day17 天池新闻数据KMeans、DBSCAN 与层次聚类的对比
在数据分析中,聚类是一种常见的无监督学习方法,用于将数据划分为不同的组或簇。本文将通过news数据集(news.csv),使用 KMeans、DBSCAN 和层次聚类三种方法进行聚类分析,并对比它们的性能。
数据来源于天池 新闻推荐
数据准备
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, MiniBatchKMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
data = pd.read_csv('news.csv') # 替换为你的数据文件路径# 提取特征
features = ['user_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country', 'click_region', 'click_referrer_type']
X = data[features]# 将时间戳转换为数值型特征(例如,提取小时数)
X['click_hour'] = pd.to_datetime(X['click_timestamp'], unit='ms').dt.hour# 删除原始时间戳列
X = X.drop(columns=['click_timestamp'])# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)k-means聚类
# 选择部分数据进行聚类
sample_size = 1000 # 选择 1000 个样本
X_scaled_sample = X_scaled[:sample_size]# 使用 PCA 降维
pca = PCA(n_components=5) # 保留 10 个主成分
X_scaled_pca = pca.fit_transform(X_scaled_sample)# 评估不同 k 值下的指标
k_range = range(2, 6) # 测试 k 从 2 到 5
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled_pca)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled_pca, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled_pca, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled_pca, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()k=2, 惯性: 3143.25, 轮廓系数: 0.635, CH 指数: 295.74, DB 指数: 0.539
