文章目录
- matcha 实现
- cosyvoice 实现
- chunk_fm
-
- stream token2wav
- 关于flow-matching 很好的原理性解释文章, 值得仔细读,多读几遍,关于文章Flow Straight and Fast:
Learning to Generate and Transfer Data with Rectified Flow 的讲解梳理。
matcha 实现
def fm_comput_loss()t = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype)z = torch.randn_like(x1)y = (1 - (1 - self.sigma_min) * t) * z + t * x1u = x1 - (1 - self.sigma_min) * zpred_y = self.estimator(y, mask, mu, t.squeeze(), spks)loss = F.mse_loss(pred_y, u, reduction="sum") / (torch.sum(mask) * u.shape[1])return loss, y
def estimator_forward():x = pack(y, mu)x = pack(x, spks)q,k,v = x, x, xx = slf_attn(q,k,v)outputs = linear(x)return outputs
cosyvoice 实现
def fm_forward():conds = torch.zeros(feat.shape, device=token.device)for i, j in enumerate(feat_len):if random.random() < 0.5:continueindex = random.randint(0, int(0.3 * j))conds[i, :index] = feat[i, :index]conds = conds.transpose(1, 2)b, _, t = mu.shapet = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype)if self.t_scheduler == 'cosine':t = 1 - torch.cos(t * 0.5 * torch.pi)z = torch.randn_like(x1)y = (1 - (1 - self.sigma_min) * t) * z + t * x1u = x1 - (1 - self.sigma_min) * zif self.training_cfg_rate > 0:cfg_mask = torch.rand(b, device=x1.device) > self.training_cfg_ratemu = mu * cfg_mask.view(-1, 1, 1)spks = spks * cfg_mask.view(-1, 1)cond = cond * cfg_mask.view(-1, 1, 1)pred = self.estimator(y, mask, mu, t.squeeze(), spks, cond, streaming=streaming)loss = F.mse_loss(pred * mask, u * mask, reduction="sum") / (torch.sum(mask) * u.shape[1])return loss, ydef estimator(x, mu, spks, cond):x = pack(x, mu, spks, cond)x = slf_attn(x)outputs = linear(x)return outputs
