通道注意力-senet
5月7日复盘
一、卷积注意力机制
通过引入卷积注意力机制,神经网络能够在同样的计算资源下获得更强的表征能力和更优的性能表现。
1. 注意力认知
AM: Attention Mechanism,注意力机制。

注意力机制 是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。
通过注意力机制,模型可以做到对图像中不同区域、句子中的不同部分给予不同的权重,从而增强感兴趣特征,并抑制不感兴趣区域。
2. 注意力应用
注意力机制最初应用于机器翻译(如Transformer),后逐渐被广泛应用于各类任务,包括:
- NLP:如机器翻译、文本生成、摘要、问答系统等。

-
计算机视觉:如图像分类(细粒度识别)、目标检测(显著目标检测)、图像分割(图像修复)等。

-
跨模态任务:如图文生成、视频描述等。
这里我们学习下视觉处理中常见的典型注意力机制,如特征注意力、空间注意力以及混合注意力。
二、通道注意力
对不同的特征通道进行增强或抑制,也就是赋予不同的权重参数。
1. SENet
Squeeze-and-Excitation Networks
挤压 - 和 - 激活、激发
大胆猜测,小心求证
SENet模型论文: https://arxiv.org/pdf/1709.01507
1.0 基本认知
Filter
SENet采用具有全局感受野的池化操作进行特征压缩,并使用全连接层学习不同特征图的权重,模型流程图如下:
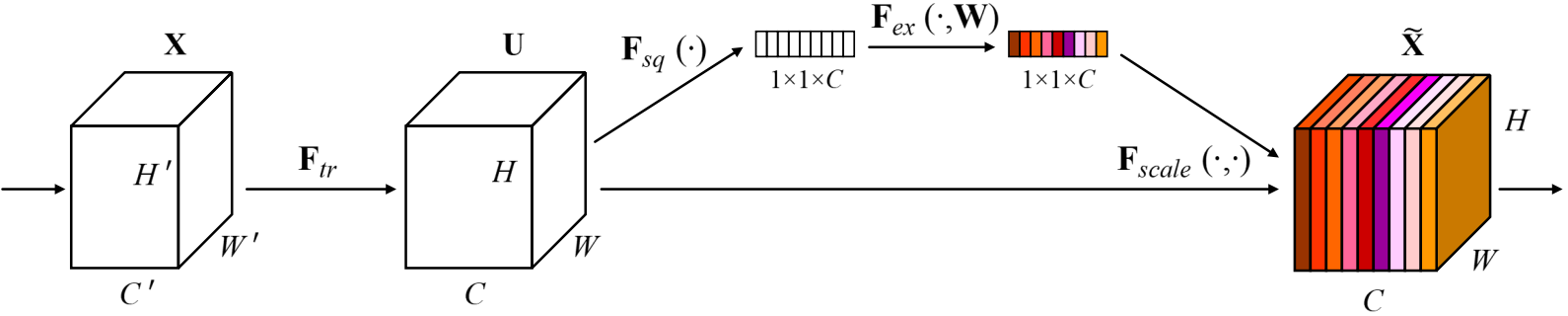
1.1 流程详解
-
Squeeze阶段:
该阶段通过全局平均池化完成全局信息提取,公式如下:
z c = F s q ( u c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_c=\mathbf{F}_{sq}(\mathbf{u}_c)=\frac1{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j) zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