k=3, 惯性: 2125.48, 轮廓系数: 0.513, CH 指数: 457.16, DB 指数: 0.800
k=4, 惯性: 1463.95, 轮廓系数: 0.461, CH 指数: 592.08, DB 指数: 0.757
k=5, 惯性: 974.44, 轮廓系数: 0.514, CH 指数: 791.42, DB 指数: 0.665
k=6, 惯性: 778.98, 轮廓系数: 0.545, CH 指数: 841.08, DB 指数: 0.733
k=7, 惯性: 696.43, 轮廓系数: 0.539, CH 指数: 802.81, DB 指数: 0.719
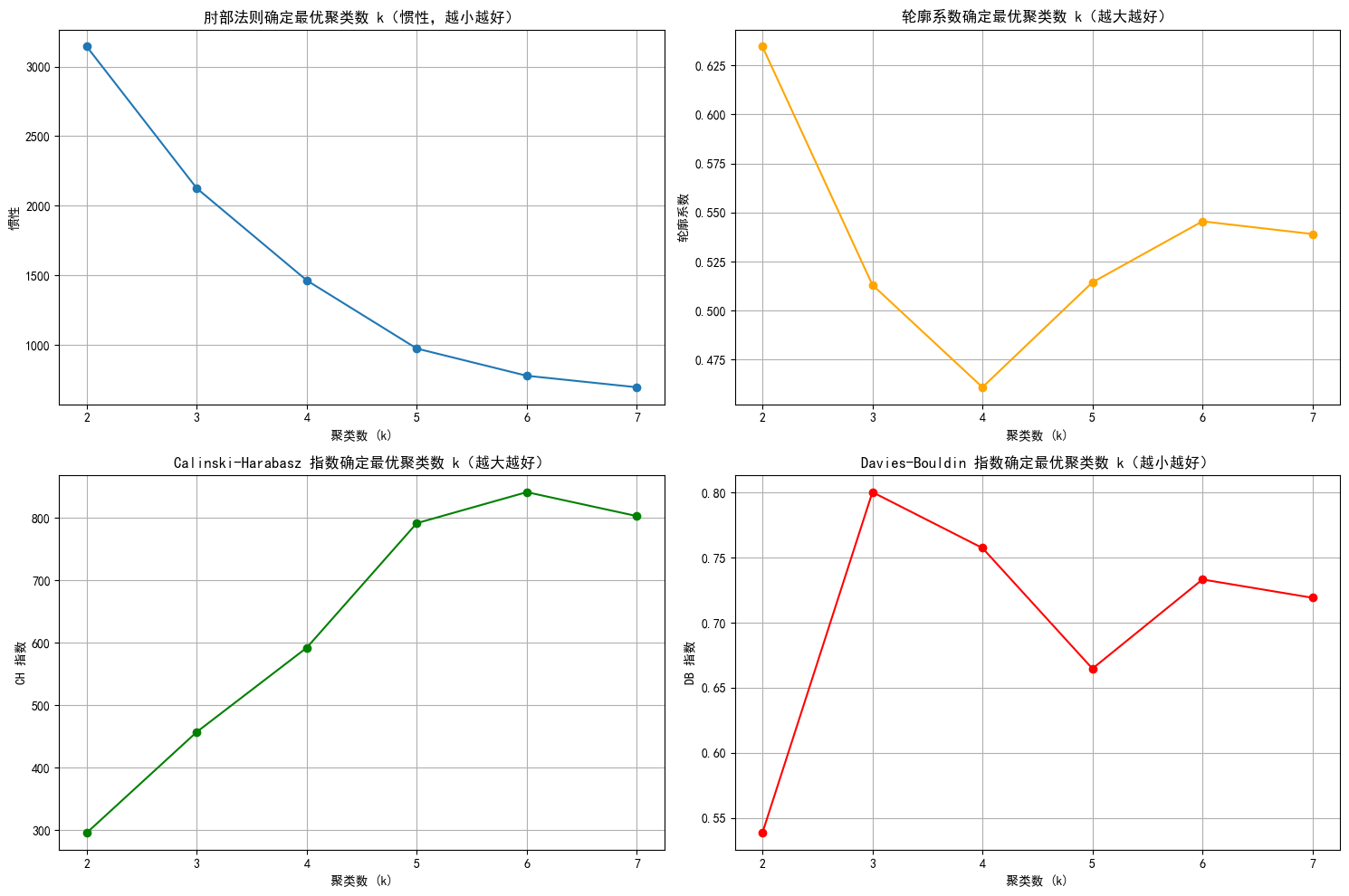
综上,选择3比较合适。
# 提示用户选择 k 值
selected_k =3# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())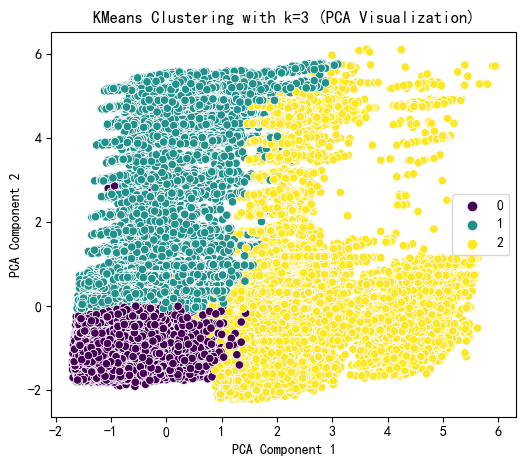
KMeans Cluster labels (k=3) added to X:
KMeans_Cluster
1 460706 0 327049
2 324868
Name: count,
dtype: int64
DBSCAN聚类
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
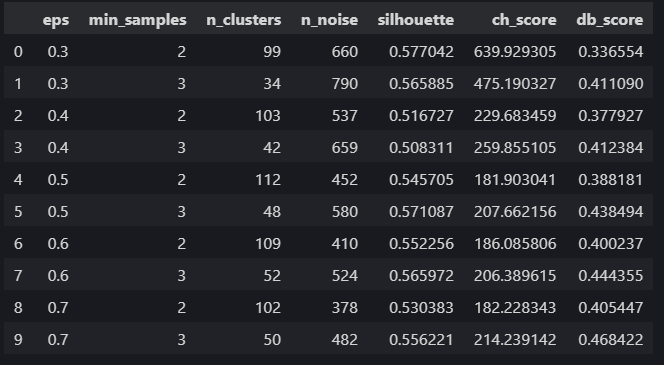
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)| eps | min\_samples | n\_clusters | n\_noise | silhouette | ch\_score | db\_score |
| --: | -----------: | ----------: | -------: | ---------: | --------: | --------: |
| 0.3 | 2 | 99 | 660 | 0.577 | 639.93 | 0.337 |
| 0.3 | 3 | 34 | 790 | 0.566 | 475.19 | 0.411 |
| 0.4 | 2 | 103 | 537 | 0.517 | 229.68 | 0.378 |
