综述:语言模型的发展及大模型推理优化
一 背景
在人工智能的快速发展浪潮中,语言模型作为自然语言处理(NLP)领域的核心技术,近年来取得了突破性进展。从早期的统计语言模型到基于深度学习的Transformer架构,再到如今参数量高达千亿甚至万亿级别的大模型(如GPT-4、DeepSeek等),语言模型的文本生成、理解与推理能力不断提升,展现出广阔的应用前景。
然而,随着模型规模的急剧扩大,如何在有限的硬件资源下实现高效推理成为亟待解决的关键问题。大模型的部署与优化面临着计算开销大、内存占用高等挑战,这也催生了诸如量化、蒸馏以及高效注意力机制等一系列创新方法。这些技术不仅推动了AI应用的落地,也为未来语言模型的进一步发展提供了重要方向。
本文将系统梳理语言模型的技术演进历程,并探讨大模型推理优化的前沿方法,希望能为读者提供对这一领域的参考。
二 语言模型的发展
首先,什么是语言模型呢?
「语言模型」是一种「人工智能系统」,旨在处理、理解和生成类似人类的语言。它们从大型数据集中学习模式和结构,使得能够产生连贯且上下文相关的文本,可以应用于翻译、摘要、聊天机器人和内容生成等领域。

目前,一般将语言模型的研究分为四个发展阶段,分别是统计语言模型、神经语言模型、预训练语言模型以及大语言模型。每个阶段语言模型的任务求解能力都比上一个阶段更强。下面我们从最初的统计语言模型开始看起。
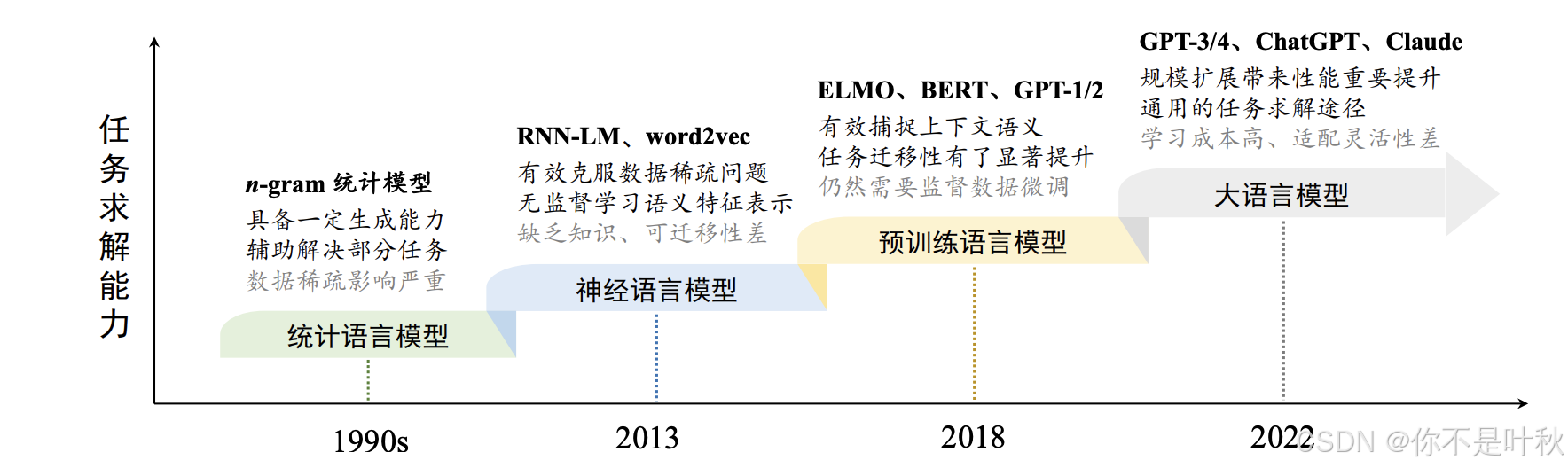
1、统计语言模型
