网页截图指南
截取网页截图看似是一项简单的任务,但当你真正动手去做的时候,就会发现事情远没有那么容易。我在尝试截取一篇很长的 Reddit 帖子时就深有体会。一开始我以为只要调用 browser.TakeImage() 就万事大吉,结果却陷入了浏览器视口、动态内容加载、内存占用等一系列问题。
在这篇文章中,我将分享从一开始的“想当然”到最后找到高效方案的全过程。我们将以 r/dotnet 子版块为案例,探索常见的陷阱以及如何避免这些问题。看完这篇文章后,你将掌握如何稳定、完整地截取包含动态内容与无限滚动的网页截图的方法。
基础截图方式
我们先从最基础的方法开始:不进行任何特殊处理,直接截取截图。在 DotNetBrowser 中,这非常简单:
var image = browser.TakeImage();
var bitmap = ToBitmap(image);
bitmap.Save("screenshot.png", ImageFormat.Png);
由于 DotNetBrowser 返回的是原始位图,我们需要一个工具方法将其转换为 System.Drawing.Bitmap ,以便进行标准的 .NET 操作:
public static Bitmap ToBitmap(DotNetBrowser.Ui.Bitmap bitmap)
{var width = (int)bitmap.Size.Width;var height = (int)bitmap.Size.Height;var data = bitmap.Pixels.ToArray();var bmp = new Bitmap(width, height, PixelFormat.Format32bppRgb);var