Baichuan-Audio: 端到端语音交互统一框架
Baichuan-Audio是一个开源的端到端语音交互模型,无缝集成了音频理解和生成功能,支持高质量、可控的实时双语(汉英)对话。
-
Baichuan-Audio-Base: 为了促进语音模型的发展,我们开源了一个端到端语音基础模型,该模型由高质量的大量数据训练而成。该模型未经过 SFT 指令微调,具有很强的可塑性。
-
Baichuan-Audio: 该模型接受文本和音频作为输入,生成高质量的文本和音频输出,能够进行无缝的高质量语音交互,同时保持预先训练的 LLM 的智能,实现与用户的实时语音对话。
-
此外,我们还开源了音频理解和生成基准(OpenAudio-Bench),以评估端到端音频能力。此外,预培训数据也即将开源。
模型架构
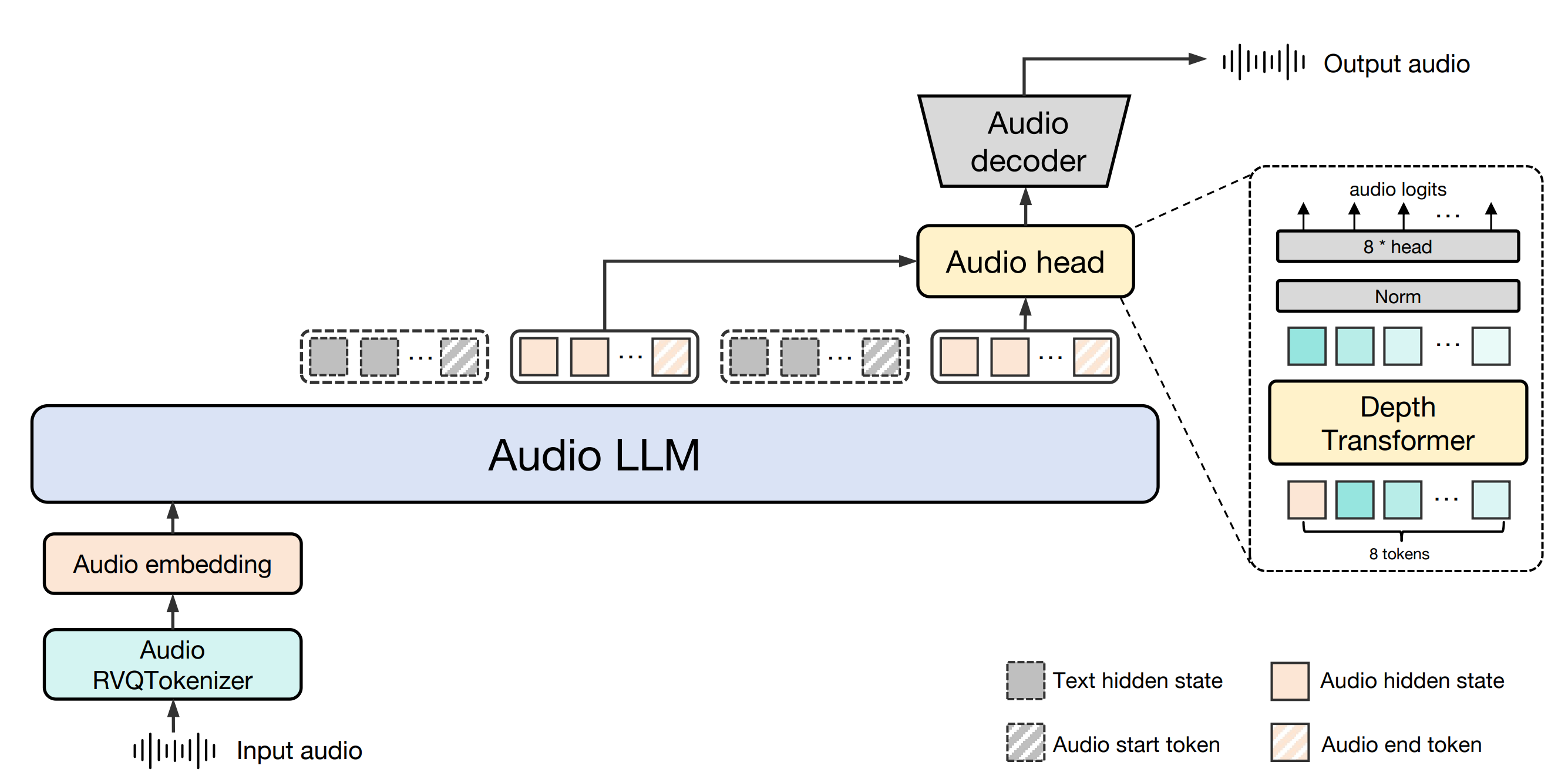