| 0.4 | 3 | 42 | 659 | 0.508 | 259.86 | 0.412 |
| 0.5 | 2 | 112 | 452 | 0.546 | 181.90 | 0.388 |
| 0.5 | 3 | 48 | 580 | 0.571 | 207.66 | 0.438 |
| 0.6 | 2 | 109 | 410 | 0.552 | 186.09 | 0.400 |
| 0.6 | 3 | 52 | 524 | 0.566 | 206.39 | 0.444 |
| 0.7 | 2 | 102 | 378 | 0.530 | 182.23 | 0.405 |
| 0.7 | 3 | 50 | 482 | 0.556 | 214.24 | 0.468 |
# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()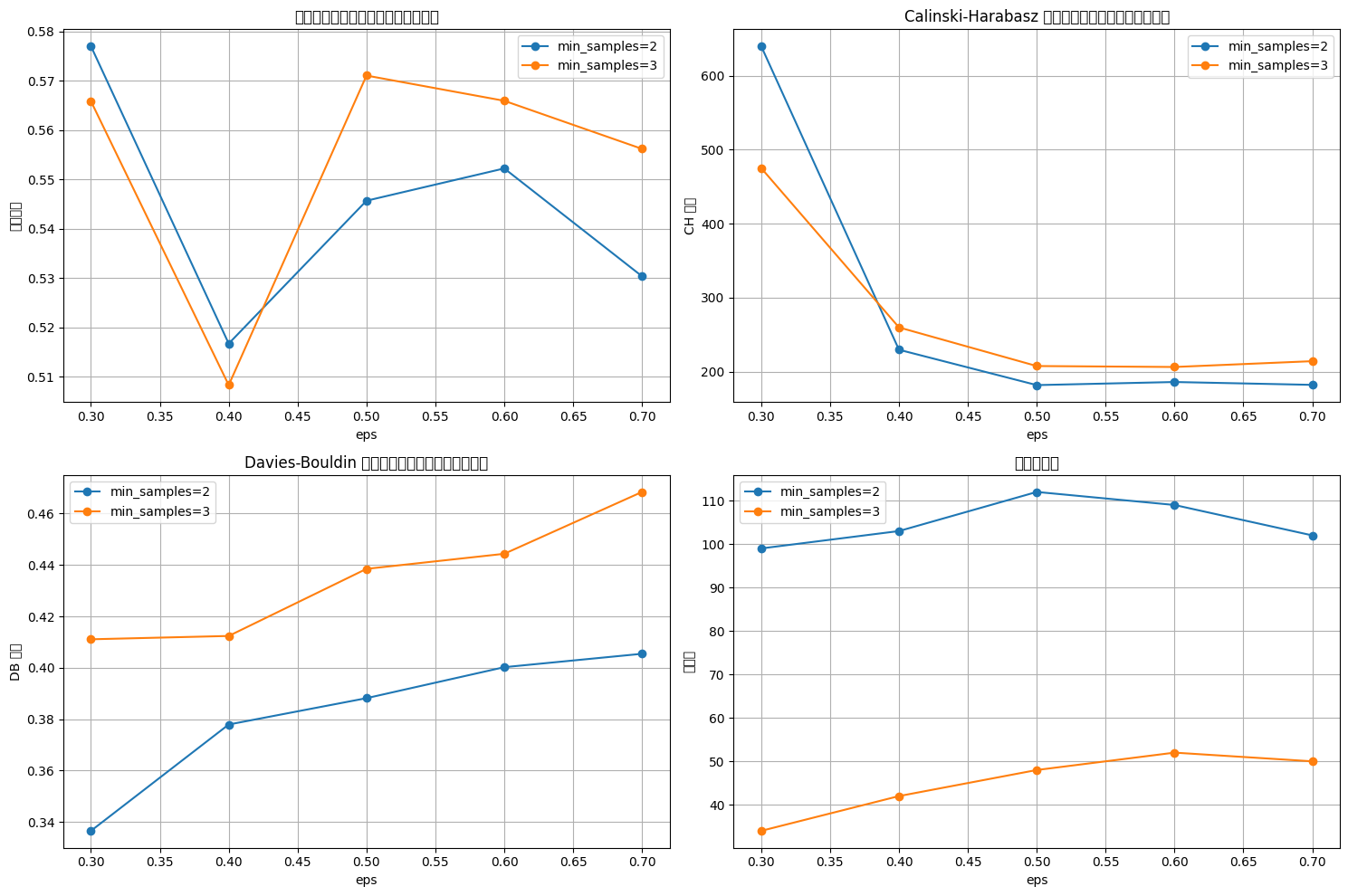
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts())features = ['user_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country', 'click_region', 'click_referrer_type']
X = data[features]
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled_sampled)# 将聚类标签添加到采样后的数据中
X_sampled['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled_sampled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X_sampled:")
print(X_sampled['DBSCAN_Cluster'].value_counts())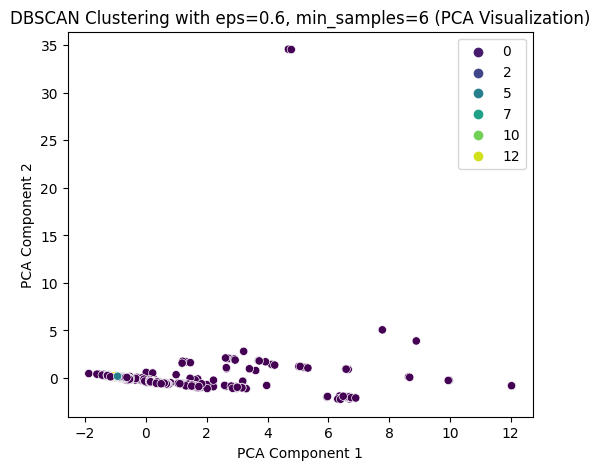
DBSCAN Cluster labels (eps=0.6, min_samples=6) added to X_sampled:
DBSCAN_Cluster
-1 707
1 78
2 62
3 31
5 25
8 17
0 14
10 13
9 12
4 9 7
8 12
7 6
6 13
6 11
5 Name: count,
dtype: int64
看起来效果不太好
层次聚类