示意图如下:
# Squeeze:压缩、降维、挤压 self.sq = nn.AdaptiveAvgPool2d(1) -
Excitation阶段:
Squeeze的输出作为Excitation阶段的输入,经过两个全连接层,动态地为每个通道生成权重,公式如下:
s = F e x ( z , W ) = σ ( g ( z , W ) ) = σ ( W 2 δ ( W 1 z ) ) \mathbf{s}=\mathbf{F}_{ex}(\mathbf{z},\mathbf{W})=\sigma(g(\mathbf{z},\mathbf{W}))=\sigma(\mathbf{W}_2\delta(\mathbf{W}_1\mathbf{z})) s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
示意图如下: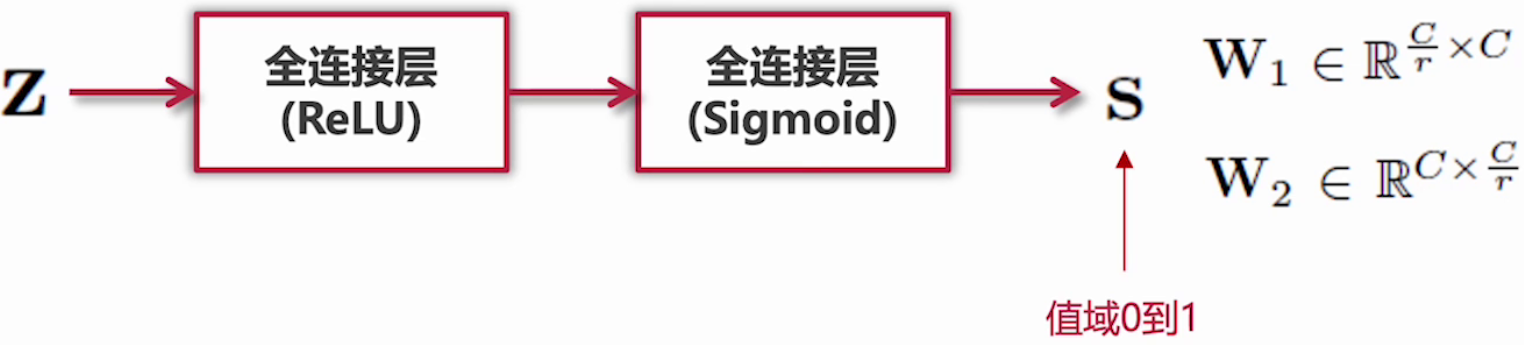
全连接层加入激活函数,用于引入非线性变化:
- 第一个全连接层(ReLU),将通道数从 C C C降维为 C / r C/r C/r。
- r r r 是缩放因子,Ratio,比例的意思,用以减少运算量和防止过拟合。
- 通过第二个全连接层(si4)将维度恢复为 C C C,输出一个 1 × 1 × C 1 \times 1 \times C 1×1×C的权重向量。
- 权重归一化:使用sigmoid确保权重在 0 0 0~$$$之间。
- 该向量代表每个通道的重要性,也就是注意力的权重。
# Excitation:激活 self.ex = nn.Sequential(nn.Linear(inplanes, inplanes // r),nn.ReLU(),nn.Linear(inplanes // r, inplanes),nn.Sigmoid(), ) -
输出阶段:
