神经网络语言模型(NNLM)的原理与实现
在NLP中,语言模型用来判断一句话是否符合正确的语法,广泛应用于信息检索、机器翻译、语音识别等重要任务中。传统的语言模型主要基于统计方法(如:N-Gram模型),虽然可解释性强、易于理解,但存在泛化能力差等问题。随着深度学习技术的发展,相关技术也应用到语言模型中,如神经网络语言模型(Neural Network Language Model模型)。
一、 NNLM模型结构
NNLM是通过第t个词前的n-1个词,预测每个词在第t个位置出现的概率,即:
![]()
其中f>0,即预测出的结果都是大于0的,且预测结果的和为1。根据论文《A Neural Probabilistic Language Model》所述,NNLM包含一个三层的神经网络,具体模型结构如下:
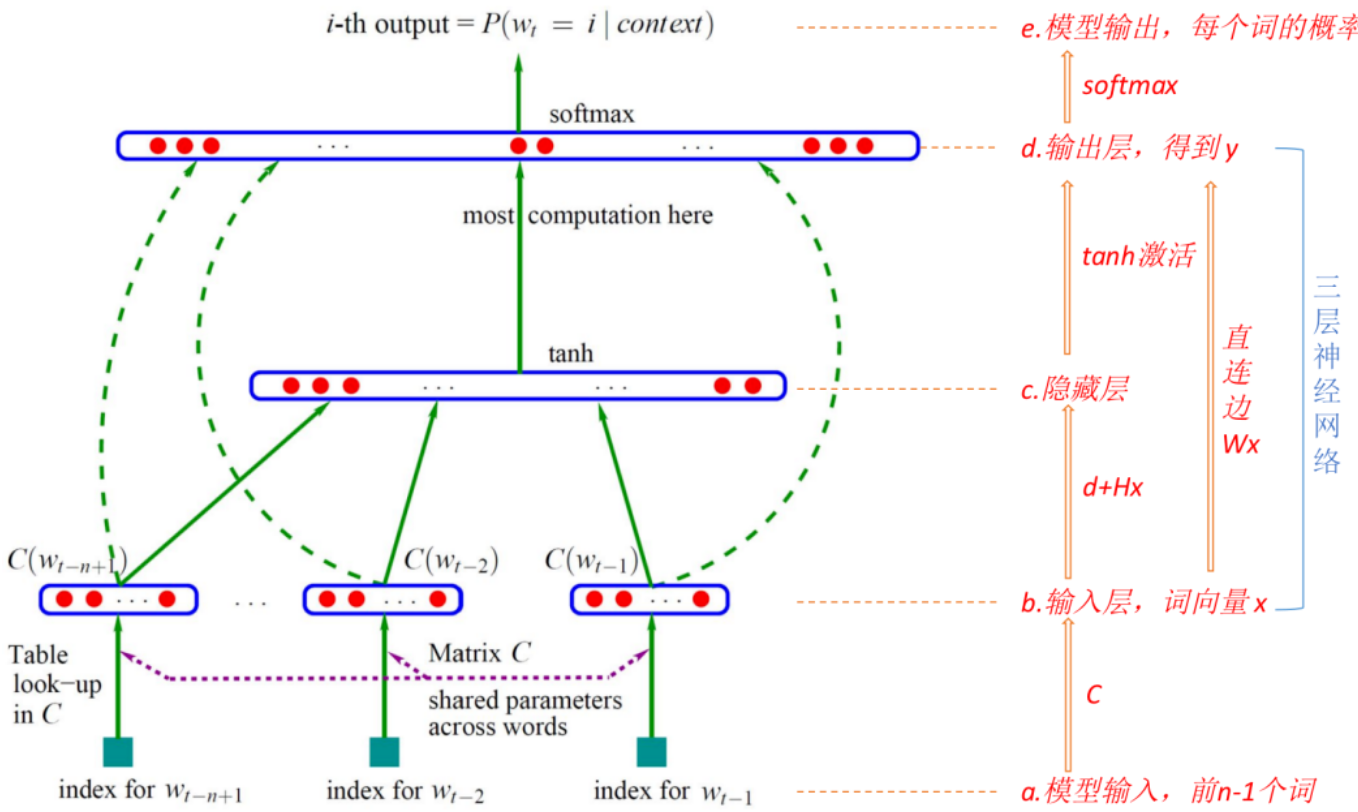
- 模型输入:输入为t位置前的n-1个词,并根据C得到每个输入词的词向量。C为V*m的矩阵,V为语料库包含的总词数,m为词向量维数。
- 神经网络-输入层:模型输入后得到的n-1个词向量,首尾拼接后得到一个整合后的向量 x。
- 神经网络-隐藏层:此处为全连接网络,tanh(d+Hx),其中d表示偏置,H是对应向量的权重,并通过tanh激活。
- 神经网络-输出层:隐藏层到输出层也是一个全连接,另外输入层到输出层有个线性变换,叫做直连边,在实验中发现加入直连接可减少迭代次数。最终得到t位置为不同词语(V个)的未归一化概率y
![]()
其中U为V*h的矩阵,h为隐藏层单元数,不需要直连边时W为0。
5. 模型输出:输出层结果经过softmax,得到归一化后的概率结果。
二、模型训练目标及参数
1. 模型参数: 一般来讲,神经网络的输入不需要训练,但是在NNLM模型中,神经网络的输入是词向量x,也是需要训练的参数。因此NNLM的权重参数和词向量是同时训练的,参数包括:
![]()
2. 训练目标: NNLM训练目标是希望找到合适的参数并使得如下似然函数最大:
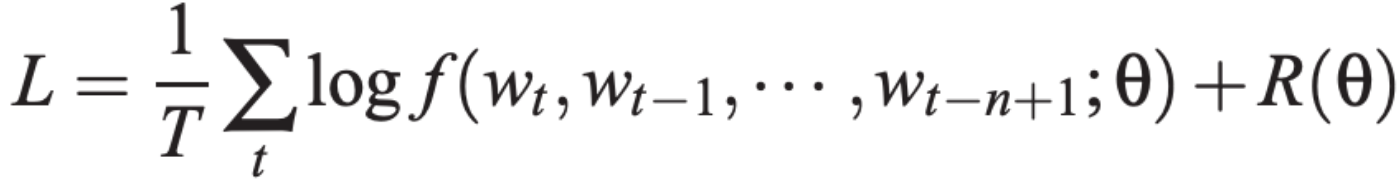
通过随机梯度下降的方式更新参数:
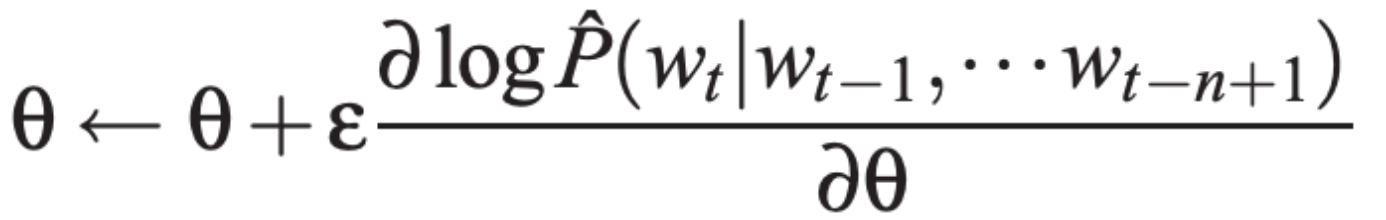
3. 与N-gram模型相比的优点
使用基于统计的N-gram时会遇到一个问题,即很多词的组合是语料库中未能出现的,因此这个词的出现概率为0,从而导致整个句子的出现概率为0。在实际应用中这样是不够合理的,因此要引入平滑算法解决这个问题。而NNLM自带平滑,不需要额外进行复杂的平滑操作。
4. 补充概念-词向量
文本数据无法直接进行计算,如果想将自然语言问题转化为模型问题,需要将文本进行数字化。最普遍使用的方法就是one-hot,但是one-hot会带来两个主要问题:一是把每个词都转化为很长的向量,带来维度灾难,且这些向量中大部分都是0;二是one-hot无法表现出两个词的相似性。