Baichuan-Audio 主要由Baichuan-Audio Tokenizer、Audio LLM 和基于流量匹配的音频解码器组成。首先,语音通过 Baichuan-Audio Tokenizer 转换器转换成离散的音频令牌。然后,音频 LLM 以交错方式生成对齐的文本和音频标记,通过特殊标记实现文本和音频之间的无缝模态切换。音频标记由独立的音频头处理,并使用基于流匹配的音频解码器将其重构为高质量的梅尔频谱图,然后通过声码器将其转换为音频波形。
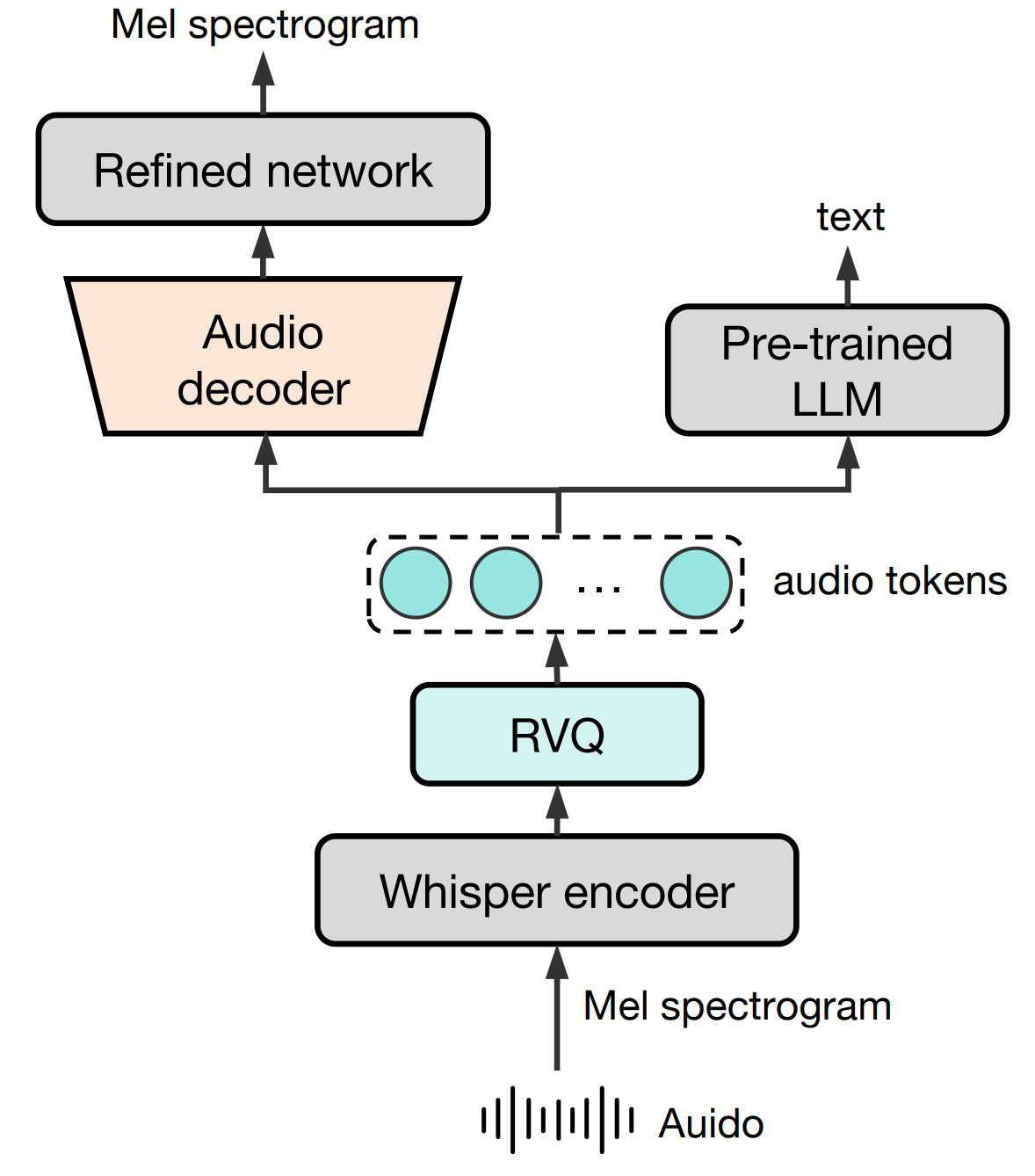
- Baichuan-Audio-Tokenizer 采用 12.5hz 帧频设计。它采用 Whisper Large 编码器从梅尔频谱图中提取高级音频特征,然后使用 8 层 RVQ 将量化过程中的信息损失降至最低。为了同时捕捉语义和声学信息,我们使用梅尔频谱图重构和预训练 LLM 分别进行声学和语义监督。