bmpData = bmp.LockBits(new Rectangle(0, 0, bmp.Width, bmp.Height),ImageLockMode.WriteOnly, bmp.PixelFormat);Marshal.Copy(data, 0, bmpData.Scan0, data.Length);bmp.UnlockBits(bmpData);return bmp;
}
运行这段代码后,我们得到了第一张截图:
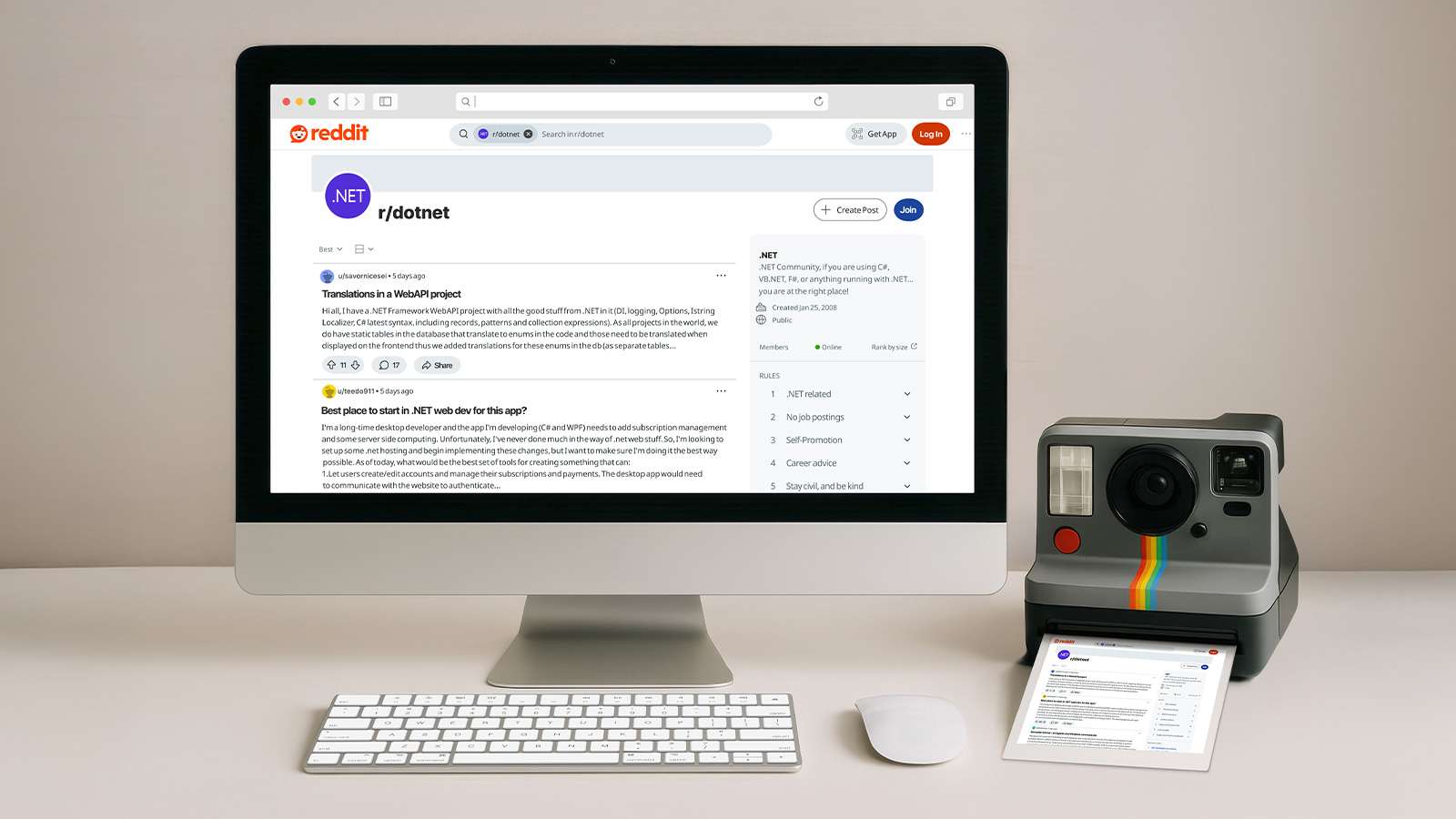
但问题显而易见:我们只截取了页面的一小部分。
这是因为 TakeImage() 方法仅截取浏览器视口内可见的内容,而默认视口大小并不足以显示整个页面。
截取整页截图
我们需要先获取网页的尺寸,并将浏览器调整为相应大小,然后重新尝试截图。可以通过 JavaScript 获取页面的尺寸,方法是取 document 或 document.documentElement 中较大的那个值:
var widthScript = @"Math.max(document.body.scrollWidth,document.documentElement.scrollWidth)";var heightScript = @"Math.max(document.body.scrollHeight,document.documentElement.scrollHeight)";
然后调整浏览器大小以匹配这些尺寸:
var frame = browser.MainFrame;
var width = frame.ExecuteJavaScript<double>(widthScript).Result;
