【论文+VLA】2505.GraspVLA——基于十亿级合成动作数据预训练的抓取基础模型(即将开源)
时间:2025.05.07
项目地址:https://pku-epic.github.io/GraspVLA-web/
论文: 2505.GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
媒体报道:真机数据白采了?银河通用具身VLA大模型已充分泛化,预训练基于仿真合成大数据!
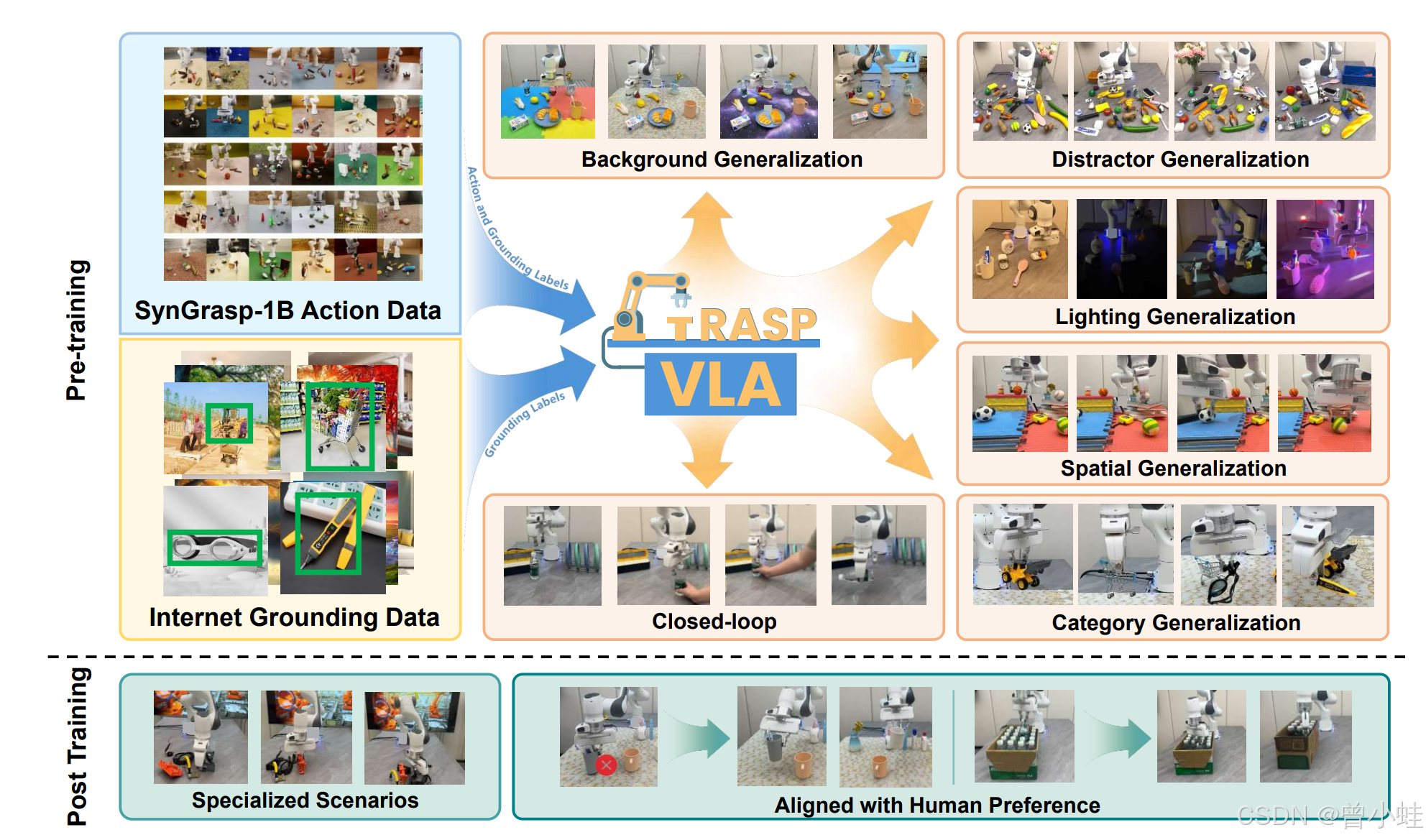
核心问题与动机
现有的具身基础模型(如视觉-语言-动作模型,VLA)依赖真实世界数据收集,成本高且难以扩展。本文探索合成数据在训练VLA模型中的潜力,提出GraspVLA,一个完全基于合成数据预训练的抓取基础模型,旨在通过大规模合成数据解决真实数据不足的问题,并实现开放词汇的抓取泛化。
还有GraspVLA团队总结的具身基础模型七大泛化「金标准」,按照Vision、Language、Action进行不同分层,这些标准包括:光照泛化、干扰物泛化、平面位置泛化、高度泛化、背景泛化、物体类别泛化、闭环能力。
主要贡献
-
SynGrasp-1B数据集