统计语言模型主要通过分析词序列的出现频率来预测下一个词。这种方法基于统计学的原理,利用大规模语料库中的词频信息来建模语言的概率分布。这个阶段最常见的统计语言模型是n-grams语言模型,n-grams是文本中连续出现的n个单词的序列,比如Uni-gram就是一个单词作为一个单独的序列,Bi-grams是两个单词作为一个序列,Tri-grams依此类推。n-grams统计语言模型在训练阶段统计语料库中所有n-grams出现的频率,然后计算在前n-1个词出现的情况下,第n个词出现的条件概率,在推理阶段使用这些条件概率来预测序列中下一个最可能出现的字。
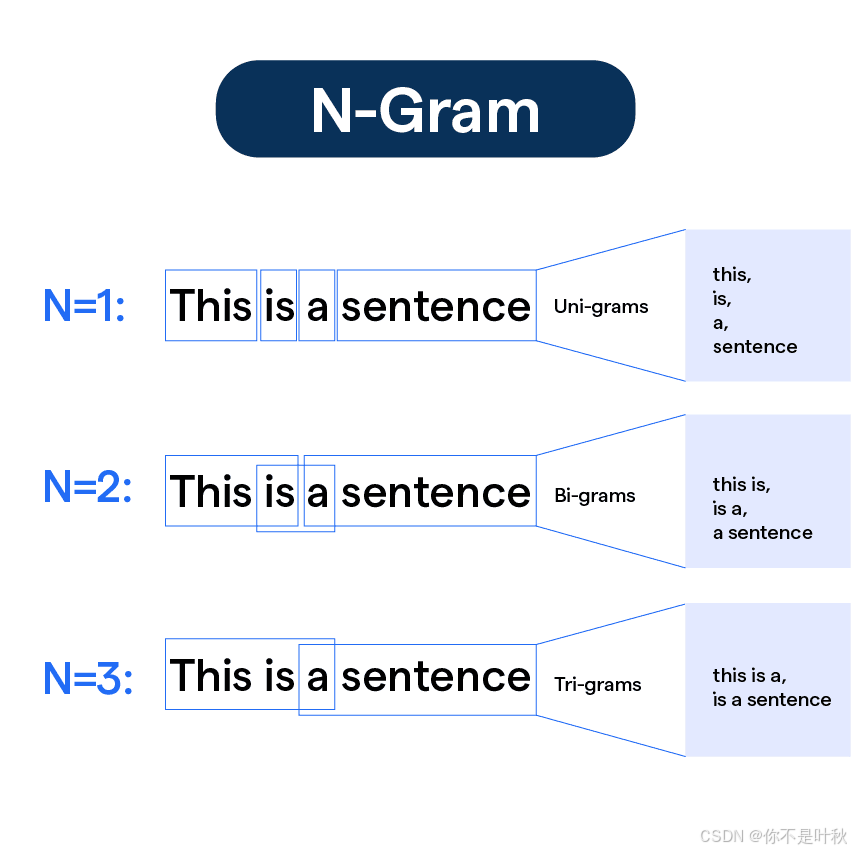
比如下面是从一个餐厅语料库中统计到的部分bi-grams的条件概率。
现在有一个序列
I want to eat _
这个文本序列的下一个词是什么呢?n-grams统计语言模型根据之前统计到的bi-grams条件概率发现eat后面可以是to/chinese/food/lunch, 其中lunch的条件概率最高,那么统计语言模型就会预测上述序列的下一个词是lunch
I want to eat lunch
统计语言模型虽然简单高效,但在实际应用中存在明显局限性。由于训练语料的有限性,许多可能的语言序列在训练数据中从未出现,导致基于最大似然估计的统计语言模型会将这些序列的概率赋值为零。然而在实际语言使用中,这些序列确实可能存在,这种现象被称为数据稀疏问题(data sparsity problem)。此外,传统统计语言模型无法捕捉词语之间的语义关联,难以处理语义相近词的替换情况,这大大限制了其应用范围。