词向量又叫做词嵌入,通过低维向量将词转化为空间中的一个点。一般是50-100维,大大降低了数据维度,且越相近的词距离越近,这也使得使用词嵌入的模型自带平滑功能。在训练语言模型的同时可以训练得到词向量。
三、模型实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
import numpy as np
import resentences = ["我爱猫", "猫吃鱼", "鱼吐泡"] # sentences = ['我爱猫', '猫吃鱼', '鱼吐泡']# 将输入的句子进行中文分字处理。它首先使用正则表达式找到句子中的中文字符,并将句子按照中文字符进行分割。然后,去除分割后的结果中的空白字符,最后返回分割后的中文字符列表。
def seg_char(sent):pattern = re.compile(r'([\u4e00-\u9fa5])')chars = pattern.split(sent)chars = [w for w in chars if len(w.strip()) > 0]return chars# 对给定的句子列表进行中文分字处理,得到一个包含所有句子中汉字的二维数组。
chars = np.array([seg_char(i) for i in sentences]) # chars = [['我' '爱' '猫'], ['猫' '吃' '鱼'], ['鱼' '吐' '泡']]# 将二维数组展平为一个一维数组。
chars = chars.reshape(1, -1) # chars = [['我' '爱' '猫' '猫' '吃' '鱼' '鱼' '吐' '泡']]# 通过去除数组中的空白字符和重复项,得到汉字的列表。
word_list = np.squeeze(chars) # word_list = ['我' '爱' '猫' '猫' '吃' '鱼' '鱼' '吐' '泡']
word_list = list(set(word_list)) # word_list = ['泡', '吐', '鱼', '吃', '猫', '爱','我']# 建立汉字与索引的映射关系,生成词典。 i=0—>鱼;i=1—>吐;i=2—>泡...i=7—>我
word_dict = {w: i for i, w in enumerate(word_list)} # word_dict = {'鱼': 0, '吐': 1, '泡': 2, '吃': 3, '猫': 4, '爱': 5, '我': 6}# 创建索引与汉字的反向映射关系,生成反向词典。
number_dict = {i: w for i, w in enumerate(word_list)} # number_dict = {0: '鱼', 1: '吐', 2: '泡', 3: '吃', 4: '猫', 5: '爱', 6: '我'}# 确定词汇表的大小。
n_class = len(word_dict) # 词汇表的大小 n_class = 7# NNLM 参数