-
音频 LLM 以交错方式生成对齐的文本和音频标记,通过特殊标记实现文本和音频模式之间的无缝切换。音频标记由独立的音频头处理。
-
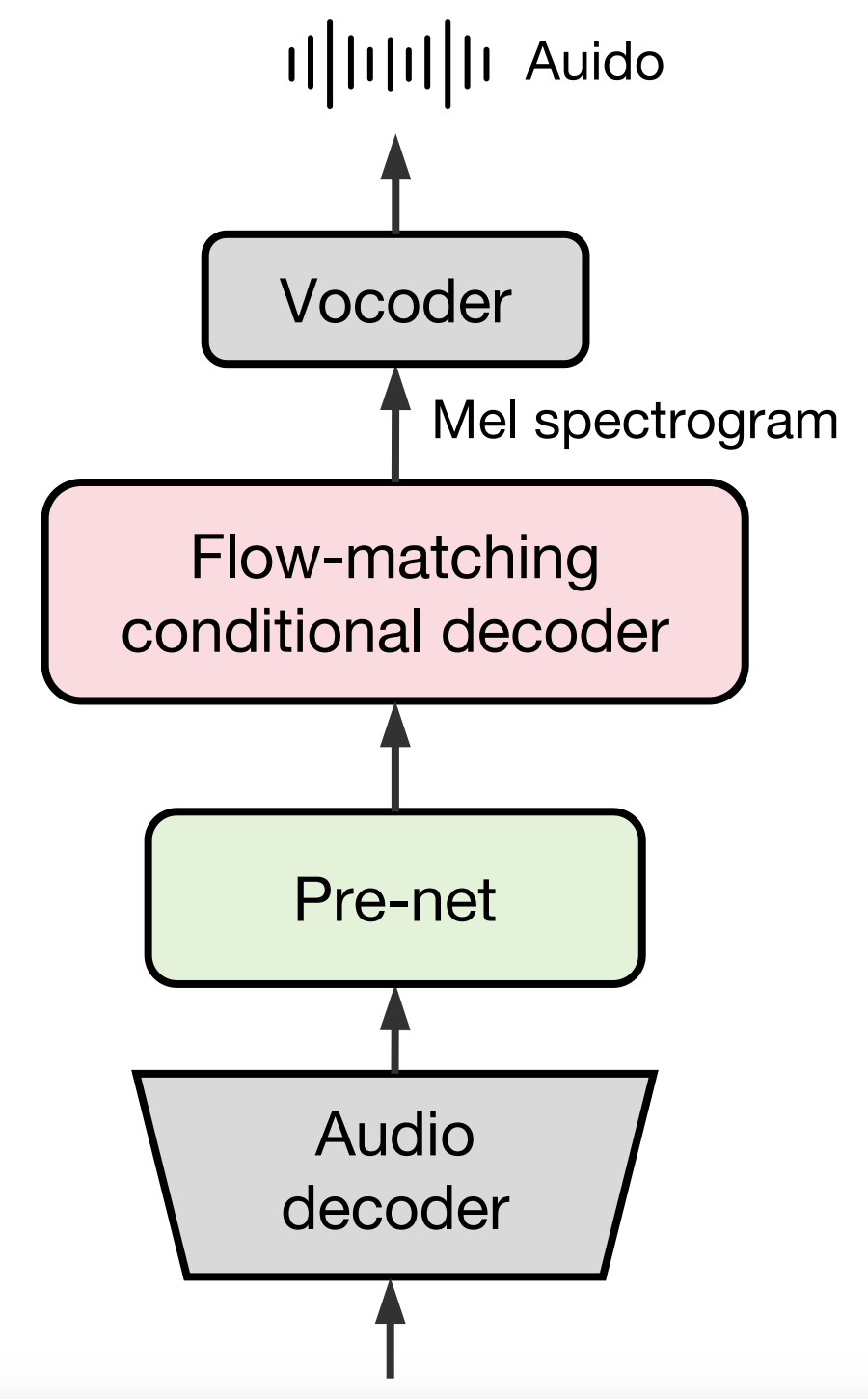
基于流匹配的音频解码器用于重建高质量的梅尔频谱图。该模型在 24 kHz 音频上进行训练,以生成目标梅尔频谱图,然后通过声码器将其转换为音频波形。
预训练细节
预训练数据
音频训练数据可大致分为两大类:音频理解数据和音频生成数据。
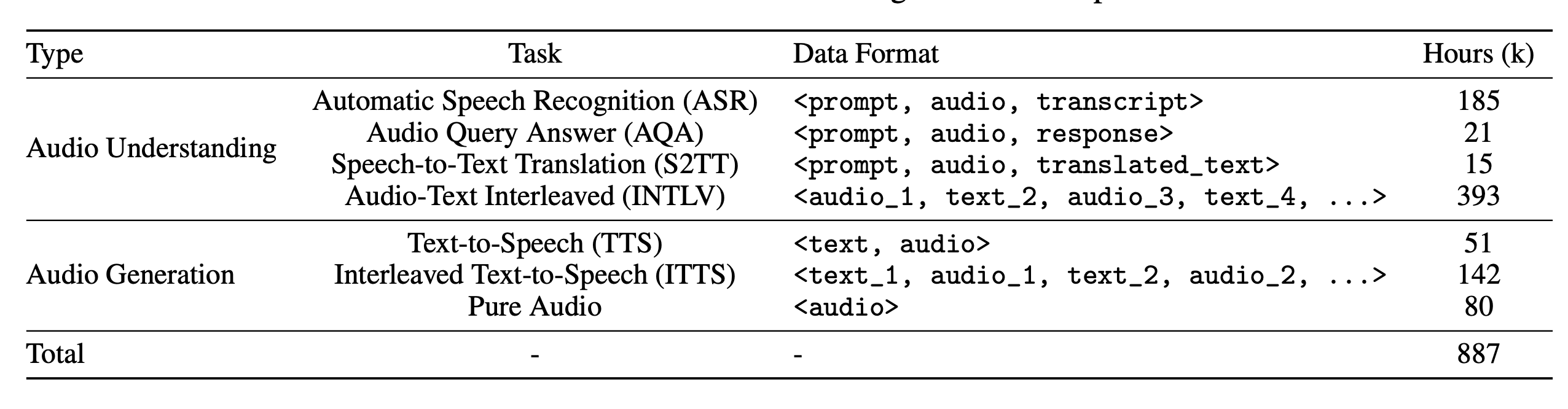
音频-文本配对数据(如 ASR 和 TTS 数据)可提高基本语音任务的性能。另一方面,纯音频数据可提高独立处理音频模式的能力。音频-文本交错数据由交替的文本和音频模式组成,并用标点符号分割,以促进跨模式知识转移。交错文本到语音数据由完全对齐的文本和音频内容组成,旨在增强模型在文本监督下生成音频标记的能力。
