WiseAD:基于视觉-语言模型的知识增强型端到端自动驾驶——论文阅读
《WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model》2024年12月发表,来自新加坡国立和浙大的论文。

在快速发展的视觉语言模型(VLM)中,一般人类知识和令人印象深刻的逻辑推理能力的出现,促使人们越来越有兴趣将VLM应用于高级自动驾驶任务,如场景理解和决策。然而,对知识水平(尤其是基本驾驶专业知识)与闭环自动驾驶性能之间关系的深入研究需要进一步探索。在这篇论文中,我们研究了基础驾驶知识的深度和广度对闭环轨迹规划的影响,并介绍了WiseAD,这是一种专为端到端自动驾驶量身定制的专用VLM,能够进行驾驶推理、动作论证、对象识别、风险分析、驾驶建议和跨不同场景的轨迹规划。我们对驾驶知识和规划数据集进行联合训练,使模型能够相应地执行知识对齐的轨迹规划。大量实验表明,随着驾驶知识多样性的扩大,严重事故显著减少,在卡拉闭环评估中,驾驶分数和路线完成率分别提高了11.9%和12.4%,达到了最先进的性能。此外,WiseAD在域内和域外数据集的知识评估方面也表现出了显著的性能。
研究背景与动机
自动驾驶技术近年来从传统规则系统转向端到端解决方案,但仍面临场景理解不足和驾驶知识利用不充分的问题。视觉语言模型(VLM)在通用知识和逻辑推理方面表现出色,但直接应用于自动驾驶时存在两大挑战:
-
驾驶导向知识不足:通用VLM缺乏对驾驶场景、经验和因果推理的深度理解。
-
知识与轨迹规划未对齐:现有方法多模仿预定义驾驶行为,缺乏对知识(如“减速以规避行人突然出现”)的显式嵌入,导致决策透明度低。
核心贡献
提出 WiseAD,一种专为自动驾驶设计的知识增强VLM,具备以下能力:
-
多任务支持:场景描述、物体识别、风险分析、驾驶建议、轨迹规划等。
-
联合训练策略:结合驾驶知识(LingoQA、DRAMA等)与轨迹规划(Carla数据集)进行联合学习,避免知识遗忘。
-
性能提升:在Carla闭环评估中,驾驶分数(DS)提升11.9%,路线完成率(RC)提升12.4%,关键事故(碰撞、闯红灯)显著减少。
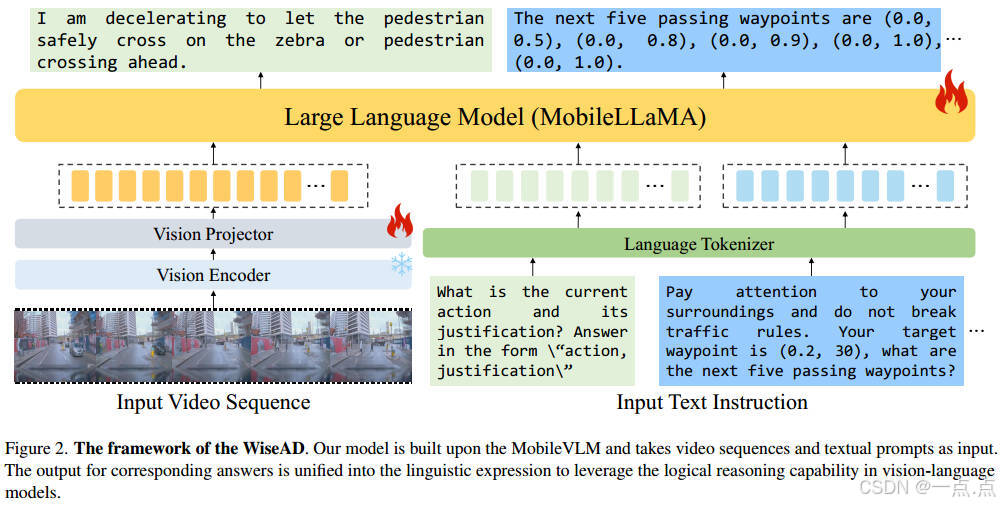
方法细节
-
模型架构:
-
视觉编码:基于CLIP ViT-L/14提取视频帧特征,投影为与文本对齐的视觉标记。
-
语言模型:采用轻量级MobileLLaMA(1.7B参数),支持多模态输入(视频+文本)。
-
输出对齐:轨迹规划结果以文本形式表达(如“下一个五个路径点为(x1, y1), (x2, y2)…”),便于利用VLM的逻辑推理能力。
-
-
数据构建:
-
驾驶知识:整合LingoQA(驾驶推理、物体识别)、DRAMA(风险分析、驾驶建议)、BDDX(动作解释)等数据集,覆盖多样化场景与任务。
-
轨迹规划:使用Carla模拟器采集轨迹数据,目标点以文本形式输入(如“目标点为(x, y),生成后续五个路径点”)。
-
-
训练策略:
-
联合学习:混合知识问答与轨迹规划数据,避免分阶段训练导致的知识遗忘。
-
注意力前缀提示:在推理阶段加入提示(如“注意周围环境,遵守交规”),显式引导模型调用驾驶知识。
-
实验结果
-
闭环驾驶性能(Carla评估):
-
SOTA对比:WiseAD在驾驶分数(69.88 vs 65.26)和路线完成率(93.79% vs 88.24%)上超越Roach、VAD等模型。
-
关键事故减少:碰撞次数从2.35降至1.43,闯红灯次数从2.60降至2.14。
-
-
知识评估(零样本测试):
-
LingoQA:L-Judge评分60.4(对比LLaVA-7B的38.0),显示对驾驶知识的深度掌握。
-
跨数据集泛化:在BDDX(动作识别)、DriveLM(物体识别)、HAD(驾驶注意力)任务中均表现优异。
-
-
消融实验:
-
注意力前缀提示:移除后路线完成率下降8.4%(93.79→85.35),验证其关键作用。
-
知识广度影响:引入DRAMA风险分析数据后,驾驶分数提升3.08(66.02→69.88)。
-
创新点与意义
-
知识驱动的端到端框架:首次将VLM与驾驶知识深度融合,提升决策可解释性与安全性。
-
轻量化与高效性:基于MobileVLM(1.7B参数),适合实时自动驾驶场景。
-
数据与训练范式创新:通过混合训练与注意力提示,实现知识与规划的高效对齐。
未来方向
-
扩展知识边界:引入更多长尾场景(如极端天气、复杂路口)的知识标注。
-
多模态融合:结合激光雷达等多传感器数据,增强环境感知鲁棒性。
-
实际部署验证:在真实道路测试中验证模型泛化能力与实时性。
WiseAD为自动驾驶领域提供了一种知识增强的新范式,通过显式嵌入驾驶逻辑与经验,推动端到端系统向“类人类驾驶”迈进。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!