【高级IO】多路转接之select
多路转接之select
- 一.IO的本质
- 二.五种IO模型
- 1.阻塞IO
- 2.非阻塞IO
- 2.1将文件描述符设置为非阻塞
- 3.信号驱动IO
- 4.多路转接IO
- 5.异步IO
- 三.多路转接之select
- 等待+拷贝
- 第一次循环:将所有关心的文件描述符设置到读/写/异常位图中
- 第二次循环:执行所有就绪的事件方法
- 第三个循环:将新文件描述符插入用户关心的文件描述符数组中
- 四.代码
- 五.select的缺点
一.IO的本质
IO称为输入输出,read和write本质上并不是将数据正在的发送或读取。
write本质是将数据先发送给内核的发送缓冲区中,read的本质是从内核的接收缓冲区中读取数据。这些操作本质是就是将数据从用户层写给OS,或者从OS写给用户层。本质是拷贝。
而进行拷贝的前提的有条件的,比如发送缓冲区要满了,数据就无法write,
所以拷贝之前愮判断条件是否成立,也就是判断读写事件是否就绪。
这个判断的过程就是在等待事件就绪。
所以真正的IO是由等待+拷贝构成的。
【什么叫高效的IO】
因为IO=等待+拷贝
所以呢什么叫高效的IO呢?IO过程中,等待的比重越小,IO效率就越高!
任何I0过程中,都包含两个步骤,第一是等待,第二是拷贝.而且在实际的应用场景中,等待消耗的时间往往都远远高于拷贝的时间.让I0更高效,最核心的办法就是让等待的时间尽量少
二.五种IO模型
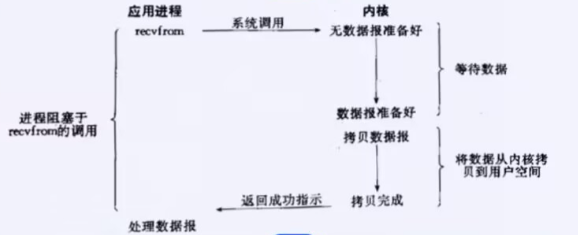
1.阻塞IO
阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式.
2.非阻塞IO
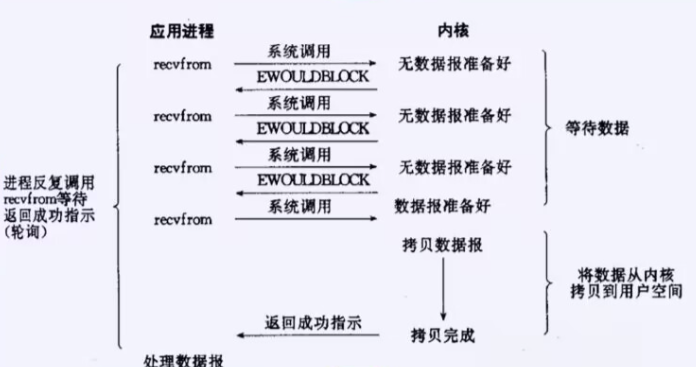
非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK错误码.