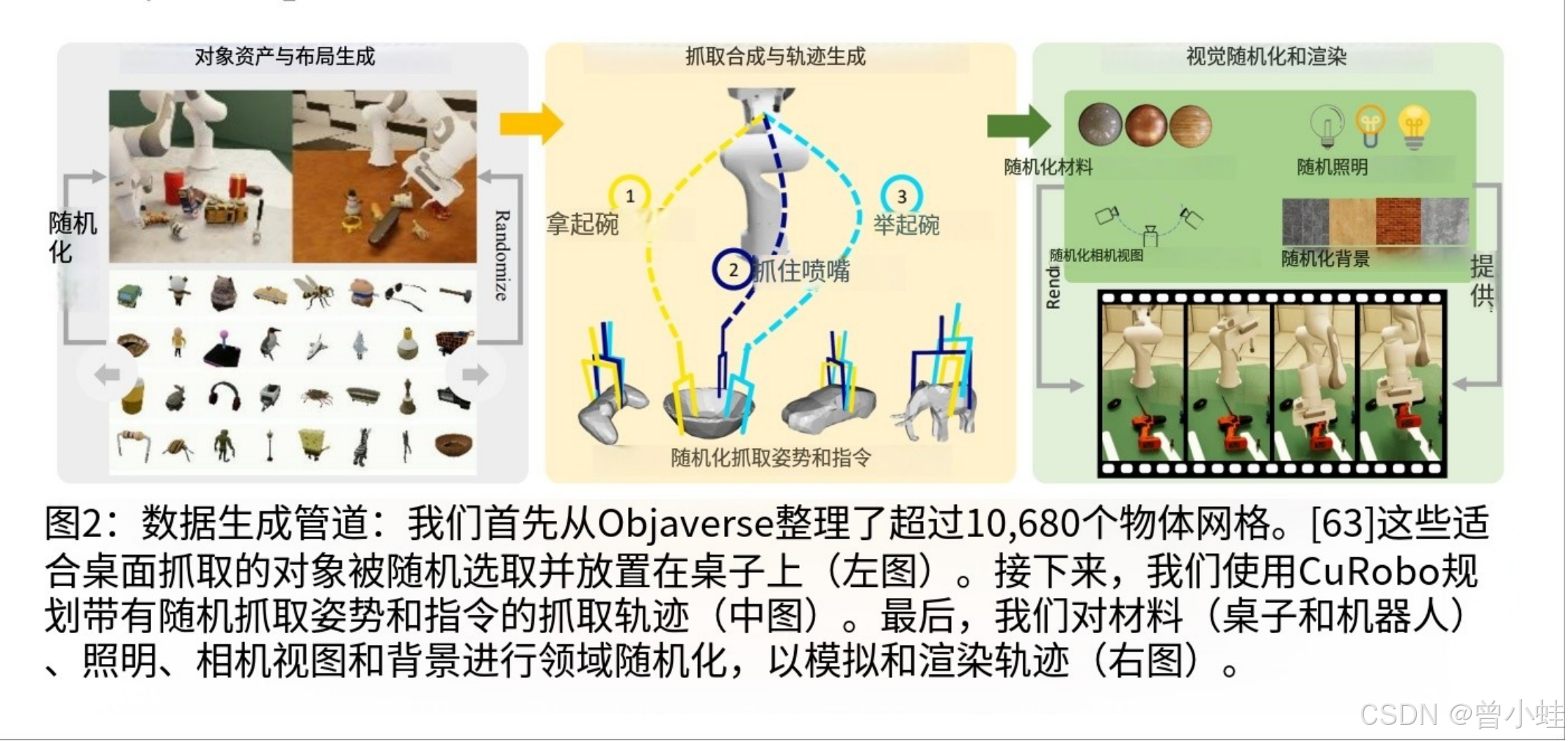
- 规模与内容:包含十亿帧抓取数据,覆盖240个类别、10,000个物体,通过物理仿真(MuJoCo)和光线追踪渲染(Isaac Sim)生成。
- 多样性增强:域随机化(光照、背景、相机参数等)和高效生成策略(异步写入、并行处理),确保数据覆盖广泛几何与视觉变化。跨6个方面的概括性,包括干扰因素,空间姿势,类别,照明,背景和近环动作



- 优化轨迹生成:单步运动规划提升轨迹平滑性,减少模仿学习中的犹豫行为。
-
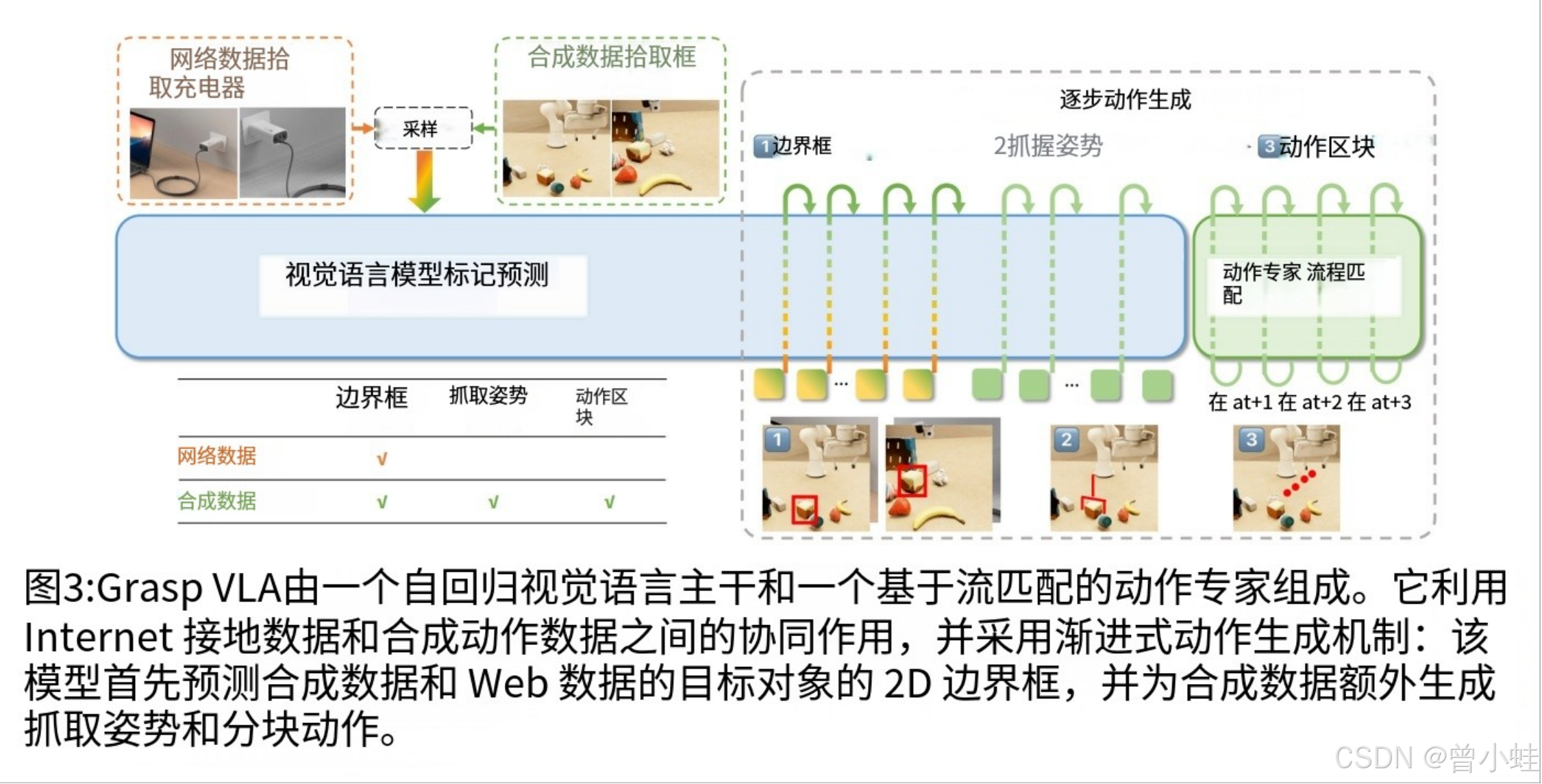
GraspVLA模型架构
- 视觉-语言-动作整合:结合视觉编码器(DINO-v2 + SigLIP)、语言模型(InternLM2 1.8B)和动作生成模块(条件流匹配)。
- 渐进式动作生成(PAG):将感知任务(视觉定位、抓取位姿预测)作为动作生成的中间步骤,形成链式推理(Chain-of-Thought),联合训练合成数据与互联网语义数据(如GRIT),融合几何与语义知识。
- 训练策略:合成数据训练完整链式流程,互联网数据仅训练感知部分,实现跨模态知识迁移。
-
实验验证