随着深度学习技术的发展,神经语言模型(Neural Language Model)应运而生。这类模型通过分布式表示和神经网络结构,不仅能有效缓解数据稀疏问题,还能自动学习词语之间的语义关系,显著提升了语言建模的性能。
2、神经语言模型
神经语言模型使用人工神经网络来建模文本序列的生成。人工神经网络的基本组成单元是人工神经元,其模仿了生物神经元的结构和功能。一个生物神经元具有多个树突,用来接受传入信息,信息传递进来后经过细胞核一系列的计算,最终产生一个信号传递到轴突,轴突只有一条,轴突尾端有许多轴突末梢,跟其他神经元的树突产生连接,从而传递信号。也就是说一个神经元接入了多个输入,最终只变成一个输出,给到了后面的神经元,那么基于此,我们可以尝试去构造一个类似的结构,即人工神经元。
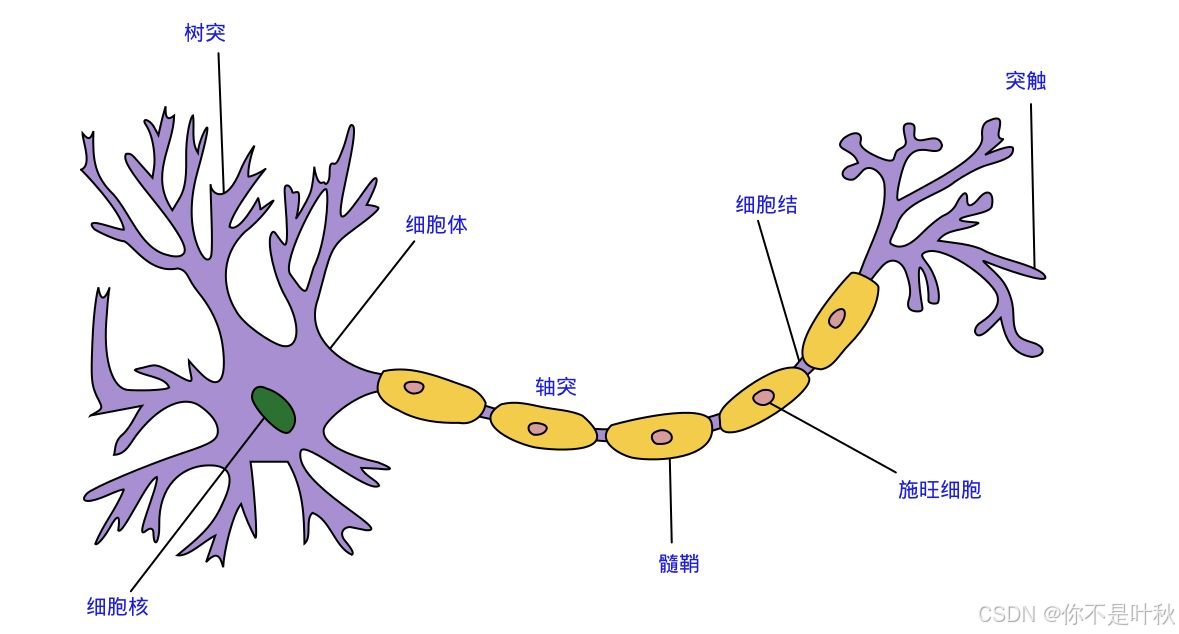
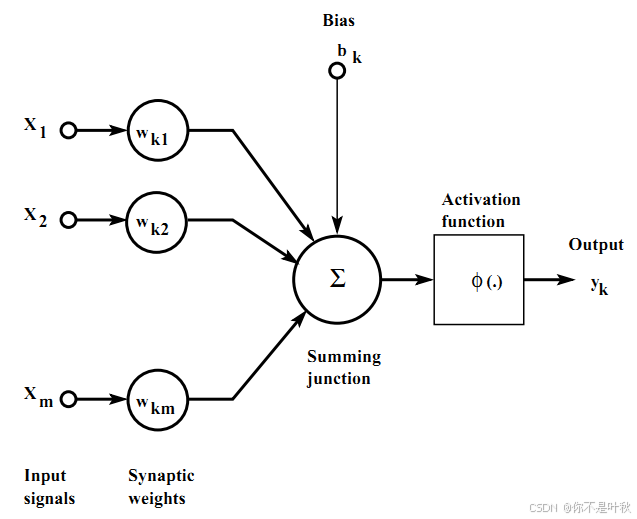
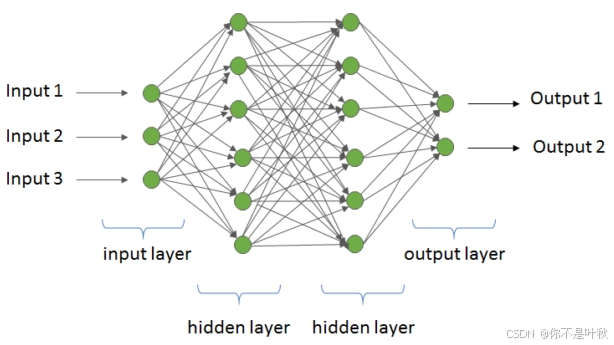
人工神经元中也有一个类似细胞核的结构,称为感知器,它接受多个输入(x1,x2,x3…),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。每个输入的重要程度不同,因此每个输入xᵢ都被赋予一个可学习的权重wᵢ,感知器首先对输入进行线性变换: z = w k 1 x 1 + w k 2 x 2 + . . . + w