非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符, 这个过程称为轮询. 这对CPU来说是较大的浪费, 一
般只有特定场景下才使用。
【阻塞IO VS 非阻塞IO】
阻塞IO和非阻塞IO动作都是一样的只不过,区别是等的方式不同。
区别只是等的方式不同,效率上没有区别的,非阻塞在等的时候它可以做其他事情所以呢,它在io上效率跟阻塞io没有太大区
别,但是因为它做了其他事情所以我们说,它效率可能会比阻塞高一些。
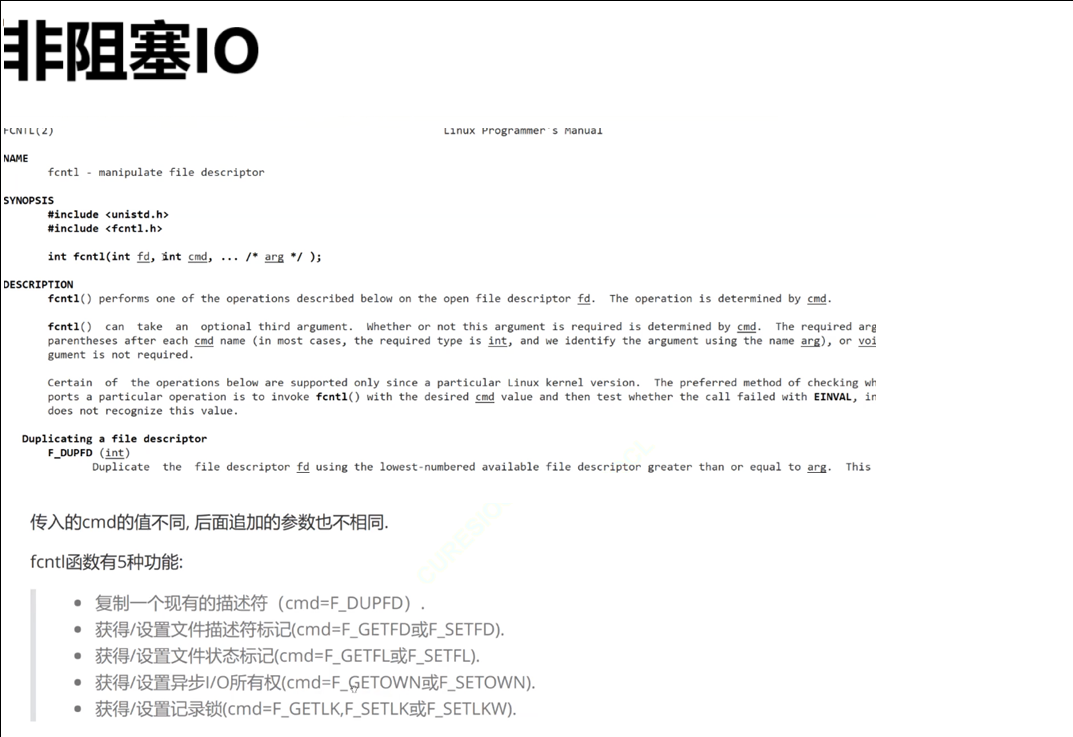
2.1将文件描述符设置为非阻塞
#include <iostream>
#include <unistd.h>
#include <cstdio>
#include <fcntl.h>
#include <cerrno>
#include <cstring>using namespace std;void SetNonBlock(int fd)
{int fl=fcntl(fd,F_GETFL);if(fl<0){perror("fcntl");return ;}fcntl(fl,F_SETFL,fl|O_NONBLOCK);cout<<"set"<<fd<<"nonblock done"<<endl;
}int main()
{char buffer[1024];SetNonBlock(0);//把标准输出设置为非阻塞IO,读取一次就返回while(1){ssize_t n= read(0, buffer, sizeof(buffer) - 1);if(n>0){buffer[n]=0;cout<<"echo: "<<buffer<<endl;}else if(n==0){cout<<"read done"<<endl;break;}else{ if(errno==EWOULDBLOCK){cout<<"没有数据可以读,需要重新试试"<<endl;sleep(1);}else{cerr << "read error, n = " << n << "errno code: "<< errno << ", error str: " << strerror(errno) << endl;break;} }}
}
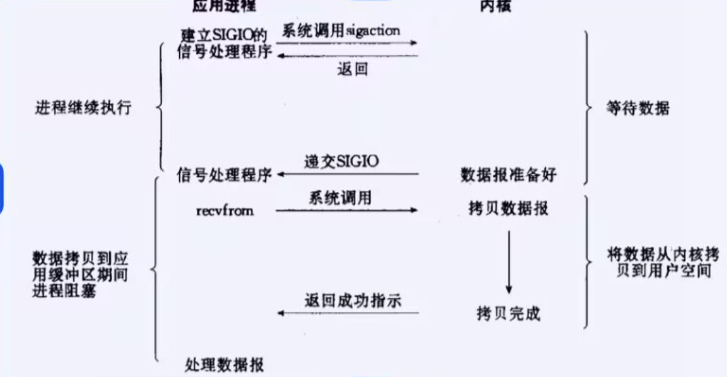
3.信号驱动IO
信号驱动IO: 内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作.
