qwen2.5vl
多模态大模型通用架构:
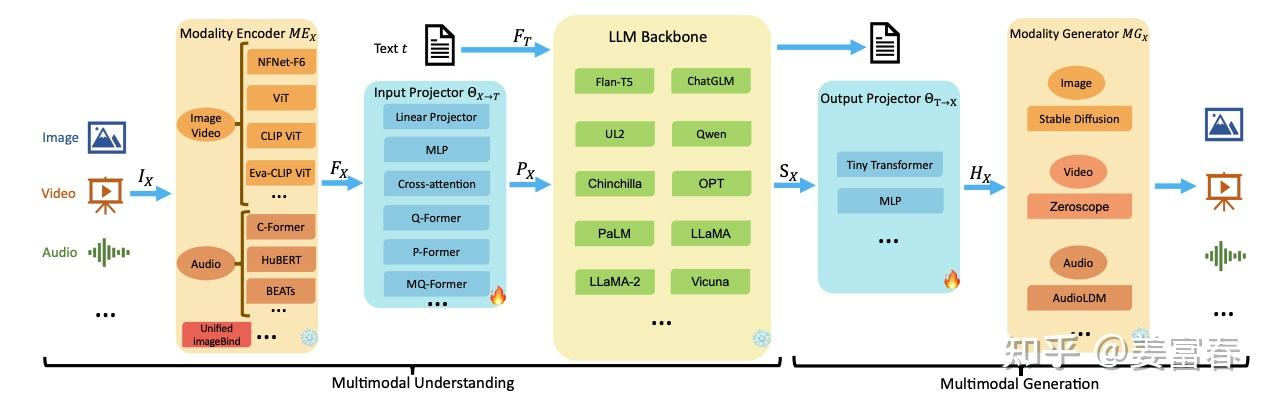
在通用的MM-LLM(Multi-Modality LLM)框架里,共有五个模块,整体以LLM为核心主干,分别在前后有一个输入、输出的投影模块(Projector),投影模块主要是用于桥接不同模态输入和输出。输入投影模块(Input Projector)用于将模态编码器处理的不同模态特征映射到文本特征空间,以便输入给LLM;输出投影模块(Output Projector)用于将文本特征空间结果映射到模态生成器的输入空间,以引导模态生成器生成多模态结果。
(https://zhuanlan.zhihu.com/p/25267823390)
一、23.08 qwenvl发版
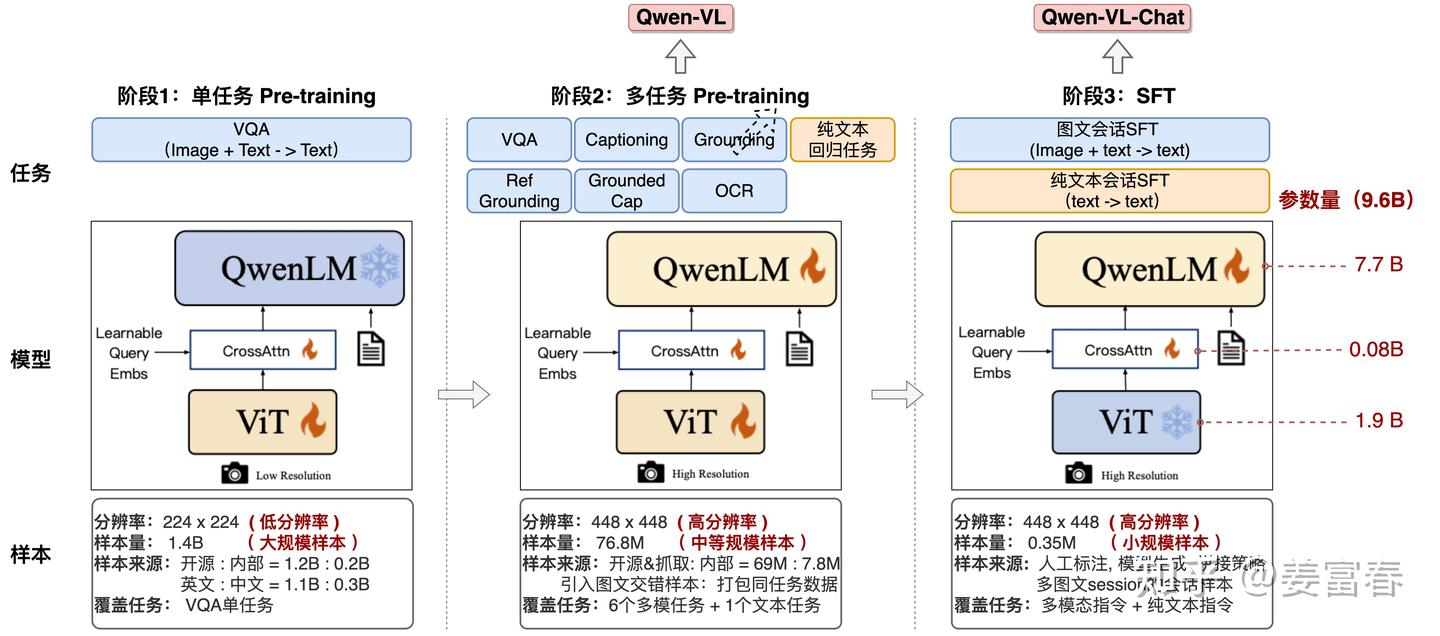
