性能分析硬核特训 · Perf 全面指南:内核实例 + 原理实战 + 面试答疑
一、引言:为什么我们需要 Perf?
在内核开发和高性能系统调优过程中,我们常会遇到:
- 为什么系统变慢了?
- 哪个函数最耗 CPU?
- 哪段代码频繁中断?
这些问题,如果单靠 top 或 htop 很难深入到内核层面。而 Perf(Performance Counters for Linux),就是为此而生的专业级性能分析工具。
它是 Linux 内核中自带的、面向开发者的性能分析工具,支持用户空间和内核空间的性能分析。
二、Perf 的工作原理与架构概览
Perf 基于 Linux 内核的 perf_event 子系统,核心机制如下:
1. 工作原理简述
- Perf 借助 CPU 的硬件性能计数器(如 cache miss、分支预测失败等)或软件事件(如 task-clock)采样;
- 可通过周期性采样、中断触发或 tracepoint 捕获信息;
- 分析内核函数调用路径、周期、热路径等。
2. 架构示意图(简化)
+------------------------+
| 用户空间命令 perf |
+------------------------+|v
+------------------------+
| perf_event_open() syscall
+------------------------+|v
+------------------------+
| 内核 perf_event 子系统 |
+------------------------+|v
+------------------------+
| CPU 硬件/PMU、tracepoint、kprobe
+------------------------+
三、安装与基础使用(基于 Ubuntu / Debian)
sudo apt install linux-tools-common linux-tools-generic linux-tools-`uname -r`
检查是否安装成功:
perf --version
四、常用 Perf 命令详解
1. perf top(动态热点查看)
实时查看当前系统中最频繁运行的函数或指令。
perf top
- 默认采样周期为 1000 次/秒;
- 可定位系统热点函数(用户空间与内核空间)。
示例:
Samples: 19K of event 'cycles', Event count (approx.): 4723080000
Overhead Command Shared Object Symbol20.30% firefox libxul.so [.] mozilla::layers::Paint12.01% swapper [kernel.kallsyms] [k] schedule
2. perf record + perf report(静态分析)
采样记录 + 分析报告,是 Perf 最常用的组合。
perf record -g ./your_program
perf report
-g表示记录调用栈;- 输出报告中包含函数耗时、调用关系。
示例:
# Record kernel-level profile
sudo perf record -g -a -- sleep 10
sudo perf report
3. perf stat(性能计数器统计)
收集 CPU 执行统计,如指令数、cache miss、分支错误率等。
perf stat ./your_program
输出示例:
Performance counter stats for './your_program':1,500,123 task-clock # 0.999 CPUs utilized200,456 context-switches4,567 cpu-migrations5,000,987,321 instructions # 3.33 insn per cycle1,500,987,321 branches200,123 branch-misses # 13.34% of all branches
4. perf annotate(汇编级分析)
用于深入查看每条汇编指令的采样数据。
perf record ./your_program
perf annotate
- 常用于分析内核热点路径的每条指令性能;
- 支持结合
objdump输出源码与汇编对应信息。
5. perf sched(调度分析)
分析调度延迟与进程调度行为。
sudo perf sched record
sudo perf sched latency
sudo perf sched map
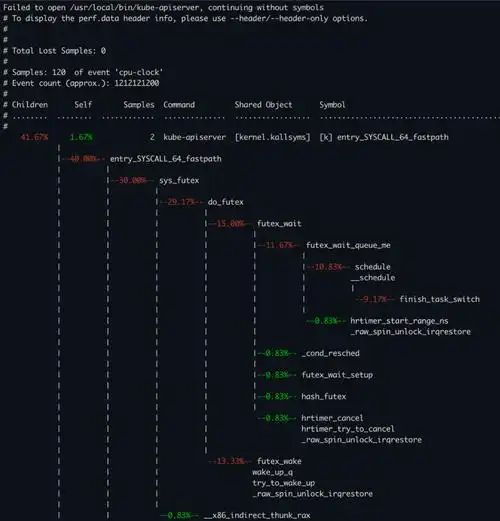