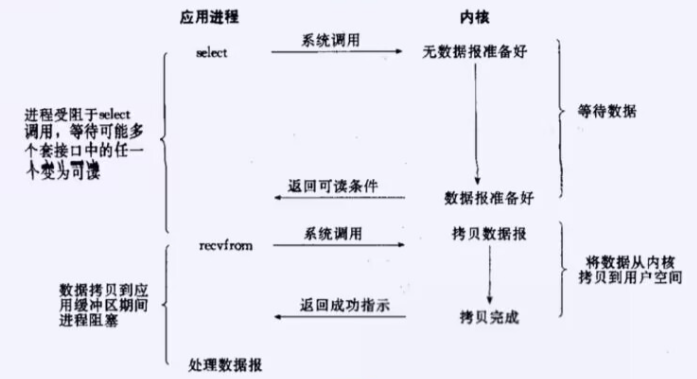
4.多路转接IO
IO多路转接: 虽然从流程图上看起来和阻塞IO类似. 实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态.
5.异步IO
异步IO: 由内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据).
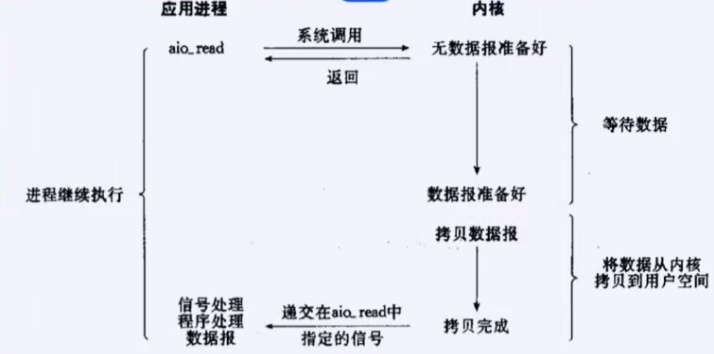
【同步IO VS 异步IO】
怎么区别是同步IO还是异步IO呢?区别在于你到底有没有参与IO的过程。IO的过程分为两步等+拷贝。只要参与其中一个就是同步,如果两个都没参与那么就是异步。
三.多路转接之select
IO=等待+拷贝
select的作用就是只负责进行等,但它的特点是一次可以等待多个文件描述符。
而拷贝的工作还是交给read,write具体接口,只不过它们不再进行等待了。事件就绪后直接进行拷贝。
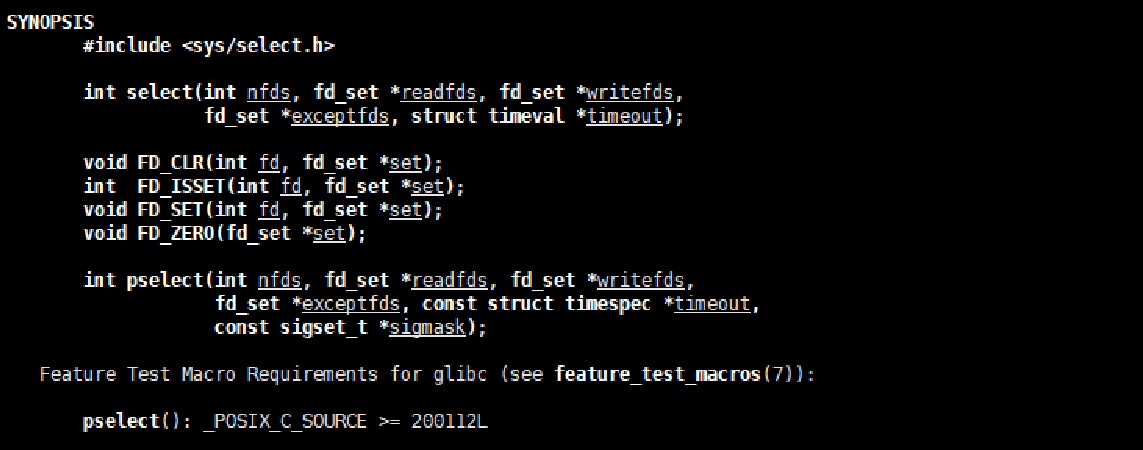
1.nfds:select要等待的文件描述符中的最大值+1
2.fd_set 是内核提供的一种数据类型,是一个位图。参数中有三个,分别表示文件描述符要关心的是读事件,还是写事件,还是异常事件。并且都是输入输出型参数。输入时的意义是让内核关心指定的文件描述符,如果就绪了就要告诉我。输出时的意义是内核告诉用户,有哪些文件描述已经就绪了。
fd_set,是一张位图,是让用户和内核之间传递fd是否就绪的信息的!这也就注定了使用select是要对fd_set进行操作。内核提供了相关的操作。
3.struct timeval *timeout 可以让select等待多少时间返回一次。
struct timeval timeout={5,0}:隔5S,timcout一次
{0,0}.立马返回,非阻塞的一种。NULL:阻塞等待

所以我们最终select本身并不负责任的读还是写它只用来在底层检测当前我们是否有数据或者是读写的条件是否满足,满足了之后我们就修改对应的fd_set位图就行。
等待+拷贝
服务器先创建一个套接字,并进行绑定,监听等工作。
select需要用户定义一个数组fd_array[],用来存放要关心的套接字。
这个辅助数组就是用来将用户要关心的所有文件描述符在不同的函数之间
互相传递,这个是select最大的特点之一。
要注意服务器启动时,一开始不能直接进行accept获取连接。因为accept本质是从全连接队列中获取已经连接成功的链接。它本质上是读取。所以所有IO=等+拷贝。
所以在accept之前我们需要等待。等待有客户端连接。
一旦有客户端连接,则全连接队列里就会存在链接,读取事件就绪,就可以直接获取链接了。
而想要让select等待listen套接字,需要将listen套接字设置到fd_set位图中,再将fd_set位图传给select内核。
前置工作:
1.定义一个fd_set rds位图对象。
2.将要关心的文件描述符设置到位图里
3.最后将位图设置到select内核中
第一次循环:将所有关心的文件描述符设置到读/写/异常位图中
void Start(){int listensock = _listensock.Fd();// 将需要关心的文件描述符插入到表格中fd_arry[0] = listensock;for (;;){// 不能直接accept,accept本质是从全连接队列里获取连接,相当于读,要实现高效的IO// 需要减少等待在IO中的比重,所以使用select可以等待多个连接fd_set rfds;//读事件位图FD_ZERO(&rfds);int maxfd = fd_arry[0]; // 目前最大的文件描述符for (int i = 0; i < fd_num_max; i++) // 第一次循环,为了将所有要关心的文件描述符告诉操作系统,并且找到下标最大的{ // 每次都需要,因为rfds是输入输出型参数,回来就不一样了if (fd_arry[i] == defaultfd) // 不是要关心的continue;FD_SET(fd_arry[i], &rfds); // 这个才是要关心的插入到读文件描述符集合中if (maxfd < fd_arry[i]){maxfd = fd_arry[i]; // 找到最大的文件描述符}}lg(Info, "max fd update,max fd is : %d", maxfd);struct timeval timeout = {0, 0}; // 相当于非阻塞int n = select(maxfd + 1, &rfds, nullptr, nullptr, nullptr);switch (n){case 0:cout << "time out,timeout:" << timeout.tv_sec << "." << timeout.tv_usec << endl;break;case -1:cout << "select error" << endl;break;default:cout << "get a link, already place queue " << endl;Dispatcher(rfds); // 表示有事件已经就绪了break;}}}