- 零样本泛化:在真实和仿真环境中(如LIBERO)显著优于现有模型(如AnyGrasp、π₀、OpenVLA),尤其在透明物体和长尾类别(如充电器、毛巾)上表现优异。
- 少样本适应性:仅需少量标注数据即可适应新任务(如避免触碰杯子内部、密集环境顺序抓取)。
- 效率与鲁棒性:闭环策略减少模块化系统的误差累积,PAG机制提升动作生成的连贯性和成功率。
方法细节
数据集生成流程
- 物体布局生成:从Objaverse筛选物体,随机缩放、姿态放置于桌面,生成多样化场景。
- 抓取轨迹规划:基于抓取合成算法生成稳定抓取位姿,使用CuRobo规划无碰撞轨迹,并通过物理仿真验证成功率。
- 视觉渲染与随机化:Isaac Sim渲染多视角RGB图像,随机化光照、背景、相机参数,提升泛化能力。
模型设计
- PAG机制:
- 步骤1(感知):视觉语言模型生成目标物体的2D边界框。
- 步骤2(几何推理):结合本体感觉(proprioception)预测3D抓取位姿。
- 步骤3(动作生成):基于流匹配(Flow Matching)生成精细的末端执行器动作序列。
- 联合训练:合成数据监督完整流程(边界框→抓取位姿→动作),互联网数据仅监督边界框预测,实现跨模态对齐。
实验结果
-