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from sklearn.utils import resample
import matplotlib.pyplot as plt
import seaborn as sns# 假设 X 是原始数据的 DataFrame# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇agglo_labels = agglo.fit_predict(X_scaled_sampled)# 计算评估指标silhouette = silhouette_score(X_scaled_sampled, agglo_labels)ch = calinski_harabasz_score(X_scaled_sampled, agglo_labels)db = davies_bouldin_score(X_scaled_sampled, agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()n_clusters=2, 轮廓系数: 0.289, CH 指数: 201.78, DB 指数: 1.878 n_clusters=3, 轮廓系数: 0.267, CH 指数: 203.11, DB 指数: 1.445 n_clusters=4, 轮廓系数: 0.289, CH 指数: 225.13, DB 指数: 1.076 n_clusters=5, 轮廓系数: 0.331, CH 指数: 255.56, DB 指数: 1.055 n_clusters=6, 轮廓系数: 0.248, CH 指数: 269.20, DB 指数: 1.159 n_clusters=7, 轮廓系数: 0.278, CH 指数: 268.75, DB 指数: 1.161 n_clusters=8, 轮廓系数: 0.275, CH 指数: 264.39, DB 指数: 1.187 n_clusters=9, 轮廓系数: 0.263, CH 指数: 258.00, DB 指数: 1.202 n_clusters=10, 轮廓系数: 0.258, CH 指数: 251.18, DB 指数: 1.158
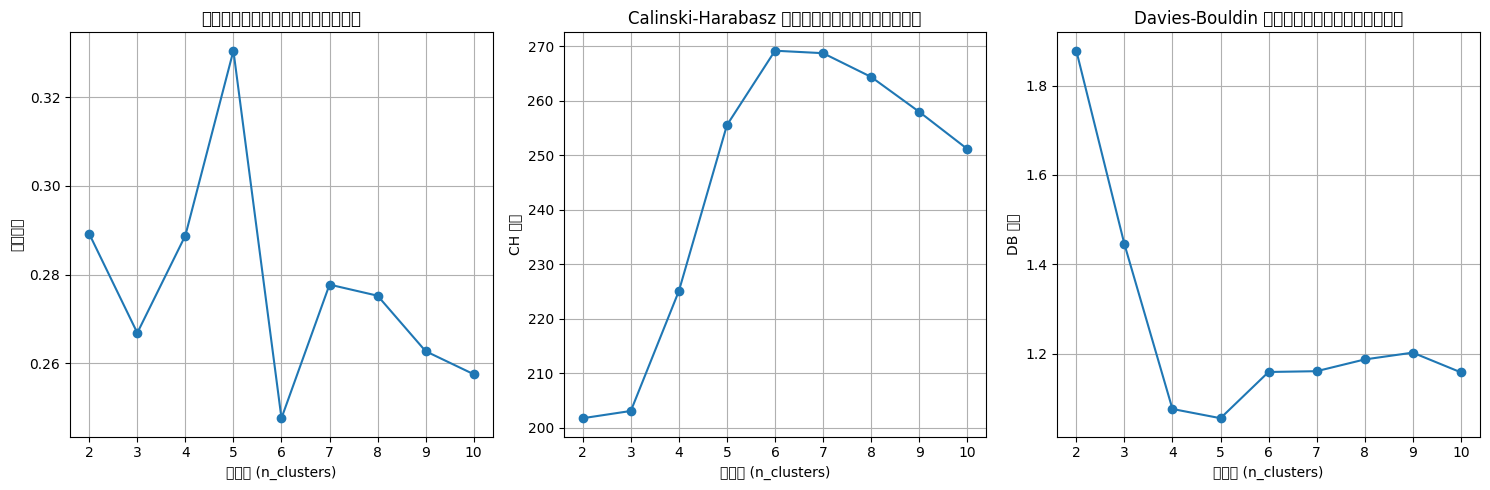
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())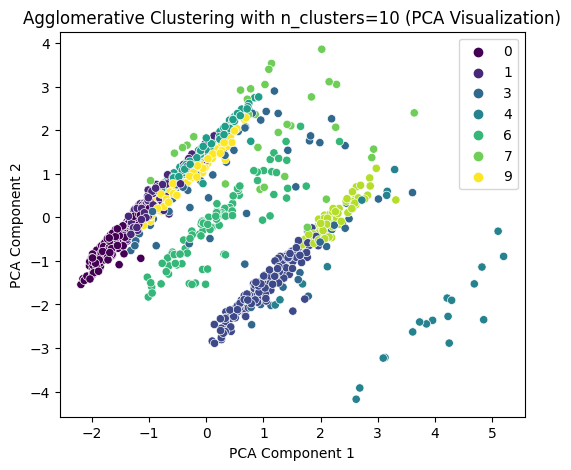