1.如果我们返回的时候select正确返回了它的返回值一定大于零的,此时rfds里面保存的就不再是用户告诉内核你要帮我关心什么文件描述符,它在返回时是内核告诉用户你要帮我关心的哪些文件描述符上的哪些事件已经就绪了。
2.但要注意因为fd_set *rds是输入输出型参数,输入时和输出的内容是不一样的。所以下次等待之前,rds是内核告诉用户就绪的,而不是用户让内核关心的,所以需要将rds再重新设置一遍。
3.在循环的过程中,并比较文件描述符数组里面最大的下标。
最终,我们经过这样的循环。我们就能够把我们叫做所有的合法的文件描述符全部重新在我们对应的rds里面重新添加并且更新出我们的最大文件描述符
4.一旦select返回,并且n大于0,就表明有读事件已经就绪。就可以将这些就绪的读事件派发出去执行。
并且所有的就绪的文件描述符都存放在rds中。可以通过rds来找到所有的就绪的文件描述符。
第二次循环:执行所有就绪的事件方法
当有读事件就绪时,select就会返回,执行
Dispatcher(rfds); 分配执行读事件所对应的方法。
而读事件分为两种:
一种是链接就绪,通过accept读取。
一种是普通的数据就绪,通过read读取。
通过就绪的套接字是否是listen套接字来区分是什么事件
所以需要分类讨论是什么读事件就绪了。如果就绪的是listen套接字,那么一定是读取连接事件就绪了。如果是普通的套接字,那么一定是读取数据事件就绪了。
因为select可以等待多个文件描述符,也就是可能就绪的文件描述符有多个,所以就需要循环将所有就绪的文件描述的读事件全部执行一遍。
void Dispatcher(fd_set &rfds){// 首先要判断是哪几个文件描述符的读事件就绪了,如果就绪了就会在rdfs表里for (int i = 0; i < fd_num_max; i++) // 第二个循环{int fd = fd_arry[i];if (fd == defaultfd)continue;// 让有效的文件描述符来比对if (FD_ISSET(fd, &rfds)) // 判断fd是否在rfds,在就说明fd的读事件就绪了{// 不能直接accept,还要判断是什么读事件,是读取连接事件就绪了,还是读取数据事件就绪了if (fd == _listensock.Fd()){Accepter();}else // 不是读取连接,就是读取数据事件{Recver(fd,i);}}}}
如果是读取链接事件的描述符就绪了,就需要执行Accepter方法,获取链接。
如果是读取数据事件就绪了,就需要执行Recver方法,读取数据。
第三个循环:将新文件描述符插入用户关心的文件描述符数组中
如果客户端发起连接,则listen套接字的读事件就会就绪,就会去执行 Dispatcher函数中的Accepter方法。
这个时候accept就不需要等待了,就直接可以获取到新连接,也就意味着又得到一个文件描述符,且需要关心它的读写。
所以我们就需要将新的文件描述符插入到用户定义维护的文件描述符数组fd_array[]中,等下次select之前第一次循环,会将所有关心的文件描述符设置到 fd_set rds中的,也就是读事件位图中的。最终由select设置到内核里关心等待。

一旦来了新的链接我们立即要处理它吗?不要,因为今天我们是select,我们要等待就绪后再去处理。
所以把这个链接呢,放在这个辅助数组里。然后呢,当我们下次再进行select的时候,那么此时,在select之前,就会重新遍历辅助数组重新添加,就会重新关心我们对应的读事件啊,那么或者是其他事件。