零样本抓取成功率
- 真实世界:在光照变化、背景干扰、物体高度变化等条件下,GraspVLA平均成功率93.3%,远超基准模型(如π₀的76.6%)。
- 仿真环境(LIBERO):在长序列任务(Long Suite)中零样本成功率82%,优于经过微调的OpenVLA(33.7%)和π₀(62.7%)。
-
透明物体抓取
- AnyGrasp因点云不完整导致成功率仅10%,GraspVLA通过多视角视觉和语义推理达到86.6%。
-
少样本微调
- 仅需100条标注数据,模型可适应新任务(如工业零件抓取),成功率90%,而从头训练模型仅30%。
局限与未来方向
- 当前局限:仅限于Franka机械臂和固定视角配置;对模糊指令(如“抓取左边的物体”)处理不足;未考虑可变形物体的物理特性。
- 未来工作:扩展至更多机器人平台和任务(如非抓取操作);结合强化学习生成复杂轨迹;优化推理速度(当前5Hz vs. AnyGrasp的37Hz)。
总结
GraspVLA通过大规模合成数据预训练和创新的链式推理机制,显著提升了抓取任务的泛化能力和适应性,为机器人基础模型提供了一种高效且可扩展的训练范式。其代码、数据集及预训练权重已开源,推动社区在合成数据驱动的具身智能研究。