var height = frame.ExecuteJavaScript<double>(heightScript).Result;browser.Size = new Size((uint)width, (uint)height);
var image = browser.TakeImage();
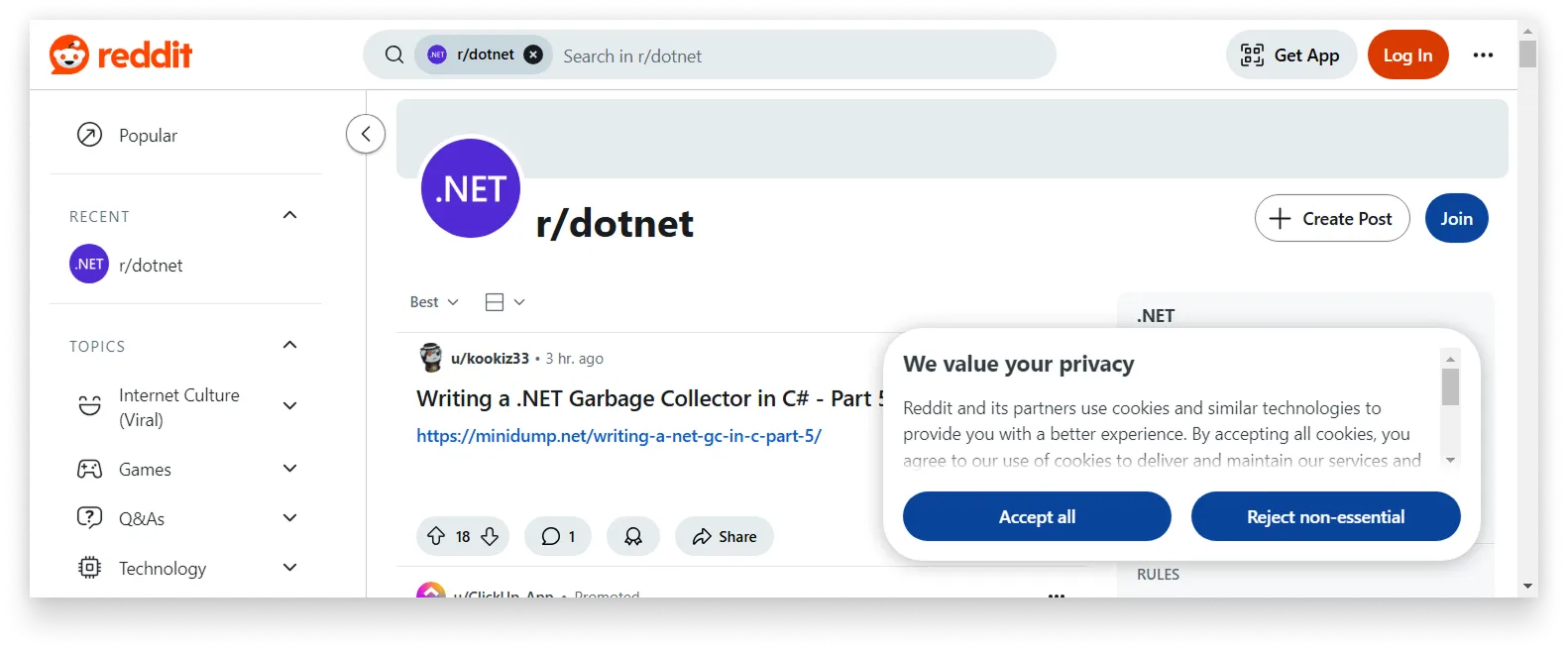
以下是使用这种改进方法得到的结果:

查看完整图片
紧接着出现了另一个问题:页面并未完全加载。这是因为我们在调整浏览器大小后立即进行了截图,没有给浏览器足够的时间来加载和渲染所有内容。从页面底部的加载指示器可以看出这一点。
让我们填加一个暂停等待时间:
browser.Size = new Size((uint)width, (uint)height);
// 通过反复试验得出的任意数字。
Thread.Sleep(2000);
var image = browser.TakeImage();
再试一次:
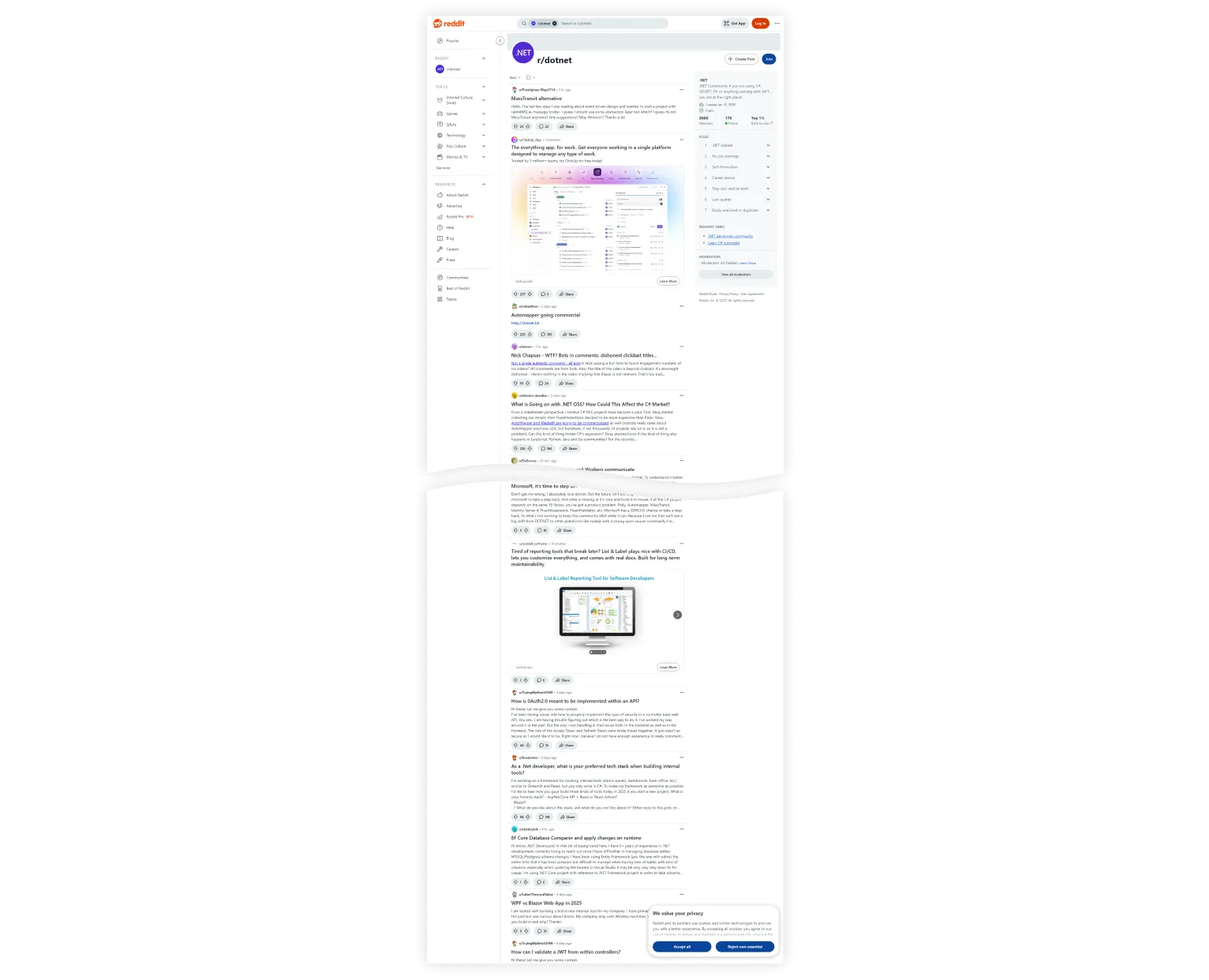
查看完整图片
终于,我们得到了一张像样的截图!但位图对象变得相当大,而且 Chromium 需要大量资源来渲染大视口,这在实际应用中并不实用。我们可以做得更好。
截取分段截图
使用之前的方法,浏览器会一次性渲染整个页面,并将结果位图传递给 .NET 进程内存。在处理长页面时,这会迅速耗尽系统资源,尤其是 RAM。
与其尝试一次性截取整个页面,不如我们将其分解为更小、更易管理的部分:
- 对页面的各个小段进行多次截图。
- 在每次截取之间滚动屏幕。
- 将各个部分拼接成最终图像。
以下是实现这种方法的代码:
// Reddit 页面是无限滚动的,因此我们需要设置一个固定的截图次数。
var numberOfShots = 15;
var viewportHeight = 1000;
browser.Size = new Size((uint)Width, (uint)viewportHeight);var capturedHeight = 0;
for (var count = 0; count < numberOfShots; count++)
{capturedHeight += viewportHeight;frame.ExecuteJavaScript($"window.scrollTo(0, {capturedHeight})").Wait();// 为了等待内容加载而设定的任意暂停时间。Thread.Sleep(500);var image = browser.TakeImage();var bitmap = ToBitmap(image);bitmap.Save($"screenshot-{count:D3}.png", ImageFormat.Png);
}
在实际应用中,我们会在另一台服务器上的异步任务中拼接这些片段。但为了简单起见,我们选择直接使用这个辅助函数:
public static Bitmap MergeBitmapsVertically(List<Bitmap> bitmaps)var files = Directory.GetFiles("/path/to/directory", "*.png").OrderBy(Path.GetFileName).ToArray();var images = files.Select(f => Image.FromFile(f)).ToArray();int width = images.Max(img => img.Width);int totalHeight = images.Sum(img => img.Height);using var merged = new Bitmap(width, totalHeight);using (var g = Graphics.FromImage(final)){int y = 0;foreach (var img in images){g.DrawImage(img, 0, y);y += img.Height;}}merged.Save("merged.png");
}
让我们看看结果如何:
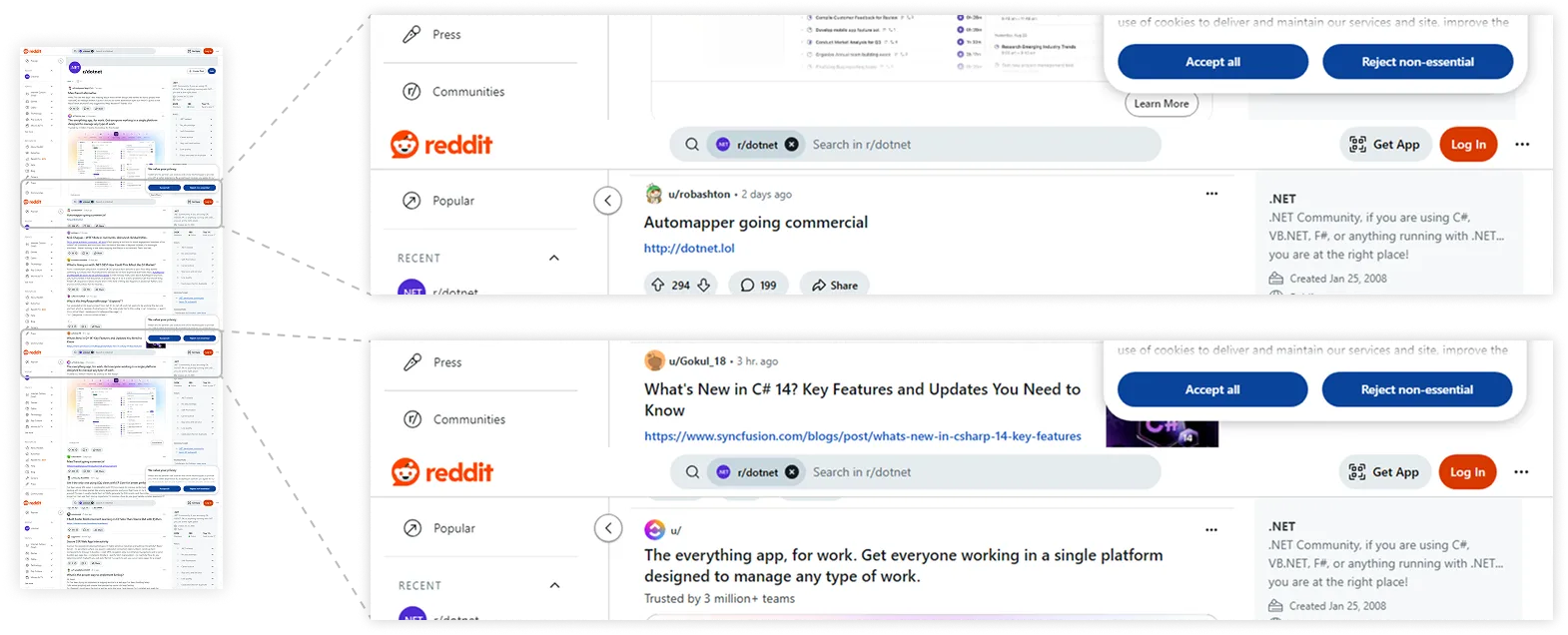
查看完整图片
又一个新问题出现了:页眉和导航侧边栏在每张分段截图里重复出现,这显然不是截图应有的样子!
处理固定元素
当我们滚动页面时,像页眉和侧边栏这样的固定元素会保持在原位不动。但在进行分段截图时,我们希望这些固定元素只出现在第一段截图中。
让我们通过 CSS 的 position 属性来找出这些元素,并将它们隐藏起来:
var removeFixedElements = @"(() => {document.querySelectorAll('*').forEach(el => {const pos = getComputedStyle(el).position;if (pos === 'fixed' || pos === 'sticky') {el.style.display = 'none';}});})()";for (var count = 0; count < numberOfShots; count++)