void Accepter(){string client_ip;uint16_t client_port;int sockfd = _listensock.Accept(&client_ip, &client_port);if (sockfd < 0)return;lg(Info, "accept success ,%s: %d, sockfd:%d ", client_ip.c_str(), client_port, sockfd);// 该事件处理完后,又产生一个文件描述符,并且需要关心它的读/写事件// 就需要将它插入到文件描述符集合中fd_array(其实就是用户要关心的文件描述符)int pos = 1;for (; pos < fd_num_max; pos++) // 第三个循环{if (fd_arry[pos] != defaultfd)continue;elsebreak;}// break跳出去有两种情况,一种是超过上限了,一种是有-1位置。if (pos == fd_num_max){lg(Warning, "server is full close %d now", sockfd);close(sockfd);}else{fd_arry[pos] = sockfd;PrintFd();}}
如果是普通的套接字就绪,那么就是读取数据事件就绪,那么就去执行Recvier方法
void Recver(int fd,int i){char buffer[1024] = {0};int n = read(fd, buffer, sizeof(buffer) - 1);if (n > 0){buffer[n] = 0;cout << "get a message: " << buffer << endl;}else if (n == 0) // 说明客户端的套接字关闭了{// 客户端的文件描述符关闭了,说明不关心了,就需要从文件描述符集合里取出来lg(Info, "client quit,me too close fd:%d", fd);close(fd);fd_arry[i] = defaultfd; // 这里本质是从select中移除}else{lg(Warning, "recv error: fd is:%d", fd);close(fd);fd_arry[i] = defaultfd;}}
四.代码
SelectServer完整代码:
#pragma once#include <iostream>
#include "Log.hpp"
#include "Socket.hpp"using namespace std;
static const uint16_t defaultport = 8888;
static const int fd_num_max = (sizeof(fd_set) * 8);
const int defaultfd = -1;
class SelectServer
{
public:SelectServer(uint16_t port = defaultport) : _port(port){for (int i = 0; i < fd_num_max; i++){fd_arry[i] = defaultfd; // 先全部初始化为-1表示无效}}bool Init(){_listensock.Socket();_listensock.Bind(_port);_listensock.Listen();return true;}void Accepter(){string client_ip;uint16_t client_port;int sockfd = _listensock.Accept(&client_ip, &client_port);if (sockfd < 0)return;lg(Info, "accept success ,%s: %d, sockfd:%d ", client_ip.c_str(), client_port, sockfd);// 该事件处理完后,又产生一个文件描述符,并且需要关心它的读/写事件// 就需要将它插入到文件描述符集合中fd_array(其实就是用户要关心的文件描述符)int pos = 1;for (; pos < fd_num_max; pos++) // 第三个循环{if (fd_arry[pos] != defaultfd)continue;elsebreak;}// break跳出去有两种情况,一种是超过上限了,一种是有-1位置。if (pos == fd_num_max){lg(Warning, "server is full close %d now", sockfd);close(sockfd);}else{fd_arry[pos] = sockfd;PrintFd();}}void Recver(int fd,int i){char buffer[1024] = {0};int n = read(fd, buffer, sizeof(buffer) - 1);if (n > 0){buffer[n] = 0;cout << "get a message: " << buffer << endl;}else if (n == 0) // 说明客户端的套接字关闭了{// 