特征 u c \mathbf{u}_c uc 和 Excitation阶段产出的 s c \mathbf{s}_c sc 进行相乘操作,用于对不同的通道添加权重:
x ~ c = F s c a l e ( u c , s c ) = s c u c \widetilde {x}_{c} = F_{scale}(u_{c},s_{c}) =s_{c}u_{c} x c=Fscale(uc,sc)=scuc

def forward(self, x):# 缓存xintifi = xx = self.sq(x)x = x.view(x.size(0), -1)x = self.ex(x).unsqueeze(2).unsqueeze(3)return intifi * x
1.2 融入模型
作为一种即插即用模块,可以添加到任意的层后,只要保证输出通道不变即可,如把SE融入到ResNet模型,如下:
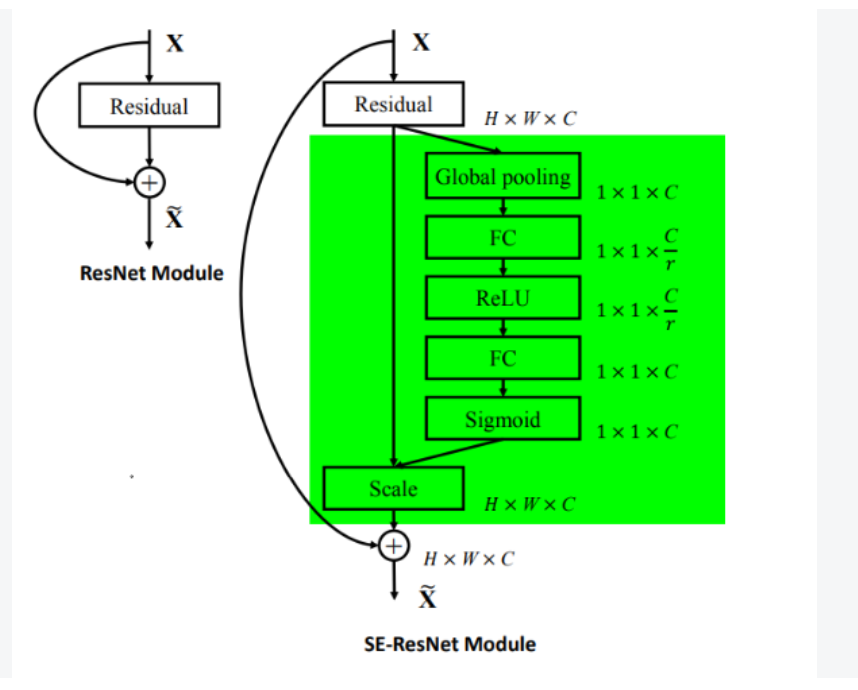
给ResNet-50加入SE注意力:
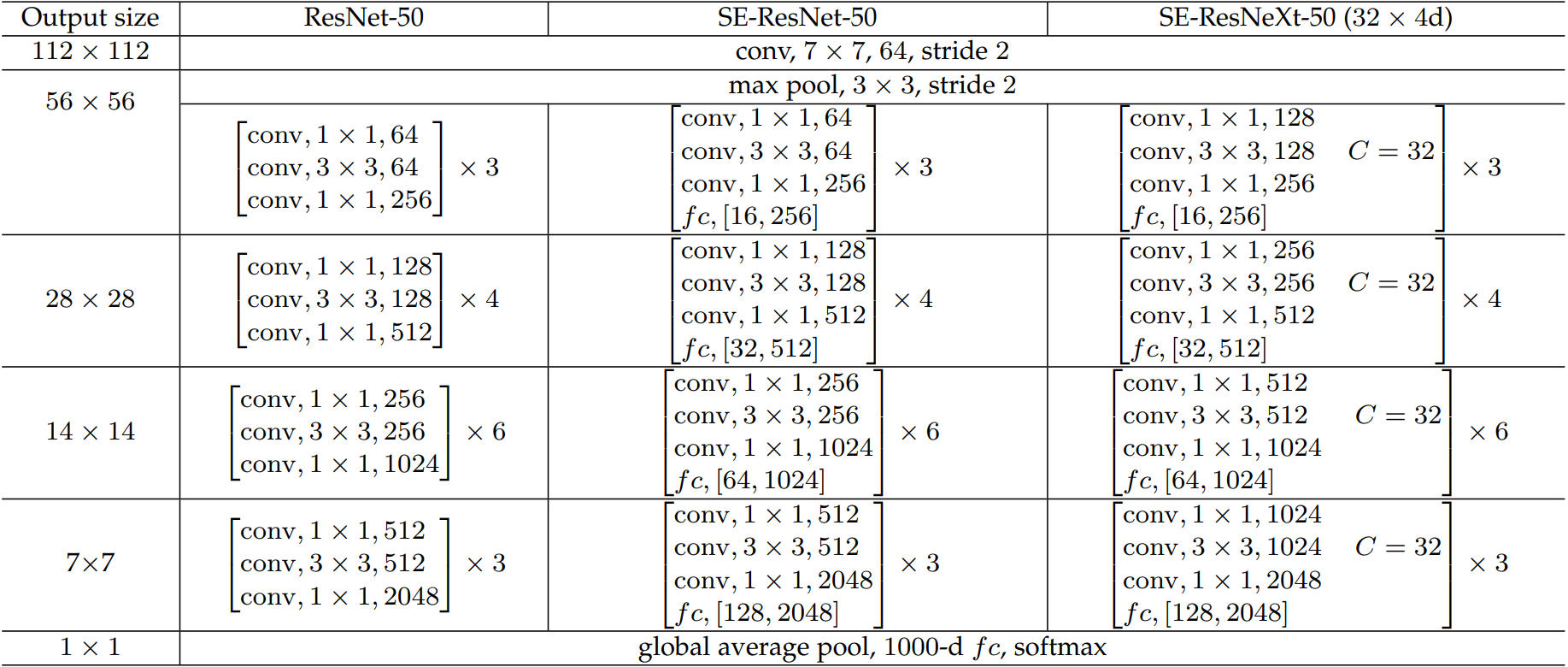
注解:表格中的 f c fc fc 后面的值,如 ( 16 , 256 ) (16, 256) (16,256) 或 ( 32 , 512 ) (32, 512) (32,512),表示在SE模块中的两个全连接层的维度变化。
1.3 性能对比
加入SE后的性能对比表:re-implementation是SE作者复现效果
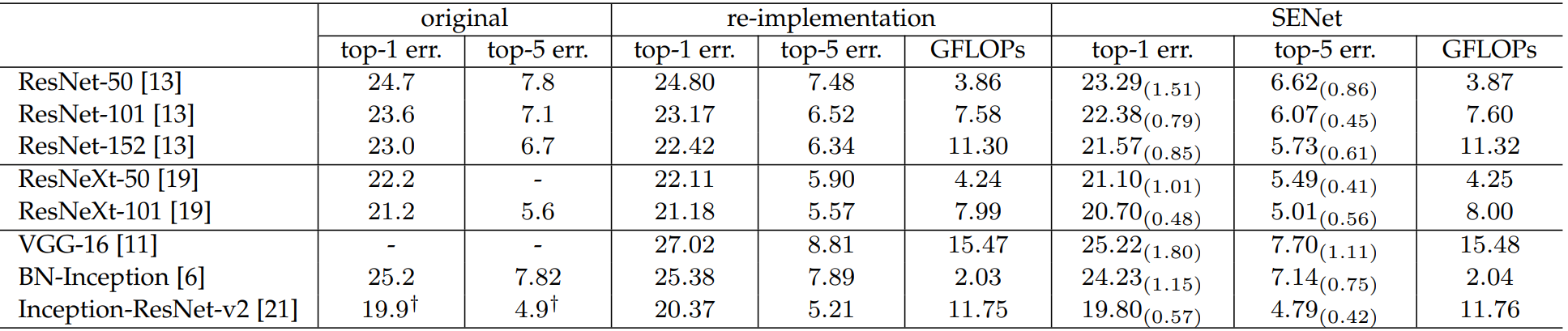
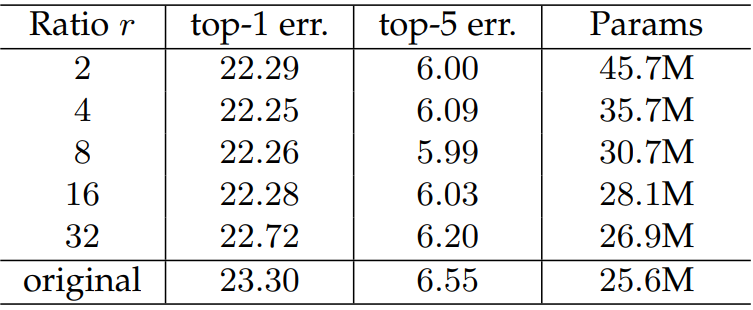
1.4 缩放因子
太小参数量大,容易过拟合。太大的话特征丢失严重,整体看8或16是比较不错的选择,具体的还是根据业务来定。
