基于GlusterFS的分布式存储集群部署实战指
实验环境说明
本实验采用最小化部署方案,通过2台CentOS 7.9虚拟机验证分布式存储集群搭建流程。硬件配置建议:
- 虚拟机规格:2核4G内存起
- 磁盘配置:系统盘20G + 数据盘10G(实验用,生产环境需扩容)
- 网络要求:确保节点间SSH互通,关闭防火墙(实验环境)
title: 基于GlusterFS的分布式存储集群部署实战指南
date: 2025-05-08
tags: [存储, 分布式系统, GlusterFS]
category: 云计算与存储解决方案
实验环境说明
本实验采用最小化部署方案,通过2台CentOS 7.9虚拟机验证分布式存储集群搭建流程。硬件配置建议:
- 虚拟机规格:2核4G内存起
- 磁盘配置:系统盘20G + 数据盘10G(实验用,生产环境需扩容)
- 网络要求:确保节点间SSH互通,关闭防火墙(实验环境)
部署流程详解
一、基础环境准备
1.1 添加存储磁盘
# 在VMware/VirtualBox中为两节点各添加10G虚拟磁盘 | |
# 开机后执行磁盘识别 | |
fdisk -l | grep sdb # 确认新磁盘设备名为/dev/sdb |
1.2 安装GlusterFS服务端
添加yum
echo "[gluster7]
name=CentOS-7 - Gluster 7
baseurl=Index of /7.9.2009/storage/x86_64/gluster-7
gpgcheck=0
enabled=1" > /etc/yum.repos.d/gluster7.repo
yum clean all && yum makecache
yum install -y glusterfs-server
# 启动服务并设置开机自启
systemctl enable --now glusterd
gluster --version # 验证版本≥7.0
1.3 主机名解析
echo "10.1.1.7 node1 | |
10.1.1.22 node2" >> /etc/hosts |
二、存储池配置
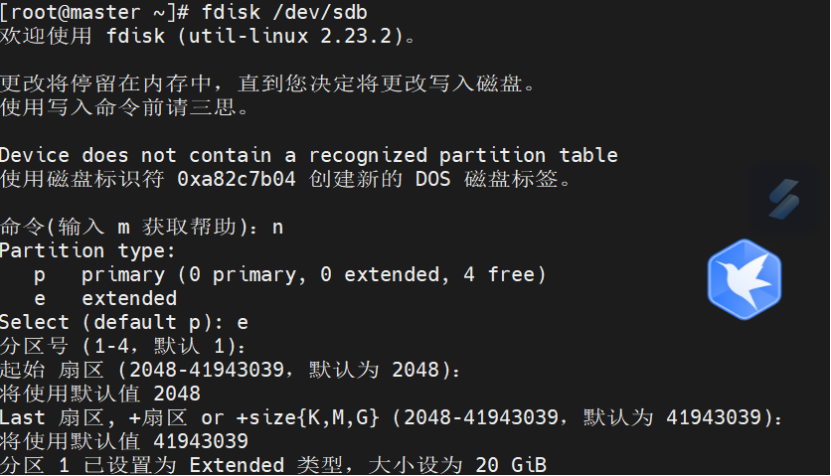
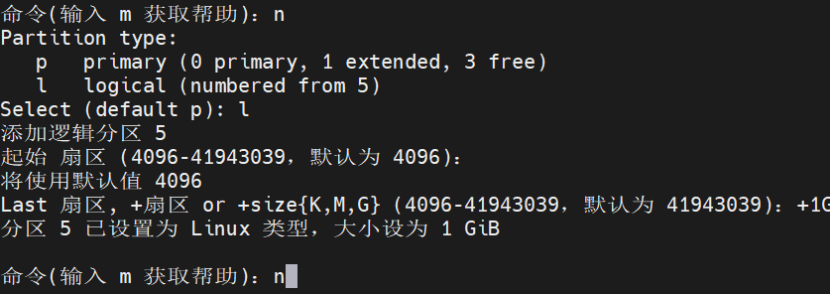
2.1 磁盘分区方案
# 推荐分区策略(实验环境) | |
fdisk /dev/sdb <<EOF | |
n # 新建分区 | |
p # 主分区 | |
1 # 分区号 | |
# 默认起始扇区 | |
+1G # 1GB容量 | |
w # 写入分区表 | |
EOF | |