qwenvl 第一代分三个阶段训练,
①clip在图像语义级理解较强,但在ocr和图像细节理解弱。qwenvl准备1T图像-文本对,得到ocr/语义都很强的vit;
②在clip的基础上做多任务预训练;
③instruct监督微调。冻结vit。
(24.08 qwen2vl)
二、25.01 qwen2.5vl
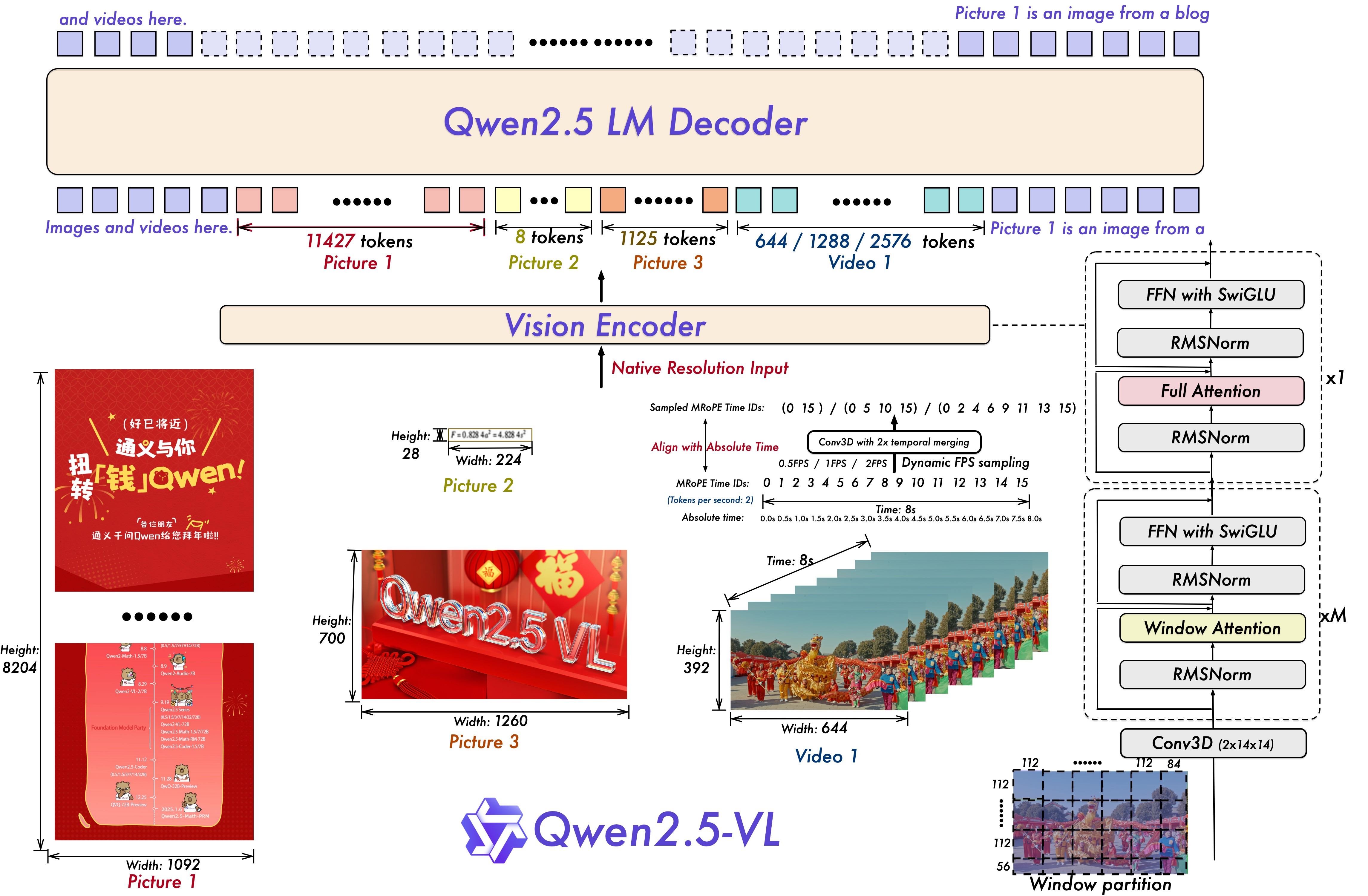
1)原生图像分辨率:尽量保持(需要resize至被28整除)原有图像分辨率和长宽比。在112*112窗口内做14*14的window attention,最后2*2merge成原图视野域为28*28的token。
2)视频动态FPS采样:在视频数据中,用2*14*14的三维卷积将连续两帧图像合并为一张特征图。在采样时按照绝对时间(如0.5秒一帧)顺序排列,并按照绝对帧序进行三维空间的位置编码。所谓动态FPS采样,即将不同采样间隔的图像序列merge到一起,兼容长短期动作的多样性。