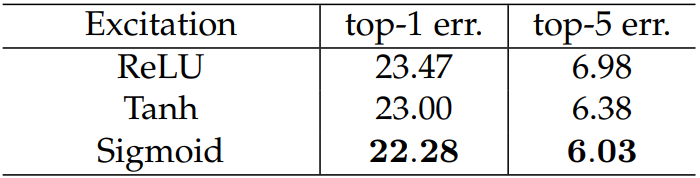
1.5 有无Squeeze
我们可以考虑不要Squeeze做平均池化,直接在Excitation阶段进行卷积操作。从下标看的出来,这个Squeeze阶段还是很有必要的。

1.6 池化方式
我们也可以考虑采用最大池化,不过效果不如平均池化。因为对注意力来讲更多的是维持原始信息,而不是强化特征。

1.7 激活函数
这里是针对第二个全连接层,我们想要的是一个概率向量,无疑返回值在( 0 0 0 ~ 1 1 1)之间的Sigmoid是最好的选择。
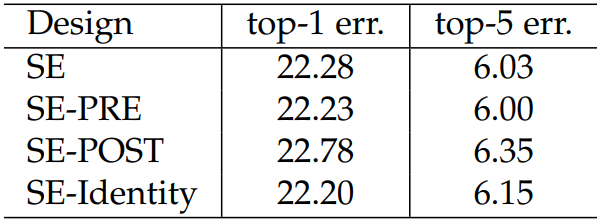
1.8 网络位置
SE模块灵活度较高,如下:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
性能对比如下:POST模式最差
1.9 不同阶段添加
比如ResNet是分很多个阶段的,不同的阶段添加SE模块效果是不一样的。
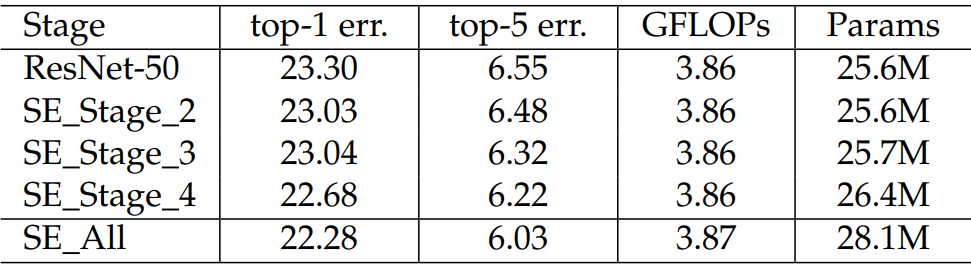
看的出来,越靠后的位置效果越好,因为越靠后特征学习的越好,此时加入效果就越好。当然全加SE的效果最好,不过参数量也不小。
1.10总结
背景与动机
在传统的卷积神经网络中,卷积操作通常是均匀地应用于各个输入通道,无法根据通道的重要性进行动态调整。而 SENet 的提出正是为了解决这一问题,它认为不同通道的特征对于最终的分类或检测任务具有不同的重要性,通过学习通道之间的相互依赖关系,可以对特征通道进行自适应的重新校准,从而提升网络的表达能力和性能。
网络结构
- 挤压(Squeeze)操作 :这是对输入特征图进行全局信息整合的过程。具体来说,对于每个特征通道,采用全局平均池化操作,将该通道的空间维度压缩为 1×1,得到一个描述该通道全局信息的特征向量。例如,假设输入特征图大小为 H×W×C(H 为高度,W 为宽度,C 为通道数),经过挤压操作后,得到一个大小为 1×1×C 的特征向量,这个向量包含了每个通道的全局信息。