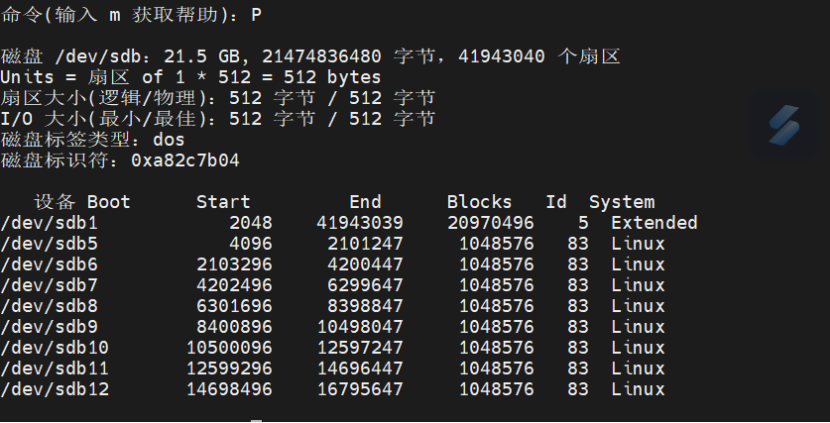
# 创建9个分区(生产环境建议6个) | |
for i in {1..9}; do | |
fdisk /dev/sdb <<EOF | |
n | |
p | |
$i | |
+1G | |
w | |
EOF | |
done | |
partprobe /dev/sdb # 刷新分区表 |
2.2 文件系统格式化
# 创建XFS文件系统(适合大文件存储) | |
mkfs.xfs /dev/sdb1 -f | |
# 创建挂载点并配置自动挂载 | |
mkdir -p /data/{brick1..brick9} | |
echo "/dev/sdb1 /data/brick1 xfs defaults 0 0" >> /etc/fstab | |
mount -a # 立即生效 |
三、集群搭建
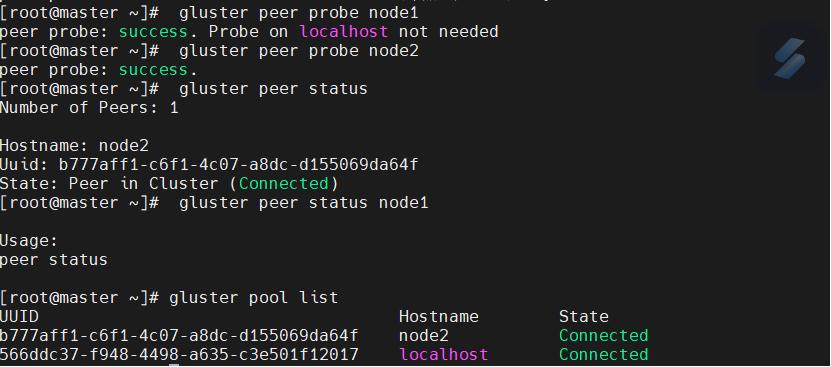
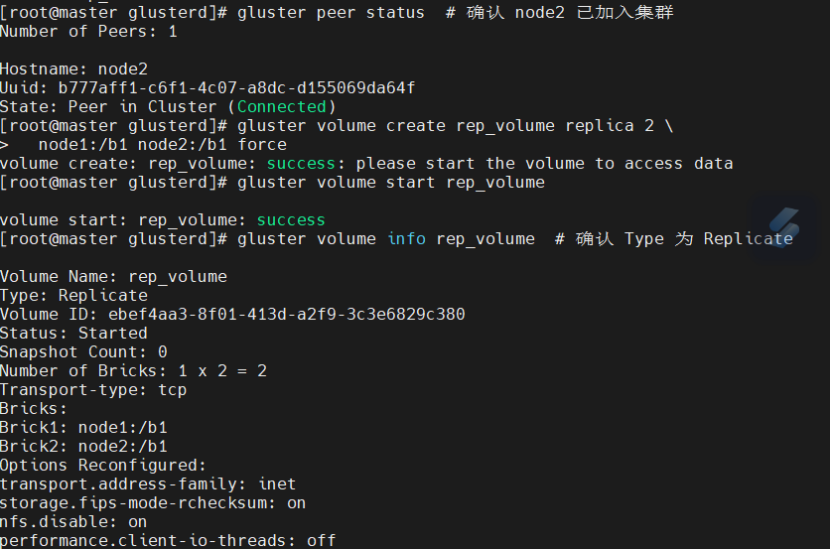
3.1 节点探测
# 在任意节点执行(假设当前节点为node1) | |
gluster peer probe node2 | |
gluster peer status # 验证节点状态 |
3.2 卷类型对比表
| 卷类型 | 特性 | 适用场景 |
|---|---|---|
| 分布卷(Distribute) | 数据分散存储,无冗余 | 临时存储,追求最大容量 |
| 复制卷(Replicate) | 实时镜像,高可用 | 关键业务数据保护 |
| 分散卷(Disperse) | 纠删码技术,空间效率高 | 冷数据归档,成本敏感场景 |
| 分布复制卷 | 分布式+副本组合 | 平衡容量与可靠性的通用场景 |
3.3 卷创建示例
# 分布卷(容量叠加) | |
gluster volume create dist-vol \ | |
node1:/data/brick1 \ | |
node2:/data/brick2 force | |
# 复制卷(双节点镜像) | |
gluster volume create rep-vol \ | |
replica 2 \ | |
node1:/data/brick3 \ | |
node2:/data/brick4 force | |
# 分布复制卷(2×2架构) | |
gluster volume create dis-rep-vol \ | |
dis-rep 2 \ | |
node1:/data/brick5 \ | |
node2:/data/brick6 \ | |