交错数据收集过程分为爬行和合成两种类型,总共产生了 142k 小时的 ITTS 数据和 393k 小时的 INTLV 数据。
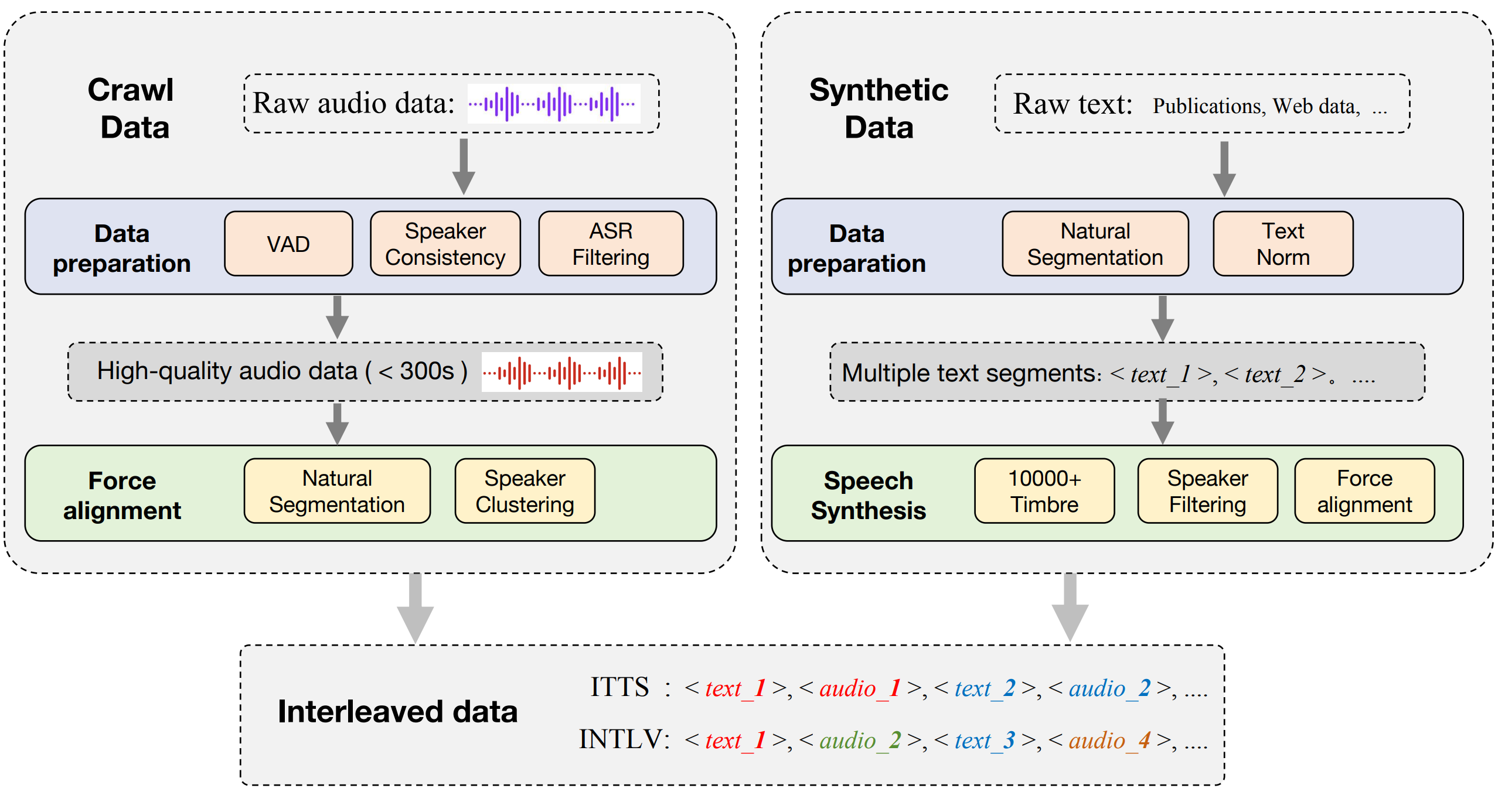
- 两阶段训练策略
语音和文本模式之间的冲突可能会干扰预训练 LLM 中的预训练文本知识表示,从而导致模型智能性能下降。为了缓解这一问题,我们采用了两阶段训练策略。在第一阶段,LLM 参数保持固定,只更新音频嵌入层和音频头参数。在第二阶段,除 LLM 嵌入层和 LLM 头参数外的所有参数都要进行训练。
WebUI Demo
conda create -n baichuan_omni python==3.12
conda activate baichuan_omni
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