Agglomerative Cluster labels (n_clusters=10) added to X_sampled: Agglo_Cluster 0 206 2 153 1 130 5 126 9 95 6 87 3 78 8 68 7 32 4 25 Name: count, dtype: int64
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt# 假设 X 是原始数据的 DataFrame# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled_sampled, method='ward') # 'ward' 是常用的合并准则# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.show()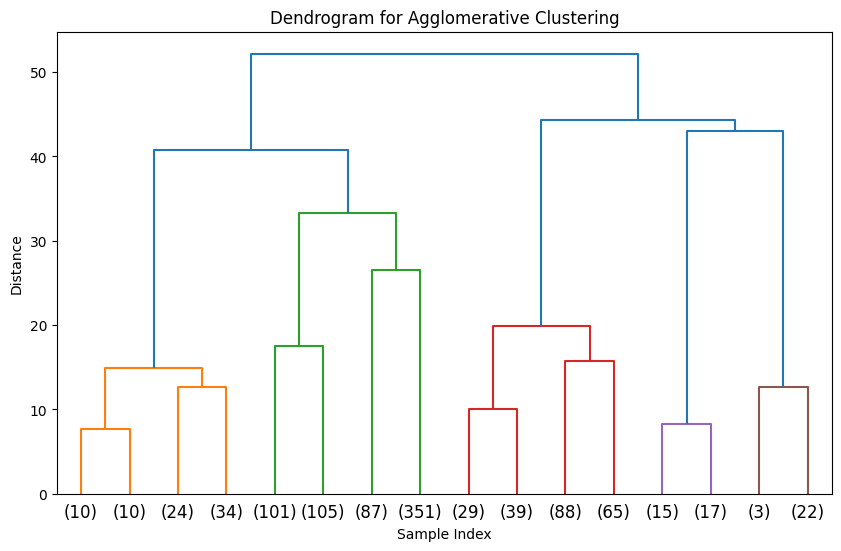
整一个流程下来,发现由于数据集的问题,导致Unable to allocate 4.50 TiB for an array with shape (618964413753,) and data type float64。可以说是维度爆炸,独热编码会为每个类别创建一个新的列,如果某个特征的类别数量非常多,就会导致生成大量的新列,从而显著增加数据的维度。这不仅会消耗大量内存,还可能导致计算速度变慢甚至崩溃。和我之前遇到的问题一样,后面通过代码将数据选择数量为1000得以解决。
# 标准化数据 scaler = StandardScaler() X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量 X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量
不同的数据集适合的算法不一样,选择合适的聚类算法,我得先看看我的数据是什么情况。如果数据点都挺规整的,像一个个圆球一样,那我就用 KMeans,这算法简单又快,特别适合这种场景。要是我的数据形状不规则,或者我怀疑里面有不少“杂点”,那我就试试 DBSCAN,它能很好地揪出这些杂点,还能处理各种奇怪形状的簇。要是数据量不大,我可能会考虑层次聚类,尤其是想看看聚类的过程,它能给我画个树状图,一目了然。但如果数据特别多,我就得用 MiniBatchKMeans 了,这样不会把电脑给“撑爆”。数据维度太高的话,我一般先用 PCA 降维,不然计算量太大,而且有时候高维度的数据也会让人看不清楚重点。我还会用一些评估指标,比如轮廓系数、CH 指数、DB 指数,来检查聚类效果怎么样。如果能画个图看看聚类结果就更好了,这样我能更直观地判断是不是符合我的预期。总之,选聚类算法就像挑工具,得看手头的活儿是个啥情况,选最顺手的那个。
@浙大疏锦行