node1:/data/brick7 \ | |
node2:/data/brick8 force |
四、客户端使用
4.1 挂载卷
# 安装客户端 | |
yum install -y glusterfs-fuse | |
# 创建挂载点 | |
mkdir -p /mnt/{dist,rep,disrep} | |
# 手动挂载(生产环境建议配置/etc/fstab) | |
mount -t glusterfs node1:/dist-vol /mnt/dist |
4.2 数据验证
# 写入测试文件 | |
dd if=/dev/urandom of=/mnt/dist/testfile bs=1G count=1 oflag=direct | |
# 验证数据分布 | |
ls -l /data/brick* # 检查各节点实际存储情况 |
常见问题处理
- 卷创建失败:
- 检查节点状态:
gluster peer status - 确认brick目录权限:
chmod 755 /data/brick* - 查看日志:
journalctl -u glusterd
- 检查节点状态:
- 数据不一致:
- 执行自愈:
gluster volume heal <VOLNAME> info - 强制修复:
gluster volume heal <VOLNAME> full
- 执行自愈:
- 性能优化建议:
- 调整TCP缓冲区:
gluster volume set <VOLNAME> performance.cache-size 256MB - 启用读写缓存:
gluster volume set <VOLNAME> performance.io-cache on
- 调整TCP缓冲区:
扩展场景
- 横向扩展:
gluster peer probe node3gluster volume add-brick <VOLNAME> node3:/data/brick9 - 配额管理:
gluster volume quota <VOLNAME> limit-usage / 100GB - 快照备份:
gluster snapshot create <SNAPNAME> <VOLNAME>
总结
本指南完整演示了从单机部署到集群验证的全流程,通过4种卷类型展示了GlusterFS的灵活架构。实际生产部署时需注意:
- 至少3个存储节点保证数据安全
- 配置专有存储网络(建议万兆网卡)
- 实施定期健康检查和备份策略
- 结合Prometheus+Grafana构建监控体系
通过合理规划卷类型和副本策略,GlusterFS可满足从PB级对象存储到高并发文件服务的多样化需求。