机器学习-简要与数据集加载
一.机器学习简要
1.1 概念
机器学习即计算机在数据中总结规律并预测未来结果,这一过程仿照人类的学习过程进行。
深度学习是机器学习中的重要算法的其中之一,是一种偏近现代的算法。
1.2 机器学习发展历史
从上世纪50年代的图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期。
60年代中到70年代末的发展几乎停滞。
80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。
90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。
21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。
从2012年开始,随着算力提升和海量训练样本的支持,深度学习(Deep Learning)成为机器学习研究热点,并带动了产业界的广泛应用。
1.3机器学习分类
1.3.1 监督学习
从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。(标签是训练数据中给定的答案,机器学习的目标就是预测出正确答案)
监督学习主要用于回归和分类:
回归主要用于预测连续的,具体的值(比如房价预测);
分类用于预测非连续的,离散型的数据(比如动物类别预测)。
1.3.2 半监督学习
利用少量标注数据和大量无标注数据进行学习的模式。
1.3.3 无监督学习
从未标注数据中寻找隐含结构的过程。
1.3.4 强化学习
强化学习中,有两个可交互对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
这其实就类似于两个AI模型共同进行学习,一个充当环境,一个充当智能体,通过不断的交互,智能体不断学习到最佳策略,从而在环境中获得最大的收益。
1.4 机器学习应用场合
1.4.1 自然语言处理(NLP)
自然语言处理是人工智能中的重要领域之一,涉及计算机与人类自然语言的交互。NLP技术可以实现语音识别、文本分析、情感分析等任务
1.4.2 医疗诊断与影像分析
包括医疗图像分析、疾病预测、药物发现等。深度学习模型在医疗影像诊断中的表现引人注目。
1.4.3 金融风险管理
尤其是在风险管理方面。模型可以分析大量的金融数据,预测市场波动性、信用风险等。
1.4.4 预测与推荐系统
如销售预测、个性化推荐等。协同过滤和基于内容的推荐是常用的技术。
1.4.5 制造业和物联网
物联网(IoT)在制造业中的应用越来越广泛,机器学习可用于处理和分析传感器数据,实现设备预测性维护和质量控制。
1.4.6 能源管理与环境保护
机器学习可以帮助优化能源管理,减少能源浪费,提高能源利用效率。通过分析大量的能源数据,识别优化的机会。
1.4.7 决策支持与智能分析
帮助分析大量数据,辅助决策制定。基于数据的决策可以更加准确和有据可依。
1.4.8 图像识别与计算机视觉
图像识别和计算机视觉是另一个重要的机器学习应用领域,它使计算机能够理解和解释图像。深度学习模型如卷积神经网络(CNN)在图像分类、目标检测等任务中取得了突破性进展。
1.5 机器学习基本步骤
(1)收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
(2)准备数据(包含特征提取):任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
(3)训练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定)。
(4)评估模型:为了测试准确性,使用数据的第二部分(测试数据)。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
(5)提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
这五个步骤将贯穿整个机器学习领域,务必记住。
二.scikit-learn工具
(1)Python语言机器学习工具
(2)Scikit-learn包括许多智能的机器学习算法的实现
(3)Scikit-learn官网:https://scikit-learn.org/stable/#
(4)Scikit-learn中文文档:https://scikitlearn.com.cn/
(5)Scikit-learn安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
三.数据集
3.1 玩具数据集
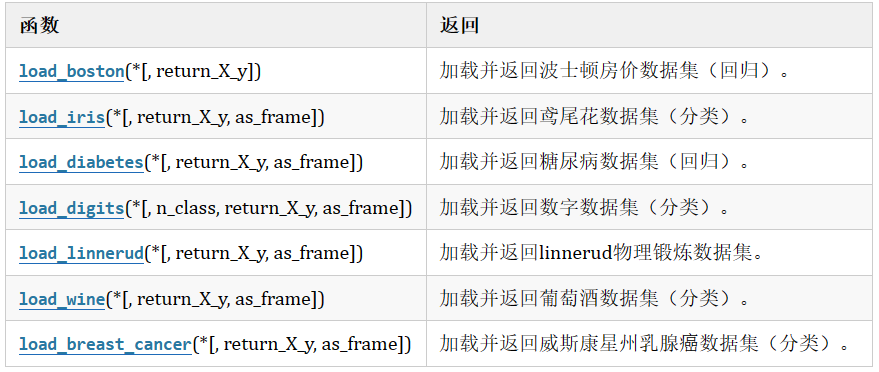
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取。
注意:回归数据集是没有target_name即标签名属性的,因为回归的预测是一个连续值,不是分类中的0,1,2等就可以表示的东西。
3.2 现实世界数据集

数据量大,但也属于sklearn,数据只能通过网络获取。
3.3 第三方数据集
从网上找的其他数据集或者公司内部的数据集。
3.4 数据集加载
接下来看看sklearn加载数据集:
# 糖尿病数据集分析(回归)
from sklearn.datasets import load_diabetes# 加载数据集
diabetes = load_diabetes()# print(digits),这里可以看出数据集是一个字典# 查看糖尿病的特征数据集,这里提取后是一个二维数组
data = diabetes.data
print(data[0:5])
print(type(data))
print(data.shape)
print(data.dtype)
print(diabetes.feature_names) # 这里是特征名称[[ 0.03807591 0.05068012 0.06169621 0.02187239 -0.0442235 -0.03482076
-0.04340085 -0.00259226 0.01990749 -0.01764613]
[-0.00188202 -0.04464164 -0.05147406 -0.02632753 -0.00844872 -0.01916334
0.07441156 -0.03949338 -0.06833155 -0.09220405]
[ 0.08529891 0.05068012 0.04445121 -0.00567042 -0.04559945 -0.03419447
-0.03235593 -0.00259226 0.00286131 -0.02593034]
[-0.08906294 -0.04464164 -0.01159501 -0.03665608 0.01219057 0.02499059
-0.03603757 0.03430886 0.02268774 -0.00936191]
[ 0.00538306 -0.04464164 -0.03638469 0.02187239 0.00393485 0.01559614
0.00814208 -0.00259226 -0.03198764 -0.04664087]]
<class 'numpy.ndarray'>
(442, 10)
float64
['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
# 查看糖尿病的标签数据集,这里是一个一维数组
target = diabetes.target
print(target[0:5])
print(type(target))
print(target.shape)
print(target.dtype)[151. 75. 141. 206. 135.]