pip install accelerate flash_attn==2.6.3 speechbrain==1.0.0 deepspeed==0.14.4
apt install llvm ffmpeg
将 web_demo/constants.py 中的 MODEL_PATH 修改为本地模型路径。
ASR 和 TTS Demo
cd web_demo
python base_asr_demo.py
python base_tts_demo.py
语音交互演示
cd web_demo
python s2s_gradio_demo_cosy_multiturn.py
Open-Source Evaluation Set
OpenAudioBench
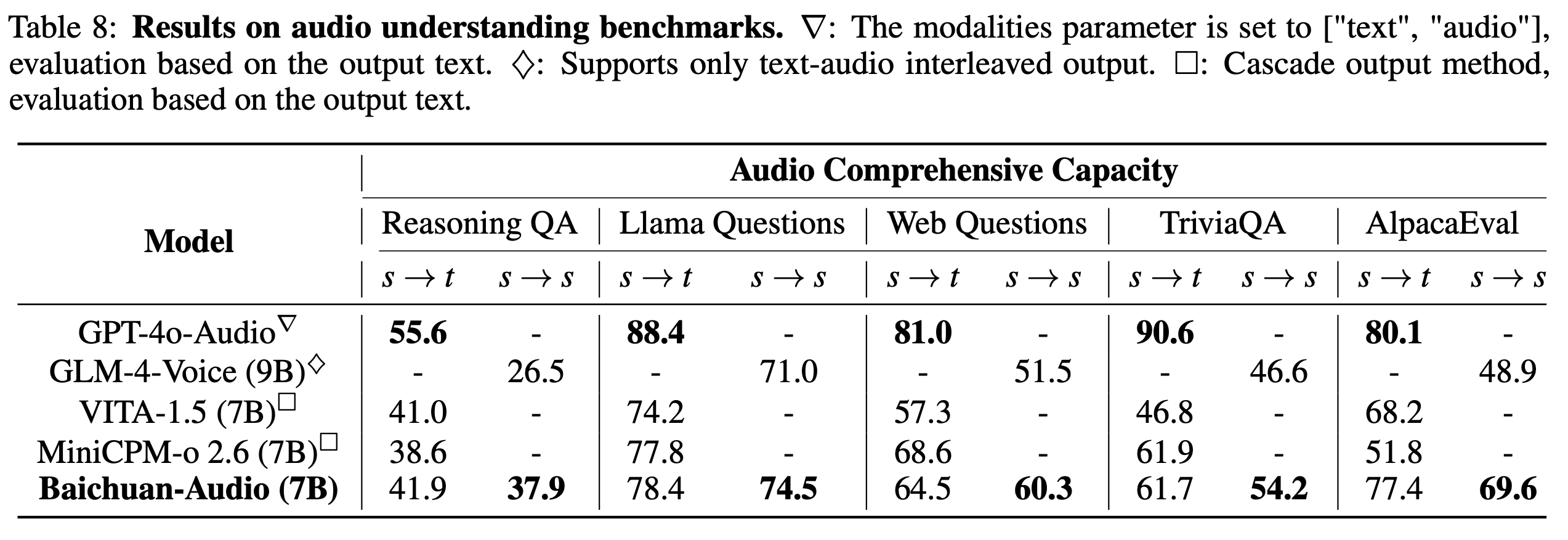
为了更有效地评估模型的 “智能”,我们构建了 OpenAudioBench,其中包括 5 个用于端到端音频理解的子评估集。其中包括 4 个公共评估集(骆驼问题、WEB QA、TriviaQA、AlpacaEval)和百川团队构建的语音逻辑推理评估集,共计 2701 个数据点。这个综合数据集反映了模型的 "智能 "水平。
模型性能
感谢
- 自动语音识别(ASR)模型:Whisper
- 大语言模型(LLM):Qwen2.5 7B
-部分代码来自:CosyVoice 和 Matcha-TTS:(https://github.com/FunAudioLLM/CosyVoice, https://github.com/shivammehta25/Matcha-TTS/) - 来自 CosyVoice 2.0 的 HiFi-GAN Vocoder: (https://funaudiollm.github.io/cosyvoice2/)