{// 仅从第二张截图开始移除固定元素,// 这样可以保留第一张截图中的页眉和导航栏。if (count == 1) {frame.ExecuteJavaScript(removeFixedElements).Wait();}// 继续进行截图操作。
}
另一个常见的固定元素是 Cookie 同意弹窗。由于每个网站的实现方式都不一样,我们需要逐个页面单独处理。
以 Reddit 为例,我们可以使用以下代码识别并隐藏 Cookie 弹窗:
var removeCookieScreen =@"(() => {const dialog = document.querySelector('reddit-cookie-banner');if (dialog) {dialog.style.display = 'none';}})()";
frame.ExecuteJavaScript(removeCookieScreen).Wait();
最终,我们以节省内存的方式截取了一张合适的网页截图。
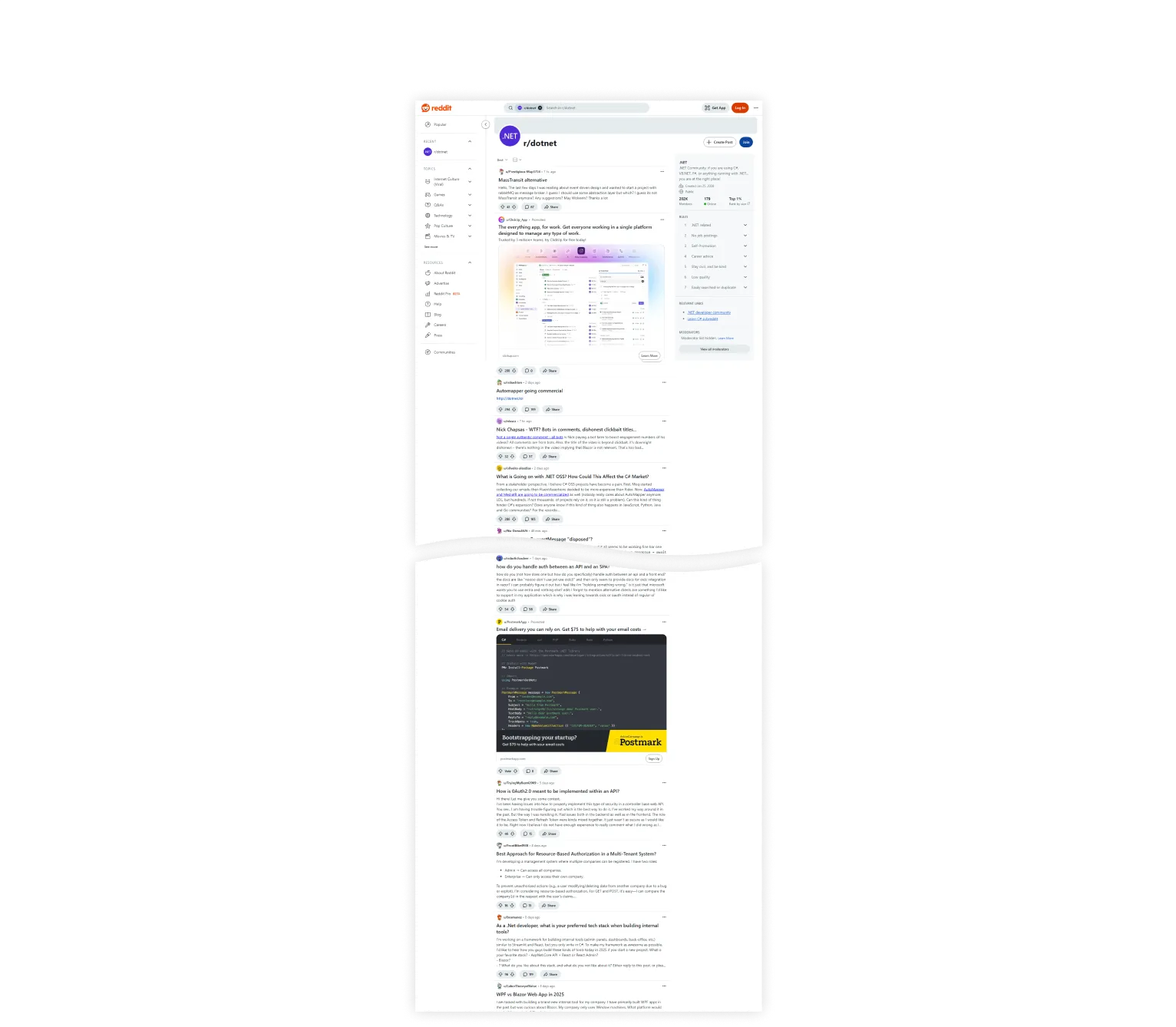
查看完整图片
总结
最初只是一个简单的 browser.TakeImage() 调用,最后演变成一个需要应对无数细节的复杂解决方案。我们解决了以下挑战:
- 一次性截取整页内容;
- 将长页面分段截取并拼接;
- 处理固定元素和 Cookie 弹窗;
- 优化内存使用和实用性。
需要说明的是,本文介绍的方法并非放之四海而皆准。每个网页都有其独特之处,而优秀的截图工具之所以强大,正是因为它能处理各种边缘场景。尽管如此,本文所展示的方法已经涵盖了使用 DotNetBrowser 进行网页截图所需掌握的所有核心知识。