- 激励(Excitation)操作 :该操作旨在学习通道之间的依赖关系,并生成每个通道的权重系数。首先,将挤压得到的特征向量通过两个全连接层,第一个全连接层将通道数减少到原来的 1/r(r 为一个可调节的约减比),引入非线性激活函数(如 ReLU)进行特征提取。然后,第二个全连接层将通道数恢复到原来的 C,并使用 sigmoid 激活函数将输出值限制在 [,01] 区间内,得到每个通道的权重系数。这些权重系数反映了每个通道的重要性,权重大的通道表示其特征对当前任务更有价值。
工作流程
输入特征图首先经过挤压操作得到全局特征向量,然后通过激励操作为每个通道生成权重系数。接着,将这些权重系数与原始输入特征图进行逐通道的加权,使得重要的通道特征被增强,不重要的通道特征被抑制,从而得到重新校准后的特征图。最后,将重新校准后的特征图作为后续网络层的输入,进行进一步的特征提取和分析。
优点
- 提升模型性能 :SENet 通过引入通道注意力机制,能够有效地捕捉通道之间的相关性,使网络更加关注对任务有重要作用的特征通道,从而在图像分类、目标检测、语义分割等多种视觉任务中取得了显著的性能提升。
- 良好的兼容性 :它不是一种独立的网络结构,而是一种可以嵌入到其他 CNN 架构中的模块。例如,可以将其添加到 ResNet、Inception 等流行的网络结构中,以增强这些网络的性能,且不会对原网络结构造成大的改动。
- 参数量和计算量增加较少 :与一些复杂的网络结构改进方法相比,SENet 所增加的参数量和计算量相对较少。挤压和激励操作主要涉及全局平均池化和两个小型的全连接层,因此不会给网络带来过多的负担,具有较高的性价比。
应用场景
广泛应用于图像分类、目标检测、语义分割、人脸识别等众多计算机视觉领域,尤其在精细需要特征分析和处理的任务中表现出色。例如在医学图像分析中,通过对不同通道特征的关注和调整,可以更准确地识别和定位病变区域。