<class 'numpy.ndarray'>
(442,)
float64
由于这个数据集是回归数据集,所以是没有标签名的。
# 数字数据集分析(分类)
from sklearn.datasets import load_digits# 加载数据集
digits = load_digits()# print(digits),这里可以看出数据集是一个字典# 查看数字的特征数据集,这里提取后是一个二维数组
data = digits.data
print(data[0:5])
print(type(data))
print(data.shape)
print(data.dtype)
print(digits.feature_names) # 这里是特征名称[[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
[ 0. 0. 0. 12. 13. 5. 0. 0. 0. 0. 0. 11. 16. 9. 0. 0. 0. 0.
3. 15. 16. 6. 0. 0. 0. 7. 15. 16. 16. 2. 0. 0. 0. 0. 1. 16.
16. 3. 0. 0. 0. 0. 1. 16. 16. 6. 0. 0. 0. 0. 1. 16. 16. 6.
0. 0. 0. 0. 0. 11. 16. 10. 0. 0.]
[ 0. 0. 0. 4. 15. 12. 0. 0. 0. 0. 3. 16. 15. 14. 0. 0. 0. 0.
8. 13. 8. 16. 0. 0. 0. 0. 1. 6. 15. 11. 0. 0. 0. 1. 8. 13.
15. 1. 0. 0. 0. 9. 16. 16. 5. 0. 0. 0. 0. 3. 13. 16. 16. 11.
5. 0. 0. 0. 0. 3. 11. 16. 9. 0.]
[ 0. 0. 7. 15. 13. 1. 0. 0. 0. 8. 13. 6. 15. 4. 0. 0. 0. 2.
1. 13. 13. 0. 0. 0. 0. 0. 2. 15. 11. 1. 0. 0. 0. 0. 0. 1.
12. 12. 1. 0. 0. 0. 0. 0. 1. 10. 8. 0. 0. 0. 8. 4. 5. 14.
9. 0. 0. 0. 7. 13. 13. 9. 0. 0.]
[ 0. 0. 0. 1. 11. 0. 0. 0. 0. 0. 0. 7. 8. 0. 0. 0. 0. 0.
1. 13. 6. 2. 2. 0. 0. 0. 7. 15. 0. 9. 8. 0. 0. 5. 16. 10.
0. 16. 6. 0. 0. 4. 15. 16. 13. 16. 1. 0. 0. 0. 0. 3. 15. 10.
0. 0. 0. 0. 0. 2. 16. 4. 0. 0.]]
<class 'numpy.ndarray'>
(1797, 64)
float64
['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4', 'pixel_0_5', 'pixel_0_6', 'pixel_0_7', 'pixel_1_0', 'pixel_1_1', 'pixel_1_2', 'pixel_1_3', 'pixel_1_4', 'pixel_1_5', 'pixel_1_6', 'pixel_1_7', 'pixel_2_0', 'pixel_2_1', 'pixel_2_2', 'pixel_2_3', 'pixel_2_4', 'pixel_2_5', 'pixel_2_6', 'pixel_2_7', 'pixel_3_0', 'pixel_3_1', 'pixel_3_2', 'pixel_3_3', 'pixel_3_4', 'pixel_3_5', 'pixel_3_6', 'pixel_3_7', 'pixel_4_0', 'pixel_4_1', 'pixel_4_2', 'pixel_4_3', 'pixel_4_4', 'pixel_4_5', 'pixel_4_6', 'pixel_4_7', 'pixel_5_0', 'pixel_5_1', 'pixel_5_2', 'pixel_5_3', 'pixel_5_4', 'pixel_5_5', 'pixel_5_6', 'pixel_5_7', 'pixel_6_0', 'pixel_6_1', 'pixel_6_2', 'pixel_6_3', 'pixel_6_4', 'pixel_6_5', 'pixel_6_6', 'pixel_6_7', 'pixel_7_0', 'pixel_7_1', 'pixel_7_2', 'pixel_7_3', 'pixel_7_4', 'pixel_7_5', 'pixel_7_6', 'pixel_7_7']
# 查看数字的标签数据集,这里是一个一维数组
target = digits.target
print(target[0:5])
print(type(target))
print(target.shape)
print(target.dtype)
print(digits.target_names) # 这里是标签名称[0 1 2 3 4]
<class 'numpy.ndarray'>
(1797,)
int64
[0 1 2 3 4 5 6 7 8 9]