客户端的文件描述符关闭了,说明不关心了,就需要从文件描述符集合里取出来lg(Info, "client quit,me too close fd:%d", fd);close(fd);fd_arry[i] = defaultfd; // 这里本质是从select中移除}else{lg(Warning, "recv error: fd is:%d", fd);close(fd);fd_arry[i] = defaultfd;}}void Dispatcher(fd_set &rfds){// 首先要判断是哪几个文件描述符的读事件就绪了,如果就绪了就会在rdfs表里for (int i = 0; i < fd_num_max; i++) // 第二个循环{int fd = fd_arry[i];if (fd == defaultfd)continue;// 让有效的文件描述符来比对if (FD_ISSET(fd, &rfds)) // 判断fd是否在rfds,在就说明fd的读事件就绪了{// 不能直接accept,还要判断是什么读事件,是读取连接事件就绪了,还是读取数据事件就绪了if (fd == _listensock.Fd()){Accepter();}else // 不是读取连接,就是读取数据事件{Recver(fd,i);}}}}void Start(){int listensock = _listensock.Fd();// 将需要关心的文件描述符插入到表格中fd_arry[0] = listensock;for (;;){// 不能直接accept,accept本质是从全连接队列里获取连接,相当于读,要实现高效的IO// 需要减少等待在IO中的比重,所以使用select可以等待多个连接fd_set rfds;FD_ZERO(&rfds);int maxfd = fd_arry[0]; // 目前最大的文件描述符for (int i = 0; i < fd_num_max; i++) // 第一次循环,为了将所有要关心的文件描述符告诉操作系统,并且找到下标最大的{ // 每次都需要,因为rfds是输入输出型参数,回来就不一样了if (fd_arry[i] == defaultfd) // 不是要关心的continue;FD_SET(fd_arry[i], &rfds); // 这个才是要关心的插入到读文件描述符集合中if (maxfd < fd_arry[i]){maxfd = fd_arry[i]; // 找到最大的文件描述符}}lg(Info, "max fd update,max fd is : %d", maxfd);struct timeval timeout = {0, 0}; // 相当于非阻塞int n = select(maxfd + 1, &rfds, nullptr, nullptr, nullptr);switch (n){case 0:cout << "time out,timeout:" << timeout.tv_sec << "." << timeout.tv_usec << endl;break;case -1:cout << "select error" << endl;break;default:cout << "get a link, already place queue " << endl;Dispatcher(rfds); // 表示有事件已经就绪了break;}}}void PrintFd(){cout << "online fd list: ";for (int i = 0; i < fd_num_max; i++){if (fd_arry[i] == defaultfd)continue;cout << fd_arry[i] << " ";}cout << endl;}~SelectServer(){}private:Sock _listensock;uint16_t _port;int fd_arry[fd_num_max]; // 这个是用户定义的,用户维护的
};
main.cc代码
#include <iostream>
#include "SelectServer.hpp"
#include <memory>
int main()
{std::unique_ptr<SelectServer> svr(new SelectServer());svr->Init();svr->Start();
}
五.select的缺点
1.select等待文件描述符是有上限的
2.输入输出型参数太多了,需要多次用户->内核。内核->用户的拷贝
3.输出型参数会覆盖原来的数据,每次都需要重新设置关心事件
4.用户层需要自己定义第三方数组来关联fd,需要多次遍历