chunk_fm
- 训练的时候将特征进行chunk_mask,推理的时候只准备chunk的部分,pre_chunk 存为kv_cache,
- cache 初始seq_len为0;每次得到的cache,只留下[-chunk_len:] 的长度,作为下一次的输入;特征x 的pos 按照真的来算;
chunk_mask
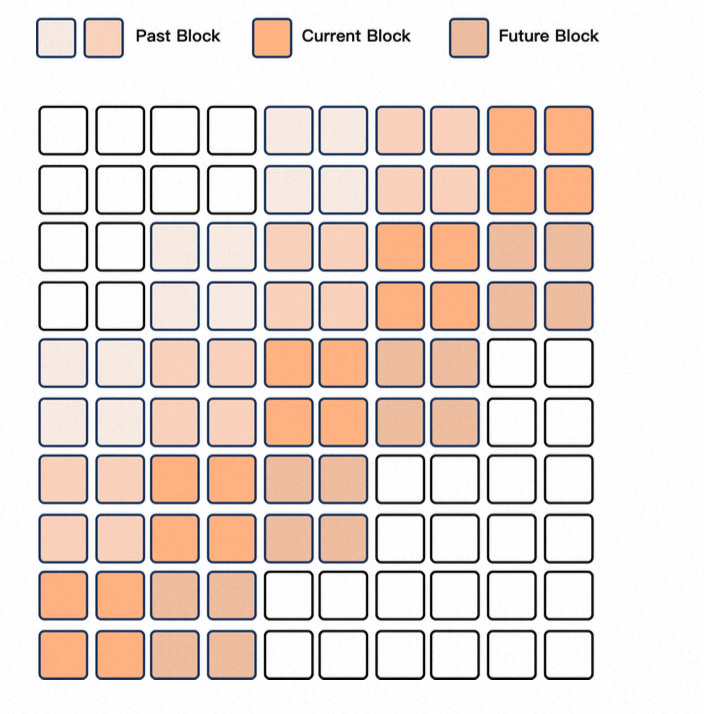
- 训练阶段样本按照seq_len 维度被mask 成不同的可见部分;chunk_mask 和长度mask 都会出现,为了加速收敛;
cache_attn
def slf_attn_cache(x, cache):k_in, v_in, q_in = x, x, xkey_cache = linear1(k_in)value_cache = linear2(v_in)if cache.size(0) != 0:key = torch.concat([cache[:, :, :, 0], key_cache], dim=1)value = torch.concat([cache[:, :, :, 1], value_cache], dim=1)else:key, value = key_cache, value_cachecache = torch.stack([key_cache, value_cache], dim=3)outputs = scale_dot_production(key, value)return outputs, cache
stream token2wav
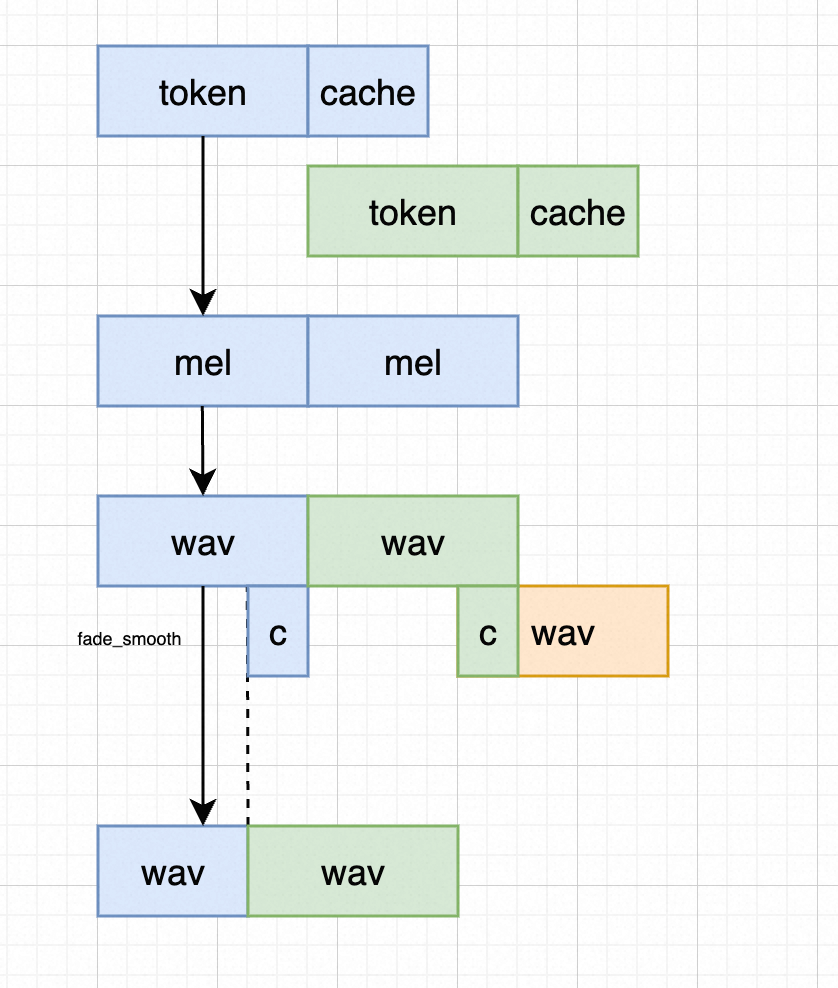
- 第一个包没有kv_cache, 卷积cache 有,但是值为0;first chunk 推理完就可以存下kv_cache & cnn_cache;
- 输入token+cache_token,得到token 对应的mel;
- mel2wav 阶段也是,第一次没有hift cache,直接退出mel 对应的wav,最后8帧存下来作为hift_cache,用于hift_wav 预测以及输出的音频片段间平滑;前n-8 帧的音频输出;
def inference(self, speech_feat: torch.Tensor, cache_source: torch.Tensor = torch.zeros(1, 1, 0)):f0 = self.f0_predictor(speech_feat)s = self.f0_upsamp(f0[:, None]).transpose(1, 2) s, _, _ = self.m_source(s)s = s.transpose(1, 2) if cache_source.shape[2] != 0:s[:, :, :cache_source.shape[2]] = cache_sourceprint('cache_source s', s.size())else:print('cache_source shape2 is 0')generated_speech = self.decode(x=speech_feat, s=s)return generated_speech, s