图像处理:对图像做复制操作,使得单一图片,变成一个时序为2的帧序列。
3)M-ROPE(Multi-Modal Rotational Positional Embedding):文本text位置编码是一维,图像是二维,视频是三维。ROPE通过旋转矩阵相乘的形式编码(可参考https://zhuanlan.zhihu.com/p/719388479)。对于文本模态,只需要三个维度位置编码相同即可与视频对齐。
4)更高效的视觉编码器vit:大部分是window attention,112*112窗口内做14*14的window attention,window size实际上只有8*8;仅在[7,15,23,31]的4层做了full attention;ViT 架构与采用了 RMSNorm 和 SwiGLU 结构。
5)视觉定位能力:在做一些grounding任务时,qwen2vl会将box的坐标点做 (0,1000) 的规范化处理,在qwen2.5vl版本中,不进行坐标归一化,而是使用实际的像素点来表示坐标,这样能是模型学习到图像的真实尺寸信息。
6)参数分布:在3/7/72B版本的qwen中,vit结构和参数是一模一样的(600+M),只是在2*2merge时,为了match LM中的维度做了不同的升维。
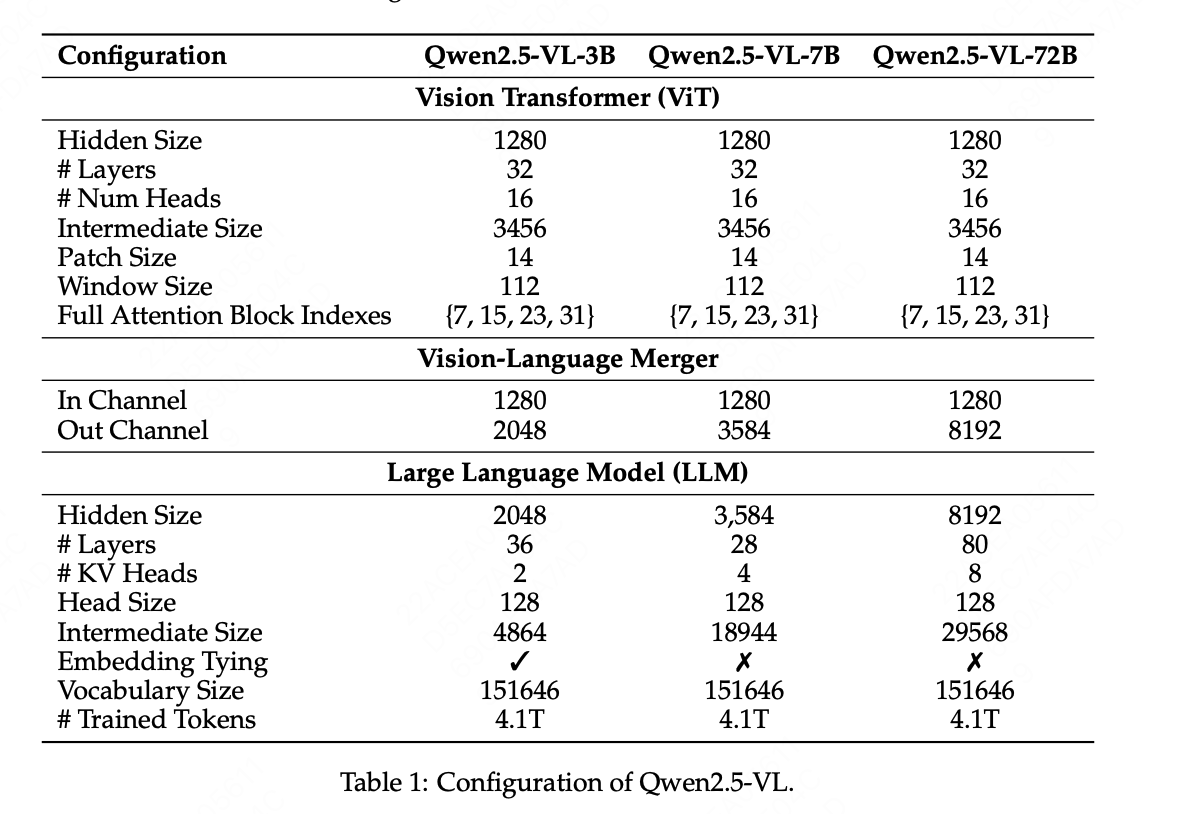
7)训练方式:
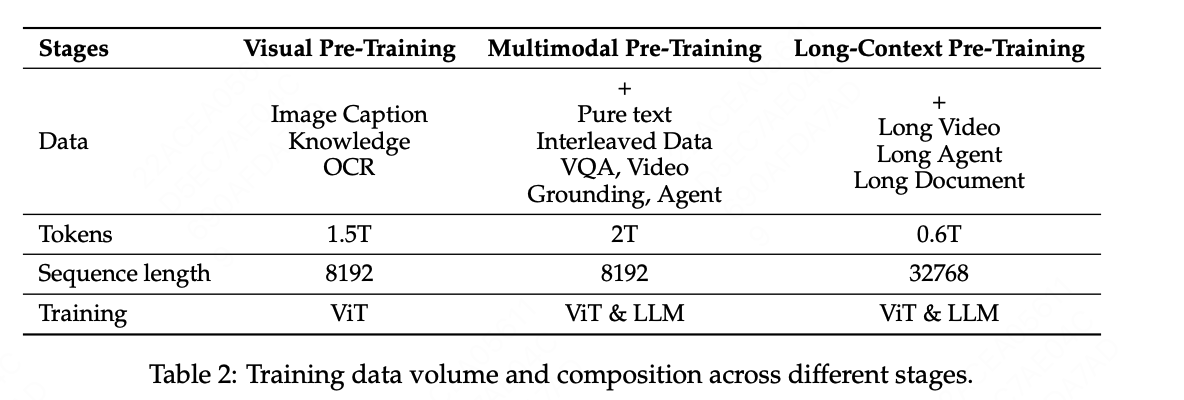
8)最高图像/视频尺度,最多支持32k长度的token,即32k*28*28区域的图像。
9)qwen2.5vl-3/7/32/72B不同规模对应着llm的尺度,即qwen2.5vl-3B用的LLM模型时qwen2.5-3B。