
2.3 清理online redo log和standby log file
#在备库操作
SQL> select group#,member from v$logfile order by group#;
GROUP# MEMBER
---------- --------------------------------------------------
1 /data/app/oracle/oradata/orclstd/redo01.log
2 /data/app/oracle/oradata/orclstd/redo02.log
3 /data/app/oracle/oradata/orclstd/redo03.log
4 /data/app/oracle/oradata/orclstd/STANDBYREDO04.LOG
5 /data/app/oracle/oradata/orclstd/STANDBYREDO05.LOG
6 /data/app/oracle/oradata/orclstd/STANDBYREDO06.LOG
7 /data/app/oracle/oradata/orclstd/STANDBYREDO07.LOG
alter database clear logfile group 1;
alter database clear logfile group 2;
alter database clear logfile group 3;
alter database clear logfile group 4;
alter database clear logfile group 5;
alter database clear logfile group 6;
alter database clear logfile group 7;
2.4 Roll the Standby Database Forward
2.4.1 将备库重新启动到mount状态
shutdown immediate;
startup mount;
2.4.2 执行Recover From Service --关键步骤
RMAN> recover database from service orcl noredo using compressed backupset;
这里的orcl是主库的instance_name
2.5 将数据库启动到open状态
alter database open;
2.6 开始应用日志日志
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE using current logfile DISCONNECT FROM SESSION;
SQL> select open_mode,database_role from v$database;
OPEN_MODE DATABASE_ROLE
-------------------- ----------------
READ ONLY WITH APPLY PHYSICAL STANDBY
2.7 验证主库故障期间产生的数据是否恢复到了备库

可以看到丢失的归档日志对应的数据同步到了备库。
--本篇文章参考自:
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=354541008397548&id=2850185.1&_adf.ctrl-state=byh8d5ycd_52