五、内核分析:以调度器为例的实战讲解
实战背景
我们想分析内核中哪个函数最影响调度性能,比如 schedule() 是否频繁调用,是否有锁竞争。
实操步骤
1. 全系统热点采样
sudo perf record -g -a -- sleep 10
sudo perf report
查找 schedule 的调用路径、比例:
- 33.33% [kernel.kallsyms] [k] schedule- __schedule- mutex_lock- fsnotify
2. 深入查看某路径的汇编指令
sudo perf annotate schedule
3. 使用 tracepoint 定位内核路径
使用调度相关 tracepoint:
sudo perf record -e sched:sched_switch -a -- sleep 5
sudo perf script
输出可读的切换事件:
swapper 0 [000] d... 100.000: sched_switch: prev_comm=swapper prev_pid=0 prev_prio=120 ... next_comm=sshd next_pid=1234
六、与其他工具的对比
| 工具 | 优势 | 劣势 |
|---|---|---|
| Perf | 内核原生,支持采样和计数,功能全 | 输出复杂,学习曲线较陡 |
| ftrace | Tracepoint 分析,轻量级 | 可视化较弱 |
| BCC/BPF | 灵活编程接口,适合大规模系统监控 | 依赖 LLVM、学习曲线更陡 |
| SystemTap | 强大脚本接口,适合自定义场景 | 配置复杂、侵入式较强 |
七、面试问题与答案精选
问题 1:Perf 工具是如何工作的?
最佳回答:
Perf 借助 Linux 的 perf_event 子系统,与 CPU 的硬件性能计数器(如 cache-miss、branch-miss)交互,也可以基于软件事件(如 context switch)或 tracepoint 采样信息,通过 perf record 捕获数据,perf report 分析函数耗时与调用路径。
问题 2:perf record 和 perf stat 有什么区别?
最佳回答:
perf record 主要用于采样记录程序执行期间的热点函数、调用路径等信息,结合 perf report 分析函数耗时。而 perf stat 用于统计程序的执行事件(如 instructions、cycles、cache-miss 等),更适合宏观性能分析。
问题 3:如何使用 Perf 定位某段内核代码的性能瓶颈?
最佳回答:
可以用 perf record -g -a -- sleep N 采样整个系统运行,结合 perf report 查看内核函数的占比,找到耗时函数如 __schedule。进一步用 perf annotate 分析汇编指令级别的细节,还可用 perf script 或 sched 分析调度行为。
问题 4:Perf 是否可以用在嵌入式平台或交叉编译环境?
最佳回答:
可以,但需目标内核启用了 perf_event 支持,并交叉编译 perf 工具链或通过 perf.data 文件在主机上进行离线分析。此外,符号信息(vmlinux 或带 debug info 的 ELF)需匹配目标系统。
问题 5:解释 perf top 中出现 [kernel.kallsyms] 的含义。
最佳回答:
[kernel.kallsyms] 表示该函数属于内核符号,通常用于未剥离符号的内核或 vmlinux。如果缺少内核符号表,perf 会无法解析函数名,因此建议使用带符号的内核映像。
八、附录:调优建议与实战经验
- 打开内核符号支持:保留
vmlinux或System.map,用于perf report的函数解析; - 使用
-g参数开启调用栈采样,利于分析上下文; - 配合火焰图(FlameGraph)工具可视化调用路径;
- 采样间隔控制:
--freq=XXX可控制采样频率,避免采样过稀或过密; - 注意核心绑定与 NUMA 架构,确保采样结果代表性强。
九、总结与推荐学习路线
Perf 是 Linux 性能调优的核心工具之一,无论是系统开发、内核调试还是性能优化,都能提供强大支持。建议如下路线:
- 掌握基础命令:
perf stat,perf record/report,perf top; - 结合真实项目或内核模块进行采样分析;
- 熟练使用 tracepoint 与 perf script;
- 进阶学习 FlameGraph、ftrace、eBPF/BCC 等辅助工具。
视频教程请关注 B 站:“嵌入式 Jerry”