n_step = 2 # 步数# 将句子列表转换为神经网络模型训练所需的输入批次和目标批次。输入输出 one-hot 编码
def make_batch(sentences): input_batch = []target_batch = []# 遍历句子列表,对每个句子进行中文分字处理,得到汉字列表。for sen in sentences: # sen = '我爱猫'# 对于每个句子,将汉字列表中的前n-1个字符作为输入,最后一个字符作为目标。word = seg_char(sen) # word = ['我', '爱', '猫']input = [word_dict[n] for n in word[:-1]] # 使用词典将汉字转换为对应的索引。input = [0, 1]target = word_dict[word[-1]] # target = 2# 对输入和目标进行 one-hot 编码,生成输入批次和目标批次。# [tensor([[0., 0., 0., 0., 0., 0., 0., 1.], [0., 0., 0., 0., 0., 1., 0., 0.]]),# tensor([[0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0.]]),# tensor([[1., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0.]])]input_batch.append(torch.eye(n_class)[input])# [tensor([0., 0., 0., 0., 0., 0., 1., 0.]), tensor([0., 0., 0., 0., 1., 0., 0., 0.]), tensor([0., 0., 1., 0., 0., 0., 0., 0.])]target_batch.append(torch.eye(n_class)[target])return input_batch, target_batch# 将所有输入批次和目标批次合并为一个张量,并整理成模型需要的形状。
input_batch, target_batch = make_batch(sentences)# tensor:(3, 16)
# tensor([[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.],
# [0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
# [1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
input_batch = torch.cat(input_batch).view(-1, n_step * n_class)# tensor:(3, 8)
# tensor([[0., 0., 0., 0., 0., 0., 1., 0.],
# [0., 0., 0., 0., 1., 0., 0., 0.],
# [0., 0., 1., 0., 0., 0., 0., 0.]])
target_batch = torch.cat(target_batch).view(-1, n_class)# 定义模型
class NNLM(nn.Module):# 初始化函数: 定义了模型的各个层和激活函数def __init__(self):super(NNLM, self).__init__()self.linear1 = nn.Linear(n_step * n_class, 2) # 全连接层, 输入大小为 n_step * n_class,输出大小为 2self.tanh = nn.Tanh() # tanh 激活函数self.linear2 = nn.Linear(2, n_class) # 另一个全连接层,输入大小为 2,输出大小为 n_classself.softmax = nn.Softmax(dim=1) # softmax 激活函数,用于输出层# 前向传播函数: 定义了数据流的传递方式def forward(self, x):x = self.linear1(x) # 输入 x 经过第一个全连接层 self.linear1 得到中间表示x = self.tanh(x) # 中间表示经过 tanh 激活函数x = self.linear2(x) # 经过第二个全连接层 self.linear2 得到输出x = self.softmax(x) # 输出经过 softmax 激活函数,得到最终的预测结果return x# 准备训练数据
train_dataset = TensorDataset(input_batch, target_batch)
train_loader = DataLoader(train_dataset, batch_size=1)# NNLM(
# (linear1): Linear(in_features=16, out_features=2, bias=True)
# (tanh): Tanh()
# (linear2): Linear(in_features=2, out_features=8, bias=True)
# (softmax): Softmax(dim=1)
# )
model = NNLM()# 定义损失函数和优化器
# 损失函数使用交叉熵损失函数 nn.CrossEntropyLoss(),用于计算模型预测结果与真实标签之间的差异
criterion = nn.CrossEntropyLoss() # criterion = CrossEntropyLoss()# 优化器使用 Adam 优化器 optim.Adam,用于更新模型的参数以最小化损失函数
# Adam (
# Parameter Group 0
# amsgrad: False
# betas: (0.9, 0.999)
# capturable: False
# differentiable: False
# eps: 1e-08
# foreach: None
# fused: None
# lr: 0.001
# maximize: False
# weight_decay: 0
# )
optimizer = optim.Adam(model.parameters())# 训练模型: 使用了一个循环来迭代执行多个 epoch(训练轮数)
epochs = 5000
for epoch in tqdm(range(epochs), desc='训练进度'): # epoch = 0,..., epoch = 4total_loss = 0.0correct = 0total_samples = 0for inputs, targets in train_loader:optimizer.zero_grad() # 首先,使用优化器的 zero_grad() 方法将模型参数的梯度归零,以准备计算新一轮的梯度。# 然后,通过模型前向传播计算得到模型的输出 outputs。# epoch = 0时:# outputs = tensor([[0.1091, 0.0567, 0.0587, 0.0967, 0.1380, 0.1759, 0.1786, 0.1863],# [0.1626, 0.0645, 0.0532, 0.1406, 0.0927, 0.1947, 0.1429, 0.1487],# [0.1081, 0.0481, 0.0837, 0.1257, 0.1359, 0.1466, 0.1929, 0.1590]],# grad_fn=<SoftmaxBackward0>)# epoch = 4时:# outputs = tensor([[0.1272, 0.1309, 0.1559, 0.0674, 0.1287, 0.0707, 0.1293, 0.1898],# [0.1423, 0.1347, 0.1282, 0.0570, 0.1251, 0.0887, 0.1523, 0.1716],# [0.1320, 0.1184, 0.1521, 0.0699, 0.1312, 0.0632, 0.1283, 0.2050]],# rad_fn=<SoftmaxBackward0>)outputs = model(input_batch)# 接着,计算模型的预测结果与真实标签之间的交叉熵损失,即模型在当前轮次的损失值 loss。# epoch = 0时:# loss = tensor(2.0923, grad_fn=<NllLossBackward0>)# epoch = 4时:# loss = tensor(2.0697, grad_fn=<NllLossBackward0>)loss = criterion(outputs, torch.max(target_batch, 1)[1])# 使用损失函数的 backward() 方法计算损失关于模型参数的梯度。loss.backward()# 最后,使用优化器的 step() 方法更新模型的参数,以最小化损失函数。optimizer.step()total_loss += loss.item() * inputs.size(0)_, predicted = torch.max(outputs, 1)correct += (predicted == torch.max(targets, 1)[1]).sum().item()total_samples += inputs.size(0)accuracy = correct / total_samplesavg_loss = total_loss / total_samples# 每隔 100 个 epoch 打印一次当前轮次的损失值。if (epoch+1) % 1000 == 0:print(f'Epoch {epoch + 1}/{epochs}')print(f'Loss: {avg_loss:.4f} - Accuracy: {accuracy:.4f}\n')# print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, epochs, loss.item()))# 预测测试
predict = model(input_batch) # 使用训练好的模型对测试数据进行预测; 将测试数据输入模型,得到模型的预测结果
_, predict = torch.max(predict, 1) # 通过 torch.max() 函数找到每个预测结果中概率最大的类别索引# 将预测结果转换为汉字,并打印出原始输入数据和模型预测得到的结果。
print('输入的是:', [seg_char(sen)[:2] for sen in sentences])
print('预测得到:', [number_dict[